深度学习理论基础(三)封装数据集及手写数字识别
目录
- 前期准备
- 一、制作数据集
- 1. excel表格数据
- 2. 代码
- 二、手写数字识别
- 1. 下载数据集
- 2. 搭建模型
- 3. 训练网络
- 4. 测试网络
- 5. 保存训练模型
- 6. 导入已经训练好的模型文件
- 7. 完整代码
前期准备
必须使用 3 个 PyTorch 内置的实用工具(utils):
⚫ DataSet 用于封装数据集;
⚫ DataLoader 用于加载数据不同的批次;
⚫ random_split 用于划分训练集与测试集。
一、制作数据集
在封装我们的数据集时,必须继承实用工具(utils)中的 DataSet 的类,这个过程需要重写__init__和__getitem__、__len__三个方法,分别是为了加载数据集、获取数据索引、获取数据总量。我们通过代码读取excel表格里面的数据作为数据集。
1. excel表格数据
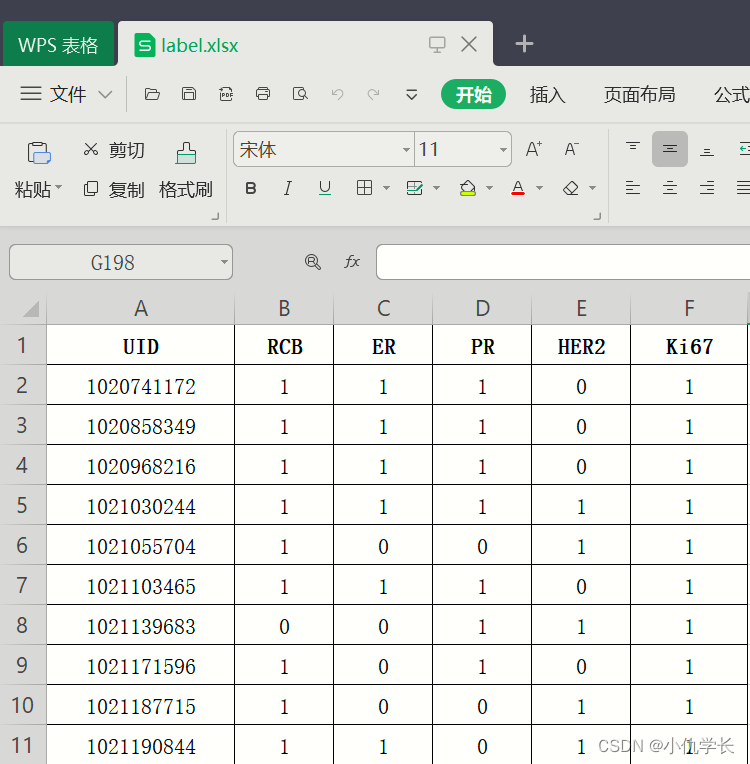
2. 代码
为了简单演示,我们将表格的第0列作为输入特征,第1列作为输出特征。
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.utils.data import random_split
import matplotlib.pyplot as plt# 制作数据集
class MyData(Dataset): """继承 Dataset 类"""def __init__(self, filepath):super().__init__()df = pd.read_excel(filepath).values """ 读取excel数据"""arr = df.astype(np.int32) """转为 int32 类型数组"""ts = torch.tensor(arr) """数组转为张量"""ts = ts.to('cuda') """把训练集搬到 cuda 上"""self.X = ts[:, :1] """获取第0列的所有行做为输入特征"""self.Y = ts[:, 1:2] """获取第1列的所有行为输出特征"""self.len = ts.shape[0] """样本的总数""" def __getitem__(self, index):return self.X[index], self.Y[index]def __len__(self):return self.lenif __name__ == '__main__': """获取数据集"""Data = MyData('label.xlsx')print(Data.X[0]) """输出为:tensor([1020741172], device='cuda:0', dtype=torch.int32)"""print(Data.Y[0]) """输出为:tensor([1], device='cuda:0', dtype=torch.int32) """print(Data.__len__()) """输出为:233 """"""划分训练集与测试集"""train_size = int(len(Data) * 0.7) # 训练集的样本数量test_size = len(Data) - train_size # 测试集的样本数量train_Data, test_Data = random_split(Data, [train_size, test_size])"""批次加载器"""""" 第一个参数:表示要加载的数据集,即之前划分好的 train_Data或test_Data 。"""""" 第二个参数:表示在每个 epoch(训练周期)开始之前是否重新洗牌数据。在训练过程中,通常会将数据进行洗牌,以确保模型能够学习到更加泛化的特征。而测试数据不需要重新洗牌,因为测试集仅用于评估模型的性能,不涉及模型参数的更新"""""" 第三个参数:表示每个批次中的样本数量为 32。也就是说,每次迭代加载器时,它会从训练数据集中加载128个样本。"""train_loader = DataLoader(train_Data, shuffle=True, batch_size=128)test_loader = DataLoader(test_Data, shuffle=False, batch_size=64)"""打印第一个批次的输入与输出特征"""for inputs, targets in train_loader:print(inputs)print(targets)
二、手写数字识别
1. 下载数据集
在下载数据集之前,要设定转换参数:transform,该参数里解决两个问题:
⚫ ToTensor:将图像数据转为张量,且调整三个维度的顺序为 (C-W-H);C表示通道数,二维灰度图像的通道数为 1,三维 RGB 彩图的通道数为 3。
⚫ Normalize:将神经网络的输入数据转化为标准正态分布,训练更好;根据统计计算,MNIST 训练集所有像素的均值是 0.1307、标准差是 0.3081
"""数据转换为tensor数据"""
