RabbitMQ3.13.x之十_流过滤的内部结构设计与实现
RabbitMQ3.13.x之十_流过滤的内部结构设计与实现
文章目录
- RabbitMQ3.13.x之十_流过滤的内部结构设计与实现
- 1. 概念
- 1. 消息发布
- 2. 消息消费
- 2. 流的结构
- 1. 在代理端进行过滤
- 2. 客户端筛选
- 3. JavaAPI示例
- 4. 流过滤配置
- 5. AMQP上的流过滤
- 6. 总结
- 3. 相关链接
1. 概念
流过滤的思想是在代理端提供第一级的高效过滤,而无需代理解释消息。 这样,只需要流子集的使用者就不需要自己获取所有数据并处理所有过滤。 这可以大大减少传输给消费者的数据。
通过筛选,可以将筛选器值与每条消息相关联。 它可以是地理信息,例如每条消息来自的世界区域,如下图所示:

因此,我们的流有 1 条(绿色)消息、1 条(深蓝色)消息、2 条(紫色)消息,然后是 2 条消息。AMER``APAC``EMEA``AMER
1. 消息发布
发布者可以将每封出站邮件与其筛选器值相关联:
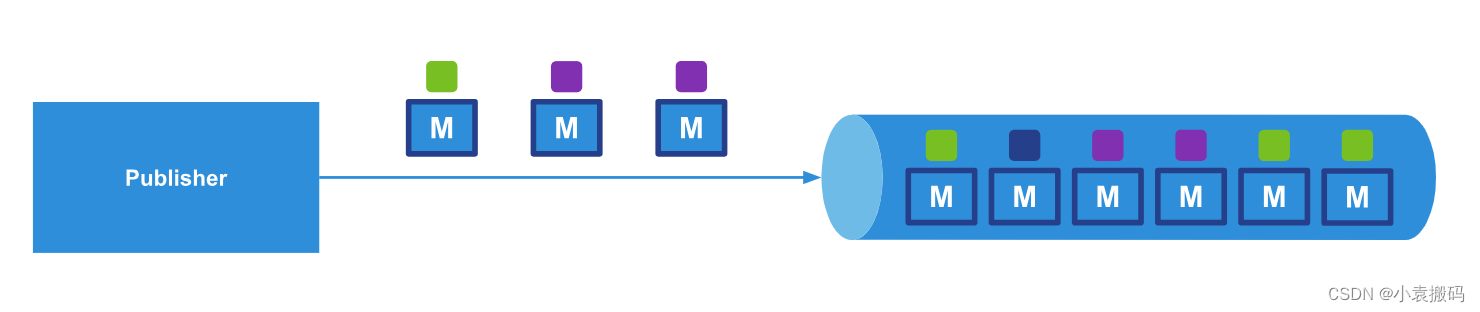
在上图中,发布者发布了 1 条(绿色)消息和 2 条(紫色)消息,这些消息将添加到流中。AMER``EMEA
2. 消息消费
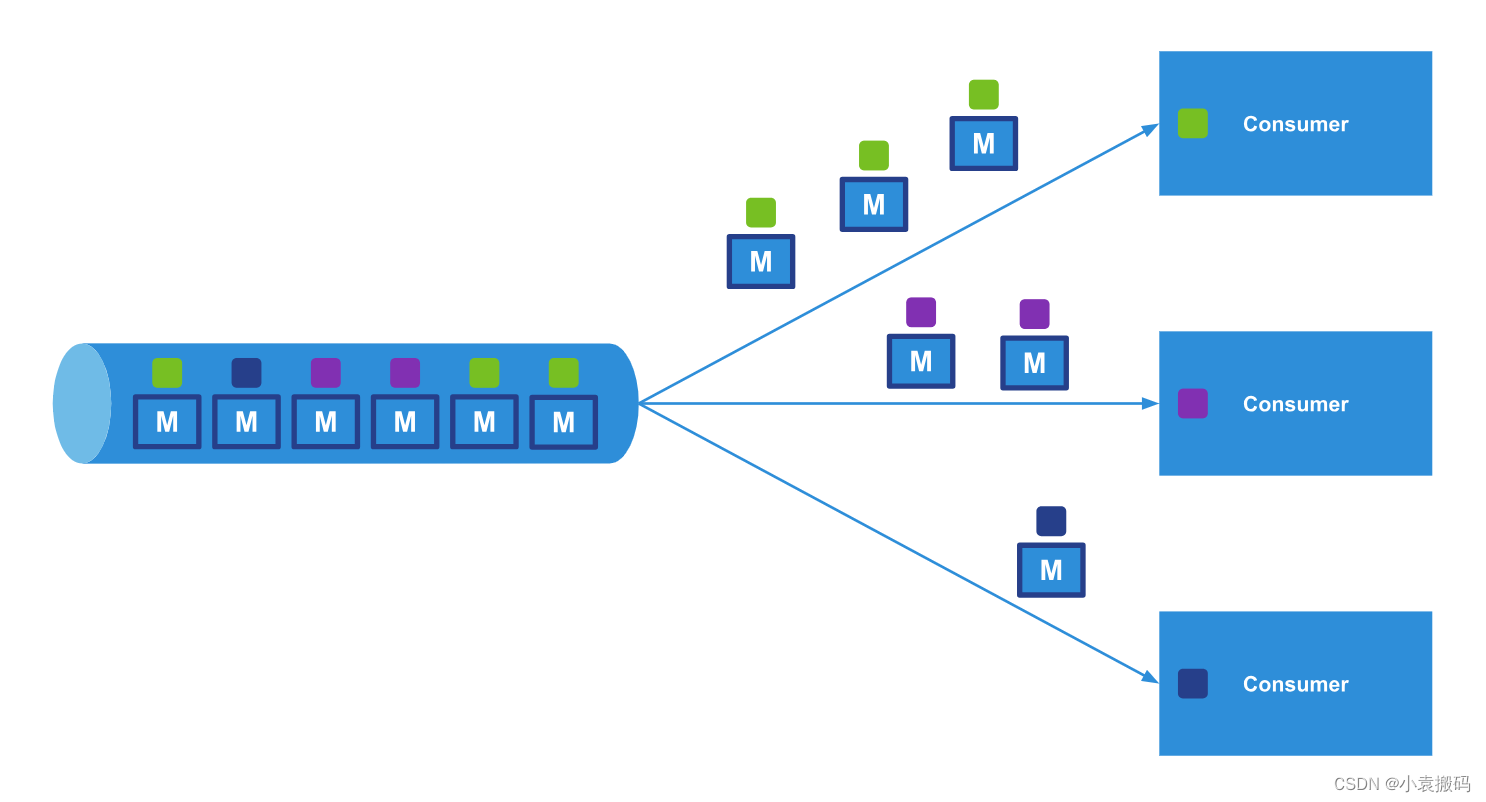
当使用者订阅时,它可以指定一个或多个过滤器值,并且代理应仅发送具有此或这些过滤器值的消息。 我们很快就会看到这在实践中有点不同,但这足以理解这些概念。
在下图中,顶部的使用者指定它只想要(绿色)消息,而代理只发送这些消息。 中间的消费者和底部的消费者也是如此。AMER``EMEA``APAC
概念就到这里了,现在让我们来了解一下实现细节。
2. 流的结构
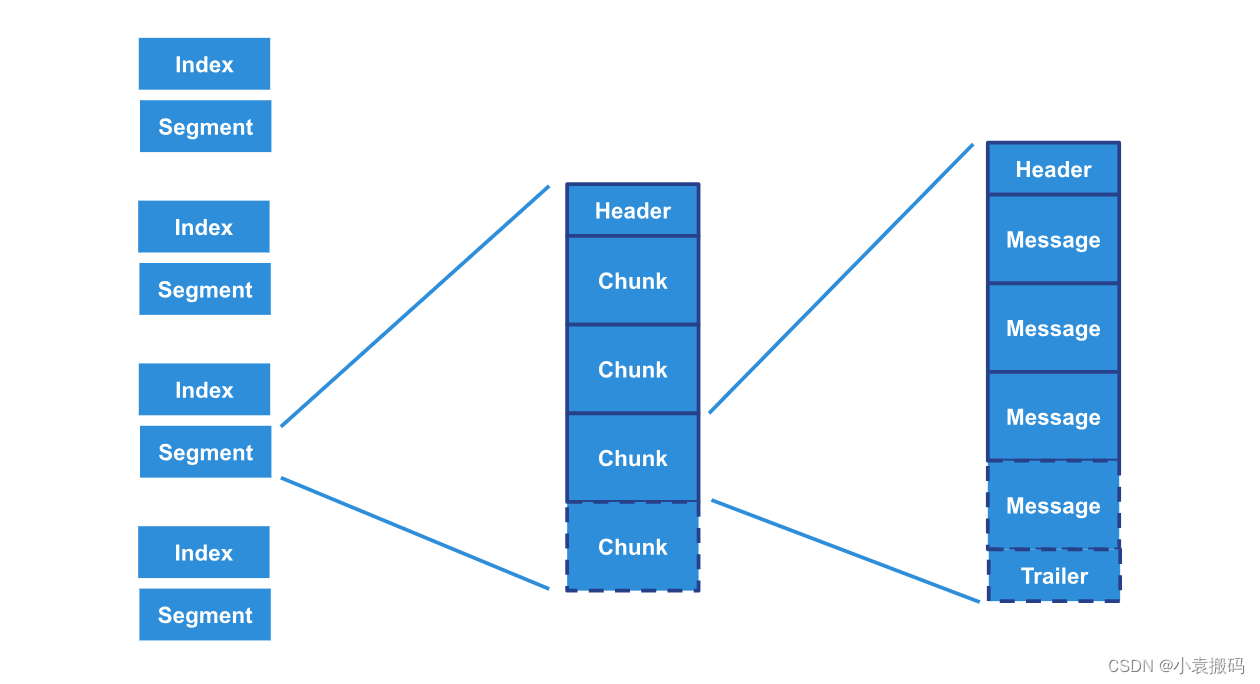
我们需要知道流是如何构建的,以便了解流过滤的内部结构。 流是包含段文件的目录。 每个区段文件都有一个关联的索引文件(用于了解在区段文件中给定偏移量处附加使用者的位置等)。 拥有多个“小”段文件比为整个流拥有一个大的整体文件要好:例如,删除“旧”段文件以截断流比删除大文件的开头更有效、更安全。
区段文件由包含消息的块组成。 区块中的消息数取决于入口速率(高入口速率表示一个块中的消息较多,低入口速率表示块中的消息较少)。 块中的消息数量从几条(甚至 1 条)到几千条不等。
