BoostSeacher
前言:
基于Boost库的搜索引擎
为何基于Boost库?
- 从技术上说:这个项目用了很多Boost库的接口
- 从搜索引擎存储内说:存储的内容是Boost库的内容预期效果
预期效果:用户在浏览器输入关键词,浏览器显示相关结果
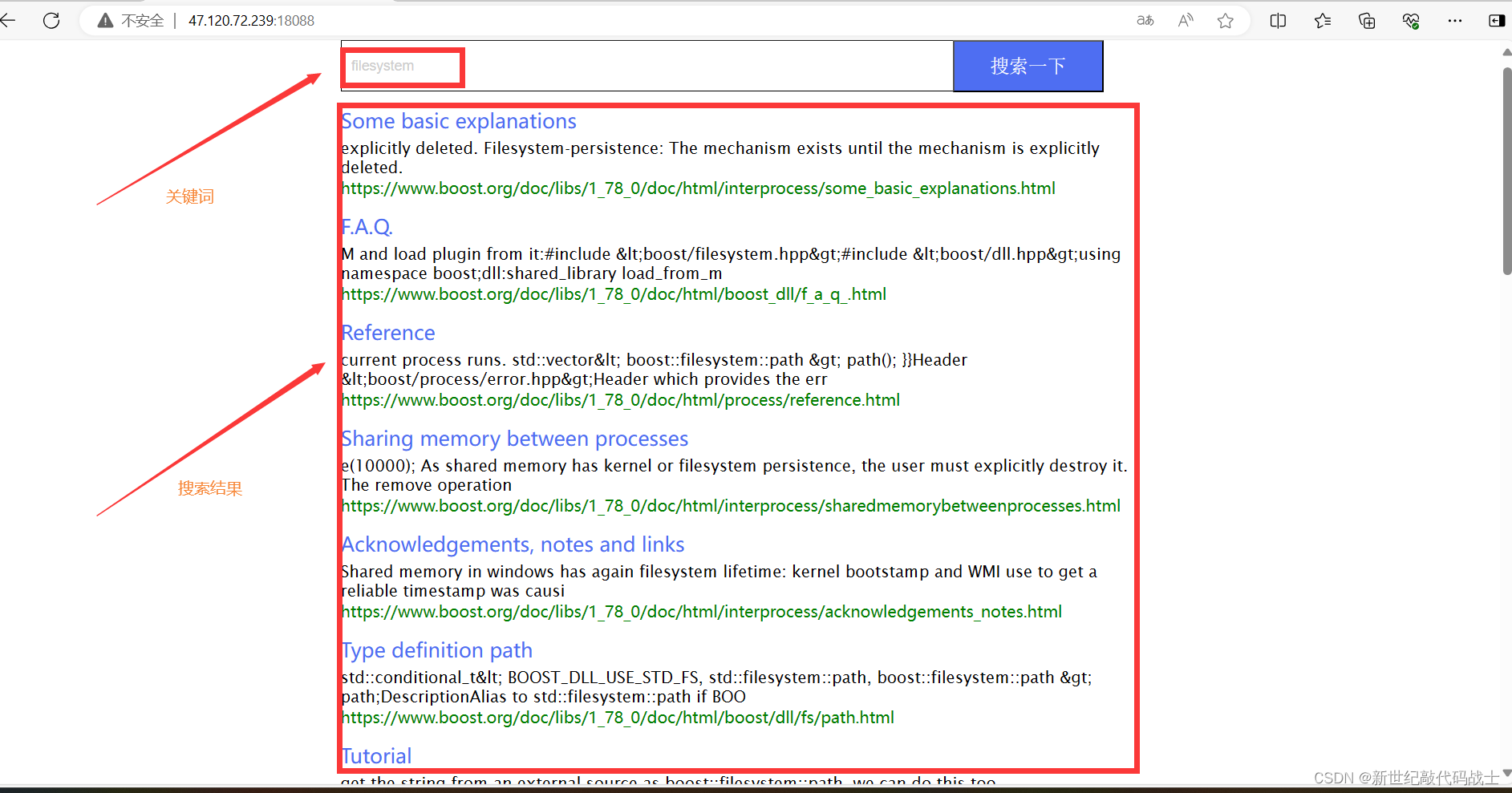
STEP1:导入Boos库数据到服务器
由于我们是将Boost库中的数据作为服务器的数据源,所以我们要把Boost库相关数据拉取到服务器上。
1.导入数据源到服务器
我们选择的是Boost 库中html文件作为数据源
数据源url:Index of main/release/1.78.0/source
boost官网下载文件,导入文件数据到Linux中,使用rz指令

2.解压文件
使用指令 tar xzf 压缩包名称,得到解压后的文件夹

但这个文件夹内,有非常多的内容
我们选择doc路径下html文件夹中的内容作为数据源(里面存放的都是html文件)

