Python爬虫之pyquery和parsel的使用
三、pyquery的使用
1、准备工作
pip3 install pyquery
2、初始化
2.1、字符串初始化
把HTML的内容当做参数,来初始化PyQuery对象。
html = '''
<div><ul><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold>third item</span></a></li><li class="item-0 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html) # 将HTML作参数传给pq,完成初始化
print(doc('li'))
2.2、URL初始化
指定PyQuery对象的参数为url。
from pyquery import PyQuery as pq
doc = pq(url='https://cuiqingcai.com')
print(doc('title'))# 和以下代码功能相同
doc = pq(requests.get('https://cuiqingcai.com').text)
print(doc('title'))
2.3、文件初始化
from pyquery import PyQuery as pq
doc = pq(filename='demo.html')
print(doc('title'))
3、基本CSS选择器
html = '''
<div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold>third item</span></a></li><li class="item-0 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('#container .list li')) # 选取id为container的节点,再选取其内部class为list的节点内部的所有li节点
print(type(doc('#container .list li'))) #PyQuery类型for item in doc('#container .list li').items(): # 遍历输出print(item.text())
4、查找节点
4.1、子节点
查找子节点时,需要用到find方法,其参数是CSS选择器。
items = doc('.list') # 选取class为list的节点
print(type(items))
print(items)
lis = items.find('li') # 选取其内部的li节点
print(type(lis)) # PyQuery类型
print(lis)
如果要筛选所有子节点中符合条件的节点,可向children方法传入CSS选择器。
lis = items.children()
lis = items.children('.active')
4.2、父节点
可以用parent方法获取某个节点的父节点。
container = items.parent()
print(type(container)) # 类型还是PyQuery
print(container)
可以用parents方法获取某个节点的祖先节点。
parents = items.parents()
print(type(parents)) # 类型还是PyQuery
print(container)
可传入参数筛选祖先节点
parent = items.parents('.wrap')
print(parent)4.3、兄弟节点
li = doc('.list .item-0.active')
print(li.siblings())5、遍历节点
-
pyquery 的选择结果可能是多个节点,也可能是单个节点,类型都是PyQuery类型,并没有像Beautiful Soup那样返回列表。
-
如果结果是单个节点,既可以直接打印输出,也可以直接转成字符串
doc = pq(html) li = doc('.item-0.active') print(li) print(str(li)) -
如果是多个节点,就需要遍历获取了。需要调用items方法:
doc = pq(html) lis = doc('li').items() print(type(lis)) for li in lis:print(li,type(li))
5.1、获取信息
比较重要的信息有两类,一是属性、二是文本。
5.1.1、获取属性
提取到某个PyQuery类型的节点后,可以调用attr方法获取其属性。
doc = pq(html)
a = doc('.item-0.active a')
print(a,type(a))
print(a.attr('href')) / print(a.attr.href)
- 当返回结果包含多个节点时,调用attr方法,只会得到第一个节点的属性。
- 如果要获取所有的,则需要遍历。
from PyQuery import PyQuery as pq
doc = pq(html)
a = doc('a')
for item in a.items():print(items.attr('href'))
5.1.2、获取文本
获取节点内部的文本,可以调用text方法:
from pyquery import PyQuery as pq
html = '''
<div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold>third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div>
</div>
'''doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.text())
- 这里首先选中a节点,然后调用text方法,就可以获取其内部的文本信息。此时text方法会忽略节点内部包含的所有HTML,只返回纯文字内容。
- html方法会得到节点内部的HTML文本。
- 如果得到的是多个节点,并且想获取所有节点的内部HTML文本,就要遍历这些节点。而text方法不需要遍历即可得到,会对所有节点取文本之后合成一个字符串。
6、节点操作
