中间件学习
一、ES
场景:某头部互联⽹公司的好房业务,双⼗⼀前⼀天,维护楼盘的运营⼈员突然接到合作开发商的通知,需要上线⼀批热⻔的楼盘列表,上传完成后,C端⼩程序⽀持按楼盘的名称、户型、⾯积等产品属性全模糊搜索热⻔楼盘。
需求:按楼盘的名称、户型、⾯积等产品属性全模糊搜索,双⼗⼀期间,楼盘搜索QPS预计在800左右,搜索完成后展示的楼盘字段信息⾮常多
业界数据一致性解决方案:
ES与数据库双写方案
实现方案:
运营后台导⼊楼盘的时候,先批量操作本地的数据库,然后再批量同步写⼊到es,这两步操作放到同⼀个事务中,如果写⼊数据库成功,调⽤es失败抛出异常,spring事务会回滚数据库记录。如果写⼊数据库成功,调⽤es超时了(但实际上es是成功的,只是接⼝返回的数据慢了)抛出异常,这个时候spring事务也会回滚数据库记录,从⽽会导致数据库和es的数据出现不⼀致。
优点:
实现非常简单,不引入任何中间件,数据同步实时
缺点:
业务逻辑中直接写入es,有一定的侵入性
数据不一致,es异常,事务回滚
数据库本地事务调用es,es超时会引起接口长事务,长时间占用数据库链接
应用场景:
系统特点:旧系统年限长,单体架构且技术比较落后,如果引入除ES之外的其他中间件治理成本很高,可以考虑这个方案
业务场景:用户量少,偏后台管理类的系统,对数据同步的实时性要求很高,接近实时
MQ异步写入方案
实现方案:
优点:
通过引入MQ,实现异步削峰,提升接口的整体性能
通过本地消息表+定时任务重试,有效保证
缺点:
引入MQ中间件,系统复杂度增加
MQ有积压风险,会存在延时的风险
应用场景:
系统特点:C端系统,系统架构已引入MQ中间件,对接口TPS有一定性能要求
业务场景:用户体量大,高并发场景,同一业务变更的地方少,允许有一定的延迟(秒级)
定时任务同步方案
实现方案:
前提条件:楼盘信息更新的时候必须更新mysql楼盘表中的更新时间字段。 这⾥需要考虑两个核⼼点:1、控制好定时任务执⾏的频率 2、定时任务采⽤增量同步(深度分⻚分批处理数据)
优点:
对业务无侵入性
缺点:
实时性很差
轮询数据库,数据量比较大的时候,会存在性能问题
频繁扫库处理大数据量的表,数据库本身压力非常大
应用场景:
系统特点:旧系统年限长,技术框架老旧,引入其他的中间件成本很高
业务场景:用户体量小,偏报表统计类业务,对数据实时性要求不高
监听binlog异构同步方案
实现方案:
优点:
对业务无任何侵入性,解耦,数据同步准实时
缺点:
需要引入第三方canal数据同步中间件
binlog同步不及时,会有一定的数据延迟(毫秒级)
应用场景:
系统特点:C端系统,开放mysql binlog日志监听,引入第三方canal中间件成本不高
业务场景:互联网公司,用户体量大,大型多中心组织,高并发场景,业务上允许有一定的延迟(秒级)
数据快速修复解决方案
发现问题:
搭建业务监控平台,配置业务监控
定位问题:
开发问题诊断平台,可视化定位问题
快速修复问题:
捞数+补数
代码落地实现:
基于监听binlog方案的代码实现
1)redis与mysql数据⼀致性如何保证?
答:优先考虑基于binlog监听的⽅案实现。
2)本地缓存、redis与mysql三者之间的数据⼀致性如何保证?
答:⽤户在管理后台针对特定的功能记录新增或修改后,后端接⼝会先将数据记录写⼊到数据库,然后再发送MQ⼴播消息(或者基于redi实现⼴播通知),各个应⽤节点接收到MQ⼴播消息后,分别从数据库中查询记录然后再刷新到本地缓存、redis缓存,从⽽保证三者之间的数据⼀致性。
二、Redis分布式锁
分布式锁
JVM锁(单机)
同一个JVM进程内种多线程并发访问资源的安全性,一般使用JDK自带的synchronized或lock锁
分布式锁(集群)
不同进程多线程并发访问资源的安全性,一般采用mysql,zk,Redis实现
应用场景:
悲观锁,当查询某条记录时,就让数据库为该记录加锁,锁住记录后别人无法操作
缺点:可能出现死锁,并发性能差
乐观锁,修改事务隔离级别RC 读已提交的
缺点:并发性能差
redis分段预扣库存和异步消息写入db
申请阶段:将库存扣减转到redis进行,一般对redis锁进行分段处理
确认阶段:引入mq,串行处理,超过阈值就不在消费队列
缺点:异步写入DB,有数据不一致的风险,告警机制和补偿措施
实现:
1)加锁
2)执行业务逻辑
3)释放锁
SpringBoot实现方式:
自定义分布式注解 @lock + AOP(开发一个切面拦截类封装加锁和解锁逻辑)
引入Spring-data-redis驱动包,集成redis某个客户端
redis客户端:
redis+lua
jedis
lettuce
redission
1)redis 除了做缓存,还可以用来做什么?
答:分布式锁、防重提交、分布式限流、简易版本的消息队列、延迟任务、session 共享(集成spring-session-data-redis)
2)redis 锁如何保证任何时刻有且只有一个线程持有这个锁?
答:使用命令:setnx key value key不存在时设置成功返回值ok,key存在设置失败,也可以采用If(!redisUtil.get(key)){set key value}, 不过这段代码需要采用 lua 脚本实现来保证原子性。
3)如何保证分布式锁不产生死锁?
答:给锁设置一个合理的过期时间,业务执行过程中节点异常宕机,有个兜底终止跳出方案 使用命令:setnx key value ex seconds 设置key和对应的过期时间,到了指定的ex时间,锁自动释放。
4)如何防止释放别的线程锁?
答:给锁设置一个当前线程id或uuid的值,释放锁的时候判断锁的值与当前的值是否相等
5)锁到期了,业务没执行完,如何保证数据的一致?
答:常见的处理办法就是采用看门狗机制对分布式锁进行续命,具体步骤如下所示: 当前线程加锁成功后,假设设置默认过期时间为30秒,会注册一个定时任务监听这个锁,每隔30/3=10 秒就去查看这个锁,如果还持有锁,就对锁的过期时间继续续命30秒,如果没持有锁,就取消定时任务。这个机制也被叫做看门狗机制.
