hadoop3.0高可用分布式集群安装
hadoop高可用,依赖于zookeeper。
用于生产环境, 企业部署必须的模式.
1. 部署环境规划
1.1. 虚拟机及hadoop角色划分
| 主机名称 | namenode | datanode | resourcemanager | nodemanager | zkfc | journalnode | zookeeper |
| master | | | | | | | |
| slave1 | | | | | | | |
| slave2 | | | | | | |
1.2. 软件版本
| java | jdk-1.8 |
| Hadoop | 3.3.0 |
| zookeeper | 3.7.0 |
1.3. 数据目录规划
| 名称 | 目录 |
| namenode目录 | /data/hadoop/dfs/name |
| datanode目录 | /data/hadoop/dfs/data |
| hadoop临时目录 | /data/hadoop/tmp |
| zookeeper数据目录 | /data/zookeeper/data |
2. 免密登录
略
3. 安装jdk
略
4. zookeeper安装
4.1. 解压
解压到目录/usr/local/ 下
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz -C /usr/local/zookeeper
4.2. 环境配置
cat>>/etc/profile <<EOF
export ZOOKEEPER_HOME=/usr/local/zookeeper/apache-zookeeper-3.7.0-bin
export PATH=\$ZOOKEEPER_HOME/bin:\$PATH
EOF
source /etc/profile
#创建数据/日志目录
mkdir -pv /data/zookeeper/{data,log} 4.3. 修改配置文件
cd /usr/local/zookeeper/apache-zookeeper-3.7.0-bin/conf/
cp zoo_sample.cfg zoo.cfg修改zoo.cfg配置文件
dataDir=/data/zookeeper/data/
dataLogDir=/data/zookeeper/log/
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888分发到slave1,slave2节点
scp zoo.cfg slave1:/usr/local/zookeeper/apache-zookeeper-3.7.0-bin/conf/
scp zoo.cfg slave2:/usr/local/zookeeper/apache-zookeeper-3.7.0-bin/conf/4.4. 创建myid
根据服务器对应的数字,配置相应的myid,master配置1,slave1配置2,slave2配置3
#各节点配置,根据server.1就是1
echo 1 > /data/zookeeper/data/myid4.5. 启动zookeeper
各个节点启动
zkServer.sh start
zkServer.sh status5. hadoop安装
5.1. 解压
tar -zxvf hadoop-3.3.0.tar.gz -C /usr/local/5.2. 环境配置
环境配置(所有节点都执行),root用户执行
chown -R hadoop:hadoop /usr/local/hadoop-3.3.0
cat>>/etc/profile <<EOF
export HADOOP_HOME=/usr/local/hadoop-3.3.0
export PATH=\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin:\$PATH
EOF
source /etc/profile5.3. 修改配置文件
5.3.1. hadoop-env.sh
cd $HADOOP_HOME/etc/hadoop
vi hadoop-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_3115.3.2. core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://mycluster/</value><description>自定义的集群名称</description></property><property><name>hadoop.tmp.dir</name><value>/data/hadoop/tmp</value><description>namenode上本地的hadoop临时文件夹</description></property><property><name>ha.zookeeper.quorum</name><value>master:2181,slave1:2181,slave2:2181</value><description>指定zookeeper地址</description></property><property><name>ha.zookeeper.session-timeout.ms</name><value>1000</value><description>hadoop链接zookeeper的超时时长设置ms</description></property>
</configuration>5.3.3. hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>2</value><description>Hadoop的备份系数是指每个block在hadoop集群中有几份,系数越高,冗余性越好,占用存储也越多</description></property><property><name>dfs.namenode.name.dir</name><value>/data/hadoop/dfs/name</value><description>namenode上存储hdfs名字空间元数据 </description></property><property><name>dfs.datanode.data.dir</name><value>/data/hadoop/dfs/data</value><description>datanode上数据块的物理存储位置</description></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property><!--指定hdfs的nameservice为myha01,需要和core-site.xml中的保持一致dfs.ha.namenodes.[nameservice id]为在nameservice中的每一个NameNode设置唯一标示符。配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。例如,如果使用"myha01"作为nameservice ID,并且使用"nn1"和"nn2"作为NameNodes标示符--><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- myha01下面有两个NameNode,分别是nn1,nn2 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><!-- nn1的RPC通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>master:9000</value></property><!-- nn1的http通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>master:50070</value></property><!