004——内存映射(基于鸿蒙和I.MAX6ULL)

目录
一、 ARM架构内存映射模型
1.1 页表项
1.2 一级页表映射过程
1.3 二级页表映射过程
1.4 cache 和 buffer
二、 鸿蒙内存映射代码学习
三、 为板子编写内存映射代码
3.1 内存地址范围
3.2 设备地址范围
一、 ARM架构内存映射模型
(以前我以为页表机制是linux这种操作系统规定的,今天看了韦东山老师的视频才知道原来这个机制是由架构来规定的。)

有一个这样的文档来指导开发A架构的程序。
1.1 页表项
ARM架构支持一级页表映射,也就是说MMU根据CPU发来的虚拟地址可以找到第1个页表,从第1个页表里就可以知道这个虚拟地址对应的物理地址。一级页表里地址映射的最小单位是1M。
ARM架构还支持二级页表映射,也就是说MMU根据CPU发来的虚拟地址先找到第1个页表,从第1个页表里就可以知道第2级页表在哪里;再取出第2级页表,从第2个页表里才能确定这个虚拟地址对应的物理地址。二级页表地址映射的最小单位有4K、1K,Linux使用4K。
一级页表项里的内容,决定了它是指向一块物理内存,还是指问二级页表,如下图:
页表项就是一个32位的数据,里面保存有物理地址,还有一些控制信息。
页表项的bit1、bit0表示它是一级页表项,还是二级页表项。
对于一级页表项,里面含有1M空间的物理基地址,这也成为段映射,该物理地址也被称为**段基址**。

上图中的TEX、C、B可以用来控制这块空间的访问方法:是否使用Cache、Buffer等待。
下图过于复杂,我们只需要知道:
* 访问外设时不能使用Cache、Buffer
* 访问内存时使用Cache、Buffer可以提高速度
* 如果内存用作DMA传输,不要使用Cache、Buffer
如下图所示:

1.2 一级页表映射过程
使用一级页表时,先在内存里设置好各个页表项,然后把页表基地址告诉MMU,就可以启动MMU了。
以下图为例介绍地址映射过程:
* ① CPU发出虚拟地址vaddr,假设为0x12345678
* ② MMU根据vaddr[31:20]找到一级页表项
* 虚拟地址0x12345678是虚拟地址空间里第0x123个1M
* 所以找到页表里第0x123项,根据此项内容知道它是一个段页表项
* 段内偏移是0x45678。
* ③ 从这个表项里取出物理基地址:Section Base Address,假设是0x81000000
* ④ 物理基地址加上段内偏移得到:0x81045678
所以CPU要访问虚拟地址0x12345678时,实际上访问的是0x81045678的物理地址。

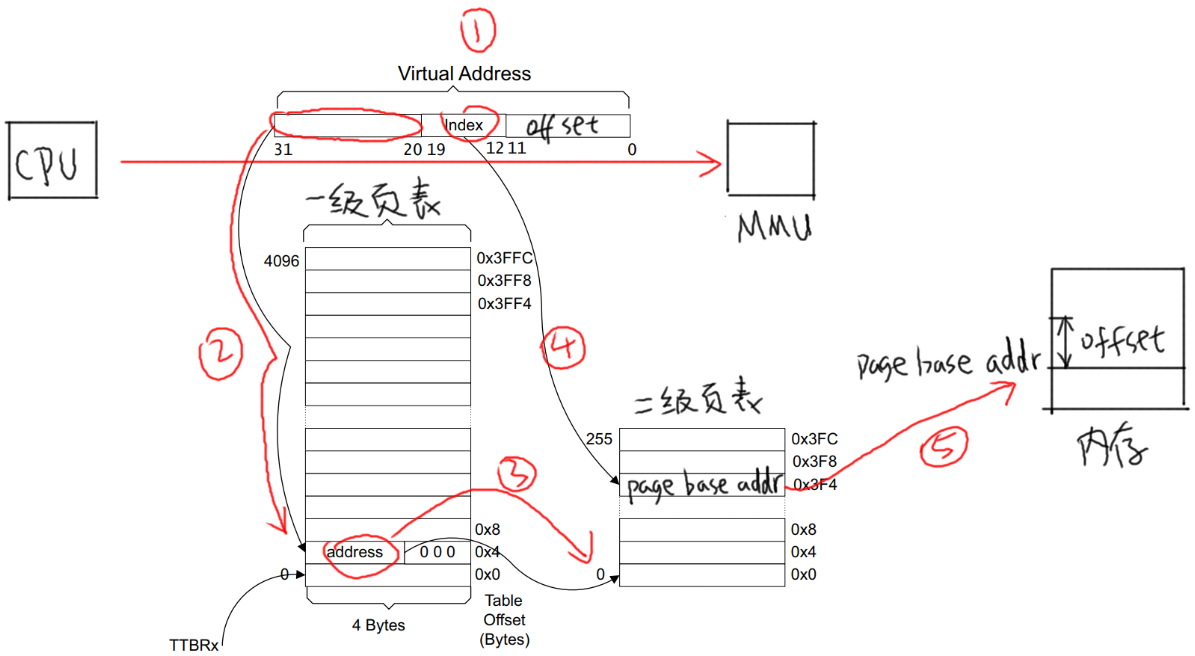
1.3 二级页表映射过程
先设置好一级页表、二级页表,并且把一级页表的首地址告诉MMU。
以下图为例介绍地址映射过程:
-
① CPU发出虚拟地址vaddr,假设为0x12345678
-
② MMU根据vaddr[31:20]找到一级页表项
-
虚拟地址0x12345678是虚拟地址空间里第0x123个1M,所以找到页表里第0x123项。
-
根据此项内容知道它是一个二级页表项。
-
-
③ 从这个表项里取出地址,假设是address,这表示的是二级页表项的物理地址;
-
④ vaddr[19:12]表示的是二级页表项中的索引index即0x45,在二级页表项中找到第0x45项;
-
⑤ 二级页表项格式如下