transform_data = transforms.Compose([transforms.ToTensor(),transforms.Normalize(0.1307, 0.3081)
])"""下载训练集与测试集"""
train_Data = datasets.MNIST(root = 'E:/Desktop/Document/4. Python/例程代码/dataset/mnist/', """下载路径"""train = True, """训练集"""download = True, """如果该路径没有该数据集,就下载"""transform = transform_data """数据集转换参数"""
)
test_Data = datasets.MNIST(root = 'E:/Desktop/Document/4. Python/例程代码/dataset/mnist_test/', """下载路径"""train = False, """非训练集,也就是测试集"""download = True, """如果该路径没有该数据集,就下载"""transform = transform_data """数据集转换参数"""
)"""批次加载器"""
train_loader = DataLoader(train_Data, shuffle=True, batch_size=64)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=64)
2. 搭建模型
class DNN(nn.Module):def __init__(self):''' 搭建神经网络各层 '''super(DNN,self).__init__()self.net = nn.Sequential( # 按顺序搭建各层nn.Flatten(), # 把图像铺平成一维nn.Linear(784, 512), nn.ReLU(), # 第 1 层:全连接层nn.Linear(512, 256), nn.ReLU(), # 第 2 层:全连接层nn.Linear(256, 128), nn.ReLU(), # 第 3 层:全连接层nn.Linear(128, 64), nn.ReLU(), # 第 4 层:全连接层nn.Linear(64, 10) # 第 5 层:全连接层)def forward(self, x):''' 前向传播 '''y = self.net(x) # x 即输入数据return y # y 即输出数据
3. 训练网络
"""实例化模型"""
model = DNN().to('cuda:0') def train_net():"""1.损失函数的选择"""loss_fn = nn.CrossEntropyLoss() # 自带 softmax 激活函数"""2.优化算法的选择"""learning_rate = 0.01 # 设置学习率optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate,momentum=0.5 # momentum(动量),它使梯度下降算法有了力与惯性)"""3.训练"""epochs = 5losses = [] """记录损失函数变化的列表"""for epoch in range(epochs):for (x, y) in train_loader: """从批次加载器中获取小批次的x与y"""x, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) #将样本放入实例化的模型中,这里自动调用forward方法。loss = loss_fn(Pred, y) # 计算损失函数losses.append(loss.item()) # 记录损失函数的变化optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数"""4.画损失图"""Fig = plt.figure()plt.plot(range(len(losses)), losses)plt.show()损失图如下:
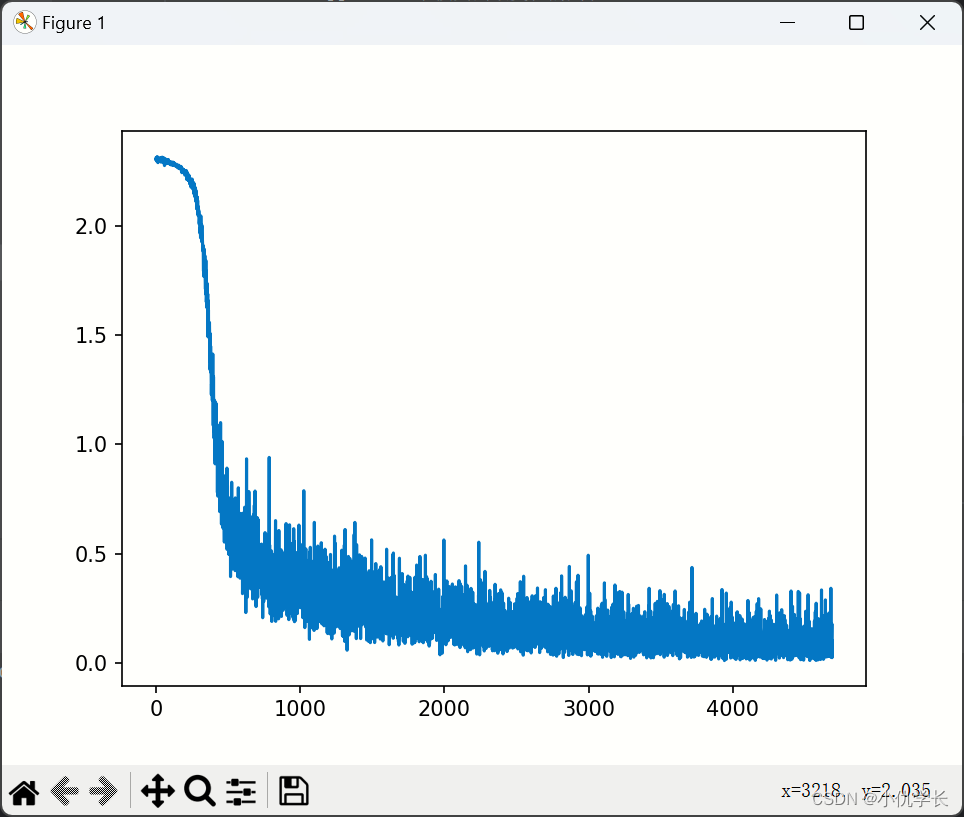
4. 测试网络
测试网络不需要回传梯度。
"""实例化模型"""
model = DNN().to('cuda:0') def test_net():correct = 0total = 0with torch.no_grad(): #该局部关闭梯度计算功能for (x, y) in test_loader: #从批次加载器中获取小批次的x与yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model (x) #将样本放入实例化的模型中,这里自动调用forward方法。_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum((predicted == y))total += y.size(0)print(f'测试集精准度: {100 * correct / total} %')