-- nn2的RPC通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>slave1:9000</value></property><!-- nn2的http通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>slave1:50070</value></property><!-- 指定NameNode的edits元数据的共享存储位置。也就是JournalNode列表该url的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalIdjournalId推荐使用nameservice,默认端口号是:8485 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value></property><!-- 指定JournalNode在本地磁盘存放数据的位置 --><property><name>dfs.journalnode.edits.dir</name><value>/data/hadoop/data/journaldata</value></property><!-- 开启NameNode失败自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 配置失败自动切换实现方式 --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 --><property><name>dfs.ha.fencing.methods</name><value>sshfenceshell(/bin/true)</value></property><!-- 使用sshfence隔离机制时需要ssh免登陆 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hadoop/.ssh/id_rsa</value></property><!-- 配置sshfence隔离机制超时时间 --><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property><property><name>ha.failover-controller.cli-check.rpc-timeout.ms</name><value>60000</value></property>
</configuration>注意 mycluster 所有地方都要一样
5.3.4. mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value><description>The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn.</description><final>true</final></property><property><name>mapreduce.jobtracker.http.address</name><value>master:50030</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property><property><name>mapred.job.tracker</name><value>http://master:9001</value></property>
</configuration>5.3.5. yarn-site.xml
<configuration><!-- 开启RM高可用 --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!-- 指定RM的cluster id --><property><name>yarn.resourcemanager.cluster-id</name><value>yrc</value></property><!-- 指定RM的名字 --><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><!-- 分别指定RM的地址 --><property><name>yarn.resourcemanager.hostname.rm1</name><value>slave1</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>slave2</value></property><!-- 指定zk集群地址 --><property><name>yarn.resourcemanager.zk-address</name><value>master:2181,slave1:2181,slave2:2181</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>86400</value></property><!-- 启用自动恢复 --><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><!-- 制定resourcemanager的状态信息存储在zookeeper集群上 --><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><property><name>yarn.application.classpath</name> <value>/usr/local/hadoop-3.3.0/etc/hadoop:/usr/local/hadoop-3.3.0/share/hadoop/common/lib/*:/usr/local/hadoop-3.3.0/share/hadoop/common/*:/usr/local/hadoop-3.3.0/share/hadoop/hdfs:/usr/local/hadoop-3.3.0/share/hadoop/hdfs/lib/*:/usr/local/hadoop-3.3.0/share/hadoop/hdfs/*:/usr/local/hadoop-3.3.0/share/hadoop/mapreduce/*:/usr/local/hadoop-3.3.0/share/hadoop/yarn:/usr/local/hadoop-3.3.0/share/hadoop/yarn/lib/*:/usr/local/hadoop-3.3.0/share/hadoop/yarn/*</value></property>
</configuration>5.3.6. workers
vim workers
master
slave1
slave25.4. 分发到其他服务器
scp -r /usr/local/hadoop-3.3.0/ slave1:/usr/local/
scp -r /usr/local/hadoop-3.3.0/ slave2:/usr/local/6. 启动集群
以下顺序不能错
6.1. 启动journalnode(所有节点)
hadoop-daemon.sh start journalnode6.2. 格式化namenode(master)
hadoop namenode -format6.3. 同步元数据
scp -r /data/hadoop/dfs/name/current/ root@slave1:/data/hadoop/dfs/name/6.4. 格式化zkfc(master)
hdfs zkfc -formatZK6.5. 启动HDFS(master)
start-yarn.sh6.6. 查看各主节点状态hdfs/yarn
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm27. 查看页面
hdfs:http://master:9870接付费咨询,调bug, 10元一次。+v:644789108
相关文章:

hadoop3.0高可用分布式集群安装
hadoop高可用,依赖于zookeeper。 用于生产环境, 企业部署必须的模式. 1. 部署环境规划 1.1. 虚拟机及hadoop角色划分 主机名称 namenode datanode resourcemanager nodemanager zkfc journalnode zookeeper master slave1 slave2 1.2. 软件版本 java …...

Flink SQL系列之:解析Debezium数据格式时间字段常用的函数
Flink SQL系列之:解析Debezium数据格式时间字段常用的函数 一、FROM_UNIXTIME二、DATE_FORMAT三、TO_DATE四、CAST五、TO_TIMESTAMP_LTZ六、CONVERT_TZ七、FROM_UNIXTIME八、TO_TIMESTAMP九、常见用法案例1.案例一2.案例二3.案例三4.案例四5.案例五...
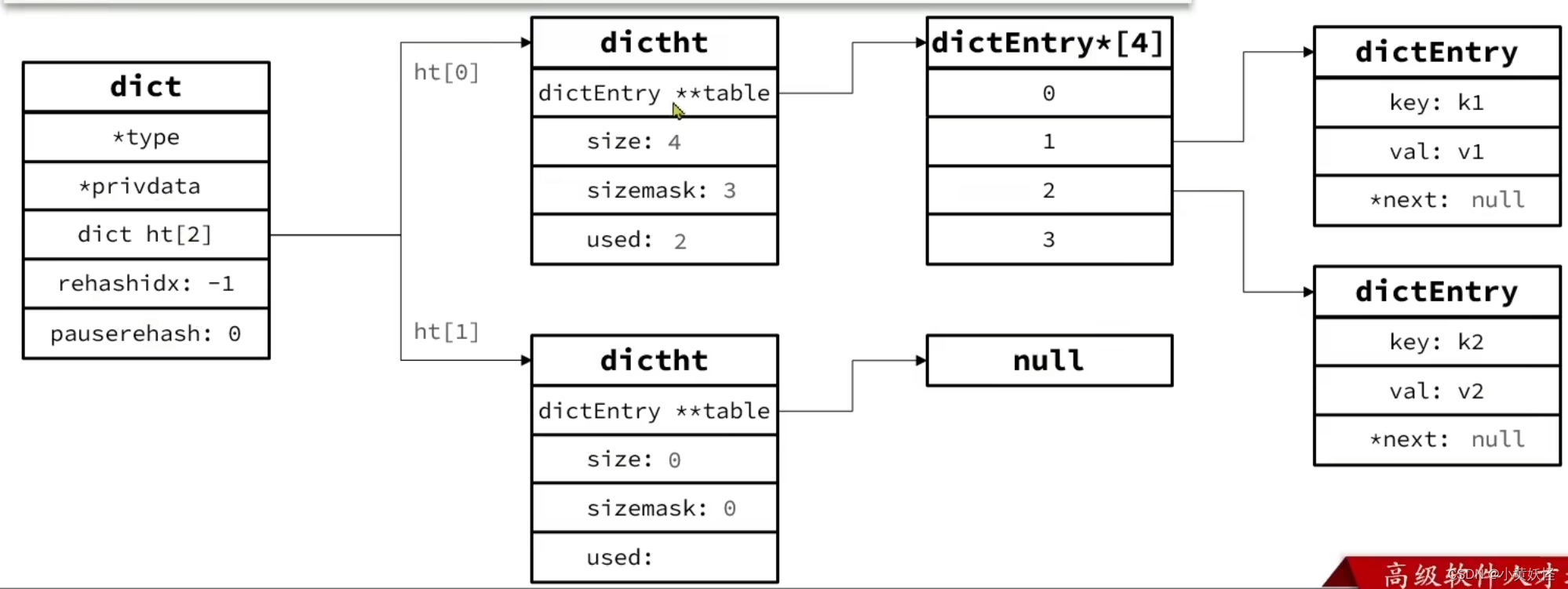
Redis底层数据结构-Dict
