C++ :STL中deque的原理
deque的结构类似于哈希表,使用一个指针数组存储固定大小的数组首地址,当数据分布不均匀时将指针数组内的数据进行偏移,桶不够用的时候会像vector一样扩容然后将之前数组中存储的指针拷贝过来,从原理可以看出deque的性能是非常高的,它不存咋像vector那样大规模的数据拷贝和大批量连续空间的需求同时也弥补了像list不支持随机访问的缺点,可以说deque集中了list和vector的大部分优点,当然缺点很致命在中间节点插入数据的时候会异常复杂,高效的前后端插入机制使得stack和queue都适配于deque。
vector动态数组
- 支持随机访问
- 可以自动扩容
- 只支持末端插入
list双向链表
- 不支持随机访问
- 支持任意位置插入
- 无需扩容
deque双端队列(vector< Array >)
- 支持随机访问(伪随机)
- 微量扩容
- 支持前后端插入
看下面一段代码
#include<iostream>
#include<deque>
using namespace std;
struct T{~T(){cout<<"T析构";}}
void Add_head(deque<int>&q){q.push_front(1);cout<<&q.front()<<" "<<endl;
}void Add_tail(deque<int>&q){q.push_back(1);cout<<&q.back()<<" "<<endl;
}int main(){deque<int>q;for(int i=0;i<10;i++) Add_head(q);for(int i=0;i<10;i++) Add_tail(q);
}
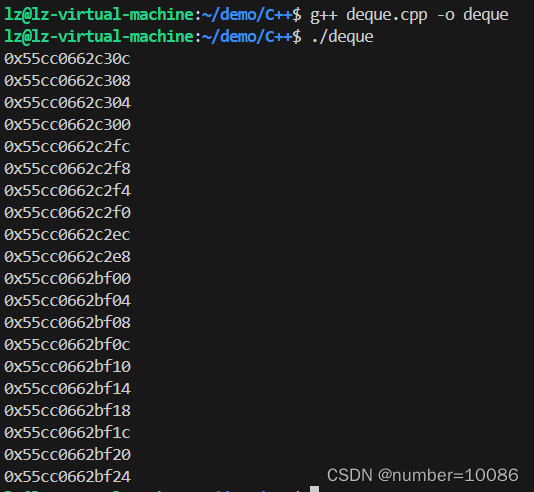
从地址大概可以看出这个东西是一块一块的,块的大小是固定的,而且块内地址是连续的,想要获取更多的信息的话还要结合源码,网上有说deque是数组链表的,但如果简单的理解为链表的话就大错特错了,这么理解的话随机访问是实现不了的,我觉得理解为一种特殊的二维数组比较好。
下面看具体一些功能的实现
看下_Deque_val模板,_Block_size 表示单个数组元素个数,这里是根据元素的大小决定单个数组的大小,_Mapptr 是桶里面装一维数组的指针,_Mapsize桶的大小根据注释可以看到桶的扩容是指数级的,_Myoff存储偏移量,_Mysize存储元素个数
注意:这个偏移量是针对_Mapptr 的头部开始到当前元素的偏移量,此外单个数组的大小受限于数据大小,所以很多时候双端队列会表现的像维护在指针数组上的链表
// CLASS TEMPLATE _Deque_val
template <class _Val_types>
class _Deque_val : public _Container_base12 {
public:using value_type = typename _Val_types::value_type;using size_type = typename _Val_types::size_type;using difference_type = typename _Val_types::difference_type;using pointer = typename _Val_types::pointer;using const_pointer = typename _Val_types::const_pointer;using reference = value_type&;using const_reference = const value_type&;using _Mapptr = typename _Val_types::_Mapptr;
private:static constexpr size_t _Bytes = sizeof(value_type);
public:static constexpr int _Block_size =_Bytes <= 1 ? 16 : _Bytes <= 2 ? 8 : _Bytes <= 4 ? 4 : _Bytes <= 8 ? 2 : 1; // elements per block (a power of 2)_Deque_val() noexcept : _Map(), _Mapsize(0), _Myoff(0), _Mysize(0) {}size_type _Getblock(size_type _Off) const noexcept {// NB: _Mapsize and _Block_size are guaranteed to be powers of 2return (_Off / _Block_size) & (_Mapsize - 1);}_Mapptr _Map; // pointer to array of pointers to blockssize_type _Mapsize; // size of map array, zero or 2^Nsize_type _Myoff; // offset of initial elementsize_type _Mysize; // current length of sequence
};
这个是_Mapptr 这个桶的基类,可以看到使用的是二级指针,它的作用就是维护一种二维的结构,这时候可能好奇了它作为一个单独的模板是如何适配作为_Deque_val 模板类型的一部分的。
template <class _Ty>
struct _Deque_simple_types : _Simple_types<_Ty> {using _Mapptr = _Ty**;
};
这个适配器完成了适配工作,将多个类适配为一个类很大程度上提高了代码的可读性,使得代码可以更高的遵循开闭原则。
template <bool _Test, class _Ty1, class _Ty2>
struct conditional { // Choose _Ty1 if _Test is true, and _Ty2 otherwiseusing type = _Ty1;
};
template <class _Ty1, class _Ty2>
struct conditional<false, _Ty1, _Ty2> {using type = _Ty2;
};
template <bool _Test, class _Ty1, class _Ty2>
using conditional_t = typename conditional<_Test, _Ty1, _Ty2>::type;
deque中迭代器访问元素,使用偏移量获取存储的行和列。
_NODISCARD reference operator*() const noexcept {const auto _Mycont = static_cast<const _Mydeque*>(this->_Getcont());
#if _ITERATOR_DEBUG_LEVEL != 0_STL_VERIFY(_Mycont, "cannot dereference value-initialized deque iterator");_STL_VERIFY(_Mycont->_Myoff <= this->_Myoff && this->_Myoff < _Mycont->_Myoff + _Mycont->_Mysize,"cannot deference out of range deque iterator");
