如何魔改 diffusers 中的 pipelines
如何魔改 diffusers 中的 pipelines
整个 Stable Diffusion 及其 pipeline 长得就很适合 hack 的样子。不管是通过简单地调整采样过程中的一些参数,还是直接魔改 pipeline 内部甚至 UNet 内部的 Attention,都可以实现很多有趣的功能或采样生图结果。
本文主要介绍两种魔改 diffusers pipelines 的方式,一是通过注册 callback 函数,来在采样生图过程中执行某些操作,二是直接自己写 custom pipelines。
pipeline callbacks
可参考官方文档:Pipelines Callback
通过在 pipe 推理生图时传入自定义的回调函数,不用动底层代码,可以在每个时间步结束时动态地执行一些我们想要的动作,比如在特定的时间步修改特定的采样参数或张量。目前仅支持 callback_on_step_end 在单步结束时执行回调函数。我们通过两个例子来介绍如何通过 callback 函数来魔改 diffusers pipelines。
Dynamic classifier-free guidance
classifier-free guidance (cfg)用于通过 prompt 来引导图像生成的内容。在 diffusers 中,会同时用 CLIP 文本编码器同时编码 prompt 的 embeds 和空 prompt (空字符串或 negative prompt)的 embeds,然后拼接起来,一起通过交叉注意力与 UNet 交互。
通过 callback 函数,我们可以按照自己的需求动态控制 cfg,比如说,我想在特定的时间步之后停止使用 cfg,从而节省计算开销,并且性能不会有很大的损失。 callback 函数需要接收以下参数:
-
pipeline:通过 pipe 可以访问和编辑许多重要的采样参数,如
pipe.num_timesteps、pipe.guidance_scale等。在本例中,我们就可以通过将pipe._guidance_scale来停用 cfg。 -
timestep 和 step_index:这两个参数可以让我们知道本次采样过程一共有多少时间步,以及当前我们位于哪一步。从而可以根据当前位于整个采样过程中的位置,来选择进行什么操作。在本例中,我们可以设置在整个采样过程 40% 及以后的位置,停用 cfg。
-
callback_kwargs:callback_kwargs 是一个字典,包含了在采样生图的过程中你可以编辑的张量。具体包含哪些张量,需要再调用 pipe 采样生图时通过
callback_on_step_end_tensor_inputs参数传入。不同的 pipe 可能包含不同的可编辑张量,具体可以通过 pipe 的_callback_tensor_inputs属性查看。在本例中,我们需要在停用 cfg 之后调整prompt_embeds张量的批尺寸,丢掉空 prompt 部分。这是因为 sd pipe 是根据_guidance_scale的值来判断是否进行 cfg,所以我们将这个值改为零,就不会进行 cfg 了,所以需要将prompt_embeds不带 prompt 的部分丢掉,只保存带 prompt 的部分。
返回值方面,回调函数必须返回(修改好的) callback_kwargs。
最终,我们的 callback 函数是这样的:
def callback_dynamic_cfg(pipe, step_index, timestep, callback_kwargs, percent):if step_index == int(pipe.num_timesteps * percent):prompt_embeds = callback_kwargs['prompt_embeds']prompt_embeds = prompt_embeds.chunk(2)[-1]pipe._guidance_scale = 0.0callback_kwargs['prompt_embeds'] = prompt_embedsreturn callback_kwargs
然后在推理生图时传入该参数:
pipeline = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
pipeline = pipeline.to("cuda")prompt = "a photo of an astronaut riding a horse on mars"generator = torch.Generator(device="cuda").manual_seed(1)
out = pipeline(prompt,generator=generator,callback_on_step_end=callback_dynamic_cfg,callback_on_step_end_tensor_inputs=['prompt_embeds']
)out.images[0].save("out_custom_cfg.png")
Display image after each generation step
在搭建生图 UI 时,一般需要支持用户在看到前几个时间步的结果不符合预期时,手动终止采样生图过程。这就需要两个功能,一是展示每一步的生图结果,二是支持在过程中终止本次生图。下面以展示中间步结果为例,介绍回调函数的使用。
我们知道,在 SD 中,去噪采样生图过程是发生在隐空间的,以 SDXL 为例,隐空间的特征图尺寸为 128 × 128 × 3 128\times 128\times 3 128×128×3 。我们需要将其转换到像素空间,才能看到这一步的实际生图结果。SDXL 还有点特殊,需要先将四通道的隐空间转换为 RGB 三通道,详情见 Explaining the SDXL latent space 。
def latents_to_rgb(latents):weights = ((60, -60, 25, -70),(60, -5, 15, -50),(60, 10, -5, -35))weights_tensor = torch.t(torch.tensor(weights, dtype=latents.dtype).to(latents.device))biases_tensor = torch.tensor((150, 140, 130), dtype=latents.dtype).to(latents.device)rgb_tensor = torch.einsum("...lxy,lr -> ...rxy", latents, weights_tensor) + biases_tensor.unsqueeze(-1).unsqueeze(-1)image_array = rgb_tensor.clamp(0, 255)[0].byte().cpu().numpy()image_array = image_array.transpose(1, 2, 0)return Image.fromarray(image_array)def decode_tensors(pipe, step, timestep, callback_kwargs):latents = callback_kwargs["latents"]image = latents_to_rgb(latents)image.save(f"{step}.png")return callback_kwargs
然后再推理生图时传入该参数回调函数:
from diffusers import AutoPipelineForText2Image
import torch
from PIL import Imagepipeline = AutoPipelineForText2Image.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0",torch_dtype=torch.float16,variant="fp16",use_safetensors=True
).to("cuda")image = pipeline(prompt = "A croissant shaped like a cute bear.",negative_prompt = "Deformed, ugly, bad anatomy",callback_on_step_end=decode_tensors,callback_on_step_end_tensor_inputs=["latents"],
).images[0]

