prompt 工程案例
目录
prompt 工程是什么?
案例
vllm 推理加速框架
prompt 工程是什么?
prompt:提示词,也就是我们使用网页版输入给大模型的内容就叫 prompt,那什么是 prompt 工程呢?
简单理解其实就是利用编写的 prompt 去让大模型完成我们想要完成的任务,一般网页版本的都是多轮对话,通过多轮对话完成想要实现的事情也是一种 prompt 的使用;
另外一种是在实际业务中的使用,实际业务中到底怎么使用 prompt 呢?
prompt 工程 = prompt + 算法,这里的算法并不是指什么高升算法,是指通过编程解析大模型的输出,以及结合一些工具预处理文本这方面的编程代码。
prompt 入门门槛我觉得比较低,网上随便找资料大概都知道编写模版套路,但效果得结合实际业务情况调优好几天,有些还得通过编程进行辅助,比如预处理工具,提取地名啥的,匹配标签啥的,再去输入给大模型。
总结来说入门低,但要想在业务中用好,也没那么容易。
案例
我找了一个案例来说明下完整的 prompt 工程到底是在干啥,
模型:qwen-7b-chat
显存:24G
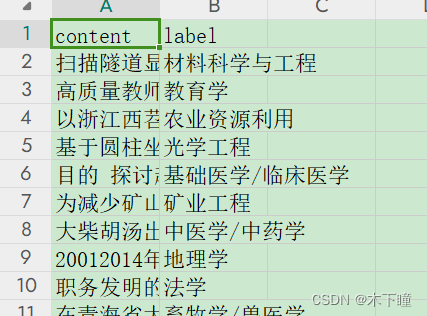
数据,专业描述的文本,还有对应的 label,
任务:通过编写 prompt ,传入专业列表,让大模型去判断是哪个专业
评判标准:其实就是文本分类任务,已经有数据标注了,让大模型预测出来后,计算准确率就可以评判效果好不好
数据链接:https://pan.baidu.com/s/1EvvNSWb9RXQm4TqHeg52fA
提取码:2jh3
链接:https://pan.baidu.com/s/1fdNsI35eiQAPsiIDeaTsAQ
提取码:6mem
直接给代码:
import pandas as pd
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import time# 加载词表,模型,配置
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp",trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("/root/autodl-tmp",device_map="auto",trust_remote_code=True).eval()
model.generation_config = GenerationConfig.from_pretrained("/root/autodl-tmp",trust_remote_code=True,temperature=0.6) # 可指定不同的生成长度、top_p等相关超参def prompt_predit(content, labels):"""prompt 预测 content 属于哪个类别"""prompt = f"""【学科分类解析】
角色设定:
作为一名资深学者,对各个专业有着深入的了解,擅长通过描述精准判断出是哪一个专业,你的任务是从给定的专业列表中找出与描述最相关的10个专业。已知条件:
[描述]: {content}
[专业列表]: {labels} 决策规则:
1. 专业必须来源于[专业列表]列表;
2. 描述中的专业名词是否指向特定的专业,例如:“数据库=》计算机科学与技术”;
3. 从描述中抽取出关键专业术语,对比`[专业列表]`内的专业名称及其涵盖范围,寻找紧密相关的匹配项。要求:
- 请直接输出专业,无需解释说明;
- 不得拒绝回答;
- 当描述中明确指向某个特定专业时,优先选择该专业;
- 若描述较为模糊或包含多个专业元素,需根据专业知识和经验作出最佳推断。输出格式严格按照列表格式输出:
[专业1, 专业2, 专业3......]
