Python爬虫实战:使用Requests和BeautifulSoup爬取网页内容
标题:Python爬虫实战:使用Requests和BeautifulSoup爬取网页内容
Python爬虫技术是网络爬虫中的一种,它可以从互联网上抓取各种网页信息,如文本、图片、视频等,并将它们存储在本地数据库中。Python语言具有简单易学、语法简洁、代码规范、开发效率高等优点,成为了爬虫开发中广泛使用的一种语言。本文将介绍使用Python的Requests和BeautifulSoup库实现爬取网页内容的具体实现。
1.安装和导入相关库
在使用Requests和BeautifulSoup库进行爬虫开发之前,需要安装并导入相关库。可以通过以下代码来实现:
import requests
from bs4 import BeautifulSoup2.发送HTTP请求获取网页内容
在Python爬虫中,首先需要向目标网站发送HTTP请求,以获取网页内容。这里我们使用Requests库发送HTTP请求,并使用BeautifulSoup库来解析网页内容。
url = 'https://www.example.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')在上面的代码中,我们指定了目标网站的URL,并设置了请求头部信息。其中,User-Agent用于伪装请求,避免被服务器禁止访问。
3.解析网页内容
BeautifulSoup库提供了一种方便的方法来解析网页内容。我们可以使用BeautifulSoup库提供的标签选择器和属性选择器来提取我们需要的内容。
title = soup.select('title')[0].get_text()
content = soup.select('div[class="content"]')[0].get_text()在上面的代码中,我们使用了标签选择器和属性选择器来选择网页中的标题和正文内容。其中,[0]表示选择第一个匹配的元素,get_text()方法用于提取元素的文本内容。
4.存储网页内容
最后,我们将爬取到的网页内容存储到本地文件或数据库中。这里我们以将爬取到的内容保存为TXT文件为例。
with open('example.txt', 'w', encoding='utf-8') as f:f.write(title + '\n')f.write(content)在上面的代码中,我们使用Python的with语句打开文件,并将爬取到的标题和正文内容写入到文件中。
总结
# 导入相关库
import requests
from bs4 import BeautifulSoup# 指定目标网站的URL,并设置请求头部信息
url = 'https://www.example.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}# 发送HTTP请求并获取网页内容
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')# 解析网页内容
title = soup.select('title')[0].get_text()
content = soup.select('div[class="content"]')[0].get_text()# 存储网页内容
with open('example.txt', 'w', encoding='utf-8') as f:f.write(title + '\n')f.write(content)本文介绍了Python爬虫技术中使用Requests和BeautifulSoup库实现爬取网页内容的具体步骤。通过学习本文,读者可以了解到Python爬虫开发的基本流程,并了解到如何使用Python的相关库来实现
相关文章:

Python爬虫实战:使用Requests和BeautifulSoup爬取网页内容
标题:Python爬虫实战:使用Requests和BeautifulSoup爬取网页内容 Python爬虫技术是网络爬虫中的一种,它可以从互联网上抓取各种网页信息,如文本、图片、视频等,并将它们存储在本地数据库中。Python语言具有简单易学、语…...

质量指标——什么是增量覆盖率?它有啥用途?
目录 引言 什么是增量覆盖率 增量覆盖率有啥用途 1、对不同角色同学的用途 2、对不同规模的业务需求的用途 增量覆盖率的适用人员 增量覆盖率不太适用的情况 引言 有些质量团队,有时会拿「增量覆盖率」做出测试的准出卡点。 但在实际的使用过程中,…...
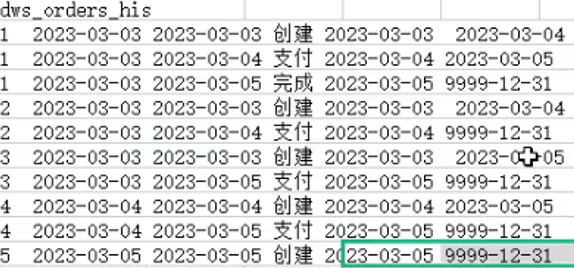
Hive---拉链表
拉链表 文章目录拉链表定义用途案例全量流程增量流程合并过程第一步第二步第三步案例二(含分区)创建外部表orders增量分区表历史记录表定义 拉链表是一种数据模型,主要是针对数据仓库设计中表存储数据的方式而定义的,顾名思义&am…...
日常文档标题级别规范
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注…...

