Python编程异步爬虫——协程的基本原理
Python编程之异步爬虫
协程的基本原理
要实现异步机制的爬虫,自然和协程脱不了关系。
- 案例引入
先看一个案例网站,地址为https://www.httpbin.org/delay/5,访问这个链接需要先等5秒钟才能得到结果,这是因为服务器强制等待5秒时间才返回响应。下面来测试一下,用requests写一个遍历程序,直接遍历100次案例网站,看看效果,代码如下:
import requests
import logging
import timelogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s:%(message)s')TOTAL_NUMBER = 100
URL = 'https://www.httpbin.org/delay/5'
start_time = time.time()
for _ in range(1, TOTAL_NUMBER + 1):logging.info('scraping %s', URL)response = requests.get(URL)end_time = time.time()
logging.info('total time %s seconds', end_time - start_time)
使用的是requests单线程,在爬取之前和爬取之后分别记录了时间,最后输出了爬取100个页面消耗的总时间。运行结果如下:
2024-03-23 18:45:12,159 - INFO:scraping https://www.httpbin.org/delay/5
2024-03-23 18:45:18,693 - INFO:scraping https://www.httpbin.org/delay/5
2024-03-23 18:45:24,865 - INFO:scraping https://www.httpbin.org/delay/5
2024-03-23 18:45:30,957 - INFO:scraping https://www.httpbin.org/delay/5
2024-03-23 18:45:37,544 - INFO:scraping https://www.httpbin.org/delay/5
….
….
2024-03-23 18:55:19,929 - INFO:scraping https://www.httpbin.org/delay/5
2024-03-23 18:55:26,069 - INFO:scraping https://www.httpbin.org/delay/5
2024-03-23 18:55:32,186 - INFO:total time 620.0276908874512 seconds
由于每个页面至少等待5秒钟,100个页面至少花费500秒,加上网站本身负载问题,总时间大约620秒,10分钟多。
- 基础知识
协程的基础概念
1. 阻塞和非阻塞:
- 阻塞:当一个任务执行时,如果需要等待某个操作完成才能继续执行,这个任务就会被阻塞。在阻塞状态下,任务无法执行其他操作。
- 非阻塞:相对于阻塞,非阻塞任务在等待某个操作完成时,可以继续执行其他操作。
2. 同步和异步:
- 同步:指的是程序按照代码顺序依次执行,一个操作完成之后才会进行下一个操作。
- 异步:异步编程允许程序在等待某个操作的同时继续执行其他操作,操作完成后通过回调或者事件通知来处理结果。
3. 多进程和协程:
- 多进程:每个进程有自己独立的内存空间,系统为每个进程分配资源,进程间通信开销较大。
- 协程:协程(coroutine)是一种轻量级的线程,可以看作是在同一个线程内部进行切换执行不同任务,共享同一个进程的资源,更高效利用 CPU 和内存。
协程的特点:
- 轻量级: 协程不需要像线程那样创建新的进程或者线程,因此比多线程的切换开销更小。
- 灵活性: 协程可以根据需要暂停和恢复执行,可以实现任务的合理调度。
- 高效性: 由于不需要进行系统调用、进程/线程切换,协程可以更高效地利用计算资源。
在 Python 中,使用 asyncio 库可以实现协程。通过 async 和 await 关键字可以定义异步函数和阻塞点,在适当的时机挂起和恢复函数的执行。
协程的优点在于它们可以解决异步编程中的并发性问题,并且能够提供更好的性能和资源利用率。通过合理地使用协程,可以实现高效的并发编程,尤其在 I/O 密集型应用中表现突出。
-
协程的用法
在 Python 中,可以使用
asyncio库来实现协程。以下是协程的基本用法示例:- 定义一个异步函数
使用
async def关键字定义一个异步函数,该函数可以包含await表达式来挂起执行。import asyncioasync def greet():print("Hello")await asyncio.sleep(1)print("World")b. 运行协程任务
使用
asyncio.run()函数来运行协程任务,并且保证事件循环的创建和销毁。asyncio.run(greet())c. 创建并发任务
使用
asyncio.create_task()函数创建多个并发任务,让它们同时运行。async def task1():print("Task 1 start")await asyncio.sleep(2)print("Task 1 end")async def task2():print("Task 2 start")await asyncio.sleep(1)print("Task 2 end")async def main():taskA = asyncio.create_task(task1())taskB = asyncio.create_task(task2())await taskAawait taskBasyncio.run(main())d. 并发等待多个任务完成
使用
asyncio.gather()函数等待多个任务完成后再继续执行。async def main():tasks = [task1(), task2()]await asyncio.gather(*tasks)asyncio.run(main())e. 异步IO操作
在协程中可以进行异步的IO操作,例如网络请求、文件读写等操作,以提高应用程序的性能和效率。
通过上述示例,您可以了解到如何定义、运行和管理协程,以及如何利用协程来处理并发任务和异步IO操作。在实际应用中,协程可以帮助降低资源消耗,提高程序响应性,并简化复杂的并发编程任务。
-
定义协程
import asyncioasync def execute(x):print('Number:', x)coroutine = execute(1) print('Coroutine:', coroutine) print('After calling excute')loop = asyncio.get_event_loop() loop.run_until_complete(coroutine) print('After calling loop')运行结果如下: Coroutine: <coroutine object execute at 0x10f5b37c0> After calling excute Number: 1 After calling loop导入asyncio包,这样才可以使用async和await关键字。然后使用async定义一个execute方法,该方法接收一个数字参数x,执行之后会打印这个数字。
随后直接执行execute方法,然而这个方法没有执行,而是返回了一个coroutine协程对象。之后我们使用了get_event_loop方法创建了一个事件循环loop,调用loop对象的run_until_complete方法将协程对象注册到了事件循环中,接着启动。可见,async定义的方法会变成一个无法直接执行的协程对象,必须将此对象注册到事件循环中才可以执行。
当我们把协程对象coroutine传递给run_until_complete方法的时候,实际上它进行了一个操作,就是将coroutine封装成task对象。显示声明,代码如下:
import asyncioasync def execute(x):print('Number:', x)return xcoroutine = execute(1) print('Coroutine:', coroutine) print('After calling execute')loop = asyncio.get_event_loop() task = loop.create_task(coroutine) print('Task:',task) loop.run_until_complete(task) print('Task:', task) print('After calling loop')运行结果如下: Coroutine: <coroutine object execute at 0x10faf37c0> After calling execute Task: <Task pending name='Task-1' coro=<execute() running at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/协程用法4.py:3>> Number: 1 Task: <Task finished name='Task-1' coro=<execute() done, defined at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/协程用法4.py:3> result=1> After calling loop定义task对象还有另外一种方法,就是直接调用asyncio包的ensure_future方法,返回结果也是task对象,写法如下:
import asyncioasync def execute(x):print('Number:', x)return xcoroutine = execute(1) print('Coroutine:', coroutine) print('After calling execute')task = asyncio.ensure_future(coroutine) print('Task:', task) loop = asyncio.get_event_loop() loop.run_until_complete(task) print('Task:', task) print('After calling loop')运行结果如下: Coroutine: <coroutine object execute at 0x10c3737c0> After calling execute Task: <Task pending name='Task-1' coro=<execute() running at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/协程用法5.py:3>> Number: 1 Task: <Task finished name='Task-1' coro=<execute() done, defined at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/协程用法5.py:3> result=1> After calling loop -
绑定回调
为某个task对象绑定一个回调方法,如下所示:
import asyncio import requestsasync def request():url = 'https://www.baidu.com'status = requests.get(url)return statusdef callback(task):print('Status:', task.result())coroutine = request() task = asyncio.ensure_future(coroutine) task.add_done_callback(callback) print('Task:', task)loop = asyncio.get_event_loop() loop.run_until_complete(task) print('Task:', task)定义了request方法,在这个方法里请求了百度,并获取了其状态码,随后我们定义了callback方法,这个方法接收一个参数,参数是task对象,在这个方法中调用print方法打印出task对象的结果。这样就定义好了一个协程对象和一个回调方法,我们希望达到的效果是,当协程对象执行完毕后,就去执行声明的callback方法。如何关联的呢?只要调用add_done_callback方法就行。将callback方法传递给封装好的task对象。这样当task执行完之后,就可以调用callback方法了。同时task对象还会作为参数传递给callback方法,调用task对象的result方法就可以获取返回结果了。运行结果如下:
Task: <Task pending name='Task-1' coro=<request() running at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/绑定回调.py:4> cb=[callback() at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/绑定回调.py:9]> status: <Response [200]> task: <Task finished name='Task-1' coro=<request() done, defined at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/绑定回调.py:4> result=<Response [200]>>实际上,即使不使用回调方法,在task运行完毕后,也可以直接调用result方法获取结果,代码如下:
import asyncio import requestsasync def request():url = 'https://www.baidu.com'status = requests.get(url)return statuscoroutine = request() task = asyncio.ensure_future(coroutine) print('Task:', task)loop = asyncio.get_event_loop() loop.run_until_complete(task) print('Task:', task) print('Task Result:', task.result())运行结果如下: Task: <Task pending name='Task-1' coro=<request() running at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/绑定回调1.py:5>> Task: <Task finished name='Task-1' coro=<request() done, defined at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/绑定回调1.py:5> result=<Response [200]>> Task Result: <Response [200]> -
多任务协程
如果想执行多次请求,应该怎么办?可以定义一个task列表,然后使用asyncio包中的wait方法执行,如下所示:
import asyncio import requestsasync def request():url = 'https://www.baidu.com'status = requests.get(url)return statustasks = [asyncio.ensure_future(request()) for _ in range(5)] print('Tasks:', tasks)loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks))for task in tasks:print('Task Result:', task.result())运行结果如下: Tasks: [<Task pending name='Task-1' coro=<request() running at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/多任务协程.py:5>>, <Task pending name='Task-2' coro=<request() running at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/多任务协程.py:5>>, <Task pending name='Task-3' coro=<request() running at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/多任务协程.py:5>>, <Task pending name='Task-4' coro=<request() running at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/多任务协程.py:5>>, <Task pending name='Task-5' coro=<request() running at /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第6章异步爬虫/多任务协程.py:5>>] Task Result: <Response [200]> Task Result: <Response [200]> Task Result: <Response [200]> Task Result: <Response [200]> Task Result: <Response [200]> -
协程实现
协程在解决IO密集型任务方面的优势,耗时等待一般都是IO操作,例如文件读取、网络请求等。协程在处理这种操作时是有很大优势的,当遇到需要等待的情况时,程序可以暂时挂起,转而执行其他操作,避免浪费时间。
以https://www.httpbin.org/delay/5为例,体验一下协程的效果。示例代码如下:
import asyncio import requests import timestart = time.time()async def request():url = 'https://www.httpbin.org/delay/5'print('waiting for', url)response = requests.get(url)print('Get response from', url, 'response', response)tasks = [asyncio.ensure_future(request()) for _ in range(10)] loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks))end = time.time() print('Cost time:', end - start)运行结果如下: waiting for https://www.httpbin.org/delay/5 Get response from https://www.httpbin.org/delay/5 response <Response [200]> waiting for https://www.httpbin.org/delay/5 Get response from https://www.httpbin.org/delay/5 response <Response [200]> waiting for https://www.httpbin.org/delay/5 Get response from https://www.httpbin.org/delay/5 response <Response [200]> ... waiting for https://www.httpbin.org/delay/5 Get response from https://www.httpbin.org/delay/5 response <Response [200]> waiting for https://www.httpbin.org/delay/5 Get response from https://www.httpbin.org/delay/5 response <Response [200]> waiting for https://www.httpbin.org/delay/5 Get response from https://www.httpbin.org/delay/5 response <Response [200]> Cost time: 63.61974787712097可以发现,与正常的顺序请求没有啥区别。那么异步处理的优势呢?要实现异步处理,先得有挂起操作,当一个任务需要等待IO结果的时候,可以挂起当前任务,转而执行其他任务,这样才能充分利用好资源。
-
使用aiohttp
aiohttp是一个支持异步请求的库,它和asyncio配合使用,可以使我们非常方便地实现异步请求操作。
aiohttp分为两部分:一部分是Client,一部分是Server。
下面我们将aiohttp投入使用,将代码改成如下:
import asyncio import aiohttp import timestart = time.time()async def get(url):session = aiohttp.ClientSession()response = await session.get(url)await response.text()await session.close()return responseasync def request():url = 'https://www.httpbin.org/delay/5'print('Waiting for', url)response = await get(url)print('Get response from', url, 'response', response)tasks = [asyncio.ensure_future(request()) for _ in range(10)] loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks))end = time.time() print('Cost time:', end - start)运行结果如下: Waiting for https://www.httpbin.org/delay/5 Waiting for https://www.httpbin.org/delay/5 Waiting for https://www.httpbin.org/delay/5 Waiting for https://www.httpbin.org/delay/5 Waiting for https://www.httpbin.org/delay/5 Waiting for https://www.httpbin.org/delay/5 ... Get response from https://www.httpbin.org/delay/5 response <ClientResponse(https://www.httpbin.org/delay/5) [200 OK]> <CIMultiDictProxy('Date': 'Sat, 23 Mar 2024 13:42:05 GMT', 'Content-Type': 'application/json', 'Content-Length': '367', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true')>Get response from https://www.httpbin.org/delay/5 response <ClientResponse(https://www.httpbin.org/delay/5) [200 OK]> <CIMultiDictProxy('Date': 'Sat, 23 Mar 2024 13:42:05 GMT', 'Content-Type': 'application/json', 'Content-Length': '367', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true')> ... Get response from https://www.httpbin.org/delay/5 response <ClientResponse(https://www.httpbin.org/delay/5) [200 OK]> <CIMultiDictProxy('Date': 'Sat, 23 Mar 2024 13:42:05 GMT', 'Content-Type': 'application/json', 'Content-Length': '367', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true')>Get response from https://www.httpbin.org/delay/5 response <ClientResponse(https://www.httpbin.org/delay/5) [200 OK]> <CIMultiDictProxy('Date': 'Sat, 23 Mar 2024 13:42:05 GMT', 'Content-Type': 'application/json', 'Content-Length': '367', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true')>Cost time: 6.868626832962036这里将请求库由requests改成了aiohttp,利用aiohttp库里ClientSession类的get方法进行请求。
测试一下并发量分别为1、3、5、10、….、500时的耗时情况,代码如下:
import asyncio import aiohttp import timedef test(number):start = time.time()async def get(url):session = aiohttp.ClientSession()response = await session.get(url)await response.text()await session.close()return responseasync def request():url = 'https://www.baidu.com/'await get(url)tasks = [asyncio.ensure_future(request()) for _ in range(number)]loop = asyncio.get_event_loop()loop.run_until_complete(asyncio.wait(tasks))end = time.time()print('Number:', number, 'Cost time:', end - start)for number in [1, 3, 5, 10, 15, 30, 50, 75, 100, 200, 500]:test(number)运行结果如下: Number: 1 Cost time: 0.23929095268249512 Number: 3 Cost time: 0.19086170196533203 Number: 5 Cost time: 0.20035600662231445 Number: 10 Cost time: 0.21305394172668457 Number: 15 Cost time: 0.25495195388793945 Number: 30 Cost time: 0.769071102142334 Number: 50 Cost time: 0.3470029830932617 Number: 75 Cost time: 0.4492309093475342 Number: 100 Cost time: 0.586918830871582 Number: 200 Cost time: 1.0910720825195312 Number: 500 Cost time: 2.4768006801605225
相关文章:

Python编程异步爬虫——协程的基本原理
Python编程之异步爬虫 协程的基本原理 要实现异步机制的爬虫,自然和协程脱不了关系。 案例引入 先看一个案例网站,地址为https://www.httpbin.org/delay/5,访问这个链接需要先等5秒钟才能得到结果,这是因为服务器强制等待5秒时…...
基于springboot+vue的旅游推荐系统
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、阿里云专家博主、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战,欢迎高校老师\讲师\同行交流合作 主要内容:毕业设计(Javaweb项目|小程序|Pyt…...

Debezium日常分享系列之:Debezium2.5稳定版本之Monitoring
Debezium日常分享系列之:Debezium2.5稳定版本之Monitoring 一、Snapshot metrics二、Streaming metrics三、Schema history metrics Debezium系列之:安装jmx导出器监控debezium指标 除了 Zookeeper、Kafka 和 Kafka Connect 提供的对 JMX 指标的内置支持…...
GuLi商城-商品服务-API-三级分类-网关统一配置跨域
参考文档: https://tangzhi.blog.csdn.net/article/details/126754515 https://github.com/OYCodeSite/gulimall-learning/blob/master/docs/%E8%B0%B7%E7%B2%92%E5%95%86%E5%9F%8E%E2%80%94%E5%88%86%E5%B8%83%E5%BC%8F%E5%9F%BA%E7%A1%80.md 谷粒商城-day04-完…...
【ai技术】(4):在树莓派上,使用qwen0.5b大模型+chatgptweb,搭建本地大模型聊天环境,速度飞快,非常不错!
1,视频地址 https://www.bilibili.com/video/BV1VK421i7CZ/ 【ai技术】(4):在树莓派4上,使用ollama部署qwen0.5b大模型chatgptweb前端界面,搭建本地大模型聊天工具,速度飞快 2,下载…...

