C/C++预处理过程

目录
前言:
1. 预定义符号
2. #define定义常量
3. #define定义宏
4. 带有副作用的宏参数
5. 宏替换的规则
6. 宏和函数的对比
7. #和##
8. 命名约定
9. #undef
10. 命令行定义
11. 条件编译
12. 头文件的包含
13. 其他预处理指令
总结:。
前言:
本篇介绍c/c++的预处理过程,c和c++在预处理阶段基本相同。
1. 预定义符号
c语言定义了一些预处理的符号,这些是可以直接使用的,并且这些符号也是在预处理期间完成的。
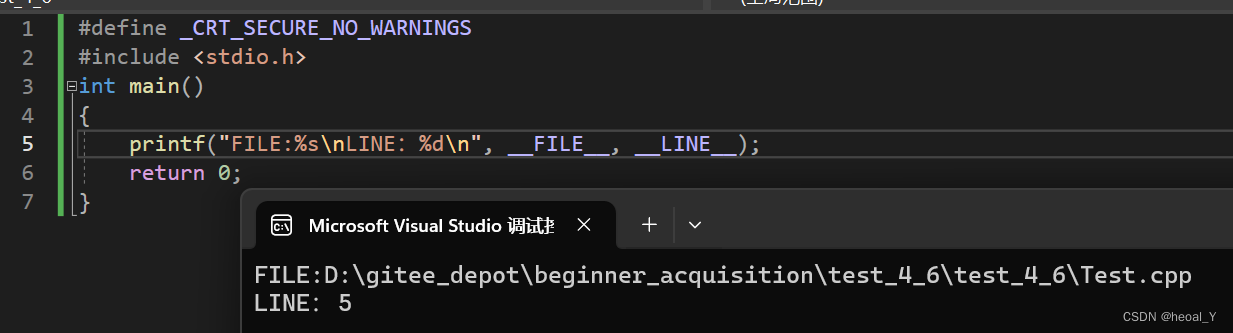
- __FILE__ //进⾏编译的源⽂件
- __LINE__ //⽂件当前的⾏号
- __DATE__ //⽂件被编译的⽇期
- __TIME__ //⽂件被编译的时间
- __STDC__ //如果编译器遵循ANSI C,其值为1,否则未定义
2. #define定义常量
例如我们定义100为一个MAX,后面使用MAX都会在预处理阶段替换为100。
#define MAX 100
如果我们觉得定义的东西太长了,也可以分行写,在结尾加上反斜杠\即可:
#define DEBUG_PRINT printf("file:%s\tline:%d\t \date:%s\ttime:%s\n" ,\__FILE__,__LINE__ , \__DATE__,__TIME__ )
现在来考虑一个问题:
在定义常量的时候,要不要加上引号???
#define MAX 1000;
#define MAX 1000其实通过#define的性质就可以知道,它在预处理阶段做的只是替换工作,如果将代码放到下面的情况下就会出错:
if(condition)max = MAX;
elsemax = 0;这样if后面就是两条语句了,而由于if如果不加大括号匹配的只有一条语句,所以这样else就没法匹配了,就出错了。
3. #define定义宏
#define机制包括了一个规定,允许把参数替换到文本中,这种实现通常称为宏(macro)或定义宏(define macro)。
语法为:
#define name( parameter-list ) stuff注意参数列表的括号必须要与name之间没有空格,不然参数列表就被识别为右边的内容了。
例如我们现在实现一个宏来实现乘法:
#define SQUARE( x ) x * x可这样能表达我们想要的意思吗???
我们要注意宏仅仅是替换,所以在打印下面的情况下,就会出错:
int a = 5;printf("%d\n", SQUARE(a + 1));//结果是11
我们想表达的是(5+1)*(5+1),而结果却是11,这就是因为宏仅仅是替换,只是替换为了a+1*a+1,所以我们加上扩号就能达到预期的效果了。
#define SQUARE(x) (x)*(x)
可这就完了吗?来看下面的代码,我们使用宏了实现一个相加:
#define DOUBLE(x) (x) + (x)看着我们好像加上了括号好像就不会出现问题了,但是如果是下面的场景:
int a = 5;
printf("%d\n" ,10 * DOUBLE(a));//结果是55,而我们预期的是100这是因为预处理阶段,宏被替换成了10*(5)+(5),所以我们还需要再加上一个括号:
1 #define DOUBLE( x) ( ( x ) + ( x ) )所以我们得出结论:
4. 带有副作用的宏参数
#define MAX(a, b) ( (a) > (b) ? (a) : (b) )
int x = 5;int y = 8;int z = MAX(x++, y++);printf("x=%d y=%d z=%d\n", x, y, z);
这样带有自增自减的是具有副作用的,再给宏传参就出错了。
结果是 x=6,y=10,z=9(尽管最后执行的是z=(y++),后置++--改变的是自己,返回的是一个没有改变的值,所以这里z是9),这样的结果不仅对xyz进行了永久性的改变,而且比较是也不是预期的结果。