块是怎么回事? 块是流中的工作单元:它们用于复制,更重要的是,对于我们的主题,用于消费者交付。 代理使用 sendfile 系统调用(将整个块从文件系统发送到网络套接字,而不将数据复制到用户空间)向使用者发送块,一次一个。
下图说明了流的结构:
有了这个,让我们看看代理如何知道是否要调度一个区块。
1. 在代理端进行过滤
想象一下,我们有一个只想要(绿色)消息的消费者。 当代理要调度一个区块时,它需要知道该区块是否包含消息。 如果是这样,它可以将块发送给消费者,如果没有,代理可以跳过该块,转到下一个块,然后重新迭代。AMER``AMER
每个区块都有一个标头,该标头可以包含一个 Bloom 过滤器,该标头告诉代理该块是否包含具有给定过滤器值的消息。 Bloom 过滤器是一种节省空间的概率数据结构,用于测试元素是否是集合的成员。 在我们的示例中,集合包含 、 和 ,元素是 。AMER``EMEA``APAC``AMER
下图说明了 3 个块的代理端过滤过程:
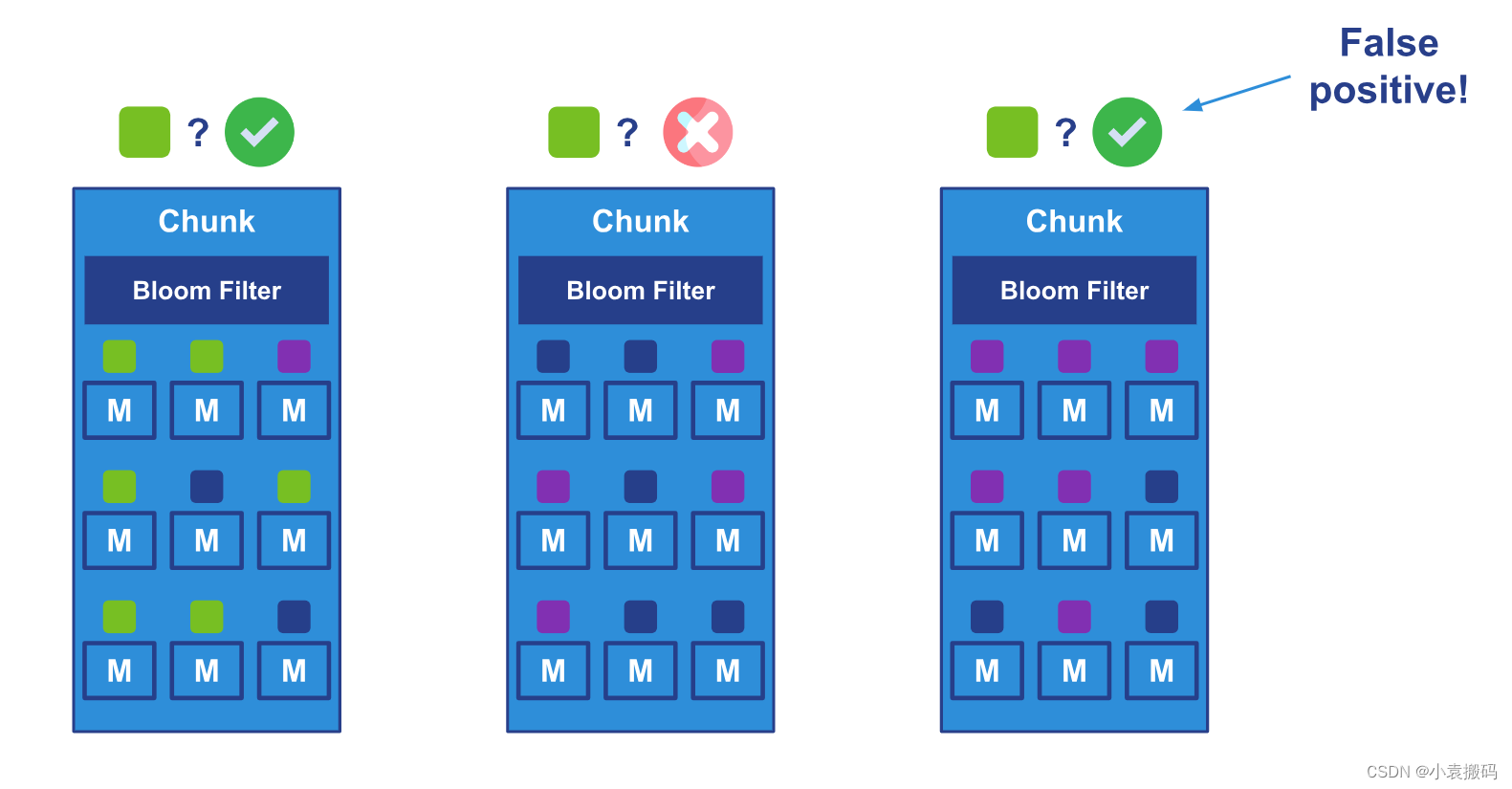
如上图所示,筛选器可能会返回误报,即不包含具有预期筛选器值的消息的块。 这是正常的,因为 Bloom 过滤器是概率性的。 不过,它们不会返回假阴性:如果过滤器显示没有(绿色)消息,我们可以确定它是真的。 我们必须忍受这种不确定性:有时我们可能会无缘无故地调度一些块,但这总比调度所有块要好。AMER
可以肯定的是,消费者可以接收到它不想要的消息:看看我们左边的第一个块,它包含消费者要求的(绿色)消息,但也包含(紫色)和(深蓝色)消息。 这就是为什么客户端也必须进行过滤的原因。AMER``EMEA``APAC
2. 客户端筛选
代理在传递消息时处理第一级过滤,但由于传递单位是块,因此使用者仍然可以接收它不想要的消息。 因此,客户端还必须执行一些筛选,这显然必须与订阅时设置的筛选值一致。
下图说明了一个消费者,它只需要(绿色)消息,并且必须执行最后一步的筛选:AMER
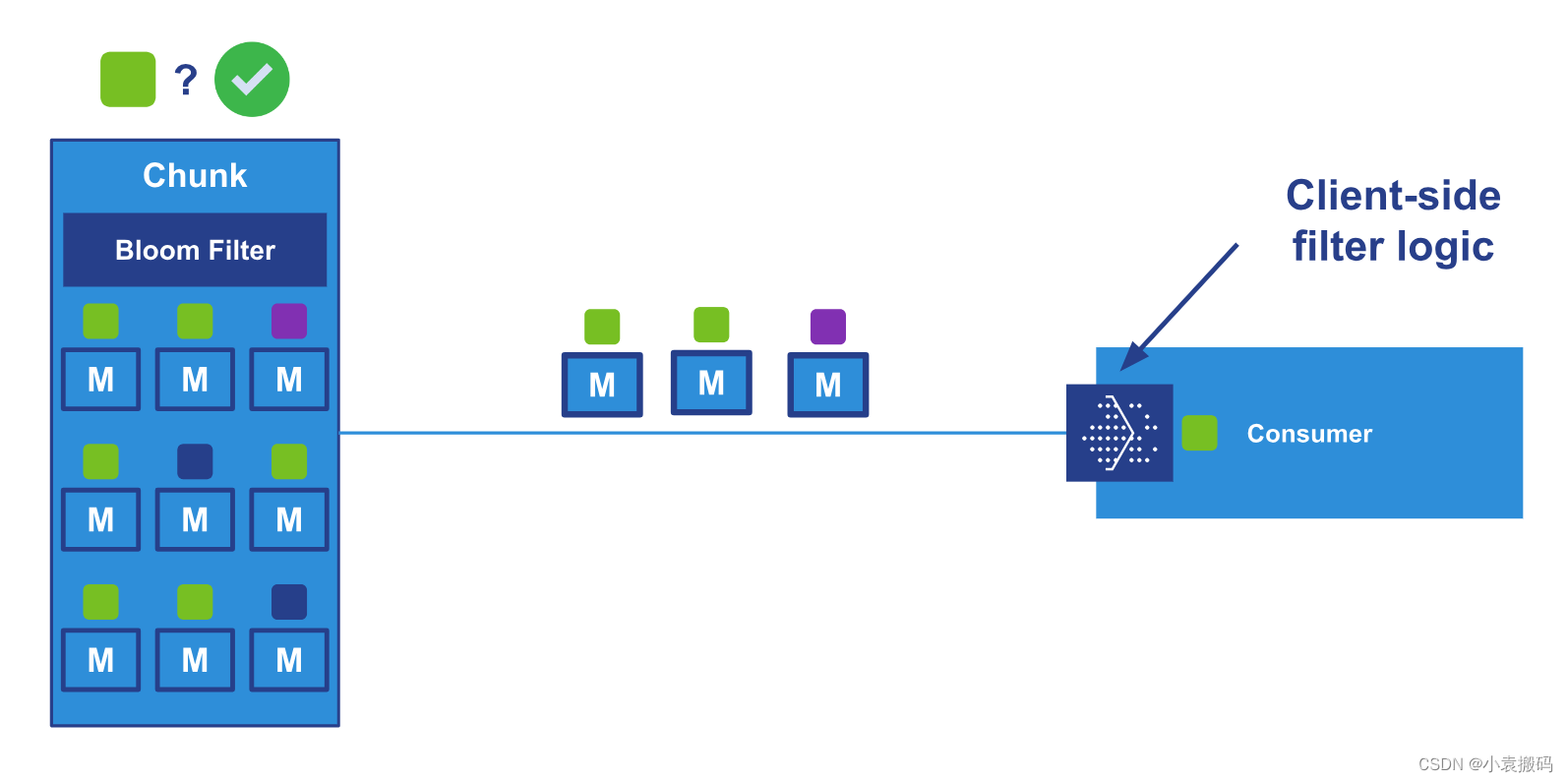
让我们看看这如何转化为应用程序代码。
3. JavaAPI示例
筛选不是侵入性的,可以作为跨领域问题进行处理,从而最大限度地减少对应用程序代码的影响。 以下是在使用流 Java 客户端(方法)声明生产者时设置从消息中提取过滤器值的逻辑:filterValue(Function<Message,String>)