"""response, history = model.chat(tokenizer, prompt, history=None)return response.replace('\n', '').replace(' ', '')if __name__ == '__main__':data = pd.read_csv('../output/classfield_data.csv')data = data.head(100)with open('../data/分类提取/labels_all.txt', 'r', encoding='utf8') as f:labels = f.readlines()res = []start_time = time.time()for index, row in data.iterrows():content = row['content']label = row['label']print(f'---------- {index + 1} / {len(data)} -----------')print(f'当前 content:{content} 正确 label:{label}')try:response = prompt_predit(content, labels)except Exception as e:response = str(e)print(f'解析错误:', response)print(f'预测结果:', '=>', response)res.append(response)data['llm_res'] = res# data['correct'] = (data['llm_res'] == data['label'])data['correct'] = data.apply(lambda row: True if row['label'] in row['llm_res'] else False, axis=1)print(f'预测正确率:', round(sum(data['correct']) / len(data) * 100, 2))data.to_excel('../output/classfield_data_predit.xlsx', index=False)end_time = time.time()print(f'用时:{end_time - start_time}')
这是最简单可以说明什么是 prompt 工程的案例,下面来讲一下思路。
1、加载模型
2、读入要处理的数据
3、把要传递给大模型的数据拿出来(content,labels)
4、调用大模型,prompt 编写好再去调用
5、如果需要,需要单独编写解析大模型返回的解析结果
6、最后保存所有结果
以上就是 prompt 工程整体流程,可以看出流程还是挺简单的,但想要想过真的没那么容易,有几方面:
1、不同模型,想通 prompt 效果不一样
2、不同词语描述,效果也不一样
3、哪怕改一个字,效果也会不一样
所以 prompt 要说什么技巧套路,我觉得有点扯淡,基本模版的技巧大家看了都会,但想要效果好得不停地调。
而且评判的数据挺重要的,就像我这个需求应该是分类任务对吧,那结果应该有一个,对就对,不对就不对,我调了几版 prompt ,最好的准确率是 39%,就去数据及理由,有些数据光是人去判断都不太好判断,或是有歧义的,更别说模型了,例如
content:20012014年对青海省主要水体中外来鱼类组成、分布和生态习性进行了系统调查。野外调查采集到外来鱼类30种,隶属6目12科25属,已建群外来鱼类16种。其中,黄河水系拥有的外来鱼类最多,共26种;长江上游有4种,为该河段首次记录;可鲁克湖12种,是内陆水体中外来鱼类最多的水域。结合历史文献记录,截至2013年,全省记录外来鱼类7目13科31属36种,已远超土著鱼类物种数(50种和亚种)的一半。调查分析发现外来鱼类呈现数量持续增多、分布范围向高海拔扩张的趋势。已建群外来鱼类主要是分布于我国东部平原地区的广布型物种。虹鳟( Oncorhynchus myskiss)是代表性外来种,现已在黄河上游干流部分河段形成自然繁殖群体,其食物组成包括水生无脊椎动物和高原鳅等土著鱼类。建立水产种质资源保护区和开展外来鱼类影响研究是防控高原地区外来鱼类的必要措施。 正确 label:地理学这段文本大家可以看看觉得他是在描述什么专业,我看了后觉得跟水产有关,大模型预测结果也是水产:
预测结果: => [水产|根据描述中提到的“外来鱼类”、“黄河水系拥有最多外来鱼类”、“已在黄河上游干流部分河段形成自然繁殖群体”等内容,可以推断出描述涉及的是水产专业。]再去看数据标注的答案,摸不着头脑,可能从描述看最相关的水产,其次再是地理学之类的,
所以我改了 prompt ,选出10 个专业,只要 label 再里面就算对,准确率直接就 67 了。
所以标注的数据也挺重要的。
vllm 推理加速框架
上面我们通过一个最基本的案例明白了什么是 prompt 工程,现在来看一个框架 vllm ,是推理加速用的,意思就是说加速模型生成的速度。
把上面的代码改为 vllm 框架,改用批次,最大化利用 gpu 效率,利用 1000 条来测试一下速度有多少提升