所以当宏参数在宏的定义时出现超过了一次(就像上面的案例),如果参数带有副作用,也就是自增自减类的,此时使用宏就可能出错。
5. 宏替换的规则
注意:1. 宏参数和#define 定义中可以出现其他#define定义的符号。但是对于宏,不能出现递归。#define string1 string #define string "1abcd"printf("%s\n", string);printf("%s\n", string1);2. 当预处理器搜索#define定义的符号的时候,字符串常量的内容并不被搜索,也就是说定义的符号不能是字符串常量。
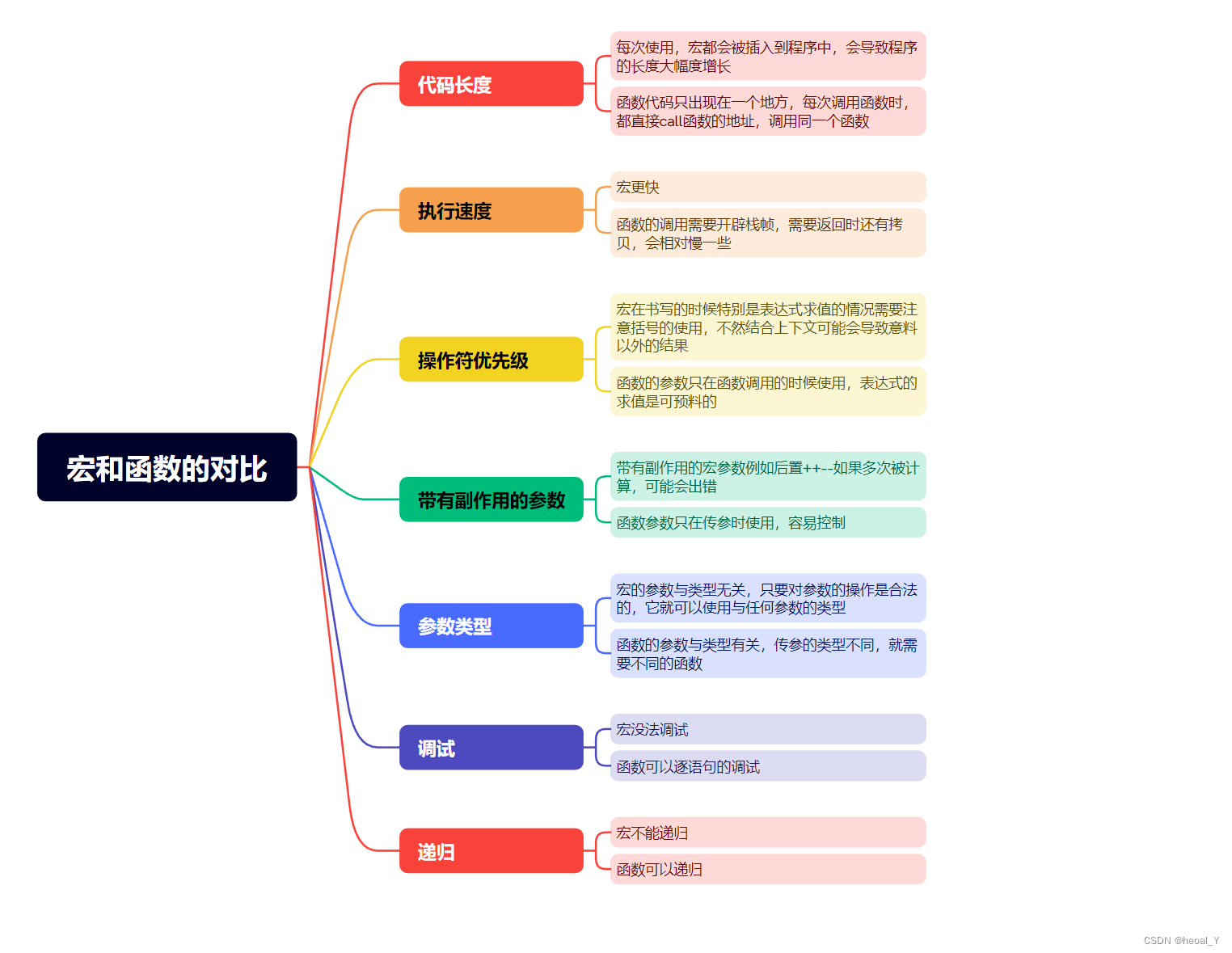
6. 宏和函数的对比
宏通常用来执行简单的计算。比如在两个数中找出一个较大的时,写成下面的宏,更有优势:
#define MAX(a, b) ((a)>(b)?(a):(b))为什么不用函数来实现呢?
1.
用于调用函数和从函数返回的代码可能比实际执行这个小型计算工作所需要的时间更多。所以宏比函数在程序的规模和速度方面更胜⼀筹。2.更为重要的是函数的参数必须声明为特定的类型。所以函数只能在类型合适的表达式上使用。反之这个宏可以适用于整形、长整型、浮点型等可以用于 > 来比较的类型。宏的参数是类型无关。
但是相比函数,宏也有它的劣势:
1. 每次使用宏的时候,一份宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序的长度。2. 宏是没法调试的。3. 宏由于类型无关,也就不够严谨。4. 宏可能会带来运算符优先级的问题,导致程容易出现错。
但其实宏也可以做到函数做不到的事情,例如宏的参数可以出现类型,但是函数做不到:
#define MALLOC(num, type)\(type*)malloc(num*sizeof(type))//使⽤MALLOC(10, int);//类型作为参数
//预处理器替换之后:(int*)malloc(10*sizeof(int));宏和函数的对比:
7. #和##
#运算符是将宏的一个参数转换为字符串字面量,它运行出现在带参数的宏的替换列表中。
#define PRINT(n) printf("the value of "#n " is %d", n);如果定义有一个a为10,现在使用宏传a过去,就打印出来the value of a is 10 ,注意这里#n要加上一个引号,不然就被识别为printf打印的内容了,就直接打印出来一个#n,而不是预处理得到的了。 就理解为如果#n要在printf里识别为字符串,就要加上""。而直接这样使用就不用:
#define PRINT(n) #nint a=10;
printf("%s\n",PRINT(a));//结果是a##运算符
//宏定义
#define GENERIC_MAX(type) \
type type##_max(type x, type y)\
{ \return (x>y?x:y); \
}GENERIC_MAX(int) //替换到宏体内后int##_max ⽣成了新的符号 int_max做函数名
GENERIC_MAX(float) //替换到宏体内后float##_max ⽣成了新的符号 float_max做函数名int main()
{//调⽤函数int m = int_max(2, 3);printf("%d\n", m);float fm = float_max(3.5f, 4.5f);printf("%f\n", fm);return 0;
}实际用的很少,不再过多解释。
8. 命名约定
一般来说函数和宏的使用语法是很相似的,所以语言本身没法帮我们区分二者。
所以命名习惯就是:
宏名全部大写,函数名不要全部大写。
9. #undef
用于移除一个宏定义。
#undef NAME
//如果现存的⼀个名字需要被重新定义,那么它的旧名字⾸先要被移除。10. 命令行定义
#include <stdio.h>
int main()