#endif // _ITERATOR_DEBUG_LEVEL != 0_Size_type _Block = _Mycont->_Getblock(_Myoff);_Size_type _Off = _Myoff % _Block_size;return _Mycont->_Map[_Block][_Off];}
那么现在就有一个问题,如果插入元素时集中在头部或者尾部时它会直接扩容吗?带着问题接着分析。
首先看一下emplace_back函数
template <class... _Tys>void _Emplace_back_internal(_Tys&&... _Vals) {if ((_Myoff() + _Mysize()) % _Block_size == 0 && _Mapsize() <= (_Mysize() + _Block_size) / _Block_size) {_Growmap(1);}_Myoff() &= _Mapsize() * _Block_size - 1;size_type _Newoff = _Myoff() + _Mysize();size_type _Block = _Getblock(_Newoff);if (_Map()[_Block] == nullptr) {_Map()[_Block] = _Getal().allocate(_Block_size);}_Alty_traits::construct(_Getal(), _Unfancy(_Map()[_Block] + _Newoff % _Block_size), _STD forward<_Tys>(_Vals)...);++_Mysize();}
可以看到整体逻辑和vector差不多,emplace_front也差不多就不看了,因为站在函数角度它的不需要关注是头插还是尾插。
这里的策略依旧是可以插入时插入不能插入时进行处理,直接看扩容处理函数,和直接注释的一样,如果没有可插入的空间时桶的大小变为原来的二倍,然后将指针挪到新的数组的中间即可,偏移量这些重新计算,这个环节虽然看起来很麻烦但是注意这里是针对指针的而不是针对元素的,所以说效率还是蛮高的。
void _Growmap(size_type _Count) { // grow map by at least _Count pointers, _Mapsize() a power of 2static_assert(1 < _Minimum_map_size, "The _Xlen() test should always be performed.");_Alpty _Almap(_Getal());size_type _Newsize = 0 < _Mapsize() ? _Mapsize() : 1;while (_Newsize - _Mapsize() < _Count || _Newsize < _Minimum_map_size) {// scale _Newsize to 2^N >= _Mapsize() + _Countif (max_size() / _Block_size - _Newsize < _Newsize) {_Xlen(); // result too long}_Newsize *= 2;}_Count = _Newsize - _Mapsize();size_type _Myboff = _Myoff() / _Block_size;_Mapptr _Newmap = _Almap.allocate(_Mapsize() + _Count);_Mapptr _Myptr = _Newmap + _Myboff;_Myptr = _STD uninitialized_copy(_Map() + _Myboff, _Map() + _Mapsize(), _Myptr); // copy initial to endif (_Myboff <= _Count) { // increment greater than offset of initial block_Myptr = _STD uninitialized_copy(_Map(), _Map() + _Myboff, _Myptr); // copy rest of old_Uninitialized_value_construct_n_unchecked1(_Myptr, _Count - _Myboff); // clear suffix of new_Uninitialized_value_construct_n_unchecked1(_Newmap, _Myboff); // clear prefix of new} else { // increment not greater than offset of initial block_STD uninitialized_copy(_Map(), _Map() + _Count, _Myptr); // copy more old_Myptr = _STD uninitialized_copy(_Map() + _Count, _Map() + _Myboff, _Newmap); // copy rest of old_Uninitialized_value_construct_n_unchecked1(_Myptr, _Count); // clear rest to initial block}_Destroy_range(_Map() + _Myboff, _Map() + _Mapsize());if (_Map() != _Mapptr()) {_Almap.deallocate(_Map(), _Mapsize()); // free storage for old}_Map() = _Newmap; // point at new_Mapsize() += _Count;}
stack和queue其实都是deque的适配器类,下面举个例子
template<class T,class dq=deque<T>>
class stk{
protected:dq d;
public:void pop(){d.pop_back();}void push(const T& val){d.push_back(val);}const T& top()const{return d.back();}
};
相关文章:
C++ :STL中deque的原理
deque的结构类似于哈希表,使用一个指针数组存储固定大小的数组首地址,当数据分布不均匀时将指针数组内的数据进行偏移,桶不够用的时候会像vector一样扩容然后将之前数组中存储的指针拷贝过来,从原理可以看出deque的性能是非常高的…...
AttributeError: ‘Namespace‘ object has no attribute ‘EarlyStopping‘
报错原因 这个报错信息表明在Python脚本train.py中尝试访问命令行参数args.EarlyStopping时出错,具体错误是AttributeError: Namespace对象没有名为EarlyStopping的属性。 在Python的argparse模块中,当我们通过命令行传递参数并解析时,解析…...