建立文件夹data/input,用于存放doc/html下的文件内容
mkdir data/input
cp -r boost_1_78_0/doc/html/* data/input/
数据源准备工作完毕
STEP2:处理数据模块
在处理数据之前,需要明确,我们的数据源现在是存储在文件上的,我们想要使用它,必须把它加载到内存中,所以第一步,我们需要存放他们的文件路径
1.存放文件路径
//src_path="data/input" --存放html文件的路径
//files_list --用于保存文件路径的容器
bool enumfile(const std::string &src_path, std::vector<std::string> *files_list)
{// 引入boost开发库 因为c++对文件系统的支持不是很好// 展开boost的命名空间namespace fs = boost::filesystem;//path是一个用于处理文件操作的类fs::path root_path(src_path);// 判断路径是否存在if (!fs::exists(root_path)){std::cerr << "file not exists" << std::endl;return false;}// 存在 递归遍历 recursive_directory_iterator end == nullptrfs::recursive_directory_iterator end;// 筛选文件for (fs::recursive_directory_iterator iter(root_path); iter != end; iter++){// is_regular_file是否为普通文件 eg:png falseif (!fs::is_regular_file(*iter))continue;//跳过本次循环,筛选下一个文件// 是否为html文件 path.extension()if (iter->path().extension() != ".html")continue;//跳过本次循环,筛选下一个文件// html文件,将文件路径导入到容器中files_list->push_back(iter->path().string());}return true;
}tips:
boost::filesystem::path
filesystem是一个模块,提供了许多与文件处理相关的组件
path是一个类,包含了许多与文件处理相关的接口,
例如,获取文件扩展名-->path::extension()
2.处理文件内容
我们已经获取到了想要的文件路径了,接下来就可以使用文件操作的相关接口,打开文件内容,并对文件内容做相关的处理——提取标题、内容、url
//files_list --存放文件路径的容器
//results --用于存放提取出来的文件内容的容器
//ns_util::fileutil::readfile --读取文件内容的接口
//docinfo_t 定义如下:
typedef struct docinfo
{std::string title;std::string content;std::string url;
} docinfo_t;static bool parsehtml(const std::vector< std::string> &files_list,std::vector<docinfo_t> *results)
{// 解析文件// file--本地文件路径for (const std::string &file : files_list){std::string result;// 1.读取文件信息ns_util::fileutil::readfile(file, &result);docinfo_t doc;// 2.解析文件的titleif (!parsertitle(result, &doc.title)){continue;}// 3.解析文件的contentif (!parsercontent(result, &doc.content)){continue;}// 4.解析文件的urlif (!parserurl(file, &doc.url)){continue;}//解析好的内容存入容器,使用移动构造提高效率 results->push_back(std::move(doc));}return true;
}提取标题
在html文件中,标题是以<title>出现</title>结尾的
举个例子:
以下html代码中,<title></title>间的白字部分就是标题

可以根据上述特性编写代码:
//file --文件内容
//title --提取的标题存放进的容器
static bool parsertitle(const std::string &file, std::string *title)
{size_t begin = file.find("<title>");//寻找title出现的位置if (begin == std::string::npos){return false;}size_t end = file.find("</title>");//寻找</title>出现的位置if (end == std::string::npos){return false;}if (begin > end){return false;}begin += std::string("<title>").size();*title = file.substr(begin, end - begin);//截取标题内容return true;
}
提取content
content是以'>'开始标志的,是以'<'为结尾标志的,<>xxxx<> xxxx就是content
举个例子:下面HTML代码中标出来的白字部分就是content内容

