Hive on Spark 配置
目录
- 1 Hive 引擎简介
- 2 Hive on Spark 配置
- 2.1 在 Hive 所在节点部署 Spark
- 2.2 在hive中创建spark配置文件
- 2.3 向 HDFS上传Spark纯净版 jar 包
- 2.4 修改hive-site.xml文件
- 2.5 Hive on Spark测试
- 2.6 报错
1 Hive 引擎简介
Hive引擎包括:MR(默认)、tez、spark。
Hive on Spark:Hive既作为存储元数据又负责 SQL 的解析优化,语法是 HQL 语法,执行引擎变成了 Spark,Spark 负责采用 RDD 执行。
Spark on Hive:Hive 只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用 RDD 执行。
2 Hive on Spark 配置
注意:官网下载的Hive3.1.2和Spark3.0.0默认是不兼容的。因为Hive3.1.2支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本。
编译步骤:官网下载Hive3.1.2源码,修改pom文件中引用的Spark版本为3.0.0,如果编译通过,直接打包获取jar包。如果报错,就根据提示,修改相关方法,直到不报错,打包获取jar包。

2.1 在 Hive 所在节点部署 Spark
(1)Spark官网下载 jar 包地址:http://spark.apache.org/downloads.html
(2)上传并解压解压spark-3.0.0-bin-hadoop3.2.tgz
[huwei@hadoop101 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
[huwei@hadoop101 software]$ mv /opt/module/spark-3.0.0-bin-hadoop3.2 /opt/module/spark
(3)配置 SPARK_HOME 环境变量
[huwei@hadoop101 module]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
使环境变量生效
[huwei@hadoop101 module]$ source /etc/profile.d/my_env.sh
2.2 在hive中创建spark配置文件
[huwei@hadoop101 software]$ cd /opt/module/hive-3.1.2/conf/