C++学习记录——십이 vector
文章目录1、vector介绍和使用2、vector模拟实现insert和erase和迭代器失效补齐其他函数深浅拷贝难点思考1、vector介绍和使用 vector可以管理任意类型的数组,是一个表示可变大小数组的序列容器。 通过vector文档来看它的使用。 #include <iostream> #inclu…...
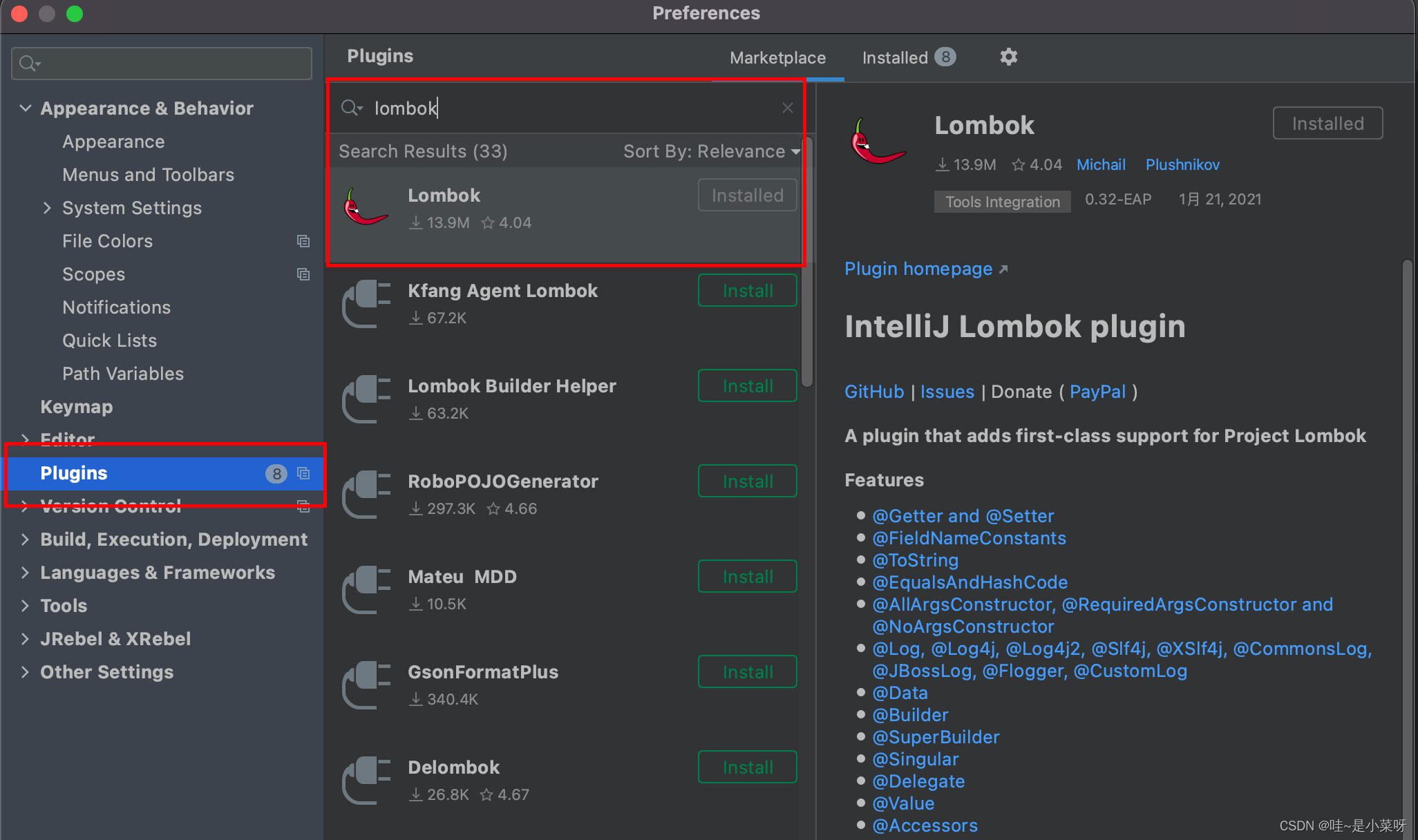
Lombok常见用法总结
目录一、下载和安装二、常见注释(一)Data(二)Getter和Setter(三)NonNull和NotNull(不常用)(四)ToString(不常用)(五&#…...
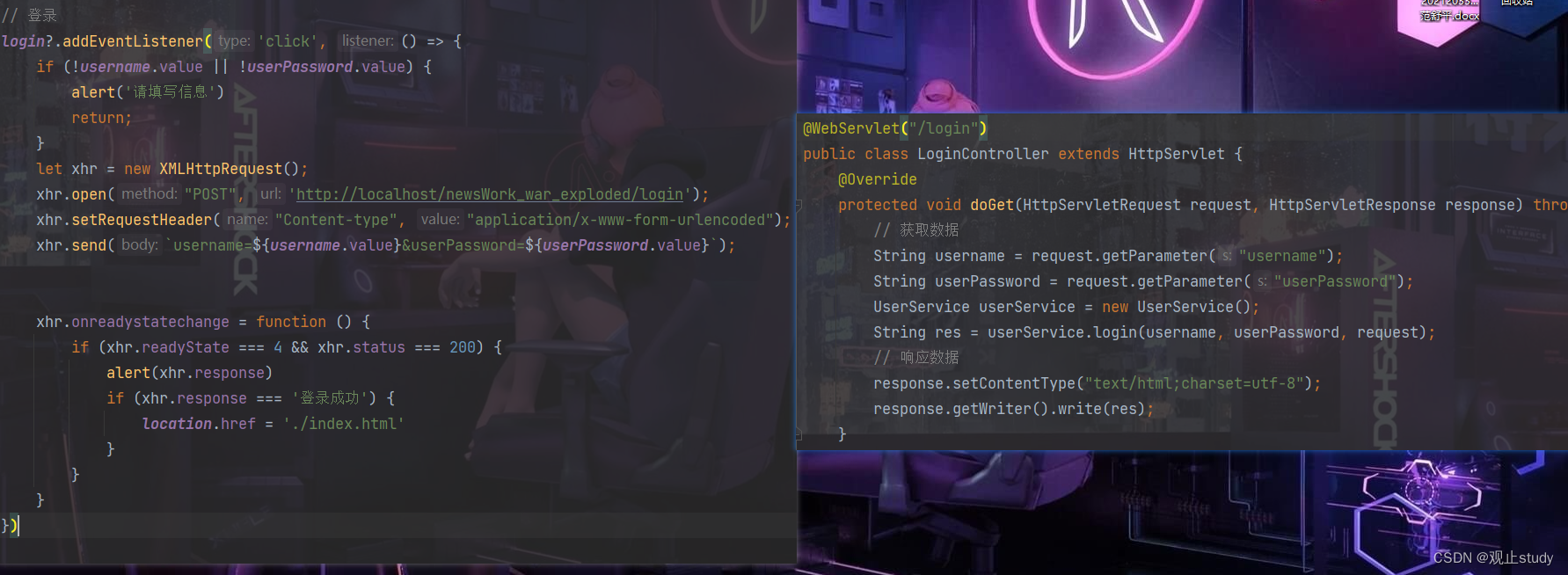
