电商-广告投放效果分析(KMeans聚类、数据分析-pyhton数据分析
电商-广告投放效果分析(KMeans聚类、数据分析)
文章目录
- 电商-广告投放效果分析(KMeans聚类、数据分析)
- 项目介绍
- 数据
- 数据维度概况
- 数据13个维度介绍
- 导入库,加载数据
- 数据审查
- 相关性分析
- 数据处理
- 建立模型
- 聚类结果特征分析与展示
- 数据结论
项目介绍
数据
假如公司投放广告的渠道很多,每个渠道的客户性质也可能不同,比如在优酷视频投广告和今日头条投放广告,效果可能会有差异。现在需要对广告效果分析实现有针对性的广告效果测量和优化工作。
本案例,通过各类广告渠道90天内额日均UV,平均注册率、平均搜索率、访问深度、平均停留时长、订单转化率、投放时间、素材类型、广告类型、合作方式、广告尺寸和广告卖点等特征,将渠道分类,找出每类渠道的重点特征,为加下来的业务讨论和数据分析提供支持。
数据维度概况
除了渠道唯一标识,共12个维度,889行,有缺失值,有异常值。
数据13个维度介绍
1、渠道代号:渠道唯一标识
2、日均UV:每天的独立访问量
3、平均注册率=日均注册用户数/平均每日访问量
4、平均搜索量:每个访问的搜索量
5、访问深度:总页面浏览量/平均每天的访问量
6、平均停留时长=总停留时长/平均每天的访问量
7、订单转化率=总订单数量/平均每天的访客量
8、投放时间:每个广告在外投放的天数
9、素材类型:‘jpg’ ‘swf’ ‘gif’ ‘sp’
10、广告类型:banner、tips、不确定、横幅、暂停
11、合作方式:‘roi’ ‘cpc’ ‘cpm’ ‘cpd’
12、广告尺寸:‘14040’ '308388’ ‘450300’ '60090’ ‘480360’ '960126’ ‘900120’ '390270’
13、广告卖点:打折、满减、满赠、秒杀、直降、满返
导入库,加载数据
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler,OneHotEncoder
from sklearn.metrics import silhouette_score # 导入轮廓系数指标
from sklearn.cluster import KMeans # KMeans模块
%matplotlib inline
## 设置属性防止中文乱码
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
以上是加载库的国际惯例,OneHotEncoder是独热编码,如果一个类别特征有n个类别,将该变量按照类别分裂成N维新变量,包含则标记为1,否则为0,用N维特征表示原来的特征。
raw_data = pd.read_csv(r'./ad_performance.csv')
raw_data.head()
-
raw_data = pd.read_csv(r'./ad_performance.csv'):这行代码使用Pandas库的read_csv()函数读取名为 “ad_performance.csv” 的CSV文件中的数据,并将数据加载到名为raw_data的DataFrame对象中。r'./ad_performance.csv'是CSV文件的路径。r表示使用原始字符串,防止反斜杠被转义。 -
raw_data.head():这行代码使用DataFrame对象的head()方法查看DataFrame的前几行数据,默认显示前5行。这有助于了解数据的结构和格式。
数据审查
# 查看基本状态
raw_data.head(2) # 打印输出前2条数据
raw_data.info()# 打印数据类型分布
raw_data.describe().round(2).T # 打印原始数据基本描述性信息
# 缺失值审查
na_cols = raw_data.isnull().any(axis=0) # 查看每一列是否具有缺失值
na_cols
raw_data.isnull().sum().sort_values(ascending=False)# 查看具有缺失值的行总记录数
-
raw_data.head(2):这行代码打印输出了数据的前两条记录,以便快速查看数据的样式和结构。 -
raw_data.info():这行代码打印输出了数据集中每一列的数据类型以及非空值的数量,这有助于了解数据的完整性和类型。 -
raw_data.describe().round(2).T:这行代码打印了数据集的基本描述性信息,包括计数、均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。.round(2)方法用于将描述性统计结果保留两位小数,.T方法用于转置结果,以便查看。 -
na_cols = raw_data.isnull().any(axis=0):这行代码查看了每一列是否具有缺失值。raw_data.isnull()会生成一个布尔值的DataFrame,表示每个单元格是否为缺失值,.any(axis=0)会沿着列方向(axis=0)判断是否有至少一个True,即是否存在缺失值。 -
na_cols:这行代码会输出一个布尔型Series,其中索引是DataFrame的列名,值为True表示该列存在缺失值,值为False表示该列没有缺失值。 -
raw_data.isnull().sum().sort_values(ascending=False):这行代码查看了具有缺失值的列,并统计了每列的缺失值数量,并按照缺失值数量降序排列。.isnull()用于判断每个单元格是否为缺失值,.sum()对每列的缺失值数量进行求和,.sort_values(ascending=False)将结果按照缺失值数量进行降序排序。
相关性分析
# 相关性分析
raw_data.corr(numeric_only=True).round(2).T # 打印原始数据相关性信息
# 相关性可视化展示
import seaborn as sns
corr = raw_data.corr().round(2)
sns.heatmap(corr,cmap='Reds',annot = True)
-
raw_data.corr(numeric_only=True).round(2).T:这行代码计算了原始数据中数值型列之间的相关性,并将结果打印输出。.corr(numeric_only=True)表示只考虑数值型列之间的相关性,.round(2)将相关性系数保留两位小数,.T方法用于转置结果,以便查看。 -
import seaborn as sns:这行代码导入了Seaborn库,用于绘制数据可视化图形。 -
corr = raw_data.corr().round(2):这行代码计算了原始数据的相关性矩阵,并将相关性系数保留两位小数。 -
sns.heatmap(corr,cmap='Reds',annot = True):这行代码绘制了一个热力图来展示相关性矩阵。heatmap()函数用于绘制热力图,corr是相关性矩阵,cmap='Reds'指定了颜色映射为红色调,annot = True表示在图中显示相关性系数的数值。