pyquery库提供了一些列方法对节点进行动态修改,例如为某个节点添加一个class,移除某个节点等。
6.1、add_class和remove_class
html = '''
<li class="item-0 active"><a href="link3.html"><span class="bold>third item</span></a></li>
'''
doc = pq(html)
li = doc('.item-0.active')
li.remove_class('active')
li.add_class('active')
6.2、attr、text和html
doc = pq(html)
li = doc('.item-0.active')
li.attr('name','link')
li.text('changed item')
li.html('<span>changed item</span>')
- attr方法第一个参数为属性名,第二个参数为属性值。若值传入一个参数,表示获取这个属性值。
- 调用text方法和html方法改变li节点内部的内容。如果传入参数则表示赋值。
6.4、remove
html = '''
<div class="wrap">Hello, World<p>This is a paragraph.</p>
</div>
'''
doc = pq(html)
wrap = doc('.wrap')
wrap.find('p').remove()
print(wrap.text())# 首先选中p节点,然后调用remove方法将其移除,这时wrap内部就只剩下Hello World这句话了,再利用text方法提取即可。
7、伪类选择器
li = doc('li:first-child') # 选择了第一个li节点
li = doc('li:last-child') # 选择了最后一个li节点
li = doc('li:nth-child(2)') # 第二个li节点
li = doc('li:gt(2)') # 第三个之后的li节点
li = doc('li:nth-child(2n)') # 偶数位置的li节点
li = doc('li:contains(second)') # 包含second文本的li节点
查看更多:http://pyquery.readthedocs.ip
四、parsel的使用
1、介绍
parsel库可以解析HTML和XML,并支持使用XPath和CSS选择器对内容进行提取和修改,同时还融合了正则表达式的提取功能。主流!!
2、准备工作
pip3 install parsel
3、初始化
html = '''
<div><ul><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold>third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul>
</div>
'''from parsel import Selector
selector = Selector(text=html) # 创建了一个Selector对象,传入text参数
items = selector.css('.item-0')
print(len(items),type(items),items)items2 = selector.xpath('//li[contains(@class,"item-0")]')
print(len(items2),type(items2),items2)
- 两个结果都是SelectorList对象,这其实是一个可迭代对象
- 用len方法获取了结果的长度。
- 每个节点还是以Selector对象的形式返回,其中每个Selector对象的data属性里包含对应提取节点的HTML代码。
4、提取文本
对上述可迭代对象SelectorList,要获取所有li节点的文本内容,就需要遍历了。
items = selector.css('.item-0')
for item in items:text = item.xpath('.//text()').get()print(text)
result = selector.xpath('//li[contains(@class,"item-0")]//text()').get()
# 这里使用//li[contains(@class,"item-0")]//text()选取了所有class包含item-0的li节点的文本内容。这里get只提取了第一个Selector对象的结果
result = selector.xpath('//li[contains(@class,"item-0")]//text()').getall()
# 使用getall则会提取所有
# css写法:
result = selector.css('.item-0 *::text').getall
5、提取属性
# 例如提取第三个li节点的href属性
result = selector.css('.item-0.active a::attr(href)').get()
result = selector.xpath('//li[contains(@class,"item-0") and contains(@class,"active")]/a/@href').get()
- 对于CSS选择器,选取属性需要加**::attr(),并传入对应的属性名称**才可选取;
- 对于XPath,直接用**/@再加属性名称**即可选取。
6、正则提取
result = selector.css('.item-0').re('link.*')
# 先用css方法提取所有class包含item-0的节点,然后使用re方法传入了link.*,用来匹配包含link的所有结果。
- 当然,如果在调用css方法时,已经提取了进一步的结果,例如提取了节点文本值,那么re方法就只会针对节点文本进行提取:
result = selector.css('.item-0 *::text').re('.*item')
- 也可用re_first方法来提取第一个符合规则的结果:
result = selector.css('.item-0').re_first('<span class="bold>(.*?)</span>')
相关文章:

Python爬虫之pyquery和parsel的使用
三、pyquery的使用 1、准备工作 pip3 install pyquery2、初始化 2.1、字符串初始化 把HTML的内容当做参数,来初始化PyQuery对象。 html <div><ul><li class"item-0">first item</li><li class"item-1">&l…...

移动硬盘怎么加密?移动硬盘加密软件有哪些?
移动硬盘是我们在工作中最常用的移动存储设备,为了保护数据安全,需要使用专业的移动硬盘加密软件加密保护。那么,移动硬盘加密软件有哪些? BitLocker BitLocker是Windows的磁盘加锁功能,可以用于加密保护移动硬盘中…...

openEuler 22.03 安装 .NET 8.0
openEuler 22.03 安装 .NET 8.0 openEuler 22.03 安装 .NET 8.0 openEuler 22.03 安装 .NET 8.0 查看内核信息 [jeffPC-20240314EIAA ~]$ cat /proc/version Linux version 5.15.146.1-microsoft-standard-WSL2 (root65c757a075e2) (gcc (GCC) 11.2.0, GNU ld (GNU Binutils)…...
)
【转载】OpenCV ECC图像对齐实现与代码演示(Python / C++源码)
发现一个有很多实践代码的git 库,特记录下: 地址:GitHub - luohenyueji/OpenCV-Practical-Exercise: OpenCV practical exercise 作者博客地址:https://blog.csdn.net/LuohenYJ 已关注。 Items项目Resources1age_gender1基于深度学习识别人脸性别和年龄Model2OpenCV_dlib_…...

每日一题(相交链表 )
欢迎大家来我们主页进行指导 LaNzikinh-CSDN博客 160. 相交链表 - 力扣(LeetCode) 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节…...

C#WPF控件大全
本文列出WPF控件大全,点击可以进入详情页查看。 列表如下: AccessText用下划线来指定用作访问键的字符。 ActivatingKeyTipEventArgs为 ActivatingKeyTip 事件提供数据。...

好书推荐 《AIGC重塑金融》
作者:林建明 来源:IT 阅读排行榜 本文摘编自《AIGC 重塑金融:AI 大模型驱动的金融变革与实践》,机械工业出版社出版 这是最好的时代,也是最坏的时代。尽管大模型技术在金融领域具有巨大的应用潜力,但其应…...
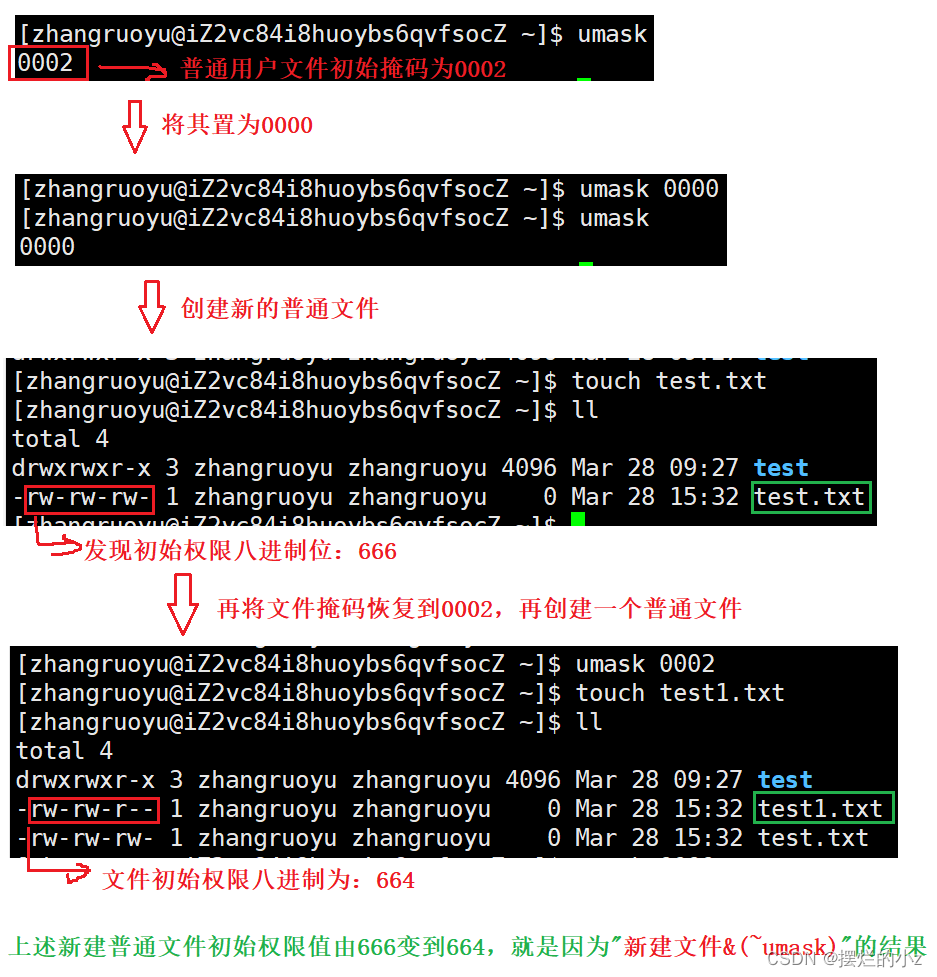
【Linux】权限理解
权限理解 1. shell命令以及运行原理2. Linux权限的概念3. Linux权限管理3.1 文件访问者的分类(人)3.2 文件类型和访问权限(事物属性)3.2.1 文件类型3.2.2 基本权限 3.3 文件权限值的表示方法3.4 文件访问权限的相关设置方法3.4.1 …...

