RDD算子(四)、血缘关系、持久化
1. foreach
分布式遍历每一个元素,调用指定函数
val rdd = sc.makeRDD(List(1, 2, 3, 4))
rdd.foreach(println)
结果是随机的,因为foreach是在每一个Executor端并发执行,所以顺序是不确定的。如果采集collect之后再调用foreach打印,则是在Driver端执行。
RDD的方法之所以叫算子,就是为了与scala集合的方法区分开来, scala集合的方法是在同一个节点执行的,而RDD的算子则是在Executor(分布式节点)执行的。从计算的角度讲,RDD算子外部的操作都是在Driver端执行,算子内部的操作都是在Executor端执行。
2. 闭包检测
class User {var age : Int = 30
}val rdd = sc.makeRDD(List(1, 2, 3, 4))
val user = new User()
rdd.foreach(num => {println("age = " + (user.age + num))
})因为foreach内部的操作是在Executor上执行的,所以在Driver上创建的user需要传递给各个Executor,如果user没有序列化,则会报错

class User extends Serializable{var age : Int = 30
}或者将User变为样例类,因为样例类在编译时会自动混入序列化特质(实现可序列化接口)
case class User {var age : Int = 30
}如果把原始集合变为空,依然会报错,这是因为RDD算子中传递的函数会包含闭包操作(匿名函数,算子内用到了算子外的数据),所以会进行闭包检测,即检查里面的变量是否序列化。
val rdd = sc.makeRDD(List[Int]())
val user = new User()
rdd.foreach(num => {println("age = " + (user.age + num))
})再看如下案例:
class Search(query:String) {def isMatch(s:String): Boolean {s.contains(query)}def getMatch1(rdd: RDD[String]): RDD[String] {rdd.filter(isMatch)}def getMatch2(rdd: RDD[String]): RDD[String] {rdd.filter(x => x.contains(query))}