[huwei@hadoop101 conf]$ vim spark-defaults.conf
添加如下内容
spark.master=yarn
spark.eventLog.enabled=true
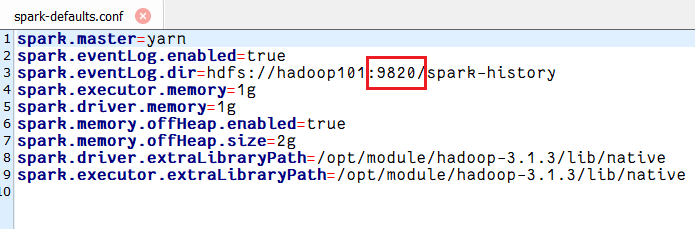
spark.eventLog.dir=hdfs://hadoop101:9820/spark-history
spark.executor.memory=1g
spark.driver.memory=1g
spark.memory.offHeap.enabled=true
spark.memory.offHeap.size=2g
spark.driver.extraLibraryPath=/opt/module/hadoop-3.1.3/lib/native
spark.executor.extraLibraryPath=/opt/module/hadoop-3.1.3/lib/native
在HDFS创建如下路径,用于存储历史日志
[huwei@hadoop101 conf]$ hadoop fs -mkdir /spark-history
2.3 向 HDFS上传Spark纯净版 jar 包
由于Spark3.0.0非纯净版默认支持的是 hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
(1)上传并解压spark-3.0.0-bin-without-hadoop.tgz
[huwei@hadoop101 conf]$ tar -zxvf /opt/software/spark-3.0.0-bin-without-hadoop.tgz -C /opt/module/
(2)上传Spark纯净版jar包到HDFS
[huwei@hadoop101 conf]$ hadoop fs -mkdir /spark-jars
[huwei@hadoop101 conf]$ hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
2.4 修改hive-site.xml文件
[huwei@hadoop101 conf]$ vim /opt/module/hive-3.1.2/conf/hive-site.xml
添加如下内容
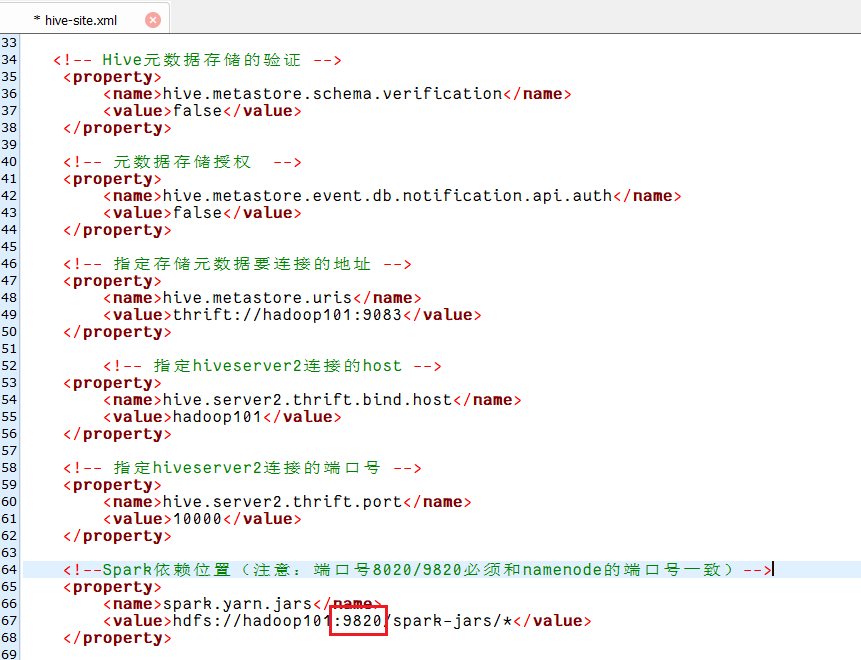