插入排序、归并排序、堆排序和快速排序的稳定性分析
插入排序、归并排序、堆排序和快速排序的稳定性分析 一、插入排序的稳定性二、归并排序的稳定性三、堆排序的稳定性四、快速排序的稳定性总结 在计算机科学中,排序是将一组数据按照特定顺序进行排列的过程。排序算法的效率和稳定性是评价其优劣的两个重要指标。稳定…...
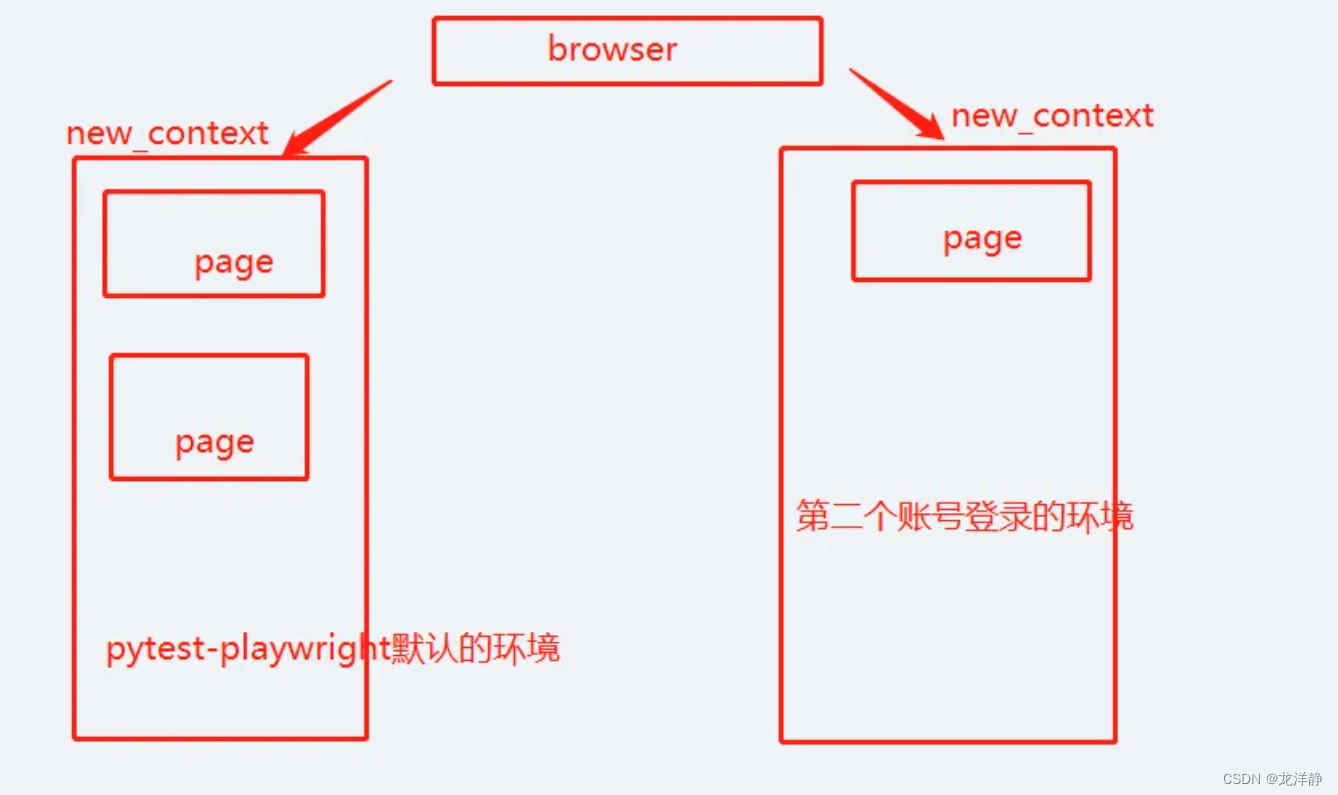
【pytest、playwright】多账号同时操作
目录 方案实现思路: 方案一: 方案二: 方案实现思路: 依照上图所见,就知道,一个账号是pytest-playwright默认的环境,一个是 账号登录的环境 方案一: 直接上代码: imp…...
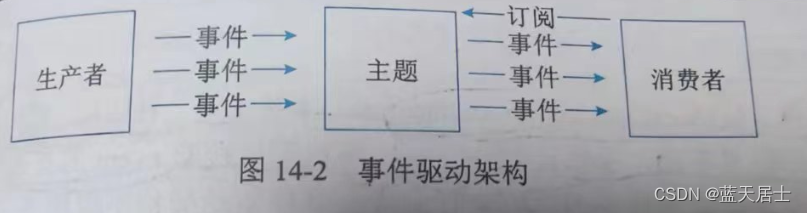
