Spark 应用调优
Spark 应用调优
- 人数统计
- 优化
- 摇号次数分布
- 优化
- Shuffle 常规优化
- 数据分区合并
- 加 Cache
- 优化
- 中签率的变化趋势
- 中签率局部洞察
- 优化
- 倍率分析
- 优化
表信息 :
- apply : 申请者 : 事实表
- lucky : 中签者表 : 维度表
- 两张表的 Schema ( batchNum,carNum ) : ( 摇号批次,申请编号 )
- 分区键都是 batchNum
运行环境 :

配置项设置 :

优化点 :

人数统计
统计至今,参与摇号的总人次和幸运的中签者人数
val rootPath: String = _// 申请者数据(因为倍率的原因,每一期,同一个人,可能有多个号码)
val hdfs_path_apply = s"${rootPath}/apply"
val applyNumbersDF = spark.read.parquet(hdfs_path_apply)
applyNumbersDF.count// 中签者数据
val hdfs_path_lucky = s"${rootPath}/lucky"
val luckyDogsDF = spark.read.parquet(hdfs_path_lucky)
luckyDogsDF.count
SQL 实现 :
selectcount(*)
from applyNumbersDFselectcount(*)
from luckyDogsDF
去重计数,得到实际摇号数 :
val applyDistinctDF = applyNumbersDF.select("batchNum", "carNum").distinctapplyDistinctDF.count
SQL 实现 :
selectcount(distinct batchNum ,carNum)
from applyDistinctDF
优化
分析 : 共有 3 个 Actions,会触发 3 个 Spark Jobs
用 Cache 原则:
- RDD/DataFrame/Dataset 引用次数为 1,坚决不用 Cache
- 当引用次数大于 1,且运行成本占比超过 30%,考虑用 Cache
优化 :
- 利用 Cache 机制来提升执行性能
val rootPath: String = _// 申请者数据(因为倍率的原因,每一期,同一个人,可能有多个号码)
val hdfs_path_apply = s"${rootPath}/apply"
val applyNumbersDF = spark.read.parquet(hdfs_path_apply)
// 缓存
applyNumbersDF.cacheapplyNumbersDF.countval applyDistinctDF = applyNumbersDF.select("batchNum", "carNum").distinct
applyDistinctDF.count
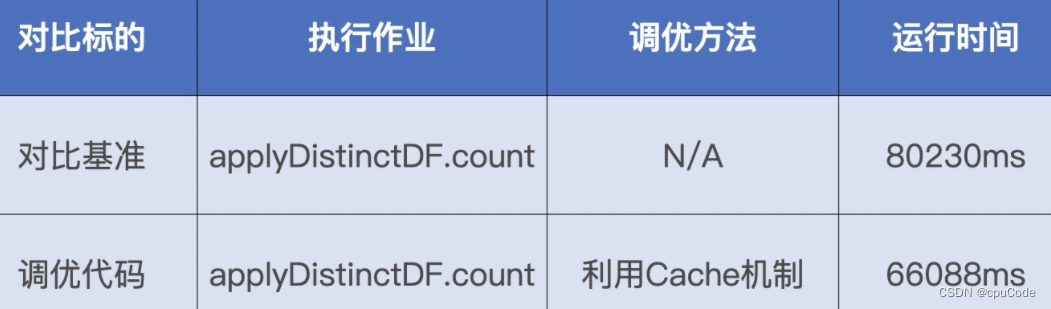
摇号次数分布
不同人群摇号次数的分布 :
- 统计所有申请者累计参与了多少次摇号
- 所有中签者摇了多少次号才能幸运地摇中签
统计所有申请者的分布情况
val result02_01 = applyDistinctDF.groupBy(col("carNum")).agg(count(lit(1)).alias("x_axis")).groupBy(col("x_axis")).agg(count(lit(1)).alias("y_axis")).orderBy("x_axis")result02_01.write.format("csv").save("_")
SQL 实现 :
with t1 as (selectcarNum,count(1) as x_axisfrom applyDistinctDFgroup by carNum
)
selectx_axis,count(1) as y_axis
from t1
group by x_axis
order by x_axis
优化
分析 : 共两次 Shuffle。以 carNum 做分组计数, 以 x_axis 列再次做分组计数
Shuffle 的本质 : 数据的重新分发,凡是有 Shuffle 地方就要关注数据分布
- 对过小的数据分片,要对进行合并
Shuffle 常规优化
优化点 : 减少 Shuffle 过程中磁盘与网络的请求次数
Shuffle 的常规优化:
- By Pass 排序操作 : 条件:计算逻辑不涉及聚合或排序;Reduce 的并行度 <
spark.shuffle.sort.bypassMergeThreshold - 调整读写缓冲区 : 条件 : Execution Memory 大
对读写缓冲区做调优 :
spark.shuffle.file.buffer: Map 写入缓冲区大小spark.reducer.maxSizeInFlight: Reduce 读缓冲区大小
读写缓冲区是以 Task 为粒度进行设置,所以调整这些参数时, 扩大 50%
| 默认 | 调优 |
|---|---|
| spark.shuffle.file.buffer = 32KB | spark.shuffle.file.buffer = 48 KB (32KB * 1.5) |
| spark.reducer.maxSizeInFlight = 48 MB | spark.reducer.maxSizeInFlight = 72MB ( 48MB * 1.5) |
性能对比 :