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property><name>spark.yarn.jars</name><value>hdfs://hadoop101:9820/spark-jars/*</value>
</property><!--Hive执行引擎-->
<property><name>hive.execution.engine</name><value>spark</value>
</property><!--Hive和Spark连接超时时间-->
<property><name>hive.spark.client.connect.timeout</name><value>10000ms</value>
</property>
2.5 Hive on Spark测试
(1)启动 spark
[huwei@hadoop101 ~]$ cd /opt/module/
[huwei@hadoop101 module]$ cd spark
[huwei@hadoop101 spark]$ sbin/start-all.sh(2)启动hive客户端
[huwei@hadoop101 conf]$ hive
(3)创建一张测试表
hive (default)> create table student(id int, name string);
(4)通过insert测试效果
hive (default)> insert into table student values(1,'abc');
若结果如下,则说明配置成功
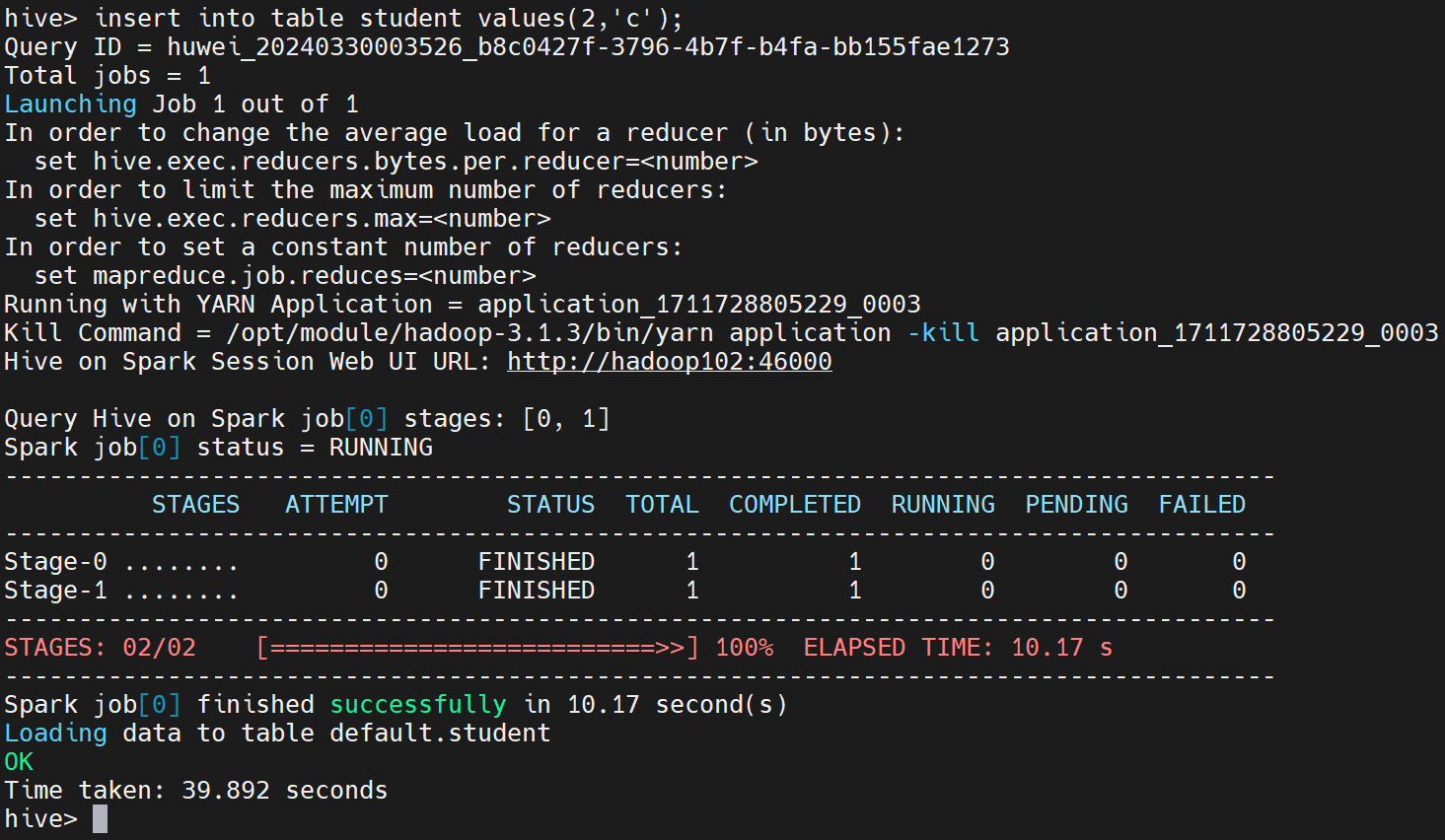
2.6 报错
在最后插入数据测试Hive on Spark的时候总是报错,也不是版本问题,也不是内存问题,困扰了一天了,最后发现跟着教程走的namenode端口号写成了8020,而我使用的是hadoop3版本,在安装hadoop时,将namenode端口号设的是9820
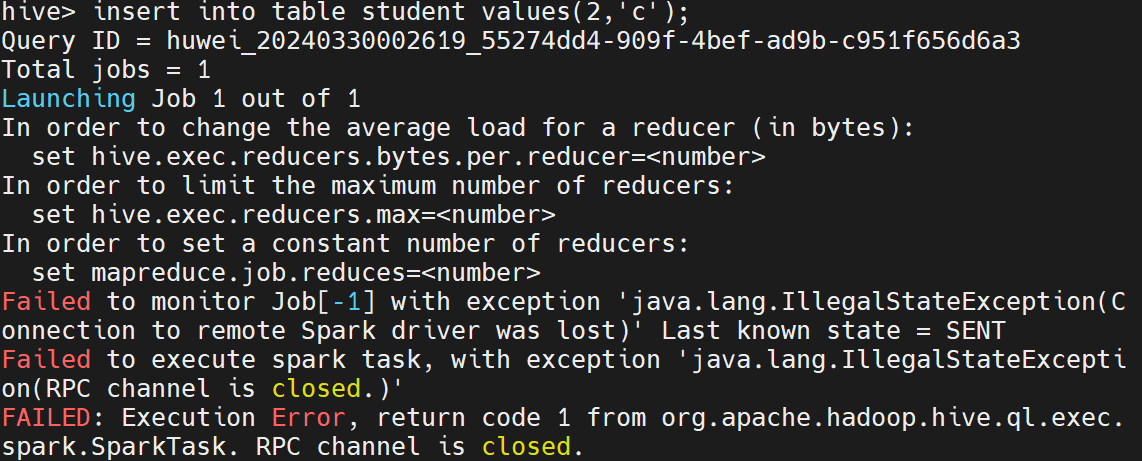
后来,我将以下两个配置文件namenode的端口号改成9820,最终才解决。
相关文章:
Hive on Spark 配置
目录 1 Hive 引擎简介2 Hive on Spark 配置2.1 在 Hive 所在节点部署 Spark2.2 在hive中创建spark配置文件2.3 向 HDFS上传Spark纯净版 jar 包2.4 修改hive-site.xml文件2.5 Hive on Spark测试2.6 报错 1 Hive 引擎简介 Hive引擎包括:MR(默认)…...