1. Dict基本结构 Redis的键与值的映射关系是通过Dict来实现的。 Dict是由三部分组成,分别是哈希表(DictHashTable),哈希节点(DictEntry),字典(Dict) 哈希表结构如下图所…...
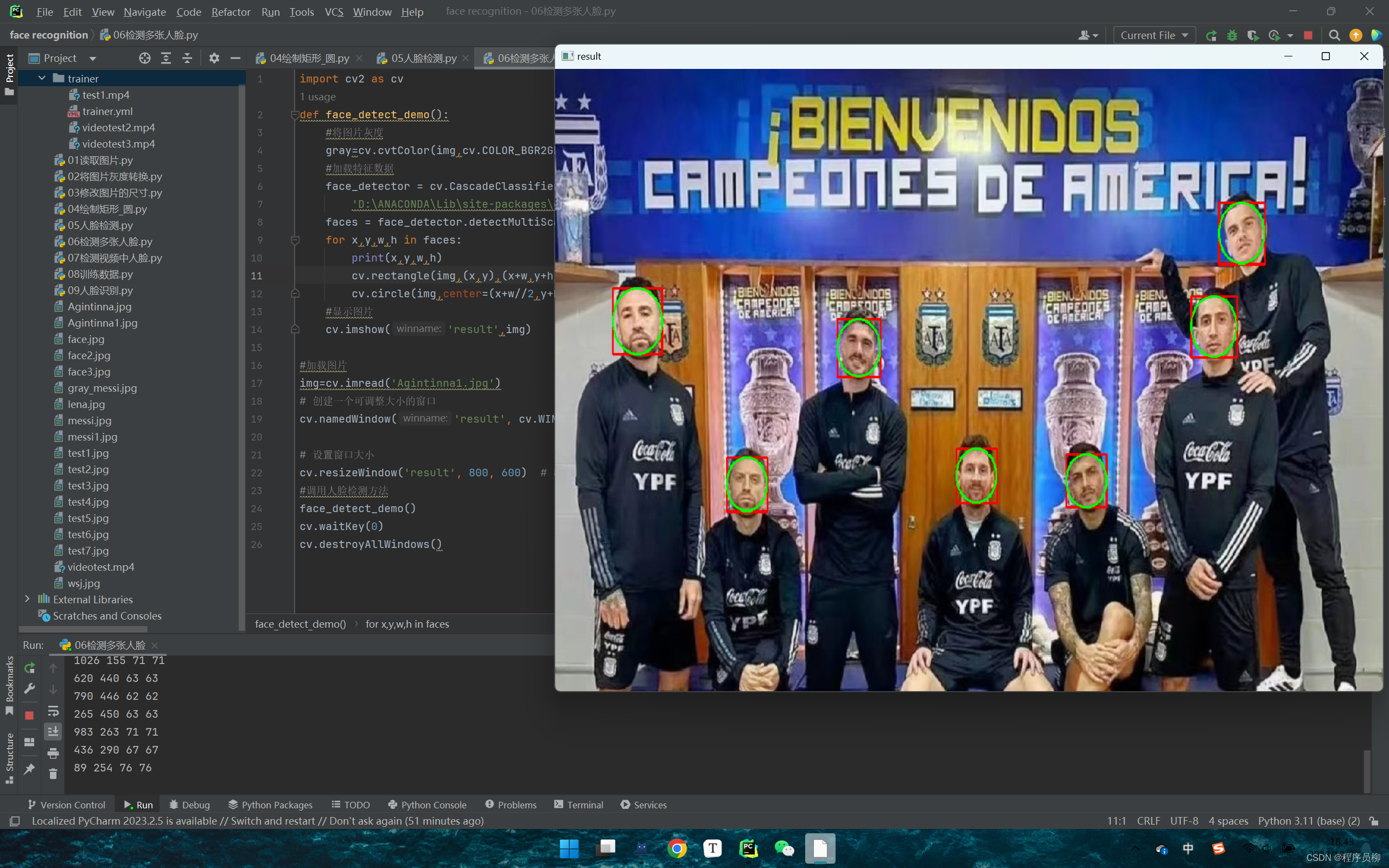
Python基于深度学习的人脸识别项目源码+演示视频,利用OpenCV进行人脸检测与识别 preview
一、原理介绍 该人脸识别实例是一个基于深度学习和计算机视觉技术的应用,主要利用OpenCV和Python作为开发工具。系统采用了一系列算法和技术,其中包括以下几个关键步骤: 图像预处理:首先,对输入图像进行预处理&am…...
CTF下加载CTFtraining题库以管理员身份导入 [HCTF 2018]WarmUp,之后以参赛者身份完成解题全过程
-------------------搭建CTFd------------------------------ 给大家介绍一个本地搭建比较好用的CTF比赛平台:CTFD。 CTFd是一个Capture The Flag框架,侧重于易用性和可定制性。它提供了运行CTF所需的一切,并且可以使用插件和主题轻松进行自…...
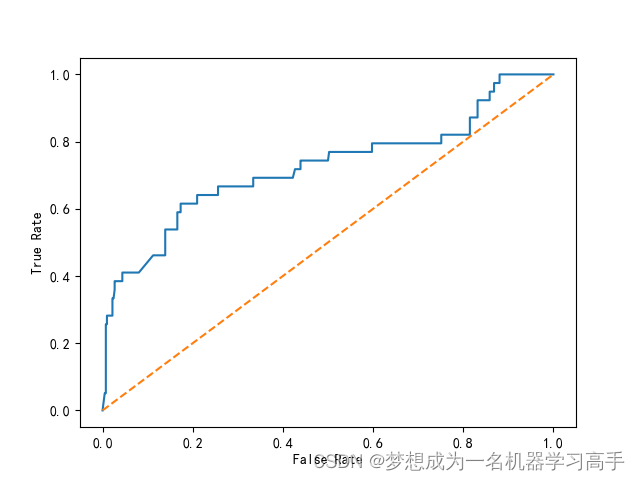