深度学习pytorch——卷积神经网络(持续更新)
计算机如何解析图片? 在计算机的眼中,一张灰度图片,就是许多个数字组成的二维矩阵,每个数字就是此点的像素值(图-1)。在存储时,像素值通常位于[0, 255]区间,在深度学习中࿰…...
【edge浏览器无法登录某些网站,以及迅雷插件无法生效的解决办法】
edge浏览器无法登录某些网站,以及迅雷插件无法生效的解决办法 edge浏览器无法登录某些网站,但chrome浏览器可以登录浏览器插件无法使用,比如迅雷如果重装插件重装浏览器重装迅雷后仍然出现问题 edge浏览器无法登录某些网站,但chro…...

OpenHarmony无人机MAVSDK开源库适配方案分享
MAVSDK 是 PX4 开源团队贡献的基于 MavLink 通信协议的用于无人机应用开发的 SDK,支持多种语言如 C/C、python、Java 等。通常用于无人机间、地面站与通信设备的消息传输。 MAVLink 是一种非常轻量级的消息传递协议,用于与无人机(以及机载无…...
模型训练----parser.add_argument添加配置参数
现在需要配置参数来达到修改训练的方式,我现在需要新建一个参数来开关wandb的使用。 首先就是在def parse_option():函数里添加上你要使用的变量名 parser.add_argument("--open_wandb",type bool,defaultFalse,helpopen wandb) 到config文件里增加你的…...

