小白学大模型:什么是生成式人工智能?
什么是生成式人工智能?
在过去几年中,机器学习领域取得了迅猛进步,创造了人工智能的一个新的子领域:生成式人工智能。这些程序通过分析大量的数字化材料产生新颖的文本、图像、音乐和软件,我将这些程序简称为“GAIs”。
革命开始
第一波GAIs主要致力于进行自然语言对话。被称为“大型语言模型”(LLMs)的这些模型已经展示出在各种任务上超凡的表现,拥有超越人类的能力,同时也显示出对虚假、不合逻辑的倾向,以及表达虚假情感的倾向,比如对对话者表达爱意。它们用通俗的语言与用户交流,并轻松解决各种复杂问题。
但这只是GAI革命的开始。支撑GAIs的技术是相当通用的,任何可以收集和准备进行处理的数据集,GAIs都能够学习,这在现代数字世界是一个相对简单的任务。
AGI vs GAI
AGI(人工通用智能)与GAI(生成式人工智能)不可混淆,AGI一直是科学家们世代追求的幻想,更不用说无数科幻电影和书籍了。值得注意的是,答案是“有条件的肯定”。在实际应用中,这些系统是多才多艺的“合成大脑”,但这并不意味着它们具有人类意义上的“思想”。它们没有独立的目标和欲望、偏见和愿望、情感和感觉:这些是独特的人类特征。但是,如果我们用正确的数据对它们进行训练并指导它们追求适当的目标,这些程序可以表现得好像具有这些特征一样。
GAIs vs 早期构建智能机器
GAIs可以被指示执行(或至少描述如何执行)你几乎能想到的任何任务……尽管它们可能会耐心地解释,它们是万事通,也是大多数领域的专家。
-
LLMs只是进行统计单词预测,根据你提供的提示的上下文选择下一个最有可能的单词。但这种描述充其量是过于简化了,并掩盖了更深层次的真相。
-
LLMs是在大量信息的基础上进行训练的。它们处理并压缩其庞大的训练集,形成一种被称为神经网络的紧凑表示,但该网络不仅仅代表单词——它代表了它们的意义,以一种称为嵌入的巧妙形式表达出来。
LLM了解其“世界”(在训练阶段);然后,它评估您提示的含义,选择其答案的含义,并将该含义转换为单词。
人工智能的历史
什么是人工智能?
这是一个容易问出但难以回答的问题,有两个原因。首先,对于智能是什么,人们几乎没有达成共识。其次,凭借目前的情况,很少有理由相信机器智能与人类智能有很大的关系,即使看起来很像。
人工智能(AI)有许多提议的定义,每个定义都有其自己的侧重点,但大多数都大致围绕着创建能够表现出人类智能行为的计算机程序或机器的概念。学科的奠基人之一约翰·麦卡锡(John McCarthy)在1955年描述了这一过程,“就像制造一台机器以人类的方式行为一样”。
术语“人工智能”起源于何处?
“人工智能”一词的首次使用可以归因于一个特定的个人——约翰·麦卡锡(John McCarthy),他是一位1956年在新罕布什尔州汉诺威达特茅斯学院(Dartmouth College)的助理数学教授。与其他三位更资深的研究人员(哈佛大学的马文·明斯基、IBM的内森·罗切斯特和贝尔电话实验室的克劳德·香农)一起,麦卡锡提议在达特茅斯举办一次关于这个主题的夏季会议。
