深度学习 线性神经网络(线性回归 从零开始实现)
介绍:
在线性神经网络中,线性回归是一种常见的任务,用于预测一个连续的数值输出。其目标是根据输入特征来拟合一个线性函数,使得预测值与真实值之间的误差最小化。
线性回归的数学表达式为:
y = w1x1 + w2x2 + ... + wnxn + b其中,y表示预测的输出值,x1, x2, ..., xn表示输入特征,w1, w2, ..., wn表示特征的权重,b表示偏置项。
训练线性回归模型的目标是找到最优的权重和偏置项,使得模型预测的输出与真实值之间的平方差(即损失函数)最小化。这一最优化问题可以通过梯度下降等优化算法来解决。
线性回归在深度学习中也被广泛应用,特别是在浅层神经网络中。在深度学习中,通过将多个线性回归模型组合在一起,可以构建更复杂的神经网络结构,以解决更复杂的问题。
手动生成数据集:
%matplotlib inline
import torch
from d2l import torch as d2l
import random#"""生成y=Xw+b+噪声"""
def synthetic_data(w, b, num_examples): #生成num_examples个样本X = d2l.normal(0, 1, (num_examples, len(w)))#随机x,长度为特征个数,权重个数y = d2l.matmul(X, w) + b#y的函数y += d2l.normal(0, 0.01, y.shape)#加上0~0.001的随机噪音return X, d2l.reshape(y, (-1, 1))#返回true_w = d2l.tensor([2, -3.4])#初始化真实w
true_b = 4.2#初始化真实bfeatures, labels = synthetic_data(true_w, true_b, 1000)#随机一些数据
print(features)
print(labels)显示数据集:
print('features:', features[0],'\nlabel:', labels[0])'''
features: tensor([ 2.1714, -0.6891])
label: tensor([10.8673])
'''d2l.set_figsize()
d2l.plt.scatter(d2l.numpy(features[:, 1]), d2l.numpy(labels), 1);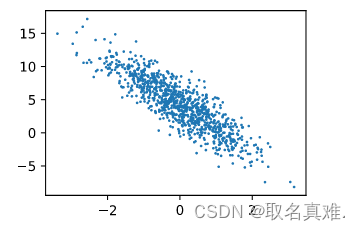
读取小批量数据集:
#每次抽取一批量样本
def data_iter(batch_size, features, labels):#步长、特征、标签num_examples = len(features)#特征个数indices = list(range(num_examples))random.shuffle(indices)# 这些样本是随机读取的,没有特定的顺序,打乱顺序for i in range(0, num_examples, batch_size):#随机访问,步长为batch_sizebatch_indices = d2l.tensor(indices[i: min(i + batch_size, num_examples)])yield features[batch_indices], labels[batch_indices]定义模型:
#定义模型
def linreg(X, w, b): """线性回归模型"""return d2l.matmul(X, w) + b定义损失函数:
#定义损失和函数
def squared_loss(y_hat, y): #@save"""均方损失"""return (y_hat - d2l.reshape(y, y_hat.shape)) ** 2 / 2定义优化算法(小批量随机梯度下降):
#定义优化算法 """小批量随机梯度下降"""