但请注意:不是说只要出现'>',后面就是content,例如
<a name="xpressive.legal"></a><p>'>'后出现的是'<',这是HTML语言的标签
只要'>'出现的不是'<',那就是content
根据上述规则,可以编写代码
//file --存放文件内容的容器
//content --存放提取内容(content)的容器
static bool parsercontent(const std::string &file, std::string *content)
{// 去标签 enum status{Lable,Content};enum status s = Lable;for (const char c : file)//按字符读取文件内容{switch (s){case Lable://是标签if (c == '>')//内容开始的标志s = Content;//切换状态break;case Content:if (c == '<')//不是内容s = Lable;else//是内容{if (c == '\n')//将\n置为空字符,原因后文会提到c == ' ';content->push_back(c);}break;default:break;}}return true;
}提取url
这里更准确的说法,应该是拼接url,按照我们预期的效果,页面应该要显示搜索内容所在的url
我们的数据源皆来自https://www.boost.org/doc/libs/1_78_0/doc/html/
我们的容器中存放的文件路径是data/input/具体的文件名
所以我们要如此拼接:https://www.boost.org/doc/libs/1_78_0/doc/html/+具体的文件名
//file_path --文件路径
//url --用于存放拼接好的url的容器
//src_path --data/input
static bool parserurl(const std::string &file_path, std::string *url)
{std::string url_head = "https://www.boost.org/doc/libs/1_78_0/doc/html";std::string url_tail = file_path.substr(src_path.size());*url = url_head + url_tail;return true;
}3.保存处理好的文件内容
我们已经将每一个文件所对应的内容存放在vector<docinfo_t>中了,接下来需要对一个个的docinfo_t进行格式化处理,并将其写入磁盘,以待使用
为什么要进行格式化处理?方便内容提取,在后文中会有具体体现
如何格式化?以特定字符作为内容内title content url的分隔符,以特定字符作为内容与内容之间的分隔符
将vector<docinfo_t>中的内容作格式化处理
title\3content\3url\n-->一个完整的内容
写到data/raw_html/raw.txt
//results --存放结构体数据的容器
//output --写入磁盘的文件路径
bool savehtml(const std::vector<docinfo_t> &results, const std::string &output)
{
#define sep '\3' // title\3content\3url\n// 按照二进制方式写入std::ofstream out(output, std::ios::out | std::ios::binary);if (!out.is_open()){std::cerr << "open " << output << "failed!" << std::endl;return false;}for (const docinfo_t &item : results)//读取每一个结构体信息{std::string out_string;out_string = item.title;out_string += sep; //title\3out_string += item.content; //title\3contentout_string += sep; //title\3content\3out_string += item.url; //title\3content\3urlout_string += '\n'; //title\3content\3url\nout.write(out_string.c_str(), out_string.size());}out.close();return true;
}STEP3:构建索引模块
何为索引?即搜索引擎的查找规则
举个例子:当我们在浏览器输入“hello world”时,浏览器会显示大量页面,从hello world 到 页面,使这一过程发生的就是索引
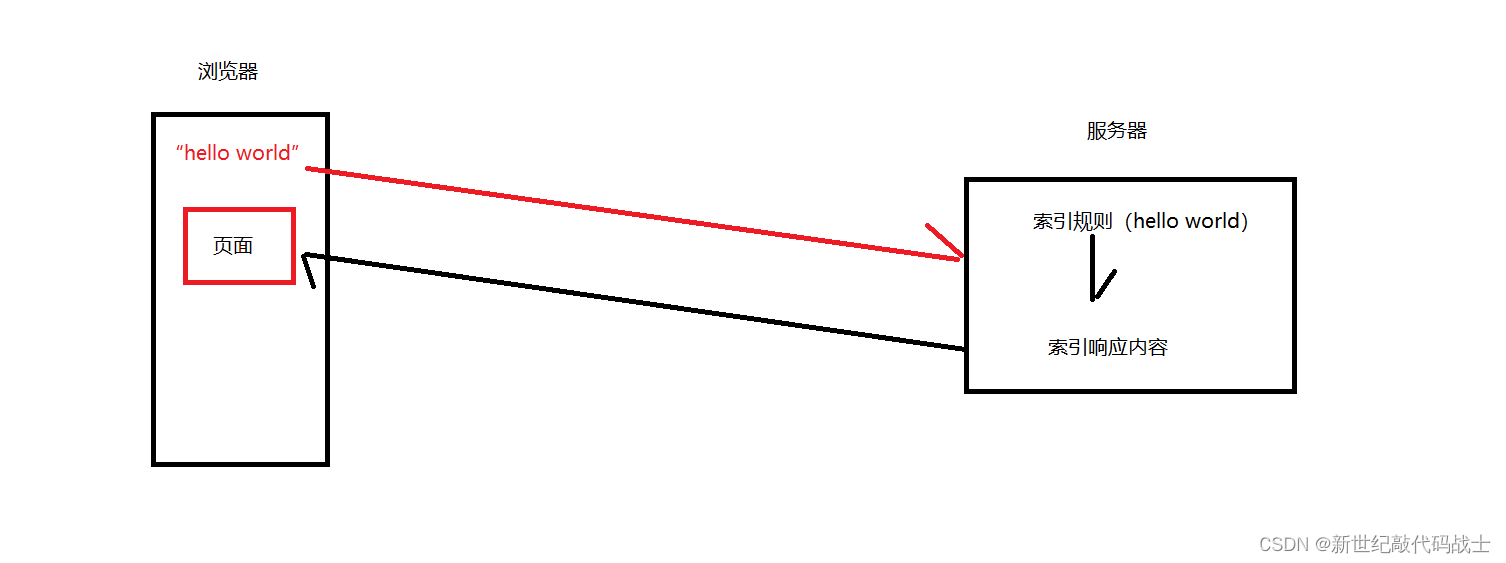
索引规则有如下2种:
- 正排索引:根据文档id找到文档内容,所以它的底层是vector<docinfo_t>,下标就是文档id,里面存的就是文档内容
- 倒排索引:根据关键词找到文档id 并通过文档id找到文档内容,他是根据关键词在文章中出现的权重为基础,构建索引的
我们要对谁构建索引?存在磁盘上的格式化的数据源
构建正排索引
//line --存放文件内容的容器
//out --存放切分结果的容器
//forwardindex --正排索引 类型vector<docinfo>struct docinfo{std::string title;std::string content;std::string url;uint64_t docid;};
//...文件读取操作
docinfo *bulidforwardindex(const std::string &line){// 对line进行 title content url 的分词 std::vector<std::string> out;const std::string sep = "\3"; //以'\3'为分割标志ns_util::stringutil::split(line, &out, sep); //调用切分字符的接口if(out.size()!=3){return nullptr;}docinfo doc;doc.title = out[0];doc.content = out[1];doc.url = out[2];doc.docid = forwardindex.size();forwardindex.push_back(std::move(doc));//std::cout<<(forwardindex[forwardindex.size()-1].url)<<std::endl;//表明正派建立成功return &forwardindex.back(); //返回构建好的一组数据,供建立倒排索引使用}构建倒排索引