5. 保存训练模型
在保存模型前,必须要先进行训练网络去获取和优化模型参数。
if __name__ == '__main__':model = DNN().to('cuda:0') train_net()torch.save(model,'old_model.pth')
6. 导入已经训练好的模型文件
导入训练好的模型文件,我们就不需要再进行训练网络,直接使用测试网络来测试即可。
new_model使用了原有模型文件,我们就需要在测试网络的前向传播中的模型修改为 new_model去进行测试。如下:
""" 假设我们之前保存好的模型文件为:'old_model.pth' """def test_net():correct = 0total = 0with torch.no_grad(): #该局部关闭梯度计算功能for (x, y) in test_loader: #从批次加载器中获取小批次的x与yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = new_model (x) #将样本放入实例化的模型中,这里自动调用forward方法。_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum((predicted == y))total += y.size(0)print(f'测试集精准度: {100 * correct / total} %')if __name__ == '__main__':new_model = torch.load('old_model.pth')test_net()
7. 完整代码
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt"""------------1.下载数据集----------"""
"""数据转换为tensor数据"""
transform_data = transforms.Compose([transforms.ToTensor(),transforms.Normalize(0.1307, 0.3081)
])"""下载训练集与测试集"""
train_Data = datasets.MNIST(root = 'E:/Desktop/Document/4. Python/例程代码/dataset/mnist/', """下载路径"""train = True, """训练集"""download = True, """如果该路径没有该数据集,就下载"""transform = transform_data """数据集转换参数"""
)
test_Data = datasets.MNIST(root = 'E:/Desktop/Document/4. Python/例程代码/dataset/mnist_test/', """下载路径"""train = False, """非训练集,也就是测试集"""download = True, """如果该路径没有该数据集,就下载"""transform = transform_data """数据集转换参数"""
)"""批次加载器"""
train_loader = DataLoader(train_Data, shuffle=True, batch_size=64)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=64)"""---------------2.定义模型------------"""
class DNN(nn.Module):def __init__(self):''' 搭建神经网络各层 '''super(DNN,self).__init__()self.net = nn.Sequential( # 按顺序搭建各层nn.Flatten(), # 把图像铺平成一维nn.Linear(784, 512), nn.ReLU(), # 第 1 层:全连接层nn.Linear(512, 256), nn.ReLU(), # 第 2 层:全连接层nn.Linear(256, 128), nn.ReLU(), # 第 3 层:全连接层nn.Linear(128, 64), nn.ReLU(), # 第 4 层:全连接层nn.Linear(64, 10) # 第 5 层:全连接层)def forward(self, x):''' 前向传播 '''y = self.net(x) # x 即输入数据return y # y 即输出数据"""-------------3.训练网络-----------"""
def train_net():# 损失函数的选择loss_fn = nn.CrossEntropyLoss() # 自带 softmax 激活函数# 优化算法的选择learning_rate = 0.01 # 设置学习率optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate,momentum=0.5)epochs = 5losses = [] # 记录损失函数变化的列表for epoch in range(epochs):for (x, y) in train_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)loss = loss_fn(Pred, y) # 计算损失函数losses.append(loss.item()) # 记录损失函数的变化optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数"""Fig = plt.figure()""""""plt.plot(range(len(losses)), losses)""""""plt.show()""""""--------------------4.测试网络-----------"""
def test_net():correct = 0total = 0with torch.no_grad(): #该局部关闭梯度计算功能for (x, y) in test_loader: #获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = new_model(x) #一次前向传播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum((predicted == y))total += y.size(0)print(f'测试集精准度: {100 * correct / total} %')if __name__ == '__main__':""" ------- 5.保存模型文件------"""""" model = DNN().to('cuda:0') """""" train_net() """""" torch.save(model,'old_model.pth') """""" ------- 6.加载模型文件 ----- """new_model = torch.load('old_model.pth')test_net()
相关文章:
深度学习理论基础(三)封装数据集及手写数字识别
目录 前期准备一、制作数据集1. excel表格数据2. 代码 二、手写数字识别1. 下载数据集2. 搭建模型3. 训练网络4. 测试网络5. 保存训练模型6. 导入已经训练好的模型文件7. 完整代码 前期准备 必须使用 3 个 PyTorch 内置的实用工具(utils): ⚫…...
vue3+eachrts饼图轮流切换显示高亮数据
<template><div class"charts-box"><div class"charts-instance" ref"chartRef"></div>// 自定义legend 样式<div class"charts-note"><span v-for"(items, index) in data.dataList" cla…...
UTONMOS:AI+Web3+元宇宙数字化“三位一体”将触发经济新爆点
人工智能、元宇宙、Web3,被称为数字化的“三位一体”,如何看待这三大技术所扮演的角色? 3月24日,2024全球开发者先锋大会“数字化的三位一体——人工智能、元宇宙、Web3.0”论坛在上海漕河泾开发区举行,首次提出&…...

