(三维重建学习)已有位姿放入colmap和3D Gaussian Splatting训练
这里写目录标题
- 一、colmap解算数据放入高斯
- 1. 将稀疏重建的文件放入高斯
- 2. 将稠密重建的文件放入高斯
- 二、vkitti数据放入高斯
一、colmap解算数据放入高斯
运行Colmap.bat文件之后,进行稀疏重建和稠密重建之后可以得到如下文件结构。
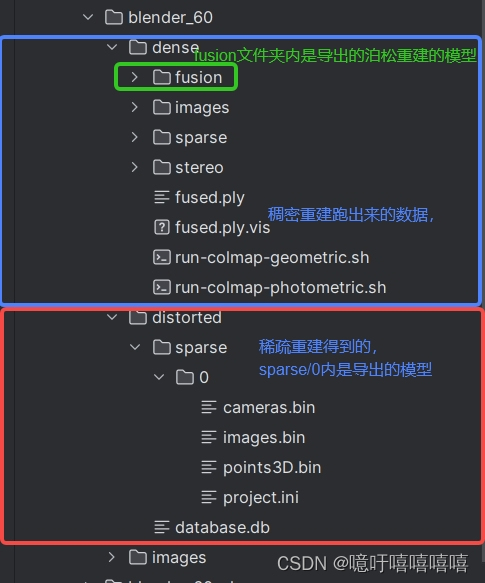
1. 将稀疏重建的文件放入高斯
按照以下文件结构将colmap中的数据放入高斯中,就可以执行 python train.py -s data/data_blender_60 -m data/data_blender_60/output 了
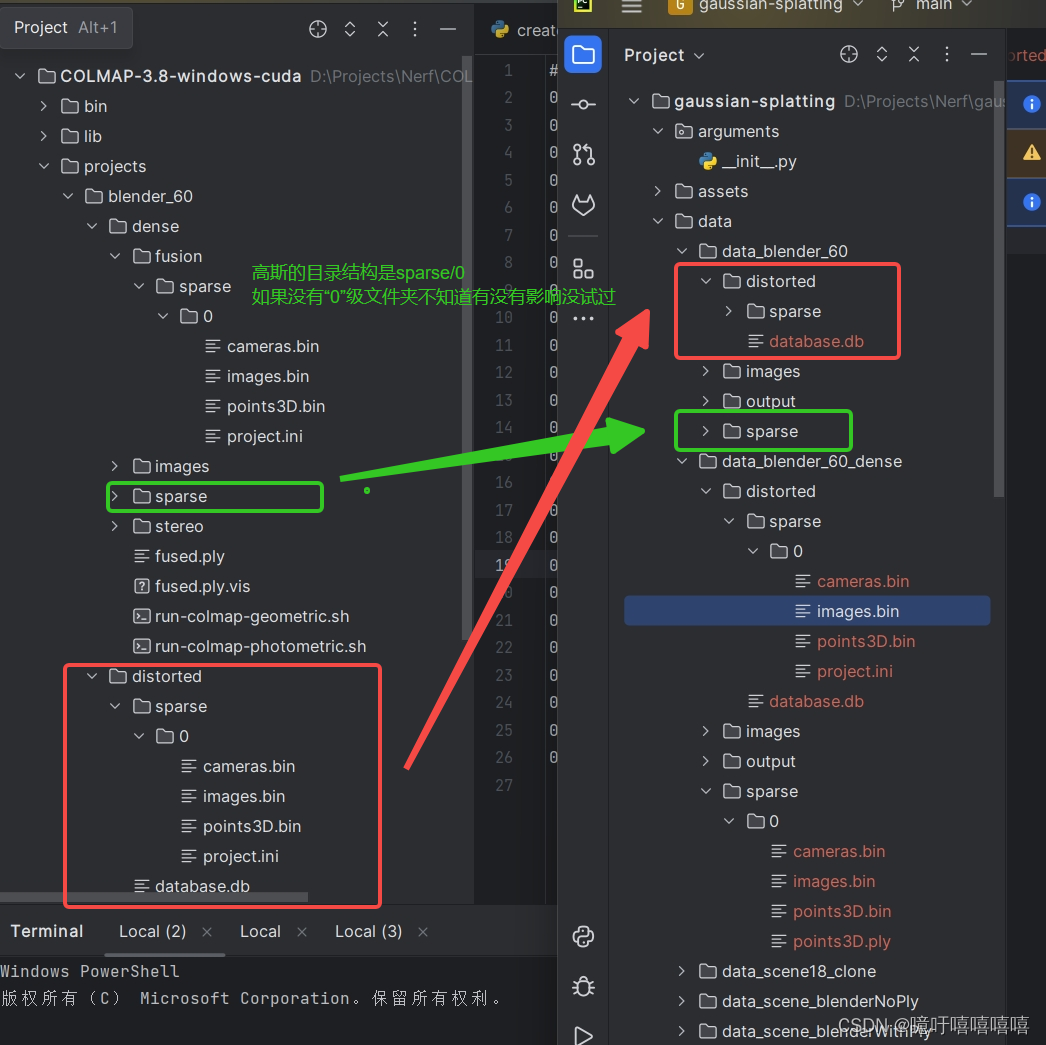
2. 将稠密重建的文件放入高斯
按照以下文件结构将colmap中的数据放入高斯中,
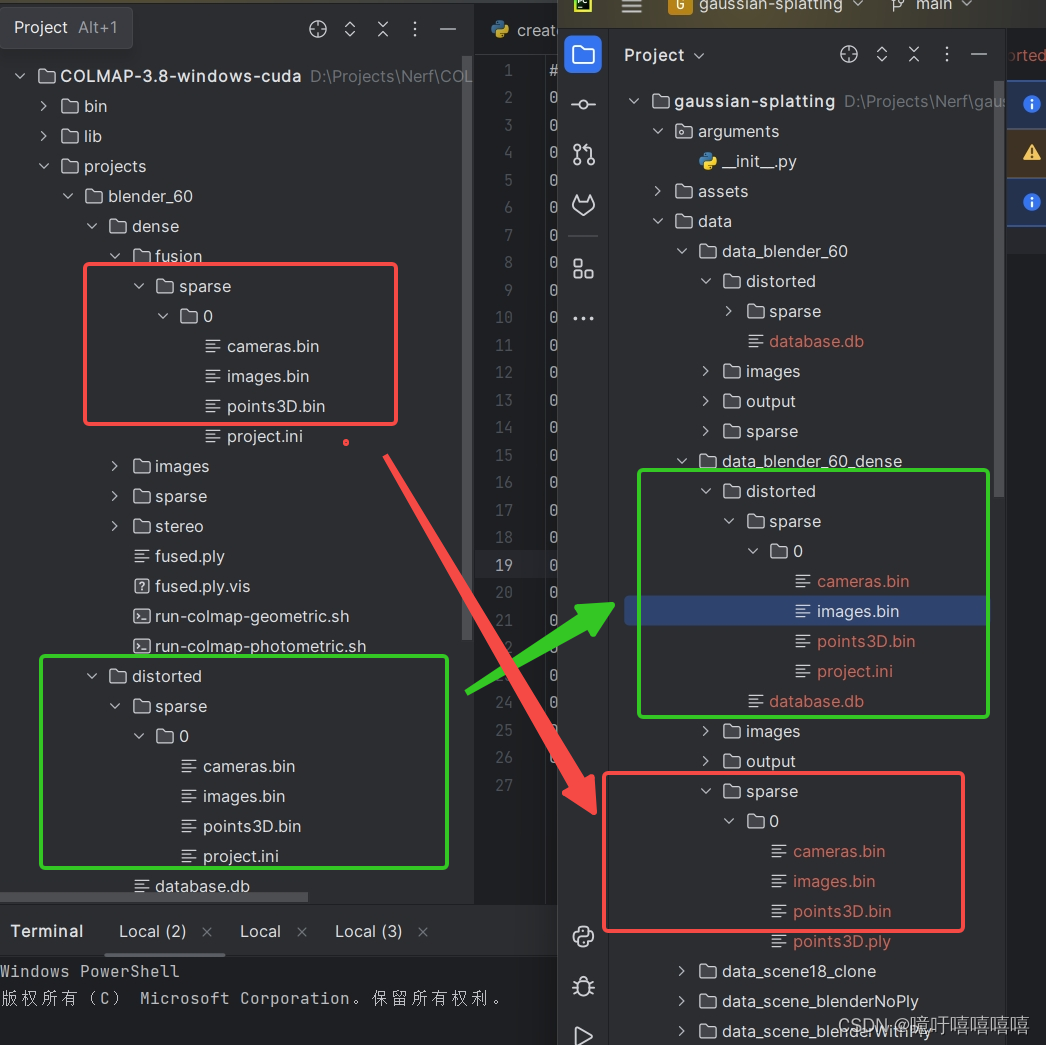
此时若直接运行train文件会有如下报错:
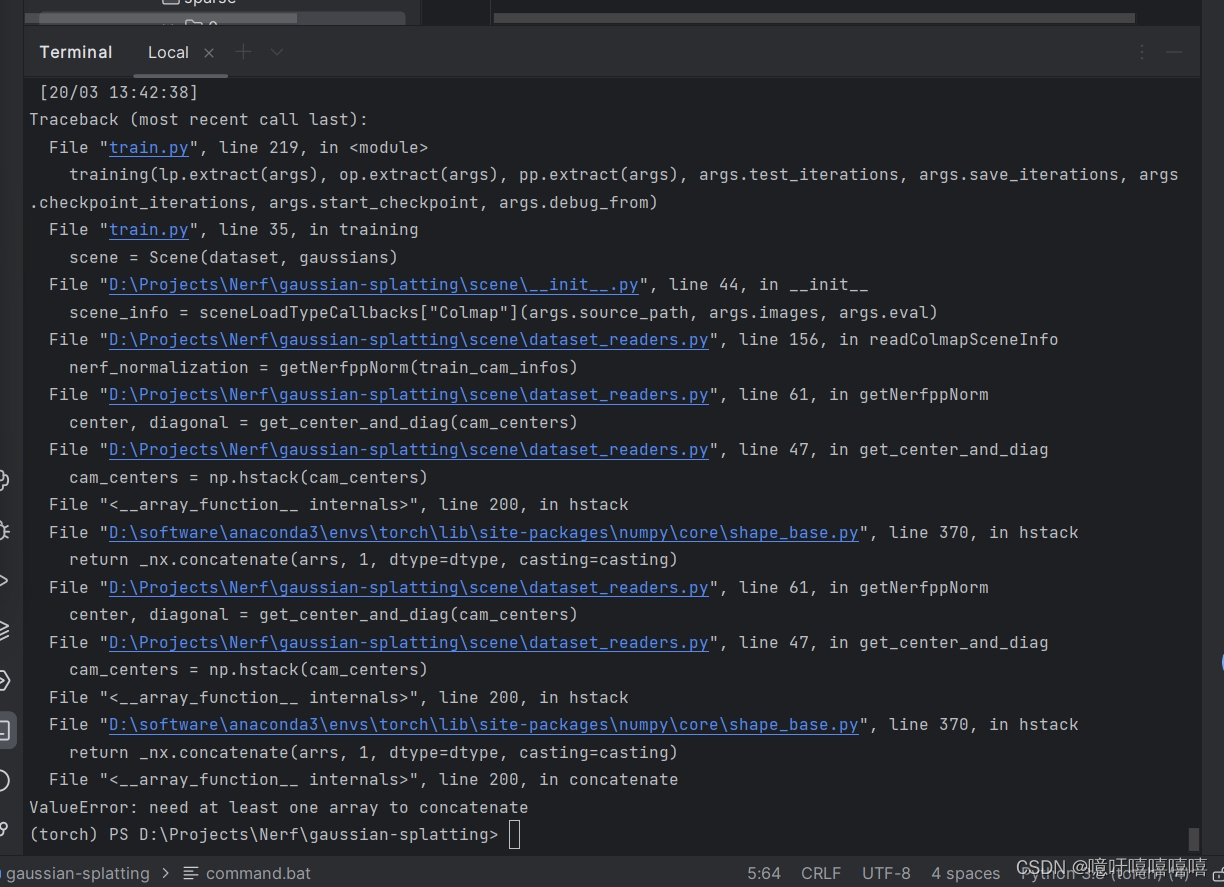
意思是没有获取到cameras,点开sparse/0中的cameras文件,发现全是null,此时,**先删除sparse/0中的cameras.bin和images.bin,再将distorted/sparse/0中的cameras.bin和images.bin文件复制到sparse/0中。**实在不行也可以在colmap中重新导出一下模型。
就可以执行 python train.py -s data/data_blender_60 -m data/data_blender_60/output 了
二、vkitti数据放入高斯
vkitti数据数据格式如下:
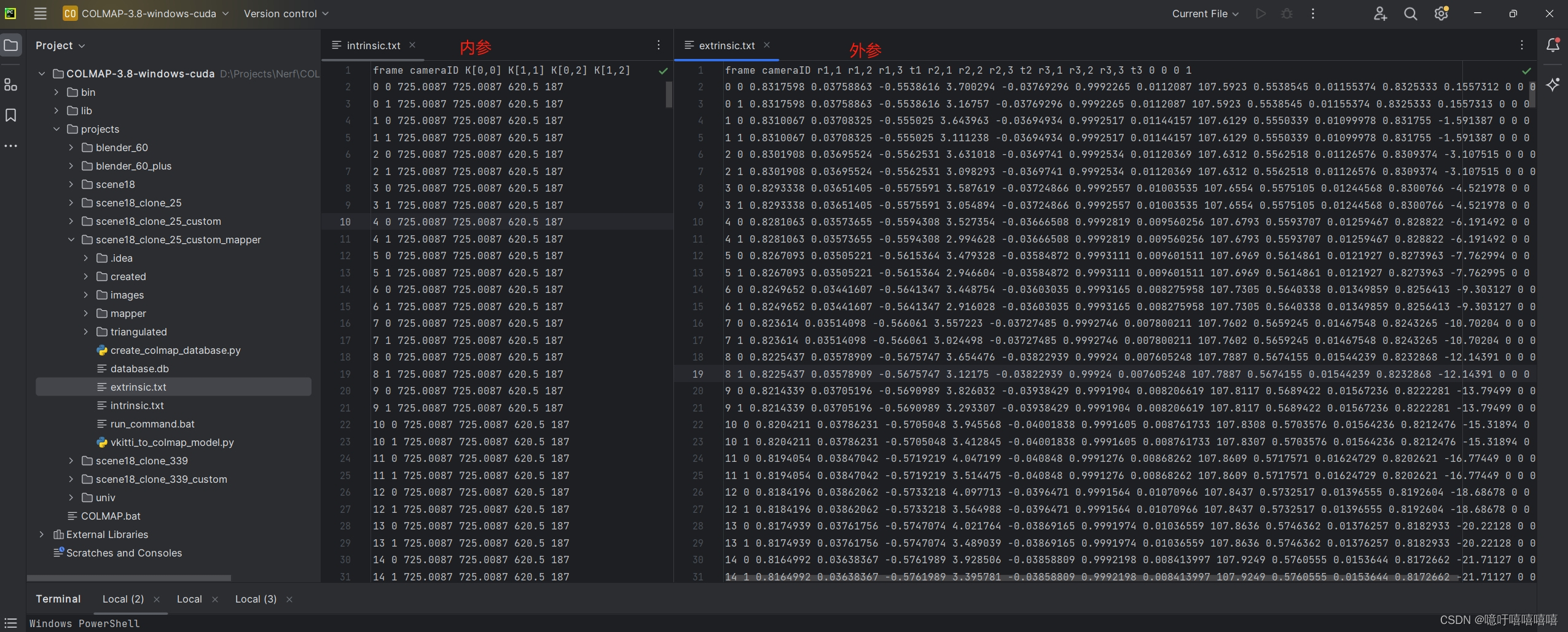
colmap数据数据格式如下(外参数据一定要空一行否则后续不会执行):
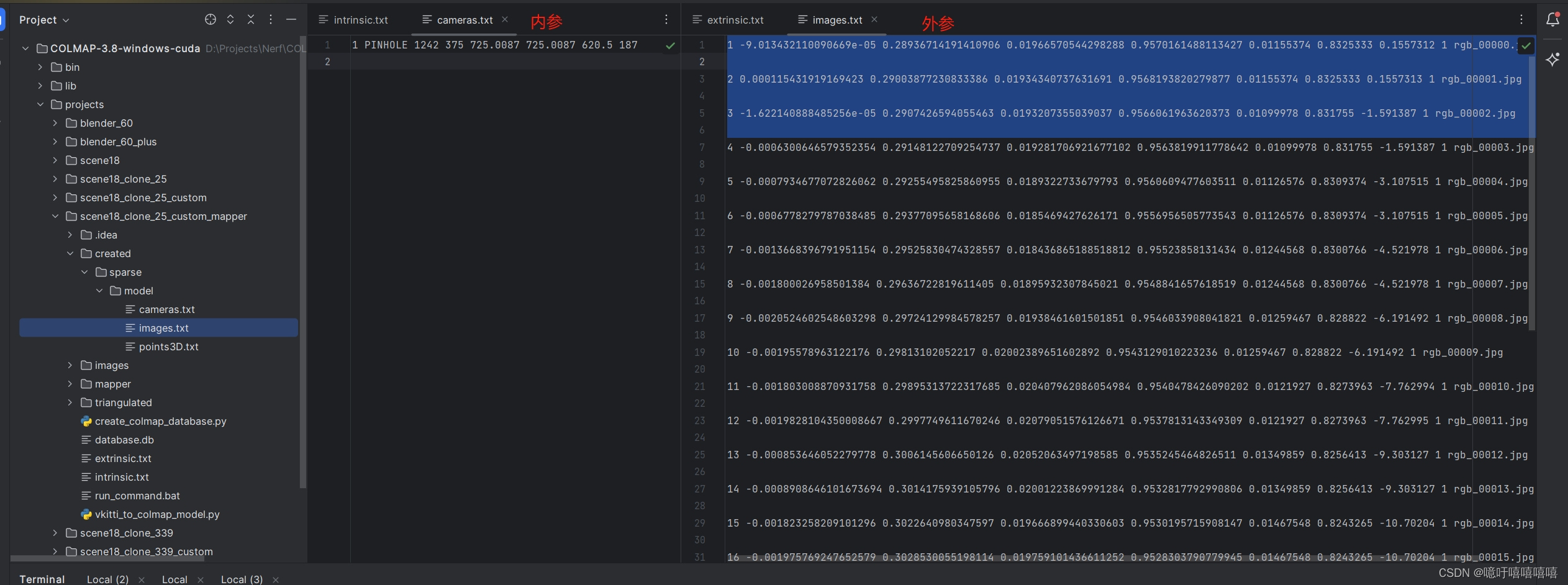
最后我的colmap中目录结构如下:
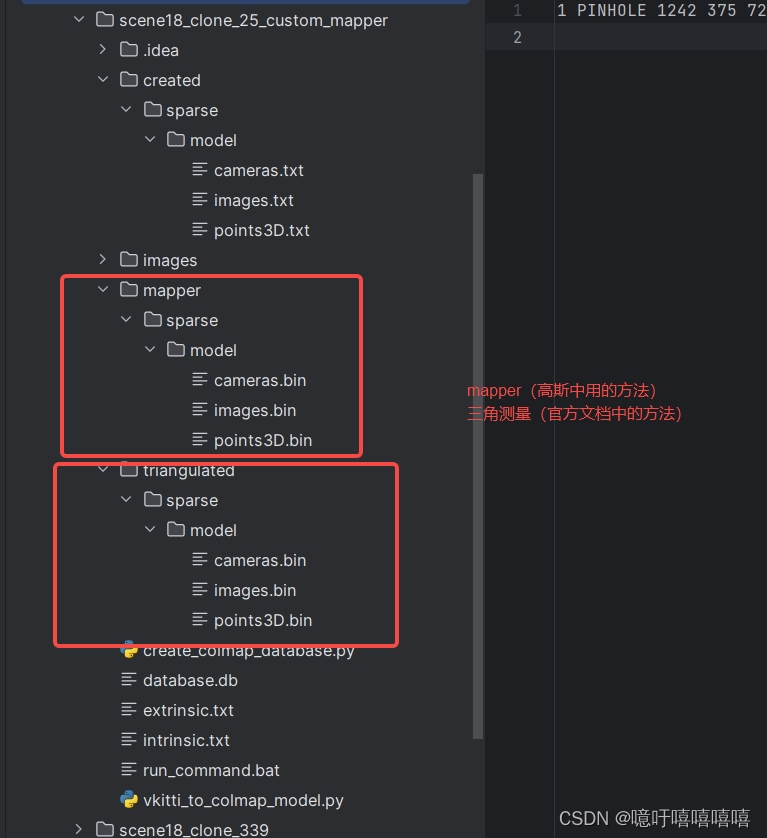
先自行创建以下几个文件夹:执行command.bat
@echo off
if not exist created\sparse\model (mkdir created\sparse\modelecho Created directory: created\sparse\model
)
if not exist triangulated\sparse\model (mkdir triangulated\sparse\modelecho Created directory: triangulated\sparse\model
)
if not exist mapper\sparse\model (mkdir mapper\sparse\modelecho Created directory: mapper\sparse\model
)
接下来开始操作:
写了一个程序进行格式转换:vkitti_to_colmap_cameras.py
import numpy as np
from scipy.spatial.transform import Rotationindex = 339 #要转换的图片张数def cameras(input_path, output_path):# 定义一个字典用于存储提取的数据data_dict = {'frame': [], 'cameraID': [], 'PARAMS': []}# 打开文件并读取内容with open(input_path, 'r') as file:lines = file.readlines()[1:]# # 删除 camera=1的行# lines = [line for index, line in enumerate(lines) if index % 2 == 0]# 遍历每一行数据for line in lines:# 分割每一行数据elements = line.split()# 提取frame和cameraIDframe = int(elements[0])cameraID = int(elements[1])if cameraID == 1:continue# 提取PARAMSPARAMS = elements[2:6]# 将提取的数据存入字典data_dict['frame'].append(frame)data_dict['cameraID'].append(frame + 1)data_dict['PARAMS'].append(PARAMS)width = 1242height = 375# 将处理后的内容写回文件# 打开文件以写入数据with open(output_path, 'w') as output_file:# 写入文件头部信息output_file.write("# Camera list with one line of data per camera:\n# CAMERA_ID, MODEL, WIDTH, HEIGHT, PARAMS[fx,fy,cx,cy]\n# Number of cameras: 1\n")# 遍历每个数据点for i in range(len(data_dict['frame'])):# 获取相应的数据if data_dict['frame'][i] > index - 1:breakcameraID = data_dict['cameraID'][i]PARAMS = data_dict['PARAMS'][i]fx, fy, cx, cy = PARAMS# 写入数据到文件output_file.write(f"{cameraID} PINHOLE {width} {height} {fx} {fy} {cx} {cy}\n")def images(input_path, output_path):# 定义一个字典用于存储提取的数据data_dict = {'frame': [], 'cameraID': [], 'quaternions': []}# 