【Ajax】异步通信
一.概述 概念:AJAX(Asynchronous JavaScript And XML):异步的 JavaScript 和 XML 作用: 与服务器进行数据交换:通过AJAX可以给服务器发送请求,并获取服务器响应的数据 使用了AJAX和服务器进行通信,就可以使…...
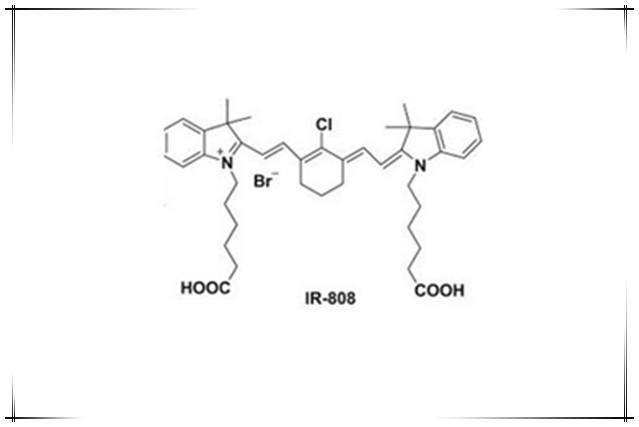
近红外吸收荧光染料IR-808,IR-808 NH2,IR-808 amine,发射808nm 性质分享
中文名称:IR-808 氨基英文名称:IR-808 NH2,IR-808 amine,IR-808-NH2规格标准:10mg,25mg,50mgCAS:N/A产品描述:IR-808,发射808nm,酯溶性染料修饰氨…...

