2.Elasticsearch入门
2.Elasticsearch入门
[toc]
1.Elasticsearch简介
Elasticsearch是用Java开发并且是当前最流行的开源的企业级搜索引擎。 能够达到实时搜索,稳定,可靠,快速,安装使用方便。
客户端支持Java、.NET(C#)、PHP、Python、Ruby等多种语言。
创始人:Shay Banon(谢巴农)
下载地址
官网地址:https://www.elastic.co/
应用场景
百度搜索
商城搜索
热榜搜索
2.Elasticsearch与Lucene的关系
Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库(框 架)
但是想要使用Lucene,必须使用Java来作为开发语言并将其直接集成到你的应用 中,并且Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它 是如何工作的。
Lucene缺点
只能在Java项目中使用,并且要以jar包的方式直接集成项目中.
使用非常复杂-创建索引和搜索索引代码繁杂
不支持集群环境-索引数据不同步(不支持大型项目)
索引数据如果太多就不行,索引库和应用所在同一个服务器,共同占用硬 盘.共用空间少.
3.ES和Solr比较
检索速度
当单纯的对已有数据进行搜索时,Solr更快。
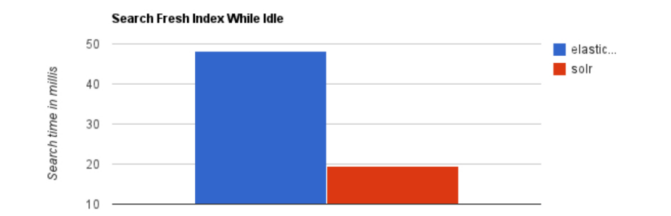
当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的 优势。
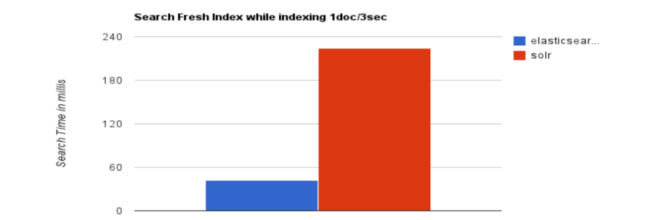
大型互联网公司,实际生产环境测试,将搜索引擎从Solr转到 Elasticsearch以后 的平均查询速度有了50倍的提升。
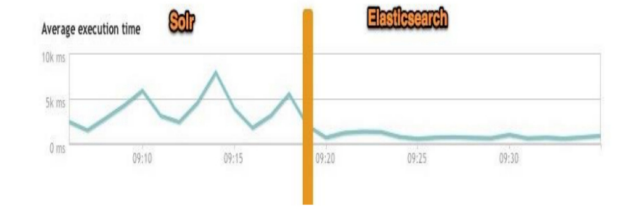
总结
二者安装都很简单。
Solr 利用 Zookeeper 进行分布式管理,而Elasticsearch 自身带有分布式协调 管理功能。
Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持 json文件格式。
Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时 效率明显低于 Elasticsearch。
Solr 是传统搜索应用的有力解决方案,但 Elasticsearch更适用于新兴的实时 搜索应用。
4.ES vs 关系型数据库
关系型数据库 | Database(数据库) | Table(表) | Row(行) | Column(列) |
Elasticsearch | index(索引库) | type(类型) | document(文档) | field(字段) |
5.Lucene全文检索框架
什么是全文检索
通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单 词在文本中的位置、以及出现的次数
用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位 置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内 容读取出来了
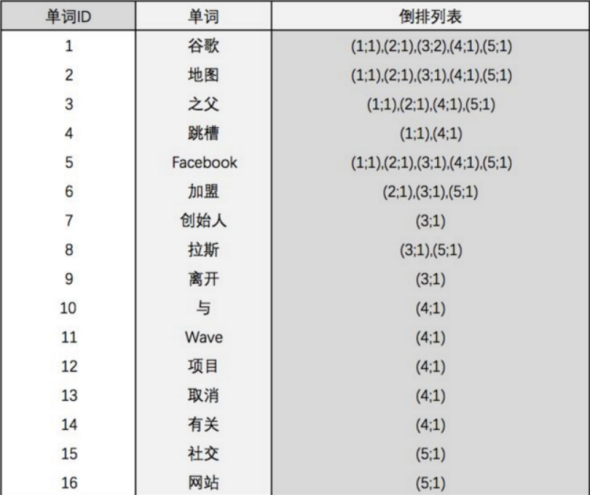
分词原理之倒排索引


6.Elasticsearch中的核心概念
索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据 的索引,另一个产品目录的索引,还有一个订单数据的索引 一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这 个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字
映射 mapping
ElasticSearch中的映射(Mapping)用来定义一个文档
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认 值、分词器、是否被索引等等,这些都是映射里面可以设置的
字段 Field
相当于是数据表的字段|列
字段类型 Type
每一个字段都应该有一个对应的类型,例如:Text、Keyword、Byte等
文档 document
一个文档是一个可被索引的基础信息单元,类似一条记录。文档以JSON(Javascript Object Notation)格式来表示;
集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提 供索引和搜索功能
节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索 引和搜索功能
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每 个节点都会被安排加入到一个叫做“elasticsearch”的集群中
这意味着,如果在网络中启动了若干个节点,并假定它们能够相互发现彼此,它们 将会自动地形成并加入到一个叫做“elasticsearch”的集群中
在一个集群里,可以拥有任意多个节点。而且,如果当前网络中没有运行任何 Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫 做“elasticsearch”的集群。
分片 shard
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10 亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或 者单个节点处理搜索请求,响应太慢
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些 份就叫做分片
当创建一个索引的时候,可以指定你想要的分片的数量
每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以 被放置到集群中的任何节点上
分片很重要,主要有两方面的原因,允许水平分割/扩展你的内容容量;允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由 Elasticsearch管理的,对于作为用户来说,这些都是透明的
副本 replicas
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎 么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转 移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分 片的一份或多份拷贝,这些拷贝叫做副本分片,或者直接叫副本
副本之所以重要,有两个主要原因
在分片/节点失败的情况下,提供了高可用性。注意到复制分片从不与原/主要(original/primary)分片置于同一节点 上是非常重要的
扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行;每个索引可以被分成多个分片。一个索引有0个或者多个副本;
一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数 量可以在索引 创建的时候指定
在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变 分片的数量
7.分词器
分词器:standard
# 分词 分词器:standard
POST _analyze
{"analyzer": "standard","text":"我爱你中国"
}分词结果
{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "<IDEOGRAPHIC>","position" : 0},{"token" : "爱","start_offset" : 1,"end_offset" : 2,"type" : "<IDEOGRAPHIC>","position" : 1},{"token" : "你","start_offset" : 2,"end_offset" : 3,"type" : "<IDEOGRAPHIC>","position" : 2},{"token" : "中","start_offset" : 3,"end_offset" : 4,"type" : "<IDEOGRAPHIC>","position" : 3},{"token" : "国","start_offset" : 4,"end_offset" : 5,"type" : "<IDEOGRAPHIC>","position" : 4}]
}分词器:ik_smart(会做最粗粒度的拆分)
# 分词 分词器:ik_smart,会做最粗粒度的拆分
POST _analyze
{"analyzer": "ik_smart","text":"中华人民共和国"
}分词结果
{"tokens" : [{"token" : "中华人民共和国","start_offset" : 0,"end_offset" : 7,"type" : "CN_WORD","position" : 0}]
}分词器:ik_max_word(会将文本做最细粒度的拆分)
# 分词 分词器:ik_max_word,会将文本做最细粒度的拆分
POST _analyze
{"analyzer": "ik_max_word","text":"中华人民共和国"
}分词结果
