Day5-Hive的结构和优化、数据文件存储格式
Hive
窗口函数
案例
-
需求:连续三天登陆的用户数据
-
步骤:
-- 建表 create table logins (username string,log_date string ) row format delimited fields terminated by ' '; -- 加载数据 load data local inpath '/opt/hive_data/login' into table logins; -- 查询数据 select * from logins tablesample (5 rows); -- 按用户分组,将登陆日期进行排序 -- over(partition by xxx order by xxx) -- 获取每一条数据两行之前的数据 select *, lag(log_date, 2) over (partition by username order by log_date) as 2d_log_date from logins; -- 获取连续三天登录的数据 select distinct username from (select *, lag(log_date, 2) over (partition by username order by log_date) as 2d_log_datefrom logins ) t where datediff(log_date, 2d_log_date) = 2;
其他操作
join
-
同MySQL类似,在Hive中也提供了表之间的join,包含:内连接
inner join,左连接left join,右连接right join和全外连接full outer join以及极少使用的笛卡尔积 -
除此之外,Hive还提供了特殊的连接:
left semi join。当a left semi join b,表示获取a表哪些数据在b表中出现过 -
案例
-- 建表 drop table if exists orders; create table orders (order_id int,order_date string,product_id int,number int ) row format delimited fields terminated by ' '; drop table if exists products; create table products (product_id int,product_name string,price double ) row format delimited fields terminated by ' '; -- 加载数据 load data local inpath '/opt/hive_data/orders' into table orders; load data local inpath '/opt/hive_data/products' into table products; select * from orders; select * from products; -- 需求一:获取每天卖了多少钱 select o.order_date,sum(o.number * p.price) from orders o left join products p on o.product_id = p.product_id group by o.order_date; -- 需求二:获取哪些商品被卖出去过 -- 获取商品表中的哪些数据在订单表中出现过 -- 方式一:left semi join select * from products p left semi join orders oon p.product_id = o.product_id; -- 方式二: select * from products where product_id in (select product_id from orders);
排序
-
不同于MySQL的地方在于,在Hive中,提供了两种排序方式
order by:全局排序。在排序的时候,会忽略掉ReduceTask的数量,对所有的数据进行整体的排序sort by:局部排序。这种方式,在每一个ReduceTask内部排序。如果没有指定,那么会根据排序字段,计算字段的哈希码,然后将字段分发到对应到ReduceTask上来进行排序
-
案例
-
原始数据
2 henry 84 3 jack 76 1 david 92 1 bruce 78 1 balley 77 2 hack 85 1 tom 79 3 peter 96 2 eden 92 1 mary 85 3 pard 61 3 charles 60 2 danny 94 3 cindy 75 -
案例
-- 建表 drop table if exists scores; create table scores (class int,name string,score int ) row format delimited fields terminated by ' '; -- 加载数据 load data local inpath '/opt/hive_data/scores' into table scores; -- 查询数据 select * from scores tablesample (5 rows); -- order by insert overwrite local directory '/opt/hive_demo/order_by1'row format delimited fields terminated by '\t' select * from scores order by score; -- sort by insert overwrite local directory '/opt/hive_demo/sort_by1'row format delimited fields terminated by '\t' select * from scores sort by score; -- Hive中的SQL默认会转化为MapReduce任务来执行 -- 在MapReduce中,如果不指定,默认只有1个ReduceTask -- 因此也只产生1个结果文件 -- 指定ReduceTask的个数 set mapreduce.job.reduces = 3; insert overwrite local directory '/opt/hive_demo/order_by2'row format delimited fields terminated by '\t' select * from scores order by score; insert overwrite local directory '/opt/hive_demo/sort_by2'row format delimited fields terminated by '\t' select * from scores sort by score; -- 在实际过程中,其实极少单独使用sort by -- sort by一般是结合distribute by来使用 -- 案例:将每一个班的学生按照成绩降序排序 insert overwrite local directory '/opt/hive_demo/distribute_by'row format delimited fields terminated by '\t' select * from scores distribute by class sort by score desc;
