在MongoDB建模1对N关系的基本方法

“我在 SQL 和规范化数据库方面拥有丰富的经验,但我只是 MongoDB 的初学者。如何建立一对 N 关系模型?” 这是我从参加 MongoDB 分享日活动的用户那里得到的最常见问题之一。
我对这个问题没有简短的答案,因为方法不只有一种,还有很多种方法。MongoDB 拥有丰富而细致的词汇来表达 SQL 中的内容,这些词汇被扁平化为术语“One-to-N”。让我带您了解一下您在建模一对 N 关系时的选择。
这里有很多值得讨论的内容,在这篇文章中,我将讨论建模一对 N 关系的三种基本方法。我还将介绍更复杂的模式设计,包括非规范化和双向引用。我将回顾所有的选择,并为您提供一些建议,以便您在建模单个一对 N 关系时可能会考虑的数千个选择中进行选择。想了解什么是**「数据库非规范化」**,以及何时不对数据进行非规范化,您可以直接跳转到文章末尾。
许多初学者认为在 MongoDB 中进行“一对多”建模的唯一方法是将子文档数组嵌入到父文档中,但事实并非如此。仅仅因为您可以嵌入文档,并不意味着您应该嵌入文档。
在设计 MongoDB 模式时,您需要从一个在使用 SQL 和规范化表时永远不会考虑的问题开始:**关系的基数是什么?**不那么正式地说:**您需要更细致地描述您的“一对多”关系:是“一对几个”、“一对多”还是“一对数”?**根据具体情况,您可以使用不同的格式来建模关系。
基础知识:一对多建模
“一对多”的一个例子可能是一个人的地址。这是嵌入的一个很好的用例。
您可以将地址放入 Person 对象内部的数组中:
> db.person.findOne()
{name: 'Kate Monster',ssn: '123-456-7890',addresses : [{ street: '123 Sesame St', city: 'Anytown', cc: 'USA' },{ street: '123 Avenue Q', city: 'New York', cc: 'USA' }]
}
这种设计具有嵌入的所有优点和缺点。主要的优点是你不必执行单独的查询来获取嵌入的细节;主要的缺点是你无法以独立的实体方式访问嵌入的细节。
例如,如果你正在建模一个任务跟踪系统,每个人都会被分配一些任务。将任务嵌入到人员文档中会使像“显示明天到期的所有任务”这样的查询变得比必要的复杂。我将在本文的后面部分介绍一种更适合检索这种用例数据的设计。
基础知识:一对多
“一对多”的一个例子可能是一个备件订购系统中的产品零件。
每个产品可能有多达数百个备件,但绝不会超过几千个左右(所有那些不同尺寸的螺栓、垫圈和垫片都会相加)。这是引用的一个很好的使用案例。你可以将零件的ObjectID放在产品文档的数组中。
*对于这些示例,我使用2字节的ObjectID,因为它们更容易阅读。实际的代码将使用12字节的ObjectID。
每个零件都有自己的文档:
> db.parts.findOne()
{_id : ObjectID('AAAA'),partno : '123-aff-456',name : '#4 grommet',qty: 94,cost: 0.94,
price: 3.99
每个产品都有自己的文档,其中包含了构成该产品的零件的ObjectID引用数组:
> db.products.findOne()
{name : 'left-handed smoke shifter',manufacturer : 'Acme Corp',catalog_number: 1234,parts : [ // array of references to Part documentsObjectID('AAAA'), // reference to the #4 grommet aboveObjectID('F17C'), // reference to a different PartObjectID('D2AA'),// etc]
然后,你将使用应用程序级联接来检索特定产品的零件:
// Fetch the Product document identified by this catalog number
> product = db.products.findOne({catalog_number: 1234});// Fetch all the Parts that are linked to this Product
> product_parts = db.parts.find({_id: { $in : product.parts } } ).toArray() ;
为了高效操作,您需要在“products.catalog_number”上有一个索引。请注意,“parts._id”上始终有一个索引,因此查询始终高效。
这种引用方式与嵌入具有互补的优点和缺点。**每个部分都是一个独立的文档,因此可以轻松地独立搜索和更新它们。**使用此模式的一个权衡是必须执行第二个查询才能获取有关产品零件的详细信息。(但是在我们讨论非规范化之前请保持这个想法。)