* 里面含有这4K或1K物理空间的基地址page base addr,假设是0x81889000
* 它跟vaddr[11:0]组合得到物理地址:0x81889000 + 0x678 = 0x81889678
* 所以CPU要访问虚拟地址0x12345678时,实际上访问的是0x81889678的物理地址
(linux二级页表使用的是4K大小)
(其实还有一个机制,就是为什么我们的内存只有16个G时linux能为每个进程分配4个G或者更多的虚拟空间)
- 虚拟内存:Linux使用虚拟内存技术,它为每个进程提供了一个独立的、连续的虚拟地址空间。这个虚拟地址空间与实际的物理内存是分开的。进程在运行时,会在这个虚拟地址空间中请求内存。Linux内核会负责将这些虚拟地址映射到实际的物理内存地址,或者当物理内存不足时,使用交换空间(swap space)来存储部分数据。
- 内存管理单元(MMU):现代计算机硬件中的内存管理单元(MMU)支持虚拟内存技术。当进程访问内存时,MMU负责将虚拟地址转换为物理地址。这意味着,尽管物理内存有限,但每个进程都可以有自己的虚拟地址空间。
- 页表:Linux内核为每个进程维护一个页表,该页表记录了虚拟地址到物理地址的映射关系。当进程访问某个虚拟地址时,内核会查找相应的页表项,将虚拟地址转换为物理地址。如果所请求的数据不在物理内存中(即发生了页面错误),内核会负责从交换空间或其他地方加载数据。
- 进程隔离:虚拟内存还提供了进程隔离的功能。每个进程都有自己的虚拟地址空间,因此一个进程无法直接访问另一个进程的内存。这增强了系统的安全性和稳定性。
这个交换空间其实是我们的外存空间,比如硬盘,将进程一部分不需要立刻执行的资源放到外存里,不断的交换到内存去执行,这样效率会大大降低,但是却可以拥有更多的内存空间。
1.4 cache 和 buffer
ARM的cache和写缓冲器(write buffer)_arm coretex a7 write buffer-CSDN博客
使用MMU时,需要有cache、buffer的知识。
下图是CPU和内存之间的关系,有cache、buffer(写缓冲器)。
Cache是一块高速内存;写缓冲器相当于一个FIFO,可以把多个写操作集合起来一次写入内存。