-
-
如果
distribute by和sort by的字段一致,那么可以省略为cluster by。注意,cluster by默认只能升序不能降序排序
beeline和JDBC
-
JDBC(Java Database Connection):类似于MySQL,Hive也提供了JDBC操作,代码和MySQL的JDBC操作一模一样
package com.fesco.jdbc;import java.sql.*;public class HiveJDBCDemo {public static void main(String[] args) throws ClassNotFoundException, SQLException {// 注册驱动Class.forName("org.apache.hive.jdbc.HiveDriver");// 获取连接// Hive对外提供的连接端口是10000Connection connection = DriverManager.getConnection("jdbc:hive2://101.36.69.196:31177/demo", "root", "root");// 获取表述Statement statement = connection.createStatement();// 执行SQLResultSet resultSet = statement.executeQuery("select * from products");// 遍历结果集while(resultSet.next()){System.out.println(resultSet.getString("product_name"));}// 关闭resultSet.close();statement.close();connection.close();}} -
利用Datagrip连接Hive,实际上就是用JDBC的方式连接的Hive
-
Hive提供了原生的远程连接方式:beeline
beeline -u jdbc:hive2://hadoop01:10000/demo -n root-u表示url,连接地址;-n表示name,用户名 -
注意:如果想要使用JDBC的方式连接Hive,那么必须开启
hiveserver2服务!!!
SerDe
-
SerDe(Serializar-Deserializar):是Hive中提供的一套用于进行序列化和反序列化操作的机制
-
可以利用SerDe来解决数据的格式问题
-
案例
-- 不使用SerDe -- 1. 建表管理原始数据 create table logs_tmp (log string ); load data local inpath '/opt/hive_data/logs' into table logs_tmp; select * from logs_tmp tablesample (5 rows); -- 2. 建表 create table logs (user_ip string, -- 用户iplog_date string, -- 访问日期和时间timezone string, -- 时区request_way string, -- 请求方式resources string, -- 请求资源protocol string, -- 请求协议state_id int -- 状态码 ) row format delimited fields terminated by '\t'; -- 3. 先将数据替换为规则形式,然后利用split拆分 insert into table logs select arr[0], arr[1], arr[2], arr[3], arr[4], arr[5], cast(arr[6] as int) from (select split(regexp_replace(log, '(.*) \-\- \\[(.*) (.*)\\] \"(.*) (.*) (.*)\" (.*) \-', '$1 $2 $3 $4 $5 $6 $7'), ' ') arr from logs_tmp ) t; -- 查询数据 select * from logs; -- 使用SerDe -- 建表 drop table if exists logs; create table logs (user_ip string, -- 用户iplog_date string, -- 访问日期和时间timezone string, -- 时区request_way string, -- 请求方式resources string, -- 请求资源protocol string, -- 请求协议state_id int -- 状态码 ) row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'with serdeproperties ('input.regex'='(.*) \-\- \\[(.*) (.*)\\] \"(.*) (.*) (.*)\" (.*) \-') stored as textfile ; load data local inpath '/opt/hive_data/logs' into table logs; select * from logs;
视图(view)
-
视图是对原表中部分字段进行抽取,可以看作是原表的子表,但是本质上是一个虚拟表
-
当不需要表中所有的字段,而只需要这个表中的部分字段的时候,那么此时就可以使用视图来对数据进行封装
-
视图只能看不能修改!
-
视图的优点
- 简单。使用视图的时候,完全不需要关心视图背后依赖的表结构是否发生变化,是否产生关联。对于用户而言,视图就是已经符合过滤条件的结果集
- 安全。用户只被允许访问视图中已经过滤好的数据,并且视图中的数据只能查不能改,此时不会影响基表的数据
- 数据独立。一旦视图创建,那么此时基表发生结构变化,不会影响视图的操作
-
Hive中,在定义视图的时候,需要封装一个select语句。此时,被封装的这个select在创建视图的时候并不会执行;而是会在第一次查询视图的时候才会触发封装的select执行
-
视图分为虚拟视图(只存储在内存中,可以认为是一个虚拟表)和物化视图(会落地到磁盘上,此时就是一个真正的子表)。需要注意的是,Hive只支持虚拟视图不支持物化视图
-
案例