深入理解PHP+Redis实现分布式锁的相关问题
概念 PHP使用分布式锁,受语言本身的限制,有一些局限性。 通俗理解单机锁问题:自家的锁锁自家的门,只能保证自家的事,管不了别人家不锁门引发的问题,于是有了分布式锁。分布式锁概念:是针对多个…...

perl:获取同花顺数据--业绩预告
perldoc LWP::UserAgent 如果没有安装,则安装模块,运行 cpanm LWP::UserAgent 。 编写 get_yjyg_10jqka.pl 如下 #!/usr/bin/perl # perl 获取同花顺数据--业绩预告 use LWP::UserAgent; use Encode qw(decode encode); use POSIX; use Data::Dump…...

如何对比引用传参和值传参两者的效率
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或…...

探索软件工程:构建可靠、高效的数字世界
软件工程是一门涵盖了设计、开发、测试、维护和管理软件的学科,它在如今数字化时代的发展中扮演着至关重要的角色。随着科技的不断进步和社会的不断变迁,软件工程的意义也愈发凸显。本文将探索软件工程的重要性、原则和实践,以及其对当今社会…...

超越肉眼:深入计算机视觉的奇妙之旅
揭秘计算机视觉的奥秘:从基础到前沿的探索之旅 引言:一、计算机视觉的基础1. 图像处理基础2. 特征提取与描述3. 基本模式识别 二、机器学习在计算机视觉中的应用1. 深度学习革命2. 迁移学习与多任务学习3. 强化学习与主动学习4. 无监督学习和自监督学习 …...
mac 安装 nvm 【真解决问题】
前提 没有node环境已有git 下载 我用的gitee极速下载 git clone https://gitee.com/mirrors/nvm.git ~/.nvm && cd ~/.nvm && git checkout git describe --abbrev0 --tags配置 1. 配置变量 在用户的目录下新增文件 .zshrc export NVM_DIR"$HOME/…...

【Godot 3.5控件】用TextureProgress制作血条
说明 本文写自2022年11月13日-14日,内容基于Godot3.5。后续可能会进行向4.2版本的转化。 概述 之前基于ProgressBar创建过血条组件。它主要是基于修改StyleBoxFlat,好处是它几乎可以算是矢量的,体积小,所有东西都是样式信息&am…...
真题- CC++ 研究生组)
第十届蓝桥杯大赛个人赛省赛(软件类)真题- CC++ 研究生组
第十届蓝桥杯大赛个人赛省赛(软件类)真题- C&C 研究生组-立方和 第十届蓝桥杯大赛个人赛省赛(软件类)真题- C&C 研究生组-字串数字 第十届蓝桥杯大赛个人赛省赛(软件类)真题- C&C 研究生组-质数…...
Linux:Gitlab:16.9.2 创建用户及项目仓库基础操作(2)
我在上一章介绍了基本的搭建以及邮箱配置 Linux:Gitlab:16.9.2 (rpm包) 部署及基础操作(1)-CSDN博客https://blog.csdn.net/w14768855/article/details/136821311?spm1001.2014.3001.5501 本章介绍一下用户的创建,组内设置用户&…...
【数据挖掘】实验5:数据预处理(1)
实验5:数据预处理(1) 一:实验目的与要求 1:熟悉和掌握数据预处理,学习数据清洗、数据集成、数据变换、数据规约、R语言中主要数据预处理函数。 二:实验内容 【缺失值分析】 第一步࿱…...