作为额外的好处,此模式允许您拥有多个产品使用的单独部件,因此您的一对 N 模式就变成了 N 对 N 模式,而不需要连接表!
基础知识:一到百千万
“one-to-squillions”的一个例子可能是收集不同机器的日志消息的事件日志系统。
任何给定的主机都可以生成足够的消息来溢出 16 MB 文档大小,即使您在数组中存储的只是 ObjectID。这是“父引用”的经典用例。您将有一个主机文档,然后将主机的 ObjectID 存储在日志消息的文档中。
> db.hosts.findOne()
{_id : ObjectID('AAAB'),name : 'goofy.example.com',ipaddr : '127.66.66.66'
}>db.logmsg.findOne()
{time : ISODate("2014-03-28T09:42:41.382Z"),message : 'cpu is on fire!',host: ObjectID('AAAB') // Reference to the Host document
}
您可以使用(略有不同)应用程序级联接来查找主机的最新 5,000 条消息:
// find the parent ‘host’ document
> host = db.hosts.findOne({ipaddr : '127.66.66.66'}); // assumes unique index// find the most recent 5000 log message documents linked to that host
> last_5k_msg = db.logmsg.find({host: host._id}).sort({time : -1}).limit(5000).toArray()
>
回顾
因此,即使在这个基本级别,设计 MongoDB 模式时也比为规范化数据库设计类似的关系数据库模式时需要考虑更多。您需要考虑两个因素:
● 一对 N 的“N”端的实体是否需要独立?
● 关系的基数是多少:是一对多吗?一对多;还是一比十呢?
基于这些因素,您可以选择三种基本的一对 N 模式设计之一:
● 如果基数是一对多,并且不需要在父对象的上下文之外访问嵌入的对象,则嵌入 N 端。
● 如果基数是一对多或者 N 端对象由于任何原因应该独立,则使用对 N 端对象的引用数组。
● 如果基数为 1 到 squillions,请使用对 N 端对象中的 One-side 的引用。
中级:双向参考
如果您想变得更奇特一点,您可以结合两种技术,并在模式中包含两种引用样式,既具有从“一”侧到“多”侧的引用,又具有从“多”侧到“一”侧的引用。
举个例子,让我们回到任务跟踪系统。有一个保存“人员”文档的“人员”集合,一个保存任务文档的“任务”集合,以及从人员到任务的一对 N 关系。应用程序需要跟踪人员拥有的所有任务,因此我们需要将人员引用到任务。
通过对 Task 文档的引用数组,单个 Person 文档可能如下所示:
db.person.findOne()
{_id: ObjectID("AAF1"),name: "Kate Monster",tasks [ // array of references to Task documentsObjectID("ADF9"), ObjectID("AE02"),ObjectID("AE73") // etc]
}
另一方面,在某些其他上下文中,此应用程序将显示任务列表(例如,多人项目中的所有任务),并且需要快速找到负责每个任务的人员。为此,您可以通过在任务文档中添加对人员的附加引用来优化数据检索。
db.tasks.findOne()
{_id: ObjectID("ADF9"), description: "Write lesson plan",due_date: ISODate("2014-04-01"),owner: ObjectID("AAF1") // Reference to Person document
}
此设计具有“一对多”模式的所有优点和缺点,但还添加了一些内容。将额外的“所有者”引用放入任务文档中意味着可以快速轻松地找到任务的所有者,但这也意味着如果您需要将任务重新分配给另一个人,则需要执行两次更新,而不仅仅是一次。具体来说,您必须更新从人员到任务文档的引用以及从任务到人员的引用。
*对于正在阅读本文的关系数据库专家来说,您是对的;在规范化数据库模型上使用此模式设计意味着不再可能通过单个原子更新将任务重新分配给新人员。这对于我们的任务跟踪系统是可以的;您需要考虑这是否适合您的特定用例。
中级:具有一对多关系的数据库非规范化
除了对各种关系进行建模之外,您还可以将非规范化添加到模式中。这可以消除在某些情况下执行应用程序级联接的需要,但代价是执行更新时会增加一些复杂性。一个例子将有助于阐明这一点。
数据库非规范化从多到一
对于零件示例,您可以将零件名称非规范化到“parts[]”数组中。作为参考,这里是没有非规范化的产品文档版本。
> db.products.findOne()