机器学习每周挑战——信用卡申请用户数据分析
数据集的截图 # 字段 说明 # Ind_ID 客户ID # Gender 性别信息 # Car_owner 是否有车 # Propert_owner 是否有房产 # Children 子女数量 # Annual_income 年收入 # Type_Income 收入类型 # Education 教育程度 # Marital_status 婚姻状况 # Housing_type 居住…...
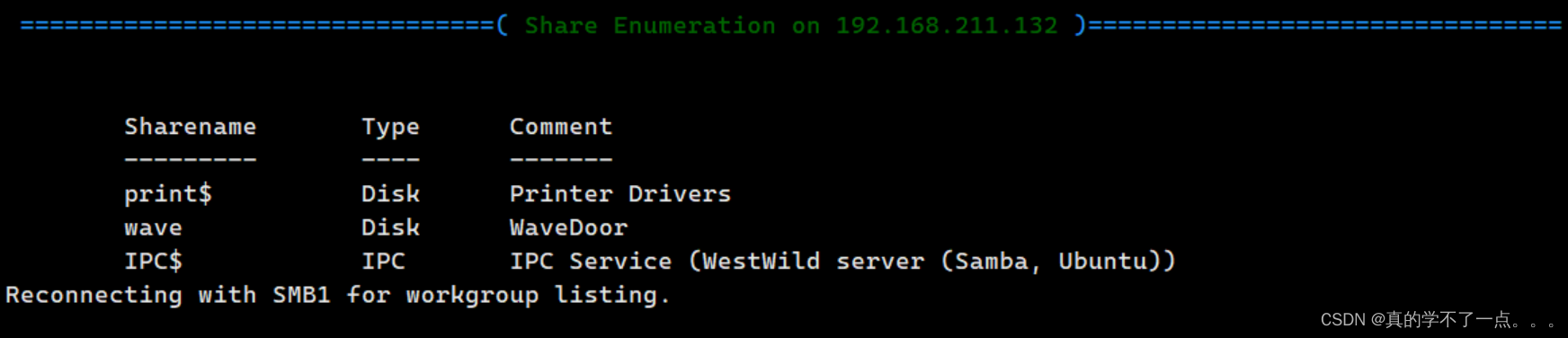
Vulnhub:WESTWILD: 1.1
目录 信息收集 arp nmap nikto whatweb WEB web信息收集 dirmap enm4ulinux sumbclient get flag1 ssh登录 提权 横向移动 get root 信息收集 arp ┌──(root㉿ru)-[~/kali/vulnhub] └─# arp-scan -l Interface: eth0, type: EN10MB, MAC: 0…...
[C#]winform使用OpenCvSharp实现透视变换功能支持自定义选位置和删除位置