Producer producer = environment.producerBuilder().stream("invoices").filterValue(msg -> msg.getApplicationProperties().get("region").toString()) .build();
在消费端,流 Java 客户端提供了设置过滤器值的方法和设置客户端过滤逻辑的方法。 声明使用者时,必须调用这两种方法:filter().values(String... filterValues)``filter().postFilter(Predicate<Message> filter)
Consumer consumer = environment.consumerBuilder().stream("invoices").filter().values("AMER") .postFilter(msg -> "AMER".equals(msg.getApplicationProperties().get("region"))) .builder().messageHandler((ctx, msg) -> {// message processing code}).build();
如您所见,筛选不会更改发布和使用代码,而只是更改生产者和使用者的声明。
现在让我们看看如何以最合适的方式为用例配置流过滤。
4. 流过滤配置
关于流过滤的第一篇文章提供了一些数字(与不过滤相比,过滤节省了大约 80% 的带宽)。 流过滤的好处很大程度上取决于用例:入口速率、基数和过滤器值的分布,以及过滤器大小。 过滤器越大越好(错误率越小)。 可以为块中使用的筛选器大小设置一个介于 16 到 255 字节之间的值,默认值为 16 字节。
流 Java 客户端提供了在创建流时设置过滤器大小的方法(它在内部设置参数):filterSize(int)``stream-filter-size-bytes
environment.streamCreator().stream("invoices").filterSize(32).create()
如何估算过滤器的尺寸? 网上有许多 Bloom 滤镜计算器。 参数包括哈希函数的数量(RabbitMQ 流过滤为 2 个)、预期元素的数量、错误率和大小。 您通常对元素的数量有所了解,因此您需要在错误率和过滤器大小之间找到权衡。
以下是一些示例:
- 10 个值,16 个字节 => 2 % 错误率
- 30 个值,16 个字节 => 14 % 错误率