}val rdd = sc.makeRDD(Array("hello world", "hello spark", "hive", "atguigu"))
val search = new Search("h")
search.getMatch1(rdd).collect().foreach(println)此时会报错Search类没有序列化,因为在rdd的filter算子内调用了query,而query作为类的构造参数,实际上是类的私有变量,isMatch方法相当于:
def isMatch(s:String): Boolean {s.contains(this.query)
}this相当于类的对象,因此需要进行闭包检测。getMatch2也有类似的问题。除了将类序列化以及改为样例类之外,还可以将query赋给方法内部的临时变量:
def getMatch2(rdd: RDD[String]): RDD[String] {val s = queryrdd.filter(x => x.contains(s))
}3. 依赖关系
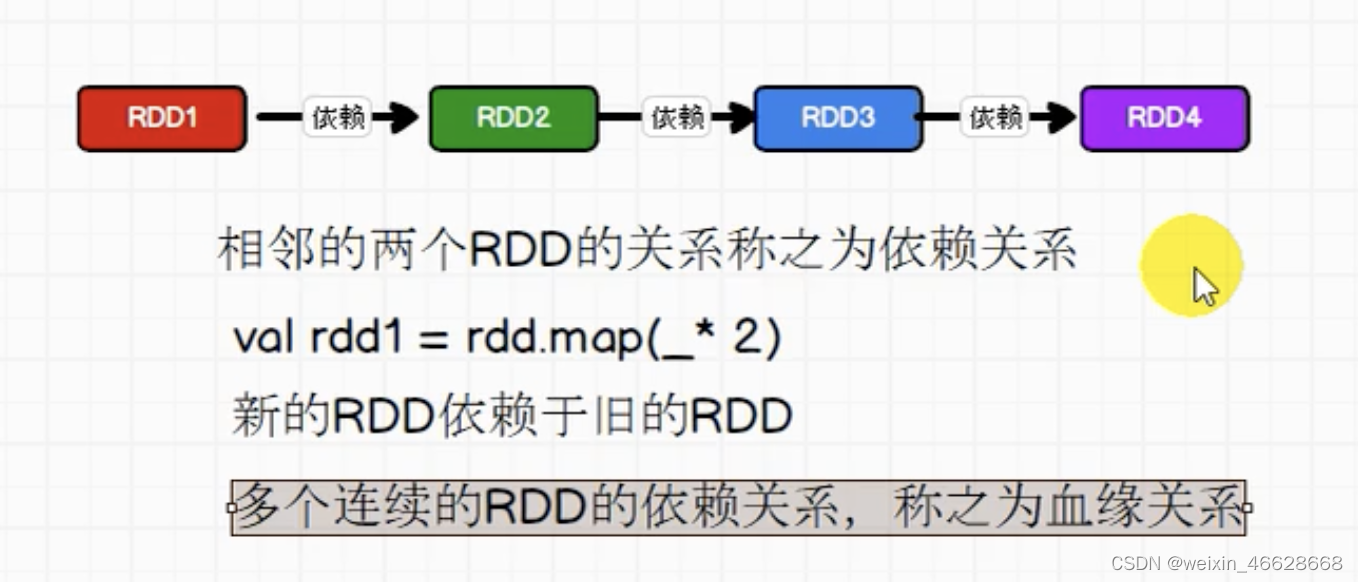
每个RDD会保存血缘关系(不会保存数据),这样提高了容错性,因为如果其中某个RDD转换到另一个RDD失败了,就可以根据血缘关系来重新读取。RDD保存依赖关系而示意图如下:
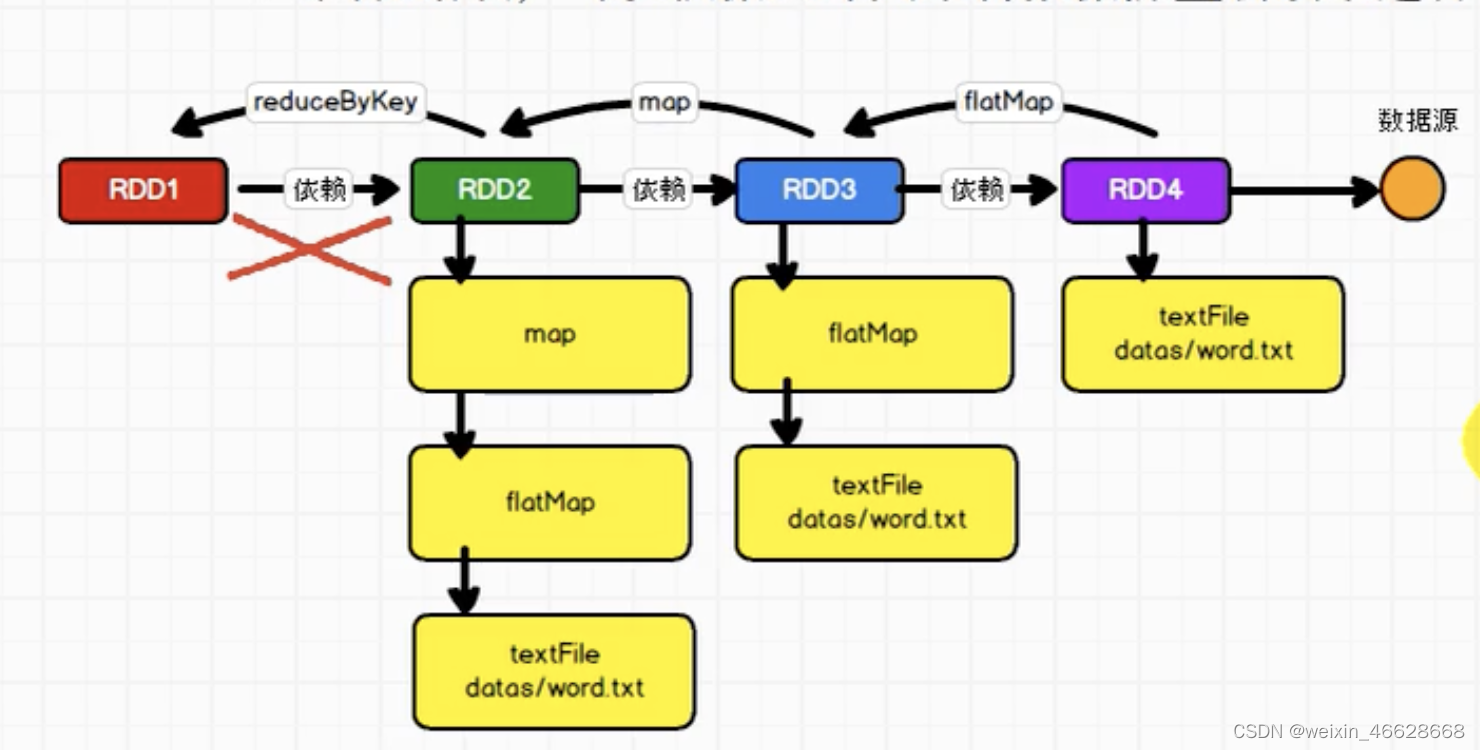
血缘关系展示代码:
val lines : RDD[String] = sc.textFile("datas")
println(lines.toDebugString)
println("******************")val words : RDD[String] = lines.flatMap(_.split(" "))
println(words.toDebugString)
println("******************")val wordToOne = words.map(word=>(word, 1))
println(wordToOne.toDebugString)
println("******************")val wordToSum : RDD[(String, Int] = wordToOne.reduceByKey(_+_)
println(wordToSum.toDebugString)
println("******************")



