[尚硅谷 flink] 基于时间的合流——双流联结(Join)
文章目录
- 8.1 窗口联结(Window Join)
- 8.2 **间隔联结(Interval Join)**
8.1 窗口联结(Window Join)
Flink为基于一段时间的双流合并专门提供了一个窗口联结算子,可以定义时间窗口,并将两条流中共享一个公共键(key)的数据放在窗口中进行配对处理。
package org.example.watermark;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;public class WindowJoinDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<Tuple2<String, Integer>> ds1 = env.fromElements(Tuple2.of("a", 1),Tuple2.of("a", 2),Tuple2.of("b", 3),Tuple2.of("c", 4)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> value.f1 * 1000L));SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> ds2 = env.fromElements(Tuple3.of("a", 1, 1),Tuple3.of("a", 11, 1),Tuple3.of("b", 2, 1),Tuple3.of("b", 12, 1),Tuple3.of("c", 14, 1),Tuple3.of("d", 15, 1)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> value.f1 * 1000L));// TODO window join// 1. 落在同一个时间窗口范围内才能匹配// 2. 根据keyby的key,来进行匹配关联// 3. 只能拿到匹配上的数据,类似有固定时间范围的inner joinDataStream<String> join = ds1.join(ds2).where(r1 -> r1.f0) // ds1的keyby.equalTo(r2 -> r2.f0) // ds2的keyby.window(TumblingEventTimeWindows.of(Time.seconds(10))).apply(new JoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {/*** 关联上的数据,调用join方法* @param first ds1的数据* @param second ds2的数据* @return* @throws Exception*/@Overridepublic String join(Tuple2<String, Integer> first, Tuple3<String, Integer, Integer> second) throws Exception {return first + "<----->" + second;}});join.print();env.execute();}
}
其实仔细观察可以发现,窗口join的调用语法和我们熟悉的SQL中表的join非常相似:
SELECT * FROM table1 t1, table2 t2 WHERE t1.id = t2.id;
这句SQL中where子句的表达,等价于inner join … on,所以本身表示的是两张表基于id的“内连接”(inner join)。而Flink中的window join,同样类似于inner join。也就是说,最后处理输出的,只有两条流中数据按key配对成功的那些;如果某个窗口中一条流的数据没有任何另一条流的数据匹配,那么就不会调用JoinFunction的.join()方法,也就没有任何输出了。
8.2 间隔联结(Interval Join)
- 间隔联结的原理
间隔联结具体的定义方式是,我们给定两个时间点,分别叫作间隔的“上界”(upperBound)和“下界”(lowerBound);于是对于一条流(不妨叫作A)中的任意一个数据元素a,就可以开辟一段时间间隔:[a.timestamp + lowerBound, a.timestamp + upperBound],即以a的时间戳为中心,下至下界点、上至上界点的一个闭区间:我们就把这段时间作为可以匹配另一条流数据的“窗口”范围。所以对于另一条流(不妨叫B)中的数据元素b,如果它的时间戳落在了这个区间范围内,a和b就可以成功配对,进而进行计算输出结果。所以匹配的条件为:
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
