深度学习基础知识
本文内容来自https://zhuanlan.zhihu.com/p/106763782
此文章是用于学习上述链接,方便自己理解的笔记
1.深度学习的网络结构
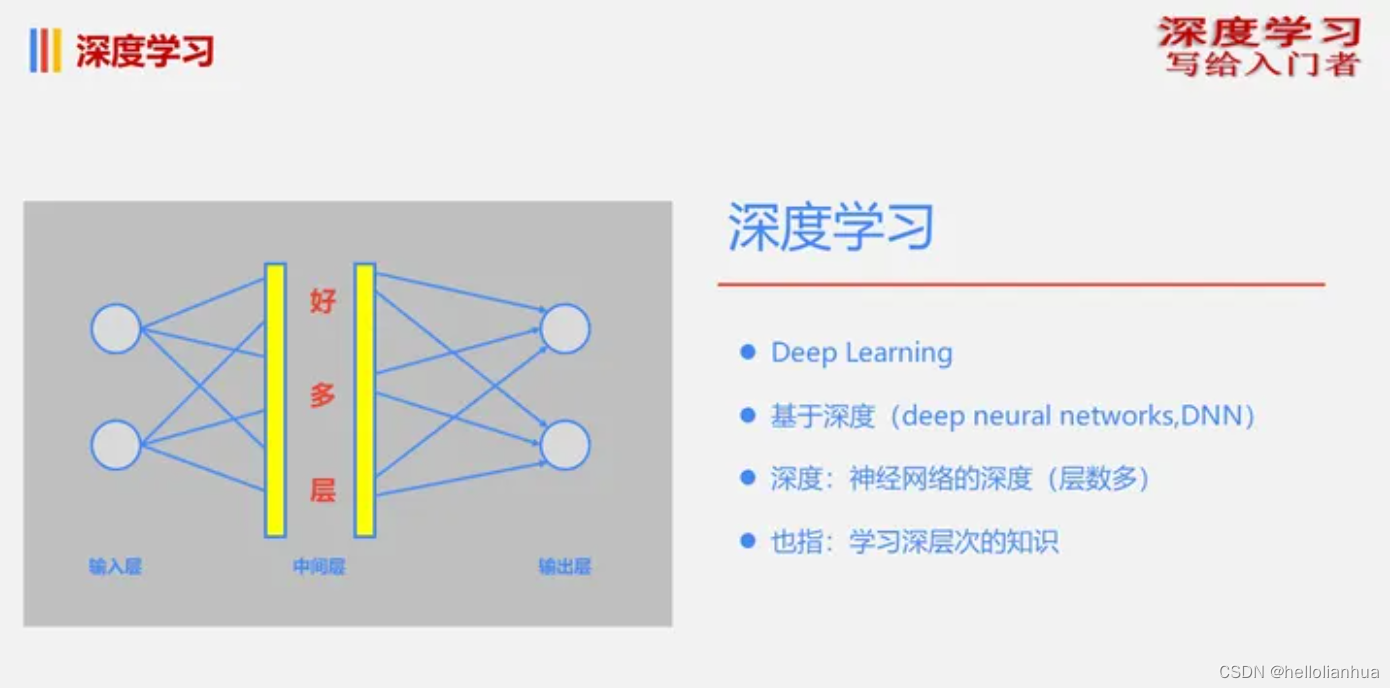
深度学习是神经网络的一种特殊形式,典型的神经网络如下图所示。

- 神经元:表示输入、中间数值、输出数值点。例如:在上述图中的一个个小圆圈,分别表示不同的神经元。
- 权重:神经元传导时,要乘以一个系数,这个系数叫做权重值。例如:从上图中输入层的神经元要传导到中间层的神经元,输入层的神经元要乘以一个系数后到达中间层,即:中间层=输入层*权重。
不同的人对层的定义是不一样,
- 如果将具有权重的对象称为“层”,那么当前网络就是2层的
- 如果将有神经元的结构称为“层”,那么当前网络就是3层的
2.深度学习
将具有多个中间层的神经网络,称之为“深度学习网络”。深度学习的本意就是“具有很深层次的网络”,也就是说“有很多层的网络”。
深度学习强大的原因主要是基于以下两个方面:
- 1。在深度学习中,不需要手动提取特征,系统自动提取了非常多的特征、特征组合,并找出有用的特征。
- 2。处理线性不可分问题。简单说,就是通过解决一个又一个的简单问题,达到解决复杂问题的目的。例如,判断一张照片上的对象,不断地判断:“它是动物吗?它是四条腿吗?它会喵喵叫吗?”等等这样的问题,能够得到照片上的对象是一只猫,还是一只狗。也类似于,我们拨打“10086”,最后它居然帮我们解决了我们的各种需求。
以图像识别为例,假设我们要识别一幅图像内的语义信息。
可能是通过4层(尽管可以叫它为5层、6层)网络实现,具体为:
- 第1层:提取图像的最基础的底层特征,包括纹理、边缘、色彩等。
- 第2层:将第1层的特征排列组合,并找到有用的组合信息。此时会找到曲线、轮廓灯特征。
- 第3层:对第2层的特征排列组合,并找到有用的组合信息。此时,会找到高级特征,例如眼睛、鼻子、嘴等等。
- 第4层:对第3层的特征进行排列组合,并找到有用的组合信息。此时,会找到有用的语义信息,例如打电话、奔跑等语义信息。
该过程的简单示意如下图所示。
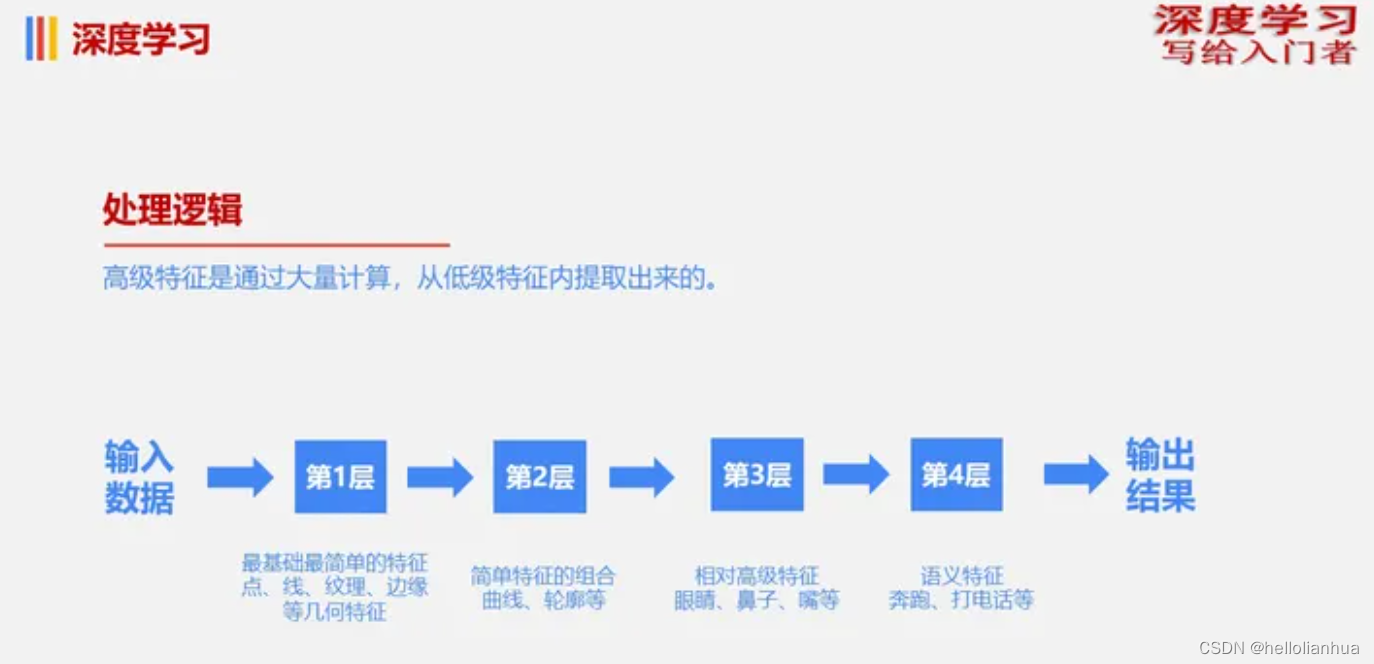
深度学习的处理逻辑就是:首先提取低级特征,然后对低级特征不断地在更高的级别上进行排列组合,并寻找组合后的有用信息。
3.神经网络基本结构
神经网络的基本结构分为四大类: 标准网络、循环网络、卷积网络和自动编码器。
此部分学习11种主要神经网络结构图解 - 知乎 (zhihu.com)
3.1 标准网络
3.1.1 感知器
感知器是所有神经网络中最基本的,也是更复杂的神经网络的基本组成部分。 它只连接一个输入神经元和一个输出神经元。