- 200 个值,128 个字节 => 10 % 的错误率
那么,过滤器越大越好? 不完全是:尽管 Bloom 过滤器在存储方面非常有效,因为它不存储元素,只是元素是否在集合中,过滤器大小是预先分配的。 如果将筛选器大小设置为 255,并且每个块至少包含一条具有筛选器值的消息,则每个块标头中将分配 255 个字节。 如果块包含许多大消息,这很好,因为与块大小相比,筛选器大小可以忽略不计。 但是,对于退化的情况,例如具有 10 字节消息和 10 字节筛选器值的单消息块,您最终会得到一个比实际数据更大的筛选器。
您必须尝试自己的用例,以估计过滤器大小对流大小的影响。 关于流过滤的第一篇文章提供了一个使用 Stream PerfTest 估计流大小的技巧(在不过滤的情况下读取整个流并查阅指标)。rabbitmq_stream_read_bytes_total
5. AMQP上的流过滤
尽管访问流的首选方式是流协议,但支持其他协议,例如 AMQP。 任何 AMQP 客户端库也支持流筛选:
- 声明:将参数设置为 并使用 在声明流时设置筛选器大小。
x-queue-type``stream``x-stream-filter-size-bytes - 发布:使用标头设置出站邮件的筛选器值。
x-stream-filter-value - 使用:使用 consumer 参数设置预期的筛选器值(字符串或字符串数组),并使用 consumer 参数(可选)接收没有任何筛选值的消息(默认值为 )。客户端过滤仍然是必要的!
x-stream-filter``x-stream-match-unfiltered``false
6. 总结
流过滤易于使用并从中受益,但有关内部的一些知识可用于优化其使用,尤其是对于棘手的用例。 请记住,客户端筛选是必需的,并且必须与配置的筛选器值一致。 这通常很容易实现。 还可以为给定的用例以最合适的方式设置过滤器大小。
3. 相关链接
参考:
Stream Filtering Internals | RabbitMQ
相关文章:
RabbitMQ3.13.x之十_流过滤的内部结构设计与实现
RabbitMQ3.13.x之十_流过滤的内部结构设计与实现 文章目录 RabbitMQ3.13.x之十_流过滤的内部结构设计与实现1. 概念1. 消息发布2. 消息消费 2. 流的结构1. 在代理端进行过滤2. 客户端筛选3. JavaAPI示例4. 流过滤配置5. AMQP上的流过滤6. 总结 3. 相关链接 1. 概念 流过滤的思…...