数据分区合并
优化点 : 提升 Reduce 阶段的 CPU 利用率
该数据集在内存的精确大小 :
def sizeNew(func: => DataFrame, spark: => SparkSession): String = {val result = funcval lp = result.queryExecution.logicalval size = spark.sessionState.executePlan(lp).optimizedPlan.stats.sizeInByte"Estimated size: " + size/1024 + "KB"
}
把 applyDistinctDF 作实参,调用 sizeNew 函数,返回大小 = 2.6 GB
- 将数据集尺寸/并行度(spark.sql.shuffle.partitions = 200) = Reduce 每个数据分片的存储大小 ( 2.6 GB / 200 = 13 MB)
- 数据分片大小在 200 MB 左右为宜,13 MB 太小
优化设置 :
- 计算集群配置 Executors core = 3 * 2 = 6,其
minPartitionNum为 6
# 开启 AQE
spark.sql.adaptive.enabled = true# 自动分区合并
spark.sql.adaptive.coalescePartitions.enabled = true
# 合并后的大小
spark.sql.adaptive.advisoryPartitionSizeInBytes = 160MB/200MB/210MB/400MB
# 分区合并后的最小分区数
spark.sqladaptive.coalescePartitions.minPartitionNum = 6
总结 :
- 并行度过高、数据分片过小,CPU 调度开销会变大,执行性能也变差
- 检验值 : 分片粒度为 200 MB 左右时,执行性能是最优的
- 并行度过低、数据分片过大,CPU 数据处理开销也会过大,执行性能会锐减
性能对比 :

加 Cache
Cache : 避免数据集在磁盘中的重复扫描与重复计算
applyDistinctDF.cache
applyDistinctDF.countval result02_01 = applyDistinctDF.groupBy(col("carNum")).agg(count(lit(1)).alias("x_axis")).groupBy(col("x_axis")).agg(count(lit(1)).alias("y_axis")).orderBy("x_axis")result02_01.write.format("csv").save("_")
性能对比 :

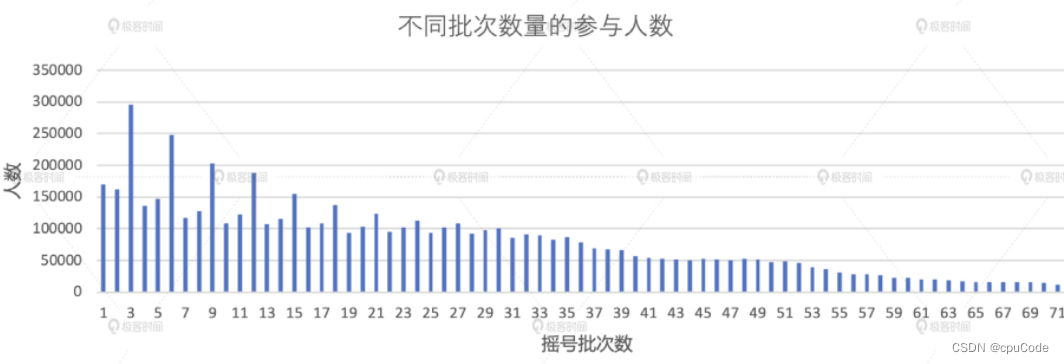
得到中签者的摇号次数
val result02_02 = applyDistinctDF.join(luckyDogsDF.select("carNum"), Seq("carNum"), "inner").groupBy(col("carNum")).agg(count(lit(1)).alias("x_axis")).groupBy(col("x_axis")).agg(count(lit(1)).alias("y_axis")).orderBy("x_axis")result02_02.write.format("csv").save("_")
SQL 实现 :
with t3 as (selectcarNum,count(1) as x_axisfrom applyDistinctDF t1 join luckyDogsDF t2on t1.carNum = t2.carNumgroup by carNum
)
selectx_axis,count(1) as y_axis
from t3
group by x_axis
order by x_axis
优化
分析 : 计算中有一次数据关联,两次分组、聚合,排序
- applyDistinctDF 有 1.35 亿条记录
- luckyDogsDF 有 115 w条记录
- 大表 Join 小表,最先想用广播变量
用广播变量来优化大小表关联计算 :
- 估算小表在内存中的存储大小
- 设置广播阈值
spark.sql.autoBroadcastJoinThreshold
用 sizeNew 计算 luckyDogsDF ,得到大小 = 18.5MB
设置广播阈值要大于 18.5MB ,即 : 设置为 20MB :
spark.sql.autoBroadcastJoinThreshold = 20MB
性能对比 :