{int array [ARRAY_SIZE];int i = 0;for(i = 0; i< ARRAY_SIZE; i ++){array[i] = i;}for(i = 0; i< ARRAY_SIZE; i ++){printf("%d " ,array[i]);}printf("\n" );return 0;
}//linux 环境演⽰
gcc -D ARRAY_SIZE=10 programe.c
11. 条件编译
#include <stdio.h>
#define __DEBUG__
int main()
{int i = 0;int arr[10] = { 0 };for (i = 0; i < 10; i++){arr[i] = i;
#ifdef __DEBUG__printf("%d\n", arr[i]);//为了观察数组是否赋值成功。
#endif //__DEBUG__}return 0;
}如果我们不定义__DEBUG__这个宏,就什么也不会输出。
常见的条件编译指令:
1.
#if 常量表达式//...
#endif
//常量表达式由预处理器求值。
如:
#define __DEBUG__ 1
#if __DEBUG__//..
#endif
2.多个分⽀的条件编译
#if 常量表达式//...
#elif 常量表达式//...
#else//...
#endif
3.判断是否被定义
#if defined(symbol)
#ifdef symbol
#if !defined(symbol)
#ifndef symbol
4.嵌套指令
#if defined(OS_UNIX)#ifdef OPTION1unix_version_option1();
#endif#ifdef OPTION2unix_version_option2();#endif
#elif defined(OS_MSDOS)#ifdef OPTION2msdos_version_option2();#endif
#endif
12. 头文件的包含
首先,查找策略:
linux下标准头文件的路径:
/usr/includewindows下(按照自己的安装路径去找):
C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\include然后就是库文件的包含:
1 #include <filename.h>当然库文件也可以使用""的形式包含,答案是可以的,但是这样不容易区分是库文件还是本地文件,查找的效率会低(尖括号是到系统路径下查找头文件,双引号是先在当前目录下查找头文件,如果没有找到,就再到系统的路径下去找)。
嵌套文件的包含:
#include的替换方式就是预处理器先删除这条指令,并用包含文件的内容替换,但如果一个头文件被包含了10次,那实际就被编译了10次,如果重复包含,对编译的压力就会比较大,因为.h的文件会将内容拷贝10分到.c文件中去,这样预处理后代码量就会激增。如果有工程比较大,用公共使用的头文件,被大家都能使用,又不做处理,工程量会非常大。
如何解决?使用条件编译:
可以在每个头文件中的开头写:
#ifndef __TEST_H__
#define __TEST_H__//头⽂件的内容#endif //__TEST_H__,写在头文件结尾也就是如果.h文件第一次被包含,此时__TEST_H__还没有被定义,所以执行#ifdef与#endif之间的代码,再次包含时,条件为假,因为以及有__TEST_H__的定义了,所以直接走到#endif,也就是什么也不执行。
或者
#pragma once13. 其他预处理指令
#error
#pragma
#line
......具体可以用到的时候再查。
总结:
对于一些预处理阶段的一些不常用的可以选择性学习,但要知道,重点关注面试题相关的。
相关文章:
C/C++预处理过程
目录 前言: 1. 预定义符号 2. #define定义常量 3. #define定义宏 4. 带有副作用的宏参数 5. 宏替换的规则 6. 宏和函数的对比 7. #和## 8. 命名约定 9. #undef 10. 命令行定义 11. 条件编译 12. 头文件的包含 13. 其他预处理指令 总结&#x…...