查看依赖关系只需直接将代码中的toDebugString改为dependencies即可
val lines : RDD[String] = sc.textFile("datas")
println(lines.dependencies)
println("******************")val words : RDD[String] = lines.flatMap(_.split(" "))
println(words.dependencies)
println("******************")val wordToOne = words.map(word=>(word, 1))
println(wordToOne.dependencies)
println("******************")val wordToSum : RDD[(String, Int] = wordToOne.reduceByKey(_+_)
println(wordToSum.dependencies)
println("******************")


一对一的依赖关系表示新的RDD的一个分区的数据来源于旧的RDD的一个分区的数据,也叫窄依赖,而Shuffle依赖关系表示新的RDD的一个分区的数据来源于旧的RDD的多个分区的数据,也叫宽依赖。
4. 阶段和任务划分
窄依赖中,分区有多少个,就有多少个任务,只有一个阶段;宽依赖中,有两个阶段,每个阶段的任务数等于分区数。
RDD阶段由有向无环图(DAG)表示

Application->Job->Stage->Task每一个层级是1对n的关系。
每个Application中可能会提交多个作业,一个作业会划分为多个阶段(阶段数=宽依赖个数+1),一个阶段可能因为多个分区而包含多个任务,一个阶段中的任务数=最后一个RDD的分区数。
5. cache和persist
如果对于同一份数据源,想做多个不同的功能(比如统计单词数以及根据单词分组),这些不同的功能在实现过程中有很多重复的步骤(比如很多相同的RDD转换),此时可能会引入性能问题。虽然看起来RDD转换的过程复用了,但是RDD不存储数据,只有逻辑,所以最终的行为算子会从头开始再读取相同的数据,比如下面代码:
val data : RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark"))val flatRDD : RDD[String] = data.flatMap(_.split(" "))val mapRDD = flatRDD.map(word=>{println("@@@@@@@@@@@@@@@")(word, 1)
})val reduceRDD : RDD[(String, Int)] = mapRDD.reduceByKey(_+_)reduceRDD.collect.foreach(println)println("****************")val groupRDD = mapRDD.groupByKey()groupRDD.collect.foreach(println)
可以看到,在一行*上下,@都执行了,说明数据从头开始读取,从最开始的RDD再次执行。
为了解决这种性能问题,可以对mapRDD里的数据进行缓存,要么缓存在内存中,要么缓存在磁盘中,得看具体情况,这就是RDD的持久化操作。使用cache方法缓存在内存中:
val data : RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark"))val flatRDD : RDD[String] = data.flatMap(_.split(" "))val mapRDD = flatRDD.map(word=>{println("@@@@@@@@@@@@@@@")(word, 1)
})mapRDD.cache()val reduceRDD : RDD[(String, Int)] = mapRDD.reduceByKey(_+_)reduceRDD.collect.foreach(println)println("****************")val groupRDD = mapRDD.groupByKey()groupRDD.collect.foreach(println)
放在内存中可能不安全,使用persist方法缓存在磁盘中:
val data : RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark"))val flatRDD : RDD[String] = data.flatMap(_.split(" "))val mapRDD = flatRDD.map(word=>{println("@@@@@@@@@@@@@@@")(word, 1)
})mapRDD.persist(StorageLevel.DISK_ONLY)val reduceRDD : RDD[(String, Int)] = mapRDD.reduceByKey(_+_)reduceRDD.collect.foreach(println)println("****************")val groupRDD = mapRDD.groupByKey()groupRDD.collect.foreach(println)注意:持久化操作也是等到行动算子触发才会真正执行。持久化操作不一定都是为了重用才引入的,有些情况下,前面一些RDD转换操作耗时很长或者数据很重要的场合,也可以进行持久化操作,这样一旦中间出了问题,重新执行任务不至于再执行之前耗时很长的操作。
除了以上的cache和persist方法,还可以使用检查点(checkpoint)的方法进行持久化操作。checkpoint需要落盘,因此需要指定存储路径,之前的persist方法也要落盘,只不过它存储在临时路径,任务执行完就会删除,而checkpoint是永久化存储。
sc.setCheckPointDir("cp")val data : RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark"))val flatRDD : RDD[String] = data.flatMap(_.split(" "))val mapRDD = flatRDD.map(word=>{println("@@@@@@@@@@@@@@@")(word, 1)
})mapRDD.checkpoint()val reduceRDD : RDD[(String, Int)] = mapRDD.reduceByKey(_+_)reduceRDD.collect.foreach(println)println("****************")val groupRDD = mapRDD.groupByKey()groupRDD.collect.foreach(println)但是checkpoint会单独再开启一个作业,因此效率可能更低。但是与cache联合执行,即先cache,再checkpoint,就不会开启新的作业。
另外,使用cache方法会改变RDD的血缘关系:
val data : RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark"))val flatRDD : RDD[String] = data.flatMap(_.split(" "))val mapRDD = flatRDD.map(word=>{println("@@@@@@@@@@@@@@@")(word, 1)
})mapRDD.checkpoint()
println(mapRDD.toDebugString)val reduceRDD : RDD[(String, Int)] = mapRDD.reduceByKey(_+_)reduceRDD.collect.foreach(println)println("****************")
println(mapRDD.toDebugString)