{"tokens" : [{"token" : "中华人民共和国","start_offset" : 0,"end_offset" : 7,"type" : "CN_WORD","position" : 0},{"token" : "中华人民","start_offset" : 0,"end_offset" : 4,"type" : "CN_WORD","position" : 1},{"token" : "中华","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 2},{"token" : "华人","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 3},{"token" : "人民共和国","start_offset" : 2,"end_offset" : 7,"type" : "CN_WORD","position" : 4},{"token" : "人民","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 5},{"token" : "共和国","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 6},{"token" : "共和","start_offset" : 4,"end_offset" : 6,"type" : "CN_WORD","position" : 7},{"token" : "国","start_offset" : 6,"end_offset" : 7,"type" : "CN_CHAR","position" : 8}]
}8.指定IK分词器作为默认分词器
ES的默认分词设置是standard,这个在中文分词时就比较尴尬了,会单字拆分,比 如我搜索关键词“清华大学”,这时候会按“清”,“华”,“大”,“学”去分 词,然后搜出来的都是些“清清的河水”,“中华儿女”,“地大物博”,“学而 不思则罔”之类的莫名其妙的结果,这里我们就想把这个分词方式修改一下,于是 呢,就想到了ik分词器,有两种ik_smart和ik_max_word。
ik_smart会将“清华大学”整个分为一个词,而ik_max_word会将“清华大学”分 为“清华大学”,“清华”和“大学”,按需选其中之一就可以了。
修改默认分词方法(这里修改school_index索引的默认分词为:ik_max_word):
# 修改默认分词器
PUT /school_index
{"settings":{"index":{"analysis.analyzer.default.type":"ik_max_word"}}
}9.ES数据管理
ES数据管理概述
ES是面向文档(document oriented)的,这意味着它可以存储整个对象或文档 (document)。
然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。 在ES中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
ES使用JSON作为文档序列化格式。
JSON现在已经被大多语言所支持,而且已经成为NoSQL领域的标准格式。
ES存储的一个员工文档的格式示例:
{"email": "584614151@qq.com","name": "张三","age": 30,"interests": ["篮球","健身"]
}10.ES基本操作
创建索引
PUT /索引名称
PUT /es_db查询索引
GET /索引名称
GET /es_db删除索引
DELETE /索引名称
DELETE /es_db添加文档
PUT /索引名称/类型/id
# 创建索引
PUT /es_db# 添加文档
PUT /es_db/_doc/1
{"name": "张三","sex": 1,"age": 25,"address": "广州天河公园","remark": "java developer"
}# 添加文档
PUT /es_db/_doc/2
{"name": "李四","sex": 1,"age": 28,"address": "上海金融大厦","remark": "java assistant"
}# 添加文档
PUT /es_db/_doc/3
{"name": "rod","sex": 0,"age": 26,"address": "广州白云山公园","remark": "php developer"
}# 添加文档
PUT /es_db/_doc/4
{"name": "admin","sex": 0,"age": 22,"address": "长沙橘子洲头","remark": "python assistant"
}# 添加文档
PUT /es_db/_doc/5
{"name": "小明","sex": 0,"age": 19,"address": "长沙岳麓山","remark": "java architect assistant"
}修改文档
PUT /索引名称/类型/id
PUT /es_db/_doc/2
{"name": "李四-修改","sex": 1,"age": 99,"address": "上海金融大厦-修改","remark": "java assistant-修改"
}查询文档
GET /索引名称/类型/id
GET /es_db/_doc/2结果
{"_index" : "es_db","_type" : "_doc","_id" : "2","_version" : 2,"_seq_no" : 5,"_primary_term" : 1,"found" : true,"_source" : {"name" : "李四-修改","sex" : 1,"age" : 99,"address" : "上海金融大厦-修改","remark" : "java assistant-修改"}
}删除文档
DELETE /索引名称/类型/id
DELETE /es_db/_doc/2结果
{"_index" : "es_db","_type" : "_doc","_id" : "2","_version" : 3,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 6,"_primary_term" : 1
}11.Restful认识
Restful是一种面向资源的架构风格,可以简单理解为:使用URL定位资源,用HTTP 动词(GET,POST,DELETE,PUT)描述操作。 基于Restful API ES和所有客户端的交 互都是使用JSON格式的数据.
其他所有程序语言都可以使用RESTful API,通过9200端口的与ES进行通信
GET 查询
PUT 添加
POST 修改
DELE 删除
使用Restful的好处
透明性,暴露资源存在。
充分利用 HTTP 协议本身语义,不同请求方式进行不同的操作
12.ES中的查询操纵
查询当前类型中所有的文档
GET /索引名称/类型/_search GET /es_db/_doc/_searchSQL: select * from student结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 5,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"name" : "rod","sex" : 0,"age" : 26,"address" : "广州白云山公园","remark" : "php developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "4","_score" : 1.0,"_source" : {"name" : "admin","sex" : 0,"age" : 22,"address" : "长沙橘子洲头","remark" : "python assistant"}},{"_index" : "es_db","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"name" : "小明","sex" : 0,"age" : 19,"address" : "长沙岳麓山","remark" : "java architect assistant"}}]}
}条件查询,想要查询age等于28岁的
GET /索引名称/类型/_search?q=*:***GET /es_db/_doc/_search?q=age:28SQL: select * from student where age = 28结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]}
}25岁
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}}]}
}范围查询,如果查询25 <= age <= 28,TO必须大写
GET /索引名称/类型/_search?q=***[25 TO 28]GET /es_db/_doc/_search?q=age[25 TO 28]SQL: select * from student where age between 25 and 26结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 30,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"name" : "rod","sex" : 0,"age" : 26,"address" : "广州白云山公园","remark" : "php developer"}}]}
}根据多个ID进行批量查询 _mget
GET /索引名称/类型/_mgetGET /es_db/_doc/_mget
{"ids":["1","2"]
}SQL: select * from student where id in (1,2)# 根据多个ID批量查询
GET /es_db/_doc/_mget
{"ids":["1","3"]
}结果
#! Deprecation: [types removal] Specifying types in multi get requests is deprecated.