一图来看你需要拥有那些知识储备
技术实践 数据 关系型数据 MySQLSQLServerOraclePostgrSQLDB2 大数据存储 RedisMemcacheMongoDBHBaseHive 大数据处理 Hadoop 数据报表看板 DataGearGrafanaKibanaMetaBase 消息对列 Rabbit MQRock MQActive MQKafka 大数据搜索 SolrElasticSearchLucenHive 服务提…...
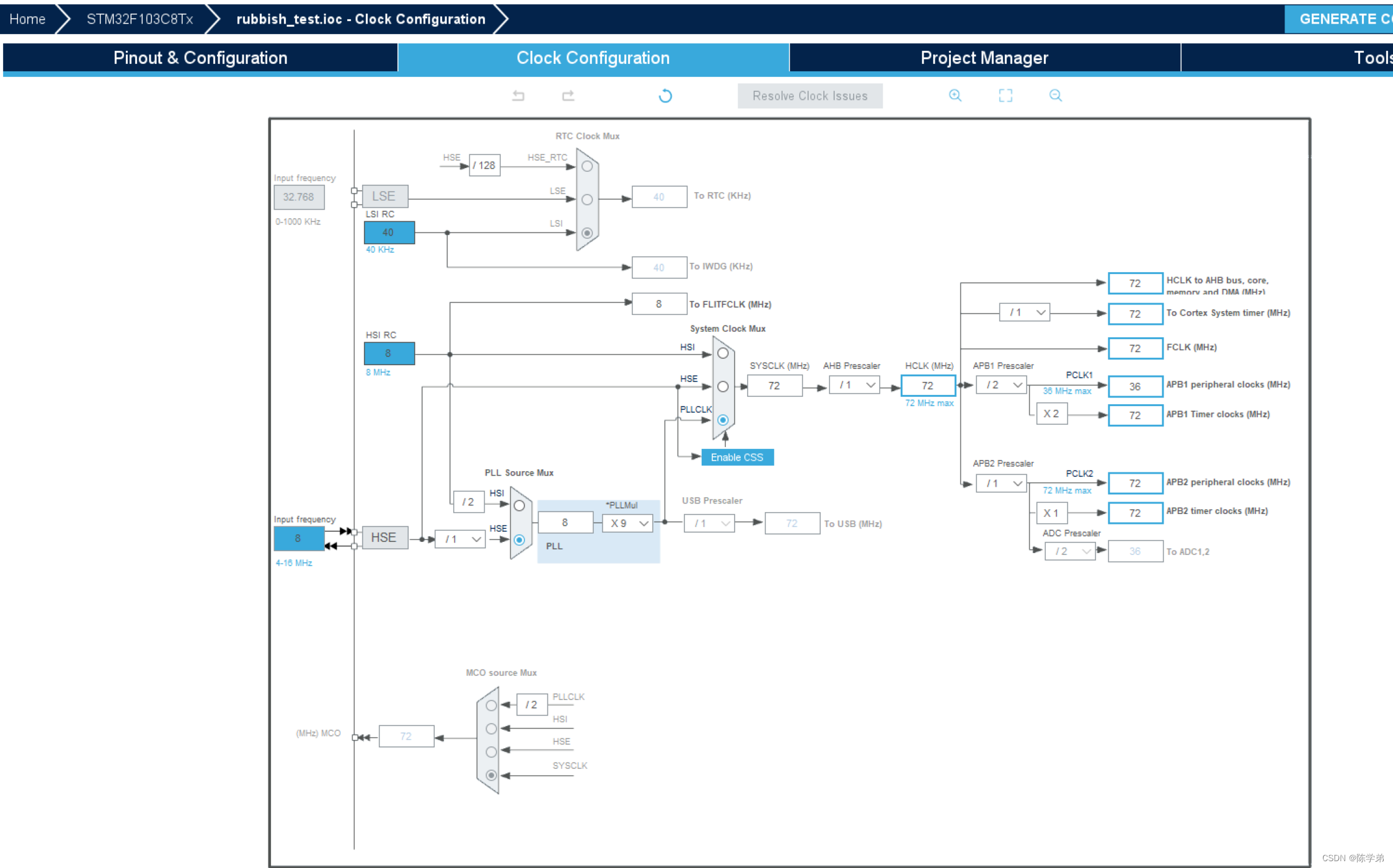
复位和时钟控制(RCC)
目录 复位 系统复位 电源复位 备份区复位 时钟控制 什么是时钟? 时钟来源 二级时钟源: 如何使用CubeMX配置时钟 复位 系统复位 当发生以下任一事件时,产生一个系统复位:1. NRST引脚上的低电平(外部复位) 2. 窗口看门狗计数终止(WWD…...