可以看到,cache方法(其实persis方法也会) 在血缘关系中添加新的依赖(原来的依赖还保留)。但是checkpoint方法会改变原来的血缘关系,建立新的血缘关系(等同于数据源变了):
sc.setCheckPointDir("cp")val data : RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark"))val flatRDD : RDD[String] = data.flatMap(_.split(" "))val mapRDD = flatRDD.map(word=>{println("@@@@@@@@@@@@@@@")(word, 1)
})mapRDD.checkpoint()
println(mapRDD.toDebugString)val reduceRDD : RDD[(String, Int)] = mapRDD.reduceByKey(_+_)reduceRDD.collect.foreach(println)println("****************")
println(mapRDD.toDebugString)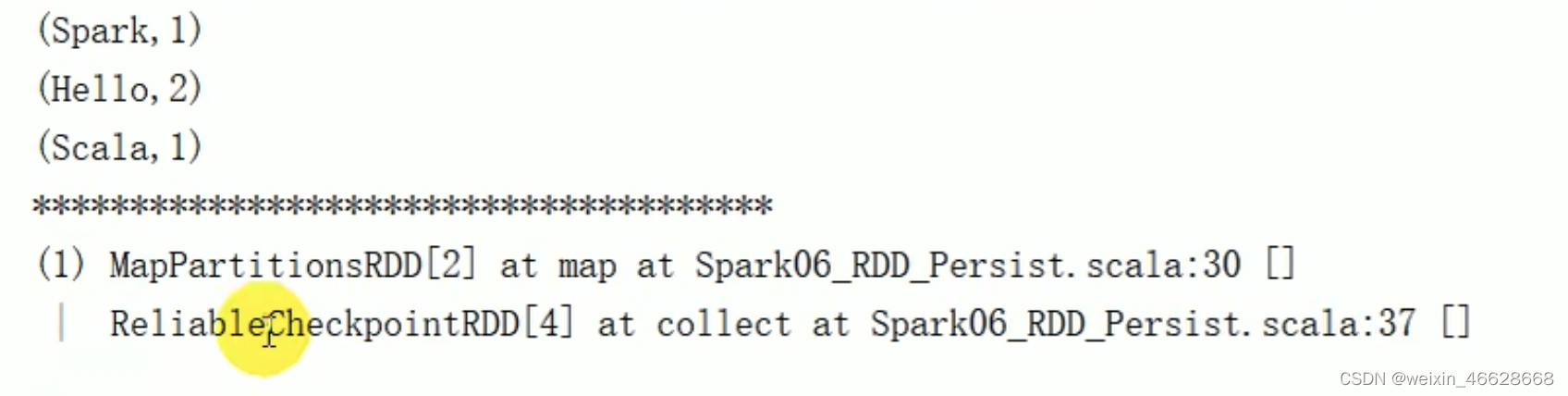
6. 自定义分区器
class MyPartitioner extends Partitioner {override def numPartitions : Int = n //自定义,可以写死override def getPartition(key : Any) : Int = {key match {case "xxx" => 0case _ => 1}}}分区器传给RDD:
val partitionRDD = rdd.partitionBy(new MyPartitioner)
相关文章:
RDD算子(四)、血缘关系、持久化
1. foreach 分布式遍历每一个元素,调用指定函数 val rdd sc.makeRDD(List(1, 2, 3, 4)) rdd.foreach(println) 结果是随机的,因为foreach是在每一个Executor端并发执行,所以顺序是不确定的。如果采集collect之后再调用foreach打印…...
51之定时器与中断系统
目录 1.定时器与中断系统简介 1.1中断系统 1.2定时器 1.2.1定时器简介 1.2.2定时器大致原理及其配置 1.2.3定时器所需的所有配置总介 2.定时器0实现LED闪烁 3.使用软件生成定时器初始化程序 1.定时器与中断系统简介 1.1中断系统 首先,我们需要来了解一下什么…...