数据处理
数据了解的差不多了,我们开始时处理数据,把常规数据通过清洗、转换、规约、聚合、抽样等方式变成机器学习可以识别或者提升准确度的数据。
# 1 删除平均平均停留时间列
raw_data2 = raw_data.drop(['平均停留时间'],axis=1)
raw_data2 = raw_data.drop(['平均停留时间'],axis=1):这行代码使用了DataFrame的drop()方法,通过指定'平均停留时间'列和axis=1参数,从原始数据中删除了’平均停留时间’列。删除操作不会在原始数据上进行,而是返回一个新的DataFrame对象,即raw_data2,其中不包含被删除的列。
类别变量的独热编码:
# 类别变量取值
cols=["素材类型","广告类型","合作方式","广告尺寸","广告卖点"]
for x in cols:data=raw_data2[x].unique()print("变量【{0}】的取值有:\n{1}".format(x,data))print("-·"*20)
-
cols=["素材类型","广告类型","合作方式","广告尺寸","广告卖点"]:定义了一个列表cols,其中包含了需要统计取值的类别变量的列名。 -
for x in cols::这是一个循环语句,用于遍历列表cols中的每个元素。 -
data=raw_data2[x].unique():这行代码获取了 DataFrame 中列x(循环变量)的唯一取值,即去除重复后的取值列表。 -
print("变量【{0}】的取值有:\n{1}".format(x,data)):这行代码使用字符串格式化,打印输出了变量x的取值列表。其中{0}和{1}分别被循环变量x和取值列表data所替代。 -
print("-·"*20):这行代码打印了一条分隔线,用于区分不同类别变量的取值统计结果。
# 字符串分类独热编码处理
cols = ['素材类型','广告类型','合作方式','广告尺寸','广告卖点']
model_ohe = OneHotEncoder(sparse=False) # 建立OneHotEncode对象
ohe_matrix = model_ohe.fit_transform(raw_data2[cols]) # 直接转换
print(ohe_matrix[:2])
-
cols = ['素材类型','广告类型','合作方式','广告尺寸','广告卖点']:定义了一个列表cols,其中包含了需要进行独热编码处理的字符串分类变量的列名。 -
model_ohe = OneHotEncoder(sparse=False):这行代码创建了一个OneHotEncoder对象model_ohe,用于进行独热编码处理。sparse=False参数表示不生成稀疏矩阵,而是直接生成密集矩阵。 -
ohe_matrix = model_ohe.fit_transform(raw_data2[cols]):这行代码对原始数据集raw_data2中的cols列进行独热编码处理,得到编码后的矩阵。fit_transform()方法将字符串分类变量转换为独热编码表示。 -
print(ohe_matrix[:2]):这行代码打印输出了独热编码后的矩阵的前两行。这样做是为了查看编码结果是否符合预期。
# 用pandas的方法
ohe_matrix1=pd.get_dummies(raw_data2[cols])
ohe_matrix1.head(5)
-
ohe_matrix1=pd.get_dummies(raw_data2[cols]):这行代码调用了 Pandas 的get_dummies()方法,对原始数据集raw_data2中的cols列进行独热编码处理。get_dummies()方法会将指定列中的每个分类值都转换为一个独热编码的列,并生成一个新的 DataFrame 对象ohe_matrix1。 -
ohe_matrix1.head(5):这行代码打印输出了独热编码后的结果的前 5 行。这样做是为了查看编码结果是否符合预期。
# 数据标准化
sacle_matrix = raw_data2.iloc[:, 1:7] # 获得要转换的矩阵
model_scaler = MinMaxScaler() # 建立MinMaxScaler模型对象
data_scaled = model_scaler.fit_transform(sacle_matrix) # MinMaxScaler标准化处理
print(data_scaled.round(2))
-
sacle_matrix = raw_data2.iloc[:, 1:7]:这行代码从原始数据集raw_data2中提取了需要进行标准化处理的数据子集。iloc[:, 1:7]表示选取所有行,以及第 2 到第 7 列的数据(Python中索引是从0开始的)。 -
model_scaler = MinMaxScaler():这行代码创建了一个MinMaxScaler对象model_scaler,用于进行最小-最大缩放标准化处理。 -
data_scaled = model_scaler.fit_transform(sacle_matrix):这行代码使用fit_transform()方法对提取的数据子集sacle_matrix进行标准化处理,得到标准化后的结果。MinMaxScaler会将每列的数据缩放到指定的范围(默认为[0, 1]),并返回一个标准化后的NumPy数组data_scaled。 -
print(data_scaled.round(2)):这行代码打印输出了标准化后的数据,使用round(2)方法保留两位小数。这样做是为了查看标准化后的数据是否符合预期。
# # 合并所有维度
X = np.hstack((data_scaled, ohe_matrix))
-
np.hstack((data_scaled, ohe_matrix)):这行代码使用了 NumPy 的hstack()函数,将两个矩阵水平堆叠在一起。data_scaled是经过标准化处理后的特征矩阵,ohe_matrix是经过独热编码处理后的特征矩阵。水平堆叠意味着将两个矩阵按列连接起来。 -
X = np.hstack((data_scaled, ohe_matrix)):这行代码将水平堆叠后的矩阵赋值给变量X,这样就得到了合并后的特征矩阵X,其中包含了标准化处理后的数据和独热编码处理后的数据。
建立模型
# 通过平均轮廓系数检验得到最佳KMeans聚类模型
score_list = list() # 用来存储每个K下模型的平局轮廓系数
silhouette_int = -1 # 初始化的平均轮廓系数阀值
for n_clusters in range(2, 8): # 遍历从2到5几个有限组model_kmeans = KMeans(n_clusters=n_clusters) # 建立聚类模型对象labels_tmp = model_kmeans.fit_predict(X) # 训练聚类模型silhouette_tmp = silhouette_score(X, labels_tmp) # 得到每个K下的平均轮廓系数if silhouette_tmp > silhouette_int: # 如果平均轮廓系数更高best_k = n_clusters # 保存K将最好的K存储下来silhouette_int = silhouette_tmp # 保存平均轮廓得分best_kmeans = model_kmeans # 保存模型实例对象cluster_labels_k = labels_tmp # 保存聚类标签score_list.append([n_clusters, silhouette_tmp]) # 将每次K及其得分追加到列表
print('{:*^60}'.format('K值对应的轮廓系数:'))
print(np.array(score_list)) # 打印输出所有K下的详细得分
print('最优的K值是:{0} \n对应的轮廓系数是:{1}'.format(best_k, silhouette_int))
总体思想(评价指标)还是怎么聚才能使得簇内距离足够小,簇与簇之间平均距离足够大来评判。