//wordmap --unordered_map<string,wordcnt>类型 用于存储被划分词在标题与内容中出现的次数
//invertedindex --unordered_map<string,invertedlist>类型 用于表示关键词与网页间的对应关系
//ilist --invertedlist类型,typedef vector<invertedelem> invertedlist
//item --invertedelem类型struct invertedelem{uint64_t docid;std::string word;int weight;invertedelem() : weight(0){}};
bool buildinvertedindex(const docinfo &doc){struct wordcnt //用于计算被划分的词在标题/内容出现的次数{int titlecnt; //用于计算被划分的标题词在标题中出现的次数 int contentcnt; //用于计算被划分的内容词在内容中出现的次数wordcnt() : titlecnt(0), contentcnt(0){}};std::string title = doc.title; //取出完整的标题std::string content = doc.content; //取出完整的内容// jieba分词--titlestd::vector<std::string> titlecut;ns_util::jiebautil::cutstring(title, &titlecut);// 拿到了jieba为我们分好的词 --titlestd::unordered_map<std::string, wordcnt> wordmap; for (auto &s : titlecut) //遍历被划分的标题词{boost::to_lower(s); //不区分大小写wordmap[s].titlecnt++; //记录标题词在标题出现次数}// jieba分词--contentstd::vector<std::string> contentcut;ns_util::jiebautil::cutstring(content, &contentcut);for (auto &s : contentcut) //遍历被划分的内容词{boost::to_lower(s);wordmap[s].contentcnt++; //记录内容词在内容出现次数}// word -> id word weight
#define X 10
#define Y 1//构建倒排索引 被划分的词才是主角for (auto &wmap : wordmap){invertedelem item;item.docid = doc.docid;item.word = wmap.first;//构建各个词在此"网页"中的权重 --标题:10/次 内容:1/次item.weight = X * wmap.second.titlecnt + Y * wmap.second.contentcnt; //构建被划分的词与"网页"的关系invertedlist &ilist = invertedindex[wmap.first];// std::cout<<"invert success"<<std::endl;//表明创建倒排成功ilist.push_back(std::move(item));}return true;}现在,forwardindex 与invertedlist都已经按照各自的索引规则存储好了数据,上层想要调用使用这里面的数据,还需要我们提供两个接口
//正排索引的调用接口
//docid --想要查找的内容对应的id
docinfo *getforwardindex(uint64_t docid){if (docid >= forwardindex.size()){std::cerr << "no expected doc" << std::endl;return nullptr;}return &forwardindex[docid];}//倒排索引的调用接口
//word: 以word关键字为key值对相应内容做检索
invertedlist *getinvertedlist(const std::string &word){auto iter = invertedindex.find(word);if (invertedindex.end() == iter){return nullptr;}return &(iter->second);}
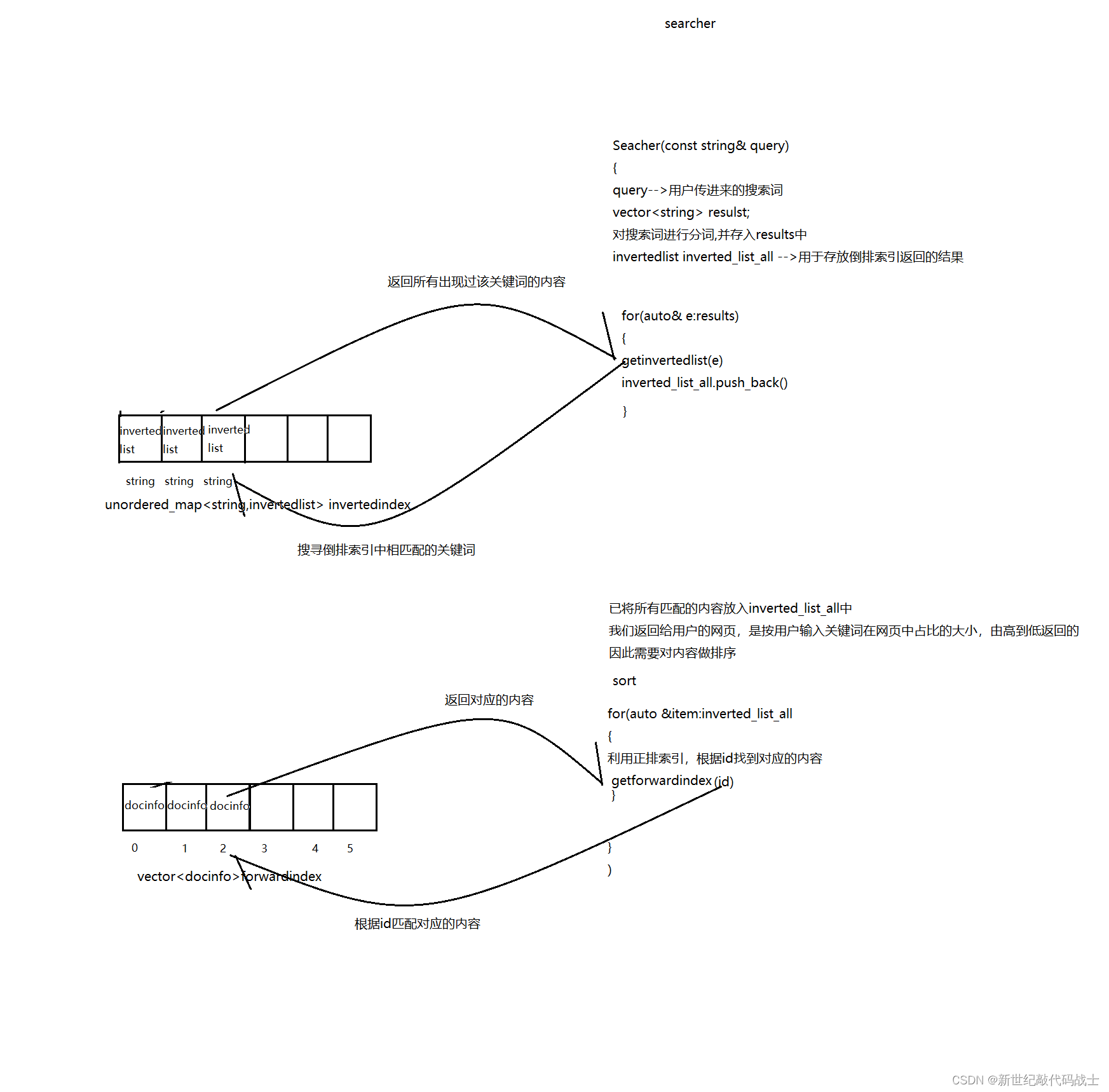
STEP4:编写服务端模块
服务端的作用是:接受客户端传过来的关键词,并对关键词进行分词,利用构建好的索引,并返回相关页面
工作流程:
InitSearcher --初始化工作
创建单例,构建索引(文件-->内存)
//Index --Index对象void initsearcher(){Index = ns_index::index::getinstance(); //获取单例if(Index==nullptr){std::cerr<<"getinstance fail"<<std::endl;exit(1);}std::cout<<"get instance success"<<std::endl; Index->buildindex(input); //创建索引}Search --搜索工作
对用户的关键词进行分词,然后查倒排,将结果存放到inverted_list_all当中去
对查找结果按照权重进行排序
根据文档id,查询相关结果
为了达到像真实网页一般显示,我们要对内容做摘要
利用 Json对结果进行序列化,返回给客户端
//query --用户传进来的关键词
//jsonstring --要返回的结果