{"docs" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "3","_version" : 1,"_seq_no" : 2,"_primary_term" : 1,"found" : true,"_source" : {"name" : "rod","sex" : 0,"age" : 26,"address" : "广州白云山公园","remark" : "php developer"}}]
}查询年龄小于等于28岁的
GET /索引名称/类型/_search?q=age:<=**GET /es_db/_doc/_search?q=age:<=28SQL: select * from student where age <= 28结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"name" : "rod","sex" : 0,"age" : 26,"address" : "广州白云山公园","remark" : "php developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "4","_score" : 1.0,"_source" : {"name" : "admin","sex" : 0,"age" : 22,"address" : "长沙橘子洲头","remark" : "python assistant"}},{"_index" : "es_db","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"name" : "小明","sex" : 0,"age" : 19,"address" : "长沙岳麓山","remark" : "java architect assistant"}}]}
}查询年龄大于28岁的
GET /索引名称/类型/_search?q=age:>**GET /es_db/_doc/_search?q=age:>28SQL: select * from student where age > 28结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]}
}分页查询
GET /索引名称/类型/_search?q=age[25 TO 26]&from=0&size=1GET /es_db/_doc/_search?q=age[25 TO 26]&from=0&size=1SQL: select * from student where age between 25 and 26 limit 0, 1结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 3,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}}]}
}对查询结果只输出某些字段_source=字段,字段
GET /索引名称/类型/_search?_source=字段,字段GET /es_db/_doc/_search?_source=name,ageSQL: select name,age from student结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "张三","age" : 25}},{"_index" : "es_db","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"name" : "rod","age" : 26}},{"_index" : "es_db","_type" : "_doc","_id" : "4","_score" : 1.0,"_source" : {"name" : "admin","age" : 22}},{"_index" : "es_db","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"name" : "小明","age" : 19}}]}
}对查询结果排序 sort=字段:desc/asc
GET /索引名称/类型/_search?sort=字段 descGET /es_db/_doc/_search?sort=age:descSQL: select * from student order by age desc结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "3","_score" : null,"_source" : {"name" : "rod","sex" : 0,"age" : 26,"address" : "广州白云山公园","remark" : "php developer"},"sort" : [26]},{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : null,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"},"sort" : [25]},{"_index" : "es_db","_type" : "_doc","_id" : "4","_score" : null,"_source" : {"name" : "admin","sex" : 0,"age" : 22,"address" : "长沙橘子洲头","remark" : "python assistant"},"sort" : [22]},{"_index" : "es_db","_type" : "_doc","_id" : "5","_score" : null,"_source" : {"name" : "小明","sex" : 0,"age" : 19,"address" : "长沙岳麓山","remark" : "java architect assistant"},"sort" : [19]}]}
}本次用到的所有语句
GET _search
{"query": {"match_all": {}}
}# 分词 分词器:standard
POST _analyze
{"analyzer": "standard","text":"我爱你中国"
}# 分词 分词器:ik_smart,会做最粗粒度的拆分
POST _analyze
{"analyzer": "ik_smart","text":"中华人民共和国"
}# 分词 分词器:ik_max_word,会将文本做最细粒度的拆分
POST _analyze
{"analyzer": "ik_max_word","text":"中华人民共和国"
}# 修改默认分词器
PUT /school_index
{"settings":{"index":{"analysis.analyzer.default.type":"ik_max_word"}}
}# 创建索引
PUT /es_db# 添加文档
PUT /es_db/_doc/1
{"name": "张三","sex": 1,"age": 25,"address": "广州天河公园","remark": "java developer"
}# 添加文档
PUT /es_db/_doc/2
{"name": "李四","sex": 1,"age": 28,"address": "上海金融大厦","remark": "java assistant"
}# 添加文档
PUT /es_db/_doc/3
{"name": "rod","sex": 0,"age": 26,"address": "广州白云山公园","remark": "php developer"
}# 添加文档
PUT /es_db/_doc/4
{"name": "admin","sex": 0,"age": 22,"address": "长沙橘子洲头","remark": "python assistant"
}# 添加文档
PUT /es_db/_doc/5
{"name": "小明","sex": 0,"age": 19,"address": "长沙岳麓山","remark": "java architect assistant"
}# 查看索引
GET /es_db# 修改文档
PUT /es_db/_doc/2
{"name": "李四-修改","sex": 1,"age": 99,"address": "上海金融大厦-修改","remark": "java assistant-修改"
}# 查询文档
GET /es_db/_doc/2# 删除文档
DELETE /es_db/_doc/2# 查询所有文档
GET /es_db/_doc/_search# 查询年龄=28岁的
GET /es_db/_doc/_search?q=age:28GET /es_db/_doc/_search?q=age:25# 查询年龄在25和28之间的
GET /es_db/_doc/_search?q=age[25 TO 28]# 根据多个ID批量查询
GET /es_db/_doc/_mget
{"ids":["1","3"]
}# 年龄<=28
GET /es_db/_doc/_search?q=age:<=28# 年龄>28
GET /es_db/_doc/_search?q=age:>28# 分页查询
GET /es_db/_doc/_search?q=age[25 TO 26]&from=0&size=1# 只输出指定字段
GET /es_db/_doc/_search?_source=name,age# 排序
GET /es_db/_doc/_search?sort=age:desc相关文章:
2.Elasticsearch入门
2.Elasticsearch入门[toc]1.Elasticsearch简介Elasticsearch是用Java开发并且是当前最流行的开源的企业级搜索引擎。 能够达到实时搜索,稳定,可靠,快速,安装使用方便。客户端支持Java、.NET(C#)、PHP、Pyth…...
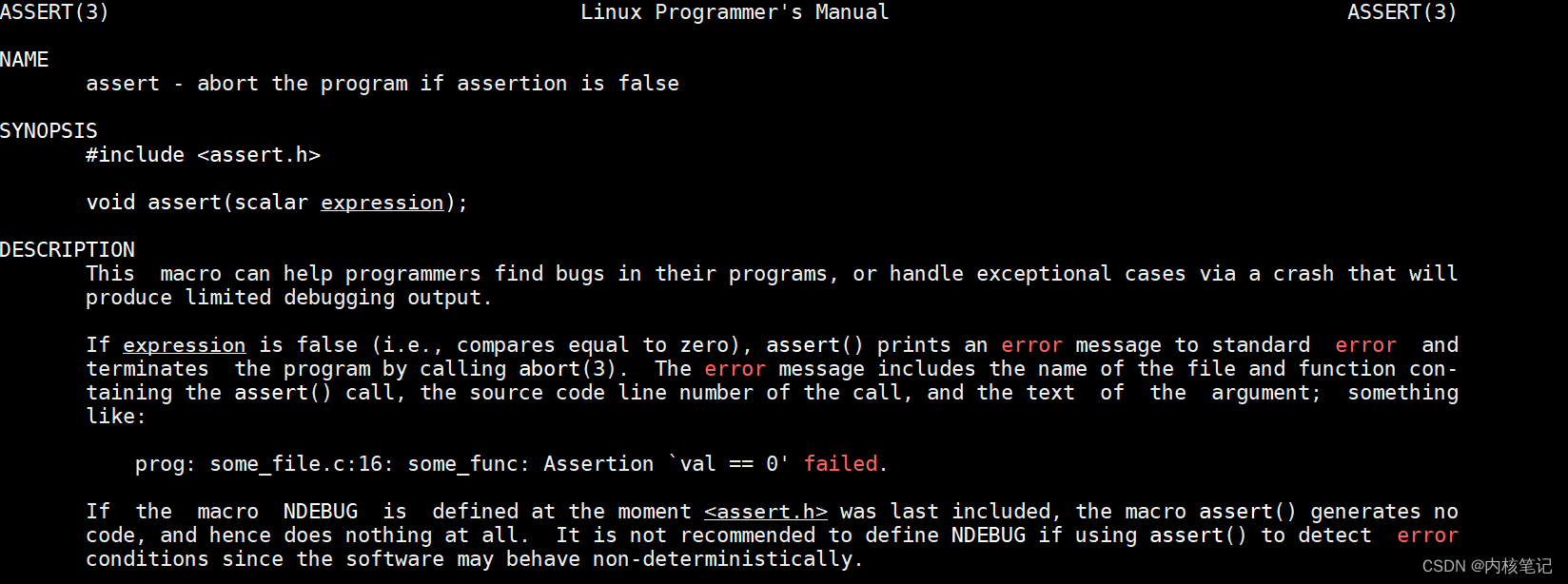
RK3399平台开发系列讲解(应用开发篇)断言的使用
🚀返回专栏总目录 文章目录 一、什么是断言二、静态断言三、运行时断言沉淀、分享、成长,让自己和他人都能有所收获!😄 📢断言为我们提供了一种可以静态或动态地检查程序在目标平台上整体状态的能力,与它相关的接口由头文件 assert.h 提供。 一、什么是断言 在编程中…...