软考 系统架构设计师系列知识点之云原生架构设计理论与实践(8)
接前一篇文章:软考 系统架构设计师系列知识点之云原生架构设计理论与实践(7) 所属章节: 第14章. 云原生架构设计理论与实践 第2节 云原生架构内涵 14.2 云原生架构内涵 关于云原生的定义有众多版本,对于云原生架构的…...
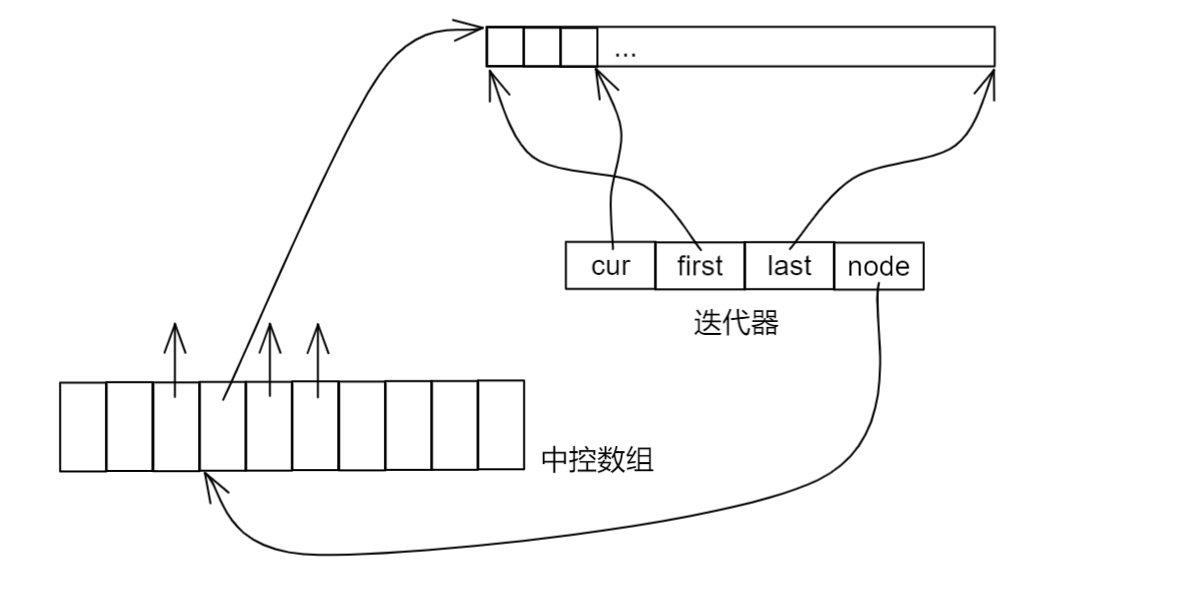
【C++】stack、queue和优先级队列
一、前言 二、stack类 2.1 了解stack 2.2 使用stack (1)empty (2)size (3)top (4)push (5)pop 2.3 stack的模拟实现 三、queue类 3.1 了解queue …...