这里需要注意,做间隔联结的两条流A和B,也必须基于相同的key;下界lowerBound应该小于等于上界upperBound,两者都可正可负;间隔联结目前只支持事件时间语义。
如下图所示,我们可以清楚地看到间隔联结的方式:
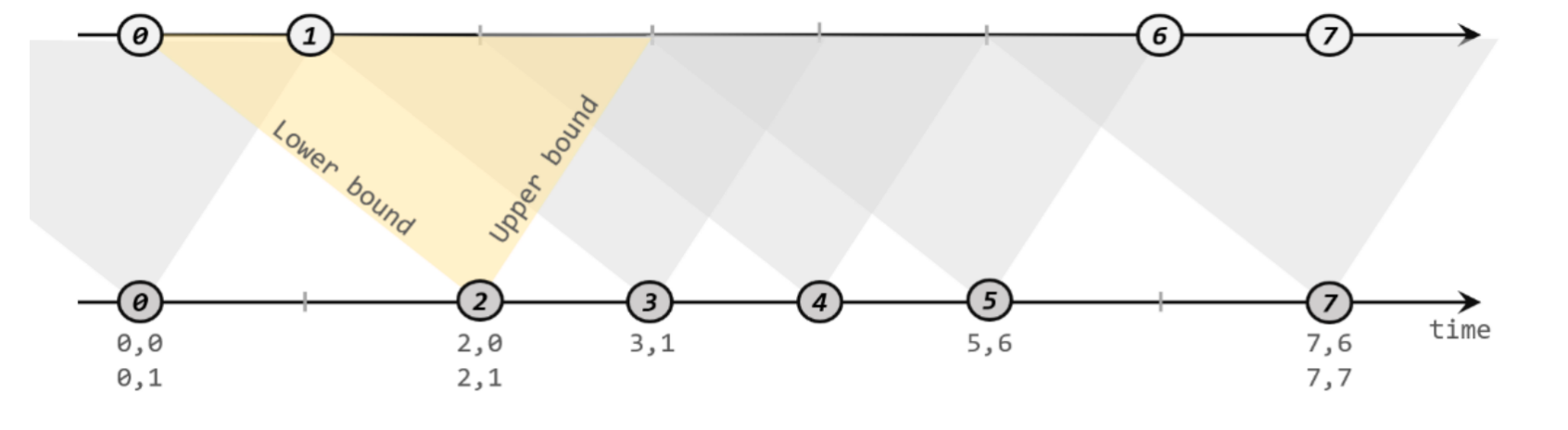
下方的流A去间隔联结上方的流B,所以基于A的每个数据元素,都可以开辟一个间隔区间。我们这里设置下界为-2毫秒,上界为1毫秒。于是对于时间戳为2的A中元素,它的可匹配区间就是[0, 3],流B中有时间戳为0、1的两个元素落在这个范围内,所以就可以得到匹配数据对(2, 0)和(2, 1)。同样地,A中时间戳为3的元素,可匹配区间为[1, 4],B中只有时间戳为1的一个数据可以匹配,于是得到匹配数据对(3, 1)。
所以我们可以看到,间隔联结同样是一种内连接(inner join)。与窗口联结不同的是,interval join做匹配的时间段是基于流中数据的,所以并不确定;而且流B中的数据可以不只在一个区间内被匹配。
stream1.keyBy(<KeySelector>).intervalJoin(stream2.keyBy(<KeySelector>)).between(Time.milliseconds(-2), Time.milliseconds(1)).process (new ProcessJoinFunction<Integer, Integer, String(){@Overridepublic void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {out.collect(left + "," + right);}});
- 处理迟到数据
//2. 调用 interval join
OutputTag<Tuple2<String, Integer>> ks1LateTag = new OutputTag<>("ks1-late", Types.TUPLE(Types.STRING, Types.INT));
OutputTag<Tuple3<String, Integer, Integer>> ks2LateTag = new OutputTag<>("ks2-late", Types.TUPLE(Types.STRING, Types.INT, Types.INT));SingleOutputStreamOperator<String> process = ks1.intervalJoin(ks2).between(Time.seconds(-2), Time.seconds(2)).sideOutputLeftLateData(ks1LateTag) // 将 ks1的迟到数据,放入侧输出流.sideOutputRightLateData(ks2LateTag) // 将 ks2的迟到数据,放入侧输出流.process(new ProcessJoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {/*** 两条流的数据匹配上,才会调用这个方法* @param left ks1的数据* @param right ks2的数据* @param ctx 上下文* @param out 采集器* @throws Exception*/@Overridepublic void processElement(Tuple2<String, Integer> left, Tuple3<String, Integer, Integer> right, Context ctx, Collector<String> out) throws Exception {// 进入这个方法,是关联上的数据out.collect(left + "<------>" + right);}});process.print("主流");
process.getSideOutput(ks1LateTag).printToErr("ks1迟到数据");
process.getSideOutput(ks2LateTag).printToErr("ks2迟到数据");env.execute();
相关文章:
[尚硅谷 flink] 基于时间的合流——双流联结(Join)
文章目录 8.1 窗口联结(Window Join)8.2 **间隔联结(Interval Join)** 8.1 窗口联结(Window Join) Flink为基于一段时间的双流合并专门提供了一个窗口联结算子,可以定义时间窗口,并…...

怎样恢复已删除的照片?教你3个方法,一键恢复!
很多人喜欢以拍照的形式记录生活,手机里的照片就很容易堆积成山,但当内存不够用时就不得不选择删除。可是这些美好的照片始终是很多人心中抹不去的记忆,那么该怎样恢复已删除的照片呢?下面几招,教你一键恢复࿰…...