void search(const std::string &query, std::string *jsonstring){// 对query进行分词std::vector< std::string> cutwords;ns_util::jiebautil::cutstring(query, &cutwords);ns_index::invertedlist inverted_list_all;for (auto word : cutwords){boost::to_lower(word);ns_index::invertedlist *inverted_list;inverted_list = Index->getinvertedlist(word);if (inverted_list == nullptr){std::cerr<<"get inverted_list err"<<std::endl;continue;}inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end());}// 按照相关性对内容进行排序std::sort(inverted_list_all.begin(), inverted_list_all.end(), [](const ns_index::invertedelem &e1, const ns_index::invertedelem &e2){ return e1.weight > e2.weight; });//利用Json对结果进行反序列化,并将结果返回给上层 Json::Value root;for (auto &item : inverted_list_all){ns_index::docinfo *doc = Index->getforwardindex(item.docid);if (nullptr == doc){std::cerr<<"get doc fail"<<std::endl;continue;}Json::Value elem;elem["title"] = doc->title;elem["desc"] = getdesc(doc->content, item.word); //对内容做摘要elem["url"] = doc->url;//here~~!!//for debugelem["weight"]=item.weight;elem["docid"]=(int)doc->docid;root.append(elem);}Json::StyledWriter writer;*jsonstring = writer.write(root);}std:: string getdesc(const std:: string &content, const std::string &word){int prev_step = 50;int next_step = 100;//int pos = content.find(word);//大小写问题 split->Splitauto iter=std::search(content.begin(),content.end(),word.begin(),word.end(),[](int x,int y){return std::tolower(x)==std::tolower(y);});if(iter==content.end()){return "none1";}int pos=std::distance(content.begin(),iter);int start = 0;int end = content.size() - 1;if (pos - prev_step > start){start = pos - prev_step;}if (pos + next_step < end){end = pos + next_step;}if (start > end)return "none2";std:: string desc = content.substr(start, end - start);return desc;}
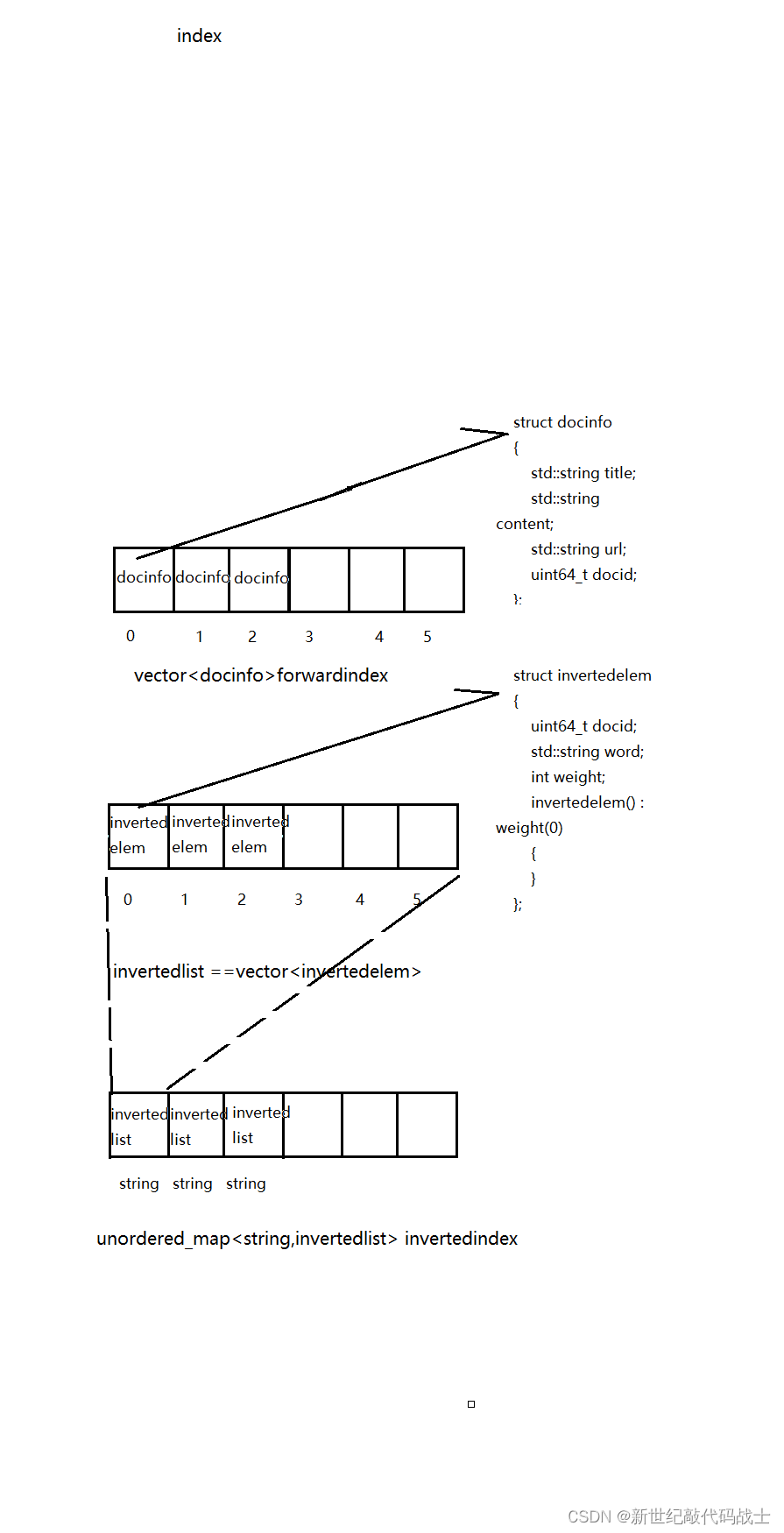
这里的服务端模块,其实就是大量的在调用索引模块的接口,服务端是上层,索引模块是下层
为方便理解,下图简单勾勒出了二者关系
server-index关系图:
STEP5:编写http服务模块
http服务模块,位于应用层,是整个服务器的最上层,具体工作是:启动服务器,完成socket编程(创建套接字、绑定套接字、监听套接字、等待连接),接受客户端请求,返回服务器结果。
#include "searcher.hpp"
#include "cpphttplib/httplib.h"
const std::string root_path = "./wwwroot";int main()
{ns_searcher::searcher sear;sear.initsearcher();httplib::Server svr;svr.set_base_dir(root_path.c_str());svr.Get("/s", [&sear](const httplib::Request &req, httplib::Response &rsp){if (!req.has_param("word")){rsp.set_content("必须要有搜索关键字!", "text/plain; charset=utf-8");return;}std::string word = req.get_param_value("word"); std::string json_string;sear.search(word, &json_string);rsp.set_content(json_string, "application/json");});svr.listen("0.0.0.0", 18088);return 0;
}STEP6:部署日志到服务器中
部署日志信息是为了监控服务器状态,方便对服务端的管理。
相关文章:
BoostSeacher
前言: 基于Boost库的搜索引擎 为何基于Boost库? 从技术上说:这个项目用了很多Boost库的接口从搜索引擎存储内说:存储的内容是Boost库的内容预期效果 预期效果:用户在浏览器输入关键词,浏览器显示相关结果 STEP1&#x…...
)
我的算法刷题笔记(3.18-3.22)
我的算法刷题笔记(3.18-3.22) 1. 螺旋矩阵1. total是总共走的步数2. int[][] directions {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};方位3. visited[row][column] true;用于判断是否走完一圈 2. 生命游戏1. 使用额外的状态22. 再复制一份数组 3. 旋转图像观…...