-
score_list = list():创建一个空列表,用于存储每个K值下模型的平均轮廓系数。 -
silhouette_int = -1:初始化平均轮廓系数的阈值为-1。 -
for n_clusters in range(2, 8)::循环遍历从2到7的整数,这些整数代表了KMeans聚类模型的聚类数。 -
model_kmeans = KMeans(n_clusters=n_clusters):创建一个KMeans聚类模型对象,其中n_clusters参数表示要创建的聚类数。 -
labels_tmp = model_kmeans.fit_predict(X):利用输入数据X对KMeans模型进行训练,并预测每个样本的聚类标签。 -
silhouette_tmp = silhouette_score(X, labels_tmp):计算当前K值下的平均轮廓系数,用来衡量聚类效果的好坏。 -
if silhouette_tmp > silhouette_int::如果当前K值下的平均轮廓系数大于之前的最高值。 -
best_k = n_clusters:更新最佳的K值为当前K值。 -
silhouette_int = silhouette_tmp:更新最高的平均轮廓系数为当前轮廓系数。 -
best_kmeans = model_kmeans:保存当前最佳的KMeans聚类模型对象。 -
cluster_labels_k = labels_tmp:保存当前最佳的聚类标签。 -
score_list.append([n_clusters, silhouette_tmp]):将当前K值和对应的平均轮廓系数追加到列表score_list中。 -
print('{:*^60}'.format('K值对应的轮廓系数:')):打印输出一个60个星号的分割线。 -
print(np.array(score_list)):打印输出所有K值及其对应的平均轮廓系数。 -
print('最优的K值是:{0} \n对应的轮廓系数是:{1}'.format(best_k, silhouette_int)):打印输出最佳的K值和对应的平均轮廓系数。
聚类结果特征分析与展示
通过上面模型,我们其实给每个观测(样本)打了个标签clusters,即他属于4类中的哪一类:
# 将原始数据与聚类标签整合
cluster_labels = pd.DataFrame(cluster_labels_k, columns=['clusters']) # 获得训练集下的标签信息
merge_data = pd.concat((raw_data2, cluster_labels), axis=1) # 将原始处理过的数据跟聚类标签整合
merge_data.head()
-
cluster_labels = pd.DataFrame(cluster_labels_k, columns=['clusters']):这行代码创建了一个名为cluster_labels的DataFrame对象,其中包含了聚类模型预测得到的聚类标签信息。cluster_labels_k是之前代码中得到的聚类标签数据,columns=['clusters']指定了DataFrame的列名为’clusters’。 -
merge_data = pd.concat((raw_data2, cluster_labels), axis=1):这行代码使用了 Pandas 的concat()函数,将原始处理过的数据raw_data2与聚类标签数据cluster_labels沿着列方向(axis=1)进行合并。合并后的结果赋值给变量merge_data。 -
merge_data.head():这行代码打印输出了合并后的DataFrame的前几行数据。这样做是为了查看整合后的数据是否符合预期。
然后看看,每个类别下的样本数量和占比情况:
# 计算每个聚类类别下的样本量和样本占比
clustering_count = pd.DataFrame(merge_data['渠道代号'].groupby(merge_data['clusters']).count()).T.rename({'渠道代号': 'counts'}) # 计算每个聚类类别的样本量
clustering_ratio = (clustering_count / len(merge_data)).round(2).rename({'counts': 'percentage'}) # 计算每个聚类类别的样本量占比
print(clustering_count)
print("#"*30)
print(clustering_ratio)
-
clustering_count = pd.DataFrame(merge_data['渠道代号'].groupby(merge_data['clusters']).count()).T.rename({'渠道代号': 'counts'}):这行代码首先使用 Pandas 的groupby()函数按照聚类标签clusters对渠道代号这一列进行分组,然后对每个组计算该列的计数。结果是一个包含每个聚类类别下的样本量的 Series 对象。接着使用pd.DataFrame()将其转换为 DataFrame,并进行转置(.T)操作,以使行和列对调。最后使用rename()函数将列名渠道代号更改为counts,以反映其含义。 -
clustering_ratio = (clustering_count / len(merge_data)).round(2).rename({'counts': 'percentage'}):这行代码计算每个聚类类别的样本量占比。首先将每个聚类类别的样本量除以总样本量,然后使用round(2)方法将结果保留两位小数。接着使用rename()函数将列名counts更改为percentage,以反映其含义。 -
print(clustering_count):打印输出每个聚类类别下的样本量。 -
print("#"*30):打印输出一个包含30个 ‘#’ 字符的分隔线。 -
print(clustering_ratio):打印输出每个聚类类别的样本量占比。
每个类别内部最显著的特征:
# 计算各个聚类类别内部最显著特征值
cluster_features = [] # 空列表,用于存储最终合并后的所有特征信息
for line in range(best_k): # 读取每个类索引label_data = merge_data[merge_data['clusters'] == line] # 获得特定类的数据part1_data = label_data.iloc[:, 1:7] # 获得数值型数据特征part1_desc = part1_data.describe().round(3) # 得到数值型特征的描述性统计信息merge_data1 = part1_desc.iloc[2, :] # 得到数值型特征的均值part2_data = label_data.iloc[:, 7:-1] # 获得字符串型数据特征part2_desc = part2_data.describe(include='all') # 获得字符串型数据特征的描述性统计信息merge_data2 = part2_desc.iloc[2, :] # 获得字符串型数据特征的最频繁值merge_line = pd.concat((merge_data1, merge_data2), axis=0) # 将数值型和字符串型典型特征沿行合并cluster_features.append(merge_line) # 将每个类别下的数据特征追加到列表# 输出完整的类别特征信息
cluster_pd = pd.DataFrame(cluster_features).T # 将列表转化为矩阵
print('{:*^60}'.format('每个类别主要的特征:'))
all_cluster_set = pd.concat((clustering_count, clustering_ratio, cluster_pd),axis=0) # 将每个聚类类别的所有信息合并
all_cluster_set
-