开始焦虑了
大家好,我是洋子,25届的暑期实习自从3月份开始招聘有一段时间了,最近接到了几个25届同学的咨询,其中一个学妹印象比较深刻,她的情况如下 个人情况 学历是双非本,计算机专业,学习方向是Java&…...
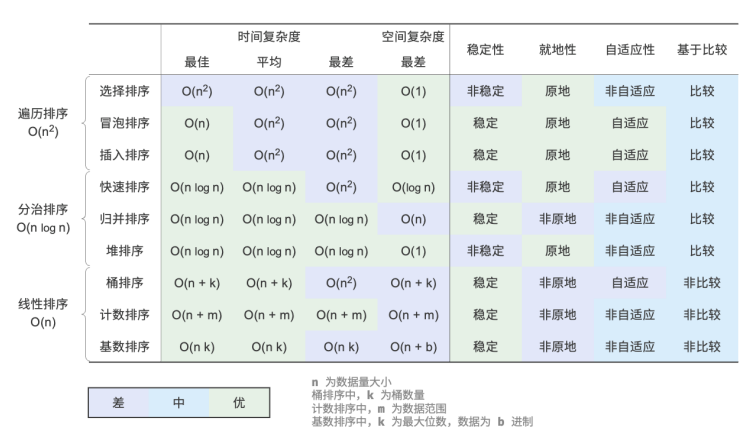
数据结构和算法:十大排序
排序算法 排序算法用于对一组数据按照特定顺序进行排列。排序算法有着广泛的应用,因为有序数据通常能够被更高效地查找、分析和处理。 排序算法中的数据类型可以是整数、浮点数、字符或字符串等。排序的判断规则可根据需求设定,如数字大小、字符 ASCII…...
LLaMA-Factory微调(sft)ChatGLM3-6B保姆教程
LLaMA-Factory微调(sft)ChatGLM3-6B保姆教程 准备 1、下载 下载LLaMA-Factory下载ChatGLM3-6B下载ChatGLM3windows下载CUDA ToolKit 12.1 (本人是在windows进行训练的,显卡GTX 1660 Ti) CUDA安装完毕后,…...