Custom Pipelines
可参考官方文档:Custome Pipelines、contribute-pipeline
在 diffusers 中,我们可以很方便的自定义并加载自己的定制化 pipelines。在实现自己的自定义 pipelines 时,需要继承基类 DiffusionPipeline。
加载 custom pipelines
1 从 diffusers 仓库中加载自定义的 pipeline
从 hf hub 加载自定义的 pipeline 非常简单,只需要将 model_id 传入 custom_pipeline 参数,然后就会加载该仓库中对应的 pipeline.py。
from diffusers import DiffusionPipelinepipeline = DiffusionPipeline.from_pretrained("google/ddpm-cifar10-32", custom_pipeline="hf-internal-testing/diffusers-dummy-pipeline"
)
2 从本地文件加载自定义的 pipeline
如果想从本地文件加载 pipeline,需要将 pipeline.py 所在的文件目录(注意是目录名)传给 custom_pipeline 参数。
from diffusers import DiffusionPipelinepipeline = DiffusionPipeline.from_pretrained("google/ddpm-cifar10-32", custom_pipeline="path/to/dir"
)
3 加载官方收录的社区 custom pipelines
这里是合入 diffuses 官方仓库的一些社区的自定义 pipelines。我们只需要将对应文件名(不含 py 后缀,如 clip_guided_stable_diffusion)传给 custom_pipeline 参数。
由于自定义 pipelines 的通常比较复杂,所以我们也可以通过官方 pipeline 来加载模型,再将模型传入自定义 pipelines。
from diffusers import DiffusionPipeline
from transformers import CLIPFeatureExtractor, CLIPModelclip_model_id = "laion/CLIP-ViT-B-32-laion2B-s34B-b79K"feature_extractor = CLIPFeatureExtractor.from_pretrained(clip_model_id)
clip_model = CLIPModel.from_pretrained(clip_model_id)pipeline = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4",custom_pipeline="clip_guided_stable_diffusion",clip_model=clip_model,feature_extractor=feature_extractor,
)
实现 custom pipelines
我们可以继承 DiffusionPipeline 基类并实现自己的 custom pipeline,这样所有人就都可以加载我们实现的 pipeline。一个 custom pipeline 的框架大致如下:
import torch
from diffusers import DiffusionPipelineclass MyPipeline(DiffusionPipeline):def __init__(self, unet, scheduler):super().__init__()self.register_modules(unet=unet, scheduler=scheduler)@torch.no_grad()def __call__(self, batch_size: int = 1, num_inference_steps: int = 50):# Sample gaussian noise to begin loopimage = torch.randn((batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size))image = image.to(self.device)# set step valuesself.scheduler.set_timesteps(num_inference_steps)for t in self.progress_bar(self.scheduler.timesteps):# 1. predict noise model_outputmodel_output = self.unet(image, t).sample# 2. predict previous mean of image x_t-1 and add variance depending on eta# eta corresponds to η in paper and should be between [0, 1]# do x_t -> x_t-1image = self.scheduler.step(model_output, t, image, eta).prev_sampleimage = (image / 2 + 0.5).clamp(0, 1)image = image.cpu().permute(0, 2, 3, 1).numpy()return image
确保 xxxPipeline 这个类的相关实现都在这一个文件,而且该文件中只包含 xxxPipeline 一个类。因为 pipeline 的识别加载是自动的。
接下来,我们以一个最简单的 one-step pipeline 为例,简单介绍自己实现 custom pipeline 的过程。在这个one-step pipeline 中,只会用到 UNet 一个模型,并将 timestep 固定为 1,只进行一次模型前向。
首先新建一个 one_step_unet.py 文件,然后在其中继承 DiffusionPipeline 基类并实现 UnetSchedulerOneForwardPipeline 类。
初始化:定义 __init__ 方法