def sgd(params, lr, batch_size): #参数、lr学习率、with torch.no_grad():for param in params:param -= lr * param.grad / batch_sizeparam.grad.zero_()模型训练:
#训练
lr = 0.03#学习率
num_epochs = 3#数据扫三遍
net = linreg#模型
loss = squared_loss#损失函数
#初始化模型参数
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)#权重
b = torch.zeros(1, requires_grad=True)#b全赋为0for epoch in range(num_epochs):for X, y in data_iter(batch_size, features, labels):#拿出一批量x,yl = loss(net(X, w, b), y) # X和y的小批量损失,实际的和预测的# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,# 并以此计算关于[w,b]的梯度l.sum().backward()sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数with torch.no_grad():train_l = loss(net(features, w, b), labels)print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
'''
epoch 1, loss 0.037302
epoch 2, loss 0.000140
epoch 3, loss 0.000048
'''print(f'w的估计误差: {true_w - d2l.reshape(w, true_w.shape)}')
print(f'b的估计误差: {true_b - b}')
'''
w的估计误差: tensor([0.0006, 0.0001], grad_fn=<SubBackward0>)
b的估计误差: tensor([-0.0003], grad_fn=<RsubBackward1>)
'''print(w)
'''
tensor([[ 1.9994],[-3.4001]], requires_grad=True)
'''print(b)
'''
tensor([4.2003], requires_grad=True)
'''
相关文章:
深度学习 线性神经网络(线性回归 从零开始实现)
介绍: 在线性神经网络中,线性回归是一种常见的任务,用于预测一个连续的数值输出。其目标是根据输入特征来拟合一个线性函数,使得预测值与真实值之间的误差最小化。 线性回归的数学表达式为: y w1x1 w2x2 ... wnxn …...
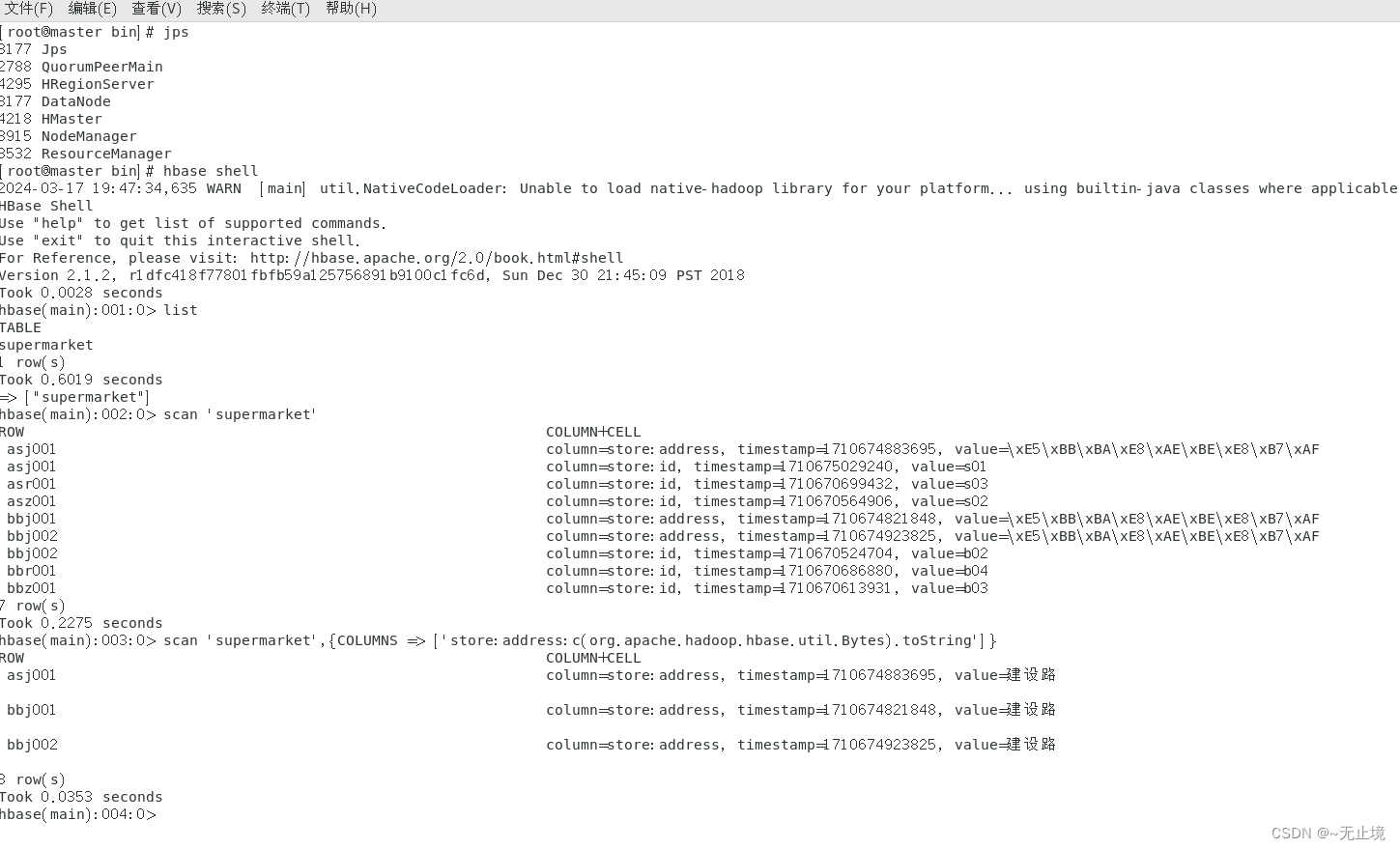
HBase在表操作--显示中文
启动HBase后,Master和RegionServer两个服务器,分别对应进程为HMaster和HRegionServe。(可通过jps查看) 1.进入表操作 hbase shell 2.查看当前库中存在的表 list 3.查看表中数据(注:学习期间可用&#…...
基于BusyBox的imx6ull移植sqlite3到ARM板子上
1.官网下载源码 https://www.sqlite.org/download.html 下载源码解压到本地的linux环境下 2.解压并创建install文件夹 3.使用命令行配置 在解压的文件夹下打开终端,然后输入以下内容,其中arm-linux-gnueabihf是自己的交叉编译器【自己替换】 ./config…...
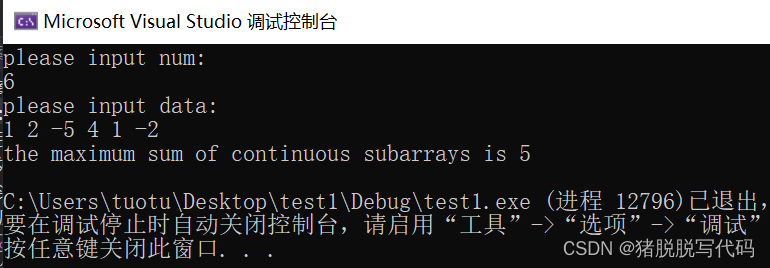
连续子数组的最大和
问题描述: 输入一个整型数组,数组里有正数也有负数。求连续子数组中的最大和为多少。 举例: 数组:arry{1 , 2 ,-5 , 4 , 1 ,-2} 输出:5,数组中连续的位置相加最大值为5, 41 方法…...

