【Leetcode】top 100 图论
基础知识补充
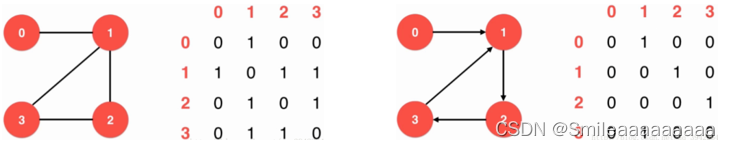
1.图分为有向图和无向图,有权图和无权图;
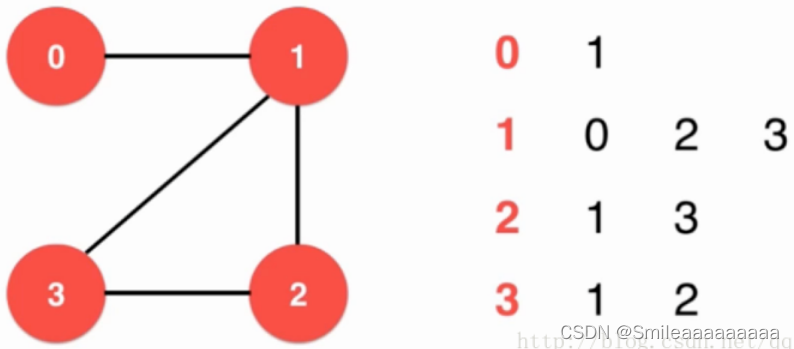
2.图的表示方法:邻接矩阵适合表示稠密图,邻接表适合表示稀疏图;
邻接矩阵:
邻接表:
基础操作补充
1.邻接矩阵:
class GraphAdjacencyMatrix:def __init__(self, num_vertices):self.num_vertices = num_verticesself.matrix = [[0] * num_vertices for _ in range(num_vertices)]def add_edge(self, start, end): # 无向图self.matrix[start][end] = 1self.matrix[end][start] = 12.邻接表:
from collections import defaultdictclass GraphAdjacencyList:def __init__(self):self.graph = defaultdict(list)def add_edge(self, start, end): # 无向图self.graph[start].append(end)self.graph[end].append(start)3.图的遍历:
# 深度优先搜索(DFS): # 从上到下,递归或栈实现 def dfs(graph, start, visited=None):if visited is None:visited = set()visited.add(start)print(start, end=" ")for neighbor in graph[start]:if neighbor not in visited:dfs(graph, neighbor, visited)# 广度优先搜索(BFS): # 从左到右,队列实现 from collections import dequedef bfs(graph, start):visited = set()queue = deque([start])visited.add(start)while queue:current = queue.popleft()print(current, end=" ")for neighbor in graph[current]:if neighbor not in visited:queue.append(neighbor)visited.add(neighbor)
题目
200 岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。此外,你可以假设该网格的四条边均被水包围。
方法一:深度优先搜索 DFS
若当前点是岛屿时,向上下左右四个点做深度搜索;终止条件:越界;当前是水;class Solution(object):def numIslands(self, grid):""":type grid: List[List[str]]:rtype: int"""def dfs(nums, x, y):if x<0 or x>len(nums)-1: return if y<0 or y>len(nums[0])-1: return if nums[x][y] =='0':return else:nums[x][y] = '0' # 必须先置0,否则会在两个'1'间连续递归至超过栈长dfs(nums, x-1, y)dfs(nums, x+1, y)dfs(nums, x, y-1)dfs(nums, x, y+1)cnt = 0for i in range(len(grid)):for j in range(len(grid[0])):if grid[i][j] == '1':dfs(grid, i, j)cnt += 1return cnt方法二:广度优先搜索 BFS
若当前点是岛屿时,将其上下左右四个点都加入队列;终止条件:越界;当前是水;
class Solution(object):def numIslands(self, grid):""":type grid: List[List[str]]:rtype: int"""def bfs(nums, x, y):queue = [(x, y)]while queue:(x, y) = queue.pop(0)if x<0 or x>len(nums)-1: continue elif y<0 or y>len(nums[0])-1: continue elif nums[x][y] =='0':continue else:nums[x][y] = '0' # 必须先置0,否则会在两个'1'间连续递归至超过栈长queue.append((x-1, y))queue.append((x+1, y))queue.append((x, y-1))queue.append((x, y+1))cnt = 0for i in range(len(grid)):for j in range(len(grid[0])):if grid[i][j] == '1':bfs(grid, i, j)cnt += 1return cnt
994 腐烂的橘子
在给定的 m x n 网格 grid 中,每个单元格可以有以下三个值之一:
- 值
0代表空单元格; - 值
1代表新鲜橘子; - 值
2代表腐烂的橘子。
每分钟,腐烂的橘子 周围 4 个方向上相邻 的新鲜橘子都会腐烂。返回 直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1 。
第一次遍历将所有新鲜橘子腐烂,统计腐烂次数;第二次遍历统计是否还有剩余的新鲜橘子;(若初始就不含有新鲜橘子呢?)
一次遍历统计新鲜橘子数量的同时记录腐烂橘子的位置(队列);
遍历队列,若当前位置是腐烂橘子则将其上下左右四个点入队,若当前位置是新鲜橘子则将新鲜橘子数量-1再将其上下左右四个点入队;需要将处理过的位置的值置为0,代表不再处理;