在初始化方法中,我们简单地的 one-step pipeline 只需要接收 unet 和 scheduler 两个初始化参数,我们在初始化方法中将变量定义好。注意,为了使得 save_pretrained 方法能够将我们的模型完整地保存下来,需要通过 register_modules 方法将我们想要保存的 unet 和 scheduler 注册进来。
from diffusers import DiffusionPipeline
import torchclass UnetSchedulerOneForwardPipeline(DiffusionPipeline):def __init__(self, unet, scheduler):super().__init__()self.register_modules(unet=unet, scheduler=scheduler)
前向推理:定义 __call__ 方法
定义好初始化方法 __init__ 之后,再来实现 pipeline 推理生图的 __call__ 方法。在这里,我们可以任意发挥,任意组合,魔改扩散模型的采样过程,实现自己想要的功能。在我们的 one-step pipeline 中,这里要做的非常简单:采样一个噪声图,UNet 进行一次前向。
@torch.no_grad()
def __call__(self):image = torch.randn(1, self.unet.config.in_channels, self.unet.config.sample_size, self.unet.sanple_size)timestep = 1model_output = self.unet(image, timestep).samplescheduler_output = self.scheduler.step(model_output, timestep, image).prev_samplereturn scheduler_output
这就 ok 了,我们已经实现好了自定义的 one-step pipeline。
推理
我们传入 unet 和 scheduler,实例化一个刚刚自定义好的 UnetSchedulerOneForwardPipeline,然后进行推理生图:
from diffusers import DDPMScheduler, UNet2DModelscheduler = DDPMScheduler()
unet = UNet2DModel()pipeline = UnetSchedulerOneForwardPipeline(unet=unet, scheduler=scheduler)output = pipeline()
如果我们的 custom pipeline 结果如果跟某个已有的 pipeline 的预训练权重是完全一样的,我们还可以直接通过 from_pretrained 方法来加载它们的权重。比如说,我们的 UnetSchedulerOneForwardPipeline 就可以直接加载 google/ddpm-cifar10-32 的权重:
pipeline = UnetSchedulerOneForwardPipeline.from_pretrained("google/ddpm-cifar10-32", use_safetensors=True)output = pipeline()
分享 custom pipelines
要共享自己的 custom pipeline 有三个方法:
-
将自己实现的 custom pipeline 推送到 hf hub 仓库,需要将文件名命名为
pipeline.py -
像 diffusers 官方仓库提交 PR,合并之后可以我们的 pipeline 就会出现在这里,别人可以通过文件名来加载
-
共享出自己的源码文件,如
clip_guided_stable_diffusion.py,别人也可以导入我们的 pipeline
而作为使用者,使用 custom pipeline 的方式有两种:
# 方式 1
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("google/ddpm-cifar10-32", custom_pipeline="hf-internal-testing/diffusers-dummy-pipeline"
)# 方式 2
from cus_pipe import CustomPipeline # cus_pipe is copied from hf-internal-testing/diffusers-dummy-pipeline
pipe = CustomPipeline.from_pretrained("google/ddpm-cifar10-32")
这两种使用方式应该是等价的,这可以从源码中看到:
if custom_pipeline is not None:pipeline_class = get_class_from_dynamic_module(custom_pipeline, module_file=CUSTOM_PIPELINE_FILE_NAME, cache_dir=custom_pipeline)
elif cls != DiffusionPipeline:pipeline_class = cls
else:diffusers_module = importlib.import_module(cls.__module__.split(".")[0])pipeline_class = getattr(diffusers_module, config_dict["_class_name"])
总结
diffusers 的 api 设计非常友好,我们可以通过 pipeline callback 和 custom pipeline 等方式定制化实现自己想要的功能,其中前者不用动底层代码,简单优雅,后者则是功能强大,现在最新的 AIGC 相关的论文基本都是通过 custom diffusion 的方式公开自己的源码,非常方便。
相关文章:
如何魔改 diffusers 中的 pipelines
如何魔改 diffusers 中的 pipelines 整个 Stable Diffusion 及其 pipeline 长得就很适合 hack 的样子。不管是通过简单地调整采样过程中的一些参数,还是直接魔改 pipeline 内部甚至 UNet 内部的 Attention,都可以实现很多有趣的功能或采样生图结果。 本…...