C语言中的内存函数
相比于内存函数,字符串函数和字符函数是对字符串和字符进行操作,内存函数是对内存进行操的。下面跟大家分享我学到的几个内存函数。 memcpy函数 void* memcpy(void* dest, const void* sour, size_t num); dest是目标地址,sour要拷贝的源地…...
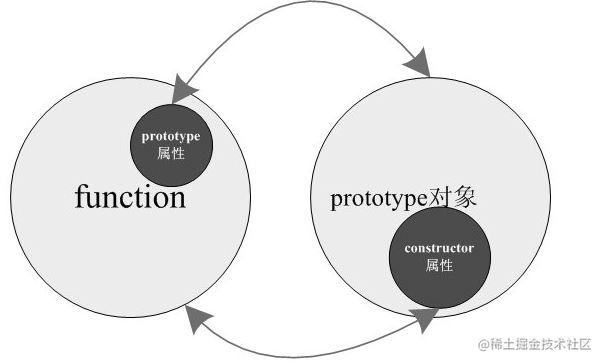
JS继承与原型、原型链
在 JavaScript 中,继承是实现代码复用和构建对象关系的重要概念。本文将讨论原型链继承、构造函数继承以及组合继承等几种常见的继承方式,并提供相应的示例代码,并分析它们的特点、优缺点以及适用场景。 在开始讲解 JavaScript 的继承方式之…...

C#基础知识总结
C语言、C和C#的区别 ✔ 面向对象编程(OOP): C 是一种过程化的编程语言,它不直接支持面向对象编程。然而,C 是一种支持 OOP 的 C 的超集,它引入了类、对象、继承、多态等概念。C# 是完全面向对象的ÿ…...

机器学习模型——决策树
决策树的定义: 决策树利用树形数据结构来展示决策规则和分类结果,它是一种归纳学习算法,可以将复杂数据转化为可以预测未知数据的模型。每一条从根节点到叶节点的路径都代表一条决策规则。 决策树内的一些重要名词: 信息熵&am…...

【HTML】制作一个简单的三角形动态图形
目录 前言 开始 HTML部分 CSS部分 效果图 总结 前言 无需多言,本文将详细介绍一段HTML和CSS代码,具体内容如下: 开始 首先新建文件夹,创建两个文本文档,其中HTML的文件名改为[index.html],CSS的文件名…...
)
Acwing.504 转圈游戏(带取余的快速幂)
题目 n个小伙伴(编号从 0到 n−1)围坐一圈玩游戏。 按照顺时针方向给 n个位置编号,从 0到 n−1。 最初,第 0号小伙伴在第 0号位置,第 1号小伙伴在第 1号位置,…,依此类推。 游戏规…...