打开文件并读取内容with open(input_path, 'r') as file:lines = file.readlines()[1:]# 遍历每一行数据for line in lines:# 分割每一行数据elements = line.split()# 提取frame和cameraIDframe = int(elements[0])cameraID = int(elements[1])if cameraID == 1:continue# 提取旋转矩阵部分rotation_matrix = np.array([[float(elements[i]) for i in range(2, 11, 4)],[float(elements[i]) for i in range(3, 12, 4)],[float(elements[i]) for i in range(4, 13, 4)]])# 将旋转矩阵转换为四元数rotation = Rotation.from_matrix(rotation_matrix)quaternion = rotation.as_quat()# 将提取的数据存入字典data_dict['frame'].append(frame)data_dict['cameraID'].append(frame + 1)data_dict['quaternions'].append(quaternion)# 打开文件以写入数据with open(output_path, 'w') as output_file:# 写入文件头部信息output_file.write("# Image list with two lines of data per image:\n# IMAGE_ID, QW, QX, QY, QZ, TX, TY, TZ, CAMERA_ID, NAME\n# POINTS2D[] as (X, Y, POINT3D_ID)\n# Number of images: 339, mean observations per image: 1\n")# 遍历每个数据点for i in range(len(data_dict['frame'])):# 获取相应的数据if data_dict['frame'][i] > index - 1:breakframe = data_dict['frame'][i]cameraID = data_dict['cameraID'][i]quaternion = data_dict['quaternions'][i]# 将四元数和平移向量分开qw, qx, qy, qz = quaterniontx, ty, tz = [float(elem) for elem in lines[i].split()[11:14]]# 写入数据到文件output_file.write(f"{frame + 1} {qw} {qx} {qy} {qz} {tx} {ty} {tz} {cameraID} rgb_{frame:05d}.jpg\n\n")if __name__ == '__main__':input_path = "./intrinsic.txt"output_path = "./cameras.txt"cameras(input_path, output_path)input_path = "./extrinsic.txt"output_path = "./images.txt"images(input_path, output_path)我的同学写了一个创建数据库的代码 ,这将cameras.txt和images.txt文件中的数据都放入database.db中:create_colmap_database.py
# Copyright (c) 2023, ETH Zurich and UNC Chapel Hill.
# All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are met:
#
# * Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
#
# * Redistributions in binary form must reproduce the above copyright
# notice, this list of conditions and the following disclaimer in the
# documentation and/or other materials provided with the distribution.
#
# * Neither the name of ETH Zurich and UNC Chapel Hill nor the names of
# its contributors may be used to endorse or promote products derived
# from this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
# ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDERS OR CONTRIBUTORS BE
# LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
# CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
# SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
# INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
# CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
# ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
# POSSIBILITY OF SUCH DAMAGE.# This script is based on an original implementation by True Price.import sys
import sqlite3
