大模型与数据分析:探索Text-to-SQL

当今大模型如此火热,作为一名数据同学,持续在关注LLM是如何应用在数据分析中的,也关注到很多公司推出了AI数智助手的产品,比如火山引擎数智平台VeDI—AI助手、 Kyligence Copilot AI数智助理、ThoughtSpot等,通过接入人工智能大模型,提升数据处理和查询分析的效率。智能数据分析助手,采用对话式分析技术,每个普通人都可以与数据进行随时随地的实时交互,根据用户的使用反馈,不断学习,自我迭代找到答案,并在团队内分享对数据的见解。
简单分析一下数据分析的发展阶段:第一阶段,以静态报表为主,传统BI和静态报表基本上都是面向开发部门的,业务部门提出需求之后,由开发根据报表工具开发出固定的报表,然后业务部门查看报表结果。第二阶段,敏捷BI自助式分析,在业务部门提出需求之后,数据分析可以基于敏捷BI的工具帮助业务部门快速获取所需的数据,帮助他们获得所需要的结果。第三阶段,不管是基于大模型的AskBI还是增强分析,都是直接面向业务的,其理念是业务部门直接使用对话式BI工具能够解决问题,获得所需的数据结果。这一过程无需像之前那样依赖开发部门开发报表,或者数据分析师基于敏捷BI再提供数据结果,而是直接由业务部门推进落地。

整体方案
通过多家数AI数智助手调研,实现智能数据分析的核心有:一是以指标为中心,二是大模型。其中也分享出了如何把指标平台+AI技术落地方案,提出了:人人用数=AI Copilot + 指标体系 + 合理成本的关键技术观点。
指标体系给到我们的是一个通用的数据语言,当我们每一个人都用数据来沟通时,我们遇到的第一个障碍一定是缺乏通用的语言。就像普通话让13 亿中国人能够自由沟通,数据的解释权有一个标准一致的口径也是非常重要的,是数据共享和协作的前提。
指标数据最理想的使用场景就是,想要就有,数据准确,可视化展示。用户期望能够随时查看自己想要的业务指标数据,绝大多数人都有自己的使用指标的渠道和方法,但是需要用户熟悉系统的操作、数据内容可能会根据需求提前预设好,如果是需要指标的话,就依赖支持者的时间了,或者需要排期开发。虽然每个人都各显其通能够拿到数据,但于用户体验来说,还是需要有操作和时间成本。
智能化的指标应用可以大幅提高数据指标的用户体验和效率。我们希望的场景是,用户对着手机:“告诉我昨天的DAU、用户留存、销售额”,系统就能快速的反馈给用户这三个指标的结果,并且是准确的。
指标的加工处理到使用中间有很多过程,从数据沉淀->数仓加工->口径定义->报表->系统->用户,中间流程最直接的方式就是自然语言直接对接到数据。
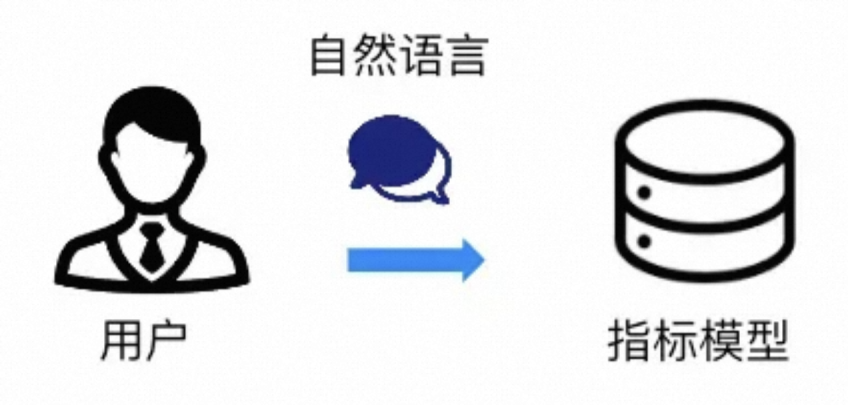
▐ 通用方案
通用做法是基于指标要素生产出指标的模型(提前预算好所有的可能),通过NLP技术,将自然语言转译成SQL,直接读取指标模型,大概的技术思路如下:
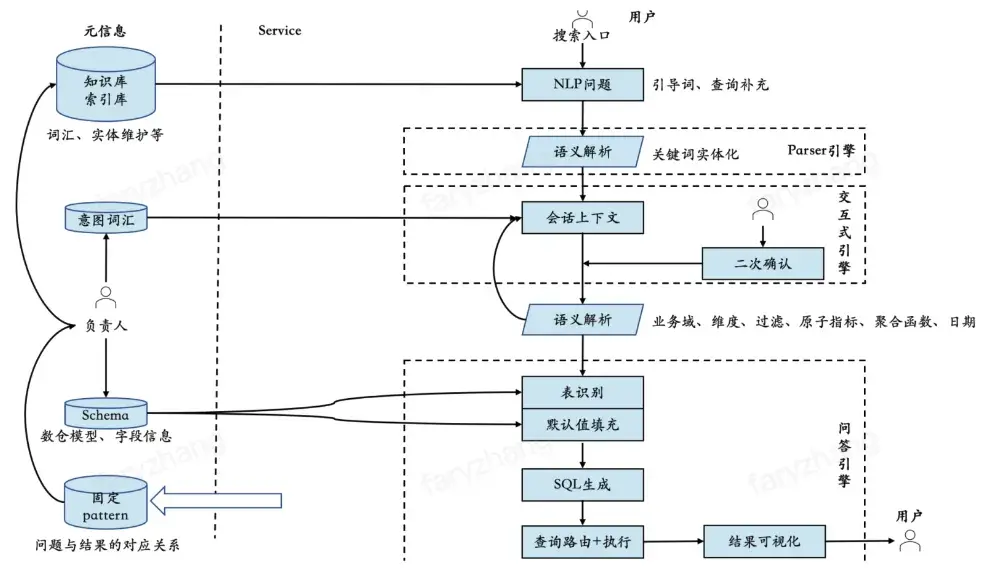
▐ 基于大模型
目标:通过大模型技术,打造用户在灵活搜索指标的时候能够快速反馈给用户正确的指标体验。
核心聚焦:
让系统尽可能的去理解自然语言,并准确的把它转换成可执行的SQL。
尽最大的可能覆盖用户的灵活需求,提高指标要素组合的成指标的组合数量。
基于LLM生成准确可执行SQL的关键思路:把指标管理模型的定义、指标要素等元数据信息送给LLM当作prompt进行指标搜索与生成。

Text-to-SQL
Text-to-SQL(简写为T2S,或者是Text2SQL),顾名思义就是把文本转化为SQL语言,更学术一点的定义是:把数据库领域下的自然语言(Natural Language,简写为NL)问题,转化为在关系型数据库中可以执行的结构化查询语言(Structured Query Language,简写为SQL)。
▐ Text-to-SQL是什么
Text-to-SQL任务相对正式的定义:在给定关系型数据库(或表)的前提下,由用户的提问生成相应的SQL查询语句。下图是spider数据集的样例,问题:有哪些系的教师平均工资高于总体平均值,请返回这些系的名字以及他们的平均工资。可以看到该问题对应的SQL语句是很复杂的,并且有嵌套关系。

▐ 数据集
常见的数据集有GenQuery、Scholar、WikiSQL、Spider、Spider-SYN、Spider-DK、Spider-SSP、CSpider、SQUALL、DuSQL、ATIS、SparC、CHASE等。
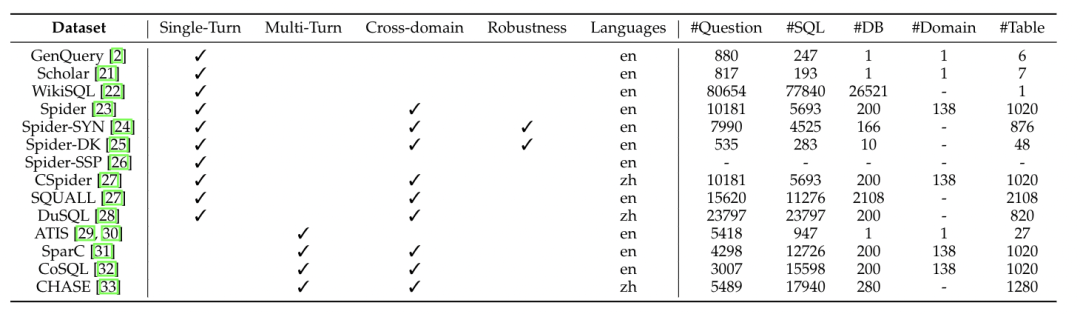
数据集的分类有单领域和交叉领域;有单轮对话和多轮对话;有简单问题和复杂问题;有中文语言和英文语言;有单张表和多张表等。重点介绍两个数据集:WikiSQL、Spider。
WikiSQL
WikiSQL数据集是目前规模最大的Text-to-SQL数据集,由2017年美国的Salesforce公司提出,场景来源于Wikipedia,属于单领域。数据标注采用外包。
包含了80654个自然语言问题,77840个SQL语句。
包含了26521张数据库表,1个数据库只有1张表。
预测的SQL语句形式比较简单,基本为一个SQL主句加上0-3个WHERE子句条件限制构成,如下图所示:
Spider
Spider数据集是多数据库、多表、单轮查询的Text-to-SQL数据集,也是业界公认难度最大的大规模跨领域评测榜单,由2018年耶鲁大学提出,由11名耶鲁大学学生标注。
10181个自然语言问题,5693个SQL语句。
涉及138个不同领域的200多个数据库。
难易程度分为:简单、中等、困难、特别困难。如下图所示

Spider数据集论文地址:https://arxiv.org/pdf/1809.08887.pdf。
CSpider是西湖大学在EMNLP2019上提出了一个中文text-to-sql的数据集,主要是选择Spider作为源数据集进行了问题的翻译,并利用SyntaxSQLNet作为基线系统进行了测试,同时探索了在中文上产生的一些额外的挑战,包括中文问题对英文数据库的对应问题(question-to-DBmapping)、中文的分词问题以及一些其他的语言现象。
▐ 评估指标
目前广泛使用的是执行准确率(Execution Accuracy,简称EX)和逻辑形式准确率(WxactMatch,简称EM)。
执行准确率
定义:计算SQL执行结果正确的数量在数据集中的比例。
缺点:存在高估的可能。因为一个完全不同的非标准的SQL可能查出于与标准SQL相同的结果(例如,空结果),这时也会判为正确。
举个例子:假如有个学生表,我们想要查询学生表中年龄等于19的学生姓名,就如“SELECT sname FROM Student where age = 19”所示,通过数据库执行标准SQL后得到结果为null;此时Text-to-SQL模型预测的SQL为“SELECT sname FROM Student where age = 20”,通过数据库执行后也得到结果为null。虽然预测的SQL跟标注的SQL不一致,但是结果是一样的,根据执行准确率指标来比较,那么就认为模型预测是正确的。
# groundtruth_SQL
SELECT sname FROM Student where age = 19;
# SQL执行结果
null# predict_SQL
SELECT sname FROM Student where age = 20;
# SQL执行结果
null逻辑形式准确率
定义:计算模型生成的SQL和标注SQL的匹配程度。
缺点:存在低估的可能。如一个SQL执行结果是正确的,但于标注SQL的字符串并非完全匹配,例如,只是select 列的顺序不同或SQL查询目的完全相同的不同SQL。为了解决一部分该问题,有研究指出了一种查询匹配精度query match accuracy:将生成的SQL和标注SQL都以标准形式表示,再计算两者匹配精度。这种方法只解决了由于排序问题而导致的误判。另外,通过对列和表进行排序并使用标准化别名来对SQL进行规范化,也可以消除不同SQL格式导致的误判问题。
举个例子:同样地,假如有个学生表,我们想要查询学生表中年龄等于19的学生姓名和学生学号。就如“SELECT sname FROM Student where age = 19”所示,通过数据库执行标准SQL后得到结果为(张三,123456);此时Text-to-SQL模型预测的SQL为“SELECT sno,sname FROM Student where age = 19”,通过数据库执行后也得到结果为(123456,张三),如果从逻辑形式准确率指标来看,因为SQL并不是一模一样,尽管两者只是筛选顺序的语序问题,所以会认为模型预测是错误的。
# groundtruth_SQL
SELECT sname,sno FROM Student where age = 19;
# SQL执行结果
张三,123456# predict_SQL
SELECT sno,sname FROM Student where age = 19;
# SQL执行结果
123456,张三▐ 研究方法
在深度学习的研究背景下,将 Text-to-SQL看作一个类似神经机器翻译的任务,主要采取seq2seq的模型框架。基线模型seq2seq在加入Attention、Copying等机制后,能够在ATIS、GeoQuery数据集上达到84%的精确匹配,但是在WikiSQL上只能达到23.3%的精确匹配,37.0%的执行正确率;在Spider上则只能达到5~6%的精确匹配。
究其原因,可以从编码和解码两个角度来看。首先编码方面,自然语言问句与数据库之间需要形成很好的对齐或映射关系,即问题中到底涉及了哪些表格中的哪些实体词,以及问句中的词语触发了哪些选择条件、聚类操作等;另一方面在解码部分,SQL作为一种形式定义的程序语言,本身对语法的要求更严格(关键字顺序固定)以及语义的界限更清晰,失之毫厘差之千里。普通的seq2seq框架并不具备建模这些信息的能力。
于是,主流模型的改进与后续工作主要围绕着以下几个方面展开:通过更强的表示(BERT、XLNet)、更好的结构(GNN)来显式地加强Encoder端的对齐关系及利用结构信息;通过树形结构解码、填槽类解码来减小搜索解空间,以增加SQL语句的正确性;通过中间表示等技术提高SQL语言的抽象性;通过定义新的对齐特征,利用重排序技术,对beamsearch得到的多条候选结果进行正确答案的挑选;以及非常有效的数据增强方法。
基于模板和匹配的方法
因为输出SQL本质上:是一个符合语法、有逻辑结构的序列,本身具有很强范式结构,所以可以采取基于模板和规则的方法。简单SQL语句都可以抽象成如下图:

简单SQL模板示例:
AGG表示聚合函数,如求MAX,计数COUNT,求MIN。
COLUMN表示需要查询的目标列。
WOP表示多个条件之间的关联规则“与and /或 or”
三元组 [COLUMN, OP, VALUE] 构成了查询条件,分别代表条件列、条件操作符(>、=、<等)、条件值。
*表示目标列和查询条件不止一个!
基于模板和匹配的方法,是早期的研究方法,适用于简单SQL,定义后的sql准确率高;不适合复杂SQL,没有定义模板的SQL不能识别。
基于Seq2Seq框架的方法
对于Text-to-SQL研究而言,本质上属于自然语言处理(Natural Language Processing,NLP),而在NLP领域中,常见的任务可以大概分为如下四个场景,1、N和M代表的是token的数量。
1 -> N:生成任务,比如输入为一张图片,输出图片的文本描述。
N -> 1:分类任务,比如输入为一句话,输出这句话的情感分类。
N -> N:序列标注任务,比如输入一句话,输出该句话的词性标注。
N -> M:机器翻译任务,比如输入一句中文,输出英文翻译。
可以发现的是,Text-to-SQL任务是符合N -> M机器翻译任务的,处理机器翻译任务最主流的方法是基于Seq2Seq框架方法,Seq2Seq是一种基于序列到序列模型的神经网络架构,它由两个部分组成:编码器Encoder和解码Decoder。因此,Text-to-SQL最主流的方法也是基于Seq2Seq框架。
更多学习和研究Text-to-SQL相关内容,可以参考2篇综述文章:《A Survey on Text-to-SQL Parsing: Concepts, Methods, and Future Directions》Text-to-SQL解析的概念、方法和未来方向;《Recent Advances in Text-to-SQL: A Survey of What We Have and What We Expect》Text-to-SQL领域的最新进展:关于我们所拥有该领域的知识以及和所期盼的发展方向的综述。