植物糖基转移酶数据库-23年-地表最强系列-文献精读-6
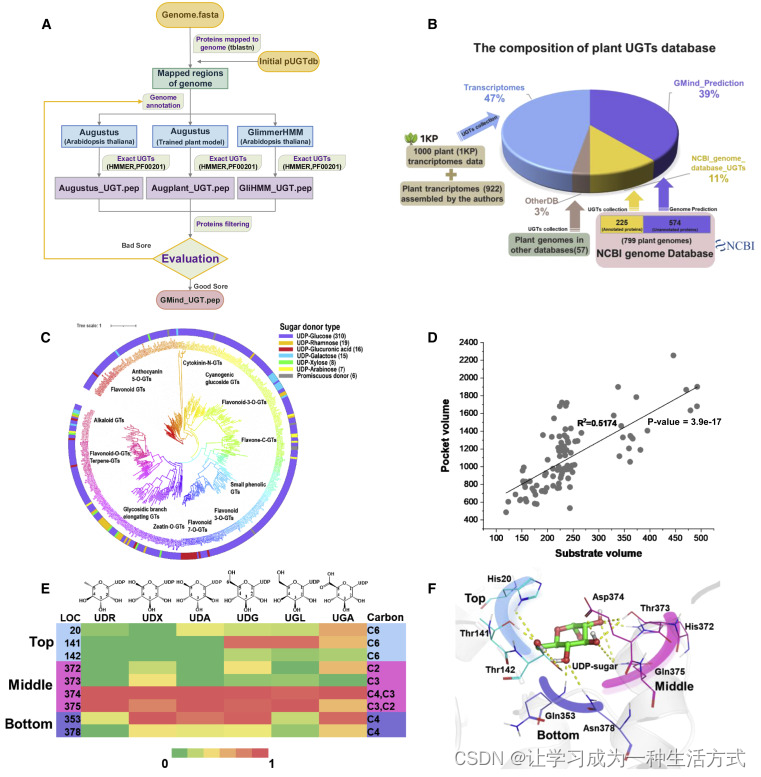
pUGTdb: A comprehensive database of plant UDP-dependent glycosyltransferases pUGTdb:植物UDP依赖糖基转移酶的全面数据库 一篇关于植物糖基转移数据库的综述,地表最强,总结的最全面的版本之一,各位看官有推荐请留言评论区~…...
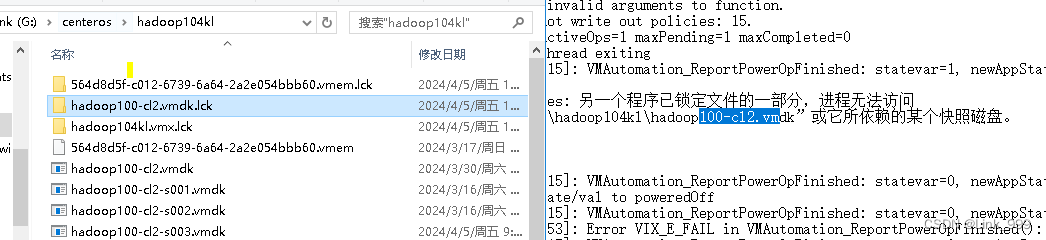
虚拟机打不开
问题 另一个程序已锁定文件的一部分,进程无法访问 打不开磁盘“G:\centeros\hadoop104kl\hadoop100-cl2.vmdk”或它所依赖的某个快照磁盘。 模块“Disk”启动失败。 未能启动虚拟机。 原因 前一次非正常关闭虚拟机导致.lck 文件是VMWare软件的一种磁盘锁文件&…...