【透视变换基本原理】 OpenCvSharp 是一个.NET环境下对OpenCV原生库的封装,它提供了大量的计算机视觉和图像处理的功能。要使用OpenCvSharp实现透视变换(Perspective Transformation),你首先需要理解透视变换的原理和它在图像处理…...
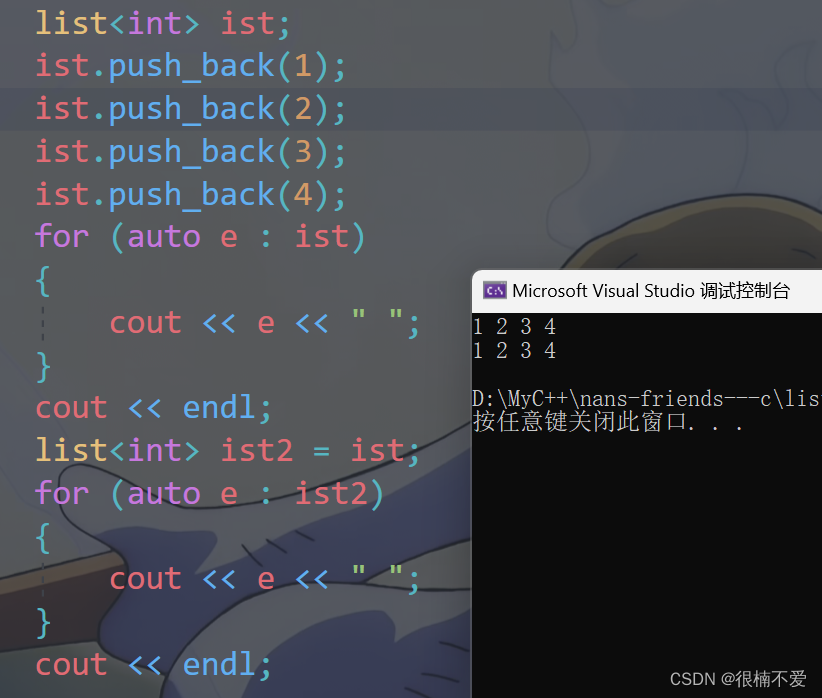
C++——list类及其模拟实现
前言:这篇文章我们继续进行C容器类的分享——list,也就是数据结构中的链表,而且是带头双向循环链表。 一.基本框架 namespace Mylist {template<class T>//定义节点struct ListNode{ListNode<T>* _next;ListNode<T>* _pre…...
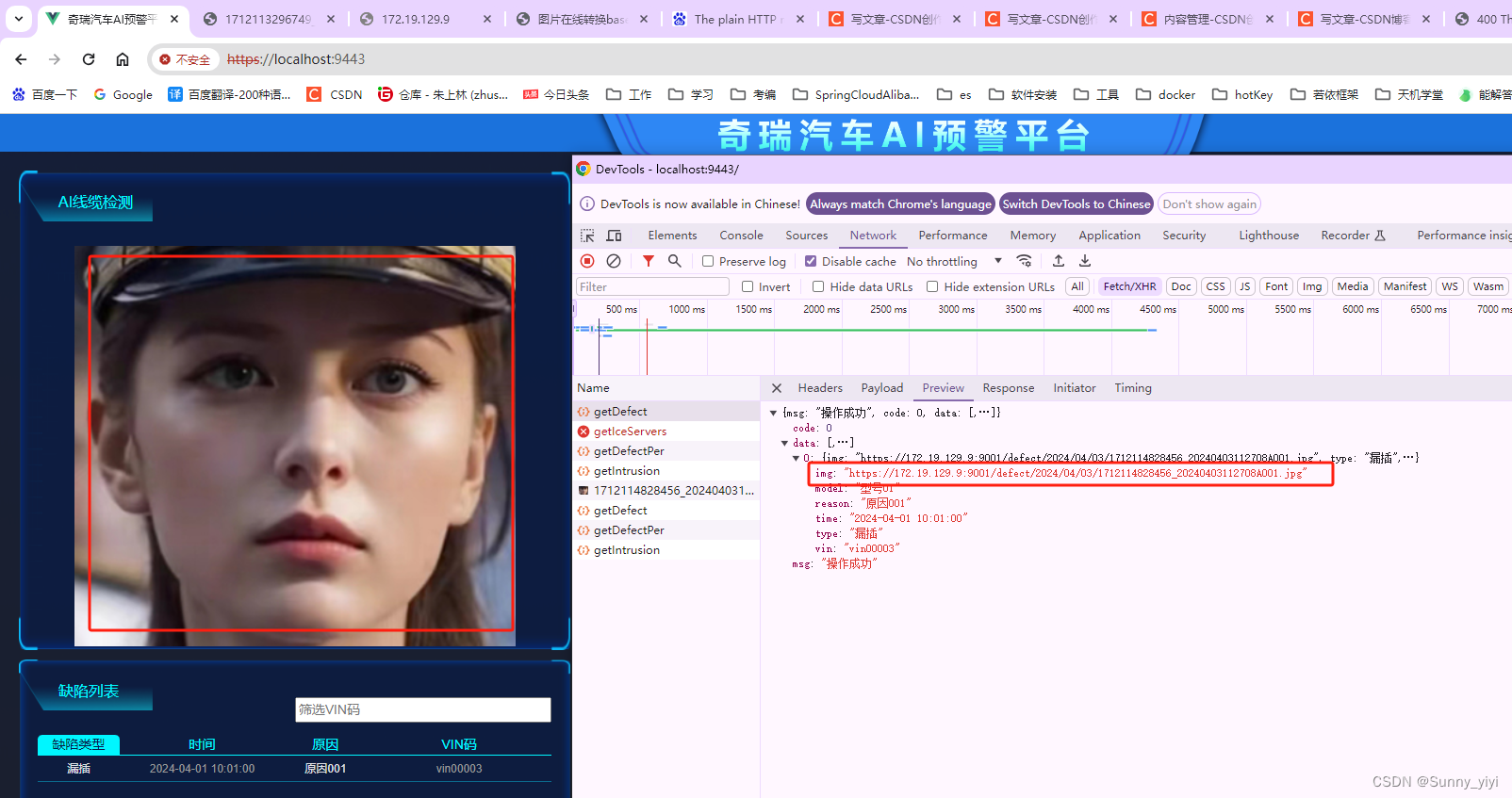
https访问http的minio 图片展示不出来
问题描述:请求到的图片地址单独访问能显示,但是在网页中展示不出来 原因:https中直接访问http是不行的,需要用nginx再转发一下 nginx配置如下(注意:9000是minio默认端口,已经占用,…...