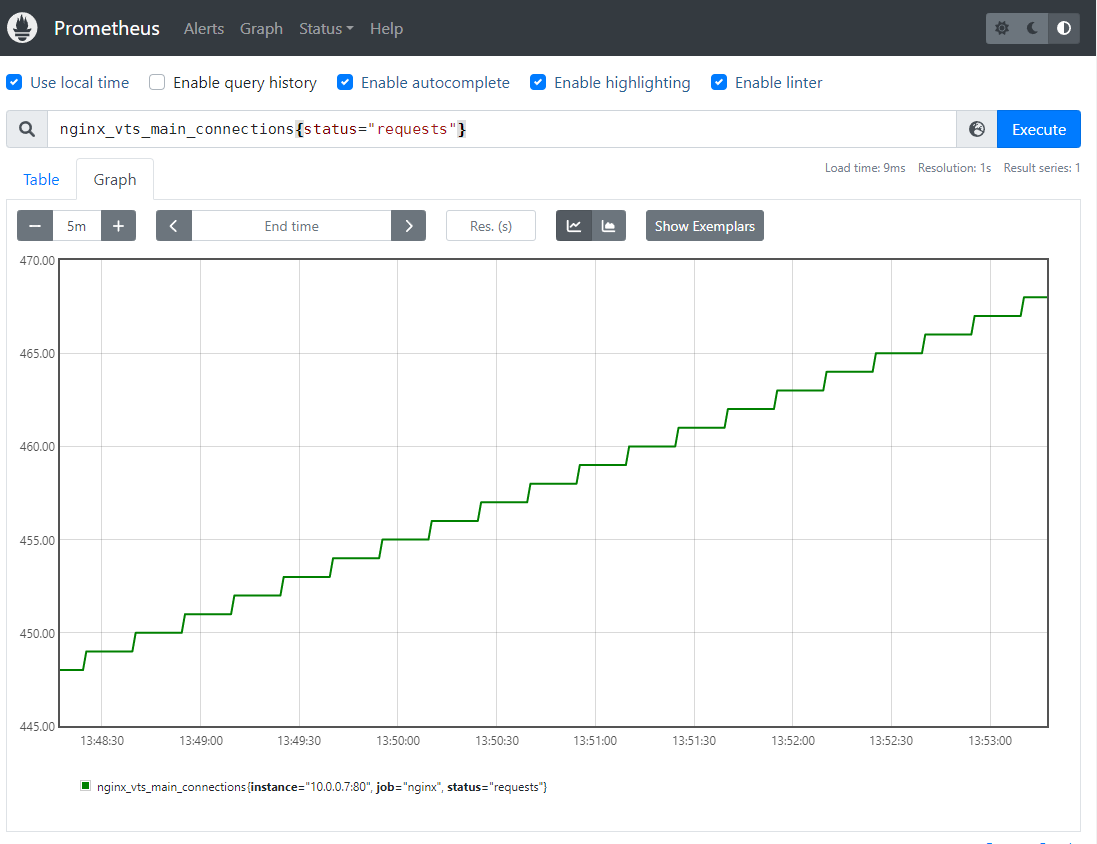
云原生系列之使用prometheus监控nginx
前言 大家好,又见面了,我是沐风晓月,本文主要讲解云原生系列之使用prometheus监控nginx 文章收录到 csdn 我是沐风晓月的博客【prometheus监控系列】专栏,此专栏是沐风晓月对云原生prometheus的的总结,希望能够加深自…...