{name : 'left-handed smoke shifter',manufacturer : 'Acme Corp',catalog_number: 1234,parts : [ // array of references to Part documentsObjectID('AAAA'), // reference to the #4 grommet aboveObjectID('F17C'), // reference to a different PartObjectID('D2AA'),// etc]
}
非规范化意味着您在显示产品的所有部件名称时不必执行应用程序级联接,但如果您需要有关部件的任何其他信息,则必须执行该联接。
> db.products.findOne()
{name : 'left-handed smoke shifter',manufacturer : 'Acme Corp',catalog_number: 1234,parts : [{ id : ObjectID('AAAA'), name : '#4 grommet' }, // Part name is denormalized{ id: ObjectID('F17C'), name : 'fan blade assembly' },{ id: ObjectID('D2AA'), name : 'power switch' },// etc]
}
虽然可以更轻松地获取部件名称,但这只会在应用程序级连接中添加一些客户端工作:
// Fetch the product document
> product = db.products.findOne({catalog_number: 1234}); // Create an array of ObjectID()s containing *just* the part numbers
> part_ids = product.parts.map( function(doc) { return doc.id } );// Fetch all the Parts that are linked to this Product
> product_parts = db.parts.find({_id: { $in : part_ids } } ).toArray() ;
**非规范化可以为您节省非规范化数据的查找,但代价是更新成本更高,**因为您向数据库添加了一些数据冗余:如果您已将部件名称非规范化到产品文档中,那么当您更新部件名称时您还必须更新“产品”集合中出现的每个位置。
**仅当读取与更新比率较高时,非规范化才有意义。**如果您经常读取非规范化数据,但很少更新它,那么为了获得更高效的查询性能,付出较慢的写入性能和更复杂的冗余数据更新的代价通常是有意义的。随着更新相对于查询变得更加频繁,非规范化带来的节省会减少。
例如,假设零件名称很少变化,但现有数量经常变化。这意味着,虽然出于数据完整性的目的,将部件名称非规范化到产品文档中是有意义的,但对现有数量进行非规范化是没有意义的。
**另请注意,如果对字段进行非规范化,您将失去对该字段执行原子和独立更新的能力。**就像双向引用一样,如果您先更新零件文档中的零件名称,然后再更新产品文档中的零件名称,则可能会出现数据异常,因为将存在一个亚秒间隔,其中产品文档中的非规范化名称不会反映零件文档中新的、更新的值。
数据库从一到多的非规范化
您还可以将字段从“一”侧非规范化为“多”侧:
> db.parts.findOne()
{_id : ObjectID('AAAA'),partno : '123-aff-456',name : '#4 grommet',product_name : 'left-handed smoke shifter', // Denormalized from the ‘Product’ documentproduct_catalog_number: 1234, // Dittoqty: 94,cost: 0.94,price: 3.99
}
但是,如果您已将产品名称非规范化到零件文档中,那么当您更新产品名称时,您还必须更新它在“零件”集合中出现的每个位置,以避免数据异常。这可能是一个更昂贵的更新,因为您要更新多个部件而不是单个产品。因此,以这种方式进行非规范化时,考虑读写比率就显得尤为重要。
中级:具有一对一关系的数据库反规范化
您还可以将一对一的关系非规范化。这可以通过以下两种方式之一进行:您可以将有关“一”侧的信息(来自“hosts”文档)放入“squillions”侧(日志条目),或者可以将“squillions”中的摘要信息放入“一”侧。
下面是“squillions”方面的非规范化示例。我将把主机的 IP 地址(从“一侧”)添加到单独的日志消息中:
> db.logmsg.findOne()
{time : ISODate("2014-03-28T09:42:41.382Z"),message : 'cpu is on fire!',ipaddr : '127.66.66.66',host: ObjectID('AAAB')