解放办公室的利器!让证卡打印机轻松应对繁忙工作场景
在现代办公室中,证卡打印机已经成为不可或缺的工作利器。但是,在繁忙的工作场景中,我们经常忽视了它的保养和清洁。然而,正确的清洁和维护不仅可以延长打印机的寿命,还可以提高工作效率,确保每一次打印都是…...

2012年认证杯SPSSPRO杯数学建模A题(第二阶段)蜘蛛网全过程文档及程序
2012年认证杯SPSSPRO杯数学建模 A题 蜘蛛网 原题再现: 第二阶段问题 现在我们假设一个具体的环境。假设有一个凸多边形的区域,蜘蛛准备在这个区域(或其一部分)上结一张网。 问题一: 在区域的边界上安置有若干…...
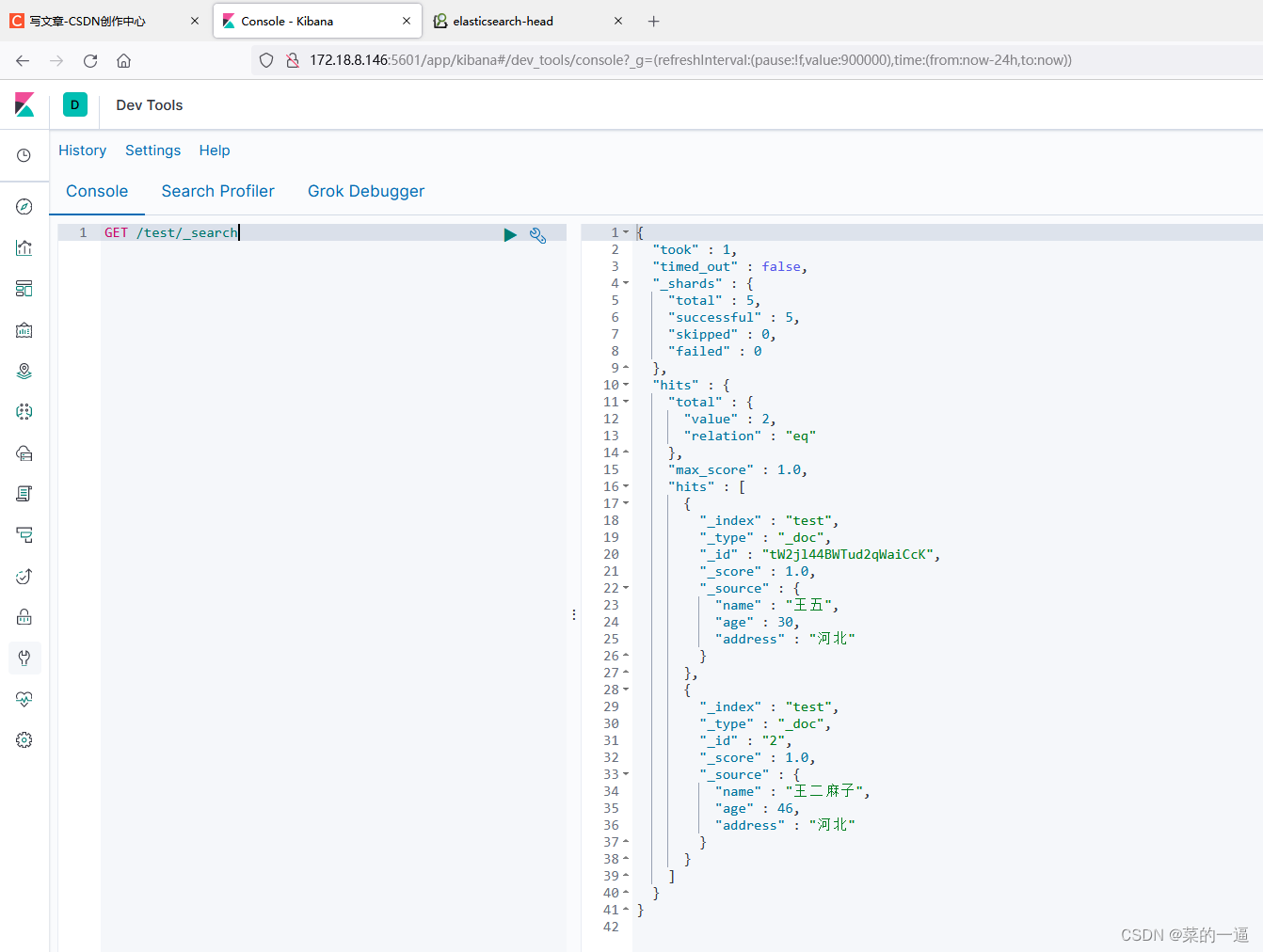
ES学习日记(七)-------Kibana安装和简易使用
前言 首先明确一点,Kibana是一个软件,不是插件。 Kibana 是一款开源的数据分析和可视化平台,它是 Elastic stack 成员之一,设计用于和Elasticsearch 协作。您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索,…...