cluster_features = []:创建一个空列表,用于存储每个聚类类别内部最显著的特征值。 -
for line in range(best_k)::循环遍历每个聚类类别的索引。 -
label_data = merge_data[merge_data['clusters'] == line]:获取特定聚类类别的数据,即通过筛选出'clusters'列值等于当前索引值的行。 -
part1_data = label_data.iloc[:, 1:7]和part2_data = label_data.iloc[:, 7:-1]:分别提取数值型特征和字符串型特征的数据子集。 -
part1_desc = part1_data.describe().round(3)和part2_desc = part2_data.describe(include='all'):分别计算数值型特征和字符串型特征的描述性统计信息。 -
merge_data1 = part1_desc.iloc[2, :]和merge_data2 = part2_desc.iloc[2, :]:分别获取数值型特征和字符串型特征的均值(数值型特征)或最频繁值(字符串型特征)。 -
merge_line = pd.concat((merge_data1, merge_data2), axis=0):将数值型特征和字符串型特征沿行方向合并为一个Series对象。 -
cluster_features.append(merge_line):将每个类别下的数据特征追加到列表cluster_features中。 -
cluster_pd = pd.DataFrame(cluster_features).T:将列表cluster_features转换为DataFrame对象,转置以便特征信息按列排列。 -
all_cluster_set = pd.concat((clustering_count, clustering_ratio, cluster_pd),axis=0):将聚类类别的样本量、样本占比和主要特征值信息沿着行方向合并为一个DataFrame对象all_cluster_set。 -
print('{:*^60}'.format('每个类别主要的特征:')):打印输出一个包含60个星号的标题行,用于分隔不同部分的输出。 -
print(all_cluster_set):打印输出合并后的聚类类别的所有信息,包括样本量、样本占比和主要特征值信息。
图形化输出:
#各类别数据预处理
num_sets = cluster_pd.iloc[:6, :].T.astype(np.float64) # 获取要展示的数据
num_sets_max_min = model_scaler.fit_transform(num_sets) # 获得标准化后的数据
print(num_sets)
print('-'*20)
print(num_sets_max_min)
-
num_sets = cluster_pd.iloc[:6, :].T.astype(np.float64):这行代码从合并后的聚类类别特征数据cluster_pd中提取了前6行(即数值型特征)的转置,并将其转换为np.float64类型的数据。这样做是为了将数据按列排列,方便后续处理。 -
num_sets_max_min = model_scaler.fit_transform(num_sets):这行代码利用之前创建的MinMaxScaler对象model_scaler对数值型特征数据进行标准化处理。使用fit_transform()方法对数据进行标准化,将数据缩放到[0, 1]的范围内。 -
print(num_sets):打印输出原始的数值型特征数据,用于查看。 -
print('-'*20):打印输出一行分隔线。 -
print(num_sets_max_min):打印输出标准化后的数值型特征数据,用于查看。
# 画图
fig = plt.figure(figsize=(7,7)) # 建立画布
ax = fig.add_subplot(111, polar=True) # 增加子网格,注意polar参数
labels = np.array(merge_data1.index) # 设置要展示的数据标签
cor_list = ['g', 'r', 'y', 'b'] # 定义不同类别的颜色
angles = np.linspace(0, 2 * np.pi, len(labels), endpoint=False) # 计算各个区间的角度
angles = np.concatenate((angles, [angles[0]])) # 建立相同首尾字段以便于闭合
# 画雷达图
for i in range(len(num_sets)): # 循环每个类别data_tmp = num_sets_max_min[i, :] # 获得对应类数据data = np.concatenate((data_tmp, [data_tmp[0]])) # 建立相同首尾字段以便于闭合ax.plot(angles, data, 'o-', c=cor_list[i], label="第%d类渠道"%(i)) # 画线ax.fill(angles, data,alpha=0.8)# 设置图像显示格式
print(angles)
print(labels)ax.set_thetagrids(angles[0:-1] * 180 / np.pi, labels, fontproperties="SimHei") # 设置极坐标轴
ax.set_title("各聚类类别显著特征对比", fontproperties="SimHei") # 设置标题放置
ax.set_rlim(-0.2, 1.2) # 设置坐标轴尺度范围
plt.legend(loc="upper right" ,bbox_to_anchor=(1.2,1.0)) # 设置图例位置
-
fig = plt.figure(figsize=(7,7)):创建一个大小为7x7的画布。 -
ax = fig.add_subplot(111, polar=True):在画布上添加一个极坐标子网格,参数polar=True表示使用极坐标。 -
labels = np.array(merge_data1.index):将聚类类别的特征名称作为要展示的数据标签。 -
cor_list = ['g', 'r', 'y', 'b']:定义不同类别的颜色。 -
angles = np.linspace(0, 2 * np.pi, len(labels), endpoint=False):计算各个特征区间的角度。 -
angles = np.concatenate((angles, [angles[0]])):建立相同首尾字段以便于闭合。 -
for i in range(len(num_sets))::遍历每个聚类类别。 -
data_tmp = num_sets_max_min[i, :]:获取当前聚类类别对应的标准化后的特征数据。 -
data = np.concatenate((data_tmp, [data_tmp[0]])):建立相同首尾字段以便于闭合。 -
ax.plot(angles, data, 'o-', c=cor_list[i], label="第%d类渠道"%(i)):绘制雷达图,表示各个特征在当前聚类类别下的数值,使用不同颜色区分不同类别。 -
ax.fill(angles, data,alpha=0.8):填充雷达图的闭合区域,以加强可视化效果。 -
ax.set_thetagrids(angles[0:-1] * 180 / np.pi, labels, fontproperties="SimHei"):设置极坐标轴的刻度标签和标签文字。 -
ax.set_title("各聚类类别显著特征对比", fontproperties="SimHei"):设置雷达图的标题。 -
ax.set_rlim(-0.2, 1.2):设置雷达图的坐标轴尺度范围。 -
plt.legend(loc="upper right" ,bbox_to_anchor=(1.2,1.0)):设置图例的位置,将图例放在图的右上角。