3.1.2 前馈网络
前馈网络是感知器的集合,其中有三种基本类型的层: 输入层、隐藏层和输出层。 在每个连接过程中,来自前一层的信号被乘以一个权重,增加一个偏置,然后通过一个激活函数。 前馈网络使用反向传播迭代更新参数,直到达到理想的性能。

3.1.3 残差网络(Residual Networks/ResNet)
深层前馈神经网络的一个问题是所谓的梯度消失,即当网络太深时,有用的信息无法在整个网络中反向传播。 当更新参数的信号通过网络传播时,它会逐渐减少,直到网络前面部分的权重不再改变或者根本不再使用。
为了解决这个问题,残差网络使用跳过连接实现信号跨层传播。 通过使用这种不易受到影响的连接来减少梯度消失问题。 随着时间的推移,通过学习特征空间,网络学会了重建跳过的层,但训练更有效,因为它的梯度不容易消失和需要探索更少的特征空间。

3.2 循环网络(Recurrent Neural Network ,RNN)
循环神经网络是一种特殊类型的网络,它包含环和自重复,因此被称为“循环”。由于允许信息存储在网络中,RNNs 使用以前训练中的推理来对即将到来的事件做出更好、更明智的决定。 为了做到这一点,它使用以前的预测作为“上下文信号”。 由于其性质,RNNs 通常用于处理顺序任务,如逐字生成文本或预测时间序列数据(例如股票价格)。 它们还可以处理任意大小的输入。

3.3 卷积网络(Convolutional Neural Network, CNN)
图像具有非常高的维数,因此训练一个标准的前馈网络来识别图像将需要成千上万的输入神经元,除了显而易见的高计算量,还可能导致许多与神经网络中的维数灾难相关的问题。 卷积神经网络提供了一个解决方案,利用卷积和池化层,来降低图像的维度。 由于卷积层是可训练的,但参数明显少于标准的隐藏层,它能够突出图像的重要部分,并向前传播每个重要部分。 传统的CNNs中,最后几层是隐藏层,用来处理“压缩的图像信息”。卷积神经网络在基于图像的任务上表现良好,例如将图像分类为狗或猫。

3.4 自动编码器(Autoencoder)
自动编码器的基本思想是将原始的高维数据“压缩”成高信息量的低维数据,然后将压缩后的数据投影到一个新的空间中。 自动编码器有许多应用,包括降维、图像压缩、数据去噪、特征提取、图像生成和推荐系统。 它既可以是无监督的方法,也可以是有监督的,可以得到对数据本质的洞见。