react 父子组件的渲染机制 | 优化手段
文章目录 父子组件的渲染机制优化手段与实践写法父组件:下发stateprops.children 传递无状态组件props传递组件 React.memo缓存子组件与useCallback结合 父子组件的渲染机制 渲染分初次渲染和重新渲染 React组件会在两种情况下发生重新渲染 当组件自身的state发生…...

elementPlus el-table动态列扩展及二维表格
1、循环列数据源,动态生成列 <template><div><el-table ref"table" :data"pageData.tableData" stripe style"width: 100%"><el-table-column v-for"column in pageData.columns" :key"column.p…...
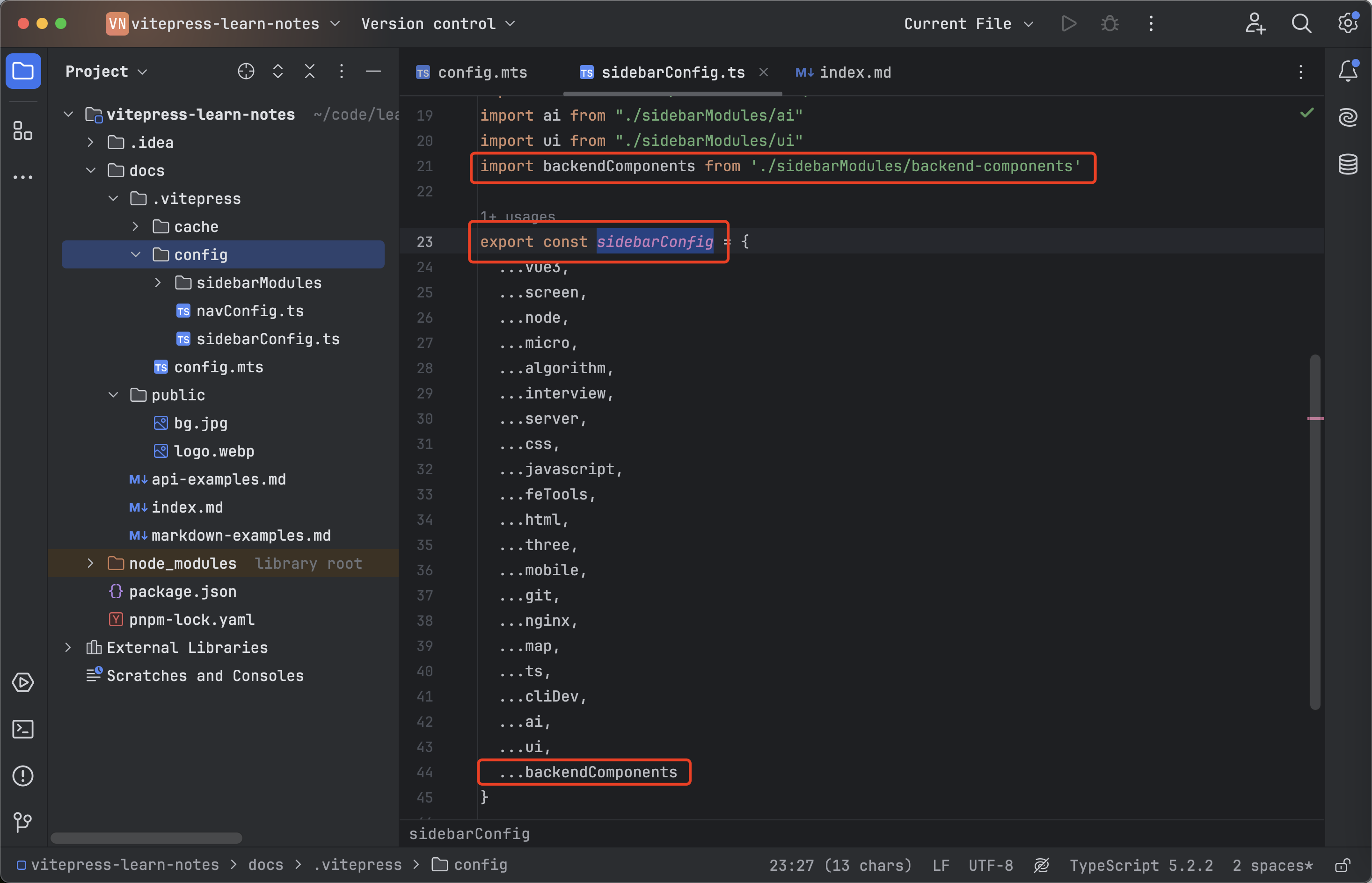
vitepress系列-04-规整sideBar左侧菜单导航
规整左侧菜单导航 新建navConfig.ts 文件用来管理左侧导航菜单: 将于其他的配置分开,避免config.mts太大 在config目录下,新建 sidebarModules文件目录用来左侧导航菜单 按模块进行分类: 在config下新建sidebarConfig.ts文件&…...