ROS 基本
ROS创建自己的功能包 ROS中工作空间(workspace)是一个存放工程开发相关文件的文件夹,其中有四个文件夹。 src:代码空间(Source Space)build:编译空间(Build Space)devel:开发空间(Development Space)install:安装空间(Install Space) OK接下来创作工作空间&#…...

Pygame基础9-射击
简介 玩家用鼠标控制飞机(白色方块)移动,按下鼠标后,玩家所在位置出现子弹,子弹匀速向右飞行。 代码 没有什么新的东西,使用两个精灵类表示玩家和子弹。 有一个细节需要注意,当子弹飞出屏幕…...

Ps:颜色查找
颜色查找 Color Lookup命令通过应用预设的 LUT 来改变图像的色彩和调性,从而为摄影师和设计师提供了一种快速实现复杂色彩调整的方法,广泛应用于颜色分级、视觉风格的统一和创意色彩效果的制作。 Ps菜单:图像/调整/颜色查找 Adjustments/Colo…...
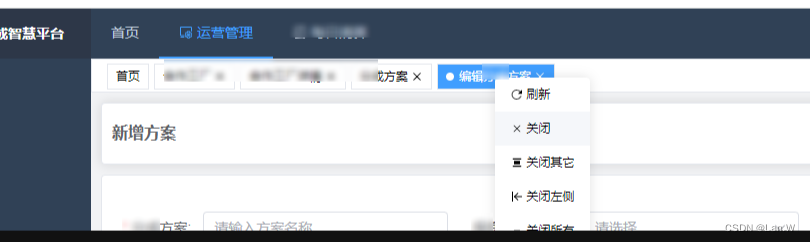
vue3+vite 模板vue3-element-admin框架如何关闭当前页面跳转 tabs
使用模版: 有来开源组织 / vue3-element-admin 需要关闭的.vue 页面增加以下方法 //setup 里import {LocationQuery, useRoute, useRouter} from "vue-router"; const router useRouter(); function close() {console.log(|--router.currentRoute.value, router.cur…...
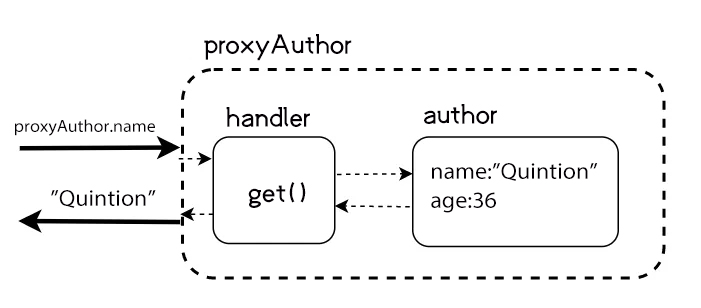
JavaScript 对象管家 Proxy
JavaScript 在 ES6 中,引入了一个新的对象类型 Proxy,它可以用来代理另一个对象,并可以在代理过程中拦截、覆盖和定制对象的操作。Proxy 对象封装另一个对象并充当中间人,其提供了一个捕捉器函数,可以在代理对象上拦截…...

Qt + Vs联合开发
Qt + Vs联合开发 文章目录 Qt + Vs联合开发环境说明VS+Qt安装注意事项QtCreator msvc编译器配置Visual Studio 2019 + Qt 5.12.10Visual Studio 2015 + Qt5.12.10VsQt环境配置安装插件 Qt Visual Studio Tools插件配置Qt创建项目Vs创建Qt项目VsQt工程转换Vs工程转Qt工程Qt工程转…...

开源知识库平台Raneto--使用Docker部署Raneto
文章目录 一、Raneto介绍1.1 Raneto简介1.2 知识库介绍 二、阿里云环境2.1 环境规划2.2 部署介绍 三、环境检查3.1 检查Docker服务状态3.2 检查Docker版本3.3 检查docker compose 版本 四、下载Raneto镜像五、部署Raneto知识库平台5.1 创建挂载目录5.2 编辑config.js文件5.3 编…...