-- 创建视图 create view logs_view as select user_ip, log_date, resources from logs order by log_date; -- 查询视图 select * from logs_view; -- 删除视图 drop view logs_view;
Hive存储
概述
- Hive中的数据最终是以文件形式落地到HDFS上,目前Hive官方原生的文件格式有6种:
textfile,RCFile,orc,parquet,avro和sequencefile- avro和sequencefile将文件以序列形式来存储(序列化文件)
- 如果不指定,那么HDFS默认将文件以textfile格式存储
- textfile,avro和sequencefile是行存储格式,RCFile,orc和parquet是列存储格式
textfile不支持修改(delete和update),但是列存储格式都支持delete和update操作,效率非常低
textfile
- Hive中的文件格式默认就是textfile
- 默认情况下,textfile不对数据进行压缩,因此占用磁盘空间相对较大;在进行数据分析的时候,开销相对也较大
- textfile支持Gzip和Bzip2的压缩格式
orc
- orc(Optimized Row Columnar,优化的行列格式),是Hive0.11版本引入的一种文件格式,是基于RCFile格式机型优化,本身是以列存储形式来存放数据
- 每一个ORC文件,由1个File Footer、1个Postscript以及1到多个Stripe来组成
- Stripe:用于存储数据的。默认情况下,每一个Stripe的大小是250M。Stripe由三部分组成
- Index Data:索引数据。默认每隔10000行数据形成一次索引,会记录每一列的最小值、最大值、以及每一列中的行索引
- Row Data:行数据。在存储数据的时候,不是将整个表的列来进行拆分,而是先截取部分行,然后将每一行数据的字段来进行拆分。因为同一列中的字段类型是一致的,所以可以给不同的列来指定的压缩机制进行更好的压缩
- Stripe Footer:记录每一列的数据类型、每一列的字节长度
- File Footer:记录每一个Stripe中包含的行数以及每一列的数据类型。初次之外,File Footer还可以记录每一列的聚合信息,例如sum、max等
- Postscript:记录了整个文件的信息,例如文件是否压缩,压缩编码是什么,以及File Footer在orc文件中的从存储位置
- 如果需要在ORC文件中查询某一条数据:
- 首先从文件末尾读取Postscript,从Postscript中获取到File Footer在文件中的存储位置
- 然后读取File Footer,从File Footer中获取这条数据所在的Stripe的位置
- 读取Stripe中的Index Data,锁定这条数据对应的索引位置,最后再通过Row Data获取到这条数据
parquet格式
- parquet格式是从Hive0.10版本开始提供的一种二进制的文件格式,所以不能直接读取
- 每一个parquet文件中,包含了四部分
- Magic Code:魔数,用于确保当前的文件是一个parquet文件
- Footer Length:记录元数据的大小。通过这个值以及parquet文件的大小,可以计算出元数据在parquet文件中的偏移量
- Metastore:元数据存储,记录了当前parquet文件的文件信息,以及文件大小、Row Group的数量
- Row Group:行组
- 将文件从行方向上进行切分,每一部分就是一个Row Group。默认情况下,Row Group和Block是等大的
- 每一个行组中,又包含了1个到多个Column Chunk(列块)。每一列对应了一个列块。因为同一个列块中的数据类型相同,所以可以给不同的列块指定不同的压缩编码
- 每一个列块中包含了一个到多个Page(页)。Page是parquet文件中数据存储的最小单位
- Page分为三种
- 数据页:存储数据
- 字典页:存储编码信息
- 索引页:记录存储的数据在文件中的偏移量
- 需要注意的是,Hive提供的原生的parquet文件不支持索引页
- parquet格式支持LZO和snappy压缩
Hive压缩
-
Hive支持对结果文件进行压缩。其中,经常对orc和parquet文件进行压缩
-
orc文件压缩可以通过属性
orc.compress来配置压缩,可以使用的值:NONE,ZLIB和SNAPPY。NONE表示不压缩create table orc_test (id int,name string,age int ) row format delimited fields terminated by ' 'stored as orc; -- 以orc格式来存储 insert into table orc_test values (1, 'Amy', 15);create table orc_zlib (id int,name string,age int ) row format delimited fields terminated by ' 'stored as orctblproperties ('orc.compress' = 'ZLIB'); insert into table orc_zlib values (1, 'Amy', 15);create table orc_snappy (id int,name string,age int ) row format delimited fields terminated by ' 'stored as orctblproperties ("orc.compress" = "SNAPPY"); insert into table orc_snappy values (1, 'Amy', 15); -
parquet文件压缩可以通过属性
parquet.compression进行配置。可以使用的值:NONE和SNAPPYcreate table parquet_test (id int,name string,age int ) row format delimited fields terminated by ' 'stored as parquet; -- 以parquet形式来存储数据 insert into table parquet_test values (1, 'May', 15);create table parquet_snappy (id int,name string,age int ) row format delimited fields terminated by ' 'stored as parquettblproperties ("parquet.compression" = "SNAPPY"); insert into table parquet_snappy values (1, 'May', 15);
Hive结构和优化
结构