初探Ruby编程语言
文章目录 引言一、Ruby简史二、Ruby特性三、安装Ruby四、命令行执行Ruby五、Ruby的编程模型六、案例演示结语 引言 大家好,今天我们将一起探索一门历史悠久、充满魅力的编程语言——Ruby。Ruby是由松本行弘(Yukihiro Matsumoto)于1993年发明…...

深圳MES系统如何提高生产效率
深圳MES系统可以通过多种方式提高生产效率,具体如下: 实时监控和分析:MES系统可以实时收集并分析生产数据,帮助企业及时了解生产状况,发现问题并迅速解决,避免问题扩大化。这种实时监控和分析功能可以显著…...

QT常见Layout布局器使用
布局简介 为什么要布局?通过布局拖动不影响鼠标拖动窗口的效果等优点.QT设计器布局比较固定,不方便后期修改和维护;在Qt里面布局分为四个大类 : 盒子布局:QBoxLayout 网格布局:QGridLayout 表单布局&am…...
Elasticsearch8 - Docker安装Elasticsearch8.12.2
前言 最近在学习 ES,所以需要在服务器上装一个单节点的 ES 服务器环境:centos 7.9 安装 下载镜像 目前最新版本是 8.12.2 docker pull docker.elastic.co/elasticsearch/elasticsearch:8.12.2创建配置 新增配置文件 elasticsearch.yml http.host…...