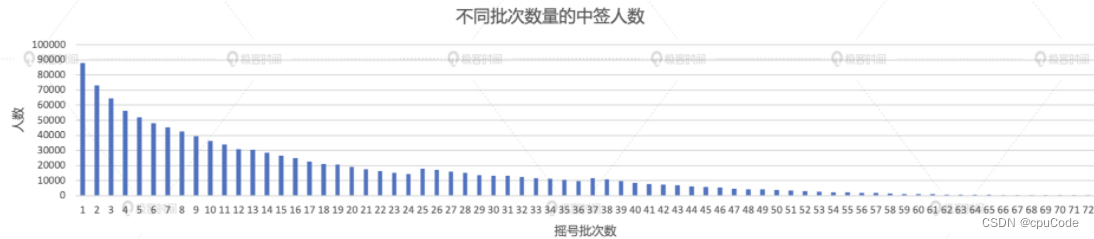
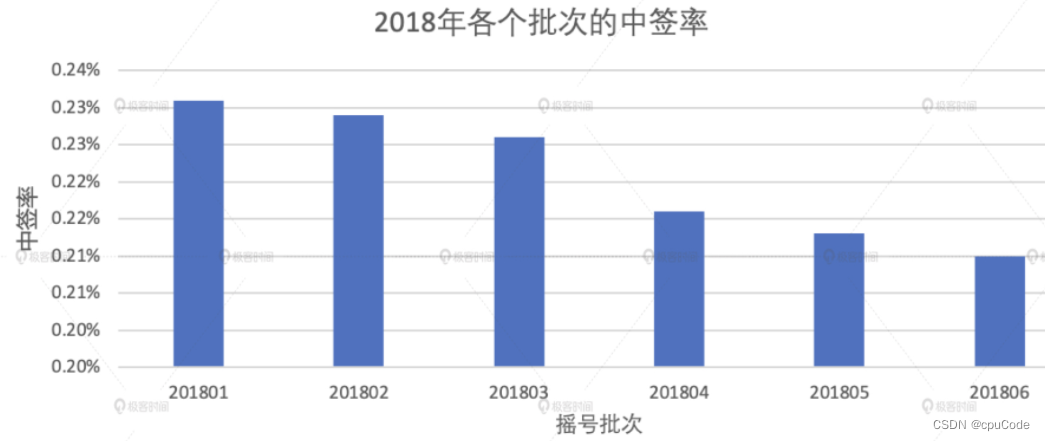
中签率的变化趋势
计算中签率,分别统计每个摇号批次中的申请者和中签者人数
// 统计每批次申请者的人数
val apply_denominator = applyDistinctDF.groupBy(col("batchNum")).agg(count(lit(1)).alias("denominator"))// 统计每批次中签者的人数
val lucky_molecule = luckyDogsDF.groupBy(col("batchNum")).agg(count(lit(1)).alias("molecule"))val result03 = apply_denominator.join(lucky_molecule.select, Seq("batchNum"), "inner").withColumn("ratio", round(col("molecule")/ col("denominator"), 5)).orderBy("batchNum")result03.write.format("csv").save("_")
SQL 实现 :
with t1 as (selectbatchNum,count(1) as denominatorfrom applyDistinctDFgroup by batchNum
),
t2 as (selectbatchNum,count(1) as moleculefrom luckyDogsDFgroup by batchNum
)
selectbatchNum,round(molecule/denominator, 5) as ratio
from t1 join t2 on t1.batchNum = t2.batchNum
order by batchNum
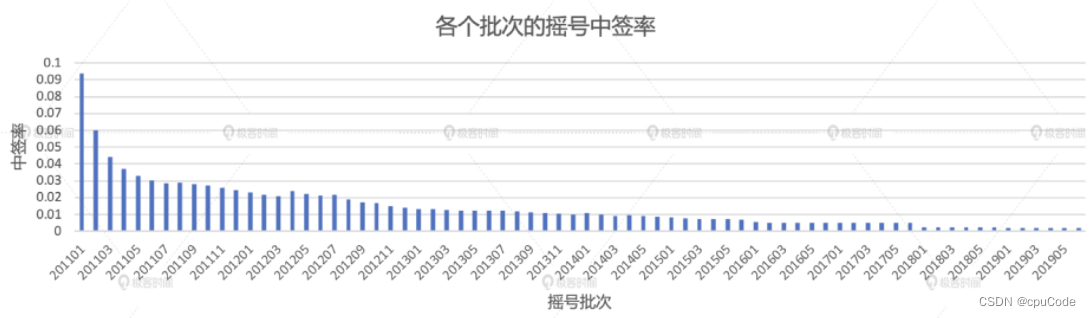
中签率局部洞察
统计 2018 年的中签率
// 筛选出2018年的中签数据,并按照批次统计中签人数
val lucky_molecule_2018 = luckyDogsDF.filter(col("batchNum").like("2018%")).groupBy(col("batchNum")).agg(count(lit(1)).alias("molecule"))// 通过与筛选出的中签数据按照批次做关联,计算每期的中签率
val result04 = apply_denominator.join(lucky_molecule_2018, Seq("batchNum"), "inner").withColumn("ratio", round(col("molecule")/ col("denominator"), 5)).orderBy("batchNum")result04.write.format("csv").save("_")
SQL 实现 :
with t1 as (selectbatchNum,count(1) as moleculefrom luckyDogsDFwhere batchNum like '2018%'group by batchNum
)
selectbatchNum,round(molecule/denominator, 5)
from apply_denominator t2 on t1.batchNum = t2.batchNum
order by batchNum
优化
DPP 的条件 :
- 事实表必须是分区表,且分区字段(可以是多个)必须包含 Join Key
- DPP 仅支持等值 Joins,不支持大于、小于这种不等值关联关系
- 维表过滤后的数据集,要小于广播阈值,调整
spark.sql.autoBroadcastJoinThreshold
DPP 优化 :
- 降低事实表 applyDistinctDF 的磁盘扫描量
applyDistinctDF.select("batchNum", "carNum").distinctapplyDistinct.count
性能对比 :