golang slice总结
目录 概述 一、什么是slice 二、slice的声明 三、slice的初始化、创建 make方式创建 创建一个包含指定长度的切片 创建一个指定长度和容量的切片 创建一个空切片 创建一个长度和容量都为 0 的切片 new方式创建 短声明初始化切片 通过一个数组来创建切片 声明一个 …...

MySQL 数据库的优化
目录 一. 常见故障 单实例常见故障 1. 故障一 2. 故障二 3.故障三 4. 故障四 5. 故障五 6.故障六 7.故障七 8.故障八 主从环境常见故障 1.故障一 2. 故障二 3. 故障三 二. 优化 1.硬件方面 1.1 关于CPU 1.2 关于内存 1.3 关于磁盘 2. 配置文件优化 关于引擎…...
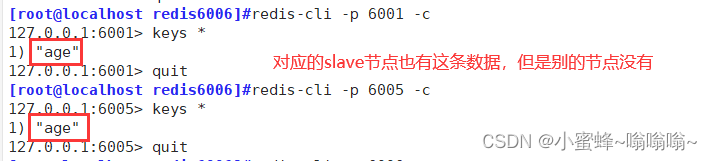
Redis 的主从复制、哨兵和cluster集群
目录 一. Redis 主从复制 1. 介绍 2. 作用 3. 流程 4. 搭建 Redis 主从复制 安装redis 修改 master 的Redis配置文件 修改 slave 的Redis配置文件 验证主从效果 二. Redis 哨兵模式 1. 介绍 2. 原理 3. 哨兵模式的作用 4. 工作流程 4.1 故障转移机制 4.2 主节…...
UI Toolkit)
Unity进阶之路(2)UI Toolkit
UI Toolkit是Unity内置的一个游戏UI解决方案。借鉴了web前端的设计模式。 web前端使用css,html,js。 其中css定义样式 html定义层级 js处理逻辑 UI Toolkit则是使用uss,uxml,C# 如果直接使用Unity提供的可视化UI创建工具创建…...

实现Hello Qt 程序
🐌博主主页:🐌倔强的大蜗牛🐌 📚专栏分类:QT❤️感谢大家点赞👍收藏⭐评论✍️ 目录 一、使用 "按钮" 实现 1、纯代码方式实现 2、可视化操作实现 (1)…...