- Client Interface:客户端端口,包含CLI(Command-line,命令行)和JDBC两种方式
- 客户端连接Client Interface,提交要执行的SQL。这个SQL会被提交给Driver(驱动器)
- Driver包含了4部分
- SQL Parser:SQL解析器,SQL提交给Driver之后,会先有SQL Parser进行解析,在解析的时候,先去检查SQL的语法是否正确,会连接元数据库查询/修改元数据,然后将SQL转化为抽象语法树(AST)
- Physical Plan:物理计划。SQL Parser将SQL解析成AST之后,将AST交给Physical PLAN,将AST编译成具体的执行逻辑
- Query Optimizer:查询优化器。Physical PLAN将执行逻辑交给Query Optimizer进行优化
- Execution:执行器。负责将优化之后的执行逻辑转化成具体的执行任务,例如将执行逻辑转化为MapReduce程序
优化
-
列裁剪或者分区裁剪。在实际生产环境中,经常需要处理大量的数据,那么此时使用
select * from x的形式,会对整个表进行扫描,从而导致查询效率变低。因此在实际过程中,最好执行列或者指定分区进行查询;如果需要进行按行的查询,那么最好限制查询的行数,例如使用limit n或者tablesample(n rows) -
group by的优化。在进行group by的时候,那么此时相同的键对应的值会被分到一组,会被分发到某一个ReduceTask来处理这一组数据。如果某一个键对应的值比较多,那么此时处理这个键的ReduceTask的任务量就相对较大,此时就产生了数据倾斜。针对这个问题,提供了两种优化方案
-
map combine:map端的聚合,就是将数据在MapTask处先进行一次聚合,然后再将聚合后的结果发送给ReduceTask处理
-- 开启聚合机制 set hive.map.aggr = true; -- 指定聚合的值 set hive.groupby.mapaggr.checkinterval = 10000; -
二阶段聚合(负载均衡方式):将Hive的执行过程拆分成2个MapReduce任务执行。第一个MapReduce中,先将数据打散之后进行聚合,第二个MapReduce中,再根据实际的要求进行聚合
-- 开启二阶段聚合 set hive.groupby.skewindata = true;
-
-
CBO(Cost based Optimizer,基于花费的优化器)
- CBO是从Hive0.10开始添加的一种优化机制,从Hive1.1.0开始,CBO优化默认是开启的,可以通过属性
hive.cbo.enable来调节 - CBO遵循的原则:谁的执行代价最小就是最好的执行计划
- CBO是从Hive0.10开始添加的一种优化机制,从Hive1.1.0开始,CBO优化默认是开启的,可以通过属性
-
谓词下推。在保证结果不发生改变的前提下,尽量将where条件(谓词)提前执行,来减少下游处理的数据量,这个过程就称之为谓词下推
-- 开启谓词下推 -- ppd是PredicatePushDown,预测/谓词下推 set hive.optimize.ppd = true; -
map join。当小表和大表进行join的时候, 将小表放入内存中分发给每一个MapTask,MapTask在处理数据时候就直接从内存中获取数据,此时join过程在Map端完成,从而减少了最终交给ReduceTask的数据量
-- 默认是25M set hive.mapjoin.smalltable.filesize = 25000000; -
SMB join
- SMB join(sort merge bucket join):基于分桶机制和map join的前提下实现的一种join方式,用于解决大表和大表之间的join问题
- 当大表和大表进行join的时候,可以考虑先将大表的数据进行分桶,每一个桶中都只包含部分数据,此时每一个桶就相当于是一个小表,在此时join的时候,就是小表和大表join,那么可以进行map join。本质上就是"分而治之"的思想
- SMB join的条件:
A join B- A表和B表都必须分桶,并且B表的桶数必须是A表桶数的整数倍。例如A分了4个桶,那么B表的桶数必须是4n
- 分桶字段和join字段必须一致。
A join B on a.id = b.id,那么此时A表和B表必须以id字段来进行分桶
-
启用严格模式
-
hive.strict.checks.no.partition.filter:默认为false,如果设置为true,那么在查询分区表的时候,必须以分区作为查询条件 -
hive.strict.checks.orderby.no.limit:默认为false,如果设置为true,那么进行order by的时候,必须添加limit语句 -
hive.strict.checks.cartesian.product:默认为false,如果设置为true,那么严禁进行笛卡尔积
-
相关文章:
Day5-Hive的结构和优化、数据文件存储格式
Hive 窗口函数 案例 需求:连续三天登陆的用户数据 步骤: -- 建表 create table logins (username string,log_date string ) row format delimited fields terminated by ; -- 加载数据 load data local inpath /opt/hive_data/login into table log…...