383.赎金信
给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。 如果可以,返回 true ;否则返回 false 。 magazine 中的每个字符只能在 ransomNote 中使用一次。 思路:将magazine 中字…...
)
Python 3 教程(8)
heisenbug601 601***902@qq.com 参考地址 311 tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出同学的名字: 代码如下: >>> classmates = (Michael, Bob, Tracy) 现在,classmates这个tuple不能变了,它也没有append(),insert()这样的方法…...
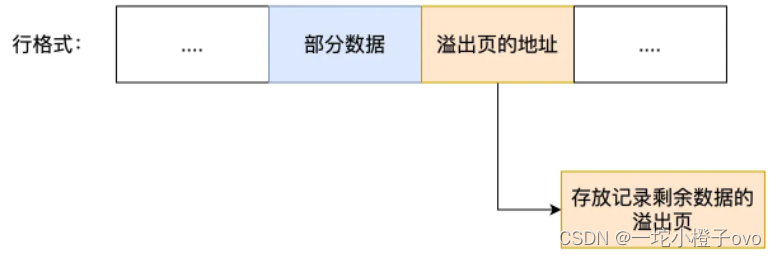
Mysql数据库深入理解
目录 一、什么是数据库 二、Mysql基本架构图 1.Mysql客户端/服务器架构 2.客户端与服务器的连接过程 3.服务器处理客户端请求 4.一条查询SQL执行顺序 4.1连接器 4.2查询缓存 4.3解析器 4.4执行器 4.4.1预处理阶段 4.4.2优化阶段 4.4.3执行阶段 5.一条记录如何存…...

android 音频焦点,音频策略梳理
音频焦点和音频策略两个不同的概念,容易搞混 先来看下音频焦点和音频策略直接的区别和联系 音频策略的主要功能是为该音频找到合适的硬件设备播放 1 音频策略流程: (从usage->device) attributesBuilder.setUsage--->audioservice.mCarAudioCont…...

go语言-基础元素与结构的使用
go基础元素与结构的使用,快速上手 编译go文件 编译为可执行文件 go build 文件名.go运行文件 ./文件名输入/输出 引用fmt库(关于输入输出的库) 输入 scanf按照给定的格式依次读取数据(包括非法数据),不…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

腾讯 Marvis 初级使用教程——从安装到上手
腾讯最新系统级AI助手Marvis(2026年5月20日发布),官网 https://marvis.qq.com,主打“一句话操作电脑”、跨端协同、GUI Agent执行。虽然是个【小龙虾】,但上手其实不难。这篇就简单写写 Marvis 的安装和基础使用&#…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...
原理与ScalableHD架构优化实践)
超维计算(HDC)原理与ScalableHD架构优化实践
1. 超维计算(HDC)基础解析超维计算(Hyperdimensional Computing, HDC)是一种受大脑信息处理机制启发的计算范式,其核心思想是用高维随机向量(通常称为超向量或HV)来表示和处理信息。与传统神经网…...

量子纠错码VarQEC:原理、实现与硬件优化
1. 量子纠错码基础与实验背景量子纠错码(Quantum Error Correction Codes, QEC)是量子计算中保护量子信息免受噪声影响的核心技术。与经典纠错码不同,量子纠错需要应对量子态特有的退相干和纠缠特性。传统QEC如[[5,1,3]]完美码虽然理论完备&a…...

网飞成立 AI 动画工作室,开启流媒体“原生 AI 制片时代”,中外布局逻辑有何不同?
1. Netflix“偷跑”在影视巨头关于 AIGC 的军备竞赛中,Netflix 再次加速。据外媒 TheVerge 报道,网飞于今年 3 月成立了名为 "INKubator" 的工作室,这是全球流媒体巨头中首个以生成式人工智能为核心的动画制作部门。此动作引发全球…...

告别手动预约:i茅台自动预约系统5分钟部署指南
告别手动预约:i茅台自动预约系统5分钟部署指南 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gitcode…...
)
告别KITTI!用TartanAir数据集在Unreal Engine仿真环境里“虐”你的VSLAM算法(附保姆级下载与使用指南)
用TartanAir数据集在Unreal Engine中打造VSLAM算法的"极限考场"当你的视觉SLAM算法在KITTI数据集上跑出98%的准确率时,是否意味着它已经准备好应对真实世界的复杂场景?现实往往会给乐观的开发者当头一棒——实验室里的"优等生"在遇到…...

昇腾CANN cmake 实战:CANN CMake 构建系统——跨平台编译配置与模块化管理
8 个 CANN 仓库各需独立构建(ops-transformer/ops-nn/hccl/ge/…)→ 手写 8 套 CMakeLists.txt(CANN 路径判断、跨 NPU 型号编译、第三方库兼容)。cmake 仓库提供统一的 FindCANN.cmake CANNConfig.cmake 模板——任何仓库只需 f…...