Node爬虫:原理简介
在数字化时代,网络爬虫作为一种自动化收集和分析网络数据的技术,得到了广泛的应用。Node.js,以其异步I/O模型和事件驱动的特性,成为实现高效爬虫的理想选择。然而,爬虫在收集数据时,往往面临着诸如反爬虫机…...
Python如何解决“滑动拼图”验证码(8)
前言 本文是该专栏的第67篇,后面会持续分享python爬虫干货知识,记得关注。 做过爬虫项目的同学,或多或少都会接触到一些需要解决验证码才能正常获取数据的平台。 在本专栏之前的文章中,笔者有详细介绍通过python来解决多种“验证码”(点选验证,图文验证,滑块验证,滑块…...

MongoDB 启动异常
Failed to start up WiredTiger under any compatibility version. 解决方案: 删除WiredTiger.lock 和 mongod.lock两个文件,在重新启动。回重新生成新的文件。...

mysql 常见数据处理 dml
学习完,mysql正则表达式查询,把常见的数据处理,做一个汇总,便于查看。 数据操纵语言(Data Manipulation Language, DML)。 1,新增数据: 1,单个插入: insert…...

课时86:流程控制_函数基础_函数退出
2.1.2 函数退出 这一节,我们从 基础知识、简单实践、小结 三个方面来学习。 基础知识 简介 我们可以将函数代码块,看成shell脚本内部的小型脚本,所以说函数代码块也会有执行状态返回值。对于函数来说,它通常支持两种种状态返回…...
【Python】无法将“pip”项识别为 cmdlet、函数、脚本文件或可运行程序的名称解决方案
【Python】无法将“pip”项识别为 cmdlet、函数、脚本文件或可运行程序的名称解决方案 大家好 我是寸铁👊 总结了一篇【Python】无法将“pip”项识别为 cmdlet、函数、脚本文件或可运行程序的名称解决方案✨ 喜欢的小伙伴可以点点关注 💝 前言 今天寸铁…...