01 计算机网络发展与分类
计算机网络:计算机技术与通信技术的结合。 阶段一:早期网络:ARPAnet。 阶段二:厂商独立发展阶段 阶段三:标准化阶段:ISO,TCP/IP 计算机网络分类 计算机网络分类1:通信子网和资源子网 通信子…...
ubuntu安装sublime3并设置中文
安装Sublime Text 3 在Ubuntu上安装Sublime Text 3可以通过以下步骤进行: 打开终端。 导入Sublime Text 3的GPG密钥: wget -qO- https://download.sublimetext.com/sublimehq-pub.gpg | sudo apt-key add - 添加Sublime Text 3的存储库: …...
python调用阿里云短信配置
1. 新增资质和签名 # 访问地址: https://dysms.console.aliyun.com/domestic/text/qualification2. 静静等待几十分钟~~~ 3. 通过sdk去调用,查看有没有python的sdk https://next.api.aliyun.com/api/Dysmsapi/2017-05-25/SendSms?完整代码 # -*- cod…...
MySQL 8.0.13安装配置教程
写个博客记录一下,省得下次换设备换系统还要到处翻教程,直接匹配自己常用的8.0.13版本 1.MySQL包解压到某个路径 2.将bin的路径加到系统环境变量Path下 3.在安装根目录下新建my.ini配置文件,并用编辑器写入如下数据 [mysqld] [client] port…...
【idea快捷键】idea开发java过程中常用的快捷键
含义win快捷键mac快捷键复制当前行或选定的代码块Ctrl DCommand D通过类名快速查找类Ctrl NCommand N通过文件名快速查找文件Ctrl Shift NCommand Shift N通过符号名称快速查找符号(类、方法等)Ctrl Alt Shift NCommand Shift O跳转到声明C…...
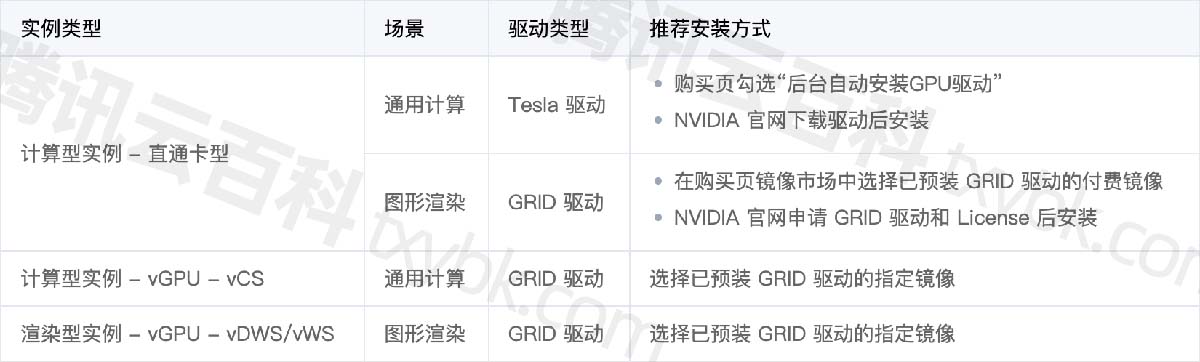
2024年腾讯云GPU云服务器配置价格表(内存/系统盘/地域)
腾讯云GPU服务器是提供GPU算力的弹性计算服务,腾讯云GPU服务器具有超强的并行计算能力,可用于深度学习训练、科学计算、图形图像处理、视频编解码等场景,腾讯云百科txybk.com整理腾讯云GPU服务器租用价格表、GPU实例优势、GPU解决方案、GPU软…...
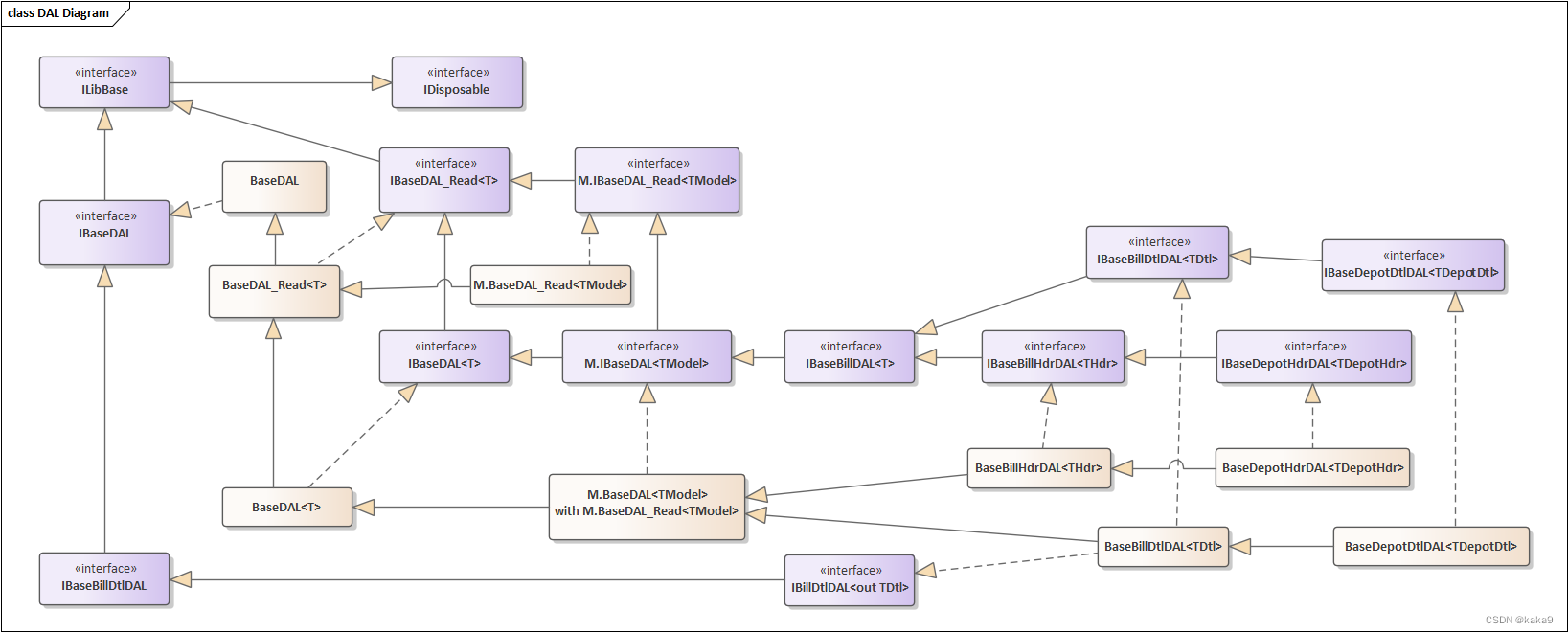
重构数据访问层-优化数据访问的开发
重新整理了一下过去开发的框架,在准备开发新项目时候,重新整理了一下思路,感觉数据访问层还是很鸡肋。过去几年中,急于完成项目开发和交付,框架都是迭代过来的,虽然满足了开发需求,但是…...