}
您对来自特定 IP 地址的最新消息的查询变得更加容易:现在只需一个查询,而不是两个。
> last_5k_msg = db.logmsg.find({ipaddr : '127.66.66.66'}).sort({time :
-1}).limit(5000).toArray()事实上,如果您只想在“one”一侧存储有限数量的信息,则可以将其全部非规范化到“squillions”一侧,并完全摆脱“一”侧集合:
> db.logmsg.findOne()
{time : ISODate("2014-03-28T09:42:41.382Z"),message : 'cpu is on fire!',ipaddr : '127.66.66.66',hostname : 'goofy.example.com',
}
另一方面,您也可以非规范化为“一”侧。假设您希望在“主机”文档中保留来自某个主机的最后 1,000 条消息。您可以使用 MongoDB 2.4 中引入的 $each / $slice 功能来保持该列表排序,并且仅保留最后 1,000 条消息:
日志消息保存在“logmsg”集合以及“hosts”文档中的非规范化列表中。这样,当消息超出“hosts.logmsgs”数组时,该消息就不会丢失。
// Get log message from monitoring system
logmsg = get_log_msg();
log_message_here = logmsg.msg;
log_ip = logmsg.ipaddr;// Get current timestamp
now = new Date()// Find the _id for the host I’m updating
host_doc = db.hosts.findOne({ipaddr : log_ip },{_id:1}); // Don’t return the whole document
host_id = host_doc._id;// Insert the log message, the parent reference, and the denormalized data into the ‘many’ side
db.logmsg.save({time : now, message : log_message_here, ipaddr : log_ip, host : host_id ) });// Push the denormalized log message onto the ‘one’ side
db.hosts.update( {_id: host_id }, {$push : {logmsgs : { $each: [ { time : now, message : log_message_here } ],$sort: { time : 1 }, // Only keep the latest ones $slice: -1000 } // Only keep the latest 1000}} );
请注意,使用投影规范 ( {_id:1} ) 可以防止 MongoDB 通过网络传输整个“hosts”文档。通过告诉 MongoDB 仅返回 _id 字段,您可以将网络开销减少到存储该字段所需的几个字节(加上有线协议开销)。
正如“一对多”情况下的非规范化一样,您需要考虑读取与更新的比率。仅当日志消息相对于应用程序需要查看单个主机的所有消息的次数来说并不频繁时,将日志消息非规范化到“主机”文档中才有意义。如果您希望查看数据的频率低于更新数据的频率,那么这种特殊的非规范化是一个坏主意。
回顾
在本节中,我介绍了您在嵌入、子引用或父引用基础知识之后所拥有的其他选择。
● 如果双向引用可以优化您的架构,并且您愿意付出没有原子更新的代价,那么您可以使用双向引用。
● 如果您正在引用,则可以将数据从“一”侧反规范化 到“N”侧,或者从“N”侧反规范化到“一”侧。
在决定数据库非规范化时,请考虑以下因素:
● 您无法对非规范化数据执行原子更新。
● 仅当读写比率较高时,非规范化才有意义。
看看所有这些数据库非规范化选择!
特别是数据库反规范化,为您提供了很多选择:如果关系中有 8 个反规范化候选者,则有 2 8 (1,024) 种不同的反规范化方式(包括根本不进行反规范化)。将其乘以三种不同的引用方式,您就有超过 3,000 种不同的方式来建模关系。
你猜怎么了?你现在陷入了“选择悖论”。因为你有很多潜在的方法来建模“一对N”关系,所以你选择如何建模它变得更加困难。
数据库非规范化经验法则:您的彩虹指南
以下是一些“经验法则”,可以指导您完成这些无数(但不是无限)的选择:
1、赞成嵌入,除非有令人信服的理由不这样做。
2、需要单独访问一个对象是不嵌入它的一个令人信服的理由。
3、数组不应该无限增长。如果“多”端有超过几百个文档,则不要嵌入它们;如果“多”端有超过几千个文档,请不要使用 ObjectID 引用数组。高基数数组是不嵌入的一个令人信服的理由。