程序运行时有“局部性原理”,这又分为时间局部性、空间局部性。
* 时间局部性:
在某个时间点访问了存储器的特定位置,很可能在一小段时间里,会反复地访问这个位置。
* 空间局部性
访问了存储器的特定位置,很可能在不久的将来访问它附近的位置。
而CPU的速度非常快,内存的速度相对来说很慢。
CPU要读写比较慢的内存时,怎样可以加快速度?
根据“局部性原理”,可以引入cache:
* 读取内存addr处的数据时
* 先看看cache中有没有addr的数据,如果有就直接从cache里返回数据:这被称为cache命中。
* 如果cache中没有addr的数据,则从内存里把数据读入
注意:它不是仅仅读入一个数据,而是读入一行数据(cache line)。
* 而CPU很可能会再次用到这个addr的数据,或是会用到它附近的数据,这时就可以快速地从cache中获得数据。
* 写数据
* CPU要写数据时,可以直接写内存,这很慢;也可以先把数据写入cache,这很快。
* 但是cache中的数据终究是要写入内存的啊,这有2种写策略:
* a. 写通(write through):
数据要同时写入cache和内存,所以cache和内存中的数据保持一致,但是它的效率很低。
能改进吗?可以!
使用“写缓冲器”:cache大哥,你把数据给我就可以了,我来慢慢写,保证帮你写完。
有些写缓冲器有“写合并”的功能,比如CPU执行了4条写指令:写第0、1、2、3个字节,每次写1字节;写缓冲器会把这4个写操作合并成一个写操作:写word。
对于内存来说,这没什么差别,但是对于硬件寄存器,这就有可能导致问题。
所以对于寄存器操作,不会启动buffer功能;对于内存操作,比如LCD的显存,可以启用buffer功能。
* b. 写回(write back):
新数据只是写入cache,不会立刻写入内存,cache和内存中的数据并不一致。
新数据写入cache时,这一行cache被标为“脏”(dirty);当cache不够用时,才需要把脏的数据写入内存。
使用写回功能,可以大幅提高效率。但是要注意cache和内存中的数据很可能不一致。这在很多时间要小心处理:比如CPU产生了新数据,DMA把数据从内存搬到网卡,这时候就要CPU执行命令先把新数据从cache刷到内存。反过来也是一样的,DMA从网卡得过了新数据存在内存里,CPU读数据之前先把cache中的数据丢弃。
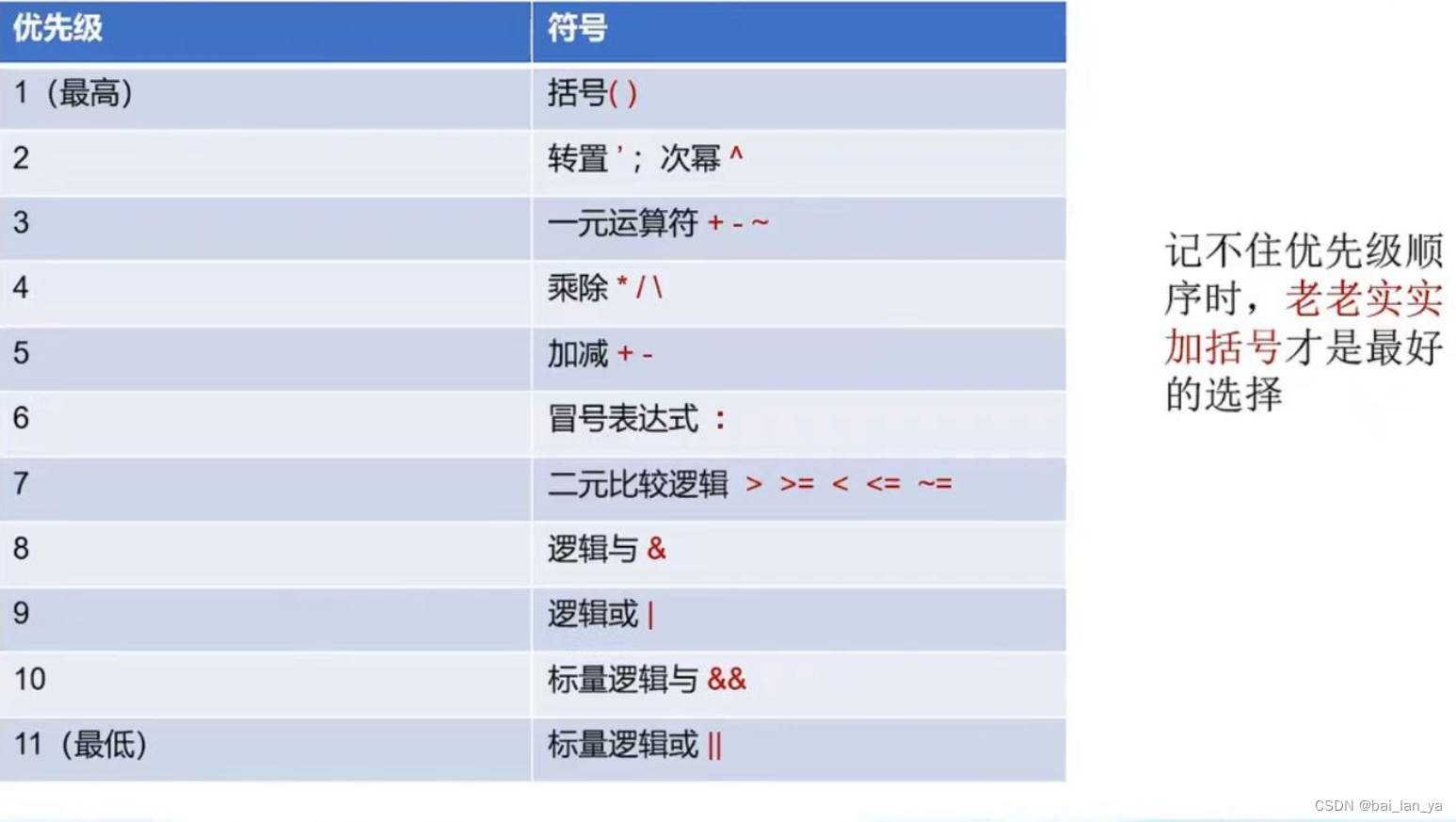
是否使用cache、是否使用buffer,就有4种组合(Linux内核文件arch\arm\include\asm\pgtable-2level.h):
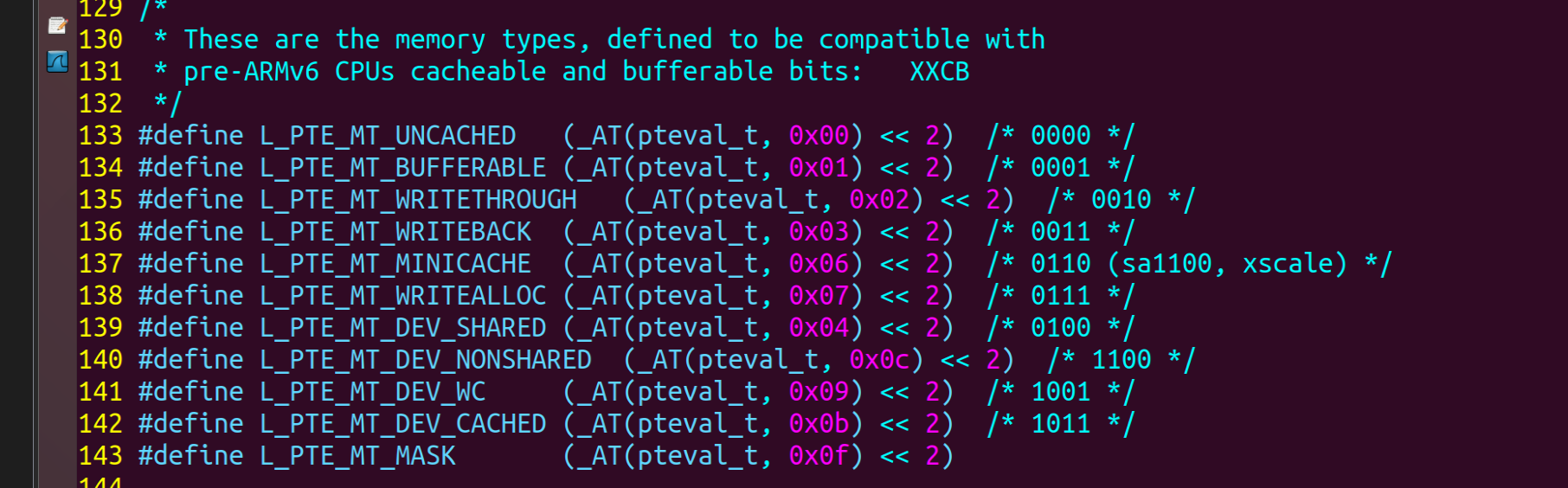
(已经不止4种了哦,这是3.14版本的)