客服电话系统:专业、便捷的服务沟通桥梁
一、引言 1.客服电话系统在现代服务中的重要性 在信息化时代,服务行业的竞争日益激烈,提供高效、便捷的服务成为企业赢得市场、获取用户信任的关键。客服电话系统作为企业与用户之间的重要沟通桥梁,不仅承载着解答疑问、处理问题的职责&…...
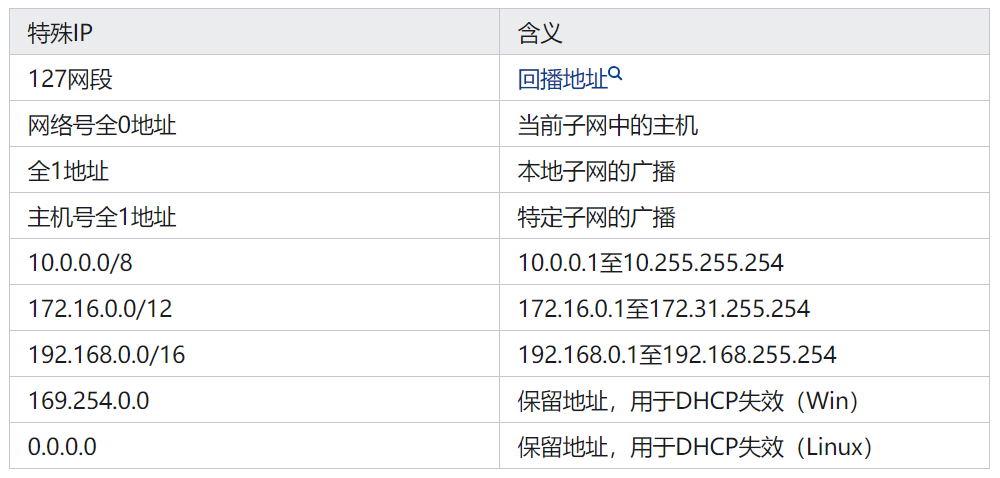
IP地址与子网掩码
1 IP地址 1.1 IPv4与IPv6 1.2 IPv4地址详解 IPv4地址分4段,每段8位,共32位二进制数组成。 1.2.1 地址分类 这32位又被分为网络号和主机号两部分,根据网络号占用位数的不同,又可分为以下几类: A类地址:…...