pair作为unordered_map的key报错
问题 pair作为unordered_map的key报错,编译时会报错 原因 因为pair没有哈希函数 解决方法 定义哈希函数 template <typename T> inline void hash_combine(std::size_t &seed, const T &val) {seed ^ std::hash<T>()(val) 0x9e3779b9 (…...
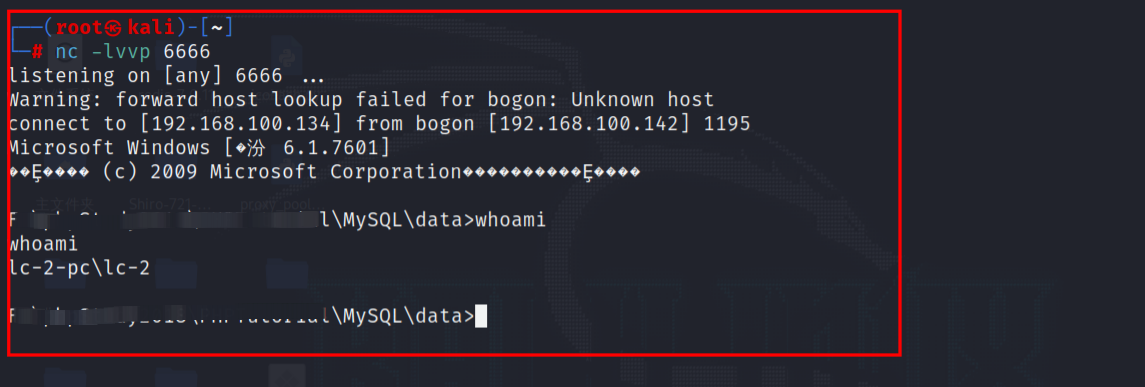
Windows提权—数据库提权-mysql提权mssql提权Oracle数据库提权
目录 Windows 提权—数据库提权一、mysql提权1.1 udf提权1.1.2 操作方法一 、MSF自动化--UDF提权--漏洞利用1.1.3 操作方法二、 手工导出sqlmap中的dll1.1.4 操作方法三、 moon.php大马利用 1.2 mof提权1.3 启动项提权1.4 反弹shell 二、MSSQL提权MSSQL提权方法1.使用xp_cmdshe…...

为什么android创建Fragment推荐用newInstance
FullScreenDialogFragment使用newInstance方法不是因为它是一个单例,而是因为这是创建DialogFragment实例并同时提供参数的一种标准模式。这种模式通常称为静态工厂方法模式,在Android开发中被广泛使用,尤其是用于Fragment的实例化。 newIns…...

MyBatis的xml实现方式
1、该项目引入的依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.o…...

大模型prompt技巧——思维链(Chain-of-Thought)
1、Zero-shot、One-shot、Few-shot 与fintune prompt的时候给出例子答案,然后再让模型回答。 2、zero-shot-CoT “Let’s think step by step”有奇迹效果 3、多数投票提高CoT性能——自洽性(Self-consistency) 多个思维链,然后取…...
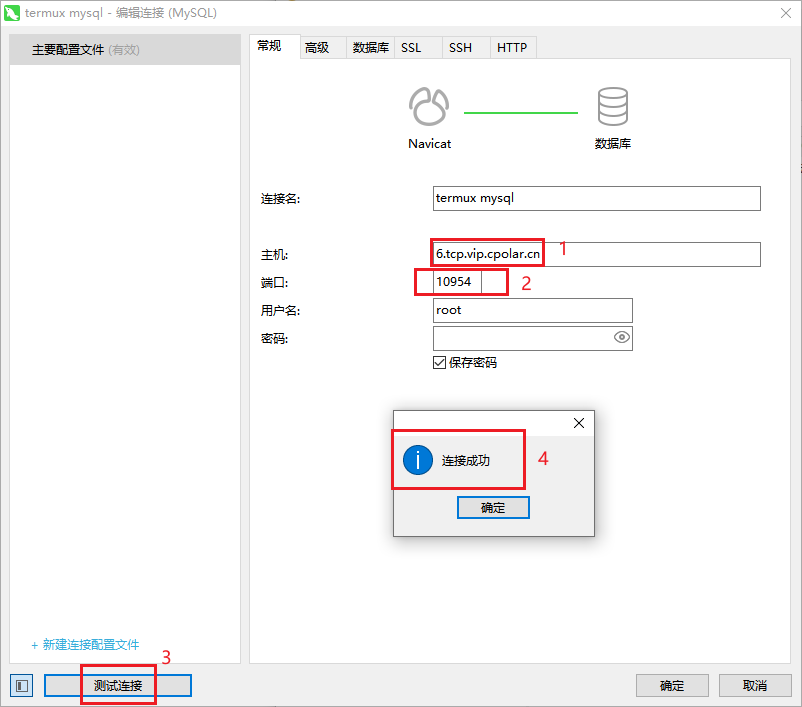
内网穿透的应用-如何在Android Termux上部署MySQL数据库并实现无公网IP远程访问
文章目录 前言1.安装MariaDB2.安装cpolar内网穿透工具3. 创建安全隧道映射mysql4. 公网远程连接5. 固定远程连接地址 前言 Android作为移动设备,尽管最初并非设计为服务器,但是随着技术的进步我们可以将Android配置为生产力工具,变成一个随身…...