6)怎么保证分布式锁可重入?
答:通过维护当前持有锁的计数来实现可重入功能。加锁的时候,第一次获取锁时保存锁的线程标识,后续再次获取锁,先看是否是同一个线程,如果是的话只对锁计数进行递增。解锁时,对锁计数进行递减,同时刷新锁的过期时间。如果计数为0,最终才释放锁。
7)如何解决redis主从节点不同步导致锁失效的问题?
答:采用红锁算法解决这个锁失效问题,红锁算法认为,只要(N/2) + 1个节点加锁成功那么就认为获取了锁,解锁时将所有实例解锁。
8)如何优化高并发下锁性能?
答:与ConcurrentHashMap 的设计思想有点类似,用分段锁来实现。
实现方案
1)redis 分布式锁(推荐)
互联网项目并发量高,对性能要求高,比较推荐。
redis 常见操作,例如基本类型string、hash、list、set等等操作可以采用jedis或lettuce。 对于跟分布式锁相关的操作集成redission。
2)分布式锁百分百可靠
可以选用 Zookeeper作为分布式锁。采用cap理论中的cp模型保证高可靠性。
一般的项目我们可以结合不同的场景,同时兼容两种分布锁的实现。
三、Redis主从复制
主从复制,将一台Redis服务器的数据,复制到其他的Redis服务器,复制是单向的,采用读写分离模式。
工作原理:
slave节点初次连接master节点,会发送psync命令并触发全量复制,此时master节点fork一个后台进程,开始生成一份RDB快照,同时将那些从外面接收的写命令缓存到缓冲区中,slave先写入磁盘,再从磁盘加载到内存,接着master会将新增加的缓存区的写命令发送给slave执行并同步数据
全量复制
增量复制
1)redis主从节点是长连接还是短连接
答:长连接
2)怎么判断redis某个节点是否正常工作
答:通过相互的ping-pong心跳检测机制,有一半以上的节点没回应,则断掉这个节点连接
3)过期的key如何处理
答:主节点处理一个key或者通过淘汰算法淘汰一个key,主节点模拟一条del命令发送给从节点,从节点接收到命令删除key
4)redis是同步复制还是异步复制
答:redis主节点每次接收到写命令之后,先写到内部的缓冲区,然后异步发送给从节点
5)redis主从切换如何减少数据丢失
异步复制同步丢失
答:client端采取降低措施,将数据暂时写入本地缓存和磁盘中,在一段时间后重新写入master来保证数据不丢失,也可以将数据写入rocketmq消息队列,发送一个延时消费消息去写入master
集群产生脑裂数据丢失
答:在redis的配置文件中有两个参数设置 min-slaves-to-write min-slaves-max-lag
6)redis主从如何做到故障自动切换
答:哨兵模式,当主节点出现故障,由redis sentinel自动完成故障发现和转移,并通知应用方,实现高可用性
7)数据备份方式有哪些
热备
冷备
多活
四、Redis高可用
Redis主从复制模式
原理:
1 个master 节点可以挂多个slave节点,master节点负责请求的读写,slave节点负责请求的读,当数据写入master节点,通过主从复制将数据同步到slave节点,从而实现高可用。
缺点:
当主从节点异常或宕机后,需要一个监控工具监听所有的节点,出现问题后发出邮件告警,人工进行干预调整主从节点,相对耗时,而且造成服务不可用
Redis哨兵模式
原理:
它是在主从复制方案的基础上引入了一组哨兵节点来实现高可用的,哨兵节点是独立的进程,独立运行的。
作用:
监控
告警提醒
自动故障转移
通知客户端连接新的master(raft协议保存数据的一致性),通过ping的方式探活
缺点:
内存利用率低
高并发写入QPS有限
Redis Cluster集群模式
原理:
通过对redis数据分片,实现redis的分布式存储,cluser集群采用去中心化的思想,节点之间的通信采用gossip二进制协议,master节点负责请求的读写,slave 节点不参与请求的处理,只作为master的备份。
-
redis 如何实现数据分片
Redis 通过引入hash槽的概念,集群预先分配16384个槽slot,并将槽点分配具体的服务节点,每个节点负责一部分槽点数据的存储,这样数据就分散到多个节点,突破了redis单机内存的限制,存储容量大大增加。 -
数据如何进行存取
当接受到客户端的请求,通过对应进行crc16(key) % 16384 取模运算得到对应的槽,从而将读写操作转发到具体的服务节点,当数据写入对应的master节点后,数据会同步到这个master的所有slave节点。 -
如何实现高可用
采用主从复制模式来保证高可用,一个主节点对应多个从节点,主节点提供存取,从节点从主节点复制数据进行备份,当这个主节点挂掉以后,选取一个从节点充当主节点,从而保证集群节点不会挂掉。节点之间通过gossip协议交换信息,每个节点除了存取数据还会维护整个集群的节点信息。
缺点:
是无中心节点架构,依靠二进制协议协同自动化修复,节点之间不断进行心跳机制,造成大量IO
数据迁移,需要人工接入,大key的迁移有可能导致自动故障转移,造成不必要的切换
五、Redis热key解决方案
利用本地缓存(guava cache 或 caffeine)
在你发现热key以后,把热key加载到系统的JVM中。针对这种热key请求,会直接从jvm中取,而不会走到redis层。常见的本地缓存可以利用guava cache或者caffeine实现。
优点:
内存访问和redis访问的速度不在一个量级,基于本地缓存,接口性能好,可以大大增加单实例的QPS
缺点:
受应用内存限制,容量有限
部分热点数据,需要提前预知
热点数据自动检测有一定延迟
冗余存储备份key
通过空间换时间的思想,将一个热key分解为多个不同的小key,分别在redis集群的不同节点进行存储,尽可能降低数据的倾斜
优点:
不受应用内存限制,轻松水平扩容
缺点:
冗余多份存储,浪费了redis部分内存
限流熔断(兜底方案,保护系统高可用)
1)基于nignx层限流
2)基于应用网关限流