import numpy as npIS_PYTHON3 = sys.version_info[0] >= 3MAX_IMAGE_ID = 2 ** 31 - 1CREATE_CAMERAS_TABLE = """CREATE TABLE IF NOT EXISTS cameras (camera_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,model INTEGER NOT NULL,width INTEGER NOT NULL,height INTEGER NOT NULL,params BLOB,prior_focal_length INTEGER NOT NULL)"""CREATE_DESCRIPTORS_TABLE = """CREATE TABLE IF NOT EXISTS descriptors (image_id INTEGER PRIMARY KEY NOT NULL,rows INTEGER NOT NULL,cols INTEGER NOT NULL,data BLOB,FOREIGN KEY(image_id) REFERENCES images(image_id) ON DELETE CASCADE)"""CREATE_IMAGES_TABLE = """CREATE TABLE IF NOT EXISTS images (image_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,name TEXT NOT NULL UNIQUE,camera_id INTEGER NOT NULL,prior_qw REAL,prior_qx REAL,prior_qy REAL,prior_qz REAL,prior_tx REAL,prior_ty REAL,prior_tz REAL,CONSTRAINT image_id_check CHECK(image_id >= 0 and image_id < {}),FOREIGN KEY(camera_id) REFERENCES cameras(camera_id))
""".format(MAX_IMAGE_ID
)CREATE_TWO_VIEW_GEOMETRIES_TABLE = """
CREATE TABLE IF NOT EXISTS two_view_geometries (pair_id INTEGER PRIMARY KEY NOT NULL,rows INTEGER NOT NULL,cols INTEGER NOT NULL,data BLOB,config INTEGER NOT NULL,F BLOB,E BLOB,H BLOB,qvec BLOB,tvec BLOB)
"""CREATE_KEYPOINTS_TABLE = """CREATE TABLE IF NOT EXISTS keypoints (image_id INTEGER PRIMARY KEY NOT NULL,rows INTEGER NOT NULL,cols INTEGER NOT NULL,data BLOB,FOREIGN KEY(image_id) REFERENCES images(image_id) ON DELETE CASCADE)
"""CREATE_MATCHES_TABLE = """CREATE TABLE IF NOT EXISTS matches (pair_id INTEGER PRIMARY KEY NOT NULL,rows INTEGER NOT NULL,cols INTEGER NOT NULL,data BLOB)"""CREATE_NAME_INDEX = ("CREATE UNIQUE INDEX IF NOT EXISTS index_name ON images(name)"
)CREATE_ALL = "; ".join([CREATE_CAMERAS_TABLE,CREATE_IMAGES_TABLE,CREATE_KEYPOINTS_TABLE,CREATE_DESCRIPTORS_TABLE,CREATE_MATCHES_TABLE,CREATE_TWO_VIEW_GEOMETRIES_TABLE,CREATE_NAME_INDEX,]
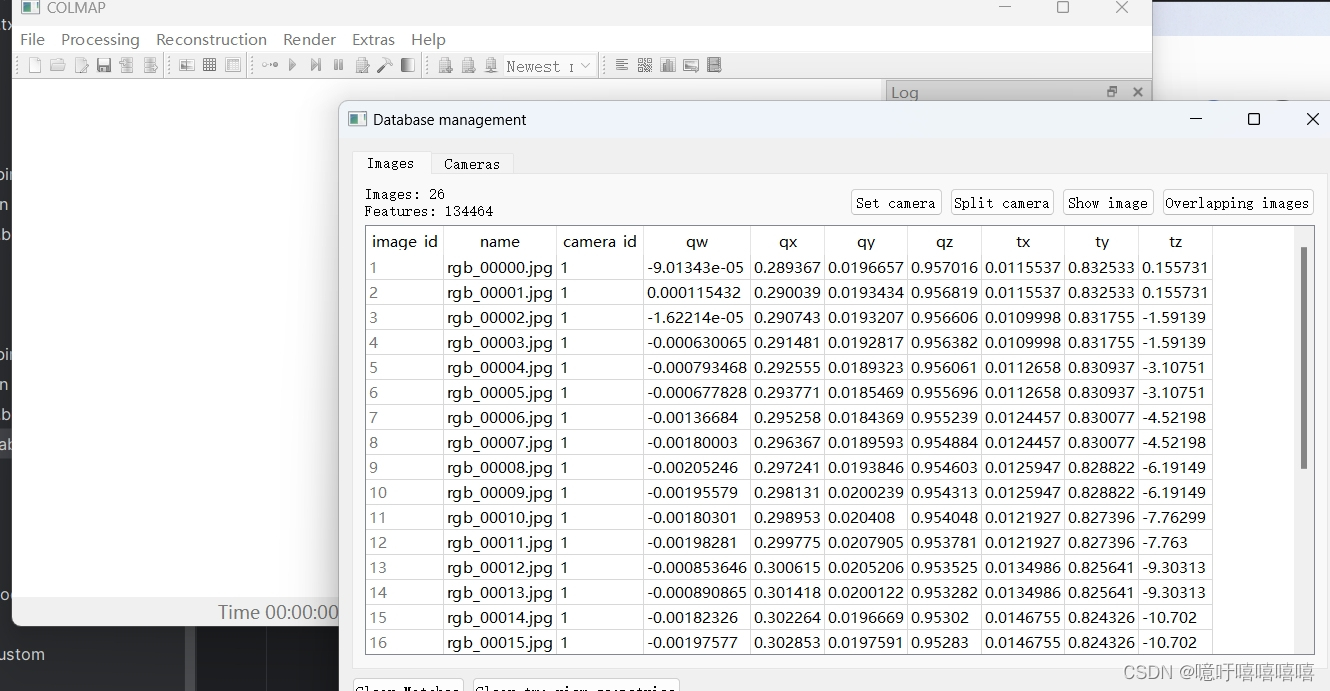
)def image_ids_to_pair_id(image_id1, image_id2):if image_id1 > image_id2:image_id1, image_id2 = image_id2, image_id1return image_id1 * MAX_IMAGE_ID + image_id2def pair_id_to_image_ids(pair_id):image_id2 = pair_id % MAX_IMAGE_IDimage_id1 = (pair_id - image_id2) / MAX_IMAGE_IDreturn image_id1, image_id2def array_to_blob(array):if IS_PYTHON3:return array.tobytes()else:return np.getbuffer(array)def blob_to_array(blob, dtype, shape=(-1,)):if IS_PYTHON3:return np.fromstring(blob, dtype=dtype).reshape(*shape)else:return np.frombuffer(blob, dtype=dtype).reshape(*shape)class COLMAPDatabase(sqlite3.Connection):@staticmethoddef connect(database_path):return sqlite3.connect(database_path, factory=COLMAPDatabase)def __init__(self, *args, **kwargs):super(COLMAPDatabase, self).