class Solution(object):def orangesRotting(self, grid):""":type grid: List[List[int]]:rtype: int"""cnt, queue = 0, []m, n = len(grid), len(grid[0])for i in range(m):for j in range(n):if grid[i][j] == 1:cnt += 1elif grid[i][j] == 2:queue.append([i,j])if cnt == 0: return 0time, stack = -1, []while queue:[x, y] = queue.pop(0)if -1<x<m and -1<y<n and grid[x][y]:if grid[x][y] == 1: cnt -= 1grid[x][y] = 0 # 不再处理这个点stack.append([x-1, y])stack.append([x+1, y])stack.append([x, y-1])stack.append([x, y+1])if not queue and stack:queue = stacktime += 1 stack = []return -1 if cnt else time计算遍历深度用BFS
207 课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
方法一:广度优先搜索
from collections import deque from collections import defaultdictclass Solution(object):def canFinish(self, numCourses, prerequisites):""":type numCourses: int:type prerequisites: List[List[int]]:rtype: bool"""degree = [0]*numCourses maps = defaultdict(list) queue = deque()for cur, pre in prerequisites:degree[cur] += 1 # 统计每门课的先修课程数maps[pre].append(cur) # 记录基础课和对应的进阶课for i in range(numCourses):if degree[i] == 0: queue.append(i) # 无先修课程(基础课)时入队count = 0while queue:course = queue.popleft()count += 1for i in maps[course]: # 将以course为基础课的进阶课的先修课数-1degree[i] -= 1if degree[i] == 0: # 已修完全部基础课queue.append(i) return count == numCourses方法二:深度优先搜索
class Solution(object):def canFinish(self, numCourses, prerequisites):""":type numCourses: int:type prerequisites: List[List[int]]:rtype: bool"""degree = [0]* numCoursesmaps = defaultdict(list)def dfs(i):if degree[i]==-1: return False # degree[i]==-1 表示会陷入循环if degree[i]==1: return True # degree[i]==1 表示能完成课 degree[i]=-1 # 防止 1-0-1 转回来的情况for pre in maps[i]: # 遍历每门基础课if not dfs(pre): return Falsedegree[i]=1 # 该门课可以完成return Truefor cur, pre in prerequisites: # 记录先修课和其基础课程maps[cur].append(pre)for i in range(numCourses): # 遍历每门课dfs(i)return sum(degree) == numCourses # 若每门课都完成应该全为1
208 实现Trie(前缀树)
Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。
核心:使用「边」来代表有无字符,使用「点」来记录是否为「单词结尾」以及「其后续字符串的字符是什么」
class TrieNode:def __init__(self):self.children = {}self.is_end = Falseclass Trie(object):def __init__(self):self.root = TrieNode()def insert(self, word):""":type word: str:rtype: None"""node = self.rootfor c in word:if c not in node.children:node.children[c] = TrieNode()node = node.children[c]node.is_end = Truedef searchPrefix(self, word):node = self.rootfor c in word:if c not in node.children: return Nonenode = node.children[c]return nodedef search(self, word):""":type word: str:rtype: bool"""node = self.searchPrefix(word)return node is not None and node.is_enddef startsWith(self, prefix):""":type prefix: str:rtype: bool"""node = self.searchPrefix(prefix)return node is not None
额外补充
flood fill 带你学习Flood Fill算法与最短路模型 - 时间最考验人 - 博客园 (cnblogs.com)
相关文章:
【Leetcode】top 100 图论
基础知识补充 1.图分为有向图和无向图,有权图和无权图; 2.图的表示方法:邻接矩阵适合表示稠密图,邻接表适合表示稀疏图; 邻接矩阵: 邻接表: 基础操作补充 1.邻接矩阵: class GraphAd…...