韦东山老师这个是哪个版本不太清楚,这四种对应下面的表。

第1种是不使用cache也不使用buffer,读写时都直达硬件,这适合寄存器的读写。
第2种是不使用cache但是使用buffer,写数据时会用buffer进行优化,可能会有“写合并”,这适合显存的操作。因为对显存很少有读操作,基本都是写操作,而写操作即使被“合并”也没有关系。
第3种是使用cache不使用buffer,就是“write through”,适用于只读设备:在读数据时用cache加速,基本不需要写。
第4种是既使用cache又使用buffer,适合一般的内存读写。
二、 鸿蒙内存映射代码学习
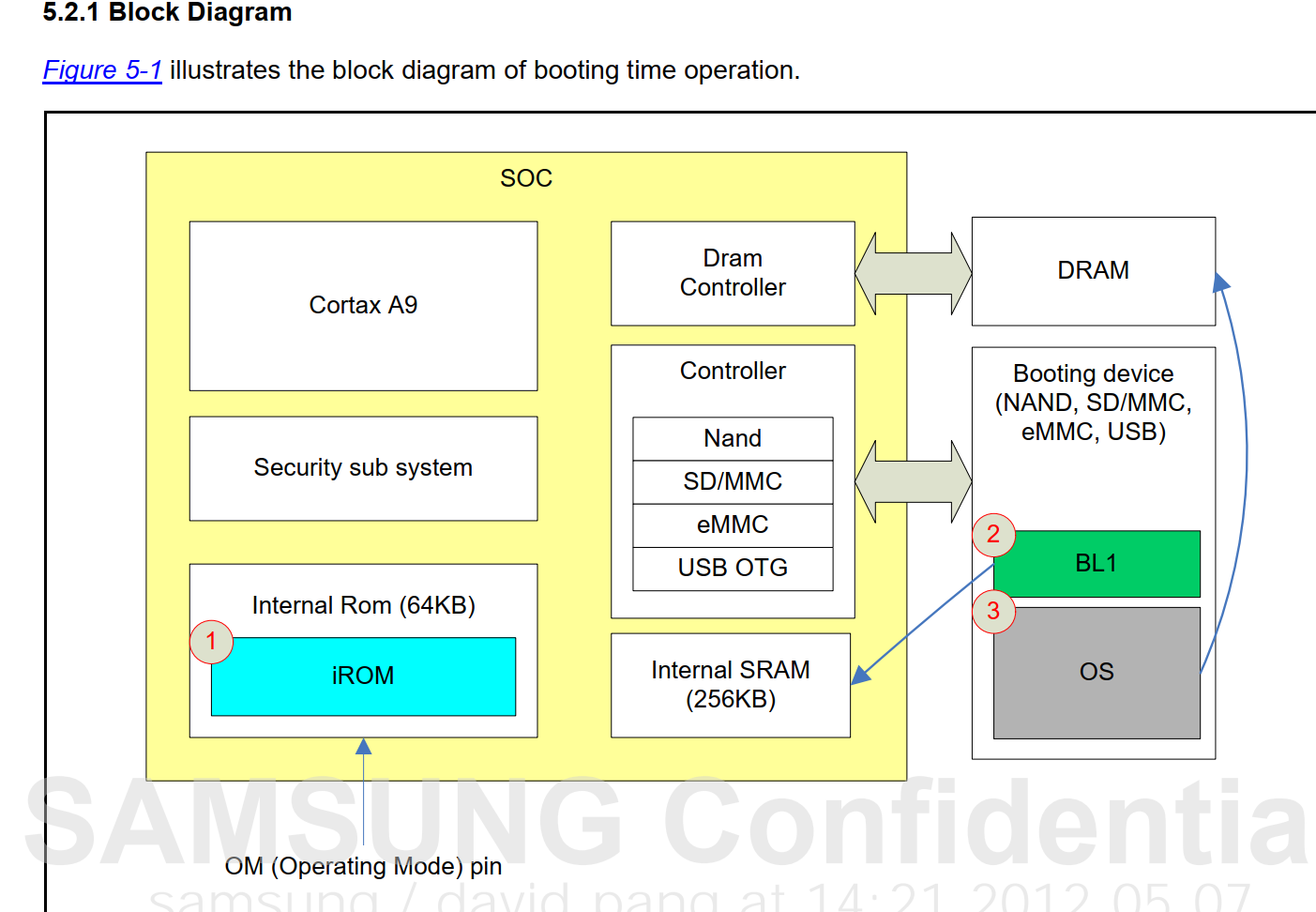
分析启动文件`kernel\liteos_a\arch\arm\arm\src\startup\reset_vector_up.S`,(up和mp的区别和我昨天猜测的一样,up是单核mp是多核(multi-processor)(uni-processor)环境)
可以得到下图所示的地址映射关系:
* 内存地址
* KERNEL_VMM_BASE开始的这块虚拟地址,使用Cache,速度快
* UNCACHED_VMM_BASE开始的这块虚拟地址,不使用Cache,适合DAM传输、LCD Framebuffer等
* 设备空间:就是各种外设,比如UART、LCD控制器、I2C控制器、中断控制器
* PERIPH_DEVICE_BASE开始的这块虚拟地址,不使用Cache不使用Buffer
* PERIPH_CACHED_BASE开始的这块虚拟地址,使用Cache使用Buffer
* PERIPH_UNCACHE_BASE开始的这块虚拟地址,不使用Cache但是使用Buffer
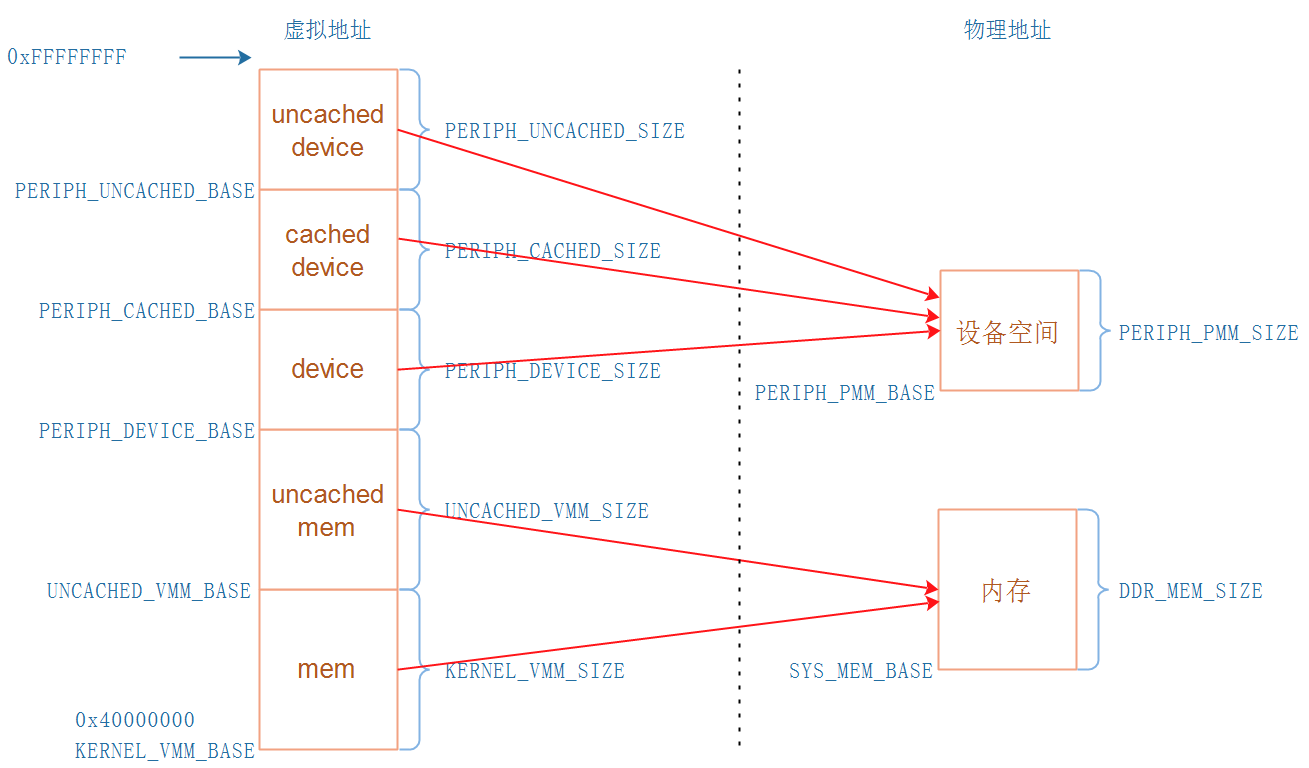
Liteos-a的地址空间是怎么分配的?
`KERNEL_VMM_BASE`等于0x40000000,并且在`kernel\liteos_a\kernel\base\include\los_vm_zone.h`看到如下语句:
#if (PERIPH_UNCACHED_BASE >= (0xFFFFFFFFU - PERIPH_UNCACHED_SIZE))
#error "Kernel virtual memory space has overflowed!"
#endif
所以可以粗略地认为:
* 内核空间:0x40000000 ~ 0xFFFFFFFF
* 用户空间:0 ~ 0x3FFFFFFF
三、 为板子编写内存映射代码
3.1 内存地址范围
这里我还是以exynos4412为例
找到了一张这个图,挺有意思的
下面这个是6ull的内存映射图