9(10)-1(2)-CSS 布局模型+CSS 浮动
个人主页:学习前端的小z 个人专栏:HTML5和CSS3悦读 本专栏旨在分享记录每日学习的前端知识和学习笔记的归纳总结,欢迎大家在评论区交流讨论! 文章目录 一、CSS 布局模型1 流动模型(标准流) 二、CSS 浮动1 浮…...
RISC-V GNU Toolchain 工具链安装问题解决(含 stdio.h 问题解决)
我的安装过程主要参照 riscv-collab/riscv-gnu-toolchain 的官方 Readme 和这位佬的博客:RSIC-V工具链介绍及其安装教程 - 风正豪 (大佬的博客写的非常详细,唯一不足就是 sudo make linux -jxx 是全部小写。) 工具链前前后后我装了…...
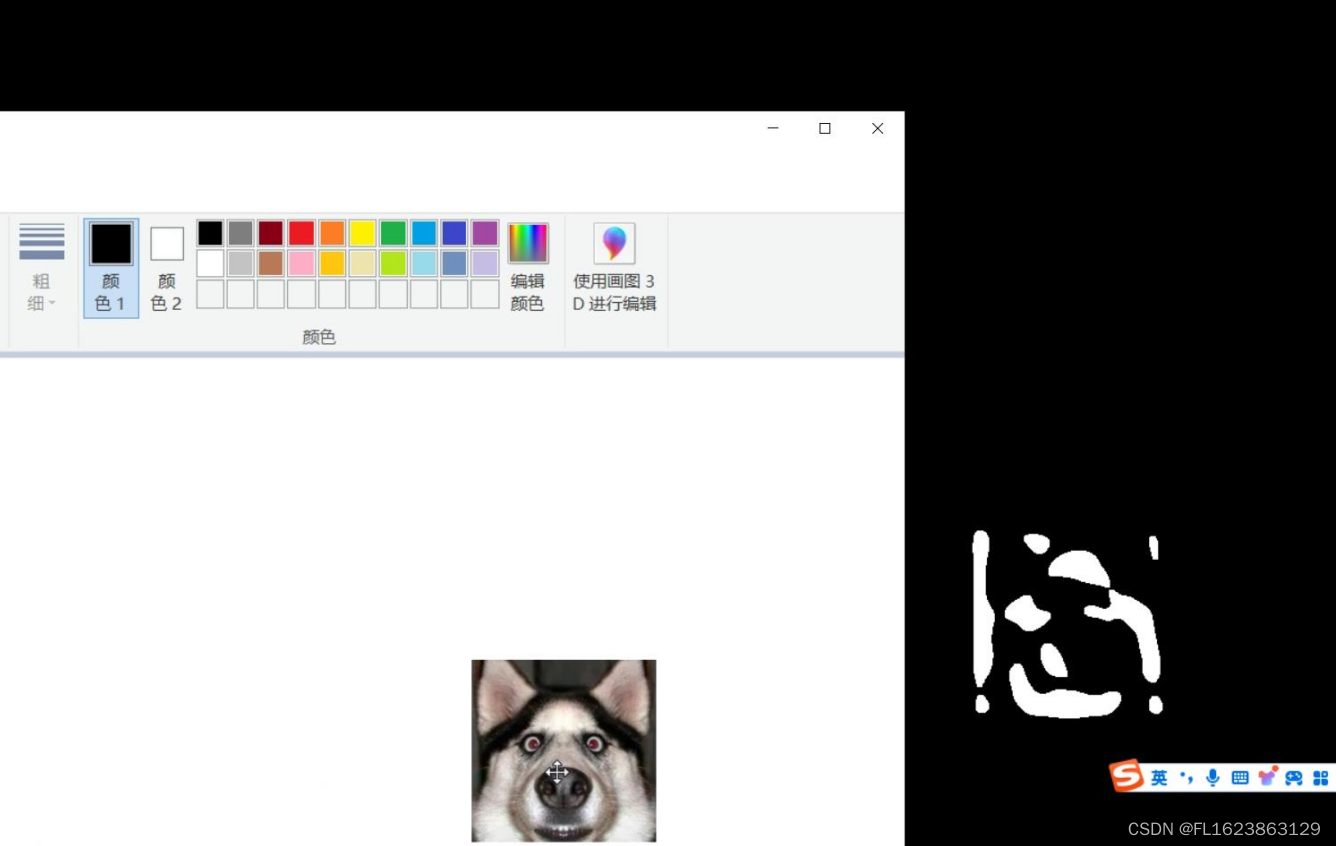
[C#]OpenCvSharp使用帧差法或者三帧差法检测移动物体
关于C版本帧差法可以参考博客 [C]OpenCV基于帧差法的运动检测-CSDN博客https://blog.csdn.net/FL1768317420/article/details/137397811?spm1001.2014.3001.5501 我们将参考C版本转成opencvsharp版本。 帧差法,也叫做帧间差分法,这里引用百度百科上的…...
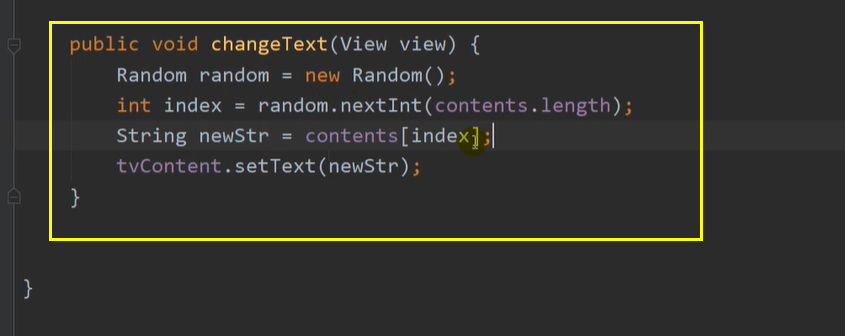
Android Studio学习8——点击事件
在xml代码中绑定 在java代码中绑定 弹出一个toast 随机,数组...
微软detours代码借鉴点备注
comeasy 借鉴点1 Loadlibray的时间选择 注入库wrotei.dll,为了获取istream的接口,需要loadlibrary,但是在dllmain中是不建议这样做的。因此,动态库在dllmain的时候直接挂载了comeasy.exe的入口 //获取入口 TrueEntryPoint (i…...
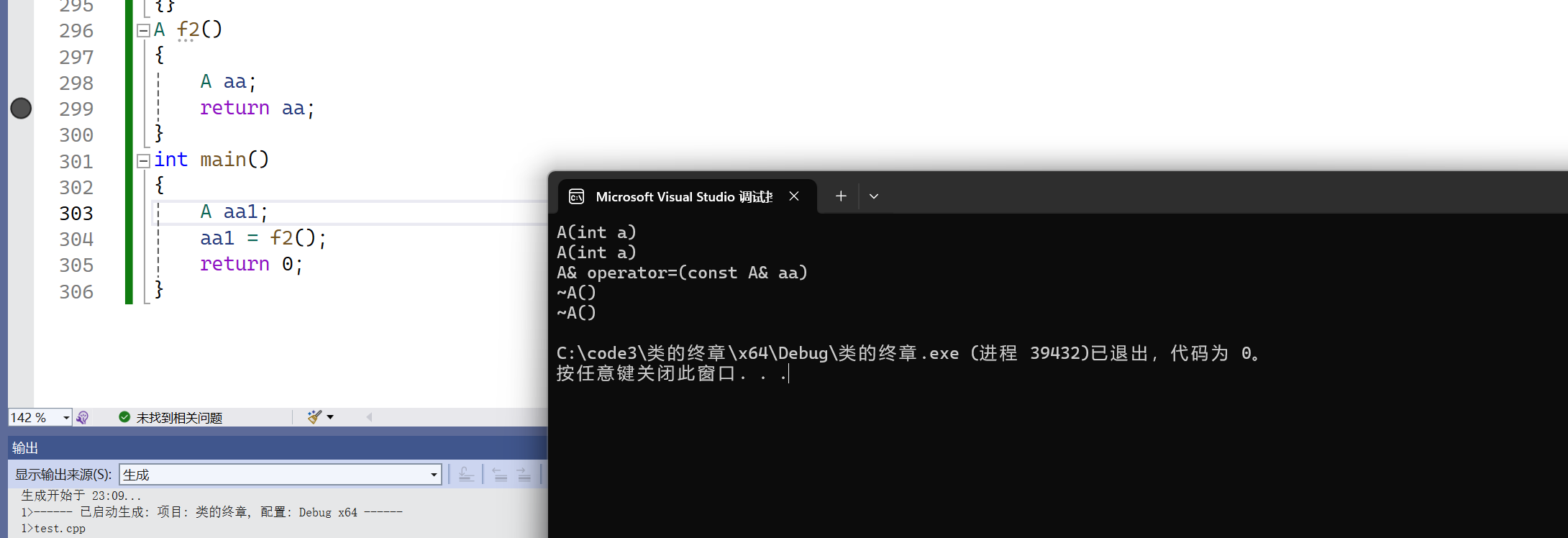
【c++】类和对象(七)
🔥个人主页:Quitecoder 🔥专栏:c笔记仓 朋友们大家好,本篇文章来到类和对象的最后一部分 目录 1.static成员1.1特性 2.友元2.1引入:<<和>>的重载2.2友元函数2.3友元类 3.内部类4.匿名对象5.拷…...