若依 ruoyi-vue 接口挂载获取Resources静态资源文件权限校验
解决小程序图片打包过大,放置后端,不引用ngnix、minio等组件,还能进行权限校验 package com.huida.web.controller.common.app;import com.huida.common.core.controller.BaseController; import com.huida.common.utils.file.FileUtils; imp…...
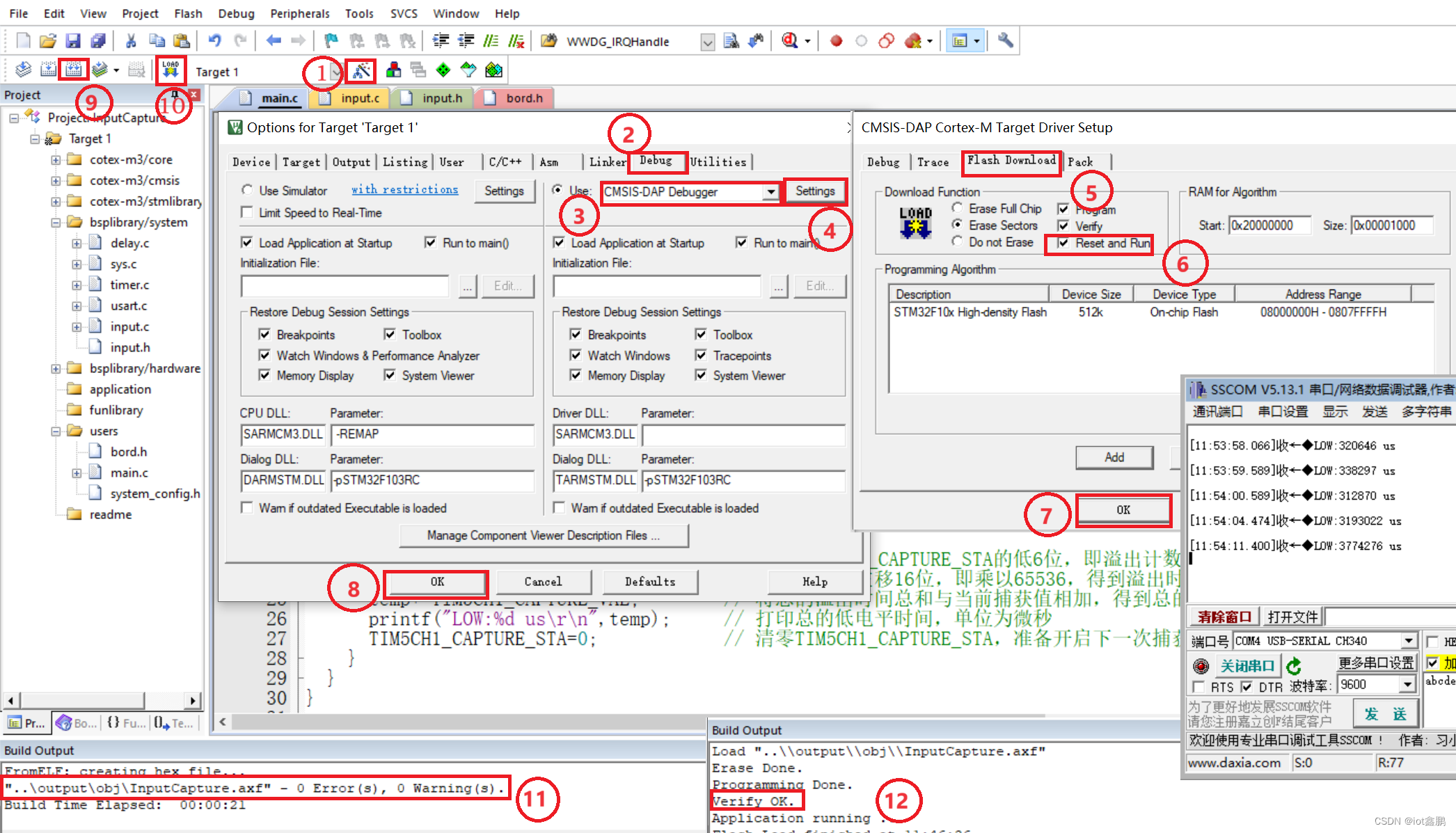
【STM32嵌入式系统设计与开发】——16InputCapture(输入捕获应用)
这里写目录标题 STM32资料包: 百度网盘下载链接:链接:https://pan.baidu.com/s/1mWx9Asaipk-2z9HY17wYXQ?pwd8888 提取码:8888 一、任务描述二、任务实施1、工程文件夹创建2、函数编辑(1)主函数编辑&#…...

「论文阅读」还在手写Prompt,自动Prompt搜索超越人类水平
每周论文阅读笔记,来自于2023LARGE LANGUAGE MODELS ARE HUMAN-LEVEL PROMPT ENGINEERS code:https://github.com/keirp/automatic_prompt_engineer 手写prompt确实很费脑筋,但其实本身大语言模型就是一个很好的自动prompt工具,APE文章提出自…...
安全测试概述和用例设计
一、安全测试概述 定义:安全测试是在软件产品开发基本完成时,验证产品是否符合安全需求定义和产品质量标准的过程。 概念:安全测试是检查系统对非法侵入渗透的防范能力。 准则:理论上来讲,只要有足够的时间和资源&a…...

JavaScript 超详细学习思路
JavaScript 是一种轻量级的编程语言,它可以在网页中嵌入,用来实现网页的动态效果和用户交互功能。它是 Web 开发中不可或缺的一部分,与 HTML 和 CSS 并称为 Web 技术的三大基石。下面我会根据您的要求,对每个部分进行详细的讲解。…...
LeetCode:1483. 树节点的第 K 个祖先(倍增 Java)
目录 1483. 树节点的第 K 个祖先 题目描述: 实现代码与解析: 倍增 原理思路: 1483. 树节点的第 K 个祖先 题目描述: 给你一棵树,树上有 n 个节点,按从 0 到 n-1 编号。树以父节点数组的形式给出&#…...