下面这个是exynos4412的内存映射图


这里我们要按手册修改,这点两个芯片有所不同,6uLL是固定的2个G
但是4412是可选的从0x40000000开始可以安3个G的内存条,这里我们安了一个G所以就是

从0x40000000~0x80000000
3.2 设备地址范围
IMX6ULL芯片上设备地址分部太零散,从0到0x6FFFFFFF都有涉及,中间有很多保留的地址不用,入下图:
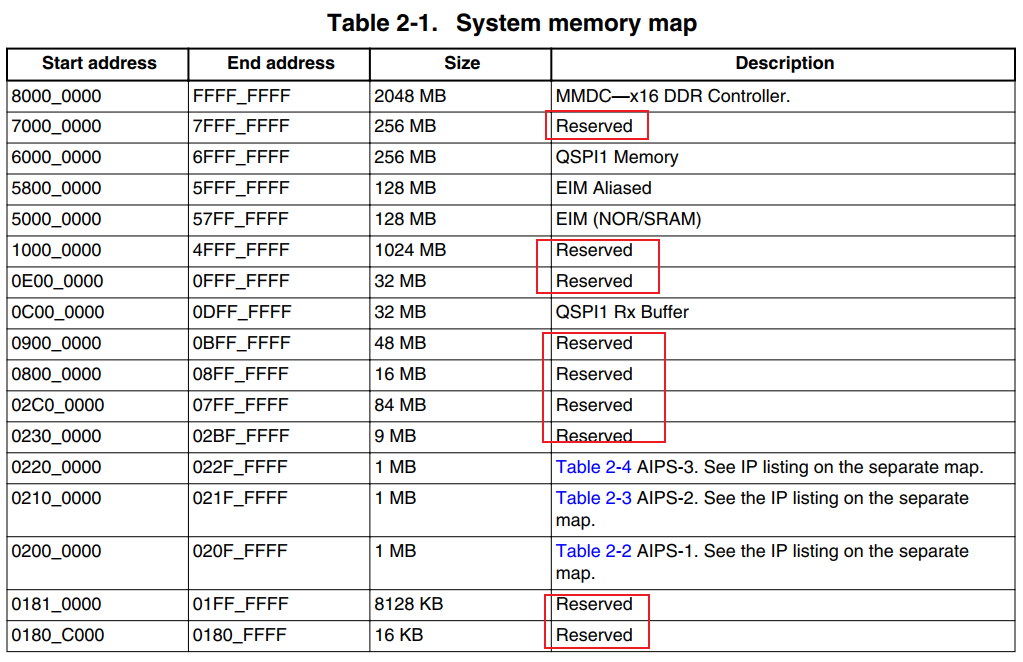
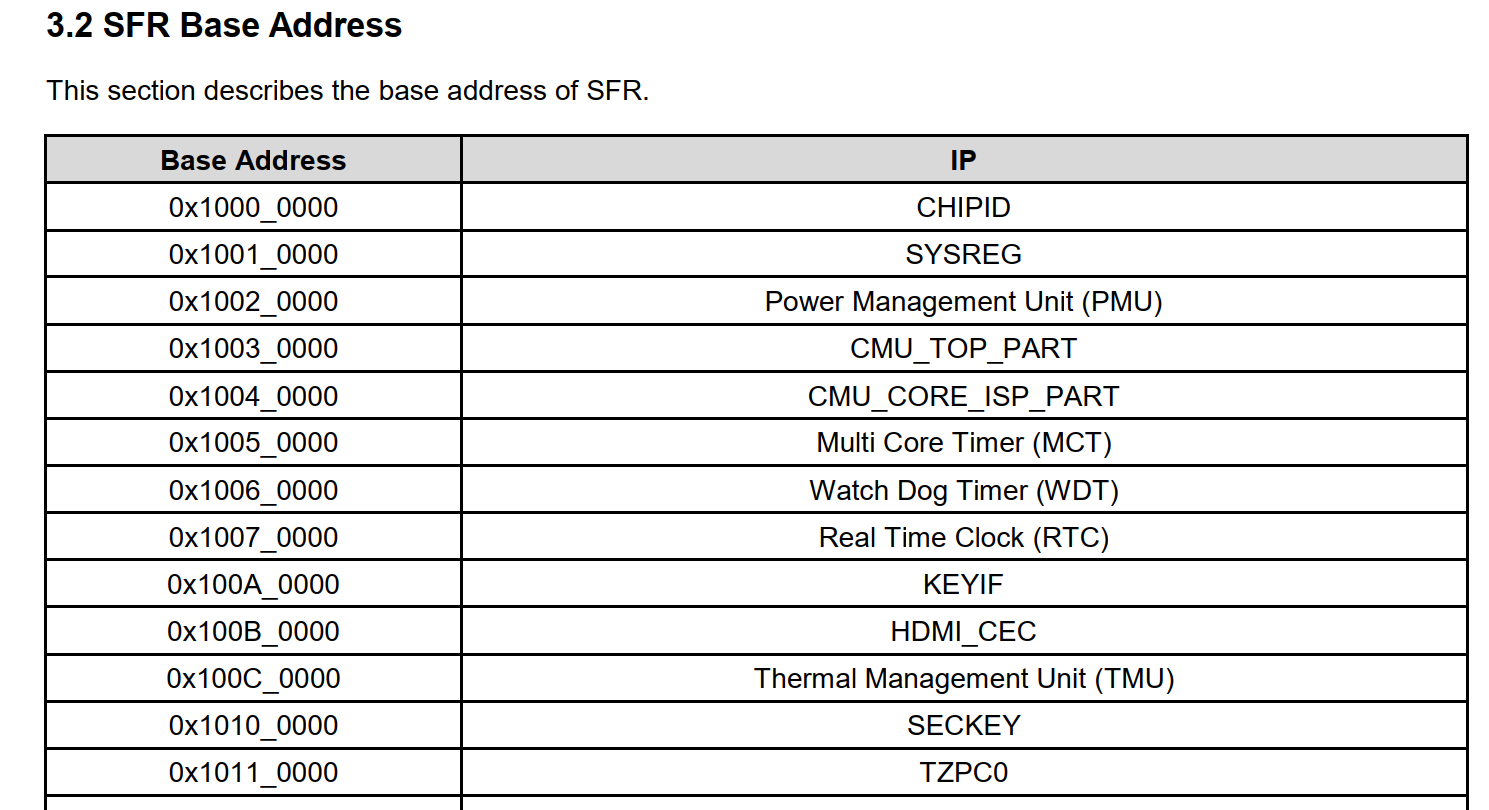
如果把0到0x6FFFFFFF全部映射完,地址空间不够; 正确的做法应该是忽略那些保留的地址空间,为各个模块单独映射地址。 但是Liteos-a尚未实现这样的代码(要自己实现也是可以的,但是我们先把最小系统移植成功)。 我们至少要映射2个设备的地址:UART1(100ASK_IMX6ULL开发板使用UART1)、GIC,如下图:


所以:
// source\vendor\democom\demochip\board\include\board.h
#define PERIPH_PMM_BASE 0x00a00000 // GIC的基地址
#define PERIPH_PMM_SIZE 0x02300000 // 尽可能大一点,以后使用其他外设时就不用映射了PERIPH_PMM_SIZE也不能太大,限制条件是:
#if (PERIPH_UNCACHED_BASE >= (0xFFFFFFFFU - PERIPH_UNCACHED_SIZE))
#error "Kernel virtual memory space has overflowed!"
#endif但是我们不用考虑这个问题我们有一个G的内存可以把整个SFR寄存器都进行映射
...
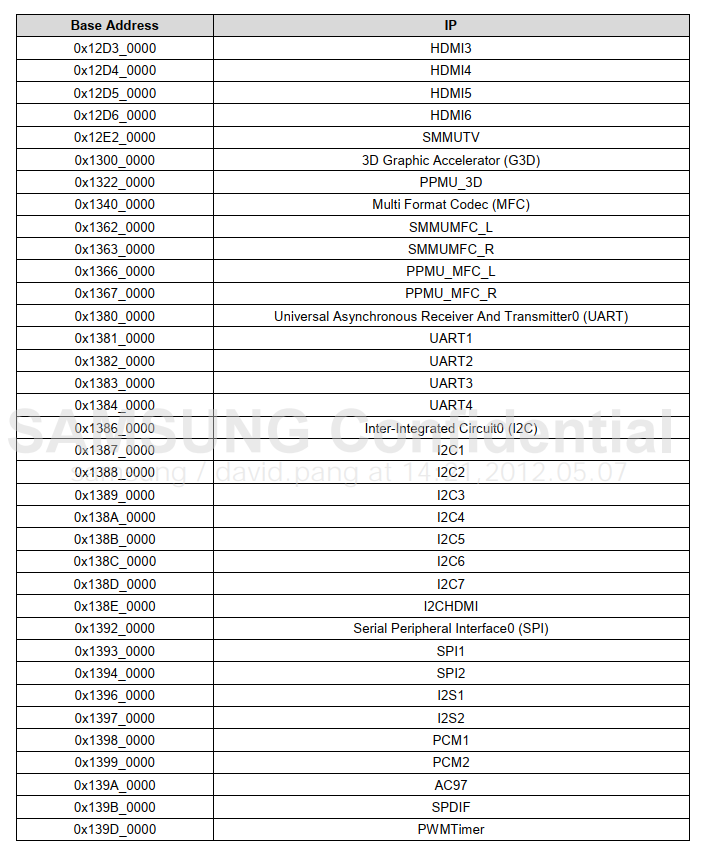
注意:MMU以1MB为单位映射,大小要是1MB的倍数。