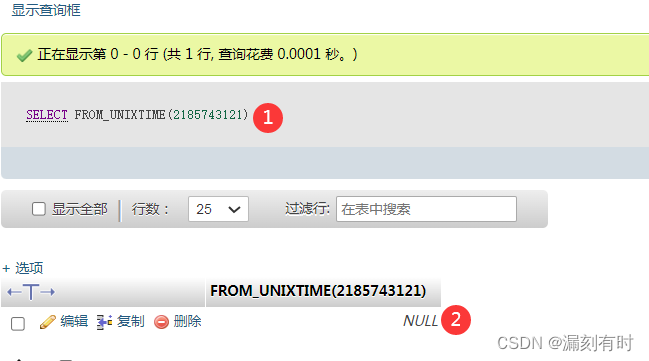
MySQL数据库版本为5.5.62,时间戳超出2038年1月19日的解决方案
MySQL数据库版本是 5.5.62,已设置字段的类型为BIGINT,使用FROM_UNIXTIME()函数来转换时间戳,返回NULL。 SELECT FROM_UNIXTIME(1617970800)SELECT FROM_UNIXTIME(2185743121)MySQL数据库版本为5.5.62,已设置字段的类型为BIGINT&a…...
 详解)
C++20 semaphore(信号量) 详解
头文件在C20中是并发库技术规范(Technical Specification, TS)的一部分。信号量是同步原语,帮助控制多线程程序中对共享资源的访问。头文件提供了标准C方式来使用信号量。 使用环境 Windows:VS中打开项目属性,修改C语…...

【简单讲解下Lisp的学习历程】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...
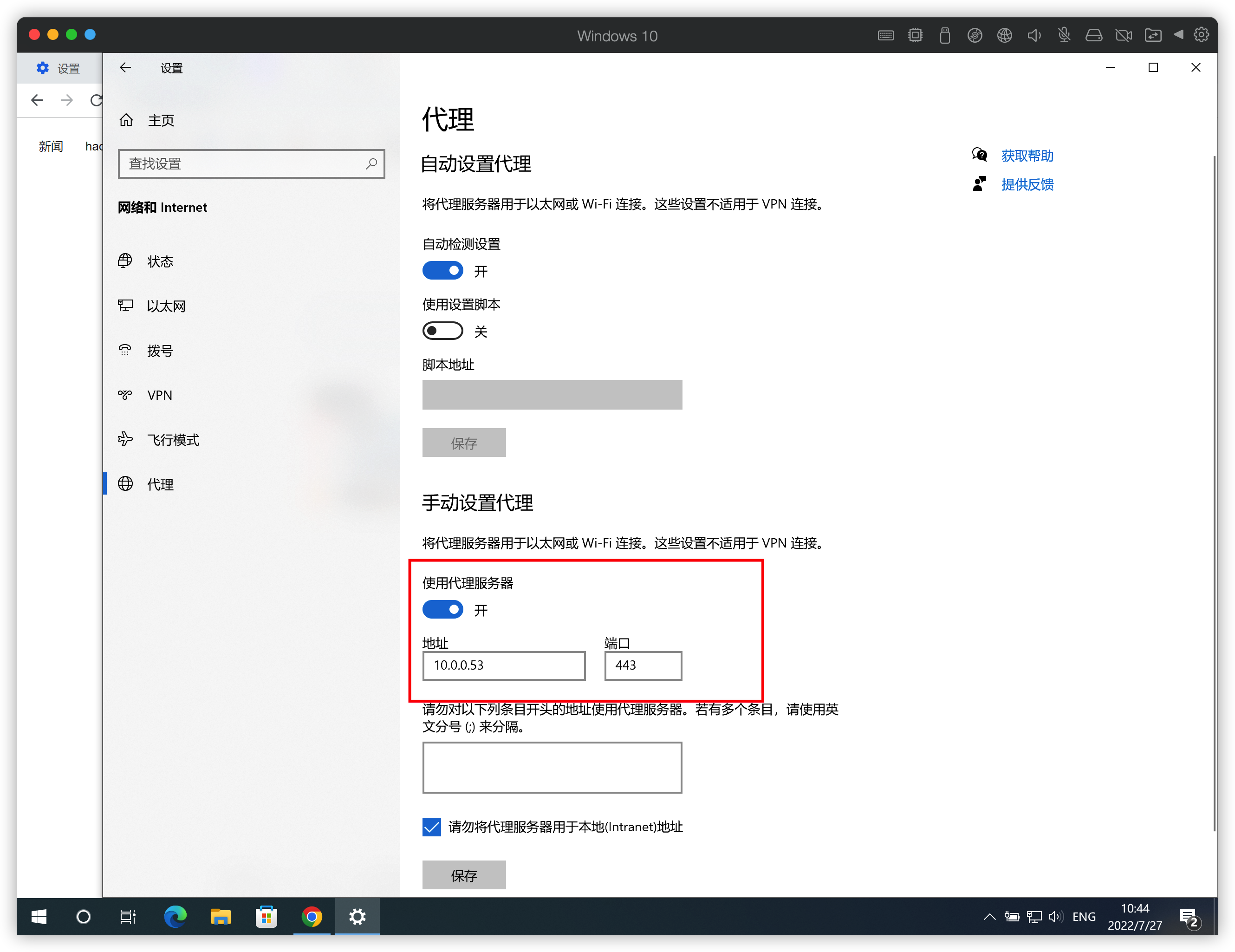
构建高效网络:深入理解正向与反向代理的作用与配置
正向代理 如果把局域网外的互联网环境想象成一个巨大的资源库,则局域网中的客户端要访问互联网则需要通过代理服务器来访问,这种代理成为正向代理。 示例: 用户想要访问 https://chensir.ink (目标服务器)࿰…...