云计算概述报告
以下是一篇论述类文章 文章目录 I. 云计算介绍(1)云计算基本概念(2)云计算基本特征 II. 云计算发展历程(1)云计算的起源(2)云计算的发展阶段 III. 云计算特点(1ÿ…...

C++:线程库的使用
文章目录 Windows和Linux平台的线程线程构造函数模板参数包 最近发现C11的线程库还没有进行总结,因此本篇对于C11当中新增的线程库的一些基本用法进行总结 Windows和Linux平台的线程 在Linux平台下是存在一些原生的线程系统调用的,比如有pthread_creat…...

机器学习模型:决策树笔记
第一章:决策树原理 1-决策树算法概述_哔哩哔哩_bilibili 根节点的选择应该用哪个特征?接下来选什么?如何切分? 决策树判断顺序比较重要。可以使用信息增益、信息增益率、 在划分数据集前后信息发生的变化称为信息增益,…...
20.2k stars项目搭建私人网盘界面美功能全
Nextcloud是一套用于创建网络硬盘的客户端-服务器软件。其功能与Dropbox相近,但Nextcloud是自由及开放源代码软件,每个人都可以在私人服务器上安装并执行它。 GitHub数据 20.2k stars561 watching3.2k forks 开源地址:https://github.com/ne…...