隐藏的神经元可以替换为卷积层,以便处理图像。
4.激活函数
学习了:https://zhuanlan.zhihu.com/p/678231997 、深度学习笔记:如何理解激活函数?(附常用激活函数) - 知乎 (zhihu.com)和神经网络的基本结构 - 知乎 (zhihu.com)
由于不同的神经元有不同的激活值,如果一个神经元的激活值过大,例如一亿。那么会导致最后输出的结果过于离谱。所以我们需要把太大的数字调小一点,太小的数字调高一点,让数据更加的靠谱。做到这一步是通过激活函数来实现的。
因为神经网络中每一层的输入输出都是一个线性求和的过程,下一层的输出只是承接了上一层输入函数的线性变换,所以如果没有激活函数,那么无论你构造的神经网络多么复杂,有多少层,最后的输出都是输入的线性组合,纯粹的线性组合并不能够解决更为复杂的问题。而引入激活函数之后,我们会发现常见的激活函数都是非线性的,因此也会给神经元引入非线性元素,使得神经网络可以逼近其他的任何非线性函数,这样可以使得神经网络应用到更多非线性模型中。
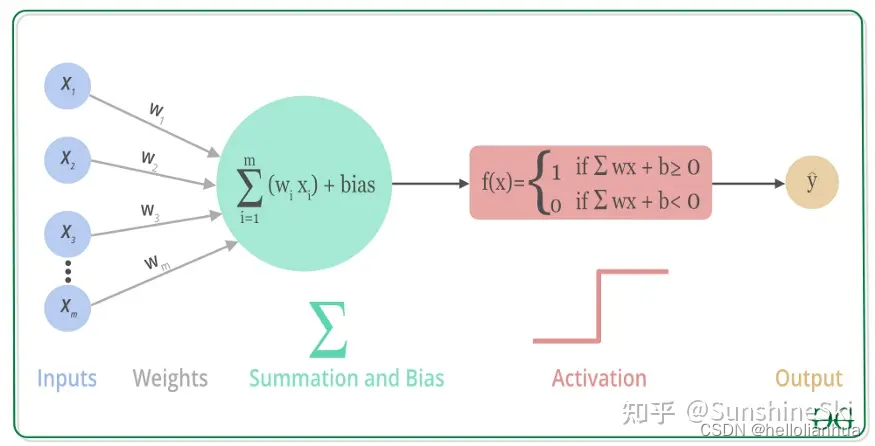
激活函数可以分为线性激活函数(线性方程控制输入到输出的映射,如f(x)=x等)以及非线性激活函数(非线性方程控制输入到输出的映射,比如Sigmoid、Tanh、ReLU、LReLU、PReLU、Swish 等) 。
- Sigmoid 函数:能将输入值压缩到0和1之间,常用于二分类问题的输出层。
- Tanh 函数:与Sigmoid类似,但输出范围是-1到1,常用于二分类问题的输出层。
- ReLU 函数:当输入值大于0时,输出值等于输入值;当输入值小于等于0时,输出值为0。ReLU是目前最常用的激活函数之一,因为它能够缓解梯度消失问题。
- Leaky ReLU 函数:在输入值小于0时,输出值为0.01乘以输入值;在输入值大于0时,输出值等于输入值。这种激活函数可以解决ReLU激活函数在负数区域的问题。
- PReLU 函数:在输入值小于0时,输出值为0.2乘以输入值的绝对值;在输入值大于0时,输出值等于输入值。这种激活函数也可以解决ReLU激活函数在负数区域的问题。
**注:Sigmoid、Tanh、ReLU、LReLU、PReLU、Swish都是非线性激活函数,它们都在人工神经网络中起到关键的作用。非线性激活函数如Sigmoid和Tanh可以将输入的线性组合转化为非线性输出。
Sigmoid函数的公式为S(x)=1/(1+exp(-x)),它将输入的每个值压缩到0和1之间。但是,当输入值远离0时,Sigmoid函数的梯度将接近于0,这可能会导致在训练过程中出现梯度消失的问题。
Tanh函数与Sigmoid函数类似,但它是零中心的,也就是说它的输出范围在-1到1之间。然而,Tanh函数也存在饱和问题。
ReLU(Rectified Linear Unit)函数对正数原样输出,负数直接置零。它在正数区域不饱和,在负数区域硬饱和。ReLU函数计算上比Sigmoid或者Tanh更省计算量,因为不用exp,因而收敛较快。能够帮助解决sigmoid随着层数的增加梯度衰减现象。但是还是非zero-centered。
LReLU(Leaky ReLU)是ReLU的变体,区别在于它不是将所有负值设为零,而是引入一个小的正数斜率。PReLU(Parametric ReLU)是另一个ReLU的变体,其参数化负数部分允许网络学习负数斜率的最佳值。
Swish是一种自门控激活函数,其计算公式为f(x) = x / ( 1 + e^(-x) )。
以上激活函数的具体讲解请查看深度学习笔记:如何理解激活函数?(附常用激活函数) - 知乎 (zhihu.com)
5.损失函数
损失函数用来计算具体正确的判断距离。越小说明越接近真实判断。
例如:
假设A是身高,B是体重,C是男女。性别1=男,0=女。
假设小明的身高是2米,体重是20kg。小红的是1米,10千克。它们和C的权重都是1。
那么没有经过标准化处理的C为:
C(小明)=2*1+20*1=22,C(小红)=1*1+10*1=11。
假设经过标准化处理的C为
C(小明)=0.99,C(小红)=0.8。
那么系统对小明的判断是正确的,因为0.99约等于1,但是对于小红的判断是错误的,因为小红是女生,这个值应该是越接近0越好。我们直接用减法确定预测数据和真实数据的距离来定义损失函数。那么这个时候损失函数Loss=|(1-0.9)+(0-0.8)|=0.9。前面说了这个数字越小越好。这个时候是0.9。
这个时候应该怎么办呢,我们回头改变一下权重和偏置,把身高的权重改成10,把偏置改成(-20),看看会发生什么。那么没有经过标准化处理的C为:
C(小明)=2*10(身高权重)+20-20(偏置)=20
C(小红)=1*10+10-20=0
好了,这下不用经过标准化处理也知道,小明的C值将会变成1,而小红会变成0。这下就成功完成了分类。(为了弄懂,不要管Sigmoid的真实计算结果)
这个时候:
Loss=Loss=|(1-1)+(0-0)|=0,损失函数降为0,那么这个模型就是一个完全拟合的模型。
损失函数在模型训练阶段发挥着重要的作用。每个批次的训练数据送入模型后,通过前向传播输出预测值,然后损失函数会计算出预测值和真实值之间的差异值,也就是损失值。得到损失值之后,模型通过反向传播去更新各个参数,以降低真实值与预测值之间的损失,使得模型生成的预测值更接近真实值,从而达到学习的目的。
关于如何选择损失函数,需要考虑以下因素:
- 回归问题:均方误差、平均绝对误差等。
- 分类问题:交叉熵、对数损失等。
- 排名问题:平均精度差、有序列表挖掘的损失等 。
损失函数详解:
六个深度学习常用损失函数总览:基本形式、原理、特点-腾讯云开发者社区-腾讯云 (tencent.com)
Pytorch学习之十九种损失函数_pytorch损失函数-CSDN博客
6.反向传播算法的原理和应用
机器学习笔记丨神经网络的反向传播原理及过程(图文并茂+浅显易懂)_神经网络反向传播原理-CSDN博客
反向传播算法(Backpropagation,简称BP算法)是“误差反向传播”的简称,是适合于多层神经元网络的一种学习算法,它建立在梯度下降法的基础上。
BP算法的学习过程由正向传播过程和反向传播过程组成。
- 在正向传播过程中,输入信息通过输入层经隐含层,逐层处理并传向输出层。如果预测值和真实值不一样,则取输出与期望的误差的平方和作为损失函数(损失函数有很多,这是其中一种)。
- 将正向传播中的损失函数传入反向传播过程,逐层求出损失函数对各神经元权重的偏导数,作为目标函数对权重的梯度。根据这个计算出来的梯度来修改权重,网络的学习在权重修改过程中完成。误差达到期望值时,网络学习结束。
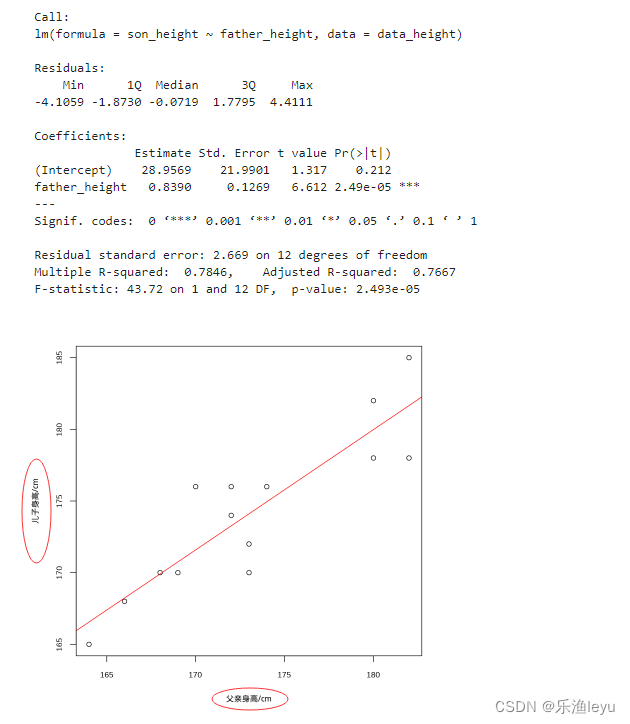
6.1 计算误差
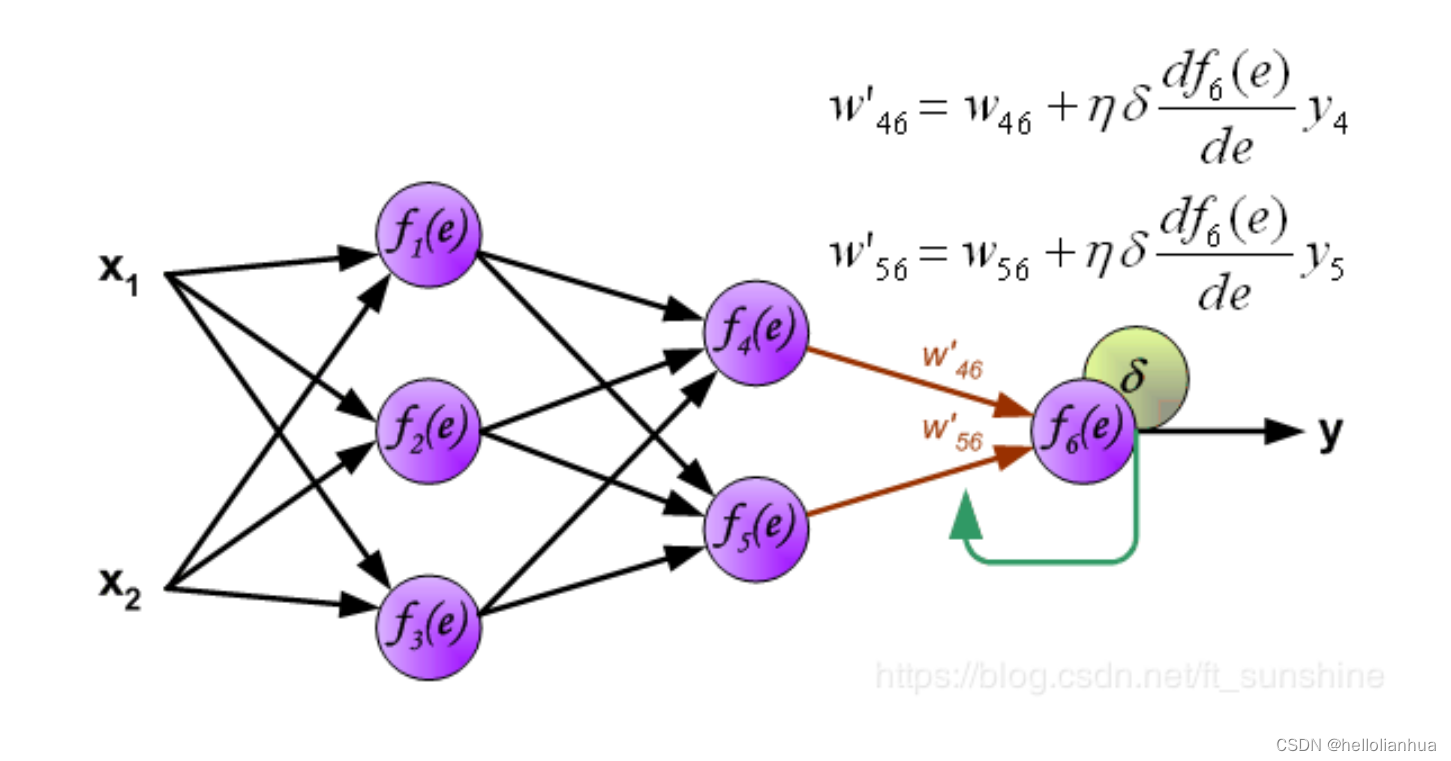
第一步是计算神经网络的输出(预测值)和真值的误差。
图中y为我们神经网络的预测值,由于这个预测值不一定正确,所以我们需要将神经网络的预测值和对应数据的标签来比较,计算出误差。误差的计算有很多方法,比如上面提到的输出与期望的误差的平方和,熵(Entropy)以及交叉熵等。计算出的误差记为 δ .