4、不要害怕应用程序级联接:如果正确索引并使用投影说明符,那么应用程序级联接几乎不会比关系数据库中的服务器端联接贵。
5、考虑非规范化的读写比。大部分被读取且很少更新的字段是非规范化的良好候选者。如果您对经常更新的字段进行非规范化,那么查找和更新所有冗余数据实例的额外工作可能会淹没您从非规范化中获得的节省。
6、与 MongoDB 一样,如何建模数据完全取决于特定应用程序的数据访问模式。您希望构建数据以匹配应用程序查询和更新数据的方式。
你的彩虹指南
在 MongoDB 中建模“一对多”关系时,您有多种选择,因此您必须仔细考虑数据的结构。您需要考虑的主要标准是:
● 关系的基数是什么?是“一对多”、“一对多”还是“一对几”?
● 您需要单独访问“N”侧的对象,还是仅在父对象的上下文中访问?
● 特定字段的更新与读取之比是多少?
您构建数据的主要选择是:
● 对于“一对多”,您可以使用一系列嵌入文档。
● 对于“一对多”,或者“N”侧必须独立的情况,您应该使用引用数组。如果可以优化您的数据访问模式,您还可以在“N”侧使用“父引用”。
● 对于“one-to-squillions”,您应该在存储“N”侧的文档中使用“parent-reference”。
一旦您决定了数据库设计中数据的总体结构,您就可以(如果您选择)跨多个文档对数据进行非规范化,方法是将数据从“One”侧非规范化到“N”侧,或者从“N”侧非规范化数据。将“N”侧插入“One”侧。您只需对经常读取、读取次数远多于更新次数以及不需要强一致性的字段执行此操作,因为更新非规范化值更慢、更昂贵,并且不是原子的。
生产力和灵活性
所有这一切的结果是 MongoDB 使您能够设计数据库模式以满足应用程序的需求。您可以在 MongoDB 中构建数据,使其轻松适应变化,并支持充分利用应用程序所需的查询和更新。
附录一:什么是数据库非规范化?
数据库非规范化技术背后有一个非常简单的原则:一起访问的数据应该存储在一起。非规范化是复制字段或从现有字段派生新字段的过程。非规范化数据库可以在多种情况下提高读取性能和查询性能,例如:
● 重复查询需要另一个集合中的大型文档中的一些字段。您可以选择在重复查询目标集合的嵌入文档中维护这些字段的副本,以避免合并两个不同的集合或执行频繁的 $lookup 操作。
● 经常需要集合中某些字段的平均值。您可以选择在单独的集合中创建派生字段,该集合作为写入的一部分进行更新,并维护该字段的运行平均值。
虽然嵌入没有重复数据的文档或数组是对相关数据进行分组的首选,但当必须维护单独的集合时,非规范化可以提高读取性能。
单个文档可以代表整个客户订单或特定太阳能电池板一天的能源产量。一些来自关系数据库、更熟悉规范化数据库模型世界的用户将文档视为表中的一行或分布在多个表中。虽然没有什么可以阻止您以这种方式构建架构,但这并不是存储数据或查询大量数据(尤其是 IoT 数据)的更有效方法。
与关系数据库的规范化数据库模型相比,非规范化使您能够提高数据库性能,同时减少连接。
尽管 MongoDB 支持副本集(从版本 4.0 开始)和分片集群(从版本 4.2 开始)的多文档事务,但对于许多场景,非规范化数据库模型将继续最适合您的数据和用例。
请注意,对于非规范化数据库**,保持一致的重复数据非常重要。**然而,在大多数情况下,数据检索性能和查询执行的提高将超过数据冗余副本的存在以及避免数据不一致的需要。
附录二:数据库非规范化与数据库规范化相比何时有意义?
**当读写比率较高时,非规范化就有意义。**通过非规范化,您可以避免昂贵的连接,但代价是进行更复杂和更昂贵的更新。因此,您应该仅对那些最常读取且很少更新的字段进行非规范化,因为数据冗余不是什么问题。
lookup 操作根据指定字段连接同一数据库中两个集合的数据。当您的数据结构类似于关系数据库并且您需要对通常分布在多个表中的大型分层数据集进行建模时,$lookup 操作可能会很有用。但是,这些操作可能很慢并且占用大量资源,因为它们需要在两个集合而不是单个集合上读取和执行逻辑。
如果您经常运行 $lookup 操作,请考虑通过非规范化重组您的架构,以便您的应用程序可以查询单个集合来获取它需要的所有信息。使用嵌入文档和数组来捕获单个文档结构中数据之间的关系。使用数据库非规范化来利用 MongoDB 的丰富文档模型,这允许您的应用程序在单个查询执行中检索和操作相关数据。
通常,对于操作数据库来说,采用数据库非规范化是最有利的——在单个操作中读取或写入整个记录的效率超过了存储需求的任何适度增加。
标准化数据模型使用文档之间的引用来描述关系。一般来说,在以下场景中使用标准化数据模型:
● 当嵌入会导致数据重复但无法提供足够的读取性能优势来抵消数据重复的影响时。
● 表示更复杂的多对多关系。
● 对大型分层数据集进行建模。
如今,市场上有各种各样的数据库设计选项。关系数据库模型和数据库规范化的实践有其优点和局限性。跨表执行联接操作的需要会影响性能、抑制扩展并带来技术和认知开销。开发人员经常在数据库中创建变通方法以实现效率优势。那些基于高性能关系数据库的应用程序通常会结合临时非规范化、物化视图和外部缓存层,以克服规范化关系数据库的限制。