OpenWrt 专栏介绍00
文章目录OpenWrt 专栏介绍00专栏章节介绍关于联系方式OpenWrt 专栏介绍00 专栏章节介绍 本专栏主要从开发者角度,一步步深入理解OpenWrt开发流程,本专栏包含以下章节,内如如下: 01.OperWrt 环境搭建02.OperWrt 包管理系统03.Op…...

udk开发-稀里糊涂
一、EDK2简介 1.EDK2工作流 二、EDK2 Packages 1.Packages介绍 EDK2 Packages是一个容器,其中包含一组模块及模块的相关定义。每个Package是一个EDK2单元。 整个Project的源代码可以被分割成不同的Pkg。这样的设计不仅可以降低耦合性,还有利于分…...

Java之内部类
目录 一.内部类 1.什么是内部类 2.内部类存在的原因 3. 内部类的分类 4.内部类的作用 二.成员内部类 1.基本概念 2.成员内部类的注意点 1.成员内部类可以用private方法进行修饰 2.成员内部类可以直接访问外部类的私有属性 3.外部类可以通过对象访问内部类的私有属性 …...
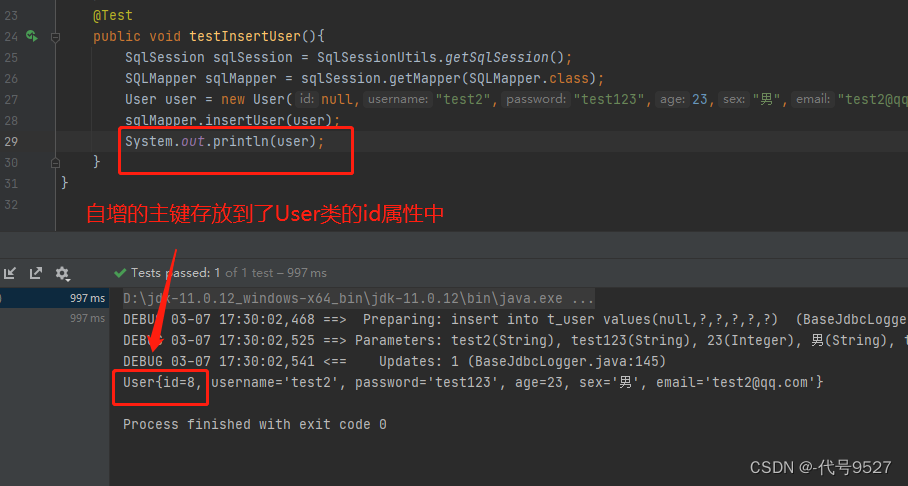
【MyBatis】篇二.MyBatis查询与特殊SQL
文章目录1、MyBatis获取参数值case1-单个字面量类型的参数case2-多个字面量类型的参数case3-map集合类型的参数case4-实体类类型的参数case5-使用Param注解命名参数总结2、MyBatis的各种查询功能case1-查询结果是一个实体类对象case2-查询结果是一个List集合case3-查询单个数据…...