数据结论
从案例结果来看,所有的渠道被分为4各类别,每个类别的样本量分别为:154、313、349 、73,对应占比分别为:17%、35%、39%、8%。
通过雷达图可以清楚的知道:
类别1(索引为2类的渠道) 这类广告媒体除了访问深度和投放时间较高,其他属性较低,因此这类广告媒体效果质量较差,并且占到39%,因此这类是主题渠道之一。 业务部门要考虑他的实际投放价值。
类别2(索引为1类的渠道) 这类广告媒体除了访问深度略差,在平均搜索量、日均UV、订单转化率等广告效果指标上表现良好,是一类综合效果较好的渠道。 但是日均UV是短板,较低。无法给企业带来大量的流量以及新用户,这类广告的特质适合用户转化,尤其是有关订单的转化提升。
类别3(索引为0类的渠道) 这类广告媒体的显著特征是日均UV和注册率较高,其“引流”和“拉新”效果好,可以在广告媒体中定位为引流角色。 符合“广而告之”的诉求,适合“拉新”使用。
类别4(索引为3类的渠道) 这类渠道各方面特征都不明显,各个流量质量和流量数量的指标均处于“中等”层次。不突出但是均衡,考虑在各场景下可以考虑在这个渠道投放广告。
相关文章:
电商-广告投放效果分析(KMeans聚类、数据分析-pyhton数据分析
电商-广告投放效果分析(KMeans聚类、数据分析) 文章目录 电商-广告投放效果分析(KMeans聚类、数据分析)项目介绍数据数据维度概况数据13个维度介绍 导入库,加载数据数据审查相关性分析数据处理建立模型聚类结果特征分析…...
练习 16 Web [极客大挑战 2019]LoveSQL
extractvalue(1,concat(‘~’, (‘your sql’) ) )报错注入,注意爆破字段的时候表名有可能是table_name不是table_schema 有登录输入框 常规尝试一下 常规的万能密码,返回了一个“admin的密码”: Hello admin! Your password is…...
C++——栈和队列容器
前言:这篇文章我们将栈和队列两个容器放在一起进行分享,因为这两个要分享的知识较少,而且两者在结构上有很多相似之处,比如栈只能在栈顶操作,队列只能在队头和队尾操作。 不同于前边所分享的三种容器,这篇…...