3)基于微服务限流
常用的限流框架:hystrix 和 sentinel
常用的限流算法:漏桶、令牌桶、计数器统计、滑动窗口
六、Kafka如何保证消息幂等
1)你做过的项目中,是如何进行系统间解耦的?
答:系统之间基本都是通过kafka消息来实现解耦的,kafka除了用于系统的解耦,还能解决流量的削峰,高并发的时候,可以极大减轻数据库的压力。
2)上游因为网络抖动同一条消息发送了两次,这个时候可能会产生一些脏数据
答:对于消息的幂等有很多种方案,常见的解决方案有四种:
1)给业务设置唯一key,比如订单业务的订单号、支付业务的支付流水号等常见的唯一key,下游针对key加一个分布式锁,最后通过数据库表设置唯一健兜底来保证消息的幂等。
2)发送消息的时候构造一个全局的唯一Id,下游消费的时候判断全局的唯一Id是否存在,如果已经存在,这条消息不用处理。
3)对于有状态流转的业务,如果状态机已经处于下一个状态,这时候来了一个上一个状态的变更消息,这个消息不用处理。
4)对于一些更新的业务,可以采用基于版本号的乐观锁,更新SQL的时候我们判断传入的当前的版本号与数据库表的版本号是否相等,如果相等更新成功,不相等更新失败。
幂等的基本概念
查询操作(天然幂等)
查询一次和查询多次,在数据不变的情况下,查询结果是一样的。查询是天然的幂等操作。
删除操作(天然幂等)
删除操作也是幂等的,删除一次和删除多次都是把数据删除(注意可能返回结果不一样,删除的数据不存在,返回0,删除的数据多条,返回结果多个)。
新增操作
新增操作,这种情况下多次请求,可能会产生重复数据
修改操作
修改操作,如果只是单纯的更新数据,比如:update account set money=100 where id=1,是没有问题的。如果还有计算,比如:update account set money=money+100 where id=1,这种情况下多次请求,可能会导致数据错误。
产生消息重复的原因
发送时消息重复
当一条消息已被成功发送到服务端并完成持久化,此时出现了网络闪断或者生产者宕机,导致服务端对生产者应答失败。 如果此时生产者Producer意识到消息发送失败并尝试再次发送消息,消费者Consumer后续会收到两条内容相同的消息。
投递时消息重复
消息消费的场景下,消息已投递到消费者Consumer并完成业务处理,当消费者给服务端反馈应答的时候网络闪断。为了保证消息至少被消费一次,消息队列的服务端将在网络恢复后再次尝试投递之前已被处理过的消息,消费者Consumer后续会收到两条内容相同的消息。
负载均衡时消息重复
当消息队列的服务端或消费者重启、扩容或缩容时,都有可能会触发rebalance,此时消费者Consumer可能会收到重复消息。
解决方案
设置业务唯一key方案
1)生产者消息体构造业务唯一key,消息端针对这个key加分布式锁
2)在消费端,创建一个消息防重表,利用插入记录唯一健约束控制 与业务有一定的耦合,另外高并发下频繁对消息防重表进行操作,性能比较低,不太建议使用。
3)数据库业务表加唯一索引(数据库)
设置全局唯一id方案
消息生产者生成一个唯一的消息Id(利用分布式Id生成服务或本地Id生成一个Id),我们在消息投递时,给每条业务消息附加一个唯一的消息Id,然后就可以在消费者利用类似分布式锁的机制,实现唯一性的消费。
基于业务的状态机方案
在业务单据上面会有个状态,状态在不同的情况下会发生变更,一般情况下存在有限状态机,当消费业务消息的时候,如果状态机已经处于下一个状态,这时候来了一个上一个状态的消息,直接丢弃消息不处理,保证了有限状态机的幂等。
基于version版本号的乐观锁方案
是适用于更新业务的场景,更新表的时候通过版本号对比来保证消息的幂等
insert …on duplicate key update 更新方案
适合一些统计更新类的业务或者定时同步第三方平台数据到自己数据库的场景
七、Kafka消费积压百万数据
解决方案
消费端:
1)应用消费节点 < kafka partition分区数,可以扩应用消费节点,否则,扩应用消费节点没用(应急:优先扩节点)
例如:dance-member-service应用节点:24个,broker分区数:16,扩应用节点是否有用?答案:没用
dance-member-service应用节点:12个,broker分区数:16,扩应用节点是否有用?答案:有用,扩4个节点,消费能力明显增强
2)优化消费端代码 . 自动提交改为手动提交 . 单条消费消息改为批量消费消息,数据单条入库改为批量入库 . 消费逻辑涉及DB操作,第一时间检查是否有慢SQL,通过explain分析是否可以通过加索引解决(大表要考虑是否会锁表,尽可能低峰期操作)
broker端:
1)kafka partition分区数 < 应用消费节点,可以扩broker分区数,否则,扩broker分区数没用(应急:优先扩节点)
例如:dance-member-service应用节点:12个,broker分区数:16,扩broker分区数是否有用?答案:没用
dance-member-service应用节点:24个,broker分区数:16,扩broker分区数是否有用?答案:有用,有8个应用节点处于空闲状态,扩8个节点,消费能力明显增强
生产端:
1)针对生产端采用动态配置开关降级,关闭MQ生产(系统不能快速扩容)
2)消费端消息没有积压后,通过消息补偿程序对业务消息补偿,同时消费端需要支持幂等
相关预案:
1)支持动态扩容
2)配置开关动态关闭生产端
3)配置开关动态关闭消费端
4)生产端支持消息补偿
5)消费端支持消息幂等
八、Kafka高性能设计
秒杀系统痛点
1)高并发,时间极短、 瞬间用户量大,而且用户会在开始前不断刷新页面,还会积累一大堆重复请求的问题,请求过多把数据库打宕机了,系统响应失败,导致与这个系统耦合的系统也GG,一挂挂一片
2)链接暴露,有人知道了你秒杀的url,然后在秒杀开始前通过这个url传要传递的参数来进行购买操作。
3)超卖,你只有一百件商品,由于是高并发的问题,一起拿到了最后一件商品的信息,都认为还有,全卖出去了,最终卖了一百十件,仓库里根本没这么多货。