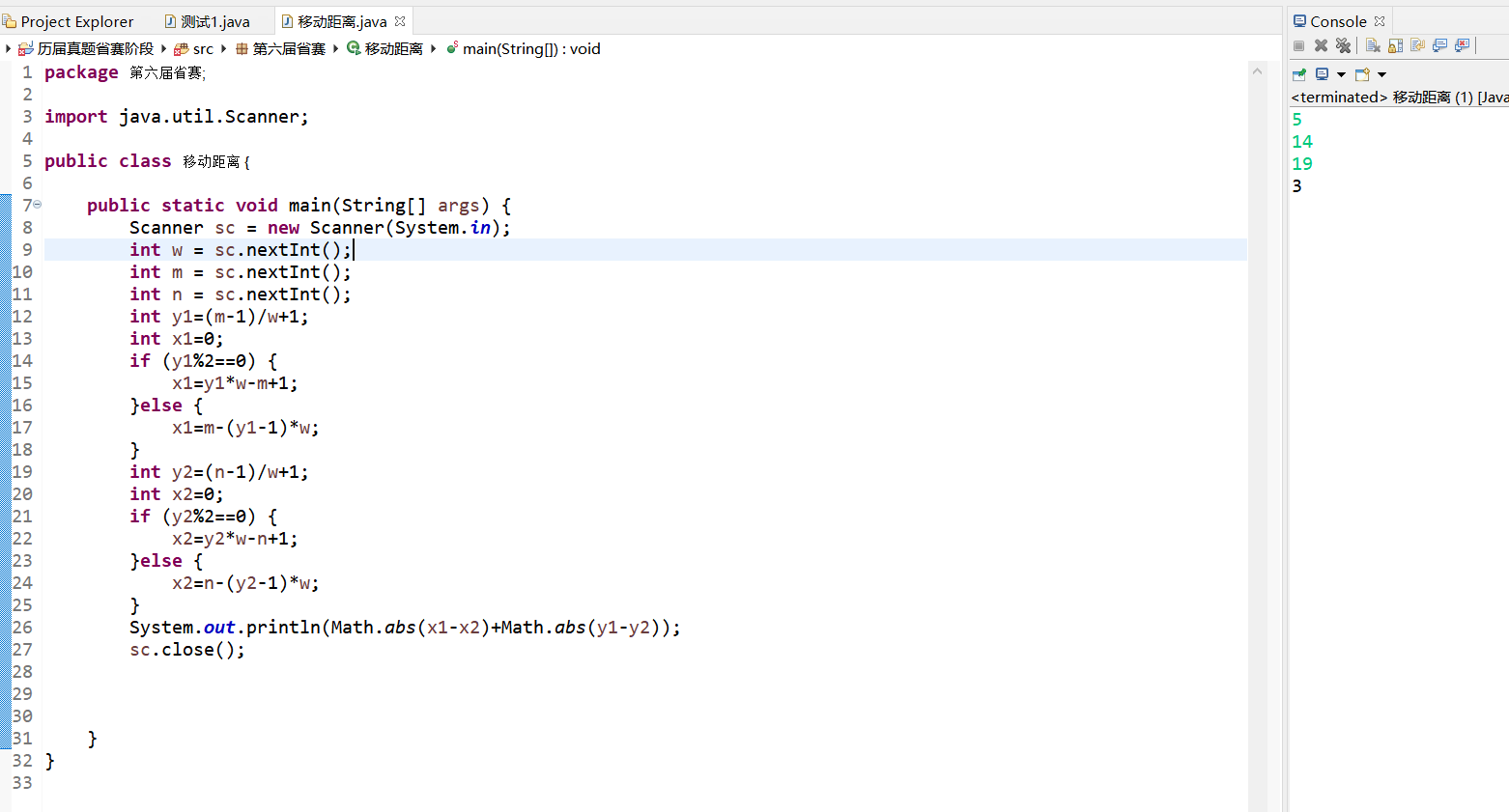
第六届省赛——8移动距离(总结规律)
题目:X星球居民小区的楼房全是一样的,并且按矩阵样式排列。其楼房的编号为1,2,3...当排满一行时,从下一行相邻的楼往反方向排号。比如:当小区排号宽度为6时,开始情形如下:1 2 3 4 5 612 11 10 9 8 713 14 1…...
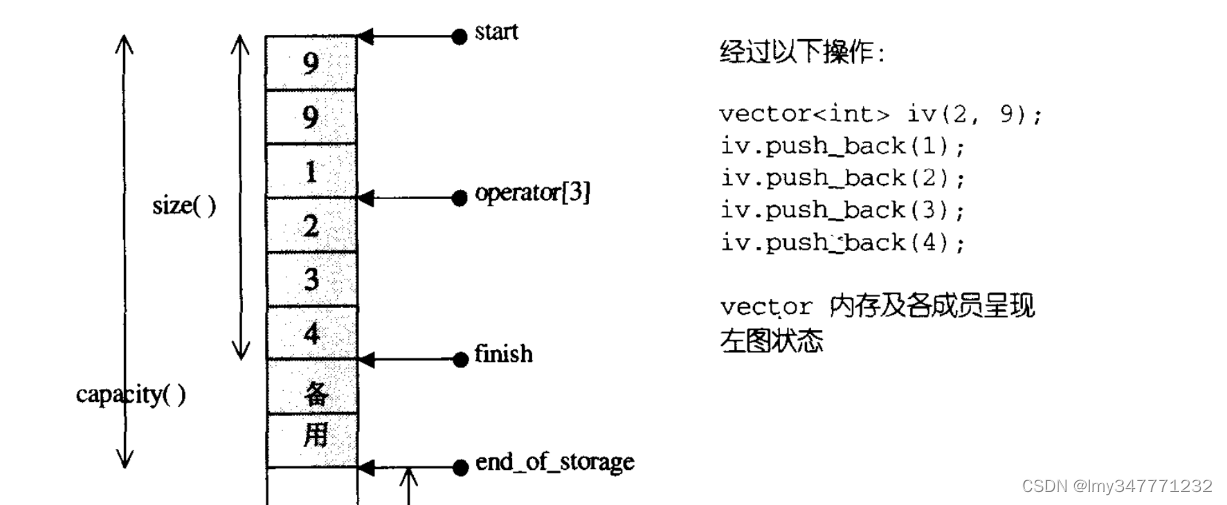
C++vector 简单实现
一。概述 vector是我们经常用的一个容器,其本质是一个线性数组。通过对动态内存的管理,增删改查数据,达到方便使用的目的。 作为一个线性表,控制元素个数,容量,开始位置的指针分别是: start …...
通用缓存存储设计实践
目录介绍 01.整体概述说明 1.1 项目背景介绍1.2 遇到问题记录1.3 基础概念介绍1.4 设计目标1.5 产生收益分析 02.市面存储方案 2.1 缓存存储有哪些2.2 缓存策略有哪些2.3 常见存储方案2.4 市面存储方案说明2.5 存储方案的不足 03.存储方案原理 3.1 Sp存储原理分析3.2 MMKV存储…...

sheng的学习笔记Eureka Ribbon
Eureka-注册中心Eureka简介官方网址:https://spring.io/projects/spring-cloud-netflixEureka介绍Spring Cloud 封装了 Netflix 公司开发的 Eureka 模块来实现服务注册和发现(请对比Zookeeper)。Zooleeper nacos.Eureka 采用了 C-S 的设计架构。Eureka Server 作为服…...
零代码工具我推荐Oracle APEX
云原生时代零代码工具我推荐Oracle APEX 国内的低码开发平台我也看了很多,感觉还是不太适合我这个被WEB抛弃的老炮。自从看了Oracle APEX就不打算看其它的了。太强大了,WEB服务器都省了,直接数据库到WEB页面。功能很强大,震撼到我…...