【沈阳航空航天大学】 <C++ 类与对象计分作业>
C类与对象 1. 设计用类完成计算两点距离2. 设计向量类3. 求n!4. 出租车收费类的设计与实现5. 定义并实现一个复数类6. 线性表类的设计与实现7. 数组求和8. 数组求最大值 1. 设计用类完成计算两点距离 【问题描述】设计二维点类Point,包括私有成员:横坐标…...

Vue3 自定义指令Custom Directives
简介 在vue中重用代码的方式有:组件、组合式函数。组件是主要的构建模块,而组合式函数更偏重于有状态的逻辑。 指令系统给我们提供了例如:v-model、v-bind,vue系统允许我们自定义指令,自定义指令也是一种重用代码的方式…...

蓝桥杯 【日期统计】【01串的熵】
日期统计 第一遍写的时候会错了题目的意思,我以为是一定要八个整数连在一起构成正确日期,后面发现逻辑明明没有问题但是答案怎么都是错的才发现理解错了题目的意思,题目的意思是按下标顺序组成,意思就是可以不连续,我…...

CSP201409T5拼图
题意:给出一个 n m nm nm的方格图,现在要用如下L型的占3个的积木拼到这个图中,总共有多少种拼法使图满。 #include<bits/stdc.h> using namespace std; long long n,m,k1,Now; int Mod1000000007; struct Matrix {long long a[129][129];Matrix(…...
mongoDB 优化(2)索引
执行计划 语法:1 db.collection_xxx_t.find({"param":"xxxxxxx"}).explain(executionStats) 感觉这篇文章写得很好,可以参考 MongoDB——索引(单索引,复合索引,索引创建、使用)_mongo…...