Python爬取公众号封面图(零基础也能看懂)
📚博客主页:knighthood2001 ✨公众号:认知up吧 (目前正在带领大家一起提升认知,感兴趣可以来围观一下) 🎃知识星球:【认知up吧|成长|副业】介绍 ❤️感谢大家点赞👍&…...

2024.4.6学习笔记
今日学习韩顺平java0200_韩顺平Java_对象机制练习_哔哩哔哩_bilibili 今日学习p315-p328 动态绑定机制 当调用方法对象的时候,该方法会和该对象的内存地址/运行类型绑定 当调用对象属性时,没有动态绑定机制,哪里声明,哪里使用 …...
)
2024年华为OD机试真题-查找一个有向网络的头节点和尾节点-Java-OD统一考试(C卷)
题目描述: 给定一个有向图,图中可能包含有环,图使用二维矩阵表示,每一行的第一列表示起始节点,第二列表示终止节点,如[0, 1]表示从0到1的路径。每个节点用正整数表示。求这个数据的首节点与尾节点,题目给的用例会是一个首节点,但可能存在多个尾节点。同时,图中可能含有…...
【Django开发】0到1美多商城项目md教程第5篇:短信验证码,1. 避免频繁发送短信验证码逻辑分析【附代码文档】
美多商城完整教程(附代码资料)主要内容讲述:欢迎来到美多商城!,项目准备。展示用户注册页面,创建用户模块子应用。用户注册业务实现,用户注册前端逻辑。图形验证码,图形验证码接口设…...