Web安全-浏览器安全策略及跨站脚本攻击与请求伪造漏洞原理
Web安全-浏览器安全策略及跨站脚本攻击与请求伪造漏洞原理 Web服务组件分层概念 静态层 :web前端框架:Bootstrap,jQuery,HTML5框架等,主要存在跨站脚本攻击脚本层:web应用,web开发框架,web服务…...
)
蓝桥杯B组C++省赛——飞机降落(DFS)
题目连接:https://www.lanqiao.cn/problems/3511/learning/ 思路:由于数据范围很小,所有选择用DFS枚举所有飞机的所有的降落顺序,看哪个顺序可以让所有飞机顺利降落,有的话就算成功方案,输出了“YES”。 …...

Java 中的 Map集合
文章目录 添加和修改元素获取元素检查元素删除元素获取所有键 / 值 / 键值对大小 在 Java 中,Map 接口是 Java 集合框架的一部分,它存储键值对(key-value pairs)。Map 接口有许多常用的方法,用于添加、删除、获取元素&…...
基于springboot大学生兼职平台管理系统(完整源码+数据库)
一、项目简介 本项目是一套基于springboot大学生兼职平台管理系统 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,eclipse或者idea 确保可以运行! 该系统功能完善、界面美观、操作简单、功…...
C#学生信息管理系统
一、引言 学生信息管理系统是现代学校管理的重要组成部分,它能够有效地管理学生的基本信息、课程信息、成绩信息等,提高学校管理的效率和质量。本文将介绍如何使用SQL Server数据库和C#语言在.NET平台上开发一个学生信息管理系统的课程设计项目。 二、项…...