4)恶意请求,因为秒杀的价格比较低,有人会用脚本来秒杀,全给一个人买走了,他再转卖,或者同时以脚本操作多个账号一起秒杀。(就是我们常见的黄牛党)
5)数据库,一瞬间高QPS把数据库打宕机了,谁都抢不到,活动失败GG,这可能与高并发有重叠的点
解决方案
1)高并发的解决方案
a. nginx做负载均衡(一个tomcat可能只能抗住几百的的并发,nginx还可以对一些恶意ip做限制)
b. 资源静态化,把前端的模板页面放到CDN服务器中(放到别的服务器中,减轻自己服务器的压力)
c. 页面的按钮,按一次后置灰X秒(防止一直用户一直点,同一个用户重复点击,虽然不会再卖给他,但是请求还是会到后端给系统压力,需要在前端按钮上做限制,比如点一下限制五秒内不能点击。)
d. 同一个uid,限制访问频度,做页面缓存,x秒内到达站点层的请求,均返回同一页面(用来防止其他程序员跳过按钮,直接用for循环不断发起http请求,具体的话可以请求每次进来都去redis查有没有对应的id的key值,没有就在redis中设置X秒过期的key)
e. 对于写请求,用消息队列(比如商品有一万件,就放一万个请求进来,当然要做好每秒几个的限制,不能一秒内全放进来,都成功了就继续放下一批,没成功就剩下的请求全部返回失败)
f. 读请求用redis集群顶住(一个redis也只能顶住几万的并发,叫上兄弟)
g. 记住一定一定要先把数据库里的东西提前加载到redis来,别等用户查了再加
2)链接暴露的解决方案
①页面中有一个计时模块,是访问秒杀页面的时候去从服务器里拿的,计时结束,显示秒杀的按钮。 问题:(为什么不直接取用户的时间?用户的本机时间是可以修改的。)
②点击秒杀按钮后,再次请求服务器时间,与秒杀的时间对比,如果秒杀进行中,返回一个由加密过的秒杀url 问题:(为什么还要再次请求服务器时间?怎么加密url?,避免时间误差,md5加密)
③通过这个加密过的url来进行支付、减库存操作。
3)超卖问题的解决方案
我们假设现在商品只剩下一件了,此时数据库中 num = 1;但有100个线程同时读取到了这个 num = 1,所以100个线程都开始减库存了。
每一个用户线程进来,key值就减1,等减到0的时候,全部拒绝剩下的请求.所以一定不会出现超卖的现象
4)恶意请求的解决方案怎么限制让一个人只能秒杀一件商品?
秒杀成功,将用户id存入redis集合。通过集合来判断
如果一个人用脚本掌握了多个账号去执行秒杀,怎么办?
可以让用户付款的时候回答问题,防止脚本的操作。比如12306买火车票的时候,是不是会有按顺序点击图中相同的文字?这就是为了防止脚本
5)数据库层面的解决方案
用消息队列来削峰
用缓存来顶住大量的查询请求
九、Kafka消息如何保证不丢失
kafka是一个分布式的消息中间件,它是基于磁盘做的数据存储,具备高性能、高吞吐量低延时的特点,其吞吐量轻松达到几十万,它在IO和计算方面做了非常的优化工作。
高性能:
顺序读写磁盘
充分利用操作系统页缓存
零拷贝
对消息批量读写
对消息批量压缩
分区分段加索引
生产者:
丢失原因:
1、kafka生产端异步发送消息后,不管broker是否响应,立即返回,伪代码:producer.send(msg),由于网络抖动,导致消息压根就没有发送到broker端。
2、kafka生产端发送消息超出大小限制,broker端接到以后没法进行存储。
解决方案:
1、生产者调用异步回调消息。伪代码如下:producer.send(msg,callback)
2、生产者增加消息确认机制,设置生产者参数:acks= all。partition的leader副本接收到消息,等待所有的follower副本都同步到了消息之后,才认为本次生产者发送消息成功了。
3、生产者设置重试次数。比如:retries>=3,增加重试次数以保证消息的不丢失
4、定义本地消息日志表,定时任务扫描这个表自动补偿,做好监控告警。
5、后台提供一个补偿消息的工具,可以手工补偿。
MQ broker:
丢失原因:
kafka broker集群接收到数据后会将数据进行持久化存储到磁盘,消息都是先写入到页缓存,然后由操作 系统负责具体的刷盘任务或者使用fsync强制刷盘,如果此时Broker宕机,且选举了一个落后leader副本很多的follower 副本成为新的leader副本,那么落后的消息数据就会丢失。
解决方案:
1、同步刷盘(不太建议)。同步刷盘可以提高消息的可靠性,防止由于机器掉电等异常造成处于页缓存而没有及时写入磁盘的消息丢失。但是会严重影响性能。
2、利用partition的多副本机制(建议)
unclean.leader.election.enable=false。数据丢失太多的副本不能选举为leader副本,防止落后太多的消息数据而引起丢失。
replication.factor>= 3。消息分区的副本个数,这个值建议设为>=3。
min.insync.replicas>1。消息写入多少副本才算已提交,这个值必须大于1,这个是要求一个leader 至少感知到有至少一个 follower还跟自己保持联系。
replication.factor>min.insync.replicas。这样消息才能保存成功。
消费者:
丢失原因:
1、消费者配置了offset自动提交参数。enable.auto.commit=true。
2、消息者收到了消息,进行了自动提交offset,kafka以为消费者已经消费了这个消息,但其实刚准备处理这个消息,还没处理完成,消费者自己挂了,此时这条消息就会丢失。
3、多线程消费消息,某个线程处理消息出现异常,还是会出现自动提交offset。
解决方案:
1、消费者关闭自动提交,采用手动提交offset。通过配置参数:enable.auto.commit=false,关闭自动提交offset,在完成业务逻辑以后手动提交offset,这样就不会丢失数据。
2、消费者多线程处理业务逻辑,等待所有线程处理完成以后,才手工提交offset。
3、消费者消费消息需要进行幂等处理,防止重复消费。
相关文章:

中间件学习
一、ES 场景:某头部互联⽹公司的好房业务,双⼗⼀前⼀天,维护楼盘的运营⼈员突然接到合作开发商的通知,需要上线⼀批热⻔的楼盘列表,上传完成后,C端⼩程序⽀持按楼盘的名称、户型、⾯积等产品属性全模糊搜索…...

iOS开发进阶(十一):ViewController 控制器详解
文章目录 一、前言二、UIViewController三、UINavigationController四、UITabBarController五、UIPageViewController六、拓展阅读 一、前言 iOS 界面开发最重要的首属ViewController和View,ViewController是View的控制器,也就是一般的页面,…...
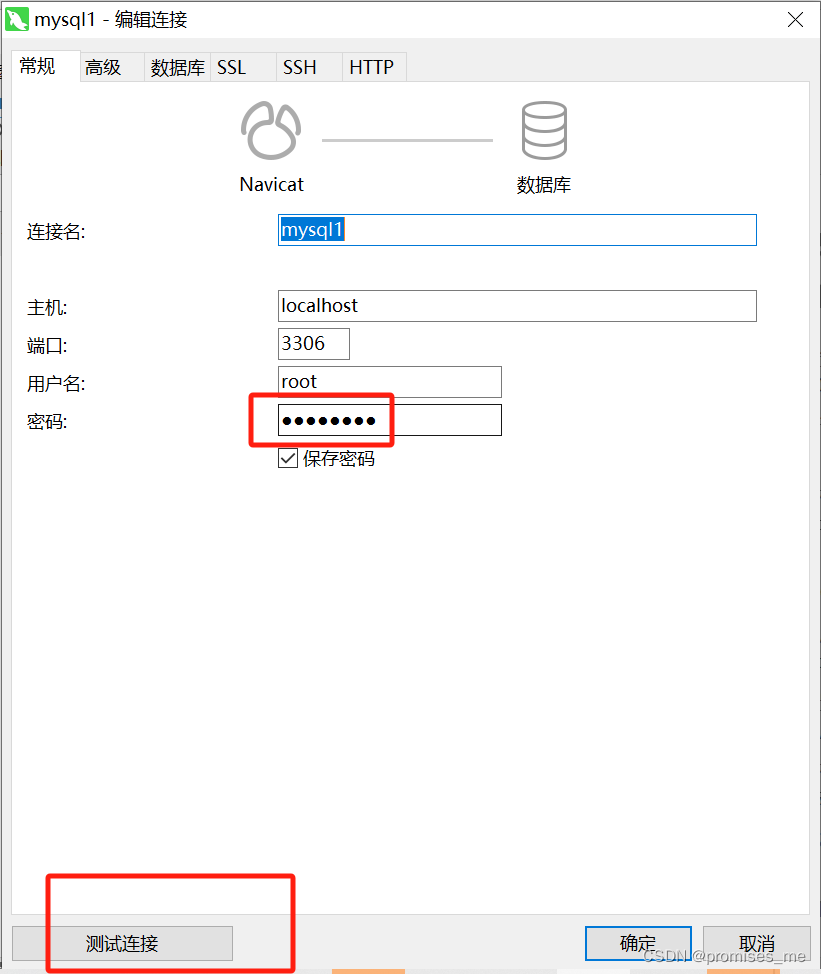
修改mysql密码
1.在此处文件夹下打开cmd 2.输入命令mysqladmin -uroot -p旧密码 password 新密码 3.在navicat进行测试连接...
uniapp 使用命令行创建vue3 ts 项目
命令行创建 uni-app 项目: vue3 ts 版 npx degit dcloudio/uni-preset-vue#vite-ts 项目名称注意 Vue3/Vite版要求 node 版本^14.18.0 || >16.0.0 如果下载失败,请去gitee下载 https://gitee.com/dcloud/uni-preset-vue/repository/archive/vite-ts…...
一周学会Django5 Python Web开发-Django5模型定义
锋哥原创的Python Web开发 Django5视频教程: 2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~共计41条视频,包括:2024版 Django5 Python we…...