鸿蒙原OS开发实例:【ArkTS类库单次I/O任务开发】
Promise和async/await提供异步并发能力,适用于单次I/O任务的场景开发,本文以使用异步进行单次文件写入为例来提供指导。 实现单次I/O任务逻辑。 import fs from ohos.file.fs; import common from ohos.app.ability.common;async function write(data:…...
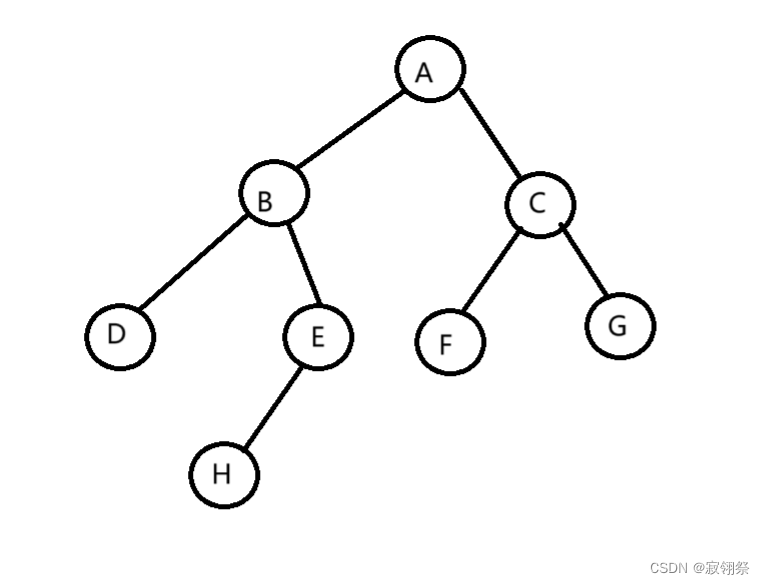
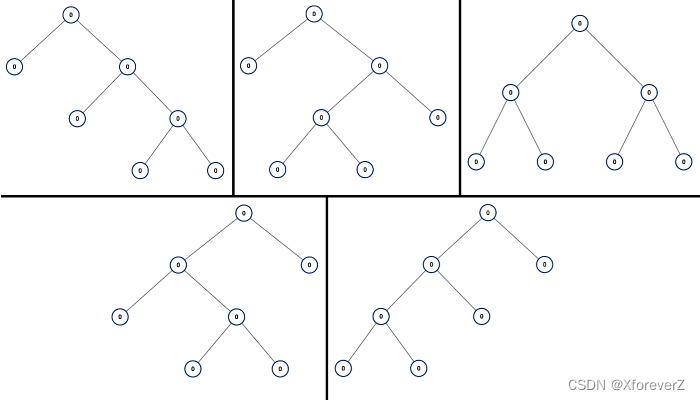
C语言:二叉树的构建
目录 一、二叉树的存储 1.1 顺序存储 1.2 链式存储 二、二叉树的顺序结构及实现 2.1堆的概念及结构 2.2堆的构建 2.3堆的插入 2.4堆顶的删除 2.5堆的完整代码 三、二叉树的链式结构及实现 3.1链式二叉树的构建 3.2链式二叉树的遍历 3.2.1前序遍历 …...

软件测试工程师面试汇总功能测试篇
Q:一、进行测试用例设计的时候用到的方法有哪些? A:最常使用的测试用例设计方法包括等价类划分法、边界值分析方法、场景法、错误推测法。其中,最容易 发现错误的是边界值法,使用最多的是场景法。以注册为例:首先从需求确定用户名…...

javaAPI1
API application pragramming interface 应用程序编程接口 除java.lang包以外,其他包中的类在使用时需要导入 建包 package com.abc.javabean; 导包格式,import 包名.类名 API使用技巧 1,先看关键字 2,看参数列表 3,看返回值类型 String 封装字符串和处理字符串的类…...