【2024系统架构设计】案例分析- 5 Web应用
目录 一 基础知识 二 真题 一 基础知识 1 Web应用技术分类 大型网站系统架构的演化:高性能、高可用、可维护、应变、安全。 从架构来看:MVC,MVP,MVVM,REST,Webservice,微服务。...
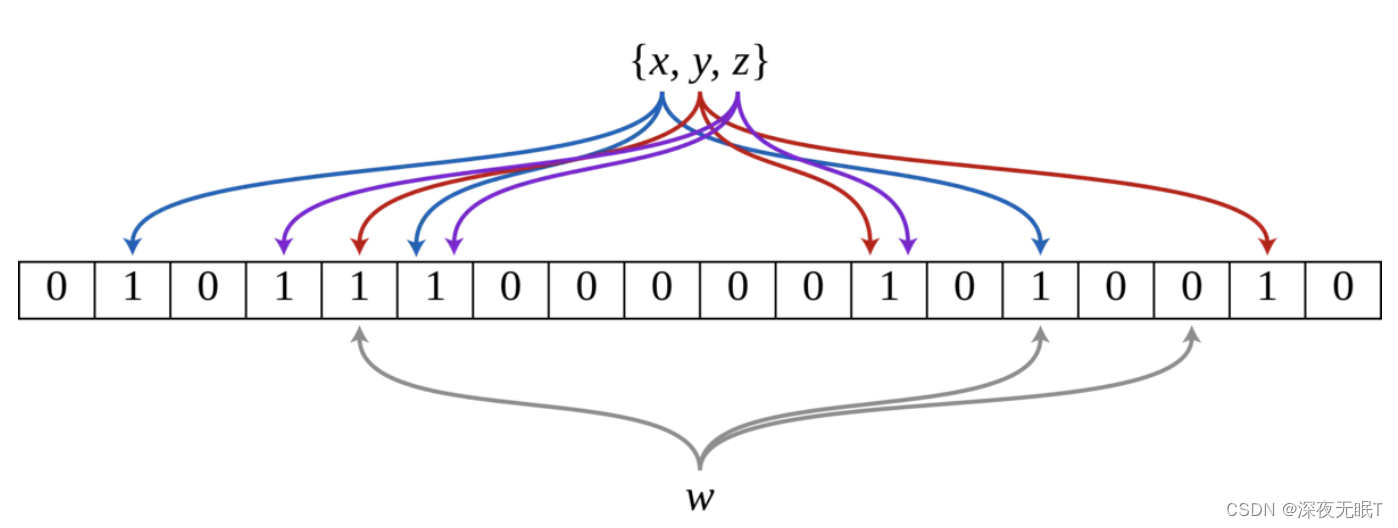
布隆过滤器详解及java实现
什么是布隆过滤器? 布隆过滤器(Bloom Filter)是一种数据结构,用于判断一个元素是否属于一个集合。它的特点是高效地判断一个元素是否可能存在于集合中,但是存在一定的误判率。 布隆过滤器的基本原理是使用一个位数组…...