kingbaseESV8逻辑备份还原
数据库逻辑备份还原 sys_dump -h127.0.0.1 -Usystem -f/home/kingbase/db01.dmp db01 ksql -h127.0.0.1 test system -c drop database db01 ksql -h127.0.0.1 test system -c create database db01 ksql -h127.0.0.1 -Usystem -ddb01 -f/home/kingbase/db01.dmp --------…...
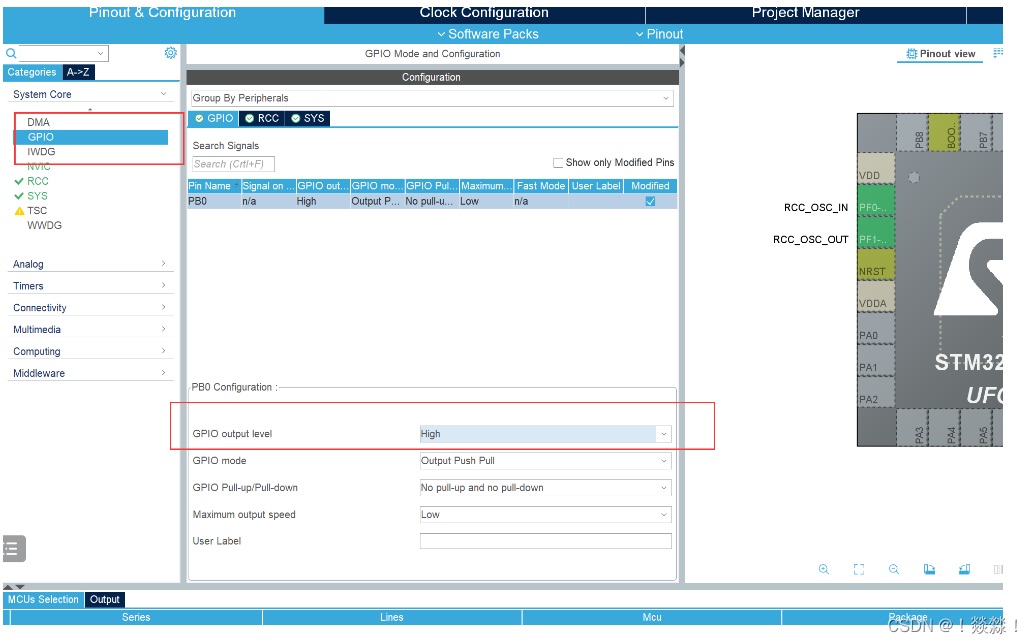
FreeRtos作业1
1.总结keil5下载代码和编译代码需要注意的事项 代码写完之后的操作流程 2.总结STM32Cubemx的使用方法和需要注意的事项 选择芯片型号 生成代码 3.总结STM32Cubemx配置GPIO的方法 4、使用定时器2让黄灯闪烁 /* USER CODE END Header */ /* Includes --------------------------…...