早期人工智能研究者是如何解决这个问题的?
在达特茅斯会议之后,对该领域的兴趣(以及某些领域对它的反对)迅速增长。研究人员开始着手各种任务,从证明定理到玩游戏等。一些早期的突破性工作包括阿瑟·塞缪尔(Arthur Samuel)于1959年开发的跳棋程序。
当时许多演示系统都专注于所谓的“玩具问题”,将其适用性限制在某些简化或自包含的世界中,如游戏或逻辑。这种简化在一定程度上受到当时有限的计算能力的驱使,另一方面也因为这并不涉及收集大量相关数据,而当时电子形式的数据很少。
机器学习是什么?
从其早期起源开始,人工智能研究人员就认识到学习能力是人类智能的重要组成部分。问题是人们是如何学习的?我们能否以与人类相同的方式,或至少与人类一样有效地编写计算机来学习?
在机器学习中,学习是中心问题——顾名思义。说某物被学习了意味着它不仅仅被捕捉并存储在数据库中的数据一样——它必须以某种方式表示出来,以便可以加以利用。一般来说,学习的计算机程序会从数据中提取模式。
生成式人工智能的原理
大型语言模型(LLMs)
大型语言模型(LLMs)是一种生成人工智能系统,用于以纯文本形式生成对问题或提示的回应。这些系统使用专门的多层次和多方面的神经网络,在非常大的自然语言文本集合上进行训练,通常从互联网和其他合适的来源收集而来。
基础模型
训练一个LLM可能非常耗时和昂贵——如今,最常见的商业可用系统在数千台强大处理器上同时训练数周,耗资数百万美元。但不用担心,这些程序通常被称为“基础模型”,具有广泛的适用性和长期的使用寿命。它们可以作为许多不同类型的专业LLM的基础,尽管直接与它们交互也是完全可能的(而且很有用和有趣)。
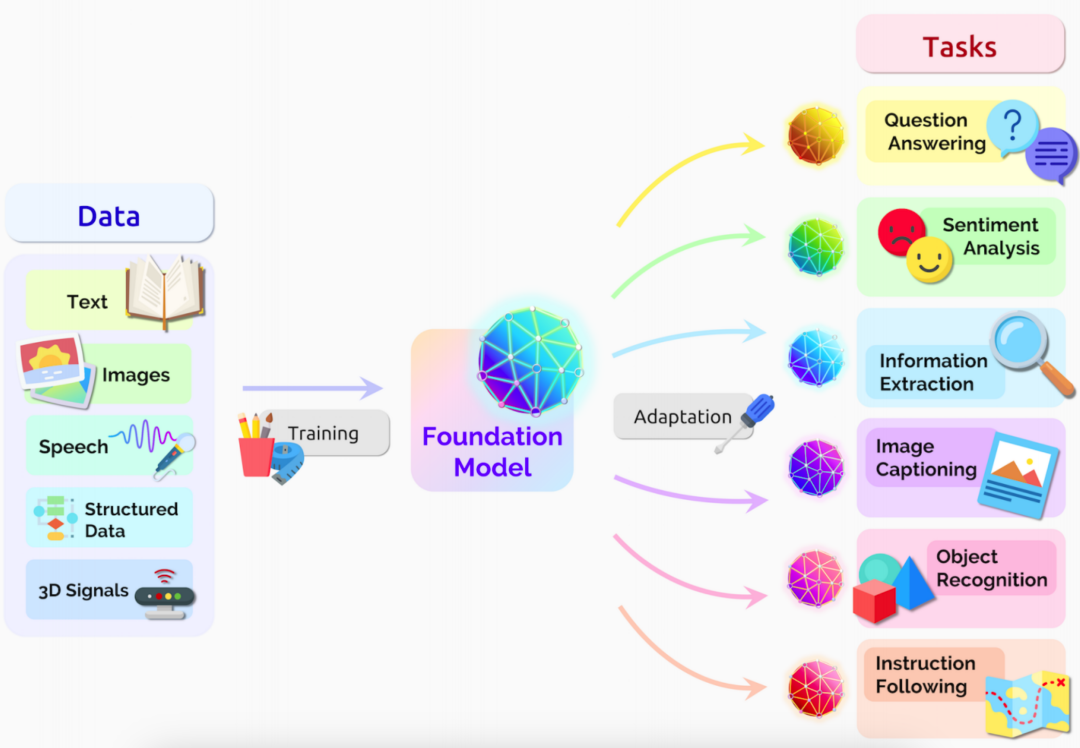
人类反馈强化学习
LLM完成了对大型文本语料库的“基础训练”后,就要进入“修身养性”的阶段。这包括向它提供一系列示例,说明它应该如何礼貌地和合作地回答问题(响应“提示”),以及最重要的是,它不被允许说什么(当然,这充满了反映其开发者态度和偏见的价值判断)。与初始训练步骤形成对比,初始训练步骤大多是自动化过程,这个社交化步骤是通过所谓的人类反馈强化学习(RLHF)来完成的。RLHF就是其名,人类审查LLM对一系列可能引起不当行为的提示的反应,然后一个人向它解释回应的问题(或禁止的内容),帮助LLM改进。
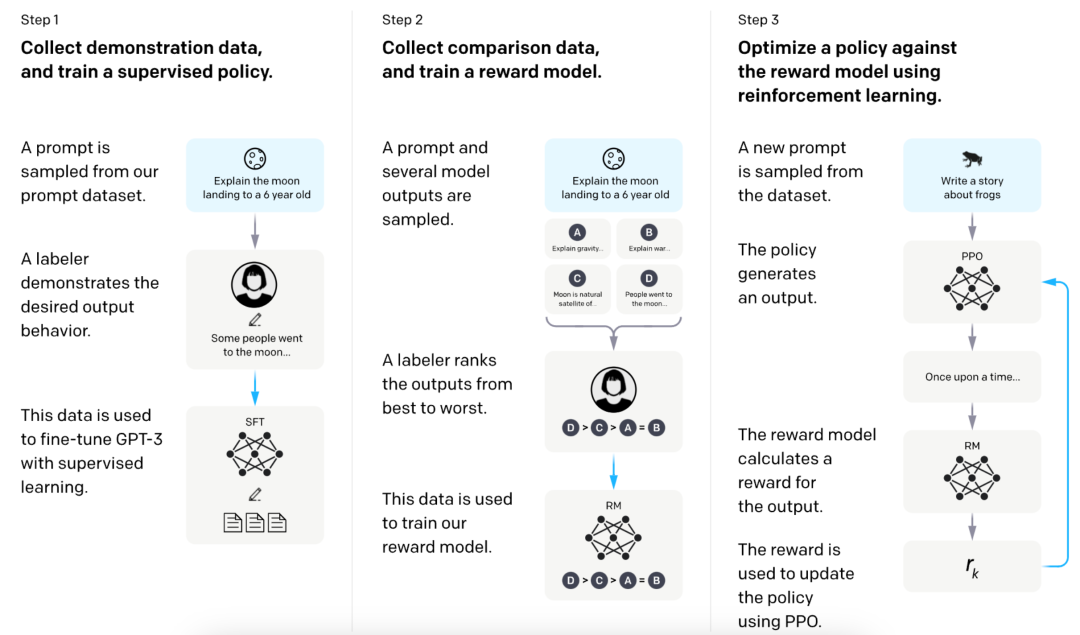
模型输入与输出
完成训练后,LLM接受用户(你)的提示或问题作为输入,然后对其进行转换,并生成一个回应。与训练步骤相比,这个过程快速而简单。但是它是如何将你的输入转换为回应的呢?