反向传播,顾名思义,是从后向前传播的一种方法。因此计算完误差后,需要将这个误差向不断的向前一层传播。向前一层传播时,需要考虑到前一个神经元的权重系数(因为不同神经元的重要性不同,因此回传时需要考虑权重系数)。

与前向传播时相同,反向传播时后一层的节点会与前一层的多个节点相连,因此需要对所有节点的误差求和。

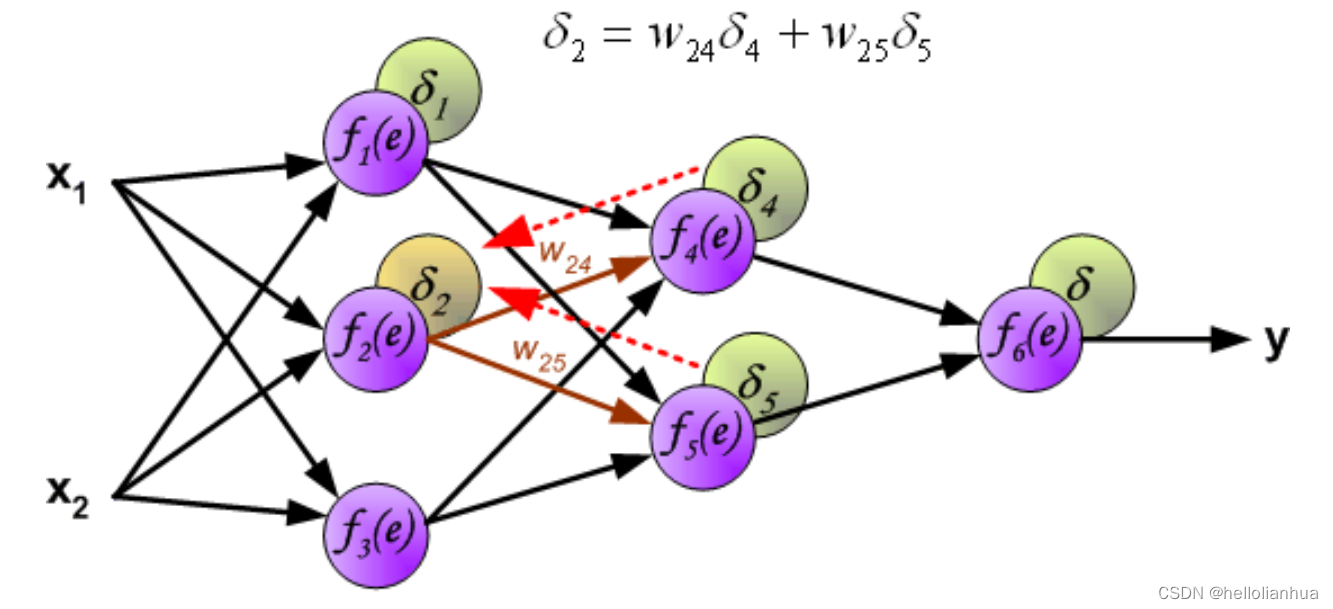
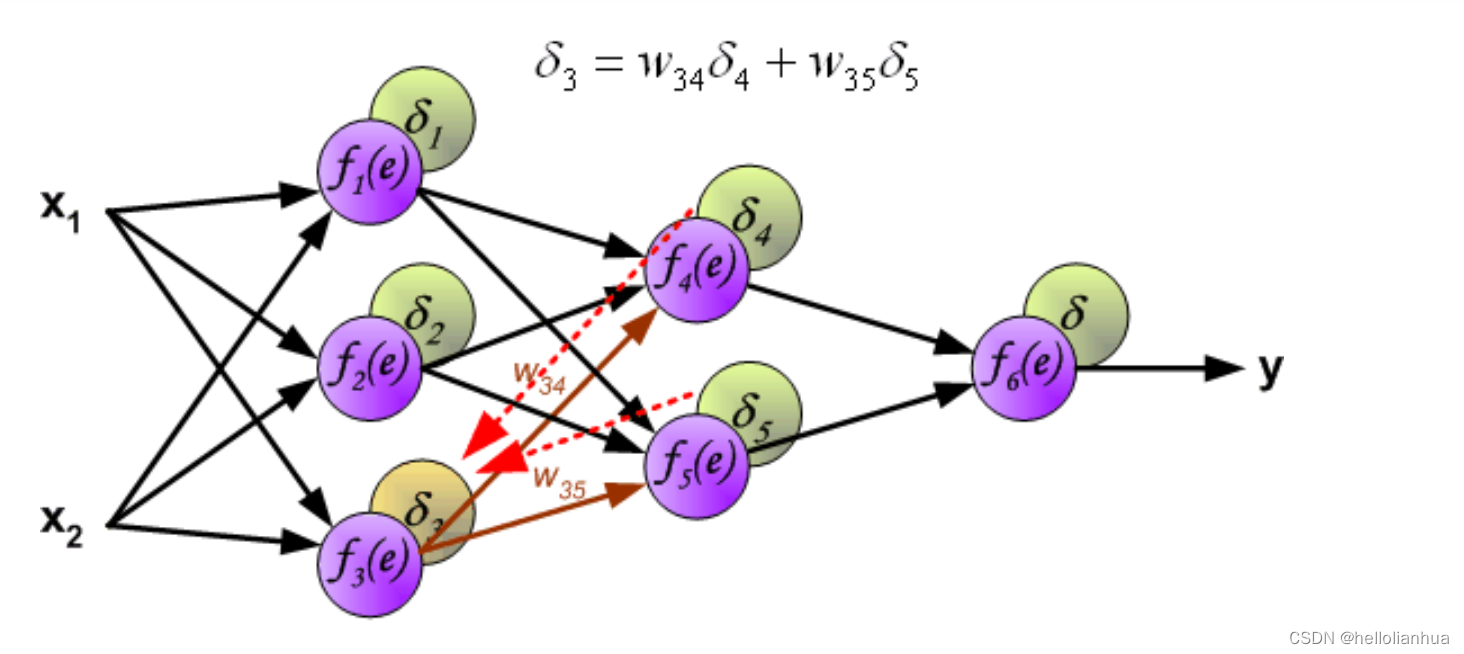
到此为止已经计算出了每个神经元的误差,接下来将更新权重。