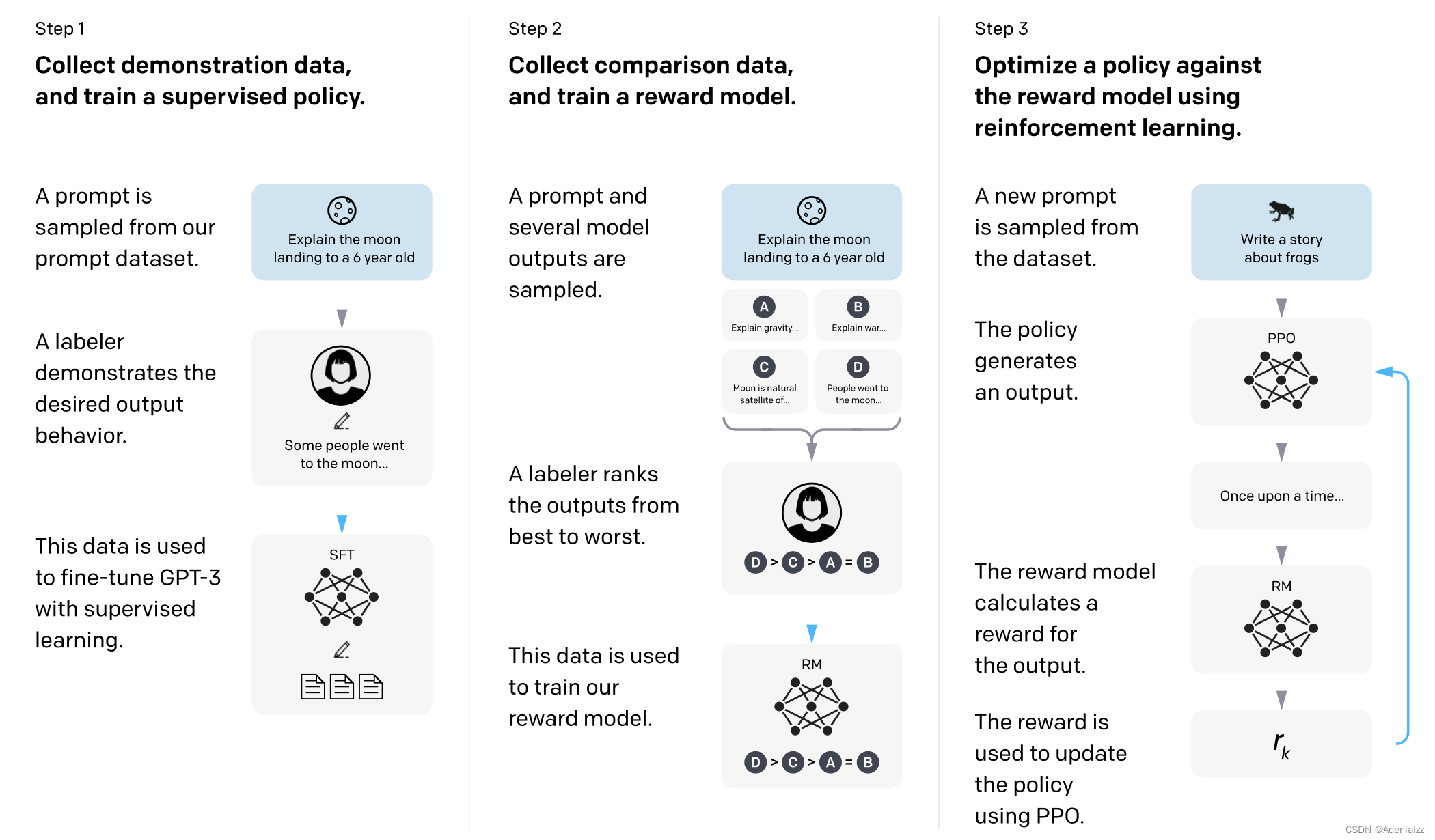
InstructGPT方法简读
InstructGPT方法简读 引言 仅仅通过增大模型规模和数据规模来训练更大的模型并不能使得大模型更好地理解用户意图。由于数据的噪声极大,并且现在的大多数大型语言模型均为基于深度学习的“黑箱模型”,几乎不具有可解释性和可控性,因此&…...

SpringCloud-5_模块集群化
避免一台Server挂掉,影响整个服务,搭建server集群创建e-commerce-eureka-server-9002微服务模块【作为注册中心】创建步骤参考e-commerce-eureka-server-9001修改pom.xml,加入依赖同9001创建resources/application.yml9002的ymlserver: # 修改端口号por…...
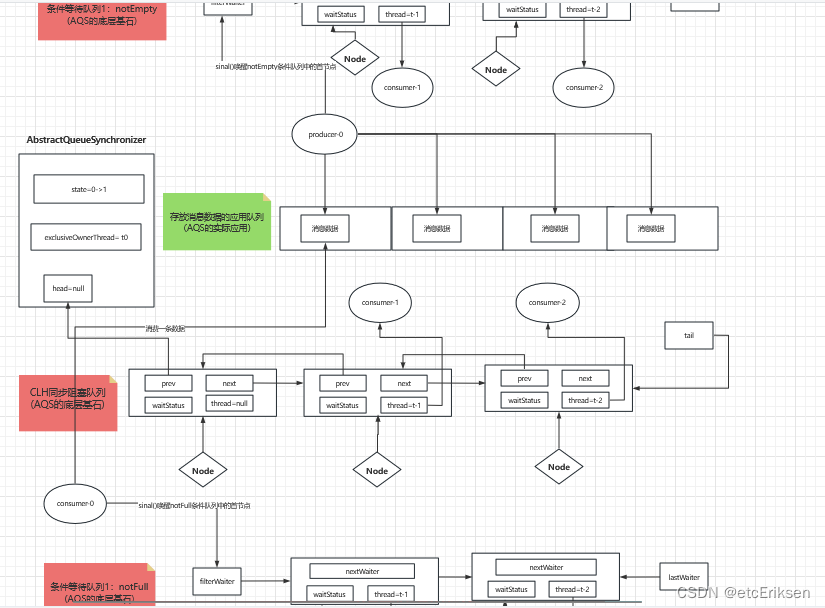
AQS底层源码深度剖析-BlockingQueue
目录 AQS底层源码深度剖析-BlockingQueue BlockingQueue定义 队列类型 队列数据结构 ArrayBlockingQueue LinkedBlockingQueue DelayQueue BlockingQueue API 添加元素 检索(取出)元素 BlockingQueue应用队列总览图 AQS底层源码深度剖析-BlockingQueue【重点中的重…...

Kotlin协程:Flow的异常处理
示例代码如下:launch(Dispatchers.Main) {// 第一部分flow {emit(1)throw NullPointerException("e")}.catch {Log.d("liduo", "onCreate1: $it")}.collect {Log.d("liudo", "onCreate2: $it")}// 第二部分flow …...
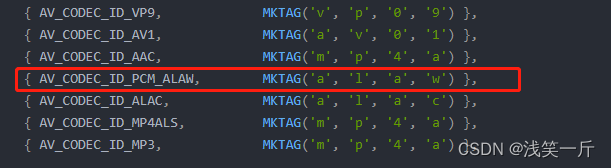
qt下ffmpeg录制mp4经验分享,支持音视频(h264、h265,AAC,G711 aLaw, G711muLaw)
前言 MP4,是最常见的国际通用格式,在常见的播放软件中都可以使用和播放,磁盘空间占地小,画质一般清晰,它本身是支持h264、AAC的编码格式,对于其他编码的话,需要进行额外处理。本文提供了ffmpeg录…...

C#读取Excel解析入门-1仅围绕三个主要的为阵地,进行重点解析,就是最理性的应对上法所在
业务中也是同样的功能点实现。只是多扩展了很多代码,构成了项目的其他部分,枝干所在。但是有用的枝干,仅仅不超过三个主要的!所以您仅仅围绕三个主要的为阵地,进行重点解析,就是最理性的应对上法所在了 str…...