第十三届蓝桥杯国赛真题 Java C 组【原卷】
文章目录 发现宝藏试题 A: 斐波那契与 7试题 B: 小蓝做实验试题 C: 取模试题 D: 内存空间试题 E \mathrm{E} E : 斐波那契数组试题 F: 最大公约数试题 G: 交通信号试题 I: 打折试题 J: 宝石收集 发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂&#x…...

docker部署ubuntu
仓库: https://hub.docker.com/search?qUbuntu 拉一个Ubuntu镜像 docker pull ubuntu:18.04 查看本地镜像: docker images 运行容器 docker run -itd --name ubuntu-18-001 ubuntu:18.04 通过ps命令可以查看正在运行的容器信息 docker ps 进入容器 最…...
iOS问题记录 - App Store审核新政策:隐私清单 SDK签名(持续更新)
文章目录 前言开发环境问题描述问题分析1. 隐私清单 & SDK签名1.1. 隐私清单 - 数据使用声明1.2. 隐私清单 - 所用API原因描述1.3. SDK签名 2. 即将发布的第三方SDK要求 解决方案最后 前言 前段时间用Flutter开发的iOS App提交了新版本,结果刚过两分钟就收到了…...
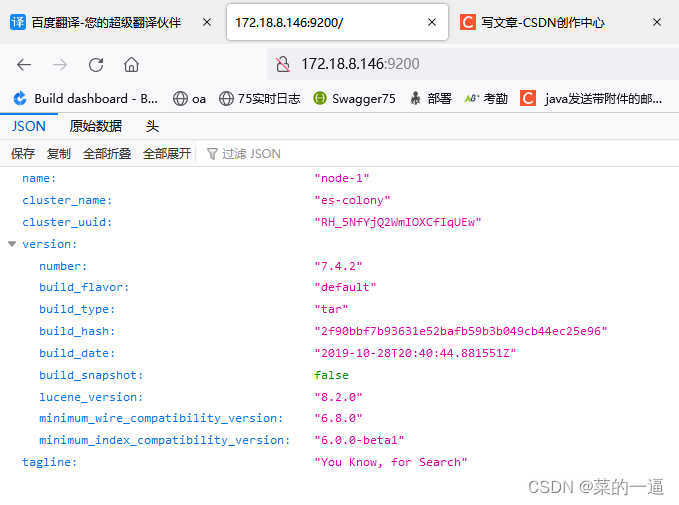
ES学习日记(二)-------集群设置
上一节写了elasticsearch单节点安装和配置,现在说集群,简单地说就是在多台服务器上搭建单节点,在配置文件里面增加多个ip地址即可,过程同单节点部署,主要说集群配置 注意:不建议在之前单节点es上修改配置为集群,据说运行之后会生成很多文件,在单点基础上修改容易出现未知问题,…...