面试算法-133-区间子数组个数
题目 给你一个整数数组 nums 和两个整数:left 及 right 。找出 nums 中连续、非空且其中最大元素在范围 [left, right] 内的子数组,并返回满足条件的子数组的个数。 生成的测试用例保证结果符合 32-bit 整数范围。 示例 1: 输入ÿ…...
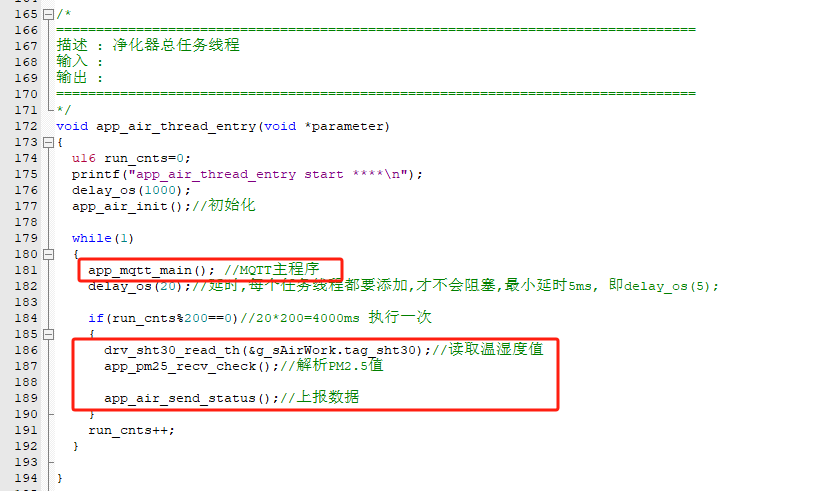
物联网实战--入门篇之(八)嵌入式-空气净化器
目录 一、风扇调速 二、通讯协议 三、净化器运行逻辑 一、风扇调速 单片机是不能直接驱动电机的,因为主芯片的驱动电流比较小(50mA左右),他们之间正常还要有个电机驱动器,常用的有TB6612、L298和L9110等,目前项目用的这个电机它…...

macOS上QT打开麦克风和摄像头的权限问题
同样的代码在Windows上可以轻松操作麦克风和摄像头,特别是用QT这种跨平台的框架。但是对macOS这种权限要求完善的系统还需要进行一些配置,那就是增加Info.plist属性配置文件。如果是之前的早期5.x版本的QTCreator因为使用的是qmake构建系统,估…...

鸿蒙手机cordova-plugin-camera不能拍照和图片不显示问题
鸿蒙手机cordova-plugin-camera不能拍照和图片不显示问题 一、运行环境 1、硬件 手机型号:NOVA 7 系统:HarmonyOS版本 4.0.0 2、软件 android SDK platforms:14.0(API Level 34)、13.0(API Level 33) SDK Build-T…...
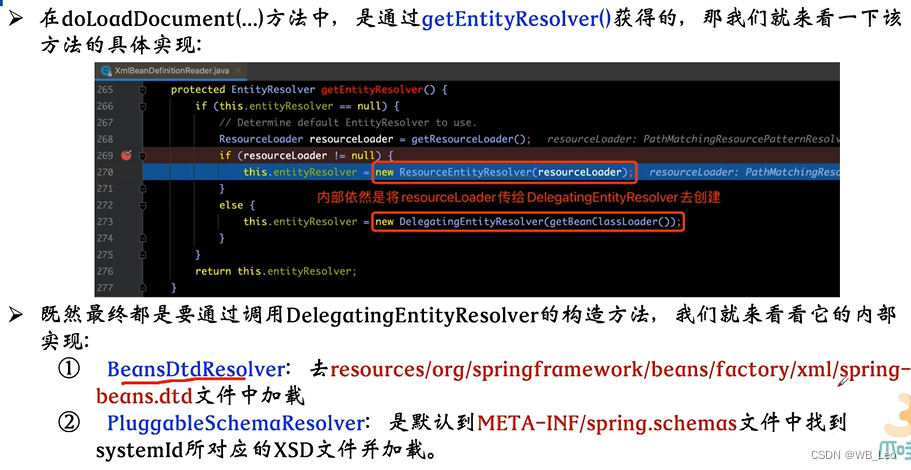
Spring源码解析上
spring源码解析 整体架构 defaultListableBeanFactory xmlBeanDefinitionReader 创建XmlBeanFactory 对资源文件进行加载–Resource 利用LoadBeandefinitions(resource)方法加载配置中的bean loadBeandefinitions加载步骤 doLoadBeanDefinition xml配置模式 validationMode 获…...