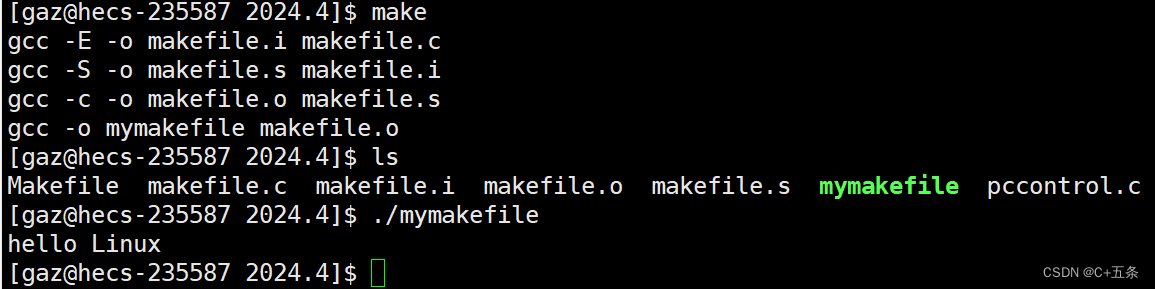
Linux:make/makefile的使用
一、什么是makefile/make 会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的 规则来指定,哪些文件需要先编译&am…...
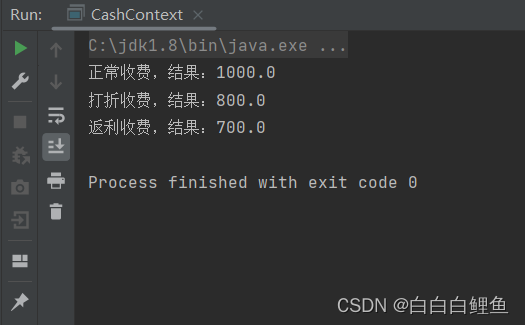
Java设计模式—策略模式(商场打折)
策略这个词应该怎么理解,打个比方说,我们出门的时候会选择不同的出行方式,比如骑自行车、坐公交、坐火车、坐飞机、坐火箭等等,这些出行方式,每一种都是一个策略。 再比如我们去逛商场,商场现在正在搞活动&…...

FOR循环
oracle从入门到总裁:https://blog.csdn.net/weixin_67859959/article/details/135209645 前面两种循环都要根据条件是否成立而确定循环体的执行,具体循环体执行多少次事先并不知道。 FOR 循环可以控制循环执行的次数,由循环变量控制循环体的…...

C++: 命名空间/C++输入输出/缺省参数/函数重载/引用/内联函数
进入C以后,就翻开了新的篇章。C支持C语言的使用。事实上,C是创建者在发现C语言中有很多不好用的地方(在后续学习中会明显看到)后,在C语言基础上又加入了许多语法,于是就成了C。 1.命名空间 来源ÿ…...

Java | Leetcode Java题解之第13题罗马数字转整数
题目: 题解: class Solution {Map<Character, Integer> symbolValues new HashMap<Character, Integer>() {{put(I, 1);put(V, 5);put(X, 10);put(L, 50);put(C, 100);put(D, 500);put(M, 1000);}};public int romanToInt(String s) {int …...

题目:学习使用register定义变量的方法。
题目:学习使用register定义变量的方法。 There is no nutrition in the blog content. After reading it, you will not only suffer from malnutrition, but also impotence. The blog content is all parallel goods. Those who are worried about being cheated …...