双机 Cartogtapher 建图文件配置
双机cartogtapher建图 最近在做硕士毕设的最后一个实验,其中涉及到多机建图,经过调研最终采用cartographer建图算法,其中配置多机建图的文件有些麻烦,特此博客以记录 非常感谢我的同门 ”叶少“ 山上的稻草人-CSDN博客的帮助&am…...
VMware提示 该虚拟机似乎正在使用中,如何解决?
VMware提示 该虚拟机似乎正在使用中,如何解决? 问题描述解决方法1.找到安装VMware的文件目录2.在VMware目录下.lck后缀的文件夹删除或重命名3.运行VMware 问题描述 该虚拟机似乎正在使用中。 如果该虚拟机未在使用,请按“获取所有权(T)”按钮获取它的所…...
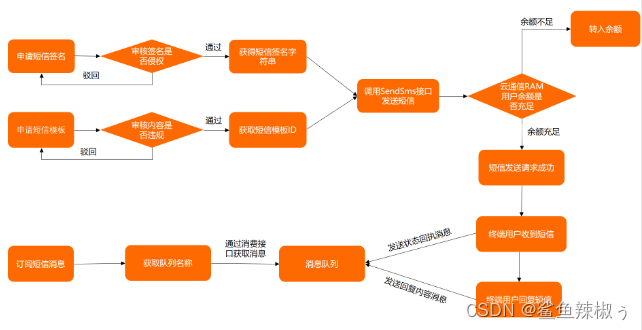
阿里云短信服务业务
一、了解阿里云用户权限操作 1.注册账号、实名认证; 2.使用AccessKey 步骤一 点击头像,权限安全的AccessKey 步骤二 设置子用户AccessKey 步骤三 添加用户组和用户 步骤四 添加用户组记得绑定短信服务权限 步骤五 添加用户记得勾选openApi访问 添加…...

ElasticSearch的DSL查询
ElasticSearch的DSL查询 准备工作 创建测试方法,初始化测试结构。 import org.apache.http.HttpHost; import org.apache.lucene.search.TotalHits; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchRespo…...

每天定时杀spark进程
##编写shell脚本 #!/bin/bash arr(“zhangsan” “lisi” “wangwu”) for i in “${arr[]}” do processps -ef|grep ${i}| grep -v "grep"| awk {print $2} kill -9 ${process} done ##每日定时杀手动启动的进程 0 19 * * * cd /kill_process && sh kil…...

win10 安装kubectl,配置config连接k8s集群
安装kubectl 按照官方文档安装:https://kubernetes.io/docs/tasks/tools/install-kubectl-windows/ curl安装 (1)下载curl安装压缩包: curl for Windows (2)配置环境变量: 用户变量: Path变…...
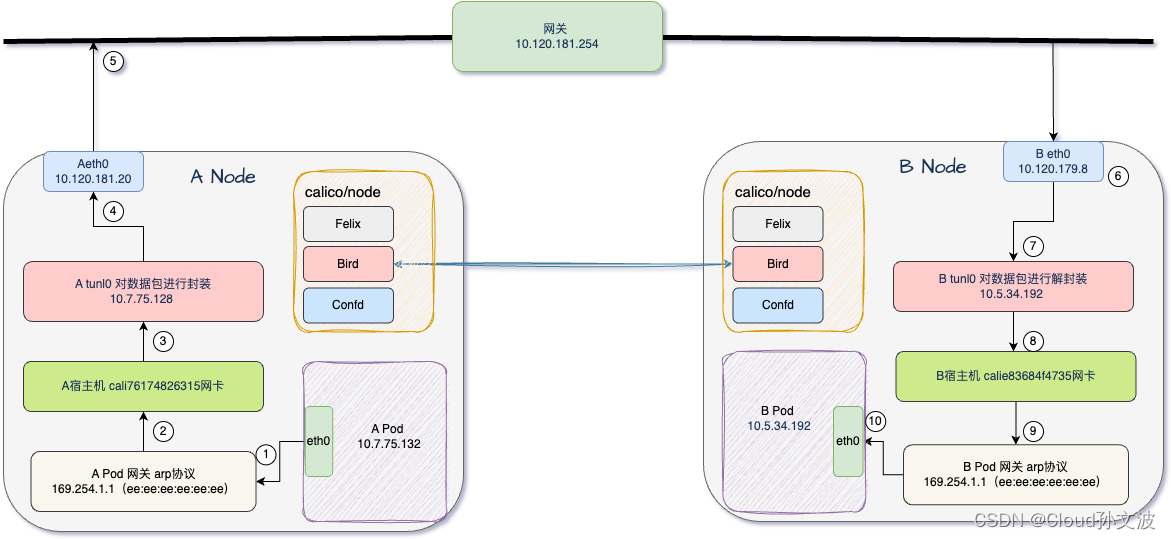
Calico IPIP和BGP TOR的数据包走向
IPIP Mesh全网互联 文字描述 APOD eth0 10.7.75.132 -----> APOD 网关 -----> A宿主机 cali76174826315网卡 -----> Atunl0 10.7.75.128 封装 ----> Aeth0 10.120.181.20 -----> 通过网关 10.120.181.254 -----> 下一跳 BNODE eth0 10.120.179.8 解封装 --…...