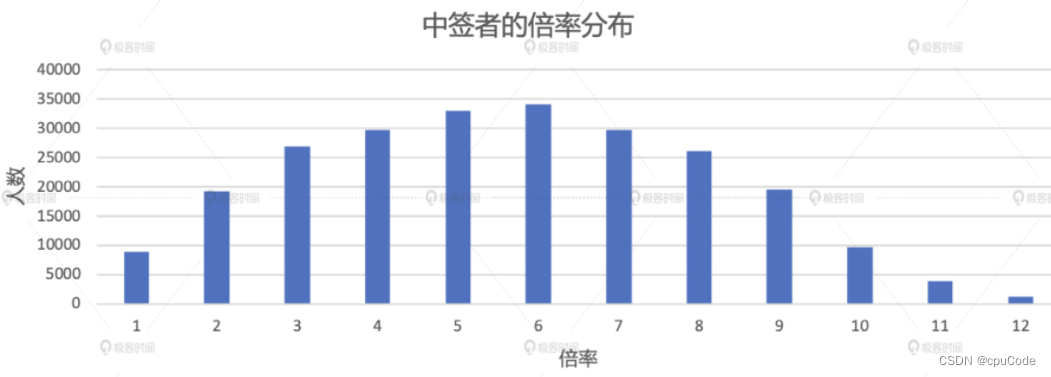
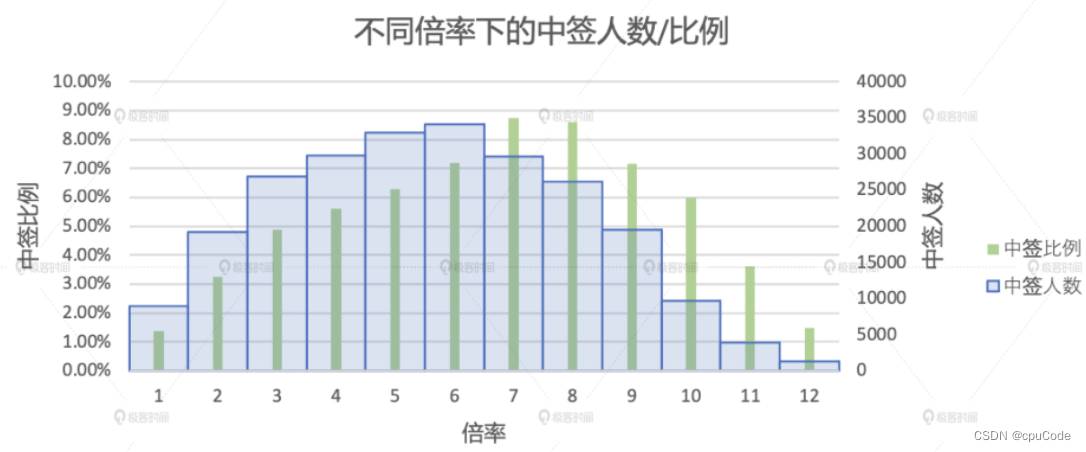
倍率分析
倍率的分布情况 :
- 不同倍率下的中签人数
- 不同倍率下的中签比例
2016 年后的不同倍率下的中签人数 :
val result05_01 = applyNumbersDF.join(luckyDogsDF.filter(col("batchNum") >= "201601").select("carNum"), Seq("carNum"), "inner").groupBy(col("batchNum"), col("carNum")).agg(count(lit(1)).alias("multiplier")).groupBy("carNum").agg(max("multiplier").alias("multiplier")).groupBy("multiplier").agg(count(lit(1)).alias("cnt")).orderBy("multiplier")result05_01.write.format("csv").save("_")
with t3 as (selectbatchNum,carNum,count(1) as multiplierfrom applyNumbersDF t1 join luckyDogsDF t2 on t1.carNum = t2.carNumwhere t2.batchNum >= '201601'group by batchNum, carNum
),
t4 as (selectcarNum,max(multiplier) as multiplierfrom t3group by carNum
)
selectmultiplier,count(1) as cnt
from t4
group by multiplier
order by multiplier;
优化
关联中的 Join Key 是 carNum (非分区键),所以无法用 DPP 机制优化
将大表 Join 小表 , SMJ 转 BHJ :
- 计算 luckyDogsDF 的内存大小,确保 < 广播阈值,利用 Spark SQL 的静态优化机制将 SMJ 转为 BHJ
- 确保过滤后 luckyDogsDF < 广播阈值,利用 Spark SQL 的 AQE 机制动态将 SMJ 转为 BHJ
# 静态BHJ
spark.sql.autoBroadcastJoinThreshold = 20MB# AQE 动态BHJ
spark.sql.autoBroadcastJoinThreshold = 10MB
性能对比 :

计算不同倍率人群的中签比例
// Step01: 过滤出2016-2019申请者数据,统计出每个申请者在每期内的倍率,并在所有批次中选取
val apply_multiplier_2016_2019 = applyNumbersDF.filter(col("batchNum") >= "201601").groupBy(col("batchNum"), col("carNum")).agg(count(lit(1)).alias("multiplier")).groupBy("carNum").agg(max("multiplier").alias("multiplier")).groupBy("multiplier").agg(count(lit(1)).alias("apply_cnt"))// Step02: 将各个倍率下的申请人数与各个倍率下的中签人数左关联,并求出各个倍率下的中签率
val result05_02 = apply_multiplier_2016_2019.join(result05_01.withColumnRenamed("cnt", "lucy_cnt"), Seq("multiplier"), "left").na.fill(0).withColumn("ratio", round(col("lucy_cnt")/ col("apply_cnt"), 5)).orderBy("multiplier")result05_02.write.format("csv").save("_")
SQL 实现 :
with t5 as (selectbatchNum,carNumcount(1) as multiplierfrom applyNumbersDF where batchNum >= '201601'group by batchNum, carNum
),
t6 as (selectcarNum,max(multiplier) as multiplierfrom t1group by carNum
),
t7 as (selectmultiplier,count(1) as apply_cntfrom t2 group by multiplier
)
select multiplier,round(coalesce(lucy_cnt, 0)/ apply_cnt, 5) as ratio
from t7 left left join t5 on t5.multiplier = t7.multiplier
order by multiplier;
相关文章:
Spark 应用调优
Spark 应用调优人数统计优化摇号次数分布优化Shuffle 常规优化数据分区合并加 Cache优化中签率的变化趋势中签率局部洞察优化倍率分析优化表信息 : apply : 申请者 : 事实表lucky : 中签者表 : 维度表两张表的 Schema ( batchNum,carNum ) : ( 摇号批次,…...
synchronized 与 volatile 关键字
目录1.前言1.synchronized 关键字1. 互斥2.保证内存可见性3.可重入2. volatile 关键字1.保证内存可见性2.无法保证原子性3.synchronized 与 volatile 的区别1.前言 synchronized关键字和volatile是大家在Java多线程学习时接触的两个关键字,很多同学可能学习完就忘记…...