它们将这种“猜测下一个词”的技术扩展到更长的序列上。然而,重要的是要理解,分析和猜测实际上不是在词本身上进行的;而是在所谓的标记上进行的——它们代表词的部分,并且这些标记进一步以“嵌入”形式表达,旨在捕捉它们的含义。
大型语言模型(LLMs)如何工作?
简化的单词级解释忽略了LLMs如何在我们今天的计算机类别中表示这些大量的单词集合。在任何现有或想象中的未来计算机系统中,存储数千个单词的所有可能序列都是不现实的:与之相比,这些序列的数量使得宇宙中的原子数量看起来微不足道。因此,研究人员重新利用了神经网络的试验和真实方法,将这些巨大的集合减少为更易管理的形式。
神经网络最初被应用于解决分类问题——决定某物是什么。例如,您可能会输入一张图片,网络将确定它是否是狗还是猫的图像。为了有用,神经网络必须以一种使相关的输入产生相似结果的方式压缩数据。
什么是“嵌入”?
LLMs将每个单词表示为一种特定形式的向量(列表),称为嵌入。嵌入将给定的单词转换为具有特殊属性的向量(有序数字列表):相似的单词具有相似的向量表示。想象一下,“朋友”,“熟人”,“同事”和“玩伴”这些词的嵌入。目标是,嵌入应该将这些单词表示为彼此相似的向量。这通过代数组合嵌入来促进某些类型的推理。
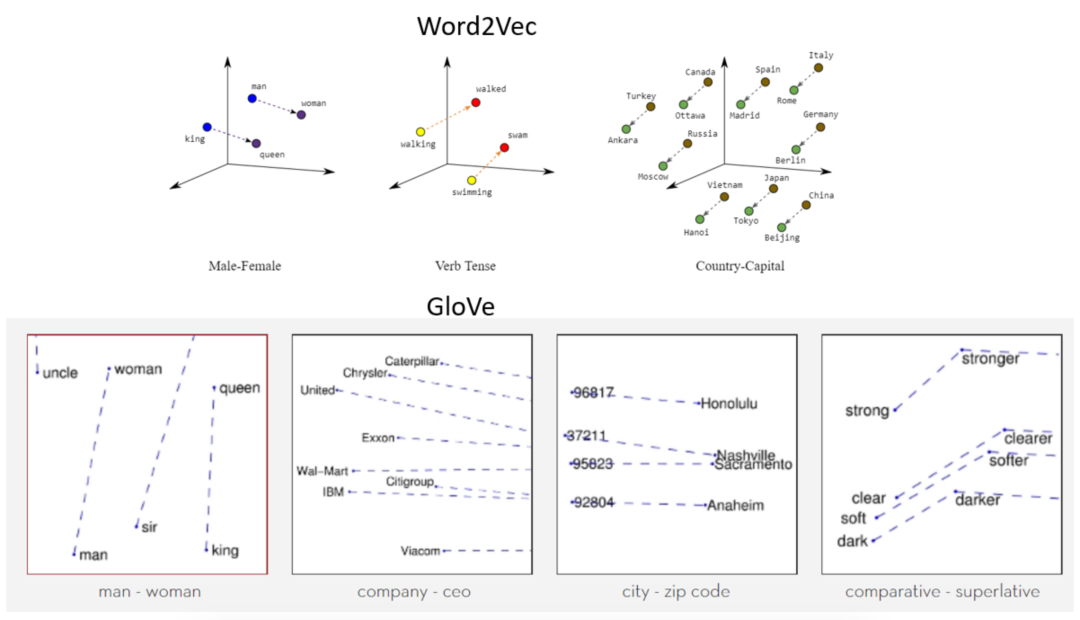
单词嵌入的一个缺点是它们并不固有地解决多义性的问题——单词具有多个含义的能力。处理这个问题有几种方法。例如,如果训练语料库足够详细,单词出现的上下文将倾向于聚合成统计簇,每个簇代表同一个单词的不同含义。这允许LLM以模棱两可的方式表示单词,将其与多个嵌入相关联。多义性的计算方法是一个持续研究的领域。
单词嵌入是如何表示含义的?
当您想知道一个词的含义时,您会怎么做?当然是查字典。在那里,您会找到什么?关于词义的描述,当然是用词语表达的。您读了定义后相信您理解了一个词的含义。换句话说,就是,通过与其他单词的关系来表示单词的含义通常被认为是语义的一种满意的实际方法。
当然,有些词确实指的是现实世界中的真实事物。但是,如果您只是在单词的领域内工作,那么事实证明这并不像您想象的那么重要。在相互关联的定义的混乱中有太多的内在结构,以至于您关于给定单词的几乎所有需要知道的东西都可以通过它与其他单词的关系来编码。
人工神经网络(ANN)
人工神经网络(ANN)是受到真实神经网络的某些假定组织原则启发的计算机程序,简而言之,就是生物大脑。尽管如此,人工神经网络与真实神经网络之间的关系大多是希望的,因为对大脑实际功能了解甚少。
人工神经网络中的神经元通常组织成层。底层也称为“输入”层,因为我们要将要分类的图片输入到这里。现在就像真正的神经元一样,我们必须表示每个输入神经元是否被激活(“发射”)或不被激活。其他内部层是行动发生的地方。这些被称为“隐藏”层,因为它们夹在输入层和输出层之间。每个隐藏层中的神经元与它们上面和下面的层中的所有神经元相连。这些相互连接被建模为数值权重,例如,零表示“未连接”,一表示“强连接”,负一表示负连接。