spring boot dynamic 动态数据数据源配置连接池
前言 我们可以使用 dynamic-datasource 来快速实现多数据源,但是多数据源配置连接池 以及说明文档都是收费的。 这里整理的连接池的配置以及配置说明 连接池配置 (druid或者 hikari 选择一个即可) 特此说明 如果配置配到了 spring.datasour…...

vue3中如何使用 watch 函数来观察响应式数据的变化
前言 在 Vue 3 中,可以使用 watch 函数来观察响应式数据的变化。这个函数可以在组件的 setup 函数中使用。watch()方法还可以实现更多复杂的功能,比如异步获取数据并在数据更新时重新渲染页面。 代码示例 1、以下是一个使用 Vue 3 watch 函数的简单示例…...

自建机房私有云吗?
大家好,我是小码哥,之前一种有没搞清楚公有云、私有云的概念,今天算是弄清楚了,这里给大家分享一下公有云、私有云的区别,以及自建机房算不算私有云! 其实私有云(Private Cloud)和公…...
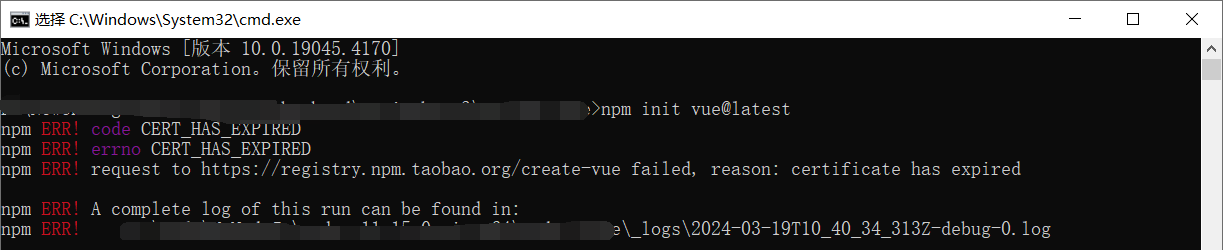
解决npm init vue@latest证书过期问题:npm ERR! code CERT_HAS_EXPIRED
目录 一. 问题背景 二. 错误信息 三. 解决方案 3.1 临时解决办法 3.2 安全性考量 一. 问题背景 我在试图创建一个新的Vue.js项目时遇到了一个问题:npm init vuelatest命令出现了证书过期的错误。不过这是一个常见的问题,解决起来也简单。 二. 错误…...
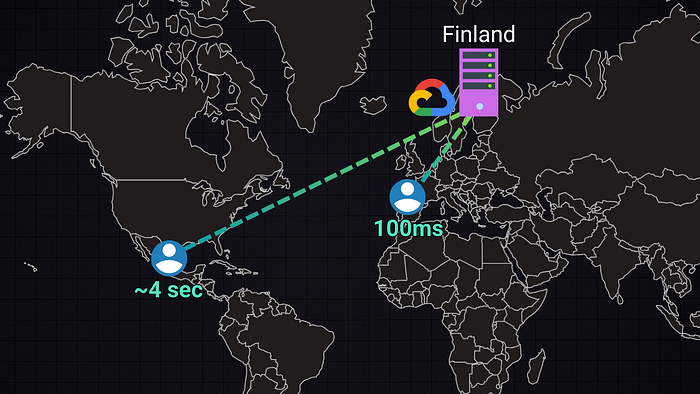
缓存和缓存的常用使用场景
想象一下,一家公司在芬兰 Google Cloud 数据中心的服务器上托管一个网站。对于欧洲用户来说,加载可能需要大约 100 毫秒,但对于墨西哥用户来说,加载需要 3-5 秒。幸运的是,有一些策略可以最大限度地减少远程用户的请求延迟。 这些策略称为缓存和内容交付网络 (CDN),它们是…...
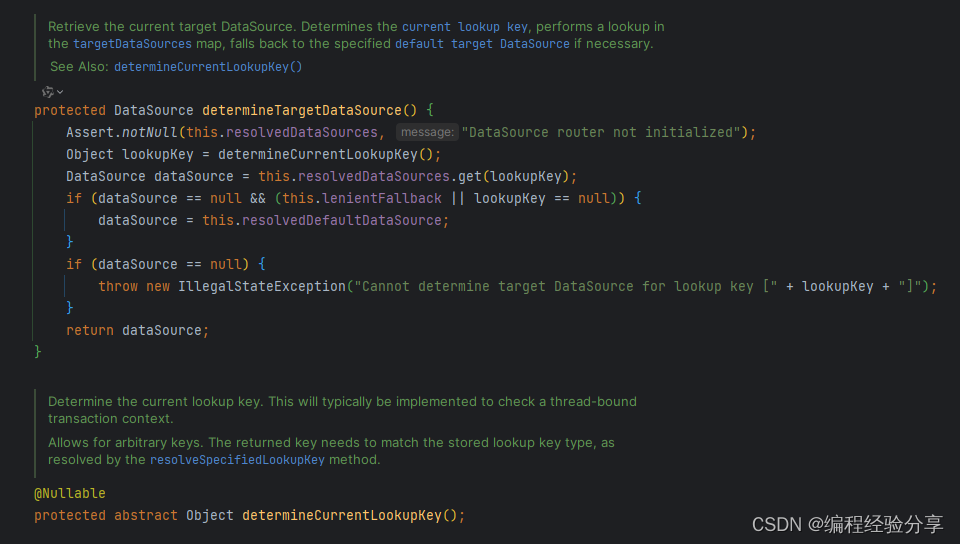
模板方法模式(继承的优雅使用)
目录 前言 UML plantuml 类图 实战代码 AbstractRoutingDataSource DynamicDataSource DynamicDataSourceContextHolder 前言 在设计类时,一般优先考虑使用组合来替代继承,能够让程序更加的灵活,但这并不意味着要完全抛弃掉继承。 …...

百度智能云千帆,产业创新新引擎
本文整理自 3 月 21 日百度副总裁谢广军的主题演讲《百度智能云千帆,产业创新新引擎》。 各位领导、来宾、媒体朋友们,大家上午好。很高兴今天在石景山首钢园,和大家一起沟通和探讨大模型的发展趋势,以及百度最近一段时间的思考和…...

Python下载cuda包失败后到成功(方便使用GPU加速运算,显著提高代码运行速度)
一、查询自己电脑上的cuda版本方法: 1.在windows的cmd里查询显卡cuda的版本号,命令行输入:nvidia-smi 2.在NVIDIA控制面板上寻找自己电脑上cuda的版本 二、安装支持的cuda的python cupy库 因为我的电脑上为cuda11.4,所以使用cuda114,不同的版…...
【Flink】Flink 处理函数之基本处理函数(一)
1. 处理函数介绍 流处理API,无论是基本的转换、聚合、还是复杂的窗口操作,都是基于DataStream进行转换的,所以统称为DataStreamAPI,这是Flink编程的核心。 但其实Flink为了更强大的表现力和易用性,Flink本身提供了多…...