__init__(*args, **kwargs)self.create_tables = lambda: self.executescript(CREATE_ALL)self.create_cameras_table = lambda: self.executescript(CREATE_CAMERAS_TABLE)self.create_descriptors_table = lambda: self.executescript(CREATE_DESCRIPTORS_TABLE)self.create_images_table = lambda: self.executescript(CREATE_IMAGES_TABLE)self.create_two_view_geometries_table = lambda: self.executescript(CREATE_TWO_VIEW_GEOMETRIES_TABLE)self.create_keypoints_table = lambda: self.executescript(CREATE_KEYPOINTS_TABLE)self.create_matches_table = lambda: self.executescript(CREATE_MATCHES_TABLE)self.create_name_index = lambda: self.executescript(CREATE_NAME_INDEX)def add_camera(self,model,width,height,params,prior_focal_length=False,camera_id=None,):params = np.asarray(params, np.float64)cursor = self.execute("INSERT INTO cameras VALUES (?, ?, ?, ?, ?, ?)",(camera_id,model,width,height,array_to_blob(params),prior_focal_length,),)return cursor.lastrowiddef add_image(self,name,camera_id,prior_q=np.full(4, np.NaN),prior_t=np.full(3, np.NaN),image_id=None,):cursor = self.execute("INSERT INTO images VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)",(image_id,name,camera_id,prior_q[0],prior_q[1],prior_q[2],prior_q[3],prior_t[0],prior_t[1],prior_t[2],),)return cursor.lastrowiddef add_keypoints(self, image_id, keypoints):assert len(keypoints.shape) == 2assert keypoints.shape[1] in [2, 4, 6]keypoints = np.asarray(keypoints, np.float32)self.execute("INSERT INTO keypoints VALUES (?, ?, ?, ?)",(image_id,) + keypoints.shape + (array_to_blob(keypoints),),)def add_descriptors(self, image_id, descriptors):descriptors = np.ascontiguousarray(descriptors, np.uint8)self.execute("INSERT INTO descriptors VALUES (?, ?, ?, ?)",(image_id,) + descriptors.shape + (array_to_blob(descriptors),),)def add_matches(self, image_id1, image_id2, matches):assert len(matches.shape) == 2assert matches.shape[1] == 2if image_id1 > image_id2:matches = matches[:, ::-1]pair_id = image_ids_to_pair_id(image_id1, image_id2)matches = np.asarray(matches, np.uint32)self.execute("INSERT INTO matches VALUES (?, ?, ?, ?)",(pair_id,) + matches.shape + (array_to_blob(matches),),)def add_two_view_geometry(self,image_id1,image_id2,matches,F=np.eye(3),E=np.eye(3),H=np.eye(3),qvec=np.array([1.0, 0.0, 0.0, 0.0]),tvec=np.zeros(3),config=2,):assert len(matches.shape) == 2assert matches.shape[1] == 2if image_id1 > image_id2:matches = matches[:, ::-1]pair_id = image_ids_to_pair_id(image_id1, image_id2)matches = np.asarray(matches, np.uint32)F = np.asarray(F, dtype=np.float64)E = np.asarray(E, dtype=np.float64)H = np.asarray(H, dtype=np.float64)qvec = np.asarray(qvec, dtype=np.float64)tvec = np.asarray(tvec, dtype=np.float64)self.execute("INSERT INTO two_view_geometries VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)",(pair_id,)+ matches.shape+ (array_to_blob(matches),config,array_to_blob(F),array_to_blob(E),array_to_blob(H),array_to_blob(qvec),array_to_blob(tvec),),)def example_usage():import osimport argparseparser = argparse.ArgumentParser()parser.add_argument("--database_path", default="database.db")args = parser.parse_args()if os.path.exists(args.database_path):print("ERROR: database path already exists -- will not modify it.")return# Open the database.db = COLMAPDatabase.connect(args.database_path)# For convenience, try creating all the tables upfront.db.create_tables()# Create dummy cameras.model1, width1, height1, params1 = (0,1024,768,np.array((1024.0, 512.0, 384.0)),)model2, width2, height2, params2 = (2,1024,768,np.array((1024.0, 512.0, 384.0, 0.1)),)camera_id1 = db.add_camera(model1, width1, height1, params1)camera_id2 = db.add_camera(model2, width2, height2, params2)# Create dummy images.image_id1 = db.add_image("image1.png", camera_id1)image_id2 = db.add_image("image2.png", camera_id1)image_id3 = db.add_image("image3.png", camera_id2)image_id4 = db.add_image("image4.png", camera_id2)# Create dummy keypoints.## Note that COLMAP supports:# - 2D keypoints: (x, y)# - 4D keypoints: (x, y, theta, scale)# - 6D affine keypoints: (x, y, a_11, a_12, a_21, a_22)num_keypoints = 1000keypoints1 = np.random.rand(num_keypoints, 2) * (width1, height1)keypoints2 = np.random.rand(num_keypoints, 2) * (width1, height1)keypoints3 = np.random.rand(num_keypoints, 2) * (width2, height2)keypoints4 = np.random.rand(num_keypoints, 2) * (width2, height2)db.add_keypoints(image_id1, keypoints1)db.add_keypoints(image_id2, keypoints2)db.add_keypoints(image_id3, keypoints3)db.add_keypoints(image_id4, keypoints4)# Create dummy matches.M = 50matches12 = np.random.randint(num_keypoints, size=(M, 2))matches23 = np.random.randint(num_keypoints, size=(M, 2))matches34 = np.random.randint(num_keypoints, size=(M, 2))db.add_matches(image_id1, image_id2, matches12)db.add_matches(image_id2, image_id3, matches23)db.add_matches(image_id3, image_id4, matches34)# Commit the data to the file.db.commit()# Read and check cameras.rows = db.execute("SELECT * FROM cameras")camera_id, model, width, height, params, prior = next(rows)params = blob_to_array(params, np.float64)assert camera_id == camera_id1assert model == model1 and width == width1 and height == height1assert np.allclose(params, params1)camera_id, model, width, height, params, prior = next(rows)params = blob_to_array(params, np.float64)assert camera_id == camera_id2assert model == model2 and width == width2 and height == height2assert