Java集合(个人整理笔记)
目录 1. 常见的集合有哪些? 2. 线程安全的集合有哪些?线程不安全的呢? 3. Arraylist与 LinkedList 异同点? 4. ArrayList 与 Vector 区别? 5. Array 和 ArrayList 有什么区别?什么时候该应 Array而不是…...
Redis -- 缓存穿透问题解决思路
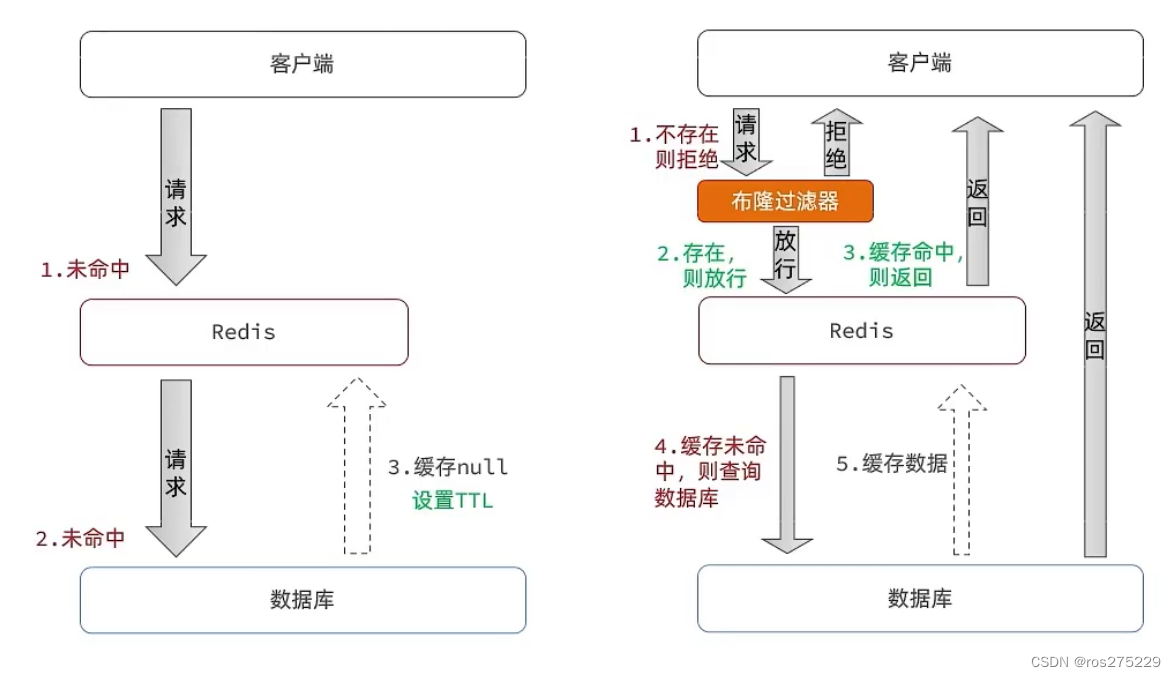
缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。 常见的解决方案有两种: 缓存空对象 优点:实现简单,维护方便 缺点: 额外…...
数据挖掘中的PCA和KMeans:Airbnb房源案例研究
目录 一、PCA简介 二、数据集概览 三、数据预处理步骤 四、PCA申请 五、KMeans 聚类 六、PCA成分分析 七、逆变换 八、质心分析 九、结论 十、深入探究 10.1 第 1 步:确定 PCA 组件的最佳数量 10.2 第 2 步:使用 9 个组件重做 PCA 10.3 解释 PCA 加载和特…...