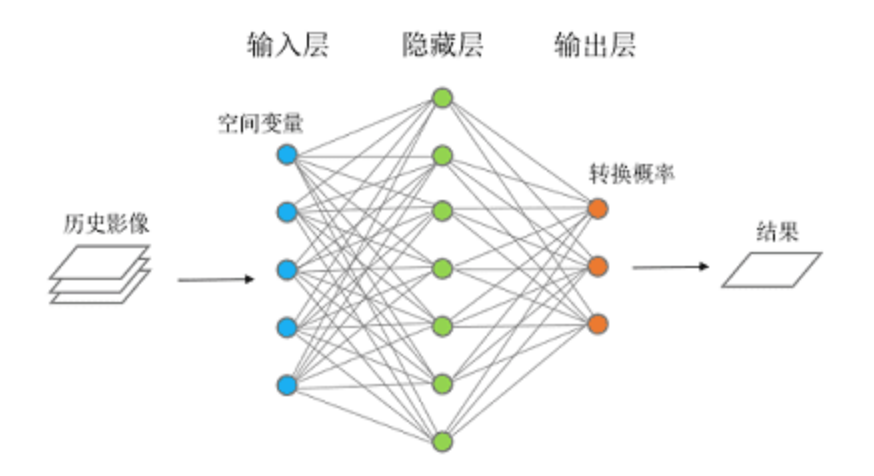
神经网络的工作原理如下:我们根据要分类的图片设置输入(底层)级别的神经元的值。然后对于上一级的每个神经元,我们通过计算下一级神经元与较低级神经元之间的连接的权重乘积来计算其激活值。我们继续这个过程,从每一级横跨,然后向上一级工作。当我们到达顶部时,如果一切都按预期进行,顶层的一个神经元将被高度激活,而另一个不会,这就给了我们答案。
Transformer
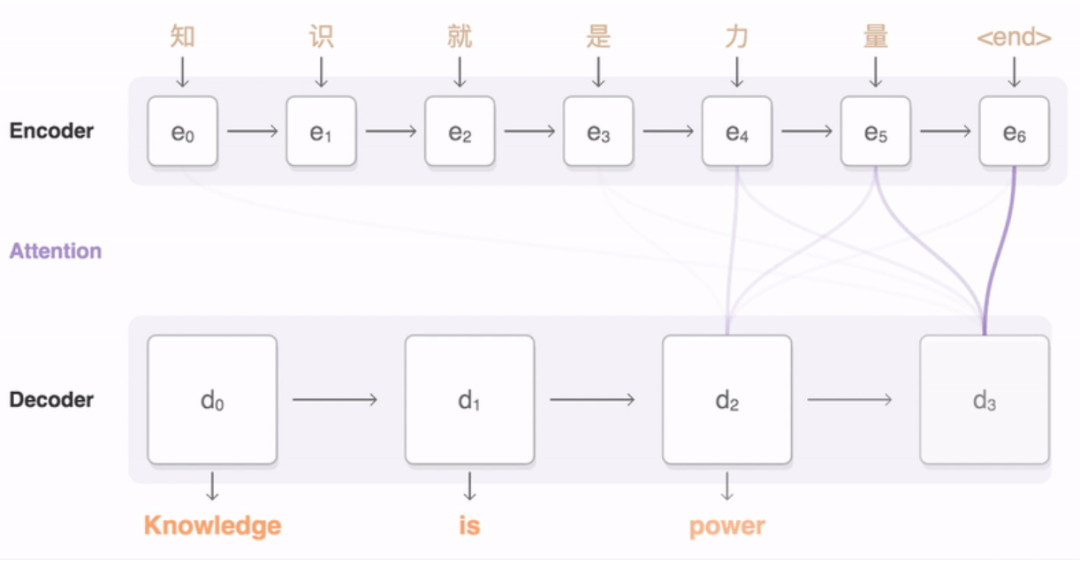
Transformer是一种特殊类型的神经网络,通常用于大型语言模型(LLM)。当一个Transformer模型被给予一句话进行处理时,它不会单独查看每个单词。相反,它一次查看所有单词,并为每对单词计算一个“注意分数”。注意分数确定了句子中每个单词应该对其他每个单词的解释产生多大影响。
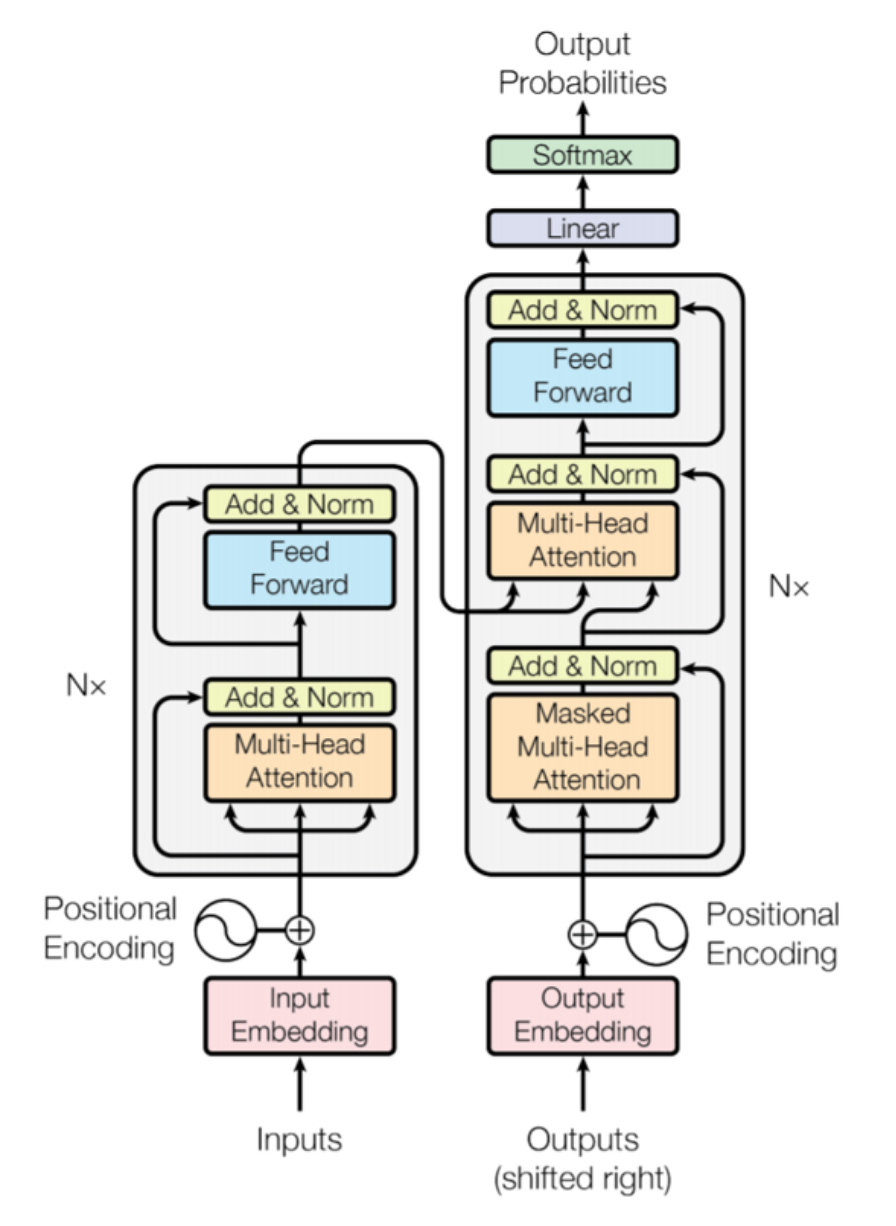
例如,如果句子是“猫坐在垫子上”,当模型处理单词“坐”时,它可能会更多地关注单词“猫”(因为“猫”是坐的对象),而对单词“垫子”关注较少。但是当处理单词“上”时,它可能会更多地关注“垫子”。
当你要求LLM回答问题时,类似的过程也会发生。LLM首先将您的单词转换为嵌入,就像它对其训练示例所做的那样。然后,它以相同的方式处理您的询问,使其能够专注于输入的最重要部分,并使用这些来预测如果您开始回答问题,则输入的下一个单词可能是什么。
Transformer vs 词嵌入
Transformer模型利用词嵌入来表达语言中的复杂概念。在Transformer中,每个单词都被表示为一个高维向量,而这些向量在表示空间中的位置反映了单词之间的语义关系。例如,具有相似含义的单词在表示空间中可能会更加接近,而含义不同的单词则会相对远离。
通过使用这种高维表示,Transformer能够更好地理解和生成自然语言。它们通过学习大量文本数据,自动调整词嵌入向量的参数,使得模型能够根据上下文理解单词的含义,并生成连贯的语言输出。Transformer模型中的注意力机制允许模型集中注意力于输入中与当前任务相关的部分,从而提高了模型在处理长文本序列和复杂语境中的性能。
什么是token?
在语言模型中,"tokens"是指单词、单词部分(称为子词)或字符转换成的数字列表。每个单词或单词部分都被映射到一个特定的数字表示,称为token。这种映射关系通常是通过预定义的规则或算法完成的,不同的语言模型可能使用不同的tokenization方案,但重要的是要保证在相同的语境下,相同的单词或单词部分始终被映射到相同的token。