Photoshop 工具使用详解(全集 · 2024版)
全面介绍 Photoshop 工具箱里的工具,点击下列表格中工具名称或图示,即可查阅工具的使用详解。 移动工具Move Tool移动选区、图层和参考线。画板工具Artboard Tool创建、移动多个画布或调整其大小。moVe快捷键:V 矩形选框工具 Rectangular Mar…...
C++函数返回机制,返回类型
return语句终止当前正在执行的函数并将控制权返回到调用该函数的地方。 return语句有两种形式 return;return expression; 无返回值函数 没有返回值的return语句只能用在返回类型是void的函数中。 返回void的函数不要求必须有return语句,因为这类函数的最后一句…...

[linux] Key is stored in legacy trusted.gpg keyring
修复 Ubuntu 中的 “Key is stored in legacy trusted.gpg keyring” 问题_key is stored in legacy trusted.gpg keyring (/etc/-CSDN博客 复制到trusted.gpd.d 目录中(快速但不优雅的方法) 如果你觉得手动做上面的事情不舒服,那么,你可以忽略这个警告…...

阿里云部署OneApi
基于 Docker 进行部署 # 使用 SQLite 的部署命令: docker run --name one-api -d --restart always -p 3000:3000 -e TZAsia/Shanghai -v /home/ubuntu/data/one-api:/data justsong/one-api # 使用 MySQL 的部署命令,在上面的基础上添加 -e SQL_DSN&qu…...
MapReduce学习问题记录
1、如何跳过对某行数据的处理 第一行数据是字段名不需要处理,我们知道第一行偏移量是0(行记录的时候是从数组首地址开始,到了行标识符进行一次计数,这个计数就是行偏移量,从0开始),我们根据偏移…...

Elasticsearch优化
集群配置 1、调整副本数:考虑数据的可用性和读取性能,合理配置分片的副本数。 2、合理配置分片大小(分片的合理容量:10GB-50GB):避免分片过大,以确保更好的性能和均衡的负载。 3、监控集群状态:使用监控工…...
【Redis知识点总结】(六)——主从同步、哨兵模式、集群
Redis知识点总结(六)——主从同步、哨兵模式、集群 主从同步哨兵集群 主从同步 redis的主从同步,一般是一个主节点,加上多个从节点。只有主节点可以接收写命令,主节点接收到的写命令,会同步给从节点&#…...

Java面试题:设计一个线程安全的单例模式,并解释其内存占用和垃圾回收机制;使用生产者消费者模式实现一个并发安全的队列;设计一个支持高并发的分布式锁
Java深度面试题:设计模式、内存管理与并发编程的综合考察 随着Java技术的不断发展,对Java开发者的技术要求也在不断提高。设计模式、内存管理、多线程工具类以及并发工具包和框架等都是Java开发者必须掌握的核心知识点。本文将通过三道综合性的面试题&a…...