卷积篇 | YOLOv8改进之引入全维度动态卷积ODConv | 即插即用
前言:Hello大家好,我是小哥谈。ODConv是一种关注了空域、输入通道、输出通道等维度上的动态性的卷积方法,一定程度上讲,ODConv可以视作CondConv的延续,将CondConv中一个维度上的动态特性进行了扩展,同时了考虑了空域、输入通道、输出通道等维度上的动态性,故称之为全维度…...
和torch.from_numpy(X_train).float()的区别)
Pytorch实用教程:torch.from_numpy(X_train)和torch.from_numpy(X_train).float()的区别
在PyTorch中,torch.from_numpy()函数和.float()方法被用来从NumPy数组创建张量,并可能改变张量的数据类型。两者之间的区别主要体现在数据类型的转换上: torch.from_numpy(X_train):这行代码将NumPy数组X_train转换为一个PyTorch张…...

深度学习pytorch好用网站分享
深度学习在线实验室Featurizehttps://featurize.cn/而且这个网站里面还有一些学习教程 免费好用 如何使用 PyTorch 进行图像分类https://featurize.cn/notebooks/5a36fa40-490e-4664-bf98-aa5ad7b2fc2f...
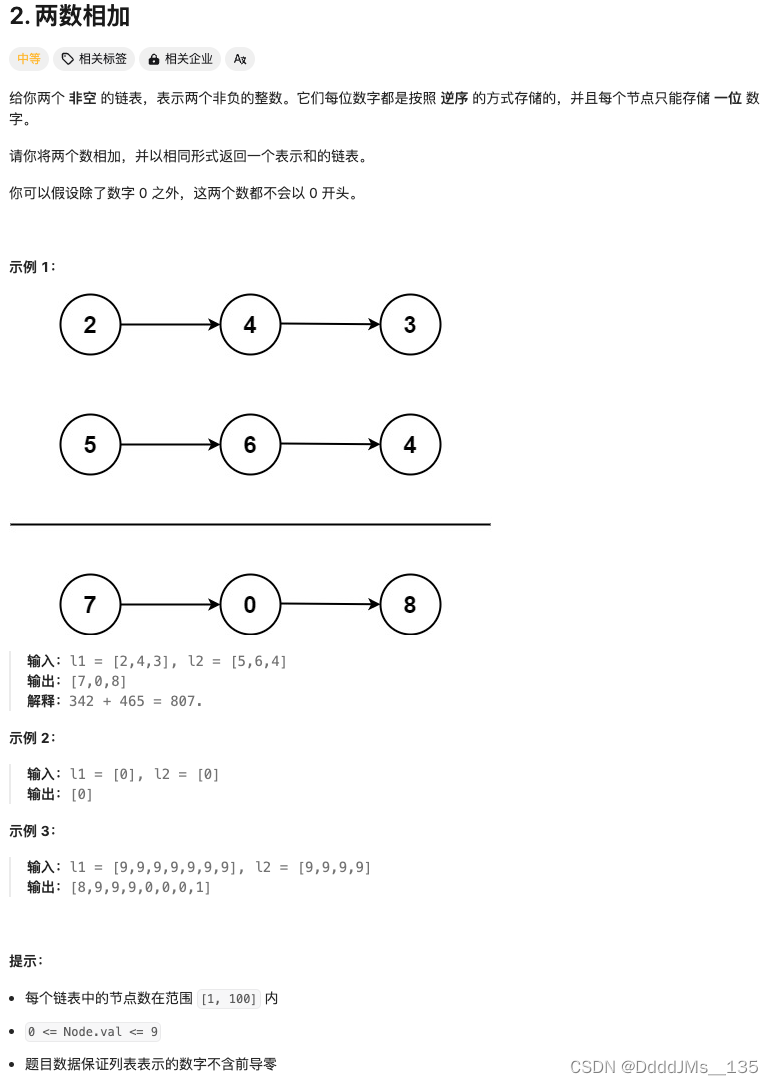
C语言 | Leetcode C语言题解之第2题两数相加
题目: 题解: struct ListNode* addTwoNumbers(struct ListNode* l1, struct ListNode* l2) {struct ListNode *head NULL, *tail NULL;int carry 0;while (l1 || l2) {int n1 l1 ? l1->val : 0;int n2 l2 ? l2->val : 0;int sum n1 n2 …...

Oracle基础
Oracle基础 Oracle,作为全球最大的数据库软件供应商,其数据库产品在企业级应用市场中占据了举足轻重的地位。Oracle数据库以高性能、高可用性、高安全性以及强大的数据管理能力赢得了广泛认可。本文旨在为读者提供Oracle数据库的基础知识,帮…...
从0到1实现RPC | 04 负载均衡和静态注册中心
一、Router的定义 Router路由用于预筛选,Dubbo有这样的设计,SpringCloud没有。 二、LoadBanlancer定义 负载均衡器:默认取第一个 当前支持随机和轮询两种负载均衡器。 随机:从所有provider中随机选择一个。 轮询:每…...