大多数语言模型倾向于使用子词(tokenization),因为这种方法既高效又灵活。子词tokenization能够处理单词的变形、错字等情况,从而更好地识别单词之间的关系。
幻觉
幻觉是指LLMs在回答问题或提示时,并不会查阅其训练时接触到的所有词序列,这是不切实际的。这意味着它们并不一定能够访问所有原始内容,而只能访问那些信息的统计摘要。与你一样,LLMs可能“知道”很多词,但它们无法重现创建它们的确切序列。
LLMs很难区分现实和想象。至少目前来说,它们没有很好的方法来验证它们认为或相信可能是真实的事物的准确性。即使它们能够咨询互联网等其他来源,也不能保证它们会找到可靠的信息。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

相关文章:
小白学大模型:什么是生成式人工智能?
什么是生成式人工智能? 在过去几年中,机器学习领域取得了迅猛进步,创造了人工智能的一个新的子领域:生成式人工智能。这些程序通过分析大量的数字化材料产生新颖的文本、图像、音乐和软件,我将这些程序简称为“GAIs”…...

并发编程01-深入理解Java并发/线程等待/通知机制
为什么我们要学习并发编程? 最直白的原因,因为面试需要,我们来看看美团和阿里对 Java 岗位的 JD: 从上面两大互联网公司的招聘需求可以看到, 大厂的 Java 岗的并发编程能力属于标配。 而在非大厂的公司, 并…...
3.类与对象(中篇)介绍了类的6个默认构造函数,列举了相关案例,实现了一个日期类
1.类的6个默认成员函数 如果一个类中什么成员都没有,简称为空类。 空类中真的什么都没有吗?并不是,任何类在什么都不写时,编译器会自动生成以下6个默认成员函数。 默认成员函数:用户没有显式实现,编译器会…...