【硬件设计】以立创EDA举例——持续更新
【硬件设计】以立创EDA举例——持续更新 文章目录 前言立创EDA官网教程一、原理图二、PCB1.布局2.设计规则3.电流与线宽 4.PCB走线5.Polar Si90006.过孔7.铺铜总结 前言 提示:以下是本篇文章正文内容,下面案例可供参考 立创EDA官网教程 立创EDA使用教程…...

Chain of Note-CoN增强检索增强型语言模型的鲁棒性
Enhancing Robustness in Retrieval-Augmented Language Models 检索增强型语言模型(RALMs)在大型语言模型的能力上取得了重大进步,特别是在利用外部知识源减少事实性幻觉方面。然而,检索到的信息的可靠性并不总是有保证的。检索…...

Uniapp 的 uni.request传参后端
以下是使用Uniapp的交互数据的两种方式 后端使用Parameter接收数据 后端使用RequestBody接收Json格式数据 后端: CrossOrigin RestController RequestMapping("/user") public class UserController {GetMapping("/login")public String lo…...
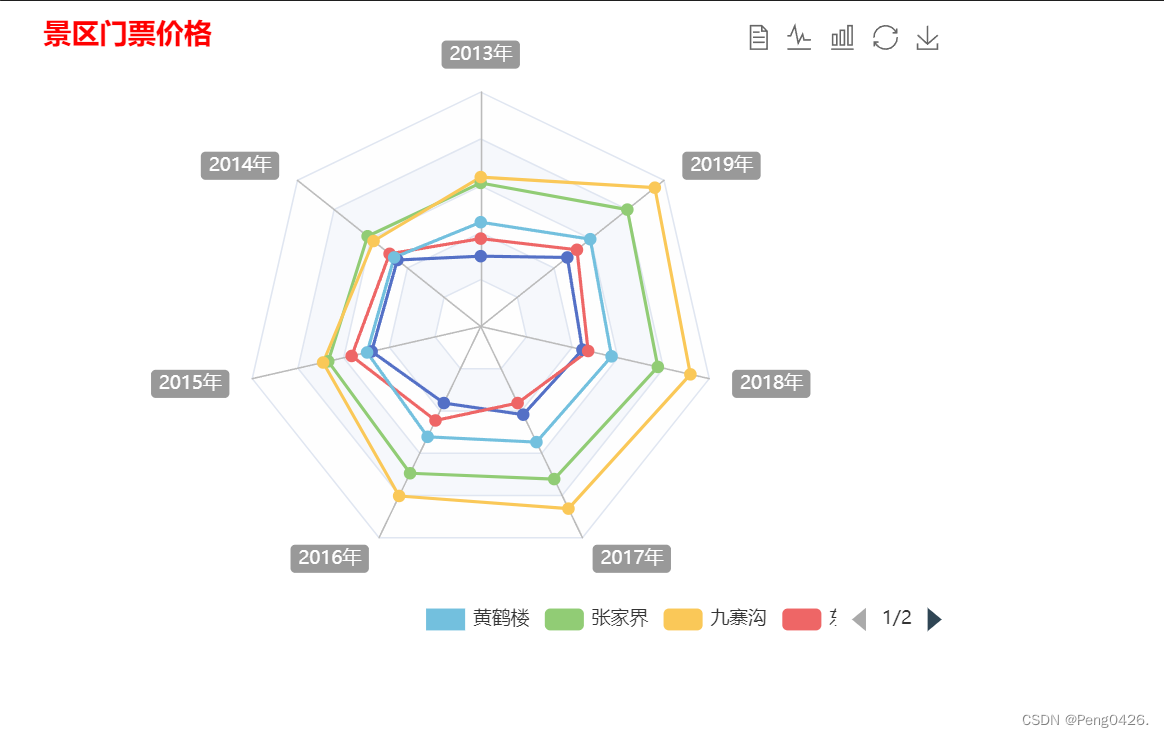
数据可视化-ECharts Html项目实战(5)
在之前的文章中,我们学习了如何设置滚动图例,工具箱设置和插入图片。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢 数据可视化-ECharts…...