DIN-SQL
2022年底,ChatGPT爆火,凭借LLM强大的逻辑推理、上下文学习、情景联系等特点,按理说LLM应该可以超过seq2seq、BERT等系列的模型,但是使用少样本、零样本提示方法用LLM解决NL2SQL问题效果却比不上之前的模型。今天分享的这篇来自NLP顶级会议的论文解决了这个问题:如何改进Prompt让LLM超越之前的方法,并让LLM在Spider数据集上霸榜。
论文原文链接:DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction(地址:https://arxiv.org/abs/2304.11015)
摘要:我们研究将复杂的文本到 SQL 任务分解为更小的子任务的问题,以及这种分解如何显着提高大型语言模型 (LLM) 在推理过程中的性能。目前,在具有挑战性的文本到 SQL 数据集(例如 Spider)上,微调模型的性能与使用 LLM 的提示方法之间存在显着差距。我们证明 SQL 查询的生成可以分解为子问题,并且这些子问题的解决方案可以输入到 LLM 中以显着提高其性能。我们对三个 LLM 进行的实验表明,这种方法持续将其简单的小样本性能提高了大约 10%,将 LLM 的准确性推向 SOTA 或超越它。在 Spider 的 Holdout 测试集上,执行准确度方面的 SOTA 为 79.9,使用我们方法的新 SOTA 为 85.3。我们的情境学习方法比许多经过严格调整的模型至少高出 5%。
该论文提出了一种基于少样本提示Few-shot Prompt的新颖方法,将Text-to-SQL的任务分解为多个步骤。
编写SQL查询的思维过程可以分解为:
检测与查询相关的数据库表和列
识别更复杂查询的一般查询结构(例如分组、嵌套、多重联接、集合运算等)
制定任何可以识别的过程子组件
根据子问题的解决方案编写最终查询。
基于这个思维过程,将文本到SQL任务的方法分解为4个模块:
模式链接
查询分类和分解
SQL生成
自我修正
如果问题被简单地分解到正确的粒度级别,LLM就有能解决所有的这些问题。
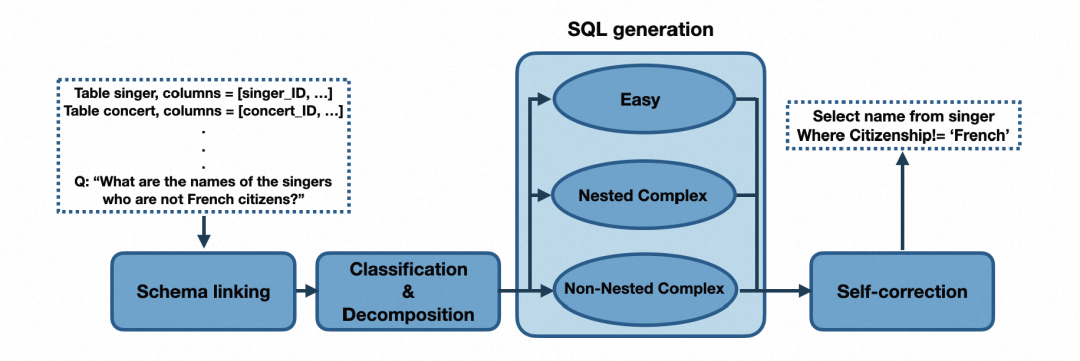
▐ Schema Linking Module
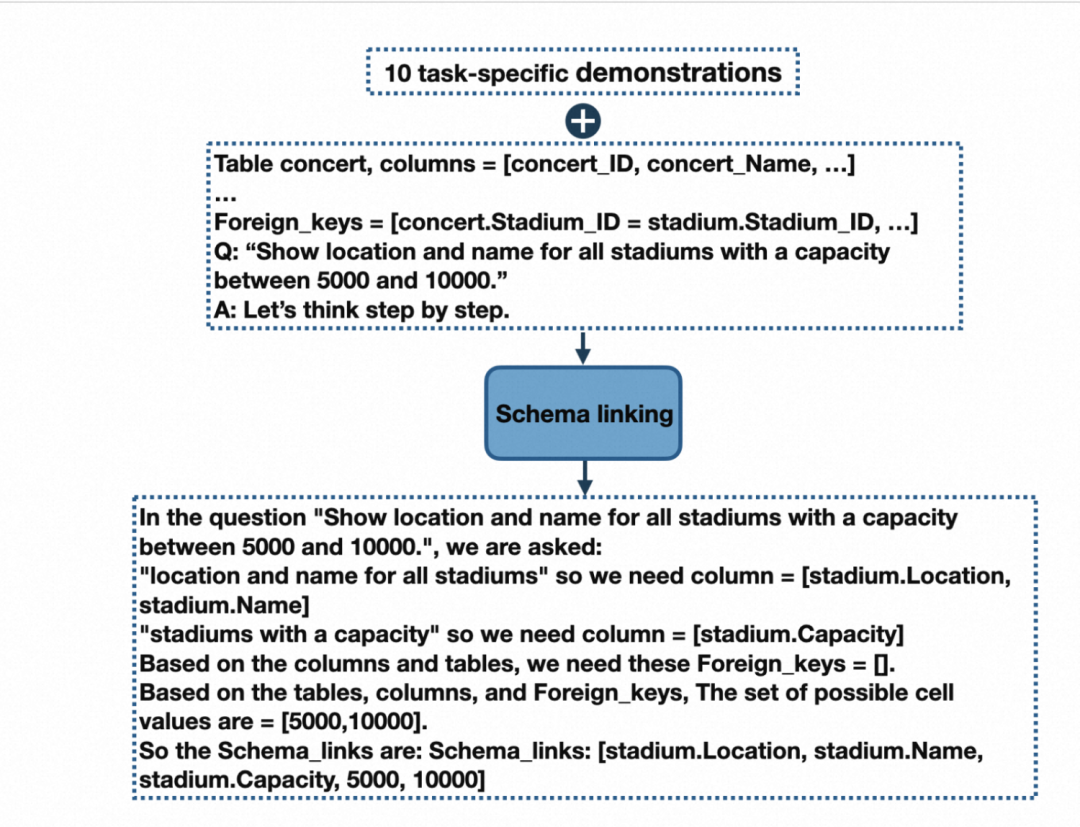
模式链接负责识别自然语言查询中对数据库模式和条件值的引用。它被证明有助于跨领域的通用性和复杂查询的综合(Lei 等人,2020),使其成为几乎所有现有文本到 SQL 方法的关键初步步骤。在我们的案例中,这也是LLM失败次数最多的一个类别(图 2)。我们设计了一个基于提示的模式链接模块。提示包括从 Spider 数据集的训练集中随机选择的 10 个样本按照思路链模板(Wei 等人,2022b),提示以“让我们一步一步思考”开头,正如 Kojima 等人(2022)建议的那样。对于问题中每次提到的列名,都会从给定的数据库模式中选择相应的列及其表。还从问题中提取可能的实体和单元格值。如下图显示模式链接模块的输入和输出的示例。
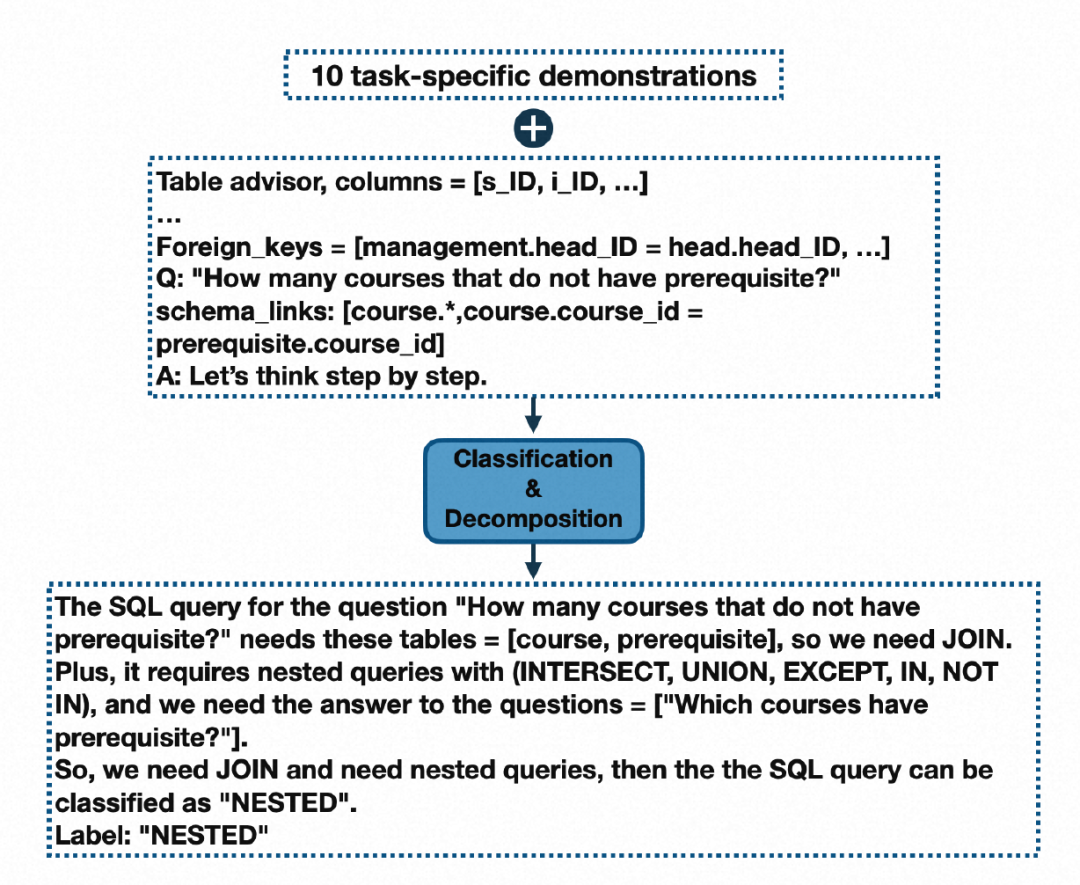
▐ Classification & Decomposition Module
对于每个连接,都有可能未检测到正确的表或连接条件。随着查询中联接数量的增加,至少一个联接无法正确生成的可能性也会增加。缓解该问题的一种方法是引入一个模块来检测要连接的表。此外,一些查询具有过程组件,例如不相关的子查询,它们可以独立生成并与主查询合并。
为了解决这些问题,我们引入了查询分类和分解模块。该模块将每个查询分为三类之一:简单、非嵌套复杂和嵌套复杂。easy 类包括无需连接或嵌套即可回答的单表查询。非嵌套类包括需要连接但没有子查询的查询,而嵌套类中的查询可以需要连接、子查询和集合操作。类标签对于我们的查询生成模块很重要,该模块对每个查询类使用不同的提示。除了类标签之外,查询分类和分解还检测要为非嵌套和嵌套查询以及可能为嵌套查询检测到的任何子查询连接的表集。如下图显示分类和分解模块的输入和输出的示例:
▐ SQL Generation Module
随着查询变得更加复杂,必须合并额外的中间步骤来弥合自然语言问题和 SQL 语句之间的差距。这种差距在文献中被称为不匹配问题(Guo et al, 2019),对 SQL 生成提出了重大挑战,这是因为 SQL 主要是为查询关系数据库而设计的,而不是表示自然语言中的含义。
虽然更复杂的查询可以从思路链式提示中列出中间步骤中受益,但此类列表可能会降低更简单任务的性能(Wei 等人,2022b)。在相同的基础上,我们的查询生成由三个模块组成,每个模块针对不同的类别。
对于我们划分的简单类别中的问题,没有中间步骤的简单的少量提示就足够了。此类示例 Ej 的演示遵循格式 <Qj, Sj, Aj>,其中 Qj 和 Aj 分别给出英语和 SQL 的查询文本,Sj 表示模式链接。
我们的非嵌套复杂类包括需要连接的查询。我们的错误分析(第3节)表明,在简单的几次提示下,找到正确的列和外键来连接两个表对于法学硕士来说可能具有挑战性,特别是当查询需要连接多个表时。为了解决这个问题,我们采用中间表示来弥合查询和 SQL 语句之间的差距。文献中已经介绍了各种中间表示。特别是,SemQL(Guo et al, 2019)删除了在自然语言查询中没有明确对应项的运算符 JOIN ON、FROM 和 GROUP BY,并合并了 HAVING 和 WHERE 子句。NatSQL(Gan 等人,2021)基于 SemQL 构建并删除了集合运算符。作为我们的中间表示,我们使用 NatSQL,它与其他模型结合使用时显示出最先进的性能 (Li et al, 2023a)。非嵌套复杂类的示例 Ej 的演示遵循格式 <Qj, Sj, Ij, Aj>,其中 Sj 和 Ij 分别表示第 j 个示例的模式链接和中间表示。
最后,嵌套复杂类是最复杂的类型,在生成最终答案之前需要几个中间步骤。此类可以包含不仅需要使用嵌套和集合操作(例如 EXCEPT、UNION 和 INTERSECT)的子查询,而且还需要多个表连接的查询,与上一个类相同。为了将问题进一步分解为多个步骤,我们对此类的提示的设计方式是LLM应首先解决子查询,然后使用它们生成最终答案。此类提示遵循格式<Qj, Sj , <Qj1, Aj1, ..., Qjk, Ajk> , Ij, Aj>,其中k表示子问题的数量,Qji和Aji分别表示第i个问题-第一个子问题和第i个子查询。和之前一样,Qj 和 Aj 分别表示英语和 SQL 的查询,Sj 给出模式链接,Ij 是 NatSQL 中间表示。
▐ Self-correction Module
生成的 SQL 查询有时可能会缺少或冗余关键字,例如 DESC、DISTINCT 和聚合函数。我们对多个 LLM 的经验表明,这些问题在较大的 LLM 中不太常见(例如,GPT-4 生成的查询比 CodeX 生成的查询具有更少的错误),但仍然存在。为了解决这个问题,我们提出了一个自我纠正模块,指示模型纠正这些小错误。
这是在零样本设置中实现的,其中仅向模型提供有错误的代码,并要求模型修复错误。我们为自我纠正模块提出了两种不同的提示:通用和温和。通过通用提示,我们要求模型识别并纠正“BUGGY SQL”中的错误。另一方面,温和提示并不假设 SQL 查询有错误,而是要求模型检查任何潜在问题,并提供有关要检查的子句的一些提示。我们的评估表明,通用提示可以在 CodeX 模型中产生更好的结果,而温和的提示对于 GPT-4 模型更有效。除非另有明确说明,否则 DINSQL 中的默认自我更正提示对于 GPT-4 设置为“温和”,对于 CodeX 设置为“通用”。
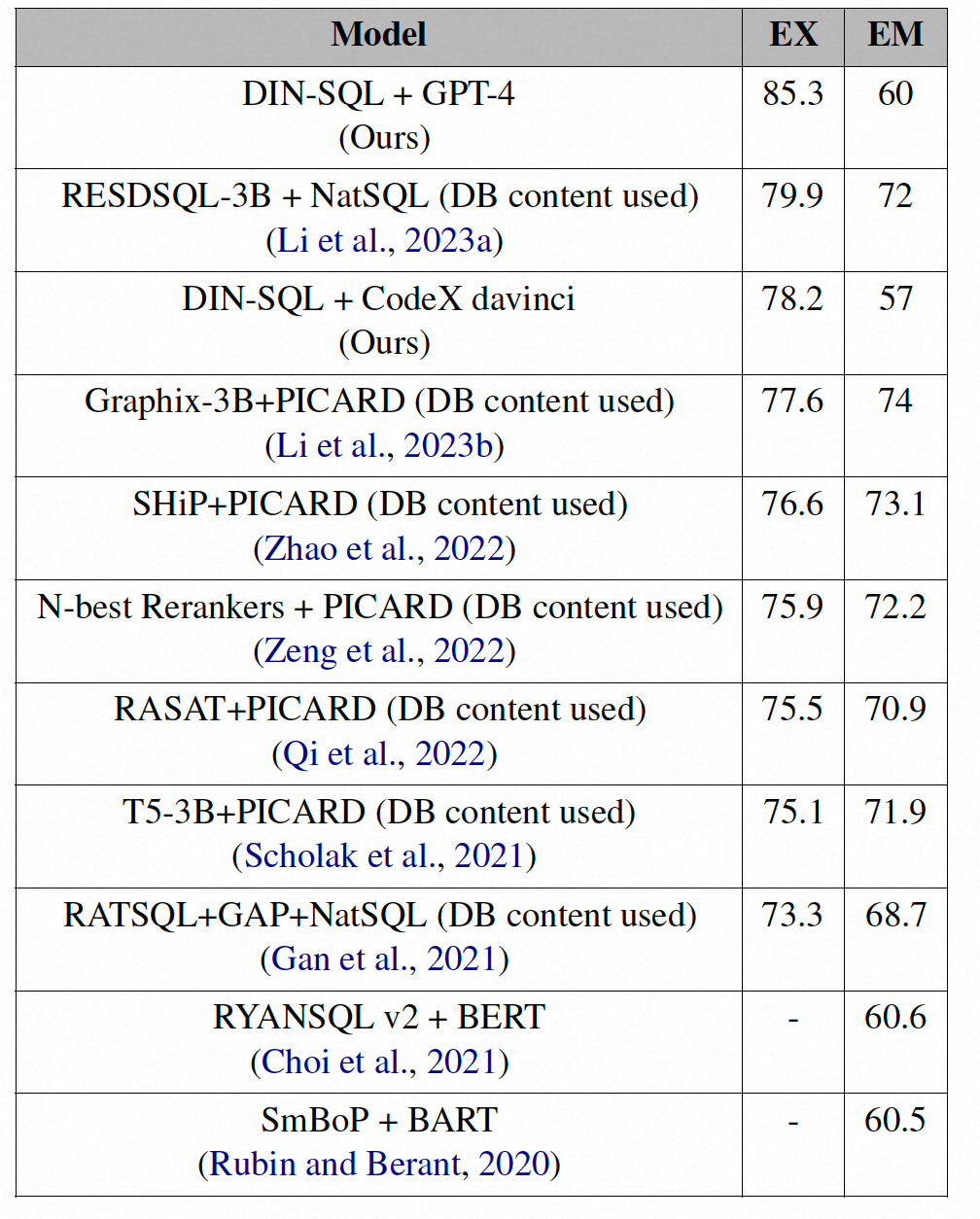
▐ 效果对比
spider的测试集上的执行精度(EX)和逻辑匹配精度(EM),使用GTP-4实现了最高的执行精度,使用CodeX Davinci实现了第三高的执行精度。