数字未来:探索 Web3 的革命性潜力
在当今数字化的时代,Web3作为互联网的新兴范式正逐渐崭露头角,引发了广泛的关注和探讨。本文将深入探索数字未来中Web3所蕴含的革命性潜力,探讨其对社会、经济和技术的深远影响。 1. Web3:数字世界的下一个阶段 Web3是一个正在崛…...
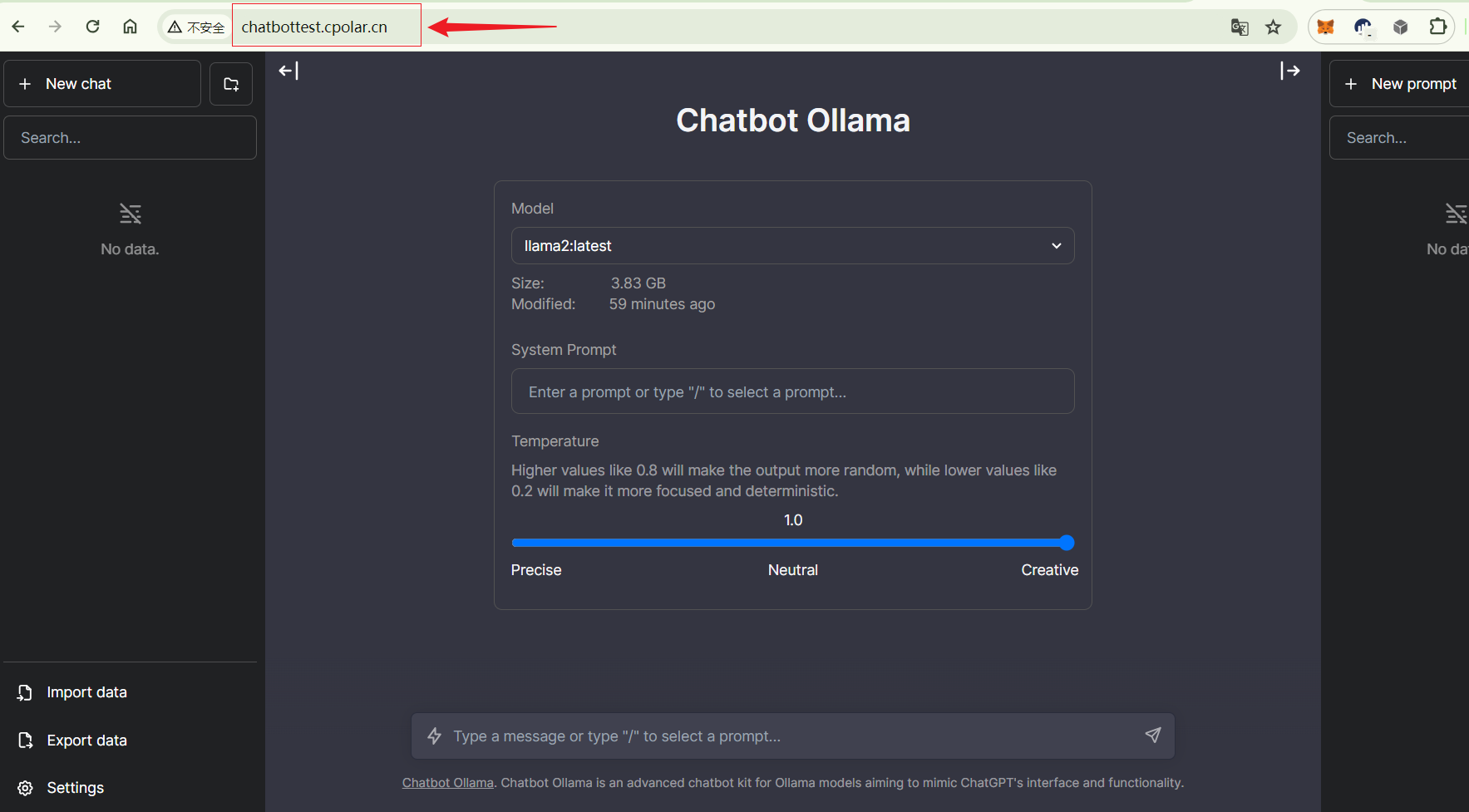
群晖NAS使用Docker部署大语言模型Llama 2结合内网穿透实现公网访问本地GPT聊天服务
文章目录 1. 拉取相关的Docker镜像2. 运行Ollama 镜像3. 运行Chatbot Ollama镜像4. 本地访问5. 群晖安装Cpolar6. 配置公网地址7. 公网访问8. 固定公网地址 随着ChatGPT 和open Sora 的热度剧增,大语言模型时代,开启了AI新篇章,大语言模型的应用非常广泛,包括聊天机…...