from vllm import LLM, SamplingParams
import os
import time
import pandas as pdos.environ['CUDA_VISIBLE_DEVICES'] = '0'
model_path = "/root/autodl-tmp"
llm = LLM(model=model_path, trust_remote_code=True, tokenizer=model_path, tokenizer_mode='slow', tensor_parallel_size=1)
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)def batch_prompt(cur_batch_data):prompts = []for index, row in cur_batch_data.iterrows():content = row['content']prompt = f"""【学科分类解析】
角色设定:
作为一名资深学者,对各个专业有着深入的了解,擅长通过描述精准判断出是哪一个专业,你的任务是从给定的专业列表中找出与描述最相关的个专业。已知条件:
[描述]: {content}
[专业列表]: {labels} 决策规则:
1. 专业必须来源于[专业列表]列表;
2. 描述中的专业名词是否指向特定的专业,例如:“数据库=》计算机科学与技术”;
3. 从描述中抽取出关键专业术语,对比`[专业列表]`内的专业名称及其涵盖范围,寻找紧密相关的匹配项。要求:
- 请直接输出专业,无需解释说明;
- 不得拒绝回答;
- 当描述中明确指向某个特定专业时,优先选择该专业;
- 若描述较为模糊或包含多个专业元素,需根据专业知识和经验作出最佳推断。输出:
[专业]
"""prompts.append(prompt)return promptsif __name__ == '__main__':data = pd.read_csv('../output/classfield_data.csv')data = data.head(1000)with open('../data/分类提取/labels_all.txt', 'r', encoding='utf8') as f:labels = f.readlines()global_time = 0batch_size = 32res = []for i in range(0, len(data), batch_size):cur_start_time = time.time()cur_batch_data = data[i:i + batch_size]cur_batch_prompt = batch_prompt(cur_batch_data)outputs = llm.generate(cur_batch_prompt, sampling_params)for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textres.append(generated_text)cur_end_time = time.time()global_time += cur_end_time - cur_start_timeprint(f'当前批次用时 {cur_end_time - cur_start_time} 目前已使用使用时间 {global_time} 进度 {i + batch_size}')data['llm_res'] = res# data['correct'] = (data['llm_res'] == data['label'])data['correct'] = data.apply(lambda row: True if row['label'] in row['llm_res'] else False, axis=1)print(f'预测正确率:', round(sum(data['correct']) / len(data) * 100, 2))data.to_excel('../output/classfield_data_predit.xlsx', index=False)print(f'总用时:{global_time}')
vllm 用时
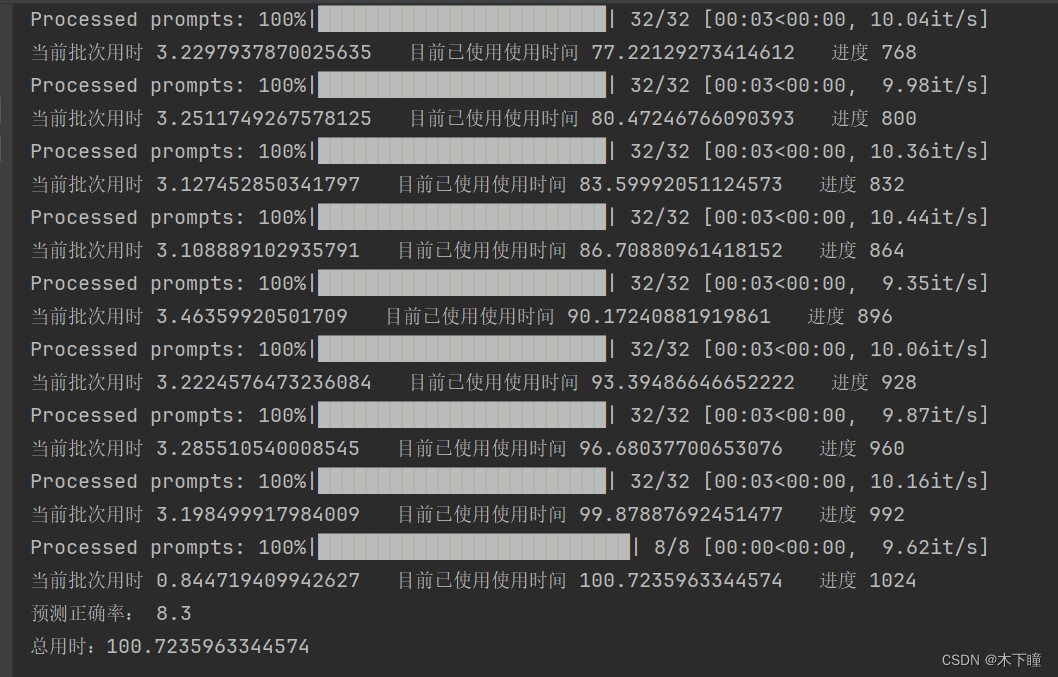
之前的代码用时:

可以看出,真的能像网上说的那样提速 2 倍左右,但准确率下降了,我把输出打印出来看,发现是输出内容没有按照之前的来了,说明 vllm 会对输出有影响。
相关文章:
prompt 工程案例
目录 prompt 工程是什么? 案例 vllm 推理加速框架 prompt 工程是什么? prompt:提示词,也就是我们使用网页版输入给大模型的内容就叫 prompt,那什么是 prompt 工程呢? 简单理解其实就是利用编写的 prom…...

燃气管网安全运行监测系统功能介绍
燃气管网,作为城市基础设施的重要组成部分,其安全运行直接关系到居民的生命财产安全和城市的稳定发展。然而,随着城市规模的不断扩大和燃气使用量的增加,燃气管网的安全运行面临着越来越大的挑战。为了应对这些挑战,燃…...

正则表达式(2)
文章目录 专栏导读1、贪婪与非贪婪2、转义匹配 专栏导读 ✍ 作者简介:i阿极,CSDN 数据分析领域优质创作者,专注于分享python数据分析领域知识。 ✍ 本文录入于《python网络爬虫实战教学》,本专栏针对大学生、初级数据分析工程师精…...

xv6源码分析 001
xv6源码分析 001 我们先看看xv6这个项目的基本结构(只看代码部分) 主要就是两个目录kernel 和 user。 user是一些用户程序,也就是我们平时在shell上面执行的命令,每执行一个命令就会创建一个新的用户进程来执行这个命令 在user目…...
)
)
JS代码小知识(个人向)
JS 对象转数组 let obj {0:"a",1:"b",length:2 //加上这个就能转了 }; console.log(Array.from(obj)); // ["a", "b"] 数组的拼接 let a ["a","b"] let b ["c","d"] let c [...a , …...