指标体系
▐ 什么是指标体系
我们在讨论一个人是否健康的时候,常常会说出一些名词:体温、血压、体脂率等。当一份体检报告出具时,上面会罗列数十项体检指标,而将这些指标综合起来考量,大概就能了解一个人的健康状况。若其中一向指标飘红,那就说明身体的某项机能出了问题。
同样,判断一家公司的经营情况,可以通过指标对业务进行监控,可往往一个指标没办法解决复杂的业务问题,这就需要使用多个指标从不同维度来评估业务,也就是使用指标体系。
指标体系(Indication System)就是从不同维度梳理业务,把指标有系统地组织起来,形成的一个整体。
▐ 指标的理解
理解指标必须明确两个重要的概念【度量】和【维度】,一个正确的指标必须包括度量和维度。“性别”是维度,“男性数量”,“女性数量”,“男性占比”,“女性占比”是度量;“城市”是维度,“一线城市占比”,“省会城市数量”,“GDP 大于 1 万亿的城市数量”是包含了维度和度量的指标。
指标都是汇总计算出来的,有聚合过程。例如单笔订单的金额不能是一个指标,统计一天的订单金额才是指标。指标需要维度进行多方面的描述分析,维度可以根据需要可以无限扩展,例如,月汽车销量,可以增加城市维度、品牌维度、是否贷款维度等等,就可以变成:城市月汽车销量,大众汽车城市月销量、有贷款的大众汽车城市月销量。
通过表格理解指标
一维表格
不存在单维表格,单一的值不能是指标,例如:
| 成交金额 |
| 2000 |
因为上面的表格没有描述是谁的成交金额,单独的一个值,无法描述这个值代表的什么事务、动作,以及在什么时间周期范围内产生的这个聚合度量。
二维表格 时间周期
任何指标统计都离不开时间周期,可以说所有的指标都会涉及时间。对在一个时间段内发生的业务进行统计。例如过去 24 小时,一个自然日、自然周,这一年,从月初到现在,往前推 30 天等等,都是时间周期。
如果在表格中描述指标,则一定且必须最少是一个二维表格(至少有两列),在表格中加入时间周期,就得到了这样的结果:
| 时间 | 成交金额 |
| day1 | 2000 |
| 最近7天 | 5000 |
业务范围
如果确定了业务范围,例如业务范围=【短视频】,度量是播放次数,并且把播放VV这个度量的时间范围确定在天这个范围内:
| 时间周期 | 业务 | 播放次数 |
| day1 | 短视频 | xxxx |
| day2 | 短视频 | xxxx |
| day2 | 短视频 | xxxx |
| dayn | 短视频 | xxxx |
业务这一列用于描述这个度量的业务范围,一般称它为业务修饰词,但通常在表格中,不会这么存放,第二列造成了冗余,一般都简化掉这一列,收敛成两列的形式,把业务范围和度量合并:
| 时间周期 | 短视频播放次数 |
| day1 | xxxx |
| day2 | xxxx |
| day3 | xxxx |
| dayn... | xxxx |
业务范围和维度的区别
业务范围也是维度,只不过在指标计算的过程中,会从最宏观的一面开始,习惯性的会定义一个范围,要统计哪个业务的数据?你有 4 家水果店,别人要问你,你的日销售额是什么?那你可能会问,是哪家门店?或者是我所有的门店?(相当于我自己的生意范围)它本身就是一个维度(视角)来统计的。但把它抽离出来,是方便于对指标的管理与认知。公司大了,有很多分支业务的时候,你问 DAU 是多少,肯定会带上业务前缀的。
多维表格
如果二维表格是最小集,那么加入更多的维度和度量,这个表格就变成多维表格,例如,修饰词=【短视频】,加入维度=【终端】和【是否会员】则多维表格是这样的:
| 时间周期 | 终端 | 是否会员 | 短视频播放vv |
| day1 | ios | 是 | xxxx |
| day1 | 安卓 | 是 | xxxx |
| day1 | ios | 否 | xxxx |
| day1 | 安卓 | 否 | xxxx |
| day1 | all | all | xxxx |
| day2 | ios | 是 | xxxx |
| day2 | 安卓 | 是 | xxxx |
也可以在此基础之上,增加度量,例如增加度量【播放时长】:
| 时间周期 | 终端 | 是否会员 | 短视频播放vv | 短视频播放时长 |
| day1 | ios | 是 | xxxx | xxxx |
| day1 | 安卓 | 是 | xxxx | xxxx |
| day1 | ios | 否 | xxxx | xxxx |
| day1 | 安卓 | 否 | xxxx | xxxx |
| day1 | all | all | xxxx | xxxx |
多维表格的表头样式就是这样的:【维度 1】【维度 2】【维度 3】【维度 n…】【度量 1】【度量 2】【度量 3】【度量 n…】。
每一行的维度+单一度量都是一个指标
这里有一个很重要的思想统一,上面的多维表中每一行都是一个指标,每一行形成了指标的基本要求【维度】+【度量】。
经常会有一种情况,用户在相互沟通指标时,没有按照每一行是一个独立指标来看待。
例如,会员在 ios 端的播放 vv 和会员在安卓端播放的 vv 是两个不同的指标,很多人会认为指标是播放 vv,会员、终端都是描述指标的维度。这样理解没问题。因为视角不同。”指标是播放 vv,会员、终端都是描述指标的维度“是典型的管理视角。一行一个指标是应用视角,在描述指标的时候,就是确定在这一行的这个数字上,如果按照管理视角来看,那么指标就会有很多行。
如果多个人有多个理解方式,就一定会产生沟通成本。
条件限定
上面的多维表是正确表达指标的一种理想状态,认为每一行都是一个可以解释的指标。但实际使用情况不单单是用【维度】+【时间周期】+【度量】就可以完成指标的描述的。
用户会随着业务的需求,有很多临时分析需要,随时对指标进行条件的设定。
例如上面的表中,指标【短视频播放时长】,需要对用户做分类,就会有一定的条件限制:播放时长大于1小时的用户,非会员且播放时长大于 1 小时的用户。
这个例子中,把指标【短视频播放时长】以及维度【是否会员】做了条件限制,用于描述指标【短视频用户数】。
| 时间周期 | 终端 | 条件限定 | 短视频用户数 |
| day1 | ios | 【播放时长】>1 小时 | xxxx |
| day1 | 安卓 | 【播放时长】>1 小时&非会员 | xxxx |
这种情况非常常见,例如大于 18 岁的用户,本科及以上学历,用户登录次数大于 3 等等。度量、维度值,都可以当做条件作用于其他指标。
以上情况我们统称为条件限定,条件限定扩大了指标的灵活性,可以基于实际的业务需要对指标进行数据剪裁。
条件限定和维度值的区别:
例如像 IOS 端,是一个维度值,单独来看 IOS 端的短视频用户数,IOS 端可以表达维度,也可以用于条件限定,但是维度值是确定且单一的,它不能组合。
条件限定是灵活的,它可以用度量来限制、也可以组合各种维度值,例如渠道包括:1,系统直播 2,线下门店 3,淘宝 4、外部直播 5、分销商,每一个数值都代表一个维度值,他是确定的观察视角。条件限定可以是他们中任何数字的组合,比如 1 和 2,2 和 3,1 或者 2,2 或者 3,不是 1 和 2 等等,它是灵活多变的。
总结
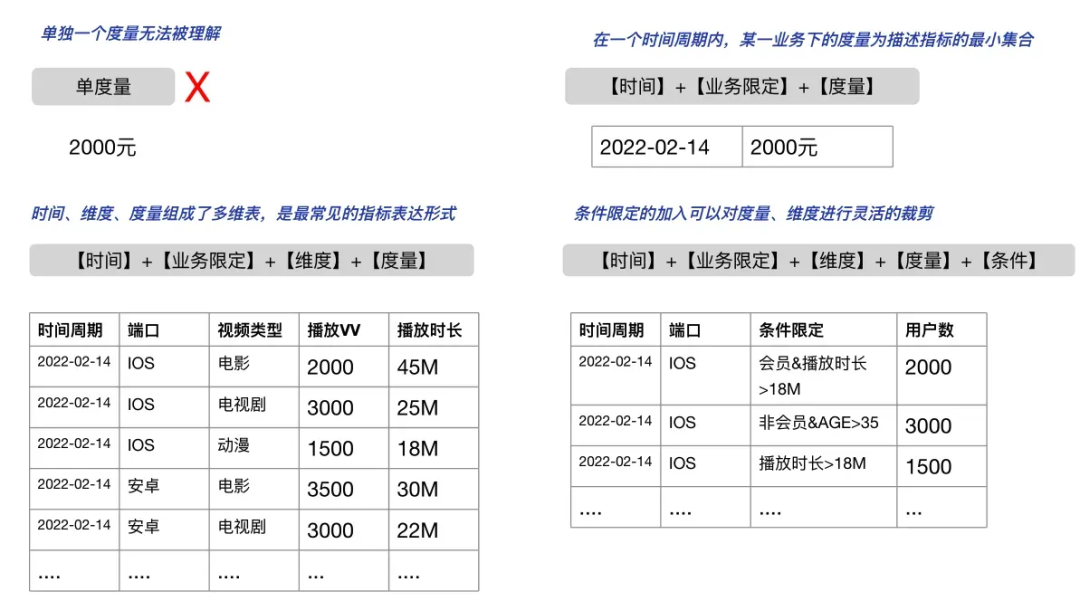
单独存在的度量、维度都不是指标
用表格描述指标的最小集是二维表,单独一列没有任何意义,不具备可读性
绝大多数指标都是多维表的形态:【维度 1】【维度 2】【维度 3】【维度 n…】【度量 1】【度量 2】【度量 3】【度量 n…】
时间周期 | 维度1 | 维度2 | 维度n | 度量1 | 度量2 |
日期 | 城市 | 品类 | 渠道 | 成交金额 | 成交订单数 |
业务范围帮助缩小和明确了处理数据和理解指标的范围
如果维度不断增多,那么数据表就是一个很宽的表。也就是常说的“大宽表”
条件限定的加入,产生了更灵活的指标形式
▐ 指标模型
原子指标
原子指标是指数据分析中最小的可度量单元,通常是一个数值或一个计数。原子指标是数据分析的基础,它们可以用来描述某个特定的事件、行为或状态,如销售额、访问量、转化率等。原子指标通常是不可再分的,因为它们已经是最小的可度量单元了。
按照上面的例子来说,原子指标可以理解为是度量,例如【销售金额】【播放时长】【访问次数】等等,这些度量是不可拆解的。
原子指标用于明确业务的统计口径及计算逻辑。具备以下特性:
原子指标是对指标统计口径算法的一个抽象,等于业务过程(原子的业务动作)+ 统计方式。例如,支付(事件)金额(度量),曝光(事件)次数(度量)
原子指标不会独立存在,一定是结合业务范围,维度进行组合才有意义
原子指标加维度可以理解为一个度量在不同视角下的变化
原子指标通常是其他指标的基础,可以通过对原子指标的分析来得出更高级别的指标。理解原子指标是整个指标管理模型中非常重要的一环。
派生指标
派生指标在业务限定的范围内,由原子指标、时间周期、维度三大要素构成,用于统计目标指标在具体时间、维度、业务条件下的数值表现,反映某一业务活动的业务状况。
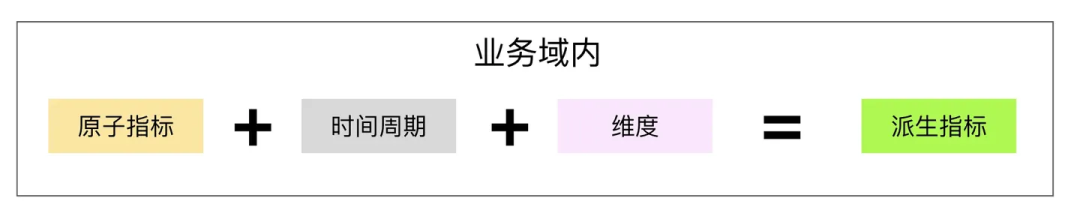
例如上面讲到的多维表中的每一行都是一个派生指标,也就是说,业务中用到的指标都是派生指标。
不同的派生指标可能具有相同的原子指标,这样派生指标就定义了一种等价关系,而属于相同的原子指标就构成了一个对指标体系的划分。在每一个划分中,存在一个可以派生出其他指标的最小派生指标,即最细粒度。
复合指标
派生指标的另一个类型是复合指标,如果把它单独独立出来也可以,如果把它归类为原子指标也可以,取决于我们如何做数据的开发以及应用。先来看几个复合指标的例子:
平均销售价格:派生指标是通过销售额和销售量计算得出的,它反映了每个产品的平均售价。原子指标是销售额和销售量。
转化率:派生指标是通过访问量和转化量计算得出的,它反映了每个渠道的转化效果。原子指标是访问量和转化量。
客户生命周期价值:派生指标是通过客户平均购买金额、购买频率和客户保留率计算得出的,它反映了每个客户对企业的贡献价值。原子指标是客户购买金额、购买频率和客户保留率。
上面三个例子都是在原子指标间进行计算的原子级复合指标。
也可以通过两个派生指标来计算复合指标,例如派生指标是:最近7天浙江 iPhone 的平均销售价格 = 近7天浙江 iPhone 的销售额 / 近7天浙江 iPhone 的销售量。
▐ 指标要素
上面介绍了很多的概念,其实核心思想是统一对指标的认知和理解,每一个概念单独去理解可能无法有一个整体的感受。可以看下图,来完成对指标的整体理解:
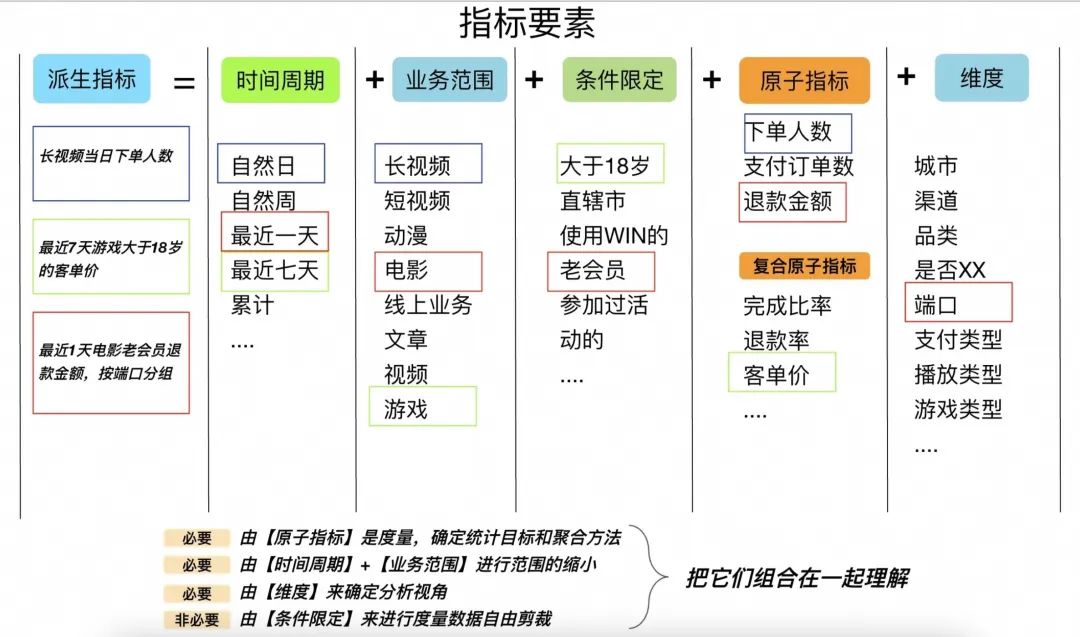
我们把【原子指标】【时间周期】【业务范围】【维度】【条件限定】统称为指标要素,他们是指标的实体组织。
原子指标:就是度量,它确定了统计目标和聚合方法
时间周期:是一种特殊的维度,它确定了统计的时间范围,从什么时间开始,从什么时间结束
业务范围:是一种特殊的维度,它确定了统计目标的范围
【时间周期】和【业务范围】单独拿出来,是为了更好的表达指标的意义
条件限定:是对统计数据进行自由剪裁的过程
维度:是用于观察统计目标的视角,可以有”无限个“维度
▐ 指标要素的SQL表达方式
基于指标要素,我们可以把它和 SQL 关联起来理解。便于了解数据的加工和实现过程,有益于从技术的视角理解指标要素。
先了解SQL的大结构
SQL 的核心作用就是从数据表中提取数据。操作对象是表,所以可以理解为:去哪张表里,以什么样的条件,取哪些数据,要以什么样的方法进行数据计算
SQL 的基本操作逻辑:
SELTECT --选取哪些字段:在这里提供字段的各种计算方式,例如SUM,MIX,MIN,IF, ELSE等,对这一列数据进行操作
FROM --从哪张表取:在这里提供单表、多表关联(JOIN,不同表提取多列合并成一张表)、多表合并 UNION(不同表,但表结构相同,上下对齐成一张表)
WHERE --以什么样的条件:在这里和SELECT一样提供字段的各种计算方式,来限制取值范围
GROUP BY,ORDER BY --组合与排序。原子指标对应select
原子指标是度量,它确定了统计目标和聚合方法,在 SQL 中,它作用于 SELECT 范围内。可以这么理解,SELECT 范围内的内容就是【原子指标】。例如:
select count(order_ID)—>计算订单数
select sum(order_amount)->计算订单金额业务范围对应from
数据来源于哪张表,一定是确定了业务范围,在数仓中,一般会对表进行分类,分类的规则会基于业务来进行,便于管理。例如:
select count(order_id)
from dwd.order_list --在订单明细表中计算订单数条件限定对应where
条件限定,一般体现在 where 条件语句中。表达以什么样的条件来看指标。例如:
-- 在订单明细表中计算订单金额大于100的订单数
select count(order_id)
from dwd.order_list
where order_amount > 100【时间周期】当作限定条件出现在where条件中
-- 在订单明细表中计算2023年5月20日订单金额大于100的订单数
select count(order_id)
from dwd.order_list
where order_amount > 100 AND order_date=‘2023-05-20'【维度值】当作条件出现在where条件中
-- 在订单明细表中计算2023年5月20日订单金额大于100且在杭州发生的订单数
select count(order_id)
from dwd.order_list
where order_amount > 100 AND order_date='2023-05-20' AND city_name='北京'维度对应group by
维度会参与 select 过程和 group by 过程。group by 的目的是分组,分组就是为了以不同的视角去看数据。
-- 在订单明细表中计算2023年5月20日订单金额大于100的订单数, 按城市分组
select count(order_id),city_name
from dwd.order_list
where order_amount>100 AND order_date='2023-05-20'
group by city_name一张图看指标要素与SQL结构的对应关系
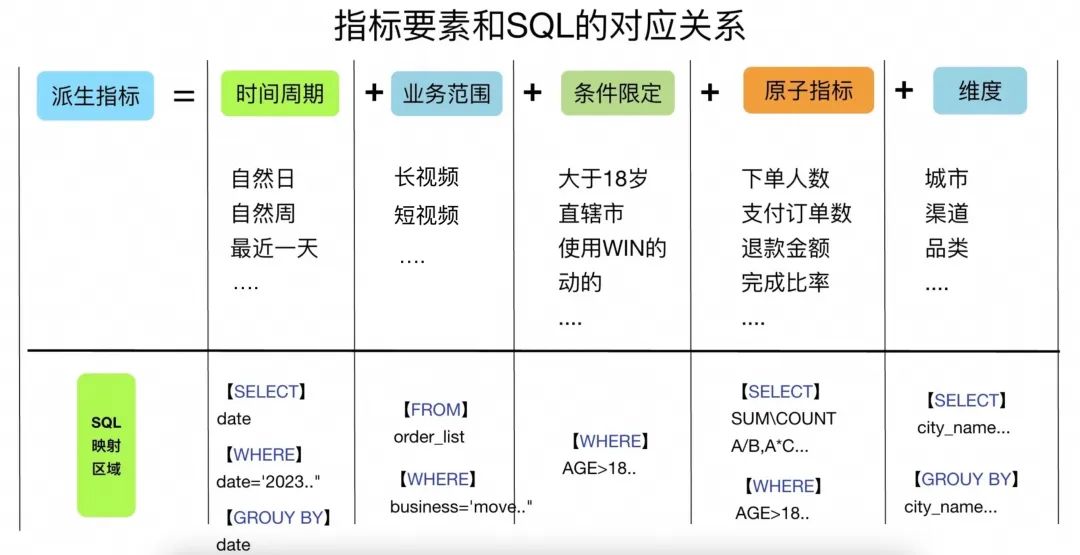
知晓指标要素与 SQL 语句的对应关系,能够对指标的实现过程有更深层次的理解。这里最重要的意义在于用户对指标的定义能够映射到技术方案上。能够基于这层关系,对数据进行合理的建模、开发与使用。
▐ 指标要素管理
上面把指标抽象成指标要素便于我们统一对指标的理解,其实更重要的目的是便于使用与管理。管理上的意义在于能够做到指标开发使用从无边界到有边界的过程,逐步收敛覆盖,另一层面能够做好统一的标准,最后由此做基础,向上放射到不同的系统、环境中去,形成整体的生态。
覆盖与收敛
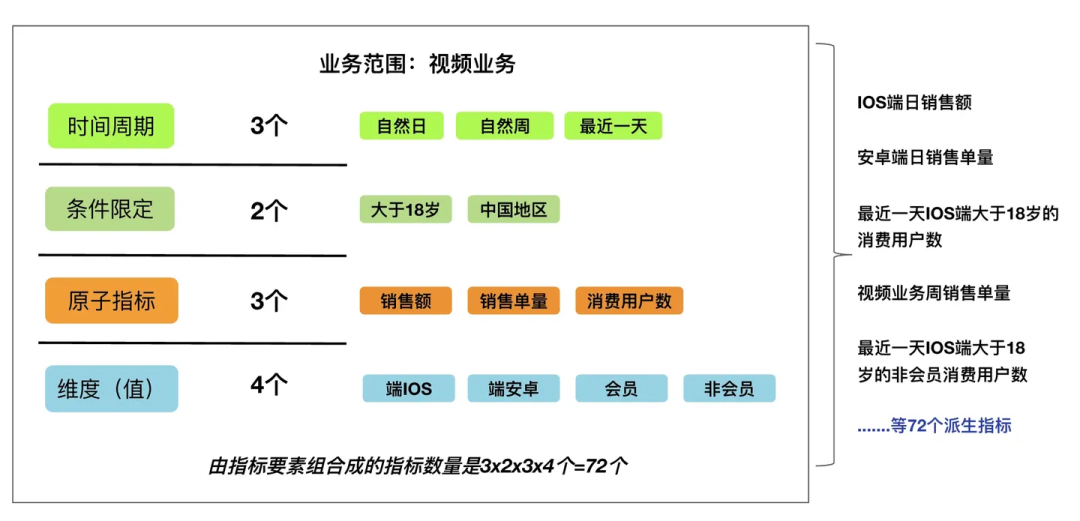
根据派生指标的概念,通过【原子指标】+【维度】+【时间周期】+【条件限定】组成了一个派生指标,当每一个指标元素出现大于1的情况时,就会出现多个派生指标,计算方法是它们的乘积。
例如上面的情况,3个【原子指标】* 4个【维度值】* 3个【时间周期】* 2个【条件限定】= 72个派生指标。
指标在使用的过程中,不论是口头交谈还是系统展示,都会以上图右边的形式来体现,【视频业务日销售额】谁都可以读懂。没有哪个用户去把指标拆解成这些要素来沟通,除非出现数据问题。所以我们在报表、汇报、业务沟通的过程中,都是如【视频业务日销售额】的指标形式体现出来的。
这样对于管理有一个非常大的好处,可以基于指标要素的组合进行最大可能的使用覆盖。
根据业务的实际诉求,完成分析体系的建设:确定分析框架,确定分析类别,确定分析场景等等,例如用户行为分析、业绩分析、经营分析、安全性分析、竞对分析、财务分析..等多个场景。基于这些分析框架,可以逐步的抽象出指标要素,确定有多少个【原子指标】+【维度】,然后就可以大致的得出,能够覆盖”多少个“指标了。
这样做的好处在于,业务用到的绝大多数指标,都是可以覆盖在指标要素组成的这些结果之内的,指标管理者、开发者只需要关注指标要素的增减即可,不用根据具体的需求 CASE BY CASE 的去完成任务,大大减少了管理和开发成本,从而实现了”收敛“ 。
及时性提升
如果已经确定好指标要素【原子指标】+【维度】+【时间周期】+【条件限定】,这些指标就可以提前进行计算:
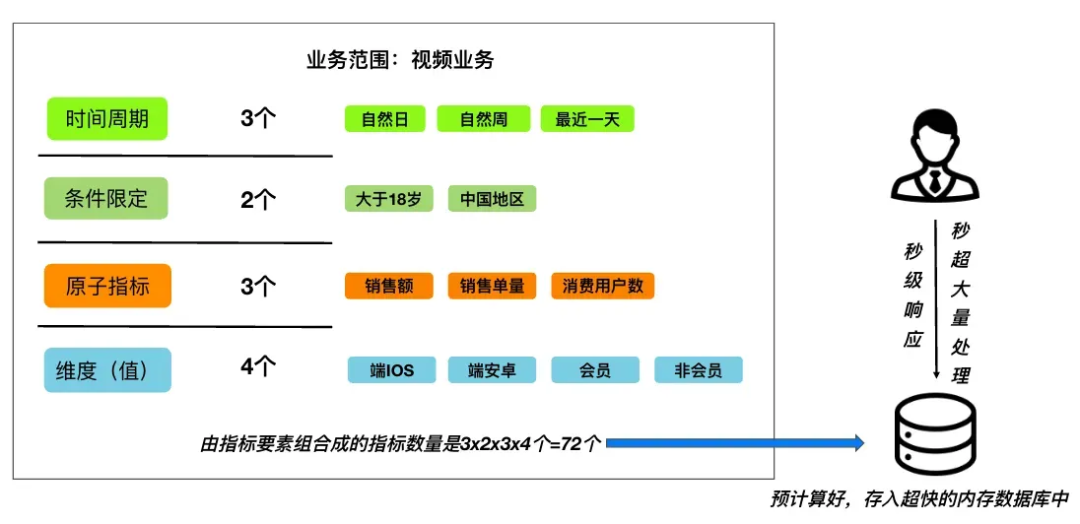
把指标要素组合的指标,提前进行预算,因为是结果集,即便是组合再多,也能控制在百万、千万级别,或者是分块、分组来存储,这样就有数据量级小的特性,我们可以把结果存入到响应速度更快的内存数据库中,完成”空间换时间“,解决大多数人无法等待超长时间的计算过程。即便数据科技技术发展到今天,如 SPARK、clickhouse 等大规模秒级响应的查询技术已经很成熟了,这种空间换时间的方式依然非常受用。从成本的角度来讲,非常划算。
命名的统一性
如果使用指标要素的管理理念来生产、管理指标,在用户使用指标的时候,可以做到指标名称的统一性。
回顾来看,所有应用的指标都可以认为是派生指标,派生指标的指标元素中,有哪些可以参与命名,哪些不用参与命名:

指标的命名规范性,直接影响使用者对指标的理解,并能够影响到整个指标使用的效果,如果命名不规范,会导致大家认知出现偏差,经常会出现不同名称同一指标,甚至还有同一指标不同名称的情况,增加大家的沟通对齐成本。
指标命名的基本原则:简短易懂,便于传播,不易出现理解偏差。
时间周期:必须参与命名,累计、昨日、月度、周;时间周期最直接的圈定了统计的范围,需要明确的展示在指标名称上,简单直接,避免不同人的理解歧义,减少错误发生的几率。
原子指标:必须参与命名,指标的核心。
业务范围:可参与命名,如果在系统、使用场景流程做的比较的情况下,可不用参与命名。例如,进入到”视频业务“的专属分析系统中,系统对业务有明确的划分板块,例如进入”电影“板块,指标名称就无需带上【电影】这个业务范围了,比如昨日电影播放量就可以直接写成播放量即可。
条件限定:不参与命名。条件限定有量个非常重要的特性,就是很容易变长,二是它出现在指标建立之后的灵活应用上,是临时性效果。例如【昨日播放量】这个条件是:大于 18 岁,中国地区,IOS 端,会员,近 30 天未登录的,如果参与命名的话就是:【会员 IOS 端中国区大于 18 岁其近 30 天未登录的昨日播放量】这样读起来就非常别扭。而且组合条件还需要考虑语言的通顺性,例如这样组合【大于 18 岁中国区 IOS 端近 30 天未登录会员昨日播放量】读起来就会拗口。另外,很多条件限定都是临时性提出的,例如年龄大于 18 岁,但是有可能随时调整到 16 岁,如果按照人的年龄分布来讲,我们可以从 1 岁到 100 岁这 100 个数字都当做限定条件,这样指标就会无限增多膨胀,增大开发、管理、使用成本。
维度:不参与指标命名,维度与条件限定相同,它具有无限扩展的情况,并且无法从语言上让指标变得易于理解。例如【昨日播放量】支持维度:销售渠道、城市、端、业务类型,加入维度后的命名是【昨日播放量销售渠道城市端业务类型】这样指标就变的不可读。实际情况是维度在分析过程中参与 GROUP BY 过程,例如表格中的分组,报表中的下钻过程,实际上指标命名带上维度没有意义,可以在应用的过程中,告知用户支持什么维度。
一致性与生态
运用指标要素的指标管理模型,本质上是抽象+收敛的过程,确定少量的指标要素,覆盖大多数的使用指标,减少开发、运维、管理和认知成本。一致性问题同样可以在这个模型中被解决。
业务基于这个模型思路,去构建指标模型,并用系统加以管理,当做整个生态的底层基础。
建立在这个模型之上,可以对接更上层的应用系统,例如报表工具,业务分析系统,用户管理系统,经营分析系统等设计到指标应用的场景中,从而让整个业务、数据分析系统生态中都利用起这个模型的思想。