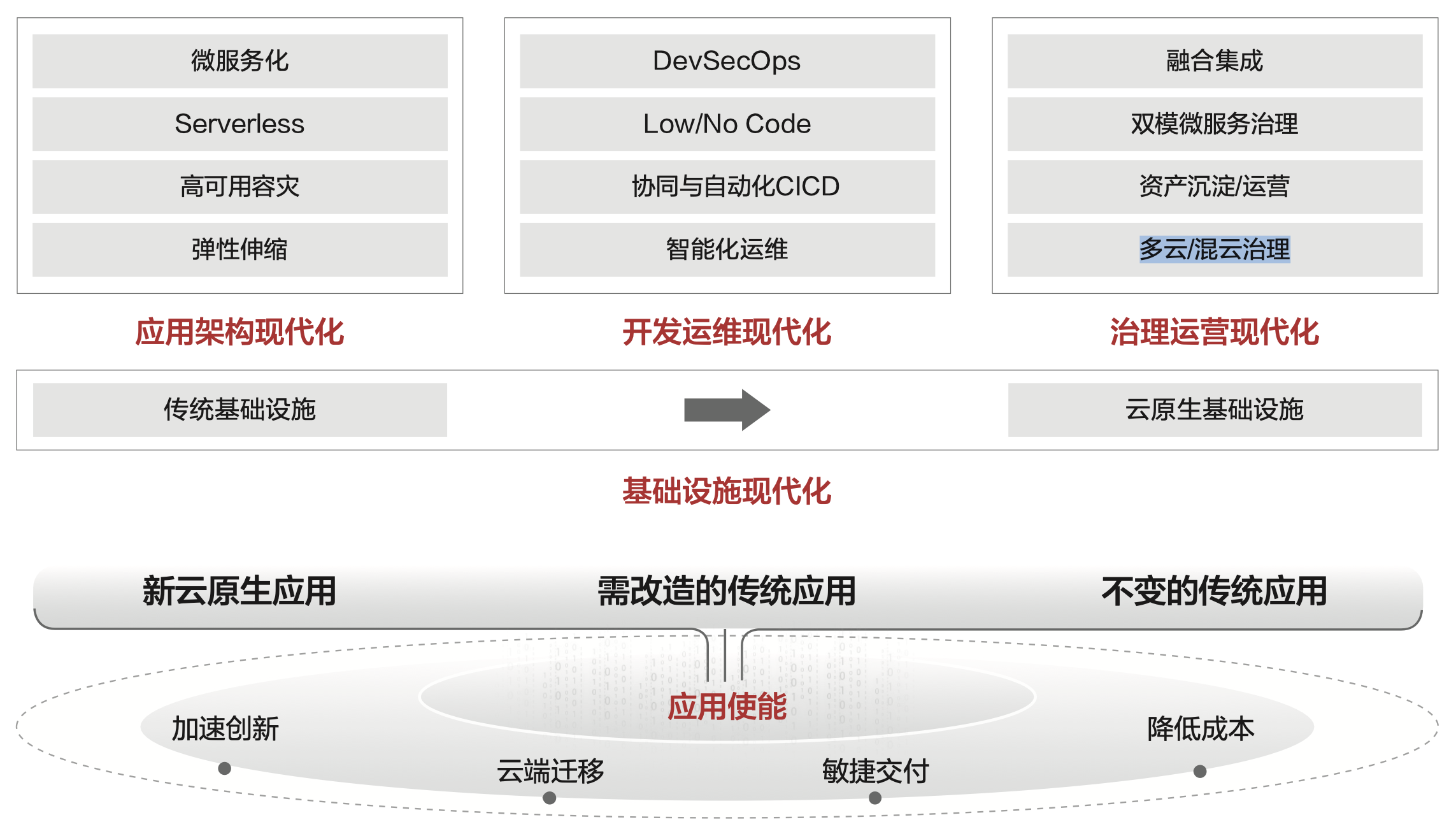
云原生:应用敏捷,华为视角下的应用现代化
Gartner 也提出,到 2023 年,新应用新服务的数量将达到 5 亿,也即是说:“每个企业都正在成为软件企业”。据IDC 预测,到 2025 年三分之二的企业将成为多产的“软件企业”,每天都会发布软件版本。越来越多的企…...
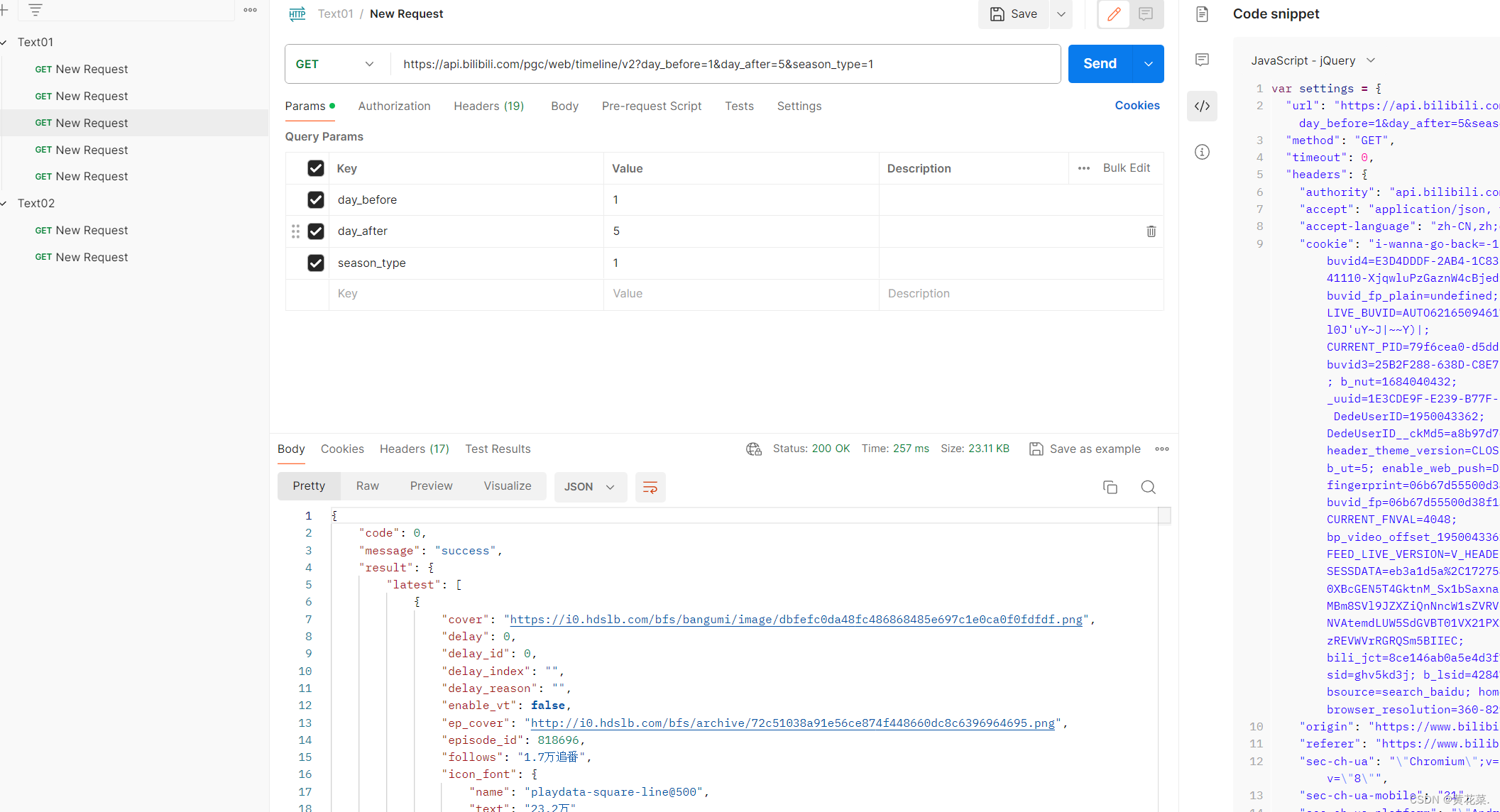
【测试篇】接口测试
接口测试,可以用可视化工具 postman。 如何做接口测试?? 我们可以先在浏览器中随机进入一个网页,打开开发者工具(F12)。 随便找一个接口Copy–>Copy as cURL(bash) 打开postman 复制地址 进行发送。 …...
突破校园网限速:使用 iKuai 多拨分流负载均衡 + Clash 代理(内网带宽限制通用)
文章目录 1. 简介2. iKuai 部署2.1 安装 VMware2.2 安装 iKuai(1) 下载固件(2) 安装 iKuai 虚拟机(3) 配置 iKuai 虚拟机(4) 配置 iKuai(5) 配置多拨分流 2.3 测试速度 3. Clash 部署(1) 配置磁盘分区(2) 安装 Docker(3) 安装 Clash(4) 设置代理 4. 热点:一起瓜分互…...