相关文章:
在MongoDB建模1对N关系的基本方法
“我在 SQL 和规范化数据库方面拥有丰富的经验,但我只是 MongoDB 的初学者。如何建立一对 N 关系模型?” 这是我从参加 MongoDB 分享日活动的用户那里得到的最常见问题之一。 我对这个问题没有简短的答案,因为方法不只有一种,还有…...

C++基础之运算符重载(十一)
首先为什么要对运算符进行重载?因为C内置的运算符只能作用于一些基本数据类型,而对类和结构体这种自定义数据类型是不管用的。所以这时我们需要对运算符进行重新定义满足一定的运算规则。 运算符重载的三种形式 1.以普通的函数进行重载 #include <…...
初始Java篇(JavaSE基础语法)(2)(逻辑控制)
个人主页(找往期文章包括但不限于本期文章中不懂的知识点):我要学编程(ಥ_ಥ)-CSDN博客 目录 逻辑控制 顺序结构 分支结构 if语句 switch 语句 循环结构 while 循环 for 循环 do while 循环 输入输出 输出到控制台 从键盘输入 …...
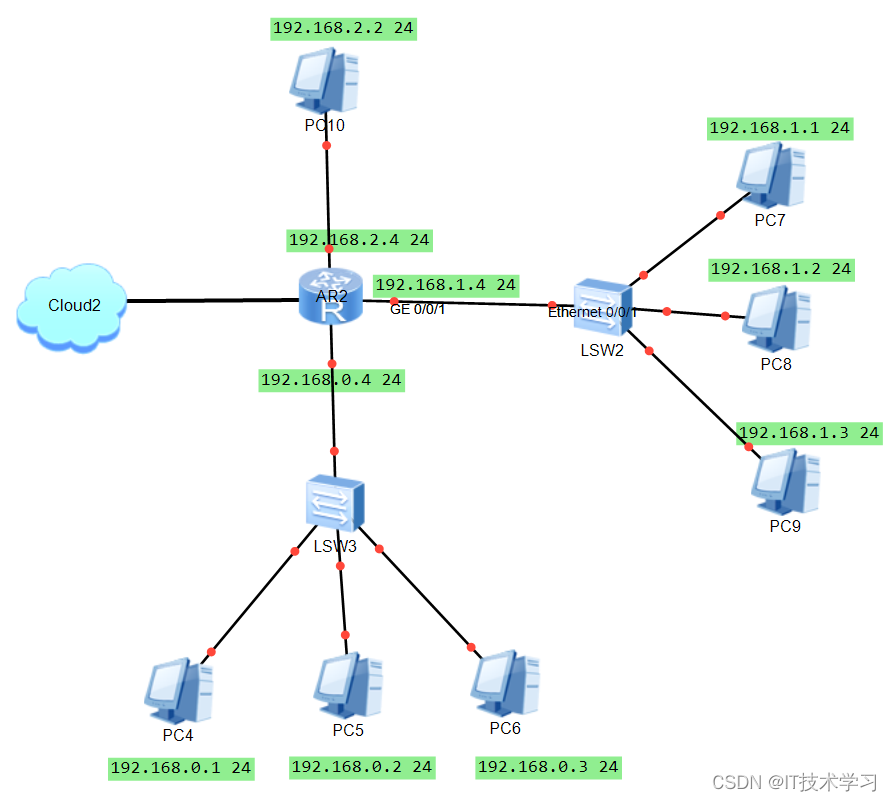
家用路由器和企业路由器的区别?
一、家用路由器 家用路由器路由器交换机 它只有一个WAN口和一个LAN口,WAN口接公网一个地址,LAN口接你电脑一个IP地址,完全符合路由器的设计,而因为家里如果用了,说明要接多个电脑,那么如果还需要对每个接口…...
)
Gin简介(Go web基础知识)
Gin简介 https://geektutu.com/post/quick-go-gin.html我是从这个网站上面摘录的,就是做个笔记,仅分享。膜拜极客兔兔大佬 Go特性: 快速:路由不使用反射,基于Radix树,内存占用少。 中间件:HT…...