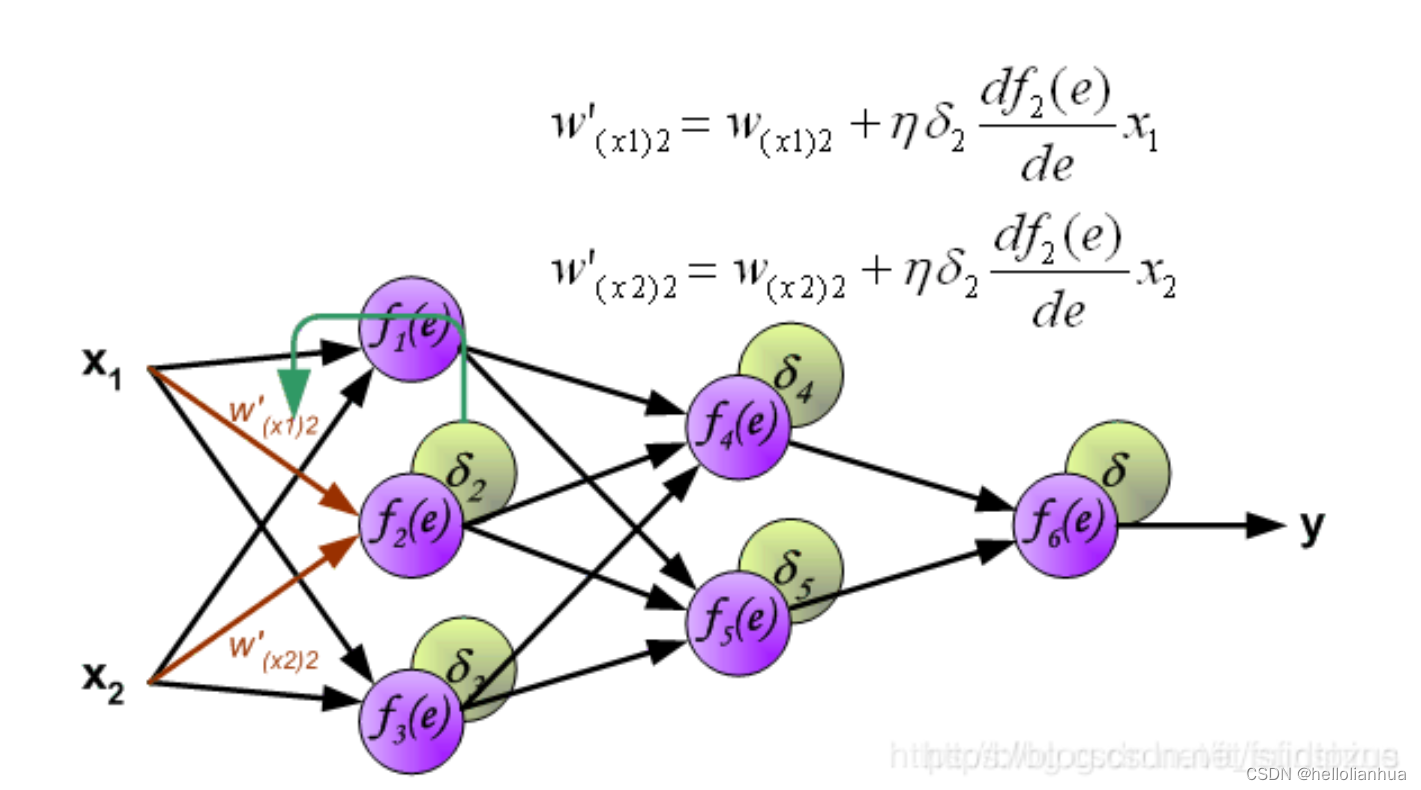
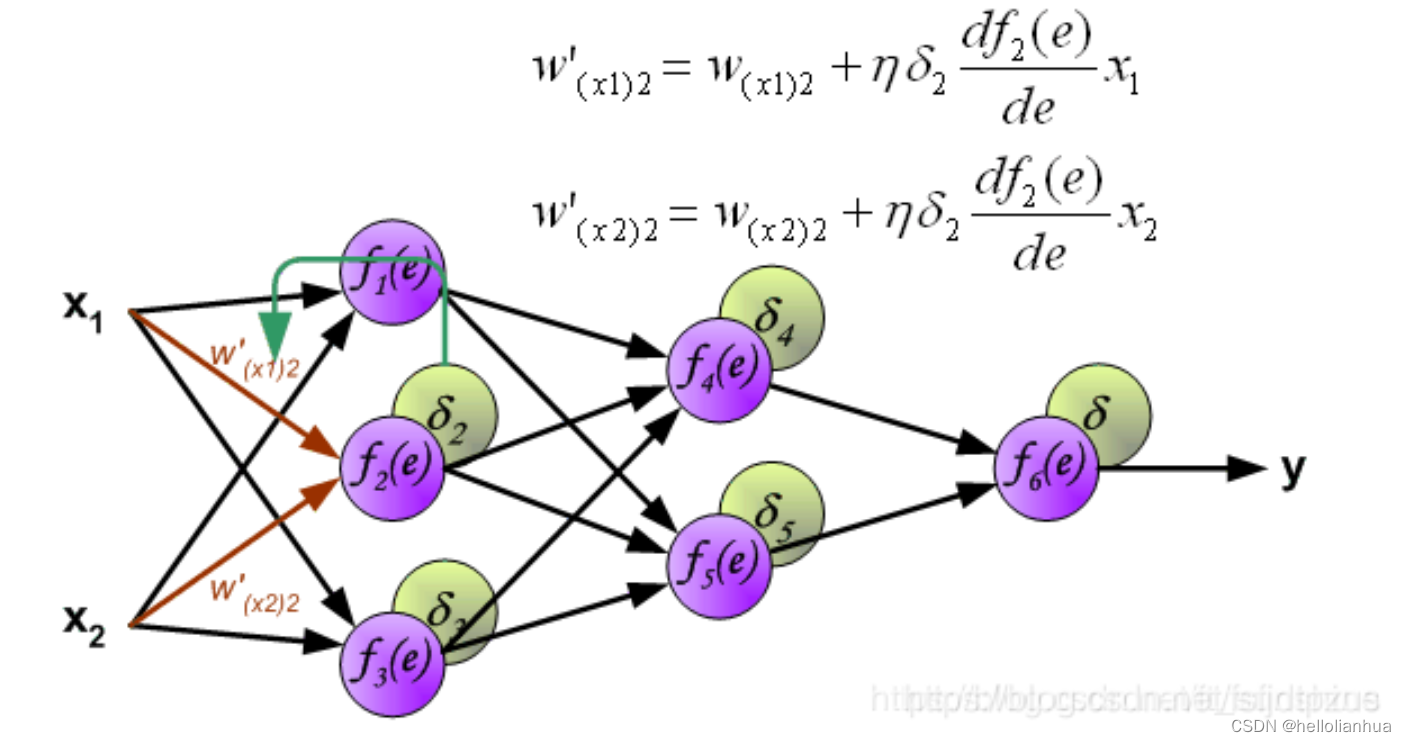
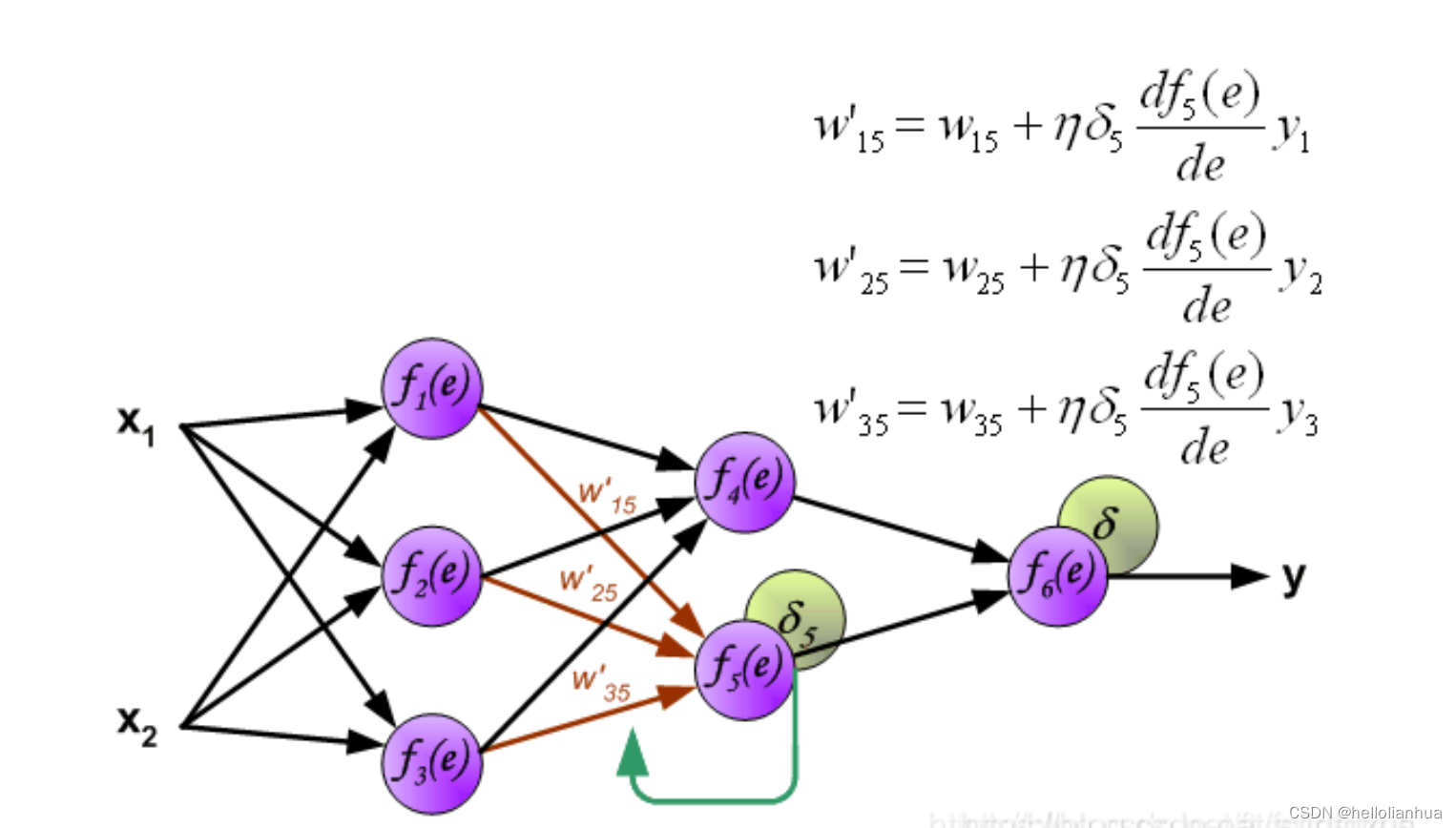
6.2更新权重
图中的η 代表学习率,w′是更新后的权重,通过这个式子来更新权重。这个式子具体是怎么来的,请看机器学习笔记丨神经网络的反向传播原理及过程(图文并茂+浅显易懂)_神经网络反向传播原理-CSDN博客第四部分具体例子。