MC34119
这份文件是关于MC34119线性集成电路的产品规格说明书,由Unisonic Technologies Co., Ltd生产。MC34119是一款低功耗音频放大器IC,主要用于电话应用,如扬声器电话。以下是该文件的核心内容概要: 产品描述: MC34119是一款…...
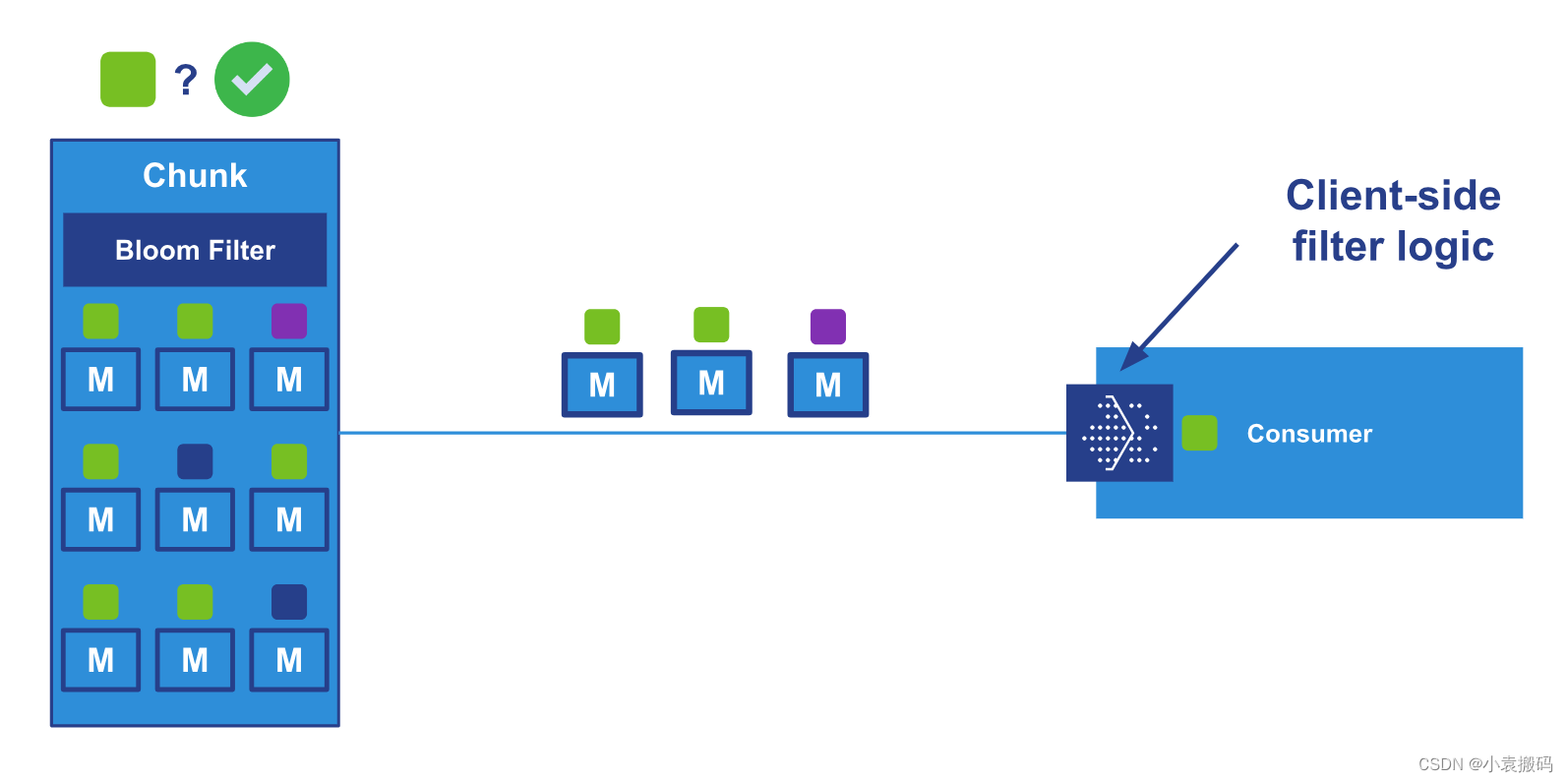
RabbitMQ3.13.x之十_流过滤的内部结构设计与实现
RabbitMQ3.13.x之十_流过滤的内部结构设计与实现 文章目录 RabbitMQ3.13.x之十_流过滤的内部结构设计与实现1. 概念1. 消息发布2. 消息消费 2. 流的结构1. 在代理端进行过滤2. 客户端筛选3. JavaAPI示例4. 流过滤配置5. AMQP上的流过滤6. 总结 3. 相关链接 1. 概念 流过滤的思…...

Node爬虫:原理简介
在数字化时代,网络爬虫作为一种自动化收集和分析网络数据的技术,得到了广泛的应用。Node.js,以其异步I/O模型和事件驱动的特性,成为实现高效爬虫的理想选择。然而,爬虫在收集数据时,往往面临着诸如反爬虫机…...
Python如何解决“滑动拼图”验证码(8)
前言 本文是该专栏的第67篇,后面会持续分享python爬虫干货知识,记得关注。 做过爬虫项目的同学,或多或少都会接触到一些需要解决验证码才能正常获取数据的平台。 在本专栏之前的文章中,笔者有详细介绍通过python来解决多种“验证码”(点选验证,图文验证,滑块验证,滑块…...