ConstraintLayout在复杂布局中,出现卡顿问题解决记录
ConstraintLayout在画界面的过程中,确实带来了不少的方便,随着使用的越来越多,也发现了一些问题,特此记录一下问题和解决方案。 在背景为图片,而背景图片宽度固定高度自适应的情况下,布局显示在图片固定位…...

责任链模式详解+代码案例
责任链设计模式 定义: 又名职责链模式,为了避免请求发送者与多个请求处理者耦合在一起,将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到…...
--CubeMX配置说明)
基于STM32HAL库的平衡小车设计(二)--CubeMX配置说明
项目开源链接 本项目资料完全开源。资料包获取方式: github : https://github.com/snqx-lqh/ProjectReleasePage gitee(国内镜像) :https://gitee.com/snqx-lqh/ProjectOpenSourceReleasePage。 项目属于 32 的编号 B005 ,在发…...

BepInEx IL2CPP启动失败终极解决指南:从异常诊断到游戏正常运行
BepInEx IL2CPP启动失败终极解决指南:从异常诊断到游戏正常运行 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx作为Unity游戏插件框架,为玩家和开发…...

【SITS2026权威前瞻】:AI研发自动化测试的5大范式跃迁与2024落地避坑指南
更多请点击: https://intelliparadigm.com 第一章:AI研发自动化测试:SITS2026专题 随着大模型驱动的研发范式演进,AI系统本身的可测试性面临全新挑战——模型行为非确定、输入空间高维、验证标准模糊。SITS2026(Softw…...

英文论文降AI教程:从97%到8%,2026实测的4种文本结构级优化方法
大家最近都在为英文降aigc率发愁吧,作为研三党,我太懂这种痛了,之前我自己写英文初稿,写完直接拿去查重,结果turnitin检测ai率飙到了89%,当时看着报告整个人都懵了。 怎么给英文降ai?对于非母语…...

只狼mod 深红誓约 法环boss分享 剑星解压即鲁版本
mod大全下载地址:https://pan.quark.cn/s/dcc6f9af1537#/list/share/7a4c672d5cc34ddf8ce899a057f361a1 安装方法:https://www.bilibili.com/video/BV13T421r79p/?spm_id_from333.337.search-card.all.click&vd_sourced68ed178f151e80fea1e02efd205802c 剑星解压即鲁版本 …...
视频质量评估技术解析与ClearView系统实践
1. 视频质量评估的行业现状与技术痛点 在数字电视和流媒体爆发式增长的今天,视频质量评估(Video Quality Assessment, VQA)已成为设备制造商和内容提供商的核心竞争力指标。我从事视频处理算法开发已有八年,亲眼见证了这个领域从依…...
— 基于SPI驱动TFTLCD实现动态数据可视化)
RT-Thread开发实战(8)— 基于SPI驱动TFTLCD实现动态数据可视化
1. 从零开始玩转SPI驱动TFTLCD 第一次用RT-Thread驱动TFTLCD屏幕时,我盯着那堆密密麻麻的引脚直发懵。后来才发现,只要搞明白SPI通信和屏幕驱动芯片的关系,这事儿其实比想象中简单多了。我们这次要对付的是ST7789V2这款驱动芯片,它…...

NPYViewer:5分钟上手的数据可视化神器,告别NumPy数组查看烦恼
NPYViewer:5分钟上手的数据可视化神器,告别NumPy数组查看烦恼 【免费下载链接】NPYViewer Load and view .npy files containing 2D and 1D NumPy arrays. 项目地址: https://gitcode.com/gh_mirrors/np/NPYViewer 还在为NumPy二进制文件头疼吗&a…...

在 Python 中使用 comtypes 时,大小写通常必须保持精确
wb excel.Workbooks.Open(file_path)print(f"文件已打开: {file_path}")后面的方法,大小写可以写错吗?这是一个非常经典的问题,答案是:在 Python 中使用 comtypes 时,大小写通常必须保持精确,不…...

手把手教你用PCI Geomatica处理Pleiades三线阵影像:从GCP刺点到DEM滤波的完整避坑指南
高分辨率卫星立体像对处理实战:PCI Geomatica全流程精解与避坑策略 当Pleiades三线阵影像遇上PCI Geomatica,会碰撞出怎样的火花?作为遥感数据处理领域的"瑞士军刀",Geomatica在立体像对处理上展现出的专业深度…...