【0成本搭建个人博客】——Hexo+Node.js+Gitee Pages
目录 1、下载安装Git 2、下载安装Node.js 3、使用Hexo进行博客的搭建 4、更改博客样式 5、将博客上传到Gitee 6、更新博客 首先看一下Hexo的博客的效果。 1、下载安装Git Git 是一个开源的分布式版本控制系统,可以有效、高速地处理从很小到非常大的项目版本…...

【面试实战】认证授权流程及原理分析
认证授权流程及原理分析 1、认证 (Authentication) 和授权 (Authorization)的区别是什么?2、什么是Cookie ? Cookie的作用是什么?如何在服务端使用 Cookie ?3、Cookie 和 Session 有什么区别?如何使用Session进行身份验证?1、认证 (Authentication) 和授权 (Authorizatio…...

TPM命令解析之tpm2_startauthsession
参考网址链接:tpm2-tools/tpm2_startauthsession.1.md at master tpm2-software/tpm2-tools GitHub 命令名称 tpm2_startauthsession 功能 启动一个TPM会话。 命令形式 tpm2_startauthsession [OPTIONS] 描述 启动一个TPM会话。默认是启动一个试验(…...

第14章 局部波动率模型
这学期会时不时更新一下伊曼纽尔德曼(Emanuel Derman) 教授与迈克尔B.米勒(Michael B. Miller)的《The Volatility Smile》这本书,本意是协助导师课程需要,发在这里有意的朋友们可以学习一下,思…...

云原生周刊:开源“赢了”,但它可持续吗?
日前召开的 State of Open 会议上,开源“赢了”,但如果政府和企业不站出来确保生态系统在未来的弹性和可持续性,那么它仍然会失败。 OpenUK 首席执行官 Amanda Brock 在开幕式上表示,数字化和开源在过去 5 到 10 年的进步提升了工…...
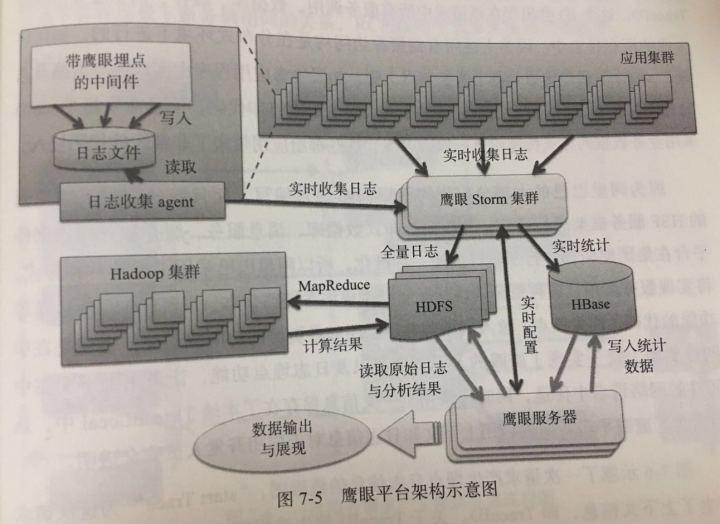
读《企业IT架构转型之道》
本书还没读完,暂摘抄一些概念,因为自身做的新系统也在转型,从单体式到一体化一年来遇到很多问题有技术上的,也有团队协作的,过程是痛苦且复杂的,所以在刚翻阅前几十页时候,对于淘宝技术团队转型…...
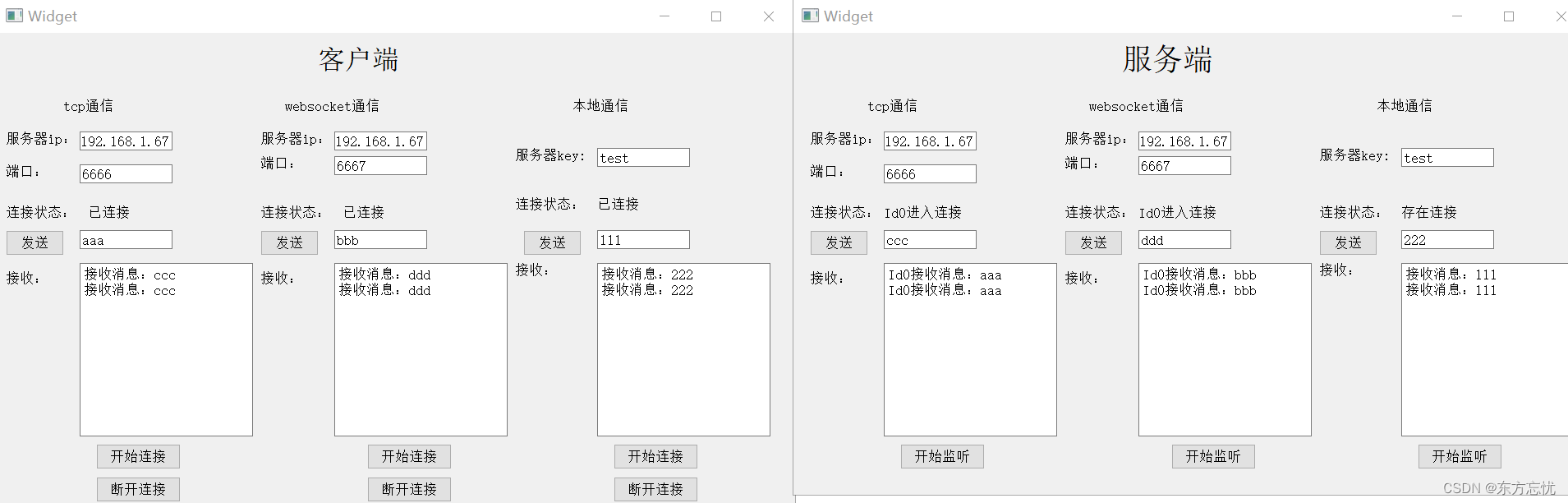
Qt中的QTcpSocket、QWebSocket和QLocalSocket
同时实现了QTcpSocket、QWebSocket和QLocalSocket的简单通讯deamon,支持自动获取本机ip,多个客户端交互。在这个基础上你可以自己加错误检测、心跳发送、包封装解析和客户端自动重连等功能。 获取本机电脑ip: QString Widget::getIp() {QSt…...