总结
上面分享方案是理想的,真正能不能应用起来,是另一回事。现实是,一个小小的指标,可能经历多个团队,多年,多次治理,都达不到好的效果;对用户来讲,指标体系建设以及使用需要一定的学习、理解成本。
数据指标是一个需要认准解决方案(流程、标准、组织)长期持续做下去的事情,如果出现中断或者反复,沉淀的经验不能继承,则很难达到指标准确、及时好用的状态。学习成本以及运营同样是一个非常重要的因素。再简单的指标,也需要读懂口径、也需要明确指标在哪里看到的最准,数据出现了问题要找谁,需要一个完善指标体系建设。

团队介绍
淘天业务技术用户运营平台技术团队是一支懂用户,技术驱动的年轻队伍,以用户为中心,通过技术创新提升用户全生命周期体验,持续为用户创造价值。
团队立足体系化打造业界领先的用户增长基础设施,以媒体外投平台、ABTest平台、用户运营平台为代表的基础设施赋能阿里集团用户增长,日均处理数据量千亿规模、调用QPS千万级。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法
相关文章:
大模型与数据分析:探索Text-to-SQL
当今大模型如此火热,作为一名数据同学,持续在关注LLM是如何应用在数据分析中的,也关注到很多公司推出了AI数智助手的产品,比如火山引擎数智平台VeDI—AI助手、 Kyligence Copilot AI数智助理、ThoughtSpot等,通过接入人…...

Unity VisionOS开发流程
Unity开发环境 Unity Pro, Unity Enterprise and Unity Industry 国际版 Mac Unity Editor(Apple silicon) visionOS Build Support (experimental) 实验版 Unity 2022.3.11f1 NOTE: 国际版与国服版Pro账通用,需要激活Pro的许可证。官方模板v0.6.2,非Pro版本会打…...

聊聊k8s服务发现的优缺点
序 本文主要研究一下使用k8s服务发现的优缺点 spring cloud vs kubernetes 这里有张spring cloud与kubernetes的对比,如果将微服务部署到kubernetes上面,二者有不少功能是重复的,可否精简。 这里主要是讲述一下如果不使用独立的服务发现&am…...

Tomcat是如何处理并发请求的?
Tomcat处理请求流程: Tomcat是采用了扩展JDK线程池的方案 :先启动若干数量的线程,并让这些线程都处于睡眠状态,当客户端有一个新请求时,就会唤醒线程池中的某一个睡眠线程,让它来处理客户端的这个请求,当处…...
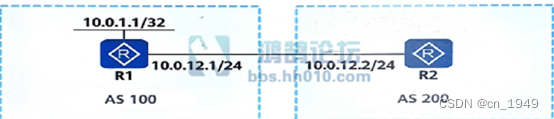
H12-831_561
单选题561、如图所示,R1使用Loopback0接口(IP地址为10.0.1.1/32)与R2的物理接口(IP地址为10.0.12.2/24)建立EBGP邻居关系,以下描述中正确的是哪一项? A.无需在R1和R2的BGP进程下指定ebgp-max-hop B.在R2的BGP进程下配置peer 10.0.1.1 ebgp-max-hop 2,且…...
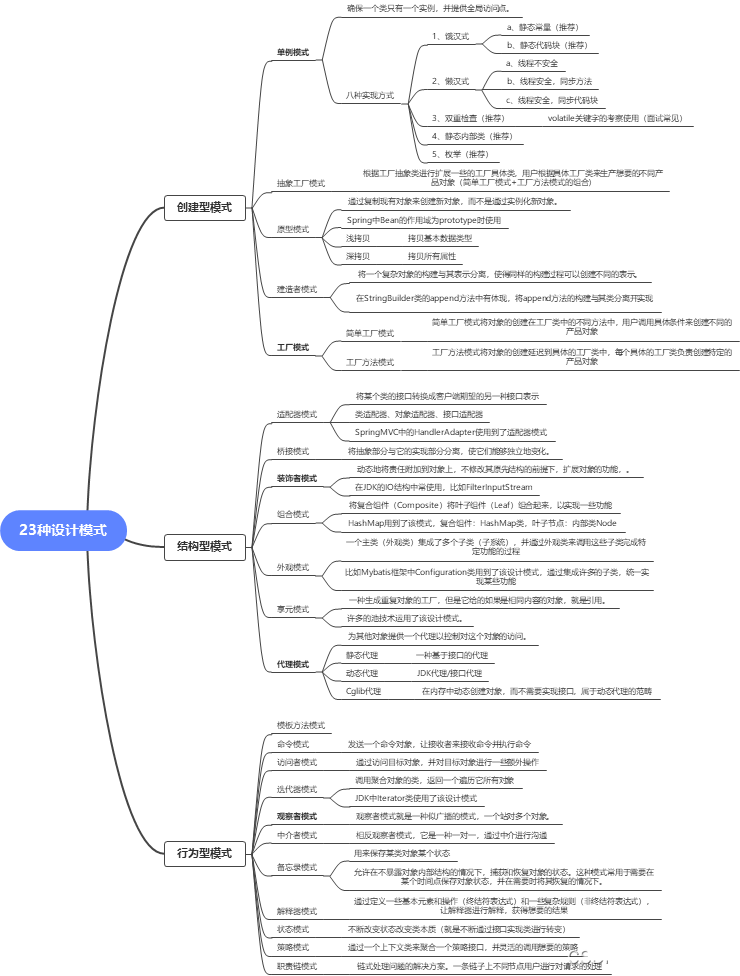
Java23种常见设计模式汇总
七大原则网站地址:设计模式7大原则+类图关系-CSDN博客 创建型设计模式:创建型设计模式合集-CSDN博客 七大结构型设计模式:7大结构型设计模式-CSDN博客 11种行为型设计模式: 11种行为型模式(上࿰…...
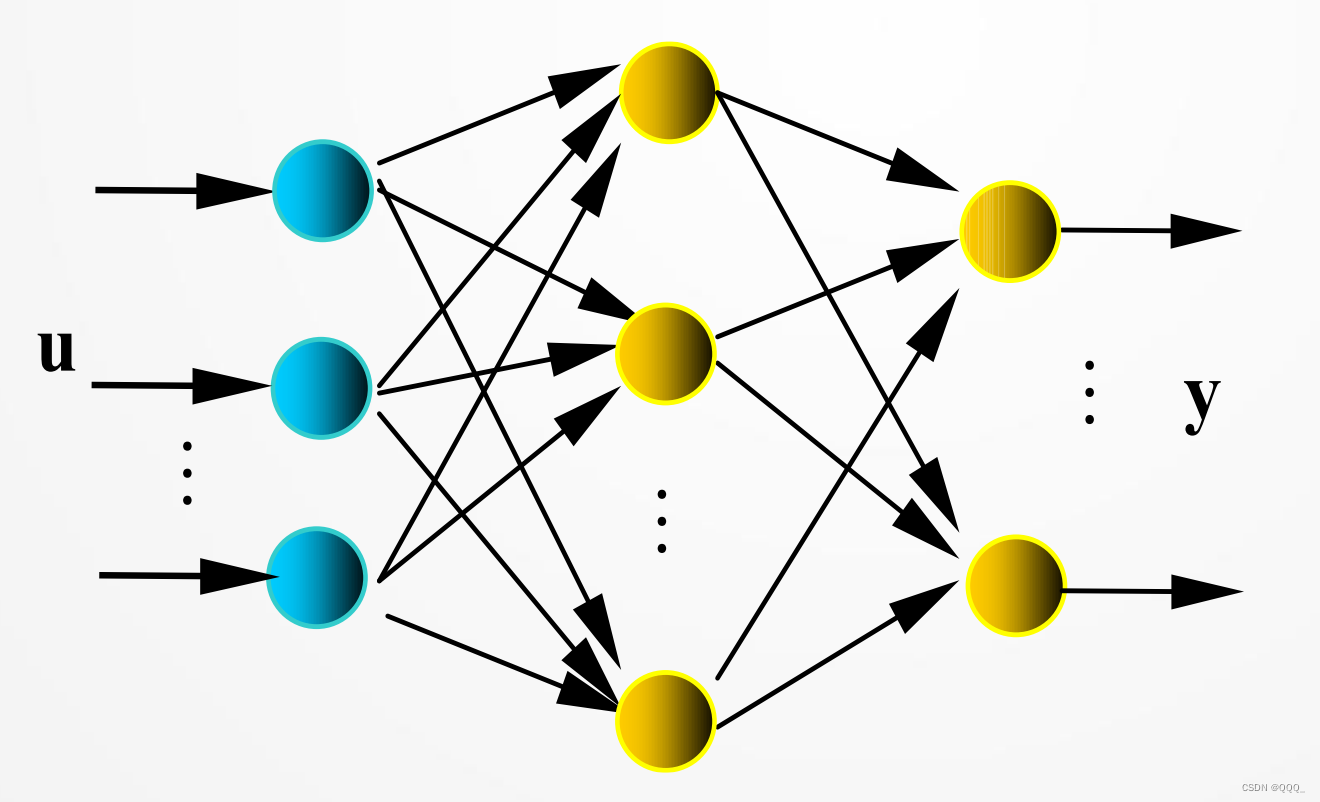
神经网络与深度学习(一)
线性回归 定义 利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法 要素 训练集(训练数据)输出数据拟合函数数据条目数 场景 预测价格(房屋、股票等)、预测住院时间&#…...
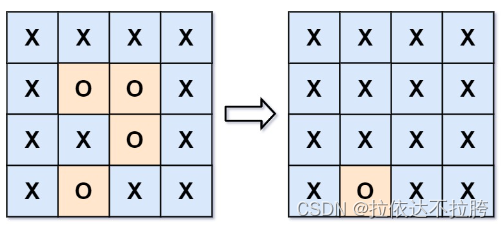
算法学习——LeetCode力扣图论篇2
算法学习——LeetCode力扣图论篇2 1020. 飞地的数量 1020. 飞地的数量 - 力扣(LeetCode) 描述 给你一个大小为 m x n 的二进制矩阵 grid ,其中 0 表示一个海洋单元格、1 表示一个陆地单元格。 一次 移动 是指从一个陆地单元格走到另一个相…...
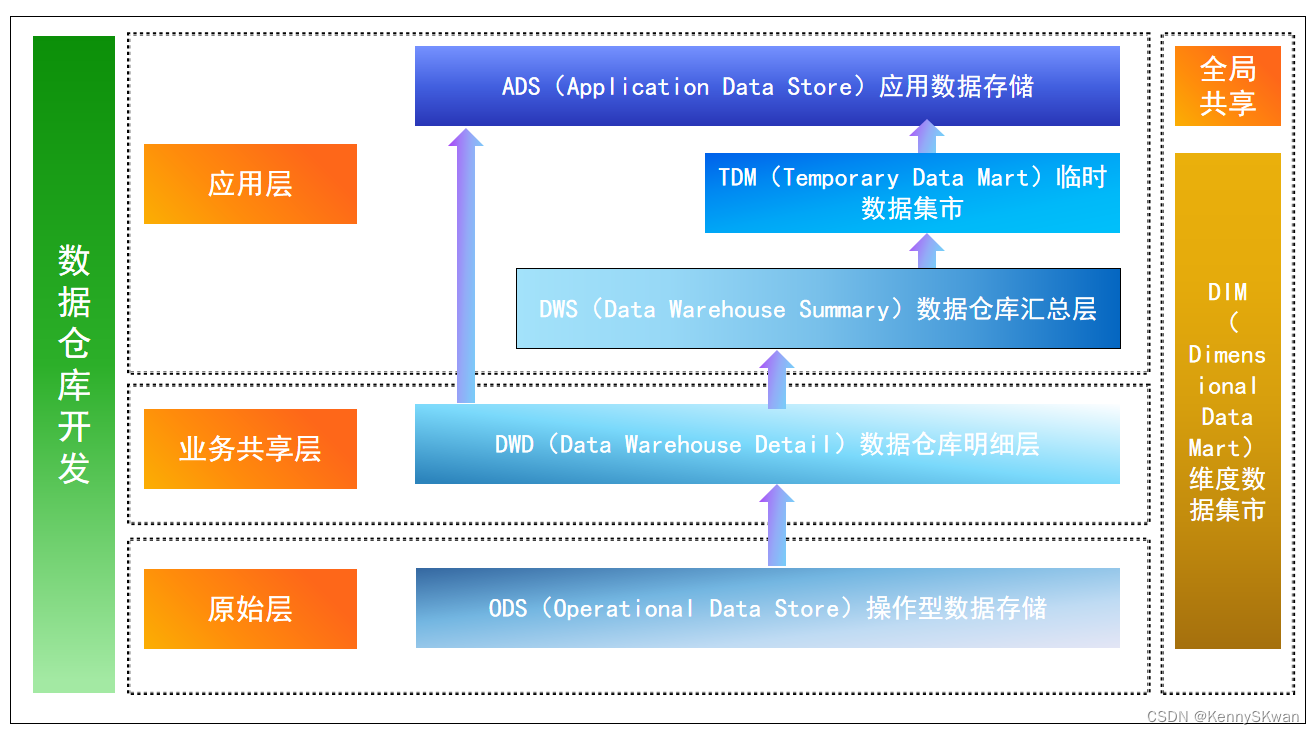
大数据设计为何要分层,行业常规设计会有几层数据
大数据设计通常采用分层结构的原因是为了提高数据管理的效率、降低系统复杂度、增强数据质量和可维护性。这种分层结构能够将数据按照不同的处理和应用需求进行分类和管理,从而更好地满足不同层次的数据处理和分析需求。行业常规设计中,数据通常按照以下…...