MongoDB 启动异常
Failed to start up WiredTiger under any compatibility version. 解决方案: 删除WiredTiger.lock 和 mongod.lock两个文件,在重新启动。回重新生成新的文件。...

mysql 常见数据处理 dml
学习完,mysql正则表达式查询,把常见的数据处理,做一个汇总,便于查看。 数据操纵语言(Data Manipulation Language, DML)。 1,新增数据: 1,单个插入: insert…...

课时86:流程控制_函数基础_函数退出
2.1.2 函数退出 这一节,我们从 基础知识、简单实践、小结 三个方面来学习。 基础知识 简介 我们可以将函数代码块,看成shell脚本内部的小型脚本,所以说函数代码块也会有执行状态返回值。对于函数来说,它通常支持两种种状态返回…...
【Python】无法将“pip”项识别为 cmdlet、函数、脚本文件或可运行程序的名称解决方案
【Python】无法将“pip”项识别为 cmdlet、函数、脚本文件或可运行程序的名称解决方案 大家好 我是寸铁👊 总结了一篇【Python】无法将“pip”项识别为 cmdlet、函数、脚本文件或可运行程序的名称解决方案✨ 喜欢的小伙伴可以点点关注 💝 前言 今天寸铁…...

9(10)-1(2)-CSS 布局模型+CSS 浮动
个人主页:学习前端的小z 个人专栏:HTML5和CSS3悦读 本专栏旨在分享记录每日学习的前端知识和学习笔记的归纳总结,欢迎大家在评论区交流讨论! 文章目录 一、CSS 布局模型1 流动模型(标准流) 二、CSS 浮动1 浮…...
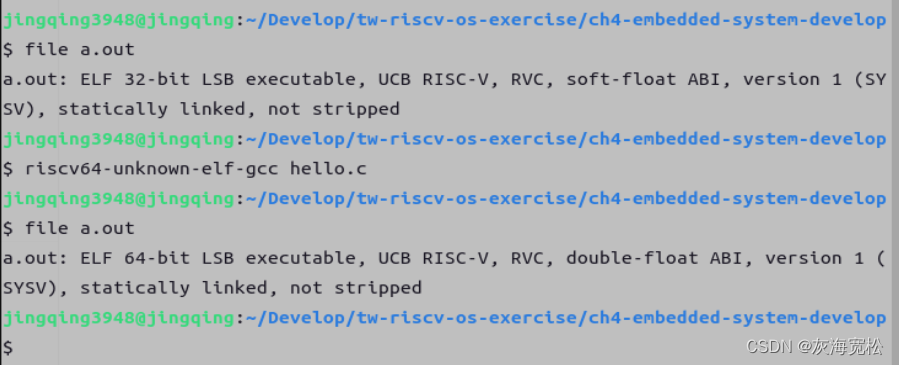
RISC-V GNU Toolchain 工具链安装问题解决(含 stdio.h 问题解决)
我的安装过程主要参照 riscv-collab/riscv-gnu-toolchain 的官方 Readme 和这位佬的博客:RSIC-V工具链介绍及其安装教程 - 风正豪 (大佬的博客写的非常详细,唯一不足就是 sudo make linux -jxx 是全部小写。) 工具链前前后后我装了…...
[C#]OpenCvSharp使用帧差法或者三帧差法检测移动物体
关于C版本帧差法可以参考博客 [C]OpenCV基于帧差法的运动检测-CSDN博客https://blog.csdn.net/FL1768317420/article/details/137397811?spm1001.2014.3001.5501 我们将参考C版本转成opencvsharp版本。 帧差法,也叫做帧间差分法,这里引用百度百科上的…...
Android Studio学习8——点击事件
在xml代码中绑定 在java代码中绑定 弹出一个toast 随机,数组...
微软detours代码借鉴点备注
comeasy 借鉴点1 Loadlibray的时间选择 注入库wrotei.dll,为了获取istream的接口,需要loadlibrary,但是在dllmain中是不建议这样做的。因此,动态库在dllmain的时候直接挂载了comeasy.exe的入口 //获取入口 TrueEntryPoint (i…...
【c++】类和对象(七)
🔥个人主页:Quitecoder 🔥专栏:c笔记仓 朋友们大家好,本篇文章来到类和对象的最后一部分 目录 1.static成员1.1特性 2.友元2.1引入:<<和>>的重载2.2友元函数2.3友元类 3.内部类4.匿名对象5.拷…...
)
数字孪生软件篇教程(从零入门到工业落地)
前言 在数字孪生行业中,硬件决定真假,软件决定颜值与逻辑。很多新手误区:把数字孪生当成3D建模、做炫酷大屏。 真正工业级软件架构:三维建模 + 后端服务 + 数据中台 + 可视化引擎 + 仿真逻辑。 本篇为配套硬件篇专属软件教程,保持一模一样排版结构、通俗易懂、零基础入…...
)
Midjourney提示词工程终极护城河:基于CLIP文本嵌入空间的向量对齐技术(附Python可视化调试工具)
更多请点击: https://intelliparadigm.com 第一章:Midjourney提示词工程终极护城河:基于CLIP文本嵌入空间的向量对齐技术(附Python可视化调试工具) 在生成式AI实践中,提示词质量差异常导致图像语义漂移——…...