Vue实现手机APP页面的切换,如何使用Vue Router进行路由管理呢?
在Vue中,实现手机APP页面的切换,通常会使用Vue Router进行路由管理。Vue Router是Vue.js官方的路由管理器,它和Vue.js深度集成,使构建单页面应用变得易如反掌。 以下是一个简单的步骤说明,展示如何使用Vue Router实现…...
软考--软件设计师(软件工程总结2)
目录 1.测试方法 2.软件项目管理 3.软件容错技术 4.软件复杂性度量 5.结构化分析方法(一种面向数据流的开发方法) 6.数据流图 1.测试方法 软件测试:静态测试(被测程序采用人工检测,计算机辅助静态分析的手段&…...

渗透测试之SSRF漏洞
一、SSRF介绍 SSRF(Cross-site Scripting,简称XSS)是一种安全漏洞,它允许攻击者通过构造特定的请求,使服务器发起对外网无法访问的内部系统请求。这种漏洞通常发生在服务端提供了从其他服务器应用获取数据的功能&#…...
【C++】1957. 求三个数的平均数
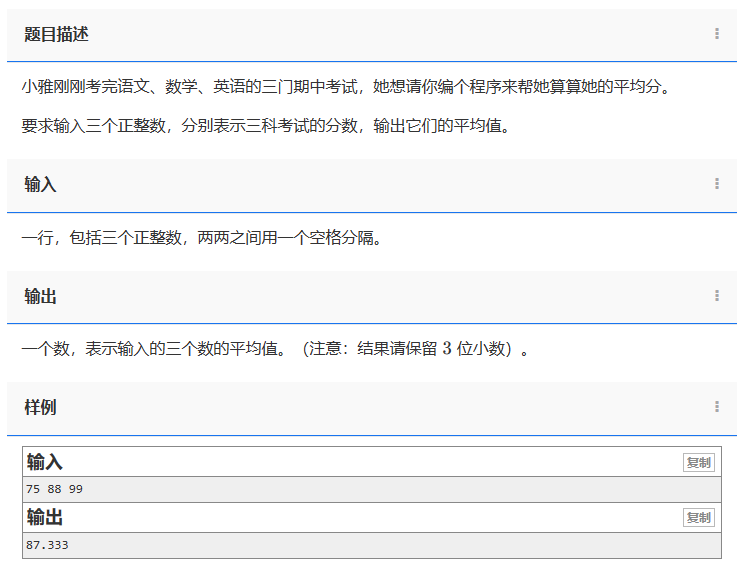
问题:1957. 求三个数的平均数 类型:基本运算、小数运算 题目描述: 小雅刚刚考完语文、数学、英语的三门期中考试,她想请你编个程序来帮她算算她的平均分。 要求输入三个正整数,分别表示三科考试的分数,输…...
GPU部署ChatGLM3
首先,检查一下自己的电脑有没有CUDA环境,没有的话,去安装一个。我的电脑是4060显卡,买回来就自带这些环境了。没有显卡的话,也不要紧,这个懒人安装包支持CPU运行,会自动识别没有GPU,…...

Windows远程执行
Windows远程执行 前言 1、在办公环境中,利用系统本身的远程服务进行远程代码执行甚至内网穿透横向移动的安全事件是非常可怕的,因此系统本身的一些远程服务在没有必要的情况下建议关闭,防止意外发生; 2、作为安全人员࿰…...
AJAX —— 学习(一)
目录 一、原生 AJAX (一)AJAX 介绍 1.理解 2.作用 3.最大的优势 4.应用例子 (二)XML 介绍 1.理解 2.作用 (三)AJAX 的特点 1.优点 2.缺点 二、HTTP 协议 (一)HTTP 介…...
Activity——idea(2020以后)配置actiBPM
文章目录 前言jar下载idea 安装本地扩展插件 前言 2020及之后版本的idea中,未维护对应的actiBPM扩展插件。如果需要安装该插件,则需要使用本地导入 jar的方式。 jar下载 访问官方网站,搜索对应的actiBPM扩展插件。 https://plugins.jetbra…...

MyBatis——配置优化和分页插件
MyBatis配置优化 MyBatis配置文件的元素结构如下: configuration(配置) properties(属性) settings(设置) typeAliases(类型别名) plugins(插件)…...

[蓝桥杯 2013 省 B] 翻硬币
[蓝桥杯 2013 省 B] 翻硬币 题目背景 小明正在玩一个“翻硬币”的游戏。 题目描述 桌上放着排成一排的若干硬币。我们用 * 表示正面,用 o 表示反面(是小写字母,不是零),比如可能情形是 **oo***oooo,如果…...
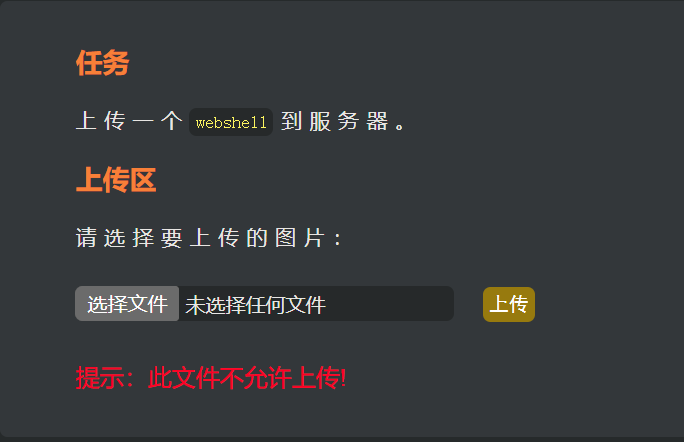
[BT]BUUCTF刷题第13天(4.1)
第13天 Upload-Labs-Linux (Basic) Pass-01 根据题目提示,该题为绕过js验证。 一句话木马: <?php eval(system($_POST["cmd"]));?> // 符号 表示后面的语句即使执行错误,也不报错。 // eval() 把括号内的字符串全部…...