HBase的Bulk Load流程
目录 1. 数据准备 2. 文件移动 3. 加载数据 4. Region处理 5. 元数据更新 6. 完成加载 7. 清理 8. 异常处理 LoadIncrementalHFiles(也称为Bulk Load)是HBase中一种将大量数据高效导入到HBase表的机制。以下是LoadIncrementalHFiles的主要流程步…...

vue中图片替换 遇到问题
问题: 在img标签里动态绑定路径:<img v-bind:src"imgSrc" /> data里这样写是错误的:imgSrc:xx/xx.png 这样渲染的路径会有问题,导致出不来图片 解决了 是这样的 data(){return(){imgSrc:require("../…...

Android 观察者模式
在Android中,观察者模式(Observer Pattern)是一种常用的设计模式,用于在对象之间建立一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知并自动更新。在Android开发中࿰…...

阿里云部署MySQL、Redis、RocketMQ、Nacos集群
文章目录 🔊博主介绍🥤本文内容MySQL集群配置云服务器选购CPU选择内存选择云盘选择ESSD AutoPL云盘块存储性能(ESSD) 镜像选择带宽选择密码配置注意事项 安装docker和docker-compose部署MySQL三主六从半同步集群一主二从同步集群规…...
day05-店铺营业状态设置
1. Redis入门 1.1 Redis简介 Redis 是一个基于内存的 key-value 结构数据库。Redis 是互联网技术领域使用最为广泛的存储中间件。 官网: https://redis.io 中文网: https://www.redis.net.cn/ 主要特点: 基于内存存储,读写性能高…...

哈希表(c++)
1、介绍 哈希表,也称为散列表,是一种非常高效的数据结构。它通过将键(Key)映射到数组的特定位置来快速查找、插入和删除数据。这个映射过程由哈希函数(Hash Function)完成,该函数将键转化为一个…...

C#基础-标识符命名规则
目录 1、标识符定义 2、遵循规则 3、标识符的例子 4、MSDN中英文解释 英文...
Zabbix Web界面中文汉化
要想达到上图的效果,第一步先查看 /usr/share/zabbix/assets/fonts/ [rootservice yum.repos.d]# ll /usr/share/zabbix/assets/fonts/ 总用量 0 lrwxrwxrwx. 1 root root 33 3月 23 16:58 graphfont.ttf -> /etc/alternatives/zabbix-web-font 继续查看graph…...
esp32CAM环境搭建(arduino+MicroPython+thonny+固件)
arduino ide 开发工具 arduino版本:1.8.19 arduino ide 中文设置: file >> preferences >> arduino IDE 获取 ESP32 开发环境:打开 Arduino IDE ,找到 文件>首选项 ,将 ESP32 的配置链接填入附加开发板管理网…...