C++学习之旅(二)运行四个小项目 (Ubuntu使用Vscode)
如果是c语言学的比较好的同学 可以直接跟着代码敲一遍,代码附有详细语法介绍,不可错过 一,猜数字游戏 #include <iostream> #include <cstdlib> #include <ctime>int main() {srand(static_cast<unsigned int>(tim…...
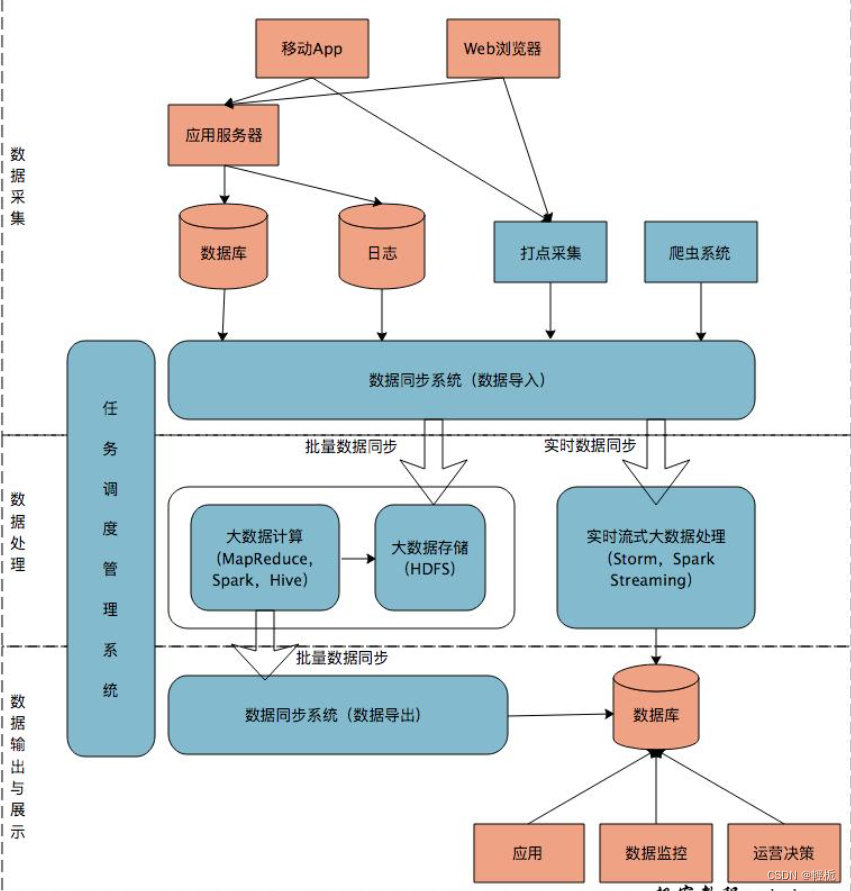
数据分析与挖掘
数据起源: 规模庞大,结构复杂,难以通过现有商业工具和技术在可容忍的时间内获取、管理和处理的数据集。具有5V特性:数量(Volume):数据量大、多样性(Variety):…...
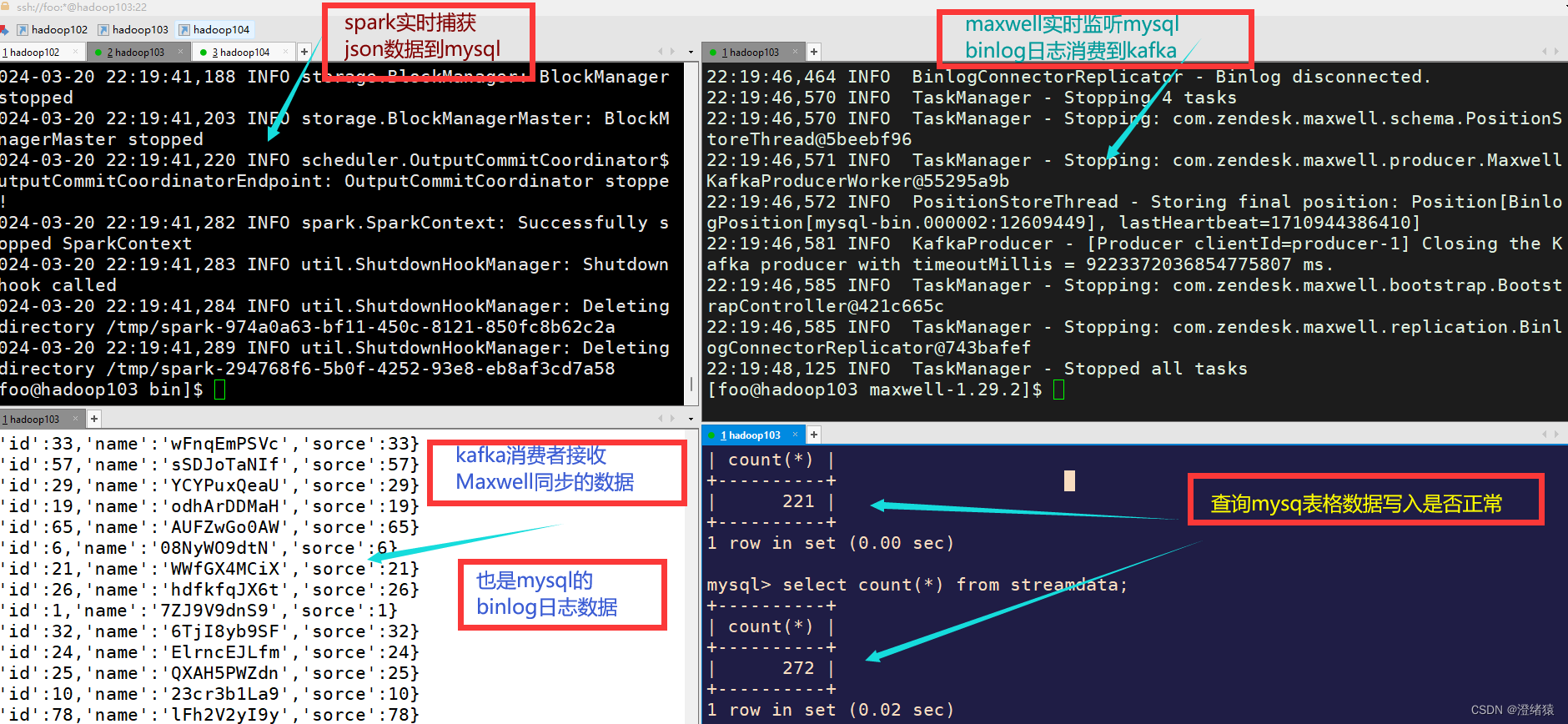
Maxwell监听mysql的binlog日志变化写入kafka消费者
一. 环境: maxwell:v1.29.2 (从1.30开始maxwell停止了对java8的使用,改为为11) maxwell1.29.2这个版本对mysql8.0以后的缺少utf8mb3字符的解码问题,需要对原码中加上一个部分内容 :具体也给大家做了总结 : 关于v1.…...