特别详细的Spring Cloud 系列教程1:服务注册中心Eureka的启动
Eureka已经被Spring Cloud继承在其子项目spring-cloud-netflix中,搭建Eureka Server的方式还是非常简单的。只需要通过一个独立的maven工程即可搭建Eureka Server。 我们引入spring cloud的依赖和eureka的依赖。 <dependencyManagement><!-- spring clo…...
Day108:代码审计-PHP模型开发篇MVC层动态调试未授权脆弱鉴权未引用错误逻辑
目录 案例1-Xhcms-动态调试-脆弱的鉴权逻辑 案例2-Cwcms-动态调试-未引用鉴权逻辑 案例3-Bosscms-动态调试-不严谨的鉴权逻辑 知识点: 1、PHP审计-动态调试-未授权安全 2、PHP审计-文件对比-未授权安全 3、PHP审计-未授权访问-三种形态 动态调试优点: 环境配置&…...
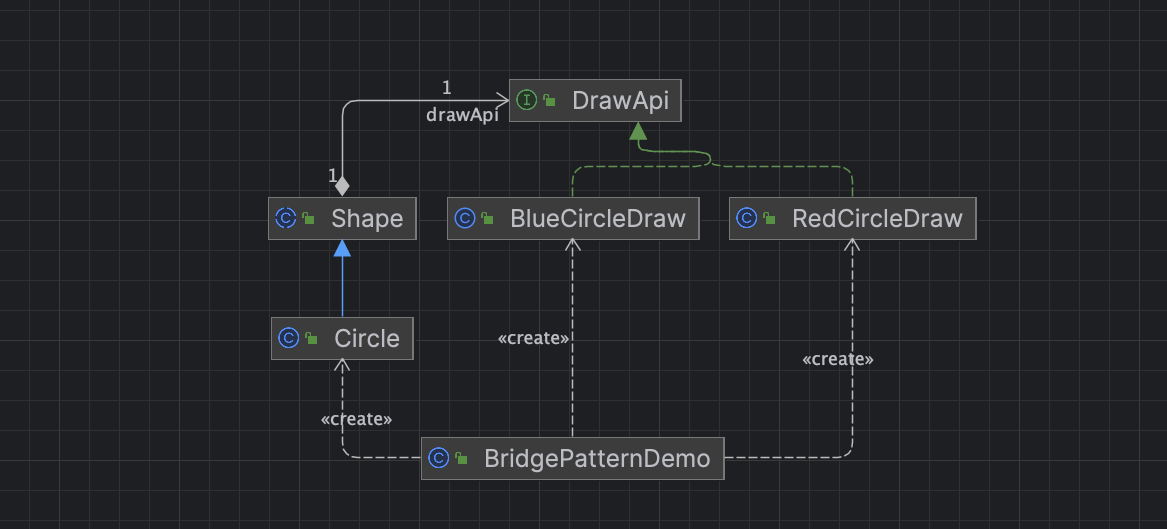
重读Java设计模式: 桥接模式详解
引言 在软件开发中,经常会遇到需要在抽象与实现之间建立连接的情况。当系统需要支持多个维度的变化时,使用传统的继承方式往往会导致类爆炸和耦合度增加的问题。为了解决这一问题,我们可以使用桥接模式。桥接模式是一种结构型设计模式&#…...

新规解读 | 被网信办豁免数据出境申报义务的企业,还需要做什么?
为了促进数据依法有序自由流动,激发数据要素价值,扩大高水平对外开放,《促进和规范数据跨境流动规定》(以下简称《规定》)对数据出境安全评估、个人信息出境标准合同、个人信息保护认证等数据出境制度作出优化调整。 …...
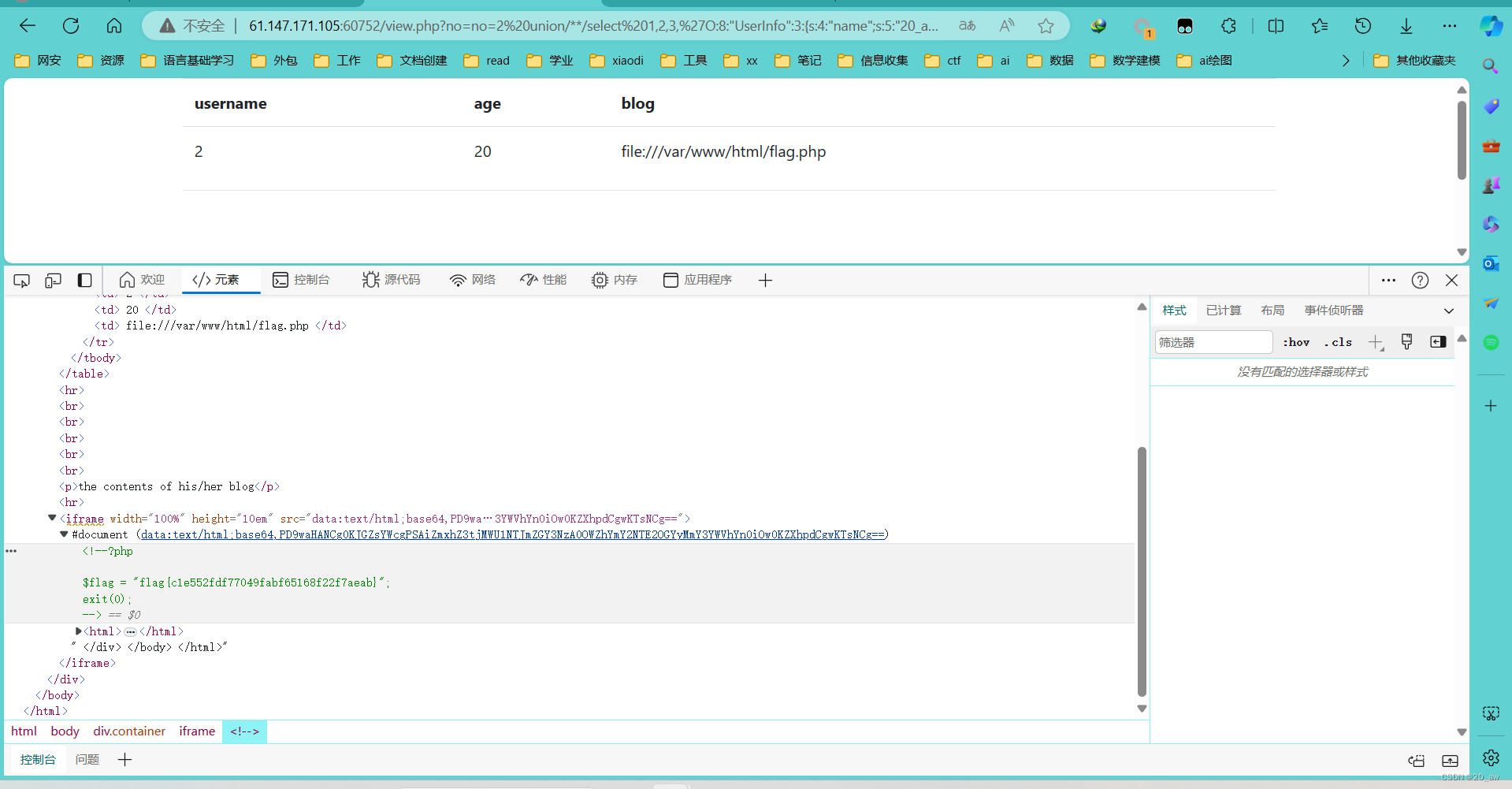
fakebook-攻防世界
题目 先目录扫描一下 dirseach 打开flag.php是空白的 访问robots.txt,访问user.php.bak <?php class UserInfo { public $name ""; public $age 0; public $blog ""; public function __construct($name, $age, $blog) { …...
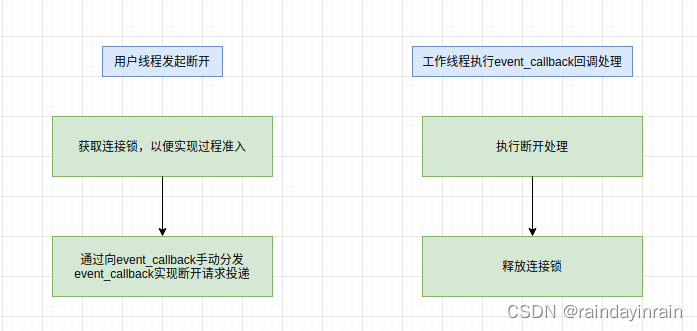
mynet开源库
1.介绍 个人实现的c开源网络库. 2.软件架构 1.结构图 2.基于event的自动分发机制 3.多优先级分发队列,延迟分发队列 内部event服务于通知机制的优先级为0,外部event优先级为1. 当集中处理分发的event_callback时,…...
)
告别Qt默认英文!3分钟搞定QMessageBox按钮中文显示(附完整代码示例)
3分钟实现QMessageBox按钮中文显示的实战指南 刚接触Qt开发的程序员经常会遇到一个尴尬问题——精心设计的界面突然弹出英文按钮的对话框。这种"半中半英"的体验在交付给国内客户时尤为明显。今天我们就来解决这个看似简单却困扰很多开发者的问题,无需复杂…...