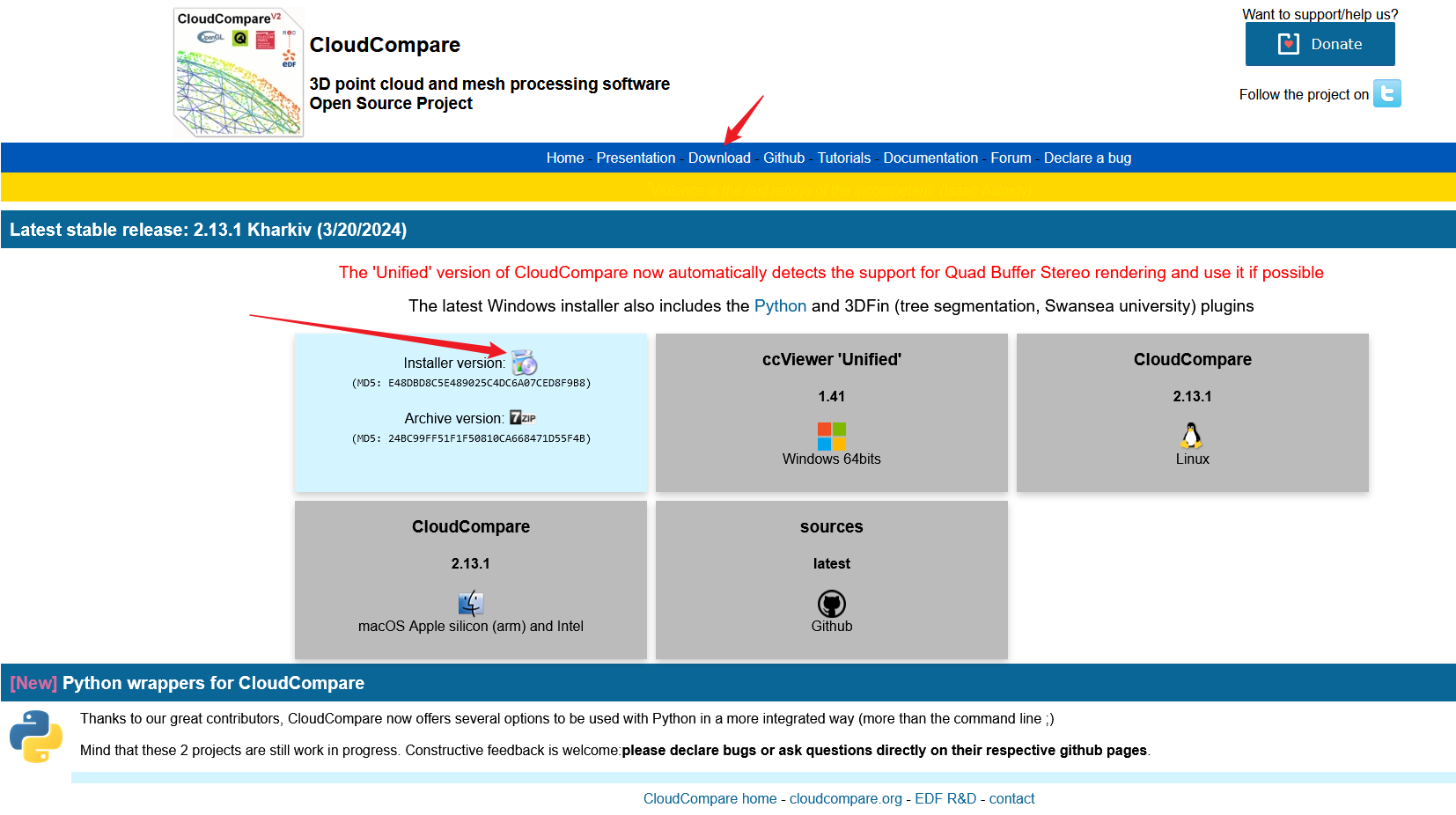
CloudCompare 点云工具
CloudCompare 点云工具 1. CloudCompare简介1.1 CloudCompare下载 2. CloudCompare安装 1. CloudCompare简介 CloudCompare 是一款开源的三维点云处理软件,它提供了一系列功能来处理、查看和分析三维点云数据。这个软件可以用于许多不同的应用领域,包括…...