Kafka系列之:Kafka Connect REST API
Kafka系列之:Kafka Connect REST API 由于 Kafka Connect 旨在作为服务运行,因此它还提供了用于管理连接器的 REST API。此 REST API 可在独立模式和分布式模式下使用。可以使用侦听器配置选项来配置 REST API 服务器。该字段应包含以下格式的侦听器列表: protocol://host:p…...

四旋翼变形控制:RL与MPC在混合动力学中的对比
1. 四旋翼变形控制的技术挑战与解决方案四旋翼变形控制(Quadrotor Morpho-Transition)是当前机器人领域最具挑战性的前沿技术之一。这项技术使机器人能够在空中完成形态变换,实现从飞行模式到地面模式的平滑切换。想象一下,一架四…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...
)
用Python+OpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图)
用PythonOpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图) 边缘检测是计算机视觉中最基础也最关键的预处理步骤之一。想象一下,当你需要让计算机"看清"一张照片中的物体轮廓时,边缘检测算法就是它的"视觉…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

浏览器 Profile 环境排查:Cookie、LocalStorage、网络出口与自动化任务配置清单
一、为什么浏览器环境经常“今天能用,明天失效”很多团队遇到登录状态丢失、页面配置异常、自动化任务失败时,会先怀疑网络、脚本或系统本身。但在实际项目里,问题经常不是单点故障,而是浏览器环境缺少稳定管理:对象常…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析
更多请点击: https://intelliparadigm.com 第一章:为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析 在对17个采用DeepSeek-R1/VL模型开展定制化开发的工业级项目进行回溯审计后,我…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...

Taotoken的审计日志功能为企业API安全与合规管理提供支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的审计日志功能为企业API安全与合规管理提供支持 当企业决定将大模型能力集成到内部业务流程中时,IT管理员和安…...