[选型必备基础信息] 存储器
存储芯片根据断电后是否保留存储的信息可分为易失性存储芯片(RAM)和非易失性存储芯片(ROM)。 简单说,存储类IC分为 ROM和RAM ROM:EEPROM / Flash / eMMC RAM:SRAM/SDRAM/DDR2/DDR3/DDR4/DDR5…...
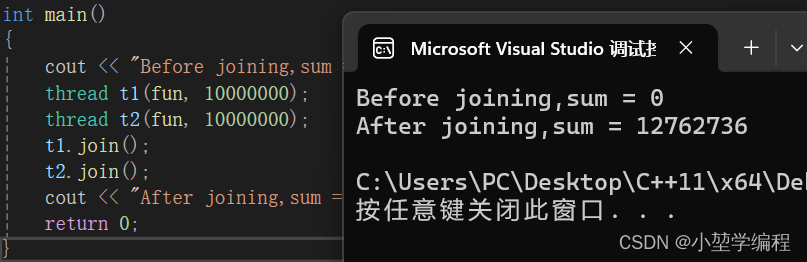
C++——C++11线程库
目录 一,线程库简介 二,线程库简单使用 2.1 传函数指针 编辑 2.2 传lamdba表达式 2.3 简单综合运用 2.4 线程函数参数 三,线程安全问题 3.1 为什么会有这个问题? 3.2 锁 3.2.1 互斥锁 3.2.2 递归锁 3.3 原子操作 3…...

机器学习 | 线性判别分析(Linear Discriminant Analysis)
1 机器学习中的建模 1.1 描述性建模 以方便的形式给出数据的主要特征,实质上是对数据的概括,以便在大量的或有噪声的数据中仍能观察到重要特征。重在认识数据的主要概貌,理解数据的重要特征。 Task:聚类分析,数据降…...