Linux 著名的sudo、su是什么?怎么用?
一、su 什么是su? su命令(简称是:substitute 或者 switch user )用于切换到另一个用户,没有指定用户名,则默认情况下将以root用户登录。 为了向后兼容,su默认不改变当前目录,只设…...
C语言分支语句
一、什么是语句 C语句可分为以下五类: 表达式语句 函数调用语句 控制语句 复合语句 空语句 本周后面介绍的是控制语句。 控制语句用于控制程序的执行流程,以实现程序的各种结构方式,它们由特定的语句定义符组成,C语 言有…...

android 资源文件混淆
AGP7.0以上引用AndResGuard有坑 记录下 在项目的build.gradle中添加如下 buildscript {ext.kotlin_version "1.4.31"repositories {google()jcenter()maven {url "https://s01.oss.sonatype.org/content/repositories/snapshots/"}}dependencies {class…...
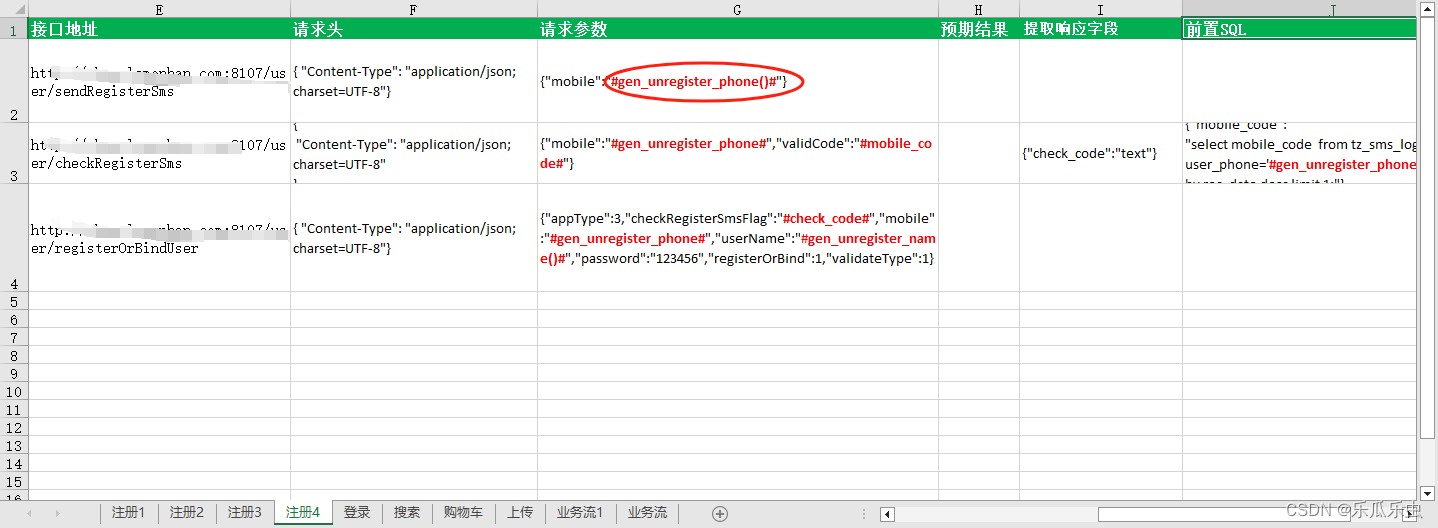
注册接口和前置SQL及数据生成及封装
注册接口 演示注册接口的三步操作:【注册流程逻辑】 第一步:发送注册短信验证码接口请求 请求方法: put 请求地址:http://shop.lemonban.com:8107/user/sendRegisterSms 请求参数:{“mobile”:“13422337766”} 请求头…...

鸿蒙实战开发-通过输入法框架实现自绘编辑框
介绍 本示例通过输入法框架实现自会编辑框,可以绑定输入法应用,从输入法应用输入内容,显示和隐藏输入法。 效果预览 使用说明 1.点击编辑框可以绑定并拉起输入法,可以从输入法键盘输入内容到编辑框。 2.可以点击attach/dettac…...