RT-Thread线程栈初始化详解:从栈溢出到精准内存管理
1. 项目概述:从栈溢出崩溃说起搞嵌入式RTOS开发,尤其是用RT-Thread的朋友,估计没少被“线程栈溢出”这个问题折磨过。程序跑着跑着就HardFault了,或者某个线程莫名其妙地“死”了,数据错乱,查到最后往往发现…...

React Fiber vs Vue 响应式:从调用栈到依赖图,前端两大架构的底层对决
写在前面 前端框架之争吵了快十年。但坦白说,大多数争论卡在"React 好用还是 Vue 好用"的层面,很少有人真正追问:这两个框架为什么从根上就是两套东西? 它们的差异不是 API 设计喜好不同,而是对"UI 的…...

如何永久保存微信聊天记录:WeChatMsg开源工具的完整解决方案
如何永久保存微信聊天记录:WeChatMsg开源工具的完整解决方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we…...

【Perplexity AI高手速成指南】:20年AI工程师亲授7大核心技能与3个避坑红线
更多请点击: https://kaifayun.com 第一章:Perplexity AI平台核心架构与能力边界 Perplexity AI 并非传统意义上的开源模型托管平台,而是一个以“答案溯源”为设计哲学的智能问答引擎。其底层融合了多阶段检索增强生成(RAG&#…...

软件测试中的bug管理:高效定位、跟踪与修复全流程解析
在软件测试全生命周期中,bug管理是保障产品质量、提升开发效率的核心环节。从bug的精准定位到全流程跟踪,再到最终的有效修复,每一个步骤都需要专业的方法、工具与团队协作。对于软件测试从业者而言,掌握科学的bug管理体系&#x…...

智能硬件企业如何高效备战行业展会:从策略到执行的全流程指南
1. 展会参与的价值与策略思考又到了一年一度的行业盛会密集期,最近我们团队正在紧锣密鼓地筹备即将到来的2023慕尼黑上海电子展。对于很多技术型公司,尤其是像我们这样专注于智能硬件核心方案的公司来说,参加大型专业展会从来都不是一件“可去…...

PCIe调试避坑指南:当你的设备报Malformed TLP/UR/UC错误时,到底发生了什么?
PCIe调试实战:Malformed TLP/UR/UC错误排查全解析 当PCIe设备突然抛出Malformed TLP、UR(Unsupported Request)或UC(Unexpected Completion)错误时,很多工程师的第一反应往往是翻查协议手册。但真实调试场景…...

从机翼到飞行:空气动力学核心概念与应用解析
1. 翼型:飞机飞行的秘密藏在形状里 第一次看到飞机机翼横截面时,我盯着那个水滴状的形状看了足足十分钟。这个被称为翼型的二维轮廓,藏着人类百年航空史最精妙的设计智慧。就像鱼类的流线型身体决定了游泳效率,翼型的每个曲线转折…...

三分钟解锁B站缓存:m4s-converter视频转换全解析
三分钟解锁B站缓存:m4s-converter视频转换全解析 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 还在为B站下架视频而烦恼吗…...