TypeScript-数组、函数类型
1.数组类型 1.1类型 方括号 let arry:number[][5,2,0,1,3,1,4] 1.2 数组泛型 let arry2:Array<number>[5,2,0,1,3,1,4] 1.3接口类型 interface makeArryRule{[index:number]:number }let arry3:makeArryRule[5,2,0,1,3,1,4] 1.4伪数组 说明: argument…...
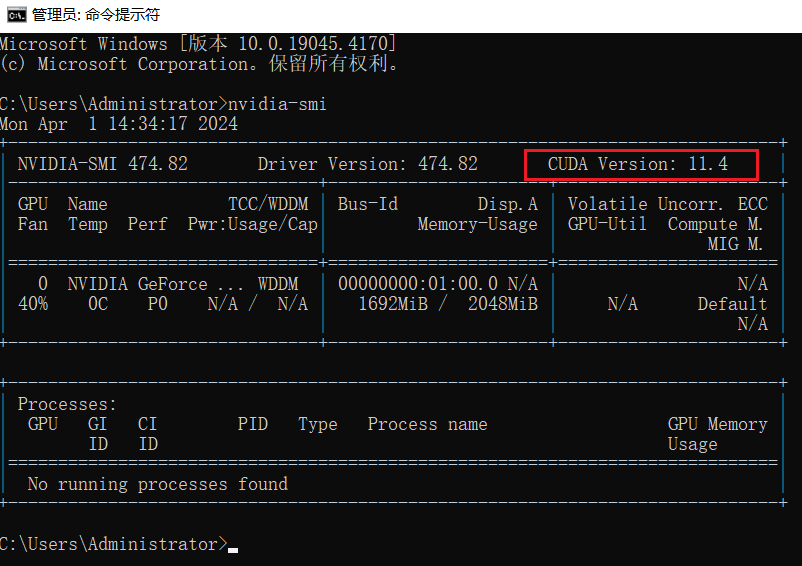
Python深度学习034:cuda的环境如何配置
文章目录 1.安装nvidia cuda驱动CMD中看一下cuda版本:下载并安装cuda驱动2.创建虚拟环境并安装pytorch的torch_cuda3.测试附录1.安装nvidia cuda驱动 CMD中看一下cuda版本: 注意: 红框的cuda版本,是你的显卡能装的最高的cuda版本,所以可以选择低于它的版本。比如我的是11…...
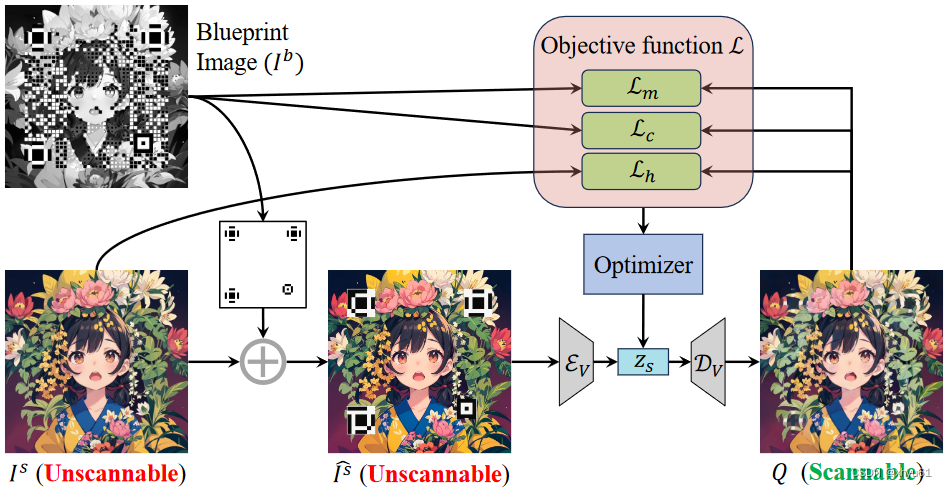
【论文笔记】Text2QR
论文:Text2QR: Harmonizing Aesthetic Customization and Scanning Robustness for Text-Guided QR Code Generation Abstract 二维码通常包含很多信息但看起来并不美观。stable diffusion的出现让平衡扫描鲁棒性和美观变为可能。 为了保证美观二维码的稳定生成&a…...
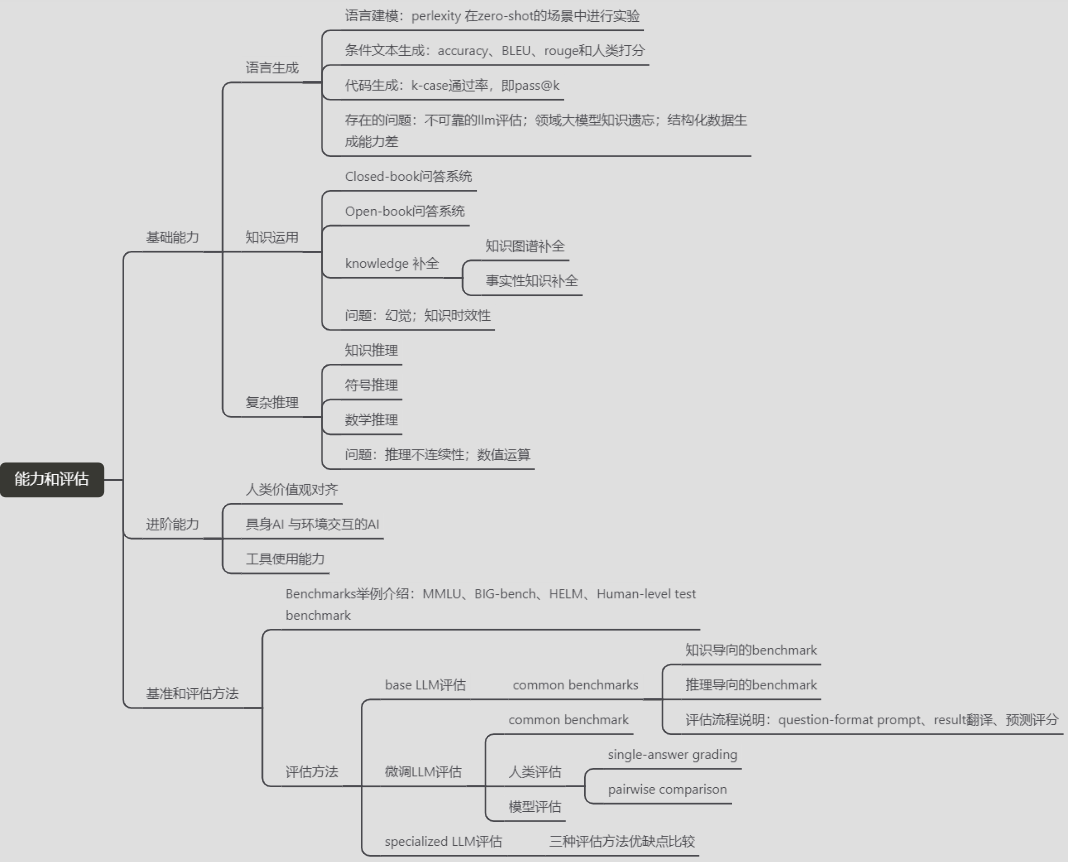
【ReadPapers】A Survey of Large Language Models
LLM-Survey的llm能力和评估部分内容学习笔记——思维导图 思维导图 参考资料 A Survey of Large Language Models论文的github仓库...