第九题:最大间隙
题目描述 给定一个序列 a1,a2,⋯ ,an。其中 a1≤a2≤⋯≤an。 相邻两个数之间的差(后一个数减前一个数)称为它们的间隙。 请问序列中最大的间隙值是多少? 输入描述 输入的第一行包含一个整数 n,表示序列的长度。 第二行包含…...

避坑指南:Double DQN和Dueling DQN在TensorFlow 2.x中的5个常见实现错误
Double DQN与Dueling DQN在TensorFlow 2.x中的五大工程陷阱与解决方案 当你在深夜调试强化学习模型时,是否遇到过这种情况:训练曲线像过山车一样剧烈波动,明明采用了Double DQN或Dueling DQN这些改进算法,效果却比基础DQN还要差&a…...
)
告别云端推理:手把手教你用Vivado HLS在AX7350开发板上部署YOLOv3(附完整工程)
从零部署YOLOv3到AX7350开发板:FPGA加速实战全流程解析 在边缘计算领域,FPGA因其低延迟、高能效和可重构特性,成为深度学习模型部署的热门选择。本文将带您完成YOLOv3目标检测模型在AX7350开发板上的完整部署流程,从环境准备到最终…...

老牌CMS的隐痛:从DedeCMS漏洞看开源系统会员模块的安全设计误区
DedeCMS会员模块漏洞剖析:开源系统安全设计的深层反思 当一款拥有百万级安装量的老牌CMS系统曝出前台任意密码修改漏洞时,我们看到的不仅是一个具体的技术缺陷,更是开源项目在安全架构设计上的系统性隐忧。2018年那场影响广泛的DedeCMS漏洞事…...
两个月搞定)
别再到处找模板了!我用这套软著申请材料(含用户手册+源代码模板)两个月搞定
两个月高效拿下软著:零基础开发者的材料准备实战指南 第一次提交软著申请时,我盯着官网模糊的材料要求整整发呆了半小时——"用户手册需图文并茂"到底要多详细?"源代码前30页后30页"该怎么截取?连续三个晚上搜…...

Mermaid在线编辑器完整指南:3步制作专业图表零基础入门
Mermaid在线编辑器完整指南:3步制作专业图表零基础入门 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-edito…...

4 种可靠的 OPPO 手机联系人备份到电脑的方法
OPPO 手机的全球出货量常年位居前五,足以见得它已经获得了越来越多用户的认可。对于年轻群体而言,入手一款高性价比的 OPPO Reno4 SE 这类机型是非常不错的选择。但日常使用中,误操作、进水等意外都可能导致数据丢失,为了避免这类…...

从.bib到.bbl:手把手教你搞定LaTeX参考文献的完整流程
从.bib到.bbl:手把手教你搞定LaTeX参考文献的完整流程 如果你曾被LaTeX的参考文献格式折磨得焦头烂额,这篇文章就是为你准备的。我们将从零开始,完整走一遍从文献管理到最终PDF生成的每个步骤,特别关注那些让新手困惑的.bib、.bbl…...

比较好的金线包封胶制造商推荐几家
嘿,朋友们!在半导体封装领域,金线包封胶就像是芯片的“贴身保镖”,保护着纤细的金线,让芯片能够稳定工作。今天咱们就来聊聊比较好的金线包封胶制造商,看看哪家更值得你选择。一、东莞市汉思新材料科技有限…...

acjscsdbhvusfd
一、yolo v1是什么? YOLO(You Only Look Once)算法 是一种目标检测算法,是经典的one-stage方法。YOLO v1 开创了单阶段目标检测的先河,其简洁的架构 和高效的推理为后续版本奠定了基础。尽管存在小目标检测和定位精度的…...

雷电模拟器装Magisk后,自带的文件管理器为啥打不开/data?用MT管理器一招搞定
雷电模拟器Magisk环境下文件管理器的权限困局与实战解决方案 当你在雷电模拟器中成功安装Magisk后,可能会遇到一个令人困惑的现象:原本可以自由访问系统目录的自带文件管理器,突然对/data和/system等关键路径"视而不见"。这并非模拟…...