静态成员主要用于提供与类本身相关的功能或数据,有什么应用场景
静态成员(包括静态方法和静态属性)在JavaScript中常用于多种应用场景,它们为类提供了与类本身直接相关而不是与实例相关的功能或数据。以下是一些常见的应用场景: 工厂方法 静态方法可以作为工厂方法,用于创建类的实…...

在线考试|基于Springboot的在线考试管理系统设计与实现(源码+数据库+文档)
在线考试管理系统目录 目录 基于Springboot的在线考试管理系统设计与实现 一、前言 二、系统设计 三、系统功能设计 1、前台: 2、后台 管理员功能 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主…...

Topit:macOS窗口置顶神器,让多任务处理效率翻倍
Topit:macOS窗口置顶神器,让多任务处理效率翻倍 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否经常在macOS上同时处理多个任务时…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...

企业云盘签章技术方案:从数字签名原理到工程落地
背景 电子签章在企业云盘中的落地,不只是一个"上传盖章图片"的功能实现。本质上,它是一套涉及数字签名、PKI基础设施、文档完整性校验的综合性技术方案。本文从技术选型角度,说清楚企业云盘内置签章需要解决哪些问题、主流实现方案…...

别再手动维护接口文档了!用Spring Boot 3和Swagger 3实现代码与文档的自动同步
Spring Boot 3与Swagger 3:构建零维护成本的API文档工作流 每次接口变更都要手动更新文档?团队成员总是抱怨文档与实际接口不一致?在敏捷开发时代,传统文档维护方式已成为拖累工程效率的典型痛点。本文将揭示如何通过Spring Boot …...

基于MAX78000与CNN的智能螺栓巡检小车:嵌入式AI实战解析
1. 项目概述与核心思路在轨道交通的日常运维中,螺栓的紧固状态检查是一项繁重且关键的任务。无论是轨道上的紧固螺栓,还是列车转向架、轮对轴承上的关键螺栓,其松动或失效都可能引发严重的安全事故。传统的人工巡检方式不仅效率低下ÿ…...

AWS DevOps Agent 完全指南
AWS DevOps Agent 是 AWS 推出的前沿 AI 运维代理,自主调查和解决事件、持续预防故障、提升系统可靠性。本文档覆盖从原理到实战的全生命周期管理。 一、定位与价值 一句话定义 AWS DevOps Agent = AI 驱动的 SRE 队友,724 自主调查告警、定位根因、生成修复方案、预防未来…...

BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕
BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还在为无法保存B站视频字幕而烦恼࿱…...

WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件
WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔兽争霸3》这…...

为什么你的Midjourney雾效总像“水汽”而非“山岚”?——资深CG总监拆解大气散射物理模型在--v 6.1中的3层映射偏差
更多请点击: https://kaifayun.com 第一章:为什么你的Midjourney雾效总像“水汽”而非“山岚”? Midjourney 生成的雾气常呈现为均匀、半透明、边界模糊的“水汽感”——厚重、潮湿、缺乏层次与呼吸感。这并非模型能力不足,而是提…...