 7. 卷积神经网络(CNN)算法和模型
7. 卷积神经网络(CNN)算法和模型
卷积神经网络(CNN)是一种深度学习算法,主要应用于图像识别领域。CNN的价值在于其能够将大数据量的图片有效地降维成小数据量,同时保留图片的特征,这类似于人类的视觉原理。
CNN的基本结构主要包括卷积层、池化层和全连接层:
1. 卷积层:这是CNN的核心部分,主要用于提取图像的特征。通过卷积操作,可以捕捉到图像中的局部特征。
2. 池化层:其主要作用是降低数据的维度,同时保留重要的特征信息。这有助于减少网络的复杂性,提高计算效率。
3. 全连接层:在卷积层和池化层提取并处理了图像的特征后,全连接层用于对特征进行高级处理并输出最终的分类结果。
7.1 CNN的常用层结构和参数设置
卷积神经网络(CNN)的常用层结构和参数设置主要包含以下几个部分:
1. 数据输入层:这是网络的第一层,用于接收原始图像数据。在处理原始图像数据时,通常需要进行预处理,包括去均值和归一化等操作。输入图像的尺寸通常是可以被2整除多次的像素值矩阵,常用的数字包括32,64,96,224,384和512。
2. 卷积计算层:也被称为CONV层,是网络的核心部分,主要用于从输入图像中提取特征。这一层会通过多个不同的滤波器(或卷积核)对输入图像进行卷积操作,以提取出图像的不同特征。
3. ReLU激励层:这一层的主要作用是对上一层输出的结果进行非线性变换,增强网络的表达能力。常用的激活函数包括ReLU、Sigmoid和Tanh等。
4. 池化层:池化层的作用主要是降低数据的维度,同时保留重要的特征信息。常用的池化方法有Max Pooling和Average Pooling等。
5. 全连接层:全连接层通常位于网络的最后部分,用于将之前提取并处理的特征进行高级处理并输出最终的分类结果。
值得注意的是,CNN的设计选择和参数设定会严重影响网络的训练和表现。例如,滤波器的大小、步长以及填充方式等都需要根据具体的应用场景和需求来设定。此外,虽然很多架构的选择都是凭借直觉,而非有充分的数学论证,但这些直觉往往是基于大量的实验结果。
相关文章:
深度学习基础知识
本文内容来自https://zhuanlan.zhihu.com/p/106763782 此文章是用于学习上述链接,方便自己理解的笔记 1.深度学习的网络结构 深度学习是神经网络的一种特殊形式,典型的神经网络如下图所示。 神经元:表示输入、中间数值、输出数值点。例如&…...
UE4_旋转节点总结一
一、Roll、Pitch、Yaw Roll 围绕X轴旋转 飞机的翻滚角 Pitch 围绕Y轴旋转 飞机的俯仰角 Yaw 围绕Z轴旋转 飞机的航向角 二、Get Forward Vector理解 测试: 运行: 三、Get Actor Rotation理解 运行效果: 拆分旋转体测试一&a…...