深度学习中的注意力模块的添加
在深度学习中,骨干网络通常指的是网络的主要结构或主干部分,它负责从原始输入中提取高级特征。骨干网络通常由卷积神经网络(CNN)或者类似的架构组成,用于对图像、文本或其他类型的数据进行特征提取和表示学习。 注意力…...
Docker 部署开源远程桌面工具 RustDesk
RustDesk是一款远程控制,远程协助的开源软件。完美替代TeamViewer ,ToDesk,向日葵等平台。关键支持自建服务器,更安全私密远程控制电脑!官网地址:https://rustdesk.com/ 环境准备 1、阿里云服务器一 台&a…...
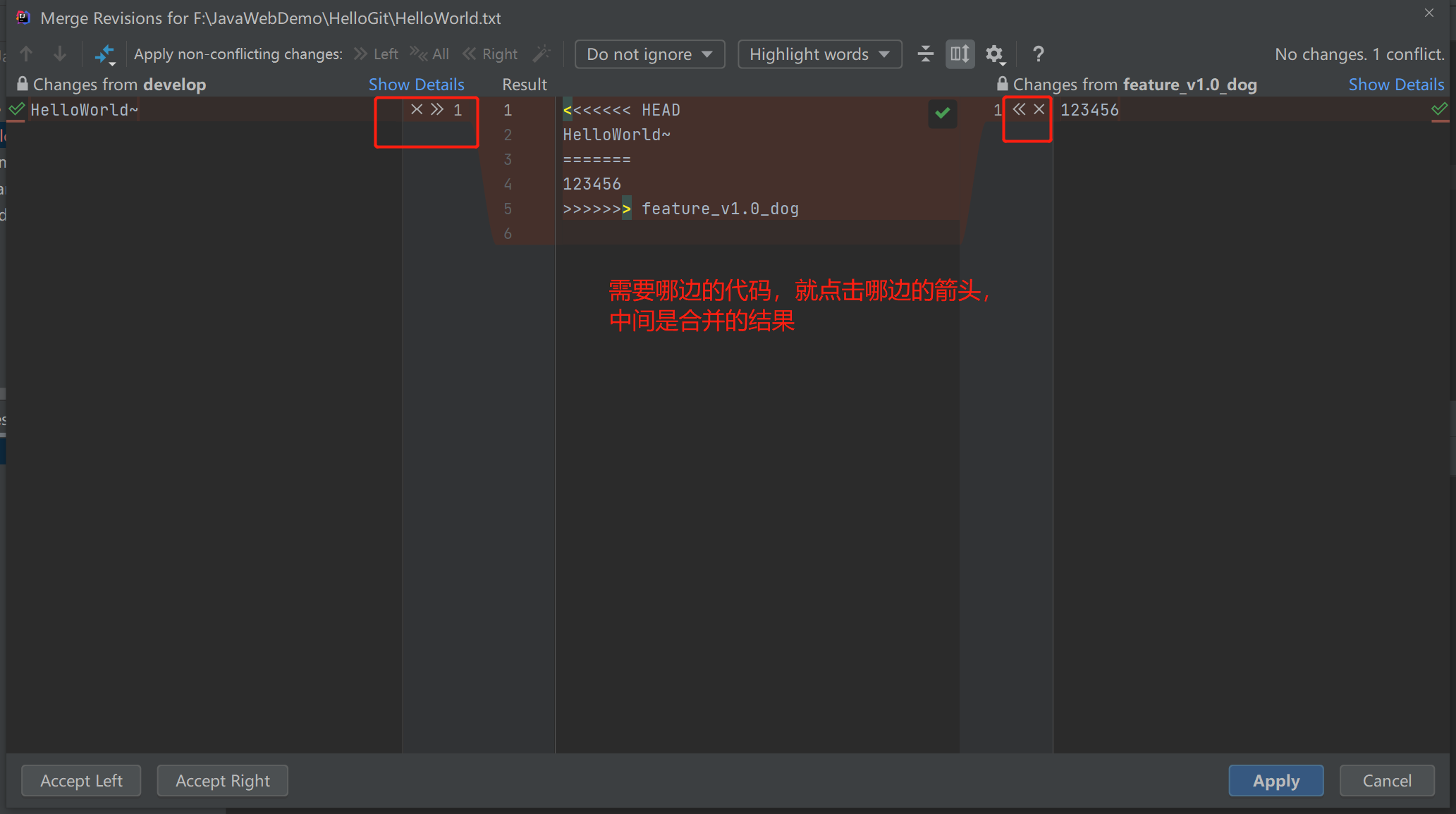
intellij idea 使用git ,快速合并冲突
可以选择左边的远程分支上的代码,也可以选择右边的代码,而中间是合并的结果。 一个快速合并冲突的小技巧: 如果冲突比较多,想要快速合并冲突。也可以直接点击上图中 Apply non-conflicting changes 旁边的 All 。 这样 Idea 就会…...

AcWing26. 二进制中1的个数。三种解法Java
输入一个 3232 位整数,输出该数二进制表示中 11 的个数。 注意: 负数在计算机中用其绝对值的补码来表示。 数据范围 −100≤ 输入整数 ≤100 样例1 输入:9 输出:2 解释:9的二进制表示是1001,一共有2个…...
)
【ADB】常见命令汇总(持续更新)
▒ 目录 ▒ 🛫 导读开发环境 1️⃣ 设备连接和识别2️⃣ 应用程序管理3️⃣ 文件传输和管理4️⃣ 设备信息和日志5️⃣ 设备操作和控制6️⃣ 截图相关🛬 文章小结📖 参考资料 🛫 导读 Android调试桥(ADB)是…...