np.allclose(params, params2)# Read and check keypoints.keypoints = dict((image_id, blob_to_array(data, np.float32, (-1, 2)))for image_id, data in db.execute("SELECT image_id, data FROM keypoints"))assert np.allclose(keypoints[image_id1], keypoints1)assert np.allclose(keypoints[image_id2], keypoints2)assert np.allclose(keypoints[image_id3], keypoints3)assert np.allclose(keypoints[image_id4], keypoints4)# Read and check matches.pair_ids = [image_ids_to_pair_id(*pair)for pair in ((image_id1, image_id2),(image_id2, image_id3),(image_id3, image_id4),)]matches = dict((pair_id_to_image_ids(pair_id), blob_to_array(data, np.uint32, (-1, 2)))for pair_id, data in db.execute("SELECT pair_id, data FROM matches"))assert np.all(matches[(image_id1, image_id2)] == matches12)assert np.all(matches[(image_id2, image_id3)] == matches23)assert np.all(matches[(image_id3, image_id4)] == matches34)# Clean up.db.close()if os.path.exists(args.database_path):os.remove(args.database_path)def create_database():import osimport argparseparser = argparse.ArgumentParser()parser.add_argument("--database_path", default="database.db")args = parser.parse_args()# if os.path.exists(args.database_path):# print("ERROR: database path already exists -- will not modify it.")# returnif os.path.exists(args.database_path):os.remove(args.database_path)# if not os.path.exists("distorted"):# os.mkdir("distorted")# Open the database.db = COLMAPDatabase.connect(args.database_path)# For convenience, try creating all the tables upfront.db.create_tables()# Create dummy cameras.camModelDict = {'SIMPLE_PINHOLE': 0,'PINHOLE': 1,'SIMPLE_RADIAL': 2,'RADIAL': 3,'OPENCV': 4,'FULL_OPENCV': 5,'SIMPLE_RADIAL_FISHEYE': 6,'RADIAL_FISHEYE': 7,'OPENCV_FISHEYE': 8,'FOV': 9,'THIN_PRISM_FISHEYE': 10}with open("created/sparse/model/cameras.txt", "r") as cameras_file:cameras_instinct = cameras_file.read().replace("\n", "")passcameras_instinct = cameras_instinct.split(" ")# print(cameras_instinct)model1 = camModelDict[cameras_instinct[1]]width1, height1 = int(cameras_instinct[2]), int(cameras_instinct[3])params1 = np.array([float(param) for param in cameras_instinct[4:]])# print(model1,width1,height1,params1)camera_id1 = db.add_camera(model1, width1, height1, params1)# print(camera_id1)# 图片with open("created/sparse/model/images.txt", "r") as images_file:images_list = images_file.readlines()passfor images_info in images_list:if images_info == "\n":continueimages_info = images_info.replace("\n", "").split(" ")# print(images_info)idx = int(images_info[0])image_name = images_info[-1]# images_info[1]-[4] QW, QX, QY, QZimage_q = np.array([float(q_i) for q_i in images_info[1:5]])# images_info[5]-[7] TX, TY, TZimage_t = np.array([float(t_i) for t_i in images_info[5:8]])image_id_from_db = db.add_image(image_name, camera_id1, prior_q=image_q, prior_t=image_t)if idx != image_id_from_db:print(f"{idx}!={image_id_from_db}")passdb.commit()db.close()if __name__ == "__main__":# example_usage()create_database()运行之后,你可以在colmap中新建项目,导入刚才的database.db文件,查看数据是否被加载进入:
执行:
colmap feature_extractor --database_path database.db --image_path images
colmap exhaustive_matcher --database_path database.db
colmap point_triangulator --database_path database.db --image_path images --input_path created\sparse\model --output_path triangulated\sparse\model
# 或者
colmap mapper --database_path database.db --image_path images --input_path created\sparse\model --output_path mapper\sparse\model
由于我的程序并没有给我 dense/stereo/ 目录下的 patch-match.cfg 等等,于是我自建:
执行程序:generate_fusion&patch_match.py
import numpy as np
import osdef main(folder_path):# 获取文件夹中所有文件名file_names = os.listdir(folder_path)# 写入文件名到txt文件output_file_path = 'patch-match.cfg'with open(output_file_path, 'w') as file:for file_name in file_names:file.write(f"{file_name}\n__auto__, 20\n")output_file_path = 'fusion.cfg'with open(output_file_path, 'w') as file:for file_name in file_names:file.write(f"{file_name}\n")if __name__ == '__main__':folder_path = "images"main(folder_path)将数据移入高斯(我用的三角测量的):
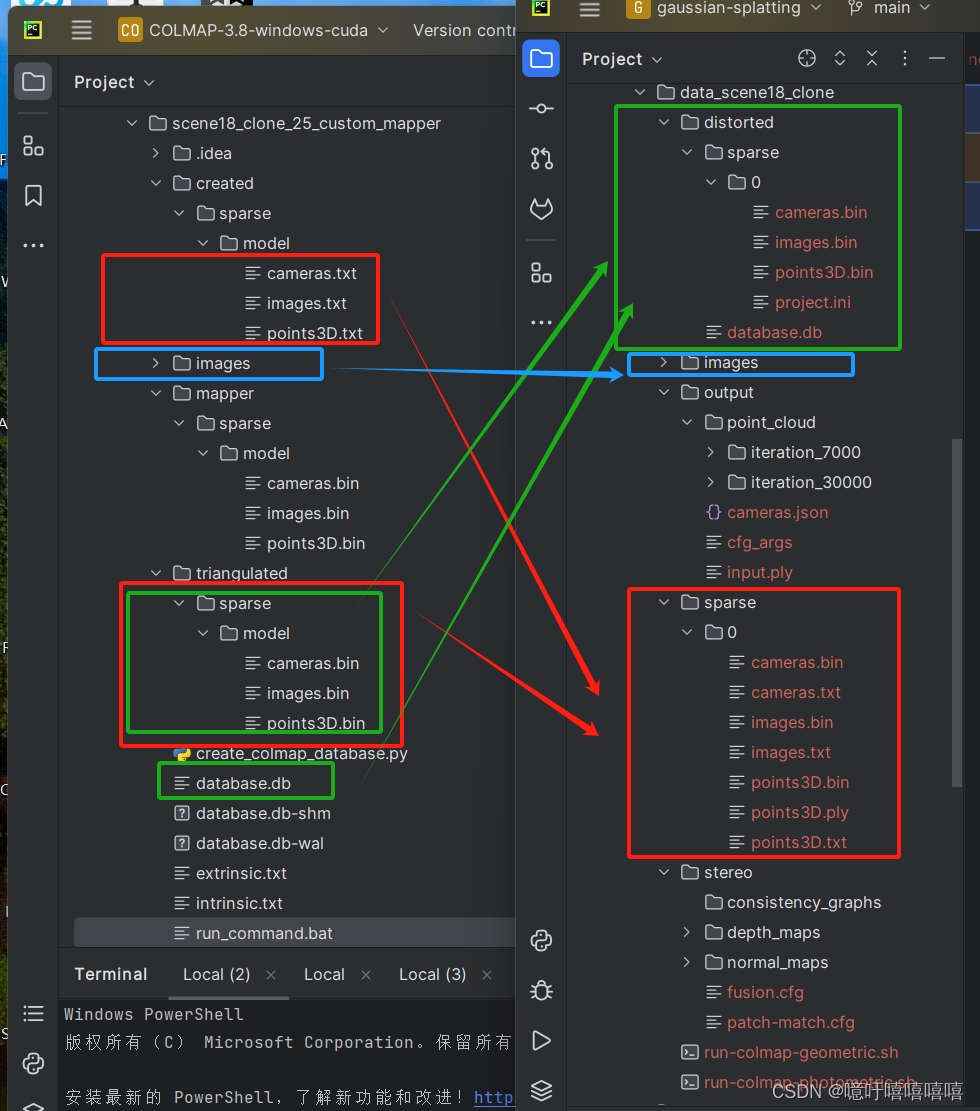
就可以在高斯中执行就 python train.py -s data/data_scene18 -m data/data_scene18 /output 了
但在可视化的时候老是会崩,而且colmap中进行系数重建和稠密重建的效果也不好。中间肯定还是有步骤出错了。
相关文章:
(三维重建学习)已有位姿放入colmap和3D Gaussian Splatting训练
这里写目录标题 一、colmap解算数据放入高斯1. 将稀疏重建的文件放入高斯2. 将稠密重建的文件放入高斯 二、vkitti数据放入高斯 一、colmap解算数据放入高斯 运行Colmap.bat文件之后,进行稀疏重建和稠密重建之后可以得到如下文件结构。 1. 将稀疏重建的文件放入高…...

4635: 【搜索】【广度优先】回家
题目描述 小 H 在一个划分成了nm 个方格的长方形封锁线上。 每次他能向上下左右四个方向移动一格(当然小 H 不可以静止不动), 但不能离开封锁线,否则就被打死了。 刚开始时他有满血 6 点,每移动一格他要消耗 1 点血量…...
Uibot6.0 (RPA财务机器人师资培训第1天 )RPA+AI、RPA基础语法
训练网站:泓江科技 (lessonplan.cn)https://laiye.lessonplan.cn/list/ec0f5080-e1de-11ee-a1d8-3f479df4d981(本博客中会有部分课程ppt截屏,如有侵权请及请及时与小北我取得联系~) 紧接着小北之前的几篇博客,友友们我们即将开展新课的学习~…...
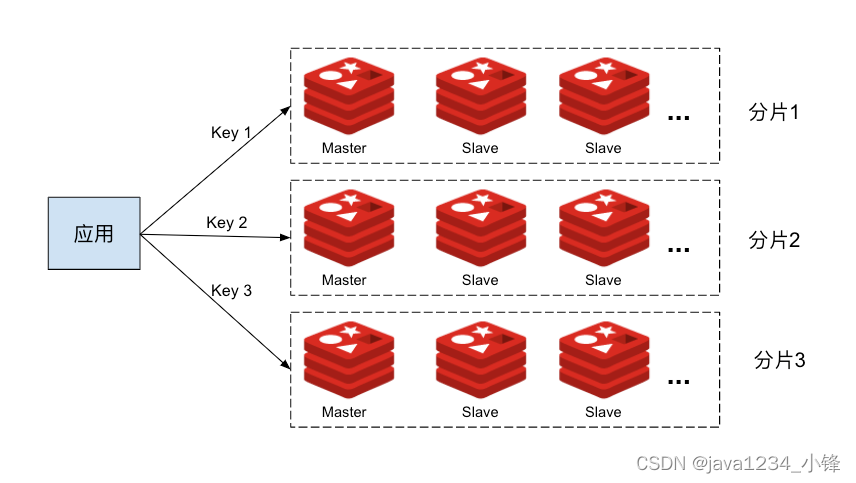
【吊打面试官系列】Redis篇 -Redis集群的主从复制模型是怎样的?
大家好,我是锋哥。今天分享关于 【Redis集群的主从复制模型是怎样的?】 面试题,希望对大家有帮助; Redis集群的主从复制模型是怎样的? 为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所…...

高效的二进制列化格式 MessagePack 详解
目录 MessagePack 序列化原理 MessagePack 数据类型及编码方式 MessagePack 序列化与反序列化过程 MessagePack 的优势 应用场景 注意事项 小结 MessagePack (简称 msgPack)是一种高效的二进制序列化格式,可以将各种数据类型ÿ…...

鸿蒙Harmony应用开发—ArkTS-if/else:条件渲染
ArkTS提供了渲染控制的能力。条件渲染可根据应用的不同状态,使用if、else和else if渲染对应状态下的UI内容。 说明: 从API version 9开始,该接口支持在ArkTS卡片中使用。 使用规则 支持if、else和else if语句。 if、else if后跟随的条件语句…...
)
JAVA 100道题(14)
14.使用LinkedList实现一个简单的堆栈(Stack)数据结构。 下面是一个简单的Java程序,使用LinkedList来实现一个堆栈(Stack)数据结构。在这个程序中,我们定义了一个MyStack类,它包含了一些基本的堆…...