枚举学习贴
1. 概述 1.1 是什么 枚举对应英文(enumeration, 简写 enum)枚举是一组常量的集合。可以这里理解:枚举属于一种特殊的类,里面只包含一组有限的特定的对象 1.2 枚举的二种实现方式 自定义类实现枚举使用 enum 关键字实现枚举 1.3 什么时候用 存在有限…...
【C++】30h速成C++从入门到精通(继承)
继承的概念及定义继承的概念继承(inheritance)机制是面向对象程序设计使代码可以复用的重要手段,它允许程序员在保持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象程序…...

Java多线程还不会的进来吧,为你量身打造
💗推荐阅读文章💗 🌸JavaSE系列🌸👉1️⃣《JavaSE系列教程》🌺MySQL系列🌺👉2️⃣《MySQL系列教程》🍀JavaWeb系列🍀👉3️⃣《JavaWeb系列教程》…...

8 神经网络及Python实现
1 人工神经网络的历史 1.1 生物模型 1943年,心理学家W.S.McCulloch和数理逻辑学家W.Pitts基于神经元的生理特征,建立了单个神经元的数学模型(MP模型)。 1.2 数学模型 ykφ(∑i1mωkixibk)φ(WkTXb)y_{k}\varphi\left(\sum_{i1…...
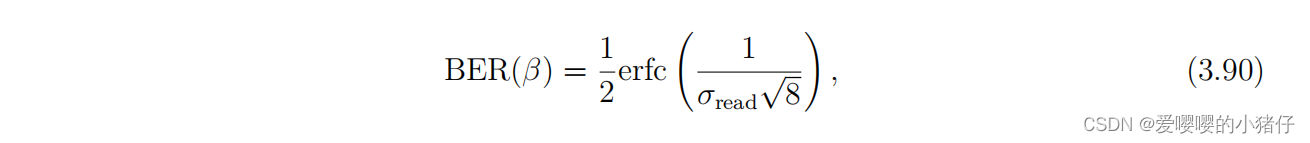
使用QIS(Quantum Image Sensor)图像重建总结(1)
最近看了不少使用QIS重建图像的文章,觉得比较完整详细的还是Abhiram Gnanasambandam的博士论文:https://hammer.purdue.edu/articles/thesis/Computer_vision_at_low_light/20057081 1 介绍 讲述了又墨子的小孔成像原理,到交卷相机…...
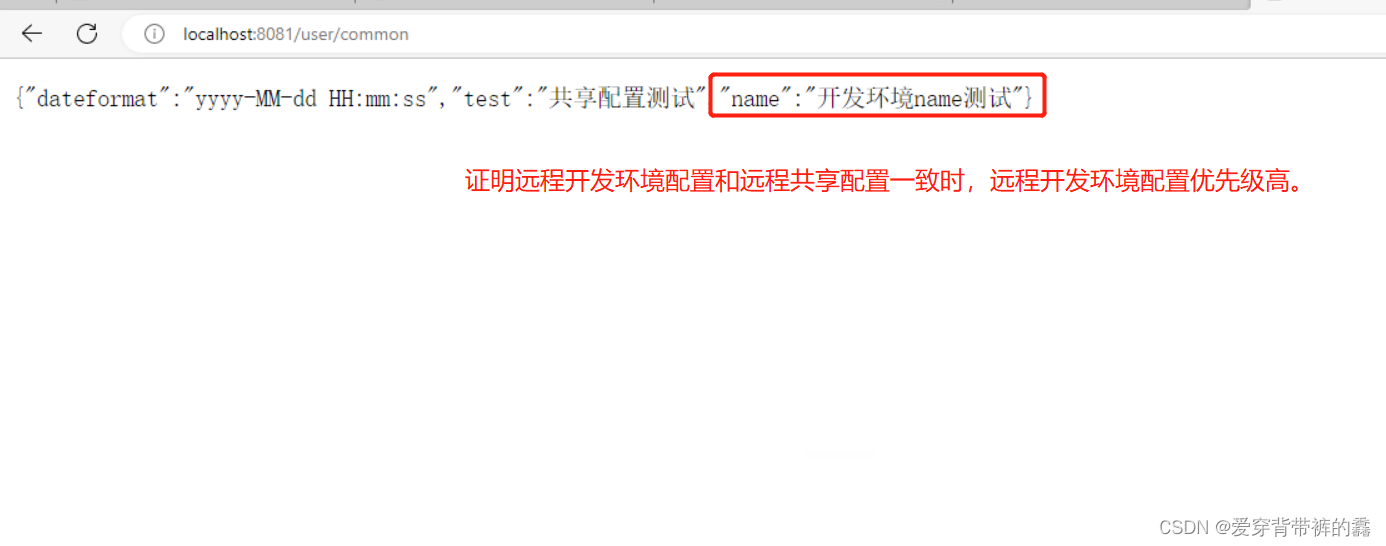
【SpringCloud】SpringCloud教程之Nacos实战(二)
目录前言一.Nacos实现配置管理二.Nacos拉取配置三.Nacos配置热更新(自动刷新,不需要重启服务)1.在有Value注入变量所在类添加注解2.新建类用于属性加载和配置热更新四.Nacos多环境配置共享1.多环境共享配置2.配置的加载优先级测试3.配置优先级前言 Nacos实战一&…...