农村集中式生活污水分质处理及循环利用技术指南
立项单位:生态环境部土壤与农业农村生态环境监管技术中心、山东文远环保科技股份有限公司、北京易境创联环保有限公司、中国环境科学研究院、广东省环境科学研究院、中铁第五勘察设计院集团有限公司、中华环保联合会水环境治理专业委员会 本文件规定了集中式村镇生活…...
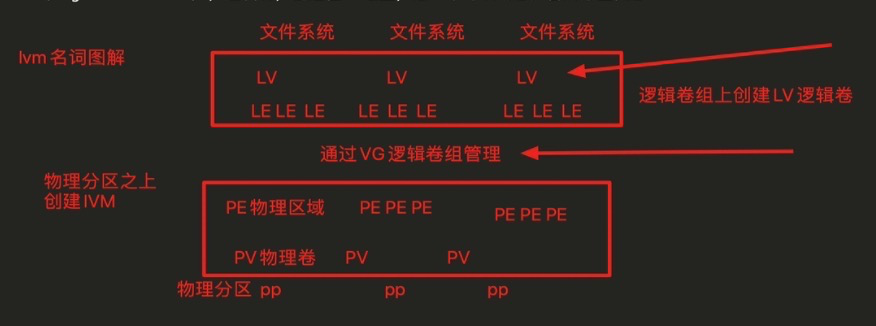
linux 一些命令
文章目录 linux 一些命令fdisk 磁盘分区parted 分区文件系统mkfs 格式化文件系统fsck 修复文件系统 mount 挂载swap 交换分区清除linux缓存df du 命令raid 命令基本原理硬raid 和 软raid案例raid 10 故障修复,重启与卸载 lvm逻辑卷技术LVM的使用方式LVM 常见名词解析…...
移动硬盘损坏打不开?别急,这里有解决方案!
在日常工作和生活中,移动硬盘几乎成为了我们必不可少的存储设备,它小巧便捷,能够容纳大量的数据。然而,当移动硬盘突然损坏打不开时,那份焦虑与无助几乎无法用言语来形容。那些重要的文件、珍贵的照片,似乎…...

微信小程序【从入门到精通】——服务器的数据交互
👨💻个人主页:开发者-曼亿点 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 曼亿点 原创 👨💻 收录于专栏:…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...

自制射频功率计:基于AD8317芯片,成本43欧元实现1MHz-10GHz测量
1. 项目概述:为什么我要亲手打造一台射频功率计在无人机和模型飞行器的圈子里,尤其是在我们荷兰FMS Spaarnwoude俱乐部,合规飞行是头等大事。我给我的八轴飞行器加装了云台相机和图传系统,工作在5.8GHz频段。根据本地法规…...
:这份内部测试SOP已被3家头部科技公司紧急采购)
DeepSeek-R1补全能力封测倒计时(仅剩72小时开放API灰度权限):这份内部测试SOP已被3家头部科技公司紧急采购
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全能力封测全景概览 DeepSeek-R1 是深度求索(DeepSeek)推出的高性能开源推理模型,在代码补全场景中展现出显著的上下文理解力与多语言泛化能力。本…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器
手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器 无人机开发者和爱好者们,是否曾想过用手机就能完成整个无人机仿真测试流程?告别笨重的电脑束缚,只需一部安卓设备,就能在沙发上调试飞控算法。…...

怎么理解Filter不是在afterCompetition里面remove掉ThreadLocal里面的东西,而是说在finally块里面remove
文章目录1. 核心原因:Filter 的“套娃(洋葱圈)”执行模型2. 为什么不能(也无法)在这里用 afterCompletion?维度一:Filter 拿不到 afterCompletion维度二:生命周期顺序的致命冲突总结…...