03-JAVA设计模式-工厂模式详解
工厂模式 工厂设计模式是一种创建型设计模式,它提供了一种封装对象创建过程的机制,将对象的创建与使用分离。 这种设计模式允许我们在不修改客户端代码的情况下引入新的对象类型。 在Java中,工厂设计模式主要有三种形式:简单工厂…...

百度文心大模型推理成本降至1% / 马斯克起诉OpenAI |魔法半周报
我有魔法✨为你劈开信息大海❗ 高效获取AIGC的热门事件🔥,更新AIGC的最新动态,生成相应的魔法简报,节省阅读时间👻 🔥资讯预览 百度文心大模型推理成本降至1%,与三星、荣耀等企业达成合作 马斯…...
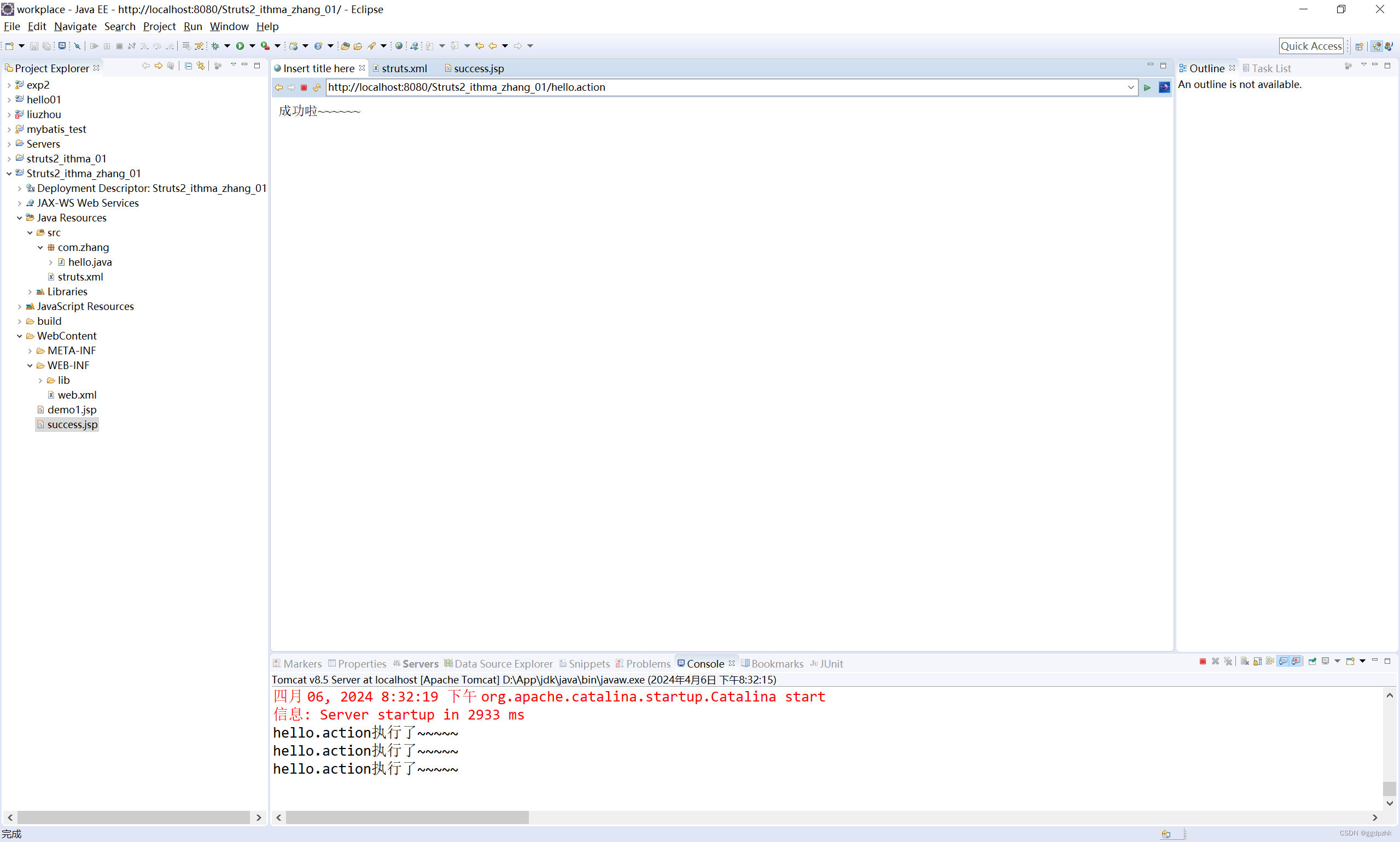
Struts2的入门:新建项目——》导入jar包——》jsp,action,struts.xml,web.xml——》在项目运行
文章目录 配置环境tomcat 新建项目导入jar包新建jsp界面新建action类新建struts.xml,用来配置action文件配置Struts2的核心过滤器:web.xml 启动测试给一个返回界面在struts.xml中配置以实现页面的跳转:result再写个success.jsp最后在项目运行 配置环境 …...

git 标签功能操作以及回退
Git 标签功能允许开发者为特定的提交打上标签,以便后续能够方便地引用这些提交。标签通常用于标记重要的版本或里程碑,例如软件发布的版本号。与分支不同,标签指向的是固定的提交,一旦设置,就不能轻易更改。下面是一些…...

利用python实现文字转语音
代码如下: import pathlib import tkinter as tk import tkinter.ttk as ttk import tkinter.filedialog as filedialog import tkinter.messagebox as msgbox import pyttsx3class Application(tk.Tk):def __init__(self):super().__init__()self.title("文本…...

拾光坞N3 ARM 虚拟主机 i茅台项目
拾光坞N3 在Dcoker部署i茅台案例 OS:Ubuntu 22.04.1 LTS aarch64 cpu:RK3566 ram:2G 部署流程——》mysql——》java8——》redis——》nginx mysql # 依赖 apt update apt install -y net-tools apt install -y libaio* # 下载mysql wg…...
docker安装nacos,单例模式(standalone),使用mysql数据库
文章目录 前言安装创建文件夹"假装"安装一下nacos拷贝文件夹删除“假装”安装的nacos容器生成nacos所需的mysql表获取mysql-schema.sql文件创建一个mysql的schema 重新生成新的nacos容器 制作docker-compose.yaml文件查看网站 前言 此处有本人写得简易版本安装&…...
【运输层】传输控制协议 TCP
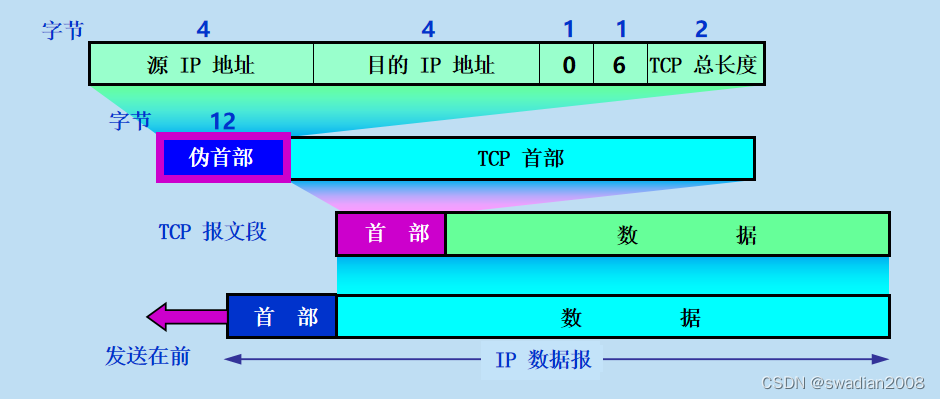
目录 1、传输控制协议 TCP 概述 (1)TCP 的特点 (2)TCP 连接中的套接字概念 2、可靠传输的工作原理 (1)停止等待协议 (2)连续ARQ协议 3、TCP 报文段的首部格式 1、传输控制协议…...