还在为不知道怎么学习网络安全而烦恼吗?这篇文带你从入门级开始学习网络安全—认识网络安全
随着网络安全被列为国家安全战略的一部分,这个曾经细分的领域发展提速了不少,除了一些传统安全厂商以外,一些互联网大厂也都纷纷加码了在这一块的投入,随之而来的吸引了越来越多的新鲜血液不断涌入。 不同于Java、C/C等后端开发岗…...
DFS基础——迷宫
迷宫 配套视频讲解 关于dfs和bfs的区别讲解。 对于上图,假设我们要找从1到5的最短路,那么我们用dfs去找,并且按照编号从大到小的顺序去找,首先找到的路径如下, 从节点1出发,我们发现节点2可以走ÿ…...

iOS开发进阶(九):OC混合开发嵌套H5应用并互相通信
文章目录 一、前言二、嵌套H5应用并实现双方通信2.1 WKWebView 与JS 原生交互2.1.1 H5页面嵌套2.1.2 常用代理方法2.1.3 OC调用JS方法2.1.4 JS调用OC方法 2.2 JSCore 实现原生与H5交互2.2.1 OC调用H5方法并传参2.2.2 H5给OC传参 2.3 UIWebView的基本用法2.3.1 H5页面嵌套2.3.2 …...

新人应该从哪几个方面掌握大数据测试?
什么是大数据 大数据是指无法在一定时间范围内用传统的计算机技术进行处理的海量数据集。 对于大数据的测试则需要不同的工具、技术、框架来进行处理。 大数据的体量大、多样化和高速处理所涉及的数据生成、存储、检索和分析使得大数据工程师需要掌握极其高的技术功底。 需要你…...

linux debian运行pip报错ssl tsl module in Python is not available
写在前面 ① 在debian 8上升级了Python 3.8.5 ② 升级了openssl 1.1.1 问题描述 在运行pip命令时提示如下错误 pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available.尝试了大神推荐的用如下方法重新编译安装python,发…...

宝塔设置限制ip后,ip改了之后 ,登陆不上了
前言 今天作死,在宝塔面板设置界面,将访问面板的ip地址限制成只有自己电脑的ip才能访问,修改之后直接人傻了,“403 forbidden”。吓得我直接网上一通搜索,还好,解决方法非常简单。 解决方法 打开ssh客户…...