相关文章:
004——内存映射(基于鸿蒙和I.MAX6ULL)
目录 一、 ARM架构内存映射模型 1.1 页表项 1.2 一级页表映射过程 1.3 二级页表映射过程 1.4 cache 和 buffer 二、 鸿蒙内存映射代码学习 三、 为板子编写内存映射代码 3.1 内存地址范围 3.2 设备地址范围 一、 ARM架构内存映射模型 (以前我以为页表机制…...
150 Linux C++ 通讯架构实战6 服务器程序目录规划,makefile编写
从无到有产生这套 通讯架构源代码【项目/工程】 一,服务器程序目录规划 一个完整的项目 肯定会有多个源文件,头文件,会分别存放到多个目录; 我们这里要规划项目的目录结构; 注意:不固安是目录还是文件&am…...

OpenCV支持哪些类型的文件格式读写?
OpenCV支持多种类型的文件格式读写,包括但不限于以下格式: Windows位图文件:包括BMP和DIB格式。JPEG文件:支持JPEG、JPG和JPE三种扩展名。便携式网络图片:即PNG格式。便携式图像格式:包括PBM、PGM和PPM三种…...

数据库中使用IN操作效率问题
1. IN操作的基本概念 IN操作符在SQL中用于指定某个字段的值是否匹配列表中的任何值。这是一个条件操作符,用于在WHERE子句中过滤记录。 SQL语法示例: SELECT * FROM table_name WHERE column_name IN (value1, value2, ...); 2. IN操作的效率问题 当…...

unity学习(67)——控制器Joystick Pack方向
1.轮盘直接复制一个拖到右边就ok了,轮盘上是有脚本的。(只复制) 2.上面的显示窗也可以复制,但是要绑定对应的轮盘(unity中修改变量),显示窗上是有脚本的。(复制改变量) 3…...
MATLAB的使用(一)
一,MATLAB的编程特点 a,语法高度简化; b,脚本式解释型语言; c,针对矩阵的高性能运算; d,丰富的函数工具箱支持; e,通过matlab本体构建跨平台; 二,MATLAB的界面 工具栏:提供快捷操作编辑器…...

JMeter并发工具的使用
视频地址:Jmeter安装教程01_Jmeter之安装以及环境变量配置_哔哩哔哩_bilibili 一、JMeter是什么 JMeter是一款免安装包,官网下载好后直接解压缩并配置好环境变量就可以使用。 环境变量配置可参考:https://www.cnblogs.com/liulinghua90/p/…...
基于springboot+vue的毕业就业信息管理系统
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、阿里云专家博主、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战,欢迎高校老师\讲师\同行交流合作 主要内容:毕业设计(Javaweb项目|小程序|Pyt…...

有什么小程序适合个人开发?
在这个信息爆炸的时代,小程序已经成为了我们生活中的一部分。无论是出行、购物还是娱乐,小程序都能为我们提供便捷的服务。对于个人开发者来说,开发一个小程序不仅可以锻炼自己的技术能力,还可以为他人提供便利,甚至有…...
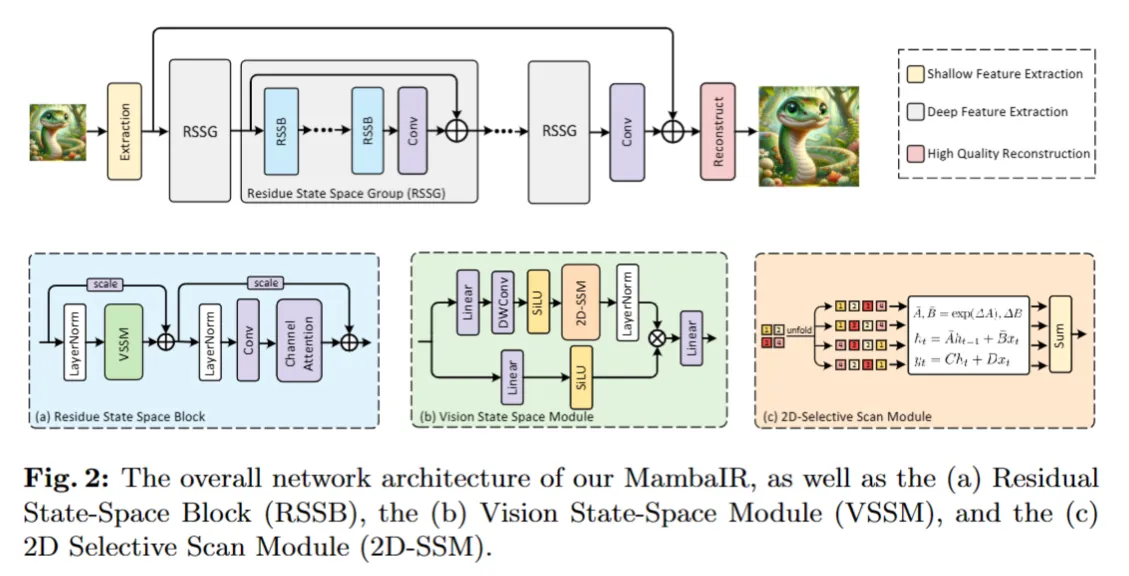
【ARXIV2402】MambaIR
这个工作首次将 Mamba 引入到图像修复任务,关于为什么 Mamba 可以用于图像修复,作者有非常详细的解释:一路向北:性能超越SwinIR!MambaIR: 基于Mamba的图像复原基准模型 作者认为Mamba可以理解为RNN和CNN的结合…...

【计算机网络篇】数据链路层(3)差错检测
文章目录 🥚误码🍔两种常见的检错技术⭐奇偶校验⭐循环冗余校验🎈例子 🥚误码 误码首先介绍误码的相关概念 🍔两种常见的检错技术 ⭐奇偶校验 奇校验是在待发送的数据后面添加1个校验位,使得添加该校验…...