案例研究|DataEase实现物业数据可视化管理与决策支持
河北隆泰物业服务有限责任公司(以下简称为“隆泰物业”)创建于2002年,总部设在河北省高碑店市,具有国家一级物业管理企业资质,通过了质量体系、环境管理体系、职业健康安全管理体系等认证。自2016年至今,隆…...
Android Studio Iguana | 2023.2.1 补丁 1
Android Studio Iguana | 2023.2.1 Canary 3 已修复的问题Android Gradle 插件 问题 295205663 将 AGP 从 8.0.2 更新到 8.1.0 后,任务“:app:mergeReleaseClasses”执行失败 问题 298008231 [Gradle 8.4][升级] 由于使用 kotlin gradle 插件中已废弃的功能&#…...

iOS17 隐私协议适配详解
1. 背景 网上搜了很多文章,总算有点头绪了。其实隐私清单最后做出来就是一个plist文件。找了几个常用三方已经配好的看了看,比着做就好了。 WWDC23 中关于隐私部分的更新(WWDC23 隐私更新官网),其中提到了第三方 SDK 的…...
LeetCode 每日一题 Day 116-122
2580. 统计将重叠区间合并成组的方案数 给你一个二维整数数组 ranges ,其中 ranges[i] [starti, endi] 表示 starti 到 endi 之间(包括二者)的所有整数都包含在第 i 个区间中。 你需要将 ranges 分成 两个 组(可以为空…...

linux离线安装jenkins及使用教程
本教程采用jenkins.war的方式离线安装部署,在线下载的方式会遇到诸多问题,不宜采用 基本环境: 1.jdk环境,Jenkins是java语言开发的,因需要jdk环境。 2.git/svn客户端,因一般代码是放在git/svn服务器上的&a…...
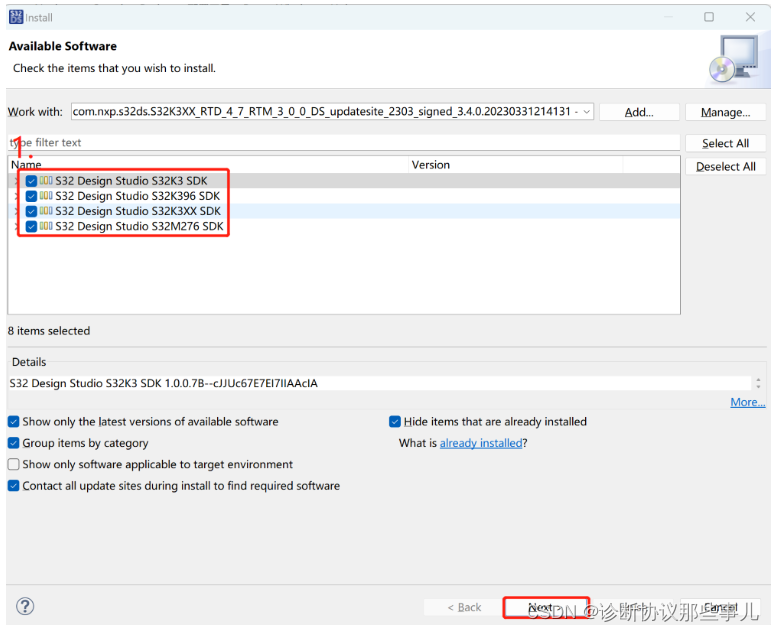
NXP-S32DS软件安装
文章目录 一、安装包获取二、S32DS安装三、芯片插件安装 一、安装包获取 登录NXP官网,进入软件目录https://www.nxp.com/ 下载S32DS软件和RTD驱动库,并安装S32DS软件。 单击“S32DS.3.5_b220726_win32.x86_64.exe”下载该软件 点击“License Keys”&…...
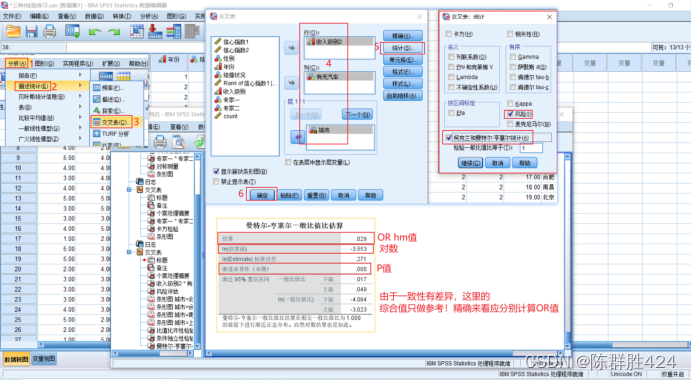
26版SPSS操作教程(初级第十五章)
前言 #由于导师最近布置了学习SPSS这款软件的任务,因此想来平台和大家一起交流下学习经验,这期推送内容接上一次第十四章的学习笔记,希望能得到一些指正和帮助~ 粉丝及官方意见说明 #针对官方爸爸的意见说的推送缺乏操作过程的数据案例文件…...
docker部署实用的运维开发手册
下载镜像 docker pull registry.cn-beijing.aliyuncs.com/wuxingge123/reference:latestdocker-compose部署 vim docker-compose.yml version: 3 services:reference:container_name: referenceimage: registry.cn-beijing.aliyuncs.com/wuxingge123/reference:latestports:…...