)
一起Talk Android吧(第五百一十八回:在Android中使用MQTT通信五)
文章目录 知识回顾问题描述解决过程经验分享各位看官们大家好,这一回中咱们说的例子是" 在Android中使用MQTT通信五",本章回内容与前后章节内容无关联。闲话休提,言归正转,让我们一起Talk Android吧! 知识回顾 我们在前面章回中介绍了如何使用MQTT通信,包含它…...
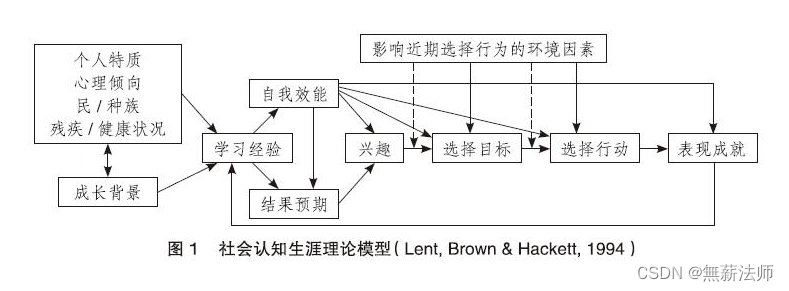
100种思维模型之混沌与秩序思维模型-027
人类崇尚秩序与连续性,我们习惯于我们的日常世界,它以线性方式运作,没有不连续或突跳。 为此,我们学会了期望各种过程以连续方式运行,我们的内心为了让我们更有安全感,把很多事物的结果归于秩序,…...
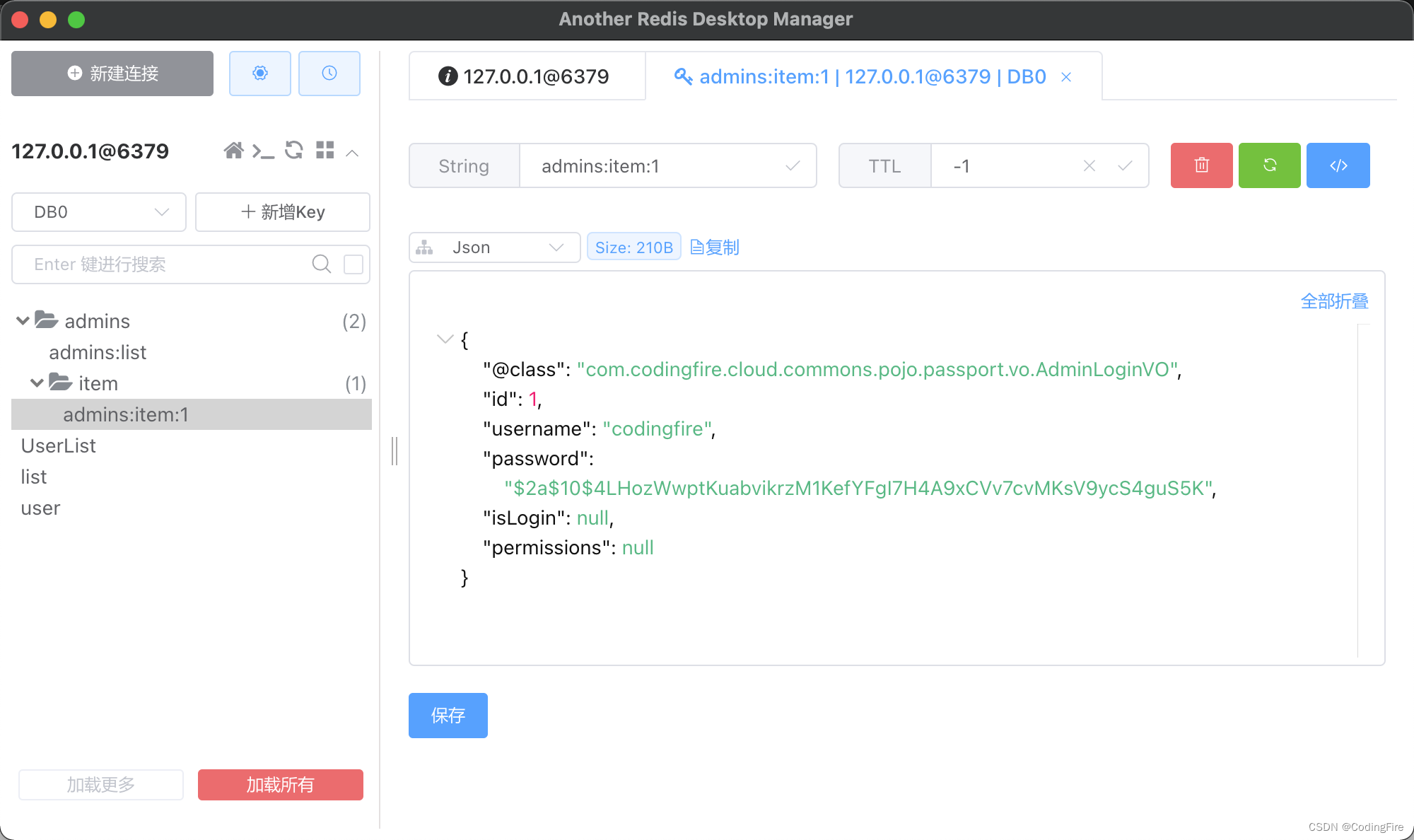
Java开发 - Redis初体验
前言 es我们已经在前文中有所了解,和es有相似功能的是Redis,他们都不是纯粹的数据库。两者使用场景也是存在一定的差异的,本文目的并不重点说明他们之间的差异,但会简要说明,重点还是在对Redis的了解和学习上。学完本…...

Python - 使用 pymysql 操作 MySQL 详解
目录创建连接 pymsql.connect() 方法的可传参数连接对象 conn pymsql.connect() 方法游标对象 cursor() 方法使用示例创建数据库表插入数据操作数据查询操作数据更新操作数据删除操作SQL中使用变量封装使用简单使用: import pymysqldb pymysql.connect(host,user…...
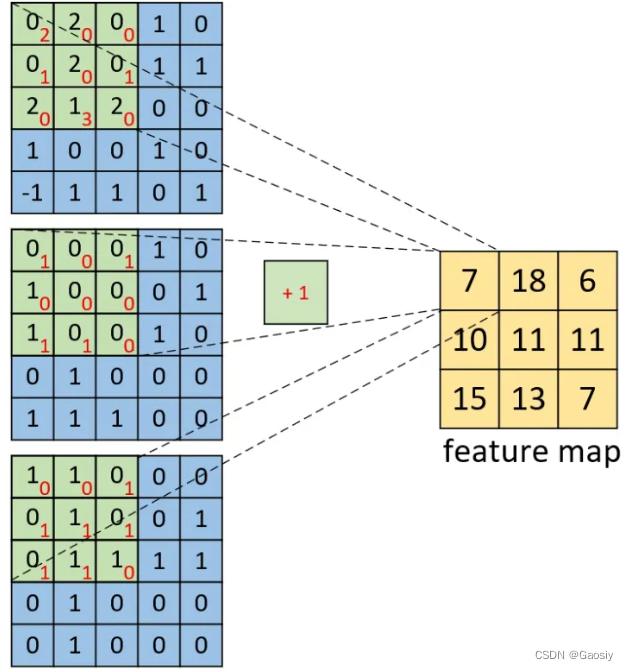
机器学习-卷积神经网络CNN中的单通道和多通道图片差异
背景 最近在使用CNN的场景中,既有单通道的图片输入需求,也有多通道的图片输入需求,因此又整理回顾了一下单通道或者多通道卷积的差别,这里记录一下探索过程。 结论 直接给出结论,单通道图片和多通道图片在经历了第一…...