利用Qemu工具仿真ARM64平台
Windows系统利用Qemu仿真ARM64平台0 写在最前1 Windows安装Qemu1.1 下载Qemu1.2 安装Qemu1.3 添加环境变量1.4测试安装是否成功2. Qemu安装Ubuntu-Server-Arm-642.1 安装前的准备2.2 安装Ubuntu server arm 64位镜像3 Windows配置Qemu网络和传输文件3.1 参考内容3.2 Windows安装…...
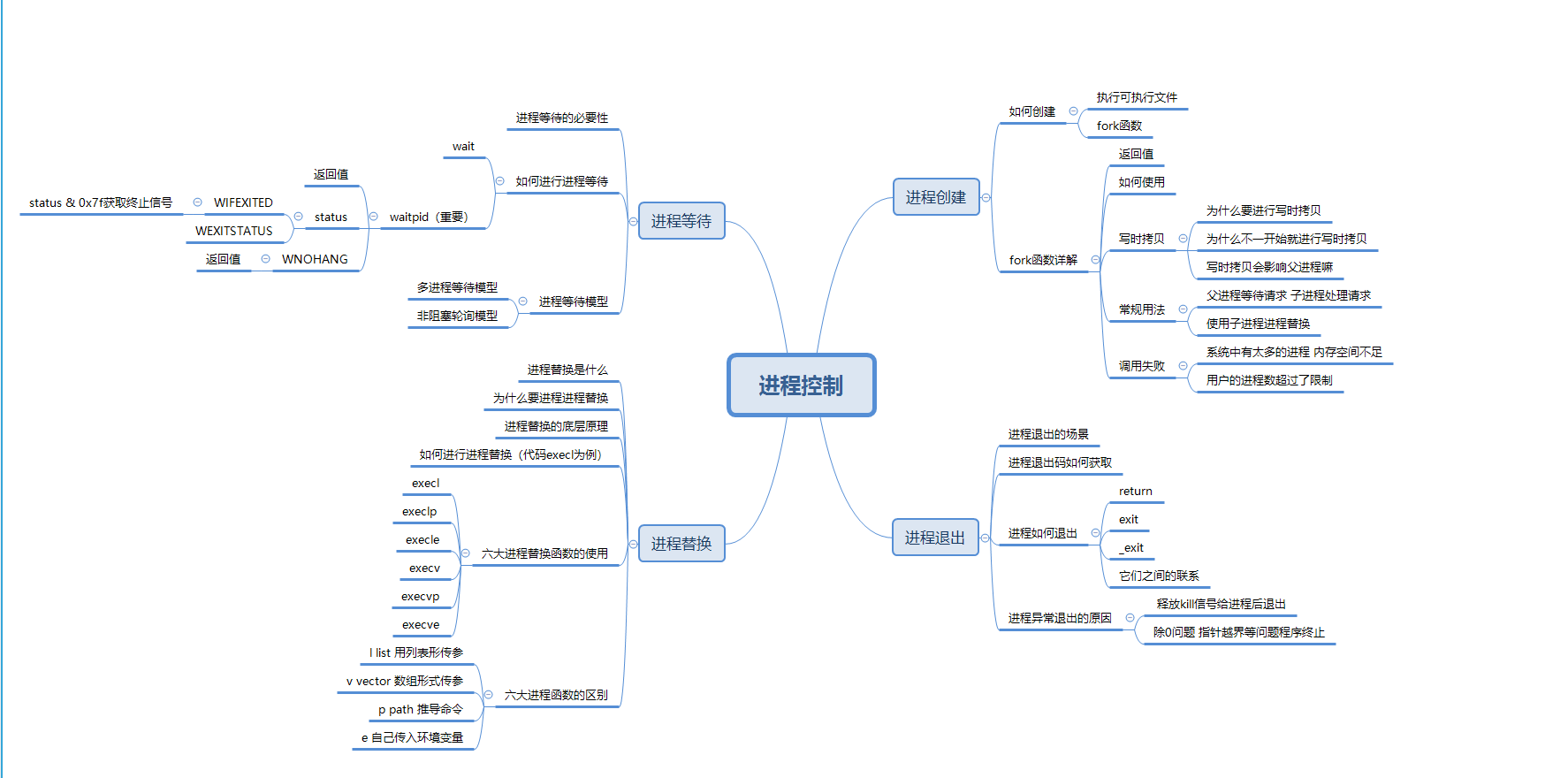
【Hello Linux】进程控制 (内含思维导图)
作者:小萌新 专栏:Linux 作者简介:大二学生 希望能和大家一起进步! 本篇博客简介:简单介绍下进程的控制 包括进程启动 进程终止 进程等待 进程替换等概念 进程控制介绍进程创建fork函数fork函数的返回值fork函数的使用…...