CE认证机构和CE证书的分类
目前,CE认证已普遍被应用在很多行业的商品中,也是企业商品进入欧洲市场的必备安全合格认证。在船舶海工行业中,也同样普遍应用,很多时候,对于规范中没有明确认证要求的设备或材料,而船舶将来还会去欧洲水域…...

Lesson 8.2 CART 分类树的建模流程与 sklearn 评估器参数详解
文章目录一、CART 决策树的分类流程1. CART 树的基本生长过程1.1 规则评估指标选取与设置1.2 决策树备选规则创建方法1.3 挑选最佳分类规则划分数据集1.4 决策树的生长过程2. CART 树的剪枝二、CART 分类树的 Scikit-Learn 快速实现方法与评估器参数详解1. CART 分类树的 sklea…...

【Unity】程序集Assembly模块化开发
笔者按:使用Unity版本为2021.3LTS,与其他版本或有异同。请仅做参考 一、简述。 本文是笔者在学习使用Unity引擎的过程中,产学研的一个笔记。由笔者根据官方文档Unity User Manual 2021.3 (LTS)/脚本/Unity 架构/脚本编译/程序集定义相关部分结…...

马尔可夫决策过程
1. 马尔可夫决策过程 马尔可夫决策过程不过是引入"决策"的马氏过程. Pij(a)P{Xn1j∣X0,a0,X1,a1,...,Xni,an1}P{Xnn1j∣Xni,ana}\begin{split} P_{ij}(a) & P\{X_{n1} j|X_0, a_0, X_1, a_1, ..., X_n i, a_n 1\} \\ &P\{X_n{n1} j|X_n i, a_n a\} \e…...
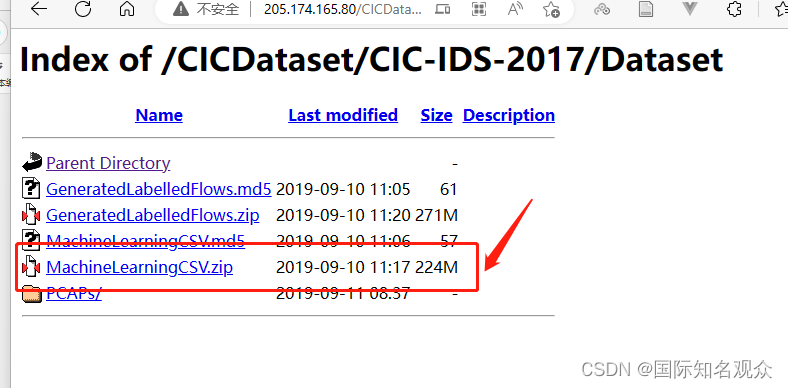
win11下载配置CIC Flowmeter环境并提取流量特征
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言一、下载CIC Flowmeter二、安装java、maven、gradle和IDEA1.java 1.82.maven3.gradle4.IDEA三、CICFlowMeter-master使用四、流量特征1.含义2.获取前言 配了一整…...
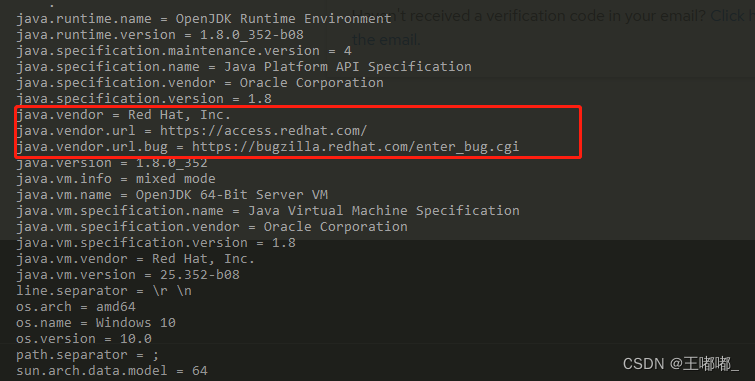
JDK如何判断自己是什么公司的
0x00 前言 因为一些事情,遇到了这样一个问题,JDK如何判断自己是什么公司编译的。因为不同的公司编译出来,涉及到是否商用收费的问题。 平时自己使用的时候,是不会考虑到JDK的编译公司是哪一个,都是直接拿起来用&#…...