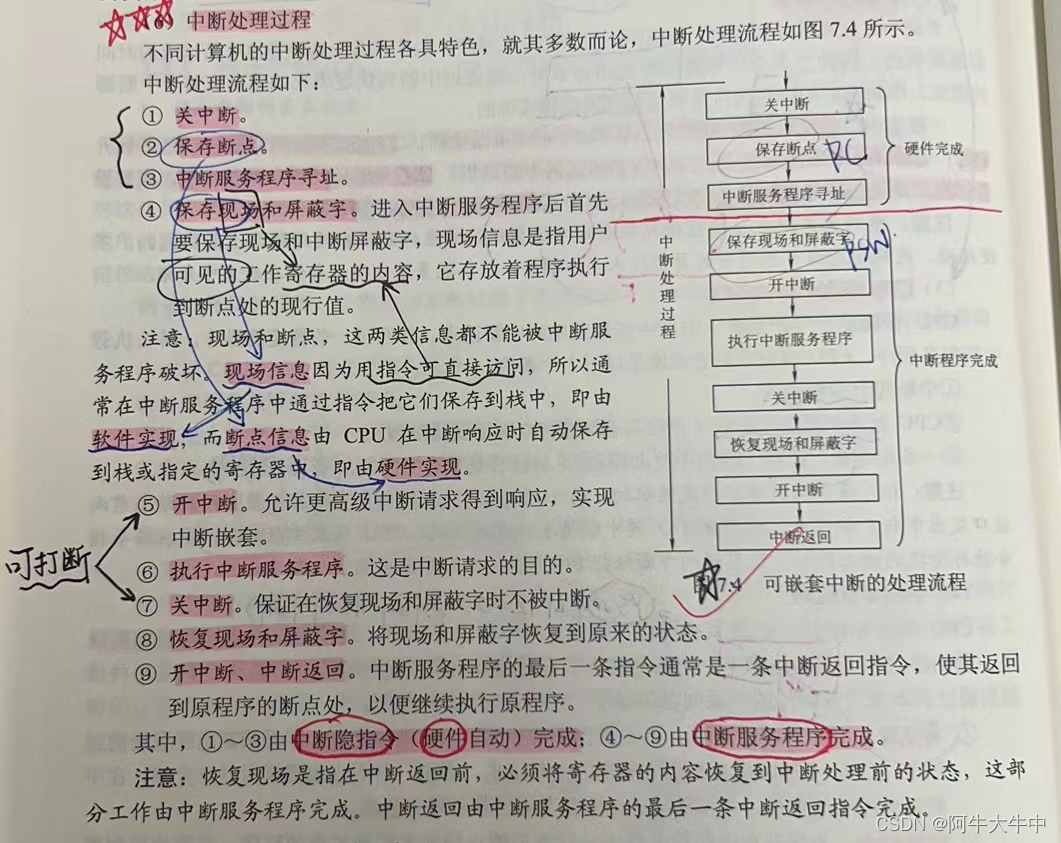
考研复试——计算机组成原理
文章目录计算机组成原理1. 计算机系统由哪两部分组成?计算机系统性能取决于什么?2. 冯诺依曼机的主要特点?3. 主存储器由什么组成,各部分有什么作用?4. 什么是存储单元、存储字、存储字长、存储体?5. 计算机…...

VisualCppRedist AIO:一站式解决Windows应用程序运行库缺失难题
VisualCppRedist AIO:一站式解决Windows应用程序运行库缺失难题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 在Windows系统中,你是否经…...

企业采购AI升级:需求驱动的智能供应商匹配实战
工业数字化与 AI 技术深度融合的当下,传统采购招标模式的短板愈发凸显。众多 Java 架构的企业采购系统仍停留在人工化、经验化运营阶段,供应商管理效率低、匹配精准度不足、人力成本居高不下。依托JBoltAI企业级 Java AI 应用开发框架所倡导的 AIGS 人工…...
)
告别按钮!用Qt实现STM32小车的键盘与手柄控制方案(附串口通信源码)
超越按钮控制:Qt框架下STM32小车的键盘与手柄交互方案 在嵌入式开发领域,人机交互体验往往被忽视,而实际上它直接影响着用户的操作效率和舒适度。对于STM32遥控小车这类需要实时操控的项目,传统的按钮点击方式存在明显局限——操作…...
·面经深度解析)
前端八股文面经大全:上海威派格前端实习(2026-05-07)·面经深度解析
前言 大家好,我是木斯佳。 相信很多人都感受到了,在AI浪潮的席卷之下,前端领域的门槛在变高,纯粹的“增删改查”岗位正在肉眼可见地减少。曾经热闹非凡的面经分享,如今也沉寂了许多。但我们都知道,市场的…...

微信自动化终极指南:5个强大功能助你高效管理微信数据
微信自动化终极指南:5个强大功能助你高效管理微信数据 【免费下载链接】wechat-toolbox WeChat toolbox(微信工具箱) 项目地址: https://gitcode.com/gh_mirrors/we/wechat-toolbox 还在为繁琐的微信数据管理而烦恼吗?微信…...

AMD Ryzen硬件调试终极指南:深入SMU Debug Tool的完整实战应用
AMD Ryzen硬件调试终极指南:深入SMU Debug Tool的完整实战应用 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...
开源语言模型项目实践:从Transformer核心到训练调优全解析
1. 项目概述:一个开源语言模型的实践与探索最近在GitHub上看到一个名为“angeluriot/Language_model”的项目,点进去一看,是个挺有意思的语言模型实现。虽然项目标题很简单,但内容却涵盖了从数据处理、模型构建到训练推理的完整链…...

OpenClaw 接入微信 / 企业微信完整教程
本文介绍如何通过 OpenClaw 框架,将个人微信和企业微信接入 AI Agent,实现「AI 自动回复」的功能。适用于树莓派、Mac/Windows 电脑、NAS 或云服务器等各类设备。 一、环境准备 1.1 安装 OpenClaw OpenClaw 是核心运行环境,负责加载插件、管…...
详解与最佳实践)
HoRain云--PHP日期格式化函数date()详解与最佳实践
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...
PixelAnnotationTool终极指南:如何用智能分水岭算法实现高效像素级图像标注
PixelAnnotationTool终极指南:如何用智能分水岭算法实现高效像素级图像标注 【免费下载链接】PixelAnnotationTool Annotate quickly images. 项目地址: https://gitcode.com/gh_mirrors/pi/PixelAnnotationTool 你是否曾经为图像标注工作感到头疼ÿ…...