深度测试在2D渲染中的性能优化实践
1. 深度测试在2D渲染中的创新应用在移动设备上,2D应用和游戏的渲染性能优化一直是个棘手的问题。传统2D渲染采用简单的后向前(back-to-front)绘制顺序来处理透明混合,这种方法虽然直观,但存在严重的过度绘制࿰…...

Go语言Beego框架如何用_Go语言Beego框架入门教程【高效】
Beego Controller 靠约定式反射自动注册,需嵌入 beego.Controller、方法名首字母大写且以 HTTP 动词开头、文件置于 controllers/ 目录下;路由参数用 :id 形式绑定到同名 string 参数;模板路径为 views/{小写控制器名}/{小写方法名}.html&…...

Win10系统下极点五笔输入法的兼容性配置与TSF框架适配实践
1. 为什么Win10需要特殊配置才能用极点五笔? 很多从Win7升级到Win10的五笔用户都会发现,用了十几年的极点五笔突然变得不听话了。这背后其实藏着微软输入法框架的大变革——从传统的IMM(Input Method Manager)架构转向了TSF&#…...
JiT源码深度剖析:从Denoiser到Transformer的完整实现
JiT源码深度剖析:从Denoiser到Transformer的完整实现 【免费下载链接】JiT PyTorch implementation of JiT https://arxiv.org/abs/2511.13720 项目地址: https://gitcode.com/gh_mirrors/jit8/JiT JiT(Just image Transformer)是一个…...

如何将Figma设计文件转换为结构化JSON数据:设计开发一体化的终极指南
如何将Figma设计文件转换为结构化JSON数据:设计开发一体化的终极指南 【免费下载链接】figma-to-json 💾 Read/Write Figma Files as JSON 项目地址: https://gitcode.com/gh_mirrors/fi/figma-to-json 想象一下这个场景:设计师刚刚完…...

Xshell6启动报错0xc000007b:从DLL缺失到Visual C++库修复的完整排障指南
1. 当Xshell6突然罢工:0xc000007b报错初体验 那天早上我像往常一样双击Xshell6图标,准备连接服务器,结果突然弹出一个冰冷的错误窗口:"应用程序无法正常启动(0xc000007b)"。这种系统级错误代码对很多Windows用户来说就…...

QtScrcpy安卓投屏终极指南:从零基础到精通应用的完整教程
QtScrcpy安卓投屏终极指南:从零基础到精通应用的完整教程 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrc…...

先进制程EPE挑战:从系统误差到量测革命,如何驯服边缘位置误差
1. 从“理所当然”到“如履薄冰”:边缘位置误差如何成为先进制程的“隐形杀手”在半导体行业过去的黄金岁月里,工程师们有一个近乎奢侈的“共识”:芯片内部那些由光刻、刻蚀定义的特征边缘,可以被理所当然地看作是笔直且在不同工艺…...