深入浅出 -- 系统架构之Keepalived搭建双机热备
Keepalived重启脚本双机热备搭建 ①首先创建一个对应的目录并下载keepalived安装包(提取码:s6aq)到Linux中并解压: [rootlocalhost]# mkdir /soft/keepalived && cd /soft/keepalived [rootlocalhost]# wget https://www.keepalived.…...

如何做好产业园运营?树莓集团:响应政府号召,规划,注重大局观
随着经济的发展和产业结构的调整,产业园区的建设和发展已经成为推动地方经济的重要力量。如何做好产业园运营,提高行业竞争力,现已成为了一个亟待解决的问题。树莓集团作为一家有着丰富产业园运营经验的企业,积极响应政府号召&…...
数据集时,我是如何通过调整图像尺寸把mAP提上去的)
踩坑实录:用YOLOv8训练小目标(足球)数据集时,我是如何通过调整图像尺寸把mAP提上去的
小目标检测优化实战:YOLOv8图像尺寸调整如何提升足球识别精度 足球在绿茵场上划出的弧线总是令人着迷,但当这份优雅遇上目标检测算法时,却常常变成开发者的噩梦——那些直径不足20像素的小球,在常规训练参数下往往成为模型"视…...

从算法理想向工程现实的跨越:SLAM 核心架构、思维误区与 Nav2 实战避坑指南
前言:直面 SLAM 的“先有鸡还是先有蛋” 在机器人领域,SLAM(Simultaneous Localization and Mapping,同时定位与地图构建) 毫无疑问是最耀眼的明珠之一。简单来说,它的核心任务就是让一个机器人在未知环境中…...
)
告别编译报错!手把手教你为最新版Keil MDK安装ARM Compiler 5(保姆级图文)
嵌入式开发者的救星:彻底解决Keil MDK缺失ARM Compiler 5的终极方案 当你满怀信心地打开一个历史遗留的嵌入式项目,准备进行功能迭代时,Keil MDK突然弹出一个冰冷的错误窗口:"Error: Compiler V5.06 update 7 (build 960) no…...
)
告别AT指令恐惧:用STM32F407驱动SIM800C实现短信报警(附完整代码)
STM32F407与SIM800C实战:构建工业级短信报警系统的完整指南 在工业自动化、智能家居和远程监控领域,可靠的异常通知机制往往决定着系统响应速度与故障处理效率。传统有线报警方式受限于物理距离,而基于Wi-Fi的解决方案又面临网络覆盖的挑战。…...
)
OpenClaw 接入 DeepSeek 模型完整配置教程(2026 最新版)
OpenClaw 接入 DeepSeek 模型完整配置教程 一、前置准备 已安装并正常运行 OpenClaw Windows 客户端;OpenClaw 顶部 Gateway 状态保持在线;电脑网络正常,可稳定访问 DeepSeek 开放平台;准备可接收验证码的手机号或微信账号&…...
)
WebSocket 库存实时监控实战(Java 服务端 + 前端)
目录 一、技术选型 二、搭建 Spring Boot 服务端 1. 创建项目 & 引入依赖 2. WebSocket 配置类 3. 库存实体类(库存 预警规则) 4. WebSocket 服务端核心代码 5. 提供接口:手动修改库存并推送 6. 启动类 三、前端页面࿰…...
全流程实操:从ONNX转换到INT8/FP16量化加速)
YOLOv8在Jetson上导出TensorRT引擎(.engine)全流程实操:从ONNX转换到INT8/FP16量化加速
YOLOv8在Jetson平台上的TensorRT引擎部署与量化加速实战指南 当目标检测模型需要部署到边缘计算设备时,性能优化往往成为最关键的技术挑战。本文将深入探讨如何将YOLOv8模型高效转换为Jetson平台专用的TensorRT引擎,并通过INT8/FP16量化技术实现推理速度…...

量子机器学习革新气象预测:高效台风轨迹建模
1. 量子机器学习在气象预测中的革新应用台风轨迹预测一直是气象学领域的重大挑战。传统数值天气预报(NWP)模型依赖于超级计算机集群,需要处理海量的大气动力学数据,计算成本高昂且能耗巨大。以台湾地区为例,每年平均遭受3.5次台风袭击&#x…...

免费开源乐谱识别工具Audiveris:从纸质乐谱到数字音乐的三步转换指南
免费开源乐谱识别工具Audiveris:从纸质乐谱到数字音乐的三步转换指南 【免费下载链接】audiveris Latest generation of Audiveris OMR engine 项目地址: https://gitcode.com/gh_mirrors/au/audiveris 还在为整理成堆的纸质乐谱而烦恼吗?Audiver…...

骁龙855深度解析:5G基带集成与移动芯片架构演进
1. 从爆料到现实:骁龙855的早期信息拼图2018年初,当搭载骁龙845的手机才刚刚在市场上崭露头角时,关于其继任者的传闻就已经开始流传。对于像我这样长期关注移动芯片发展的从业者来说,每一代旗舰SoC的迭代节奏都像是一场精心编排的…...