【递归与递推】数的计算|数的划分|耐摔指数
1.数的计算 - 蓝桥云课 (lanqiao.cn) 思路: 1.dfs的变量>每一次递归什么在变? (1)当前数的大小一直在变:sum (2)最高位的数:k 2.递归出口:最高位数字为1 3.注意&#…...

软件设计师下午题训练1-3题 练习真题训练10
一、2019下1、问题1E1:帮买顾问E2:车辆交易系统E3:物流商2、问题2D1:线索表D2:订单表D3:路线表D4:合约表D5:物流商表3、问题3数据流 起点 终点物流信息 P5 …...
)
Vit工程化应用(timm 库)
pip install timm import timm import torch from PIL import Image import requests from io import BytesIO# 1. 加载模型 (ViT Base版本,16x16图块,在ImageNet-1k上预训练) # 设置 pretrainedTrue 自动下载权重 model timm.create_model(vit_base_pa…...

千万级用户购物车系统的架构设计
我们当时搞的购物车服务,其实还是有点庞大的,看似是一个简单的CRUD,但是当你真正去实现一个购物车的时候,发现压根不是那回事。 当商品类型从单一SKU扩展到普通商品、套餐组合、活动商品,拼单等混合的时候,…...

一键获取国家中小学智慧教育平台电子课本:开源解析工具完全指南
一键获取国家中小学智慧教育平台电子课本:开源解析工具完全指南 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容。 …...

法律AI助手weclaw:基于RAG与领域大模型的智能法律应用实践
1. 项目概述:一个面向法律领域的智能助手 最近在关注一些开源项目,发现了一个挺有意思的,叫 shp-ai/weclaw 。光看这个名字,就能猜个八九不离十——“weclaw”,听起来像是“we”和“law”的结合,指向性非…...

HealthGPT入门教程:5分钟快速搭建你的个人健康助手
HealthGPT入门教程:5分钟快速搭建你的个人健康助手 【免费下载链接】HealthGPT Query your Apple Health data with natural language 💬 🩺 项目地址: https://gitcode.com/gh_mirrors/he/HealthGPT 想要用自然语言查询你的Apple健康…...

RK3368安卓9.0固件烧录后开机卡Recovery?手把手教你调整分区表解决4GB闪存空间不足
RK3368安卓9.0固件烧录实战:4GB闪存分区优化全解析 当你满怀期待地将Android 9.0固件烧录到RK3368开发板,却发现设备直接进入了Recovery模式,屏幕上躺着那个令人沮丧的红色感叹号机器人——这可能是每个嵌入式开发者都经历过的"入门仪式…...

基于OneBot协议与Go语言的QQ机器人框架Samantha开发实践
1. 项目概述:一个开源的QQ机器人框架 最近在折腾QQ机器人,想给自己的社群或者频道加点自动化功能,比如定时提醒、关键词回复、游戏查询什么的。市面上现成的机器人框架不少,但要么功能臃肿,要么配置复杂,要…...

Mac Mouse Fix终极指南:如何让普通鼠标在Mac上获得超越触控板的体验
Mac Mouse Fix终极指南:如何让普通鼠标在Mac上获得超越触控板的体验 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 还在为Mac上第三…...

A Survey for Image Quality Assessment: From Handcrafted Features to Deep Learning
1. 图像质量评估的起源与核心挑战 当你用手机拍完一张照片,系统自动弹出"画质优化建议"时,背后就是图像质量评估(IQA)技术在发挥作用。这项技术最早可以追溯到上世纪70年代电视信号传输质量检测,当时工程师们…...