【ArcGIS微课1000例】0107:ArcGIS加载在线历史影像服务WMTS
文章目录 一、WMTS历史影像介绍二、ArcGIS加载WMTS服务三、Globalmapper加载WMTS服务一、WMTS历史影像介绍 通过访问历史影响WMTS服务,可以将全球范围内历史影像加载进来,如下所示: WMTS服务: https://wayback.maptiles.arcgis.com/arcgis/rest/services/World_Imagery/WM…...

IP归属地在互联网行业中的应用
摘要:IP(Internet Protocol)地址归属地是指互联网上某个IP地址所对应的地理位置信息。在互联网行业中,IP归属地具有重要的应用价值,包括网络安全、广告定向、用户定位等方面。IP数据云将探讨IP归属地在互联网行业中的应…...

非关系型数据库-----------探索 Redis高可用 、持久化、性能管理
目录 一、Redis 高可用 1.1什么是高可用 1.2Redis的高可用技术 二、 Redis 持久化 2.1持久化的功能 2.2Redis 提供两种方式进行持久化 三、Redis 持久化之----------RDB 3.1触发条件 3.1.1手动触发 3.1.2自动触发 3.1.3其他自动触发机制 3.2执行流程 3.3启动时加载…...

每日一题:三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组。 示例 1…...
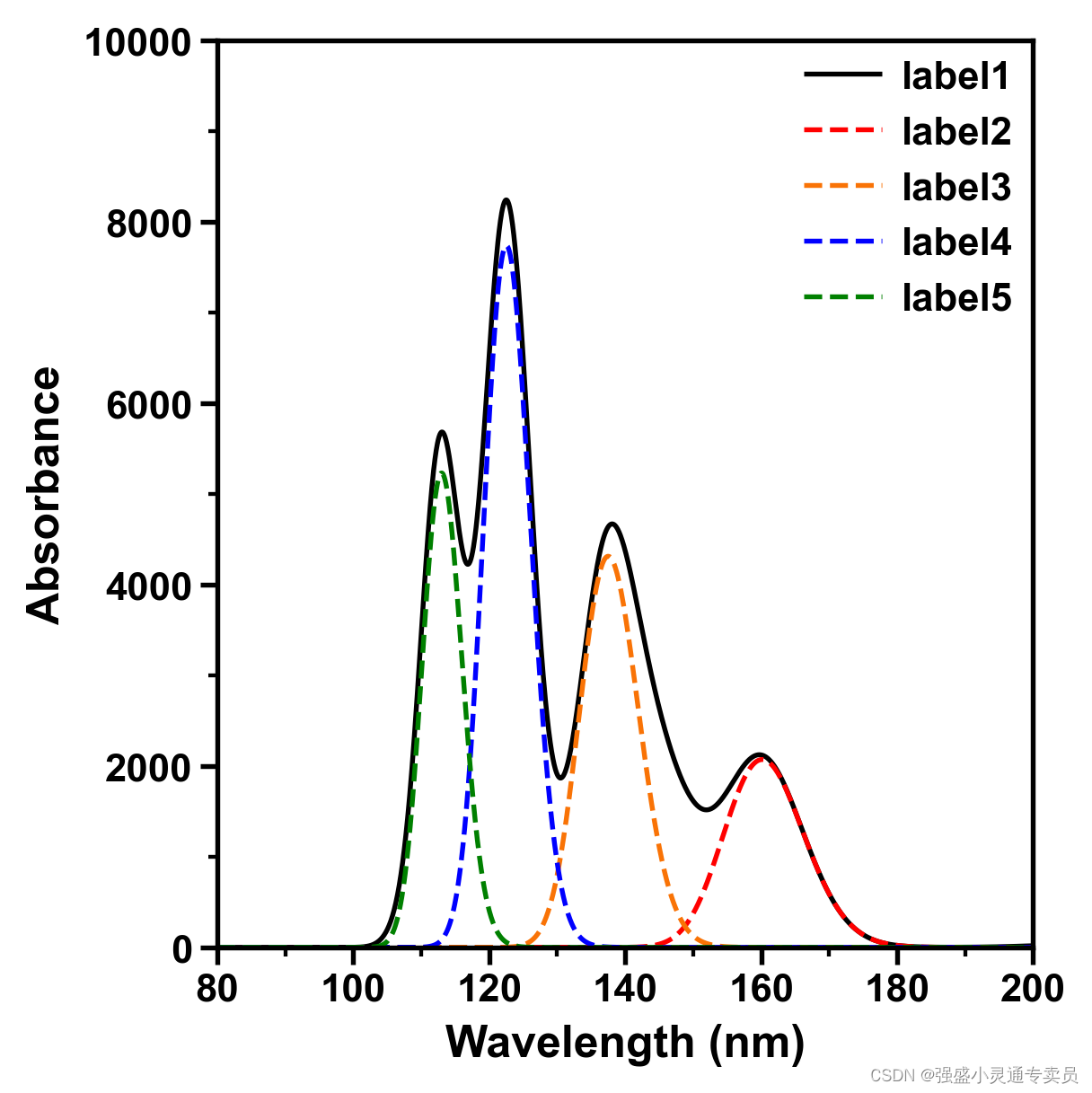
【SCI绘图】【曲线图系列2 python】多类别标签对比的曲线图
SCI,CCF,EI及核心期刊绘图宝典,爆款持续更新,助力科研! 本期分享: 【SCI绘图】【曲线图系列2 python】多类别标签对比的曲线图,文末附完整代码。 1.环境准备 python 3 import proplot as pp…...
达梦DMHS-Manager工具安装部署
目录 1、前言 1.1、平台架构 1.2、平台原理 2、环境准备 2.1、硬件环境 2.2、软件环境 2.3、安装DMHS 2.3.1、源端DMHS前期准备 2.3.2、源端DMHS安装 2.3.3、目的端DMHS安装 3、DMHS-Manager客户端部署 3.1、启动dmhs web服务 3.2、登录web管理平台 4、添加DMHS实…...

Marketo营销自动化集成Zoho CRM
Marketo 本身是一种营销自动化工具,可让您根据指定的标准对潜在客户进行评分,并确定哪些潜在客户最有可能进行转化。 CRM 和 Marketo 之间的紧密集成可帮助您规划销售和营销活动,以培育这些高价值潜在客户并最大限度地提高您的团队可以赢得的…...

【Leetcode每日一题】模拟 - 外观数列(难度⭐⭐)(51)
1. 题目解析 题目链接:38. 外观数列 这个问题的理解其实相当简单,只需看一下示例,基本就能明白其含义了。 2.算法原理 所谓“外观数列”,其实只是依次统计字符串中连续且相同的字符的个数。依照题意,依次模拟即 可。…...
CMakeLists.txt编写简单介绍:CMakeLists.txt同时编译.cpp和.cu
关于CMakeLists.txt的相关介绍,这里不赘诉,本人的出发点是借助于CMakeLists.txt掌握基本的C++构建项目流程,下面是本人根据网络资料以及个人实践掌握的资料。 CMakeList.txt构建C++项目 下图是一个使用CUDA实现hello world的项目,一般来说,一个标准的C++项目包括三个文件…...