Perplexity无法解析Springer LaTeX公式?2024.06最新MathJax兼容补丁+3类数学文献精准摘要生成术
更多请点击: https://intelliparadigm.com 第一章:Perplexity解析Springer文献的底层机制与失效归因 Perplexity 作为衡量语言模型预测能力的关键指标,在学术文献解析场景中常被误用为“质量代理”,尤其在处理 Springer 出版集团…...

EmbedClaw:RAG应用中文本智能分块与向量化检索的工程实践
1. 项目概述:一个面向嵌入向量检索的“机械爪”最近在折腾RAG(检索增强生成)应用,发现向量数据库的检索效果,很大程度上取决于你“喂”进去的文本是怎么被切成一块一块的(也就是分块,Chunking&a…...

Fomu FPGA工作坊:从LED闪烁到RISC-V软核的微型硬件开发指南
1. 项目概述:当FPGA遇见指尖,一场硬件的微型革命如果你对嵌入式开发、硬件编程感兴趣,但又觉得传统的FPGA开发板笨重、昂贵且入门门槛高,那么im-tomu/fomu-workshop这个项目可能会让你眼前一亮。这不仅仅是一个代码仓库࿰…...

Arm DDT:高性能计算并行程序调试利器
1. Arm DDT调试工具概述Arm DDT(Distributed Debugging Tool)是Arm公司开发的一款专业级并行程序调试工具,专为高性能计算(HPC)领域设计。作为Arm Forge工具套件的重要组成部分,DDT提供了强大的MPI程序调试…...

从ARIMA差分到MIM网络:一个老派时间序列技巧如何革新了深度学习预测
从差分思想到记忆网络:传统时间序列技巧如何重塑深度学习架构 在气象预报的雷达回波图中,降水云团的形态每秒钟都在剧烈变化;城市交通流量监测数据里,早晚高峰的波动与平峰期形成鲜明对比;股票市场的价格曲线更是以难以…...
算力优化细节详解)
DeepSeek(V3为主、兼顾V2/R1)算力优化细节详解
DeepSeek(V3为主、兼顾V2/R1)算力优化细节详解以下是针对核心优化模块的深入技术拆解,包含MLA数学原理、FP8精准实现、无辅助损失负载均衡、R1-GRPO算法核心,内容基于DeepSeek-V3官方技术报告及2026年5月公开权威分析。DeepSeek系…...

WarcraftHelper魔兽争霸III优化工具:让你的经典游戏重获新生
WarcraftHelper魔兽争霸III优化工具:让你的经典游戏重获新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔兽争霸III》…...

为 OpenClaw 配置 Taotoken 以实现自动化工作流中的模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 OpenClaw 配置 Taotoken 以实现自动化工作流中的模型调用 OpenClaw 是一款强大的自动化工作流工具,能够通过编排任务…...

AI碳足迹深度解析:从模型压缩到软硬协同的绿色AI实践
1. 从“算力怪兽”到“绿色引擎”:AI碳足迹问题的深度拆解 最近和几个在芯片厂和云服务商工作的老朋友聊天,话题总绕不开一个词:电费。不是开玩笑,现在训练一个大模型,电费账单能轻松超过一个小型数据中心的日常运维成…...

零代码到全球上线:我用 Dify + EdgeOne Pages 为跨境电商打造了一个 7×24 小时 AI 智能客服
文章目录每日一句正能量目录1. 引言:一个独立站卖家的深夜焦虑2. 技术选型:为什么选择 Dify EdgeOne Pages?3. 场景拆解:跨境电商客服的三大核心痛点3.1 痛点一:意图混杂,一句话可能包含多个需求3.2 痛点二…...