STM32+ESP8266水墨屏天气时钟:简易多级菜单(数组查表法)
项目背景 本次的水墨屏幕项目需要做一个多级菜单的显示,所以写出来一起学习,本篇文章不单单适合于水墨屏,像0.96OLED屏幕也适用,区别就是修改显示函数。 设计思路 多级菜单的实现,一般有两种实现的方法 1.通过双向…...

数学建模综合评价模型与决策方法
评价方法主要分为两类,其主要区别在确定权重的方法上 一类是主观赋权法,多次采取综合资讯评分确定权重,如综合指数法,模糊综合评判法,层次评判法,功效系数法等 另一类是客观赋权法,根据各指标…...
window下安装并使用nvm(含卸载node、卸载nvm、全局安装npm)
window下安装并使用nvm(含卸载node、卸载nvm、全局安装npm) 一、卸载node二、安装nvm三、配置路径和下载源四、使用nvm安装node五、nvm常用命令六、卸载nvm七、全局安装npm、cnpm八、遇到的问题 nvm 全名 node.js version management,顾名思义…...
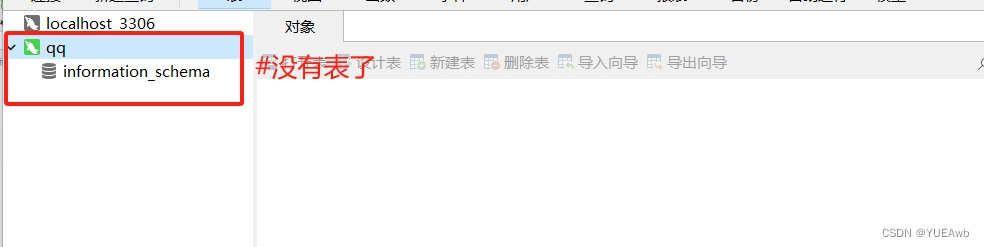
Mysql——基础命令集合
目录 前期准备 先登录数据库 一、管理数据库 1.数据表结构解析 2.常用数据类型 3.适用所有类型的修饰符 4.使用数值型的修饰符 二、SQL语句 1.SQL语言分类 三、Mysql——Create,Show,Describe,Drop 1.创建数据库 2.查看数据库 3.切换数据库 4.创建数据表 5.查看…...

记录一次流相关故障
记录一次流相关故障 1、项目中有个JSON字典文件,通过流的方式加载进来,写了个输入流转字符串的方法,idea开发环境下运行一切正常,打成jar或者war包运行时,只能加载出部分数据,一开始怀疑过运行内存分配过小…...

linux源配置:ubuntu、centos;lspci与lsmod命令区别
1、ubuntu源配置 1)先查电脑版本型号: lsb_release -c2)再编辑源更新,源要与上面型号对应 参考:https://midoq.github.io/2022/05/30/Ubuntu20-04%E6%9B%B4%E6%8D%A2%E5%9B%BD%E5%86%85%E9%95%9C%E5%83%8F%E6%BA%90/ /etc/apt/…...
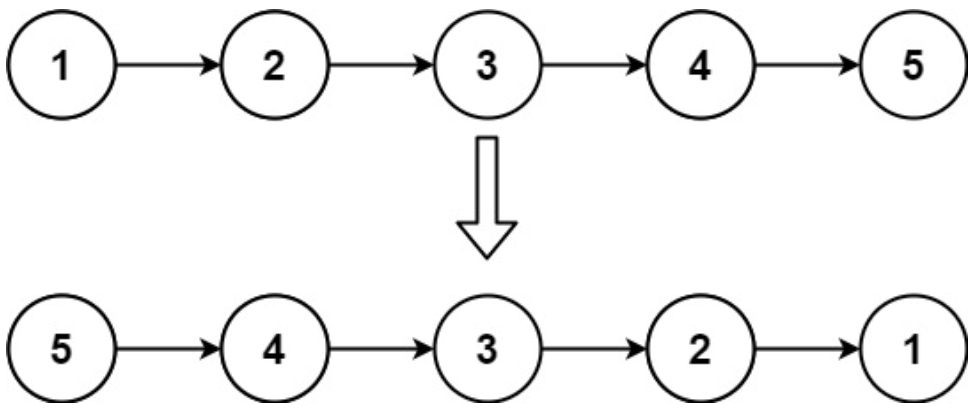
面试算法-88-反转链表
题目 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 示例 1: 输入:head [1,2,3,4,5] 输出:[5,4,3,2,1] 解 class Solution {public ListNode reverseList(ListNode head) {if(head null || hea…...
如何在个人Windows电脑搭建Cloudreve云盘并实现无公网IP远程访问
文章目录 1、前言2、本地网站搭建2.1 环境使用2.2 支持组件选择2.3 网页安装2.4 测试和使用2.5 问题解决 3、本地网页发布3.1 cpolar云端设置3.2 cpolar本地设置 4、公网访问测试5、结语 1、前言 自云存储概念兴起已经有段时间了,各互联网大厂也纷纷加入战局&#…...

一文详解Rust中的字符串
有人可能会说,字符串这么简单还用介绍?但是很多人学习rust受到的第一个暴击就来自这浓眉大眼、看似毫无难度的字符串。 请看下面的例子。 fn main() {let my_name "World!";greet(my_name); }fn greet(name: String) {println!("Hello…...

Mysql中用户密码修改
1、命令行修改 请确保已使用root或其他拥有足够权限的用户登录MySQL,对于MySQL 5.7.6及以上版本或者MariaDB 10.1.20及以上版本。 ALTER USER ‘root’‘localhost’ IDENTIFIED BY ‘root’; 1、使用命令 mysql -uroot -p你的密码 连接到mysql管理工具 2、使用命…...

day14-SpringBoot 原理篇
一、配置优先级 SpringBoot 中支持三种格式的配置文件: 注意事项 虽然 springboot 支持多种格式配置文件,但是在项目开发时,推荐统一使用一种格式的配置 (yml 是主流)。 配置文件优先级排名(从高到低&…...
ChatGPT论文指南|揭秘8大ChatGPT提示词研究技巧提升写作效率【建议收藏】
点击下方▼▼▼▼链接直达AIPaperPass ! AIPaperPass - AI论文写作指导平台 公众号原文▼▼▼▼: ChatGPT论文指南|揭秘8大ChatGPT提示词研究技巧提升写作效率【建议收藏】 目录 1.写作方法 2.方法设计 3.研究结果 4.讨论写作 5.总结结论 6.书…...

P1563 [NOIP2016 提高组] 玩具谜题
题目传送门 这道题实在是一道水题 话不多说,上代码 #include<iostream> #include<cstring> using namespace std; struct a{int io;//in朝里 out朝外 小人的朝向 string name;//小人的名字 int number;//角色编号 }a[100000]; int main(){int n, m…...

AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度
AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度 【免费下载链接】alphafold3 AlphaFold 3 inference pipeline. 项目地址: https://gitcode.com/gh_mirrors/alp/alphafold3 你是否在蛋白质结构预测项目中遇到MSA生成效率低下的瓶颈&#x…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

从多路复用到三维光阵:Arduino驱动8x8x8 LED立方体全解析
1. 项目概述:用Arduino点亮一个三维世界几年前,我第一次在创客展上看到一个8x8x8的LED立方体,那种由数百个光点构成的、在三维空间中流动的动画效果,瞬间就把我吸引住了。它不像普通的平面LED屏,而是真正有“深度”的光…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...