Spring Boot从入门到实战
课程介绍 本课程从SpringBoot的最基础的安装、配置开始到SpringBoot的日志管理、Web业务开发、数据存储、数据缓存,安全控制及相关企业级应用,全程案例贯穿,案例每一步的都会讲解实现思路,全程手敲代码实现。让你不仅能够掌Sprin…...
:整合RateLimiter实现接口限流)
Spring Boot(七十一):整合RateLimiter实现接口限流
1 简介 RateLimiter 从概念上来讲,速率限制器会在可配置的速率下分配许可证。如果必要的话,每个acquire() 会阻塞当前线程直到许可证可用后获取该许可证。一旦获取到许可证,不需要再释放许可证。 RateLimiter使用的是一种叫令牌桶的流控算法,RateLimiter会按照一定的频率…...

通过jsDelivr实现Github的图床CDN加速
最近小伙伴们是否发现访问我的个人博客http://xiejava.ishareread.com/图片显示特别快了? 我的博客的图片是放在github上的,众所周知的原因,github访问不是很快,尤其是hexo博客用github做图床经常图片刷不出来。一直想换图床&…...

Kafka系列之:Connect 中的错误报告
Kafka系列之:Connect 中的错误报告 Kafka Connect 提供错误报告来处理各个处理阶段遇到的错误。默认情况下,转换期间或转换中遇到的任何错误都会导致连接器失败。每个连接器配置还可以通过跳过此类错误、选择性地将每个错误以及失败操作的详细信息和有问题的记录(具有各种详…...
MySQL面试题--开发(最全,涵盖SQL基础、架构、事务)
MySQL面试题--事务https://mp.csdn.net/mp_blog/creation/editor/136947072 MySQL面试题--MySQL内部技术架构https://blog.csdn.net/Timebro/article/details/136946046?spm1001.2014.3001.5501 MySQL面试题--最全面-索引https://blog.csdn.net/Timebro/article/details/136…...

【移动端】Flutter 获取Android AMap实例
背景 本文的背景,是因为我在开发高德地图时,需要自定义高德比例尺位置和样式;但结果查看了AMap Flutter插件和AMap SDK源码后,发现AMap无法添加自定义MyMethodCallHandler的实现类! why? 源码 在Flutte…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

Win10系统清理避坑指南:你的BAT脚本真的安全吗?盘点那些不能乱删的文件
Win10系统清理避坑指南:BAT脚本安全操作手册每次看到那些号称"一键清理系统垃圾"的BAT脚本在技术论坛被疯狂转发,我的工程师朋友老张就会忍不住摇头。上周他刚帮一位设计师修复了崩溃的Photoshop——原因正是某个清理脚本删除了Adobe的临时工作…...

AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了
AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了2026年真正值得重视的AI底层能力,是让模型知道该信谁 你有没有发现一个很扎心的变化。 以前我们用AI,最怕它不会。 现在我们用AI,最怕它太会了。 它能写…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案
WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3》在现代电…...

phpMyAdmin CVE-2018-12613:从文件读取到RCE的伪协议利用链
1. 这个漏洞不是“能读文件”那么简单,而是后台权限的彻底失守phpMyAdmin 4.8.1里那个CVE-2018-12613,很多人扫到就报个“存在文件包含”,顺手贴个?targetphp://filter/convert.base64-encode/resource/etc/passwd截图完事。我去年在给一家教…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

【2026实测】怎么提高论文原创度?盘点8款主流降AI工具,附结构级优化指南
写文章最怕碰到什么,是辛辛苦苦自己码出来的字,却被标了极高的AI值。目前很多文本审核机制对内容的原创度要求极高,纯手写的初稿也可能因为句式太工整被判定为机器生成的。 为了帮几个快被这事折腾疯了的学弟学妹找条出路,我花了…...

中小企无需重型数据中台:轻量化数据体系搭建完整方案
过去几年,“数据中台”一度成为企业数字化的标配热词。大量中小企业盲目跟风搭建重型数据中台,投入高额成本、耗费数月甚至数年周期,最终落地效果极差:功能冗余、运维复杂、使用率低、投入产出比失衡。大量项目最终沦为“摆设式中…...