【Python整理】 Python知识点复习
1.Python中__init__()中声明变量必须都是self吗? 在Python中的类定义里,init() 方法是一个特殊的方法,称为类的构造器。在这个方法中,通常会初始化那些需要随着对象实例化而存在的实例变量。使用 self 是一种约定俗成的方式来引用实例本身。…...

汽车电子行业知识:UWB技术及应用
文章目录 1.什么是UWB技术1.1.UWB测距原理1.2.UWB数据传输原理2.汽车UWB技术应用2.1.UWB雷达2.1.1.信道的冲击响应CIR2.2.舱外检测目标2.3.舱内检测活体2.3.1.活体检测原理2.4.脚踢尾箱开门2.4.1.脚踢检测原理1.什么是UWB技术 UWB(ultra wideband)也叫超宽带技术,是一种使用…...

Claude-3全解析:图片问答,专业写作能力显著领先GPT-4
人工智能技术的飞速发展正在深刻改变着我们的工作和生活方式。作为一名资深的技术爱好者,我最近有幸体验了备受瞩目的AI助手Claude-3。这款由Anthropic公司推出的新一代智能工具展现出了非凡的实力,尤其在图像识别和专业写作领域的表现更是让人眼前一亮&…...

Mac 如何彻底卸载Python 环境?
第一步:首先去应用程序文件夹中,删除关于Python的所有文件; 第二步:打开terminal终端,输入下面命令查看versions下有哪些python版本; ls /library/frameworks/python.framework/versions第三步࿱…...
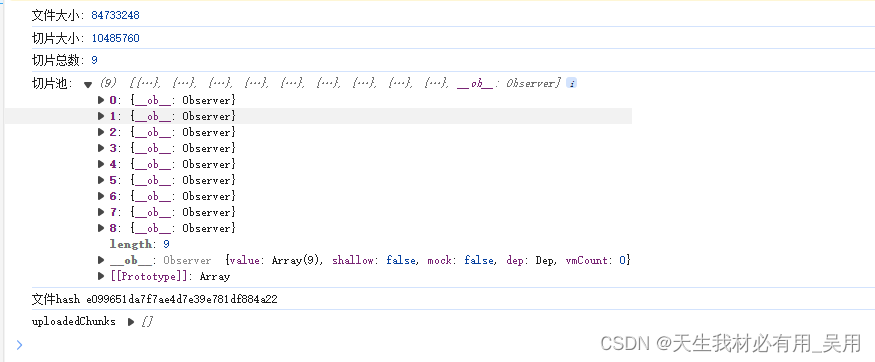
Vue 大文件切片上传实现指南包会,含【并发上传切片,断点续传,服务器合并切片,计算文件MD5,上传进度显示,秒传】等功能
Vue 大文件切片上传实现指南 背景 在Web开发中,文件上传是一个常见的功能需求,尤其是当涉及到大文件上传时,为了提高上传的稳定性和效率,文件切片上传技术便显得尤为重要。通过将大文件切分成多个小块(切片࿰…...

【VUE+ElementUI】el-table表格固定列el-table__fixed导致滚动条无法拖动
【VUEElementUI】el-table表格固定列el-table__fixed导致滚动条无法拖动 背景 当设置了几个固定列之后,表格无数据时,点击左侧滚动条却被遮挡,原因是el-table__fixed过高导致的 解决 在index.scss中直接加入以下代码即可 /* 设置默认高…...

重置gitlab root密码
gitlab-rails console -e production user User.where(id: 1).first user User.where(name: "root").first #输入重置密码命令 user.password"admin123!" #再次确认密码 user.password_confirmation"admin123!" #输入保存命令&am…...

v-text 和v-html
接下来,我讲介绍一下v-text和v-html的使用方式以及它们之间的区别。 使用方法 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-widt…...
)
学习笔记——C语言基本概念结构体共用体枚举——(10)
1、结构体 定义新的数据类型: 数据类型:char short int long float double 数组 指针 结构体 结构体: 新的自己定义的数据类型 格式: struct 名字{ 成员 1; 成员 2; 。 。 。 …...