oracle pdb从12.1迁移到19.20
oracle pdb从12.1迁移到19.20 1 unplug (12c的环境执行) SQL> alter pluggable database VINCENT_TEST close immediate; SQL> alter pluggable database VINCENT_TEST unplug into /u01/backup/temp_20240401/VINCENT_TEST.xml;2 plug …...

[Python GUI PyQt] PyQt5快速入门
PyQt5快速入门 PyQt5的快速入门0. 写在前面1. 思维导图2. 第一个PyQt5的应用程序3. PyQt5的常用基本控件和布局3.1 PyQt5的常用基本控件3.1.1 按钮控件 QPushButton3.1.2 文本标签控件 QLabel3.1.3 单行输入框控件 QLineEdit3.1.4 A Quick Widgets Demo 3.2 PyQt5的常用基本控件…...

vue3中播放flv流视频,以及组件封装超全
实现以上功能的播放,只需要传入一个流的地址即可,当然组件也只有简单的实时播放功能 下面直接上组件 里面的flvjs通过npm i flv.js直接下载 <template><div class"player" style"position: relative;"><p style&…...
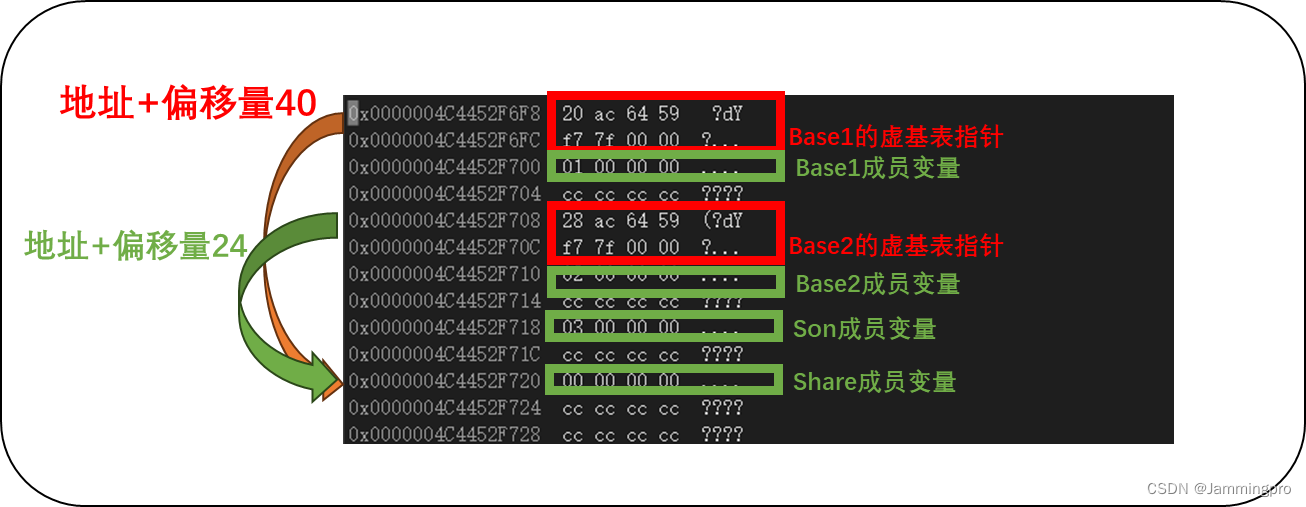
【浅尝C++】继承机制=>虚基表/菱形虚继承/继承的概念、定义/基类与派生类对象赋值转换/派生类的默认成员函数等详解
🏠专栏介绍:浅尝C专栏是用于记录C语法基础、STL及内存剖析等。 🎯每日格言:每日努力一点点,技术变化看得见。 文章目录 继承的概念及定义继承的概念继承的定义定义格式继承关系与访问限定符 基类和派生类对象赋值转换继…...