管理幅度怎样设置才合理?
https://mp.weixin.qq.com/s/aoUgKUmsOUyC7wWOONMIIw...

【Midjourney Gouache风格终极指南】:20年AI绘画专家亲授7大参数黄金组合与3类易踩翻车点
更多请点击: https://intelliparadigm.com 第一章:Gouache风格的本质解构与AI绘画语境迁移 Gouache(水粉画)并非简单意义上的“不透明水彩”,其本质在于颜料颗粒的物理遮盖性、媒介乳化稳定性与干湿叠压响应的三重耦合…...

社区团购系统源码推荐:为什么越来越多团队开始关注 LikeShop 社区团购系统?
如果你最近在研究:社区团购系统源码社区团购平台搭建团长分销系统私域社区团购社区自提系统你会发现一个现象:越来越多人开始提到:“LikeShop社区团购系统”。尤其是在:生鲜团购社区零售社群团购县域电商社区便利店私域卖货这些场…...

魔兽争霸3现代兼容性终极解决方案:WarcraftHelper深度优化指南
魔兽争霸3现代兼容性终极解决方案:WarcraftHelper深度优化指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸3作为经典即时战略…...

三步彻底解决Zotero中文文献管理的三大难题:茉莉花插件完整指南
三步彻底解决Zotero中文文献管理的三大难题:茉莉花插件完整指南 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 你是否…...

告别图形界面:在Linux终端中高效管理百度网盘文件的完整指南
1. 为什么需要命令行管理百度网盘? 很多开发者都遇到过这样的场景:远程连接到Linux服务器时,需要快速上传日志文件到网盘,或者从网盘下载数据集到服务器。传统做法是先把文件下载到本地电脑,再用SFTP工具上传到服务器—…...

AI支付架构选型:Card Rails与Agent Rails的深度对比与实践指南
1. 项目概述:AI支付架构的十字路口最近在设计和落地几个AI驱动的支付系统时,我反复被一个核心的架构选择所困扰:是采用“Card Rails”还是“Agent Rails”?这不仅仅是技术选型,更是两种截然不同的产品哲学和风险控制思…...

面向密集预测任务的神经网络架构搜索:从原理到工程实践
1. 项目概述与核心价值“神经网络架构搜索在密集预测任务中的应用与优化”,这个标题听起来很学术,但背后其实是我们这些在一线搞计算机视觉、图像分割、深度估计的工程师和研究员们每天都在琢磨的“硬骨头”。简单来说,它探讨的是如何让机器自…...

2026年AGI突围:自主智能体驱动,数字生命从架构落地到自我迭代全解析
2026年,AI行业正式告别“生成式狂欢”,迈入“自主智能体(AI Agent)规模化落地元年”。Gartner将自主智能体列为年度十大战略技术趋势之首,各大科技厂商纷纷布局,从实验室概念到产业应用,自主智能…...

浏览器端微信使用指南:告别繁琐安装,开启轻量沟通新时代
浏览器端微信使用指南:告别繁琐安装,开启轻量沟通新时代 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为微信PC版的庞大…...