Dockerfile将jar部署成docker容器
将jar包copy到linux,新建Dockerfile文件 -rw-r--r-- 1 root root 52209844 Mar 25 22:55 data-sharing-0.0.1-SNAPSHOT.jar -rwxrwxrwx 1 root root 227 Mar 25 22:57 Dockerfile [rootlocalhost mnt]# pwd /mntDockerfile内容 # 指定基础镜像 FROM java:8-a…...
)
Android14音频进阶:AudioFlinger向HAL输出数据过程(六十四)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒体系统工程师系列【原创干货持续更新中……】🚀 人生格言: 人生从来没有捷径,只…...

docker构建镜像命令
编写dockerfile文件 例子1; FROM oraclelinux:7-slim ENV release19 ENV update13 RUN curl -o /etc/yum.repos.d/public-yum-ol7.repo https://yum.oracle.com/public-yum-ol7.repo && \yum-config-manager --enable ol7_oracle_instantclient && \yum in…...

每日一题——LeetCode1720.解码异或后的数组
方法一 异或运算的性质 encoded[i−1]arr[i−1]⊕arr[i] 在等式两边同时异或arr[i−1] 由于: 一个数异或它自己,结果总是0。 0异或任何数,结果都是那个数本身。 所以等式可以转化为: arr[i]arr[i−1]⊕encoded[i−1] 由于 a…...
Day47:WEB攻防-PHP应用文件上传函数缺陷条件竞争二次渲染黑白名单JS绕过
目录 文件上传与测试环境安装 1、前端 JS 2、.htaccess(apache独有的配置文件) 3、MIME类型 4、文件头判断 5、黑名单-过滤不严 6、黑名单-过滤不严 7、低版本GET-%00截断 8、低版本POST-%00截断 9、黑名单-过滤不严 10、逻辑不严-条件竞争 11、二次渲染 12、函数…...
【Android】美团组件化路由框架WMRouter源码解析
前言 Android无论App开发还是SDK开发,都绕不开组件化,组件化要解决的最大的问题就是组件之间的通信,即路由框架。国内使用最多的两个路由框架一个是阿里的ARouter,另一个是美团的WMRouter。这两个路由框架功能都很强大࿰…...

python知识点总结(九)
python知识点总结九 1、TCP中socket的实现代码实现TCP协议a、服务端b、客户端: 2、写装饰器,限制函数被执行的频率,如10秒一次3、请实现一个装饰器,通过一次调用函数重复执行5次4、写一个登录装饰器对一下函数进行装饰,…...