【Java - 框架 - Lombok】(2) SpringBoot整合Lombok完成日志的创建使用 - 快速上手;
"SpringBoot"整合"Lombok"完成日志的创建使用 - 快速上手; 环境 “Java"版本"1.8.0_202”;“Lombok"版本"1.18.20”;“Spring Boot"版本"2.5.9”;“Windows 11 专业版_22621…...

linux 系统安装php 8.0.2
1. 安装包准备 https://www.php.net/distributions/php-8.0.22.tar.gz 我下载到 /usr/local/src 这个目录了 cd /usr/local/srcwget https://www.php.net/distributions/php-8.0.22.tar.gz 2. tar 解压 然后进到解压的文件夹 tar -zxvf php-8.0.22.tar.gz cd php-8.0.2…...

你管这破玩意叫网络
你是一台电脑,你的名字叫 A 很久很久之前,你不与任何其他电脑相连接,孤苦伶仃。 直到有一天,你希望与另一台电脑 B 建立通信,于是你们各开了一个网口,用一根网线连接了起来。 用一根网线连接起来怎么就能…...

系统开发实训小组作业week5 —— 用例描述与分析
目录 1、电影管理 1.1、 用例描述 1.2、 活动图 1.3、 界面元素 1.4、 功能 2、用户管理 2.1、 用例描述 2.2、 活动图 2.3、 界面元素 2.4、 功能 1、电影管理 1.1、 用例描述 用例号 UC009-01 用例名称 电影管理 用例描述 管理员实现对电影信息、座位数量、价…...

基于MCP协议的食品安全供应链智能风险评估服务器设计与应用
1. 项目概述:一个为AI工作流赋能的食品安全供应链智能MCP服务器如果你在食品制造、餐饮连锁或进口贸易领域工作,那么“食品安全”这四个字背后,是无数个不眠之夜和如履薄冰的日常。从原料采购到成品上架,每一个环节都可能潜藏着生…...

OpenClaw Gateway智能守护者:双触发自愈与AI诊断实践
1. 项目概述:一个为OpenClaw Gateway设计的智能守护者如果你在运维一个基于OpenClaw Gateway的服务,大概率经历过这样的深夜惊魂:手机突然收到告警,提示网关服务挂了,然后你不得不从床上爬起来,摸黑打开电脑…...

3分钟掌握Get-cookies.txt-LOCALLY:浏览器Cookie本地导出的终极隐私保护方案
3分钟掌握Get-cookies.txt-LOCALLY:浏览器Cookie本地导出的终极隐私保护方案 【免费下载链接】Get-cookies.txt-LOCALLY Get cookies.txt, NEVER send information outside. 项目地址: https://gitcode.com/gh_mirrors/ge/Get-cookies.txt-LOCALLY 在数字身份…...

【Perplexity引用格式设置终极指南】:20年科研老炮亲授5大避坑法则,90%用户都设错了!
更多请点击: https://intelliparadigm.com 第一章:Perplexity引用格式设置的核心价值与认知重构 Perplexity 作为衡量语言模型预测能力的关键指标,其引用格式的规范性直接影响评估结果的可比性、复现性与学术严谨性。当研究者在论文、技术报…...

Allegro丝印层加汉字和防静电标识?我找到了比自带功能更香的免费Skill工具
Allegro丝印层高效处理方案:汉字与防静电标识的终极实践指南 在PCB设计的最后阶段,丝印层的处理往往成为工程师们头疼的问题。尤其是当设计需要添加中文注释、企业标识或行业标准符号(如防静电警告标志)时,Allegro原生…...

5分钟搞定Windows和Office激活:KMS_VL_ALL_AIO智能激活完全指南
5分钟搞定Windows和Office激活:KMS_VL_ALL_AIO智能激活完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活而烦恼吗?每次重装系统后都要面对繁…...
)
玩转OurBMC第二十六期:OpenBMC固件远程更新原理与实践(下)
栏目介绍:“玩转OurBMC” 是OurBMC社区开创的知识分享类栏目,主要聚焦于社区和BMC全栈技术相关基础知识的分享,全方位涵盖了从理论原理到实践操作的知识传递。OurBMC社区将通过 “玩转OurBMC” 栏目,帮助开发者们深入了解到社区文…...

VLC技术重构:模块化架构深度解析与跨平台媒体处理突破
VLC技术重构:模块化架构深度解析与跨平台媒体处理突破 【免费下载链接】vlc VLC media player - All pull requests are ignored, please use MRs on https://code.videolan.org/videolan/vlc 项目地址: https://gitcode.com/gh_mirrors/vl/vlc 技术洞察&…...

基于本地大模型与Playwright的隐私优先求职自动化助手RedClaw实践
1. 项目概述:一个真正为你掌控的本地化求职AI助手在求职季,我们常常面临一个两难困境:一方面,海投简历耗时耗力,重复填写那些大同小异的在线申请表让人筋疲力尽;另一方面,市面上一些所谓的“自动…...

苹果为何拒绝TD-SCDMA特供版iPhone?复盘技术标准与市场时机的战略博弈
1. 项目概述:一场关于苹果与中国移动的世纪猜想2012年的科技圈,空气中弥漫着一股躁动与期待。几乎所有的行业分析师和手机发烧友都在讨论同一个话题:苹果公司是否会为了全球最大的移动运营商——中国移动,专门推出一款支持TD-SCDM…...