css3之2D转换transform
2D转换transform 一.移动(translate)(中间用,隔开)二.旋转(rotate)(有单位deg)1.概念2.注意点3.转换中心点(transform-origin)(中间用空格)4.一些例子(css三角和旋转) 三…...

pytest中文使用文档----6临时目录和文件
1. 相关的fixture 1.1. tmp_path1.2. tmp_path_factory1.3. tmpdir1.4. tmpdir_factory1.5. 区别 2. 默认的基本临时目录 1. 相关的fixture 1.1. tmp_path tmp_path是一个用例级别的fixture,其作用是返回一个唯一的临时目录对象(pathlib.Path…...
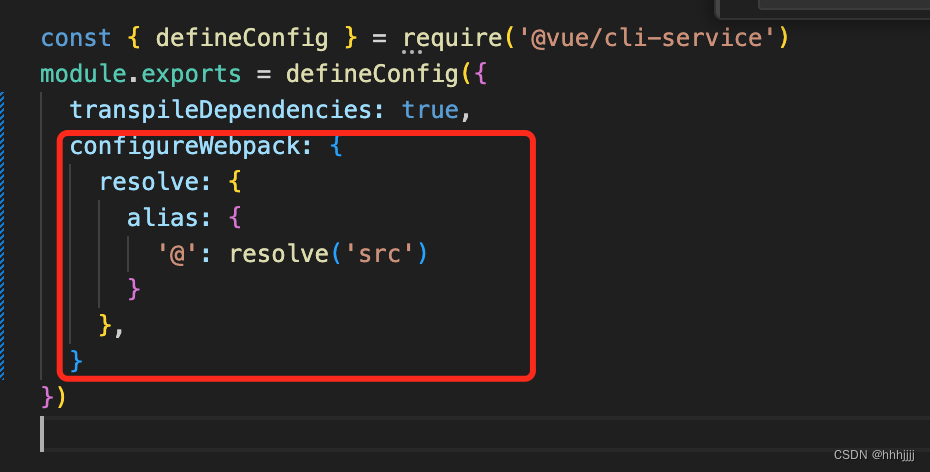
从0开始搭建基于VUE的前端项目
准备与版本 安装nodejs(v20.11.1)安装vue脚手架(vue/cli 5.0.8) ,参考(https://cli.vuejs.org/zh/)vue版本(2.7.16),vue2的最后一个版本 初始化项目 创建一个git项目(可以去gitee/github上创建ÿ…...
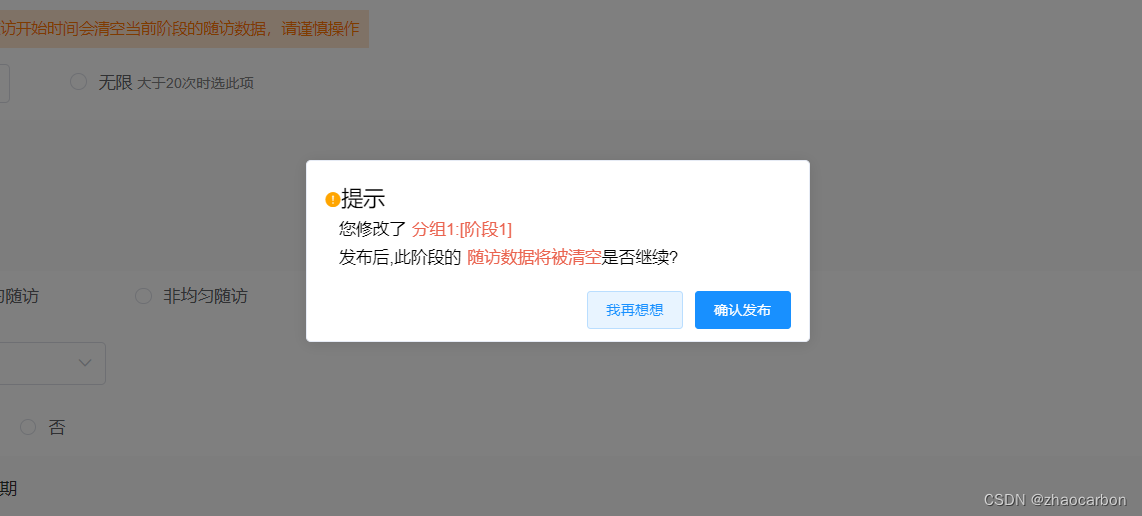
elementUI this.$msgbox msgBox自定义 样式自定义 富文本
看这个效果是不是很炫?突出重点提示内容,对于用户交互相当的棒! 下来说说具体实现: let self = this const h = self.$createElement; this.$msgbox({title: null,message: h("p", {style: "margin-top:10px"}, [h("i", {class: "el-i…...