站群CMS系统
站群CMS系统是一种用于批量建立和管理网站的内容管理系统,它能够帮助用户快速创建大量的网站,并实现对这些网站的集中管理。以下是三个在使用广泛的站群CMS系统,它们各具特色,可以满足不同用户的需求。 1. Z-BlogPHP Z-BlogPHP是…...

landsat8数据产品说明
1、下载数据用户手册 手册下载网址,搜索landsat science关键词,并点击到官网下载。 2、用户手册目录 3、landsat8数据产品说明 具体说明在手册的第四章,4.1.4数据产品章节,具体描述如下: 英文意思: L8 的…...
Golang 内存管理和垃圾回收底层原理(二)
一、这篇文章我们来聊聊Golang内存管理和垃圾回收,主要注重基本底层原理讲解,进一步实战待后续文章 垃圾回收,无论是Java 还是 Golang,基本的逻辑都是基于 标记-清理 的, 标记是指标记可能需要回收的对象,…...
OpenHarmony:全流程讲解如何编写ADC平台驱动以及应用程序
ADC(Analog to Digital Converter),即模拟-数字转换器,可将模拟信号转换成对应的数字信号,便于存储与计算等操作。除电源线和地线之外,ADC只需要1根线与被测量的设备进行连接。 一、案例简介 该程序是基于…...