VMware虚拟机三种网络模式
VMware虚拟机提供了三种主要的网络连接模式,它们分别是: 桥接模式(Bridged Mode)网络地址转换模式(NAT Mode)仅主机模式(Host-Only Mode) 1. 桥接模式(Bridged Mode&am…...

超导输电技术:从原理到工程应用的挑战与前景
1. 超导输电线路:从技术神话到工程现实的漫长跋涉大约二十年前,当“高温超导”这个名词开始从实验室走向产业界的视野时,整个电力工程领域都为之振奋。想象一下,我们日常依赖的庞大电网,其输电线路中高达5%到10%的电能…...

AI支付架构选型:Card Rails与Agent Rails的深度对比与实践指南
1. 项目概述:AI支付架构的十字路口最近在设计和落地几个AI驱动的支付系统时,我反复被一个核心的架构选择所困扰:是采用“Card Rails”还是“Agent Rails”?这不仅仅是技术选型,更是两种截然不同的产品哲学和风险控制思…...
2026-05-11 全国各地响应最快的 BT Tracker 服务器(联通版)
数据来源:https://bt.me88.top 序号Tracker 服务器地域网络响应(毫秒)1udp://60.172.236.18:6969/announce安徽芜湖联通102udp://118.196.100.63:6969/announce安徽芜湖联通113http://211.75.205.187:6969/announce安徽芜湖联通384http://211.75.205.188:80/announ…...

ARM链接器Scatter文件解析与内存布局优化
1. ARM链接器Scatter文件核心概念解析在嵌入式系统开发中,内存布局的精确控制是确保系统稳定运行的关键。ARM链接器通过Scatter文件这一强大工具,为开发者提供了细粒度的内存管理能力。Scatter文件本质上是一个描述文件,它定义了代码和数据在…...

中文智能体协作框架agency-agents-zh:从原理到实战搭建多AI智能体系统
1. 项目概述:一个中文智能体协作框架的诞生最近在开源社区里,一个名为jnMetaCode/agency-agents-zh的项目引起了我的注意。作为一名长期关注AI应用落地的开发者,我深知“智能体”这个概念从学术论文走向实际工程应用,中间隔着巨大…...

FMCP协议:构建创作者统一文件管理中枢,打破应用孤岛
1. 项目概述:一个为创作者而生的文件管理中枢如果你是一位内容创作者,无论是视频剪辑师、摄影师、平面设计师,还是播客制作人,你的工作流里一定少不了与海量文件打交道。原始素材、工程文件、渲染输出、版本迭代……这些文件散落在…...
)
解决Modelsim SE 10.6c仿真Vivado 2019乘法器IP核的“.vhd only”难题(附完整脚本)
解决Modelsim SE 10.6c仿真Vivado 2019乘法器IP核的“.vhd only”难题(附完整脚本) 在FPGA设计流程中,Xilinx Vivado与Mentor Modelsim的组合是许多工程师的首选工具链。但当Vivado 2019生成的乘法器IP核仅提供VHDL接口文件(.vhd)时ÿ…...

Discord集成Claude智能体:极简Docker容器化部署与安全实践
1. 项目概述:一个为Discord量身定制的Claude智能体运行栈 如果你和我一样,既想在日常工作的Discord频道里无缝调用Claude这样的强大AI助手,又对复杂、臃肿的Bot框架感到头疼,那么 nanoclaw-discord 这个项目可能就是你在找的答…...

ANSI转义序列封装:cursor-reset库实现终端光标精准控制
1. 项目概述与核心价值 最近在折腾一些自动化工具链,发现一个挺有意思的小项目,叫 zhitrend/cursor-reset 。乍一看名字,你可能会觉得这只是一个重置光标位置的小工具,但实际用下来,我发现它解决的痛点非常精准&…...

从公式到代码:用STM32实现直线滑台S曲线加减速控制的保姆级教程
从公式到代码:用STM32实现直线滑台S曲线加减速控制的保姆级教程 在工业自动化和精密设备领域,直线滑台模组的运动控制质量直接影响着加工精度和设备寿命。传统的梯形加减速算法虽然简单易实现,但在启停阶段会产生明显的机械冲击,导…...