MSSQL有关数据库、表的循环操作可使用的存储过程 sp_MSforeachdb 及 sp_MSforeachtable
MSSQL有关数据库、表的循环操作可使用的存储过程: 1. sp_MSforeachdb command1print ?, command2DBCC CHECKDB(?) --检查所有的数据库 2. sp_MSforeachtable command1print ?, command2sp_spaceused ? --统计各个表的空间使用情况 【说明】sys.sp_MSforeachdb 和 …...
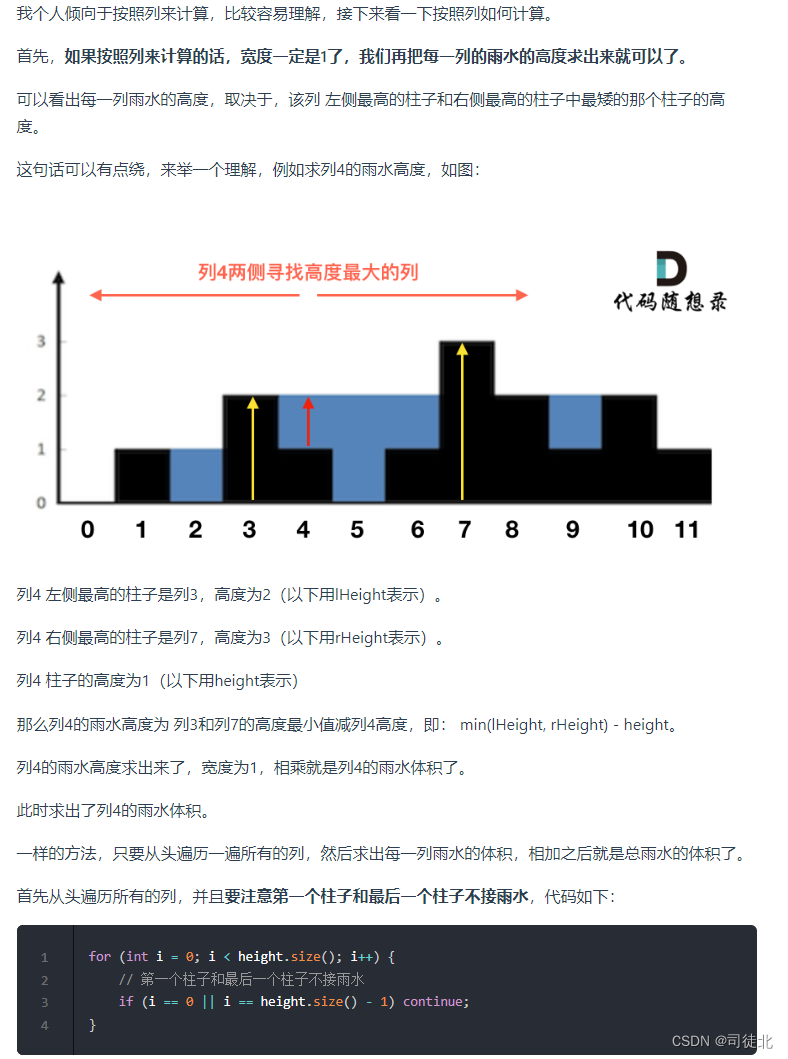
day63 单调栈part02
503. 下一个更大元素 II 中等 给定一个循环数组 nums ( nums[nums.length - 1] 的下一个元素是 nums[0] ),返回 nums 中每个元素的 下一个更大元素 。 数字 x 的 下一个更大的元素 是按数组遍历顺序,这个数字之后的第一个比它更…...

上市公司股权性质演变:2000-2022年集中度数据深度剖析(5W+数据)
01、数据介绍 股权性质主要指的是股份公司中不同性质的股东即股权所有人的身份,以及他们各自持有的股份比例。在我国,股权性质通常涉及国家股东、法人股东(包括机构投资者)和流通股东等。 股权集中度则是反映公司股东对管理者的…...
安装Redis Windows版
一、安装Redis Windows版 1.1、下载安装包 官网:https://github.com/microsoftarchive/redis/releases 我分享的链接: 链接:https://pan.baidu.com/s/1Lg-b_k02XO6UAXMHxGD0FA?pwdyyds 提取码:yyds 1.2、安装 (1&a…...

用 ipset 和 iptables 保护 sip 端口
这里先假定 sip 端口是 5060 和 5080 cat china.sh,and ./china.sh #!/bin/bash apt install -y ipset ipset destroy china ipset create china hash:net maxelem 65536 ipset flush china wget --no-check-certificate -O- http://ftp.apnic.net/apnic/stats/apn…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

OpenClaw 连接阿里云百炼图文教程
OpenClaw 连接阿里云百炼图文教程 前置准备 已安装并可以正常打开 OpenClaw Windows。 OpenClaw 顶部 Gateway 状态保持在线。 已准备好可正常登录的阿里云账号。 可以正常访问阿里云百炼登录地址:https://bailian.console.aliyun.com/cn-beijing#/home 建议提…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

中兴光猫终极管理指南:解锁工厂模式与Telnet权限的实战教程
中兴光猫终极管理指南:解锁工厂模式与Telnet权限的实战教程 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 掌握中兴光猫的设备管理和权限获取能力是网络管理员和技术爱好者…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...
)
Allegro PCB设计小技巧:如何让Route Keepout区域既能走线又能打过孔(附详细步骤图)
Allegro PCB设计实战:Route Keepout区域的灵活控制技巧 在高速PCB设计中,Route Keepout区域的管理常常让工程师陷入两难境地——元件封装自带的限制区域与实际布线需求产生冲突。特别是处理PCIE等高速信号时,这种矛盾尤为突出。传统做法要么完…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

【数据结构与算法】数据结构基础——栈和队列
目录栈和队列1. 栈1.1 栈的概念1.2 栈的实现方式分析1.3 栈的实现1.3.1 栈的初始化与销毁1.3.2 入栈与出栈1.3.3 栈的判空与有效元素个数1.3.4 栈顶元素1.4 栈的扩展1.4.1 两栈共享空间2. 队列2.1 队列的概念2.2 队列的实现方式分析2.3 队列的实现2.3.1 队列的初始化与销毁2.3.…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...