计算机学生求职简历的一些想法
面试真的是一件非常难的事情,因为在短短的半小时到一个小时,来判断一个同学行不行,其实是很不全面的。作为一个求职的同学应该怎么办呢?求职的同学可以提前做一些准备,其中比较重要的要数简历的编写。 简历的作用 简…...
)
紧急预警:Midjourney即将下架Nihonga相关风格标签?(内部消息+已存档的5类不可再生提示词组合,仅限今日开放获取)
更多请点击: https://intelliparadigm.com 第一章:Nihonga风格在Midjourney中的历史定位与美学内核 Nihonga(日本画)作为明治维新后确立的现代民族绘画体系,以天然矿物颜料、金箔银箔、胶质媒介及传统和纸为物质基础&…...

TinyRedis随笔
在TinyRedis的内存与AOF之间的关系中,AOF接入点在命令层中,因为只有在执行写命令,修改DB内存之后,再对AOF文件进行写入。但是这里也存在一个问题,如果对aof文件写入失败了呢,那就会造成内存与aof文件数据不…...

照片去背景的方法有哪些?2026年最全工具推荐与实用指南
前两天有个朋友问我,怎样能快速把证件照的底色换掉,还有电商卖家想给商品图去背景。我才意识到,现在还有很多人不知道照片去背景有这么多方便的办法。与其逐个讲解,我决定写篇文章,把我这些年试过的各种照片去背景的方…...

如何选择AI写论文工具?
本科生、研究生写论文常陷文献难找、逻辑混乱、查重超标、AI幻觉等困境,盲目用AI工具还易触碰学术诚信红线。本文结合学术规范、查重要求、功能适配与数据安全,实测AI论文工具,帮你精准选对合规高效的写作助手。一、先守学术合规底线…...
到Stream API:Java二维数组初始化的几种高效写法与性能对比)
从Arrays.fill()到Stream API:Java二维数组初始化的几种高效写法与性能对比
从Arrays.fill()到Stream API:Java二维数组初始化的几种高效写法与性能对比 在算法竞赛和数据处理应用中,二维数组的初始化往往是性能优化的第一个瓶颈。我曾在一个图像处理项目中,因为选择了不当的初始化方式,导致整体性能下降了…...

STC8H8K64U单片机IAP升级实战:从官方例程到自定义协议的完整移植指南
STC8H8K64U单片机IAP升级实战:从官方例程到自定义协议的完整移植指南 在嵌入式系统开发中,固件升级是一个永恒的话题。想象一下这样的场景:你的设备已经部署在客户现场,突然发现了一个需要紧急修复的Bug,或者需要增加新…...

从平面到立体:ImageToSTL如何让任何图片在3分钟内变成立体可打印模型
从平面到立体:ImageToSTL如何让任何图片在3分钟内变成立体可打印模型 【免费下载链接】ImageToSTL This tool allows you to easily convert any image into a 3D print-ready STL model. The surface of the model will display the image when illuminated from t…...

3分钟快速上手:91160-cli医疗预约自动化助手完整指南
3分钟快速上手:91160-cli医疗预约自动化助手完整指南 【免费下载链接】91160-cli 健康160全自动挂号脚本,捡漏神器 项目地址: https://gitcode.com/gh_mirrors/91/91160-cli 还在为医院挂号难而烦恼吗?91160-cli是一款专为医疗预约设计…...

CREO 6.0装配实战:别再乱拖零件了,手把手教你用‘移动’和‘角度偏移’精准定位
CREO 6.0装配实战:从零件乱飞到精准定位的进阶技巧 刚接触CREO装配模块的新手设计师,最常遇到的挫败感莫过于:明明在脑海中构思好了零件位置,实际操作时却总是出现零件"乱飞"、"定位不准"的情况。这种体验就像…...

汽车芯片市场深度解析:从电动化、智能化到供应链变革
1. 汽车芯片行业:短期阵痛与长期增长的辩证观最近和几个在车厂和Tier 1供应商做研发的老朋友聊天,大家普遍的感觉是:冰火两重天。一边是终端市场感觉“卷”得厉害,销量波动、价格战不停;另一边,研发部门的芯…...