Lua与Python区别
Lua和Python都是流行的编程语言,但它们在设计哲学、应用领域和性能特点上有所不同。以下是Lua和Python之间的对比: 1. **设计哲学**: - Lua被设计为一个轻量级的嵌入式脚本语言,重点在于简单性和效率。它有一个小巧的标准库,通…...
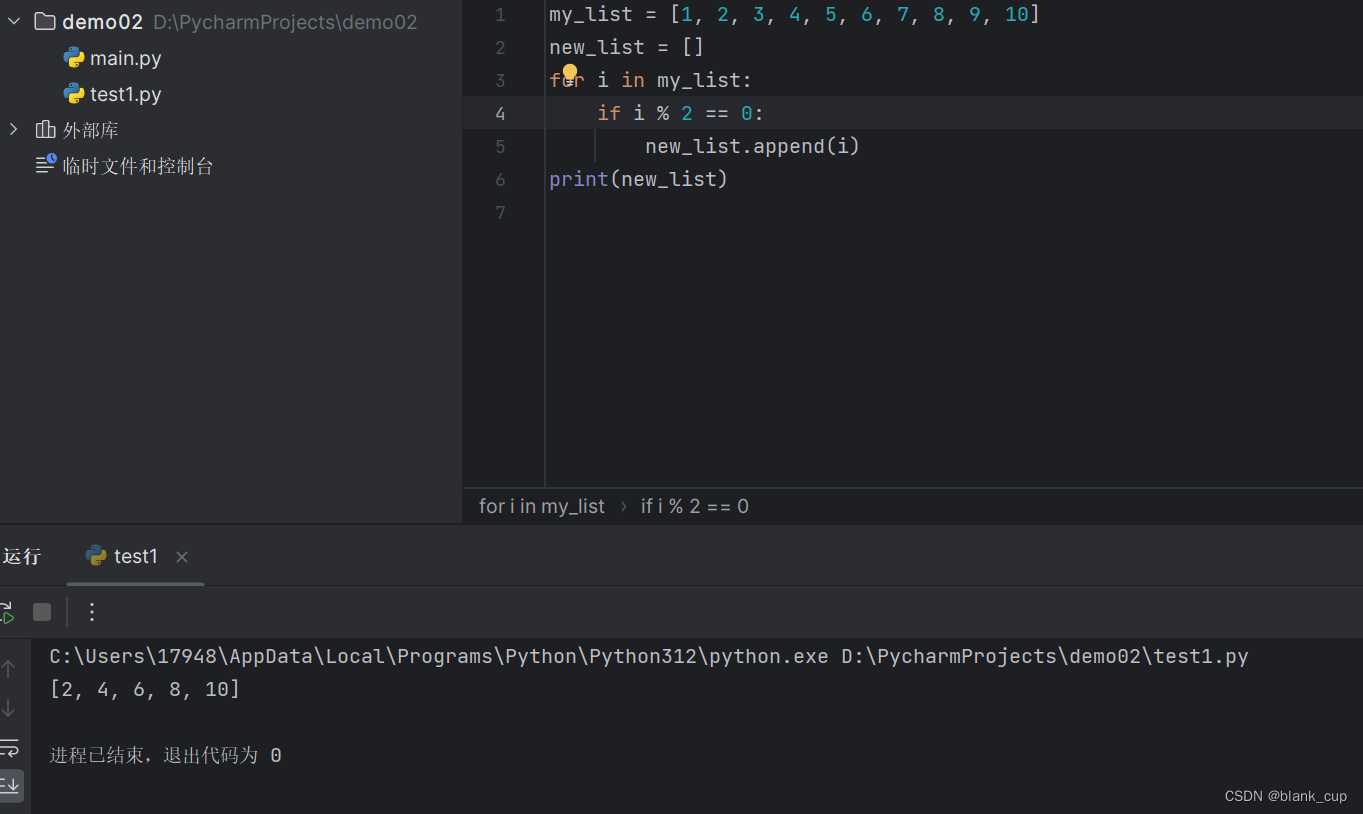
Python学习(二)
数据容器 数据容器根据特点的不同,如: 是否支持重复元素是否可以修改是否有序,等 分为5类,分别是: 列表(list)、元组(tuple)、字符串(str)、集…...
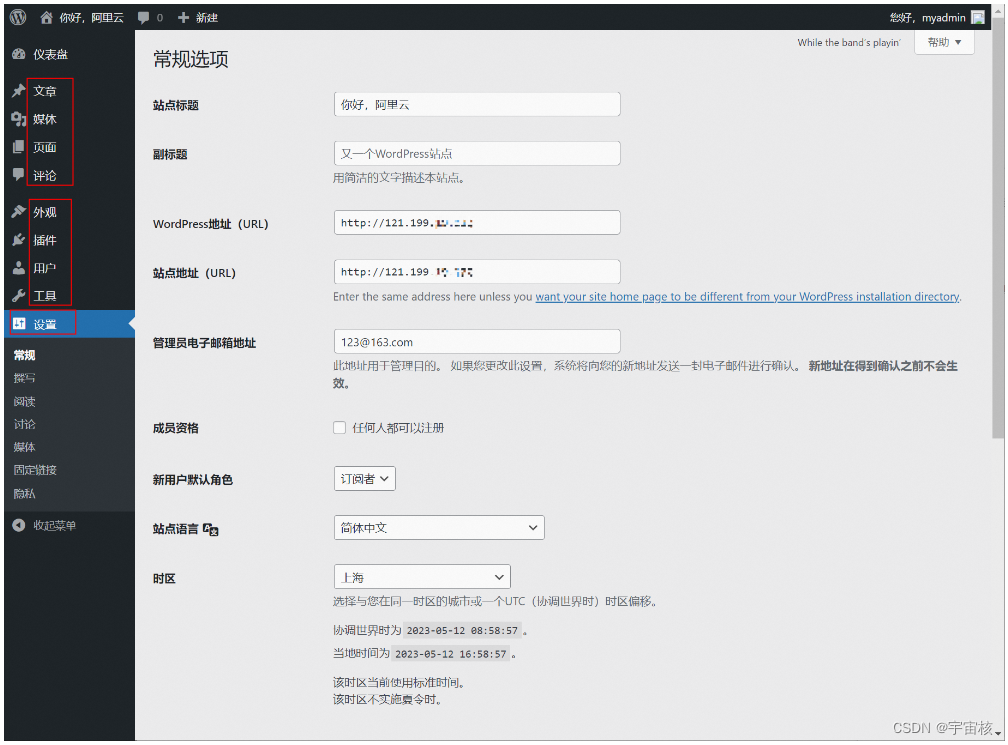
管理阿里云服务器ECS -- 网站选型和搭建
小云:我已经学会了如何登录云服务器ECS了,但是要如何搭建网站呢? 老王:目前有很多的个人网站系统软件,其中 WordPress 是使用非常广泛的一款,而且也可以把 WordPress 当作一个内容管理系统(CMS…...
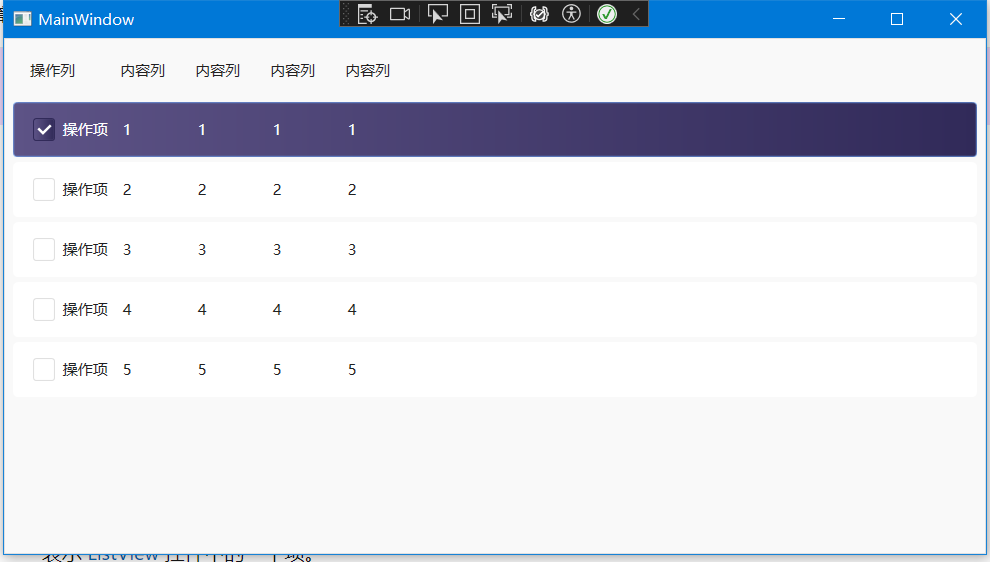
WPF中继承ItemsControl子类控件数据模板获取选中属性
需求场景 列表类控件,如 ListBox、ListView、DataGrid等。显示的行数据中,部分内容依靠选中时触发控制,例如选中行时行记录复选,部分列内容控制显隐。 案例源码以ListView 为例。 Xaml 部分 <ListView ItemsSource"{Bi…...
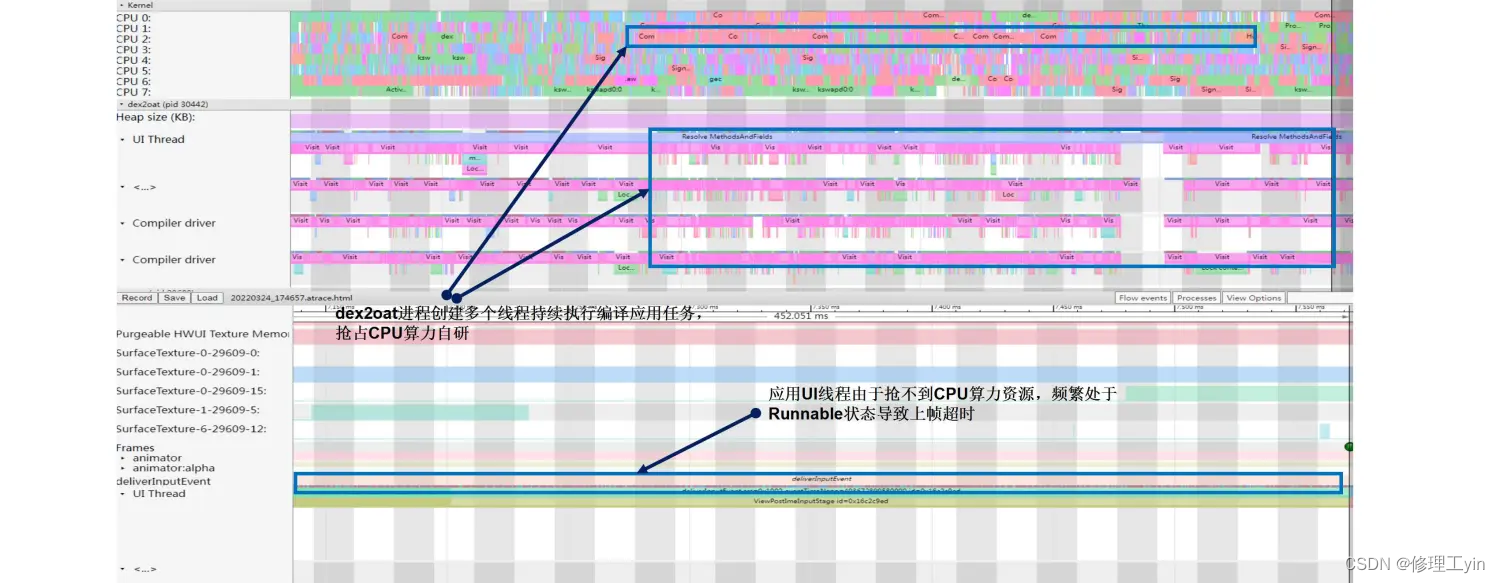
Android卡顿掉帧问题分析之实战篇
本文将结合典型实战案例,分析常见的造成卡顿等性能问题的原因。从系统工程师的总体角度来看 ,造成卡顿等性能问题的原因总体上大致分为三个大类:一类是流程执行异常;二是系统负载异常;三是编译问题引起。 1 流程执行异…...
OpenKylin安装Kafka
一、操作系统 openKylin 1.0.1 X86 二、下载安装包 # 安装依赖jdk sudo apt-get update sudo apt-get install default-jdk # 下载kafka mkdir -p /data/software/kafka wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.13-2.4.1.tgz三、解压安装 # 解压缩Kafka…...

嵌入式硬件中常见的面试问题与实现
1 01 请列举您知道的电阻、电容、电感品牌(最好包括国内、国外品牌) ▶电阻 美国:AVX、VISHAY威世 日本:KOA兴亚、Kyocera京瓷、muRata村田、Panasonic松下、ROHM罗姆、susumu、TDK 台湾:LIZ丽智、PHYCOM飞元、RALEC旺诠、ROYALOHM厚生、SUPEROHM美隆、TA-I大毅、TMT…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...
)
Windows10下V-REP教育版安装保姆级教程(附百度网盘资源与避坑点)
Windows10系统V-REP教育版完整安装指南:从下载到实战避坑在机器人仿真和自动化控制领域,V-REP(现更名为CoppeliaSim)作为一款功能强大的跨平台机器人仿真软件,已经成为众多工科学生和研究人员的首选工具。特别是其教育…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...

<背包问题>
背包问题是一类组合优化问题,其基本形式是给定一组物品,每个物品都有一个重量和一个价值,以及一个有限的背包容量,目标是在不超过背包容量的前提下,选择物品使得背包中的物品价值最大化。动态规划是解决背包问题的常用…...

全球无障碍宣传日:iOS 26 辅助功能大升级,这些实用小功能你用过吗?
辅助功能发展与升级很多人对辅助功能的印象还停留在 "小白点",但随着 iPhone 进入全面屏时代,它逐渐变得陌生。实际上,Apple 每年都会为其增添功能,方便身体有障人士使用 iPhone。而且,这些功能不仅惠及有障…...

如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南
如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南 【免费下载链接】GASShooter Advanced FPS/TPS Sample Project for Unreal Engine 4s GameplayAbilitySystem plugin 项目地址: https://gitcode.com/gh_mirrors/ga/GASShooter GASShooter是Un…...

XZ6128A工作电压5-100V 输出电流5A 升压型大功率LED灯恒流驱动控制芯片
概述 XZ6128A是一款高效率、高精度的升压型大功率LED灯恒流驱动控制芯片。 XZ6128A内置高精度误差放大器,固定关断时间控制电路,恒流驱动电路等,特别适合大功率、多个高亮度LED灯串的恒流驱动。 XZ6128A采用固定关断时间的控制方式࿰…...