嵌入式linux物联网毕业设计项目智能语音识别基于stm32mp157开发板
stm32mp157开发板FS-MP1A是华清远见自主研发的一款高品质、高性价比的Linux单片机二合一的嵌入式教学级开发板。开发板搭载ST的STM32MP157高性能微处理器,集成2个Cortex-A7核和1个Cortex-M4 核,A7核上可以跑Linux操作系统,M4核上可以跑FreeRT…...
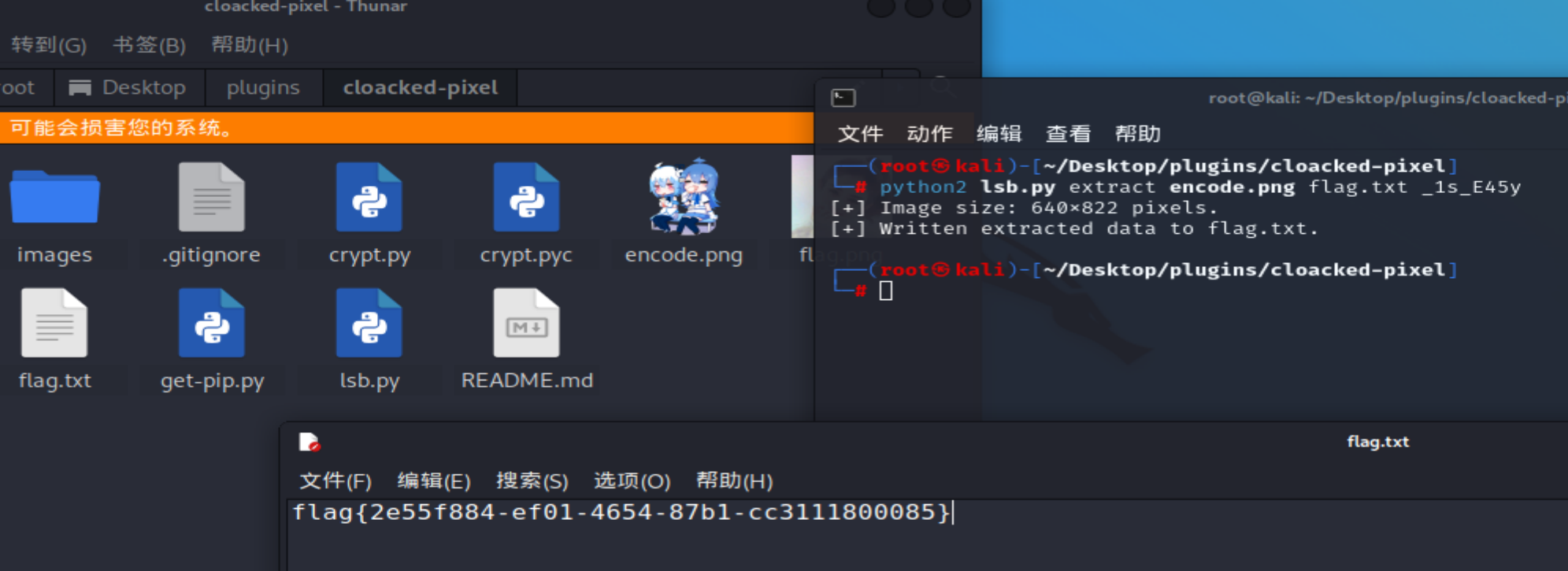
【黄河流域公安院校网络空间安全技能挑战赛】部分wp
文章目录webbabyPHPfunnyPHPEzphp**遍历文件目录的类**1、DirectoryIterator:2、FilesystemIterator:3、**Globlterator**读取文件内容的类:SplFileObjectMisc套娃web babyPHP <?php highlight_file(__FILE__); error_reporting(0);$num $_GET[nu…...

五点CRM系统核心功能是什么
很多企业已经把CRM客户管理系统纳入信息化建设首选,用于提升核心竞争力,改善企业市场、销售、服务、渠道和客户管理等几个方面,并进行创新或转型。CRM系统战略的五个关键要点是:挖掘潜在客户、评估和培育、跟进并成交、分析并提高…...

告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南
告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次开机都看到"需要激活"的提…...

基于WPF开发桌面AI助手:架构设计与实现详解
1. 项目概述:一个开源的WPF桌面AI助手 最近在GitHub上看到一个挺有意思的项目,叫“MayDay-wpf/AIBotPublic”。光看名字,可能有点摸不着头脑,但点进去研究一下,你会发现这其实是一个用WPF(Windows Present…...

UEFITool深度解析:实战指南与高效使用技巧
UEFITool深度解析:实战指南与高效使用技巧 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool UEFITool是一款专为UEFI固件分析设计的开源工具,能够将复杂的二进制固件映像…...

Arm Cortex-X2/X3架构解析与性能优化实践
1. Arm Cortex-X2/X3集群架构概述在Armv9架构的高性能计算领域,Cortex-X2和X3代表了当前最先进的CPU设计理念。作为DynamIQ共享单元(DSU)的核心组件,它们通过可配置的缓存层次结构和智能一致性协议,为现代异构计算提供了灵活的解决方案。1.1 …...

罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性
罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求…...

基于MCP协议构建AI金融数据可视化服务器:从原理到实战部署
1. 项目概述:一个为AI智能体提供实时金融数据可视化的MCP服务器最近在折腾AI智能体(Agent)的生态,发现一个挺有意思的痛点:当你想让AI帮你分析股票、基金或者加密货币时,它往往只能给你干巴巴的数字和文字描…...

构建通用Docker工具镜像:从设计到实践的全流程指南
1. 项目概述:一个“反重力”的Docker镜像?看到这个镜像名runzhliu/docker-antigravity,很多人的第一反应可能是好奇和疑惑。在Docker Hub上,以“antigravity”(反重力)命名的镜像并不常见,它不像…...

云原生安全工具:保护云原生环境
云原生安全工具:保护云原生环境 一、云原生安全工具概述 1.1 云原生安全工具的定义 云原生安全工具是指专为云原生环境设计的安全工具和解决方案。它们用于保护容器、Kubernetes集群、微服务和Serverless应用的安全。 1.2 云原生安全工具的价值 安全防护:…...

基于Claude API构建可编程AI智能体:从对话到自动化生产单元
1. 项目概述:从Claude中“招聘”一个AI伙伴最近在GitHub上看到一个挺有意思的项目,叫“hire-from-claude”。初看这个标题,你可能会有点摸不着头脑:Claude不是Anthropic公司开发的那个AI助手吗?怎么还能从它那里“招聘…...

知乎API完全指南:用Python轻松获取知乎数据的5个核心技巧
知乎API完全指南:用Python轻松获取知乎数据的5个核心技巧 【免费下载链接】zhihu-api Zhihu API for Humans 项目地址: https://gitcode.com/gh_mirrors/zh/zhihu-api 在当今数据驱动的时代,知乎数据采集和Python API开发已成为获取高质量中文知识…...