卷积神经网络-池化层
卷积神经网络-池化层 池化层(Pooling Layer)是深度学习神经网络中的一个重要组成部分,通常用于减少特征图的空间尺寸,从而降低模型复杂度和计算量,同时还能增强模型的不变性和鲁棒性。 池化操作通常在卷积神经网络&am…...

【干货集】C# XmlHelper帮助类操作Xml文档的通用方法汇总
前言 该篇文章主要总结的是自己平时工作中使用频率比较高的Xml文档操作的一些常用方法和收集网上写的比较好的一些通用Xml文档操作的方法(主要包括Xml序列化和反序列化,Xml文件读取,Xml文档节点内容增删改的一些通过方法)。当然可…...
)
别再手动算占空比了!手把手教你用TI C2000 EPWM互补输出驱动电机(附死区配置避坑指南)
从零到精通的TI C2000 EPWM电机驱动实战:死区配置与波形调试全解析 在电机控制领域,精确的PWM信号生成直接决定了系统性能和可靠性。传统的手动计算占空比方式不仅效率低下,还容易引入人为误差。TI C2000系列DSP内置的增强型PWM模块ÿ…...

MyBatisPlus SQL解析踩坑记:JSqlParser版本升级的那些事儿
MyBatisPlus SQL解析踩坑记:JSqlParser版本升级的那些事儿 当你在深夜被生产环境的报警短信惊醒,发现原本运行良好的SQL查询突然报出Encountered unexpected token错误时,很可能正遭遇JSqlParser版本升级带来的"惊喜"。作为MyBatis…...

SillyTavern角色创建完全指南:从入门到精通
SillyTavern角色创建完全指南:从入门到精通 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 一、基础认知:揭开角色系统的面纱 1.1 什么是角色系统? 想…...

80+款Android UI模板深度解析:从零到一构建专业级应用界面的实战指南
80款Android UI模板深度解析:从零到一构建专业级应用界面的实战指南 【免费下载链接】Android-ui-templates Download free android app templates free and paid. 项目地址: https://gitcode.com/gh_mirrors/an/Android-ui-templates 在当今移动应用开发领域…...

开源工具权限重置指南:跨平台AI编程助手试用限制解决方案
开源工具权限重置指南:跨平台AI编程助手试用限制解决方案 【免费下载链接】go-cursor-help 解决Cursor在免费订阅期间出现以下提示的问题: Youve reached your trial request limit. / Too many free trial accounts used on this machine. Please upgrade to pro. …...

Phi-3 Forest Lab快速部署:使用Podman替代Docker的无root安全运行方案
Phi-3 Forest Lab快速部署:使用Podman替代Docker的无root安全运行方案 1. 项目概述 Phi-3 Forest Lab是一个基于微软Phi-3 Mini 128K Instruct模型构建的极简主义AI对话终端,旨在为用户提供一个静谧、高效且富有逻辑的思考空间。与传统AI终端不同&…...

从零开始:使用mmsegmentation训练自定义数据集的全流程指南
1. 环境准备与安装指南 第一次接触mmsegmentation时,最头疼的就是环境配置。记得我刚开始用的时候,光是解决CUDA和PyTorch版本兼容问题就折腾了一整天。现在把踩过的坑都总结出来,让你10分钟搞定环境搭建。 核心依赖清单: Python …...

智能协作:让快马AI成为你的算法优化顾问,自动分析并改进代码
今天想和大家分享一个特别实用的开发技巧——如何用AI辅助优化算法代码。作为一个经常和动态规划算法打交道的开发者,我发现InsCode(快马)平台的AI功能真的能帮我们省去很多重复劳动。 先说说我最近遇到的一个实际问题:经典的0-1背包问题。虽然动态规划…...

如何用G-Helper智能恢复ROG笔记本色彩显示:终极解决方案
如何用G-Helper智能恢复ROG笔记本色彩显示:终极解决方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项目地…...

Speech Seaco Paraformer问题解决:识别不准?试试热词功能提升准确率
Speech Seaco Paraformer问题解决:识别不准?试试热词功能提升准确率 1. 语音识别不准的常见困扰 语音识别技术在日常工作和生活中应用越来越广泛,但很多用户在使用过程中都会遇到一个共同问题:识别结果不准确。特别是当录音内容…...