tomcat中的web项目配置指引
文章目录 目录结构I server.xml 配置文件1.1 Host标签1.2 contex标签1.3 server.xml 的端口配置1.4 appBase和docBase的区别1.5 Engine标签1.6 Connector标签II Tomcat应用的配置2.1 配置虚拟路径2.2 配置连接数2.3 使用线程池2.4 配置内存大小III 预备知识...
如果你正在投简历,一定要试试这款AI工具!
今天给大家分享一款AI简历神器 - BitBitFly AI 简历助手,这个工具可以帮助大家快速、精准投简历,并且提供职位匹配度分析报告,提供专业优化简历建议提高简历和职位匹配度,轻松拿下offer。 如果你在找工作的时候遇到以下问题&…...
Unity:2D SpriteShape
1.1 简介 Sprite Shape 可以很灵活的更改sprite的轮廓。比如: 它由两部分组成:Sprite Shape Profile、Sprite Shape Controller,需要导入2D Sprite Shape Package. 1.1.1 Sprite导入要求 Texture Type - ‘Sprite (2D and UI)’.Sprite Mo…...

别再只会-sS了!Nmap实战:用Wireshark抓包带你搞懂TCP全连接、SYN半连接和隐秘扫描的区别
穿透网络迷雾:用Wireshark解密Nmap扫描背后的TCP握手玄机 在网络安全评估和渗透测试中,端口扫描是最基础却最关键的步骤。大多数工程师都能熟练使用nmap -sS进行SYN扫描,但你是否真正理解数据包在网络层究竟经历了什么?当防火墙规…...

【C++ AI 大模型接入 SDK】 - 项目介绍与 AI 知识科普
大家好,我是Halcyon.平安 欢迎文末添加好友交流,共同进步! 一、项目介绍核心功能二、AI 基础知识科普2.1 什么是大语言模型(LLM)2.2 API 调用方式2.3 全量响应 vs 流式响应2.4 SSE(Server-Sent Events&…...

设计程序统计行业淡季旺季,职场工作量数据,合理调配人力,解决忙闲不均,人力资源浪费职场现状。
一、实际应用场景描述在许多行业(如零售、旅游、物流、电商、教育培训等)中,普遍存在明显的季节性波动:- 旺季:订单/任务激增,员工超负荷加班- 淡季:业务量骤减,人员闲置、工时不足-…...

Taotoken多模型聚合平台为arm7边缘AI应用提供稳定API服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken多模型聚合平台为arm7边缘AI应用提供稳定API服务 对于在arm7架构硬件上部署轻量级AI应用的开发者而言,将大模型…...

设计器模版底图,一直渲染错误,是因为第一张图变形后内存中图片数据被改了,其他尺码一直错误
这其实是你们现在更需要的组合:不是只看 decode(),而是再确认“这次 decode 对应的还是当前这张图”。再确认“这次 decode 对应的还是当前这张图” 是怎么做到的,详细列举代码我直接从现在这次改动的代码里,把"确认图片身份…...

从‘一片蓝’到‘五彩斑斓’:手把手教你美化Matlab三维柱状图,让论文图表脱颖而出
从‘一片蓝’到‘五彩斑斓’:科研级Matlab三维柱状图视觉优化全攻略 当审稿人翻开一篇论文时,图表往往是他们最先注意到的元素。我曾参与过多次学术期刊的评审工作,那些配色考究、细节精致的图表总能在第一时间抓住眼球——这不仅仅是审美问题…...

AI Agent变现难题与破局之道:小白程序员必备收藏,2026年蓝海掘金指南!
文章深入分析了当前AI Agent行业的冰火两重天现象,揭示了技术不成熟、伪需求泛滥、基础设施不完善等六大核心底层逻辑导致变现困难。同时,文章指出了电商全链路、企业办公自动化、本地生活商家、开发者垂直、垂类定制化等五大变现蓝海赛道,并…...
)
保姆级教程:用COMSOL 5.6搞定房间声学模态分析(附网格划分避坑指南)
保姆级教程:用COMSOL 5.6实现高精度房间声学模态分析 当你第一次尝试用COMSOL分析房间的声学特性时,是否曾被复杂的参数设置和网格划分搞得晕头转向?本文将带你一步步攻克声学模态分析中最关键的环节——特征频率求解与网格优化。不同于泛泛而…...

DAB的TPS控制闭环到底怎么调?从开环公式到稳定PI调节的实战心得
DAB的TPS控制闭环调试实战:从开环公式到稳定PI调节 调试双有源桥(DAB)变换器的三重移相(TPS)控制闭环,就像在高速公路上同时操控三辆并排行驶的赛车——任何一个小失误都可能导致系统失控。本文将带您深入理…...

魔兽争霸3终极优化:WarcraftHelper让你的经典游戏在现代电脑上焕然新生
魔兽争霸3终极优化:WarcraftHelper让你的经典游戏在现代电脑上焕然新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3…...