浅谈Linux中的软锁定(soft lockup)和硬件监视器(watchdog)
目录 1. 问题所示2. 基本知识3. 进阶知识 1. 问题所示 跑深度学习的时候遇到卡顿卡机 hostname kernel:watchdog BUG:soft lockup - CPU#16 stuck for 130s![P2PMain-72:4030570]界面如下所示: 大概意思是: watchdog_thresh参数是硬件监视器的超时阈值…...

数据库的四个特性?MySQL是如何实现的?
首先MySQL中,数据库的四个特性分为: 原子性一致性隔离性持久性 也就是我们常说的ACID。 那么这四个特性数据库是如何实现的呢? 持久性---> redo log: redo log(重做日志): redolog本身是…...
Jupyter R绘图 汉字显示乱码的解决办法
1.Jupyte中,R绘图,汉字显示乱码 2.如何解决? (1)R中安装showtext 登录linux服务器 #R > install.packages(“showtext”) … 出错 (2)退出R,安装freetype-config #apt install libfreetype6-dev 出错 (3)进入R&…...

推荐几个值得一读的Qt开源项目
VNote - 基于Qt的免费开源笔记软件,适合那些寻找跨平台笔记解决方案的用户。项目地址:https://github.com/vnotex/vnote Qt NodeEditor - 类似于UE4蓝图的节点编辑器,对于想要深入了解Qt图形编辑和节点系统的人来说,这是一个极好…...

【XR806开发板试用】使用PWM模块模拟手机呼吸灯提示功能
一般情况下,我们的手机在息屏状态,当收到消息处于未读状态时,会有呼吸灯提醒,这次有幸抽中XR806开发板的试用,经过九牛二虎之力终于将环境搞好了,中间遇到各种问题,在我的另一篇文章中已详细描述…...

Mysql——索引下推
MySQL的索引下推(Index Condition Pushdown, ICP)是一种查询优化技术,它允许MySQL在存储引擎层执行部分WHERE子句中的过滤条件,而非全部在MySQL服务器层执行。这使得在扫描索引过程中就可以剔除不满足条件的记录,从而减…...

Springboot项目之mybatis-plus多容器分布式部署id重复问题之源码解析
mybatis-plus 3.3.2 部署多个pod id冲突问题 配置: # 设置随机 mybatis-plus.global-config.worker-id: ${random.int(1,31)} mybatis-plus.global-config.datacenter-id: ${random.int(1,31)}源码解析:MybatisSqlSessionFactoryBean 重点:…...

微信答题小程序云开发--实现云函数上传题目图片 base64功能
需求功能 题目带有图片,需要支持上传图片功能。微信答题小程序云开发,实现云函数上传题目图片、存储功能、查询显示等功能。 云函数开发遇到的问题 在微信云开发环境当中,普通的用户并没有往云存储内写入文件的权限。 所以普通用户想要使用…...
学会Sass的高级用法,减少样式冗余
在当今的前端开发领域,样式表语言的进步已经显著提升了代码组织性和可维护性。Sass(Syntactically Awesome Style Sheets)作为CSS预处理器的翘楚,以其强大的变量、嵌套规则、混合宏(mixin)、循环和函数等高…...

【Java初阶(五)】类和对象
❣博主主页: 33的博客❣ ▶文章专栏分类: Java从入门到精通◀ 🚚我的代码仓库: 33的代码仓库🚚 目录 1. 前言2.面向对象的认识3.类的认识4. 类的实例化4.1什么是实例化4.2类和对象的说明 5.this引用6.对象初始化6.1 构造方法 7.static关键字8.代码块8.1 …...

AWTK-MODBUS 服务器
AWTK-MODBUS 服务器 1. 介绍 AWTK-MODBUS 提供了一个简单的 MODBUS 服务器,可以通过配置文件来定义寄存器和位的数量和初始值。 启动方法: bin/modbus_server_ex config/default.json2. 配置文件 配置文件使用JSON格式。 url: 连接地址auto_inc_in…...

通过Taotoken CLI工具一键配置团队开发环境与统一模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置团队开发环境与统一模型调用 在团队协作开发中,统一管理大模型API的接入配置是一项常见且…...

m4s-converter技术解析:跨平台B站缓存视频无损转换方案
m4s-converter技术解析:跨平台B站缓存视频无损转换方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter m4s-converter是一个专业的开…...

ODM终极指南:5步快速上手免费开源无人机影像处理,生成专业三维模型与正射影像
ODM终极指南:5步快速上手免费开源无人机影像处理,生成专业三维模型与正射影像 【免费下载链接】ODM A command line toolkit to generate maps, point clouds, 3D models and DEMs from drone, balloon or kite images. 📷 项目地址: https…...

Redis容器内存统计失真与cgroup隔离失效深度解析
1. 这不是“老漏洞复现”,而是Redis容器化部署中被集体忽视的底层内存契约崩塌你有没有遇到过这样的情况:一套跑在Docker里的Redis服务,配置没动、版本没升、流量平稳,某天凌晨突然开始OOM Killer杀进程,docker stats显…...

从‘拍脑袋’到‘有章法’:用Python实战Embedded与Wrapper方法,为你的模型精准选特征
从‘拍脑袋’到‘有章法’:Python实战Embedded与Wrapper方法的高阶特征选择指南在金融风控和医疗诊断这类对模型精度要求严苛的领域,数据科学家们常常面临这样的困境:当特征数量膨胀到数百甚至上千维时,盲目依赖过滤法选特征就像在…...

设计岗位替代风险评估程序,分析岗位可替代性,给出创新能力补强提升方向。
一、实际应用场景描述在数字化转型加速背景下,企业和个人普遍关心以下问题:- HR 在做岗位规划时需要评估 自动化风险- 员工希望了解自己的岗位是否容易被 AI / 脚本替代- 创业者需要判断某类服务是否值得人力长期投入- 学生在做职业规划时需要参考岗位演…...

量子机器学习:首次光子实验实现明确量子优势,开启超低功耗AI新范式
1. 量子机器学习:从理论到实验的首次明确优势量子计算和人工智能,这两个听起来都充满未来感的领域,在过去几年里各自都取得了令人瞩目的进展。但一个核心问题始终悬而未决:量子力学那些“反直觉”的特性,比如叠加和纠缠…...

衰老生物学领域首个1站式标准化DNA甲基化数据库
摘要 准确量化生物年龄对于解析衰老机制、研发高效干预手段至关重要。分子衰老时钟(尤其是基于DNA甲基化数据的表观遗传时钟)已成为衰老研究领域的核心工具。然而,目前缺少覆盖多年龄、多组织且格式统一的公开DNA甲基化数据集,导致表观遗传时钟研究难以高效推进。研究者在…...

Windows上的安卓应用安装神器:APK-Installer完全指南
Windows上的安卓应用安装神器:APK-Installer完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上轻松安装安卓应用,又不想…...

Cursor Pro工具完整指南:5步实现AI编程助手设备标识管理方案
Cursor Pro工具完整指南:5步实现AI编程助手设备标识管理方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached yo…...