软件配置管理计划
1. 配置管理目标 本软件配置管理计划的目标在于确保软件开发生命周期内的所有配置项(CI)都得到适当的标识、控制、版本管理和追踪。通过实施有效的配置管理,我们的目标是: 保持配置项的一致性和完整性。确保配置项的可追溯性。减…...

嵌入式备考错题汇总
若某条无条件转移汇编指令采用直接寻址,则该指令的功能是将指令中的地址码送入()。 A.PC(程序计数器) B.AR(地址寄存器) C.AC(累加器) D.ALU(算术逻辑运算单元) 解析:选A,直接寻址是指操作数存放在内存单元中,指令中直接给出操作数所在存储单…...

38 mars3d 对接地图图层 绘制点线面员
前言 这里主要是展示一下 mars3d 的一个基础的使用 主要是设计 接入地图服务器的 卫星地图, 普通的二维地图, 增加地区标记 基础绘制 点线面园 等等 测试用例 <template><div style"width: 1920px; height:1080px;"><div class"mars3dClas…...

什么是Webhook 和 HTTP Endpoint?
Webhook 和 HTTP Endpoint 都是基于HTTP协议的网络通信概念,但它们在使用场景和目的上有所不同。 Webhook Webhook 是一种允许一个应用程序提供实时信息给其他应用程序的方法,这种通信是基于HTTP的“回调”或“钩子”。Webhook 通常被用来在一种服务上…...

小程序跨端组件库 Mpx-cube-ui 开源:助力高效业务开发与主题定制
Mpx-cube-ui 是一款基于 Mpx 小程序框架的移动端基础组件库,一份源码可以跨端输出所有小程序平台及 Web,同时具备良好的拓展能力和可定制化的能力来帮助你快速构建 Mpx 应用项目。 Mpx-cube-ui 提供了灵活配置的主题定制能力,在组件设计开发阶…...

GDC期间LayaAir启动全球化战略
3 月 18 日至 3 月 22 日,一年一度的游戏开发者大会(GDC)在美国旧金山举行。在此期间,Layabox宣布LayaAir引擎启动全球扩张战略,这标志着引擎将步入快速发展的新阶段。此举旨在利用公司先进的3D引擎技术,将…...
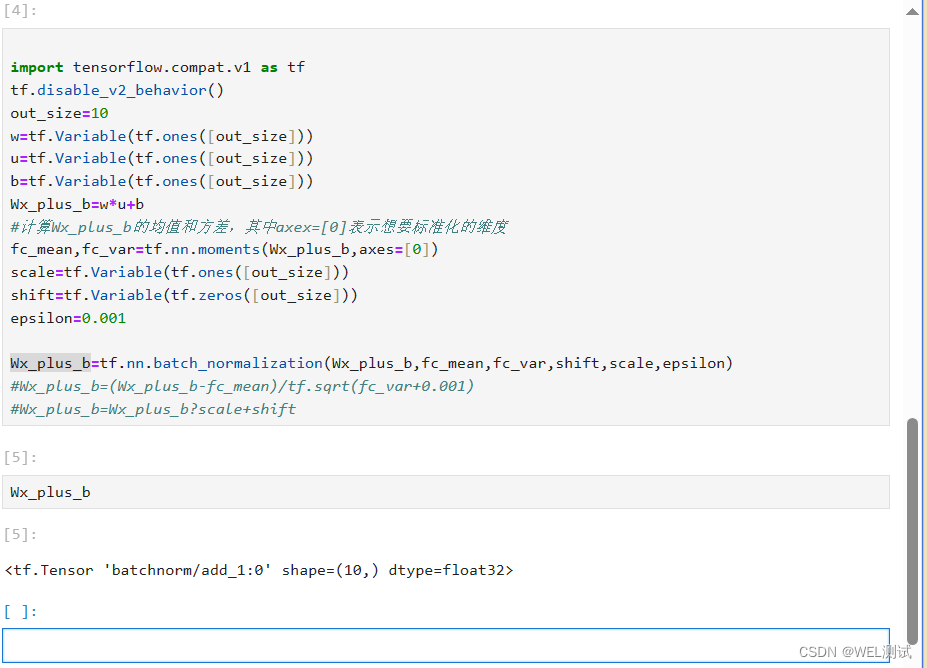
人工智能之Tensorflow批标准化
批标准化(Batch Normalization,BN)是为了克服神经网络层数加深导致难以训练而诞生的。 随着神经网络的深度加深,训练会越来越困难,收敛速度会很慢,常常会导致梯度消失问题。梯度消失问题是在神经网络中,当前…...
自动化的免下车服务——银行、餐厅、快餐店、杂货店
如果您在20世纪70年代和2020年分别驾车经过免下车服务餐厅(汽车穿梭餐厅),您会发现,唯一的不同是排队的车型。50多年来,免下车技术一直为我们提供着良好的服务,但现在也该对它进行现代化改造了。 乘着AI和自…...

Git常用指令总结
Git常用指令总结 下载git,这个不需要交的!!! 1、初始化自己的git仓库 git config --global user.name “Your name” 配置自己的用户名 git config --global user.email “mailexample.com” 配置邮箱 git config --global c…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...

为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析
更多请点击: https://intelliparadigm.com 第一章:为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析 在对17个采用DeepSeek-R1/VL模型开展定制化开发的工业级项目进行回溯审计后,我…...

告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击
告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软…...

光轮智能 谢晨 访谈总结机器人仿真数据产业
光轮智能 谢晨 访谈总结机器人仿真关于创始人关于数据数据金字塔数据痛点仿真数据的重要性仿真数据的质量b站链接地址公司官网关于创始人 清华物理;哥伦比亚金融;英伟达智驾仿真;小鹏智驾仿真;现为光轮智能CEO 关于数据 数据的…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

2026长沙智能家居品牌实测,这些本地老牌值得选
2026年,长沙的智能家居市场已经从“概念热”转向“落地战”。我走访了长沙多个本地服务商,实测了不同品牌在别墅、酒店、大平层等场景的真实表现。今天,结合数据与案例,分享几个值得关注的本地品牌,尤其是深耕8年以上的…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...