解锁新功能,Dynadot现支持BITPAY平台虚拟货币
Dynadot现已支持虚拟货币付款!借助与BitPay平台的合作,Dynadot为您提供了多种安全的虚拟货币选择。我们深知每位客户都有自己偏好的支付方式,因此我们努力扩大了支付方式范围。如果您对这一新的支付方式感兴趣,在结账时您可以尝试…...

Android下的Touch事件分发详解
文章目录 一、事件传递路径二、触摸事件的三个关键方法2.1 dispatchTouchEvent(MotionEvent ev)2.2 onInterceptTouchEvent(MotionEvent ev)2.3 onTouchEvent(MotionEvent event) 三、ViewGroup中的dispatchTouchEvent实现四、总结 在Android系统中,触摸事件的分发和…...

uniapp的配置文件、入口文件、主组件、页面管理部分
pages.json 配置文件,全局页面路径配置,应用的状态栏、导航条、标题、窗口背景色设置等 main.js 入口文件,主要作用是初始化vue实例、定义全局组件、使用需要的插件如 vuex,注意uniapp无法使用vue-router,路由须在pag…...
B端设计:如何让UI组件库成为助力,而不是阻力。
首发2023-09-24 15:42贝格前端工场 Hi,我是大千UI工场,网上的UI组件库琳琅满目,比如elementUI、antdesign、iview等等,甚至很多前端框架,也出了很多UI组件,如若依、Layui、bootstrap等等,作为U…...
敏捷开发最佳实践:学习与改进维度实践案例之会诊式培养敏捷教练
自组织团队能够定期反思并采取针对性行动来提升人效,但2022年的敏捷调研发现,70%的中国企业在学习和改进方面仍停留在团队级。本节实践案例将分享“会诊式培养敏捷教练”的具体做法,突出了敏捷以人为本的学习和改进,强调了通过人员…...
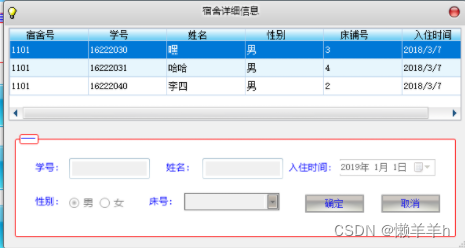
C#宿舍信息管理系统
简介 功能 1.发布公告 2.地理信息与天气信息的弹窗 3.学生信息的增删改查 4.宿舍信息的增删改查 5.管理员信息的增删改查 6.学生对宿舍物品的报修与核实 7.学生提交请假与销假 8.管理员对保修的审批 9.管理员对请假的审批 技术 1.采用C#\Winform开发的C\S系统 2.采用MD5对数据…...

测试环境搭建整套大数据系统(十三:设置开机自启动)
一:编写程序启动命令脚本 vim /root/start.sh二:编写启动脚本 cd /etc/systemd/system vim start.service[Unit] DescriptionStart My Server Afternetwork.target[Service] Typeforking ExecStart/root/start start TimeoutSec0 RemainafterExityes G…...

算法练习第三十二天|122.买卖股票的最佳时机II、55. 跳跃游戏、45.跳跃游戏II
45. 跳跃游戏 II 55. 跳跃游戏 122.买卖股票的最佳时机II 122.买卖股票的最佳时机II class Solution {public int maxProfit(int[] prices) {int result 0;for(int i 1;i<prices.length;i){result Math.max(prices[i] - prices[i-1],0);}return result;} }跳跃游戏 cla…...

Godot PCK解包原理与专业逆向实践指南
1. 这不是“解压软件”,而是Godot游戏逆向工程的第一把手术刀你刚下载了一款用Godot引擎开发的独立游戏,想研究它的UI动效逻辑,或者复刻一段粒子特效,又或者只是单纯好奇——那个让你反复通关三次的像素风过场动画,图层…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

电信运营商每月处理海量工单,如何不再出错?基于AI Agent的端到端自动化解决方案
在2026年的电信行业,海量工单处理已不再仅仅是效率问题,而是合规与生存的底线。随着2026年5月20日《电信和互联网服务 基础电信企业网上营业厅服务规范》国家标准的正式实施,监管层对“信息透明、流程闭环、计费精准”的要求达到了前所未有的…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

基于IRS2092的200W D类功放设计:从PWM原理到保护电路实战
1. 项目概述与核心思路折腾音响功放,从经典的AB类玩到D类,感觉就像是从燃油车换到了电动车,动力响应和效率完全是两个维度。这次要聊的这块“200W Class-D Audio Power Amplifier [150115]”单板功放,就是一个非常典型的D类功放设…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...

用图神经网络做缺陷定位,准确率比传统方法高出30%
在现代软件工程的复杂迷宫中,缺陷定位始终是测试团队面临的核心挑战。想象这样一个场景:一个电商系统在特定压力条件下偶发订单丢失,日志中只留下泛泛的超时错误,问题可能深藏在上百个微服务的调用链、分布式事务的竞态条件或某个…...

抖音内容批量下载实战:从零开始构建个人视频资料库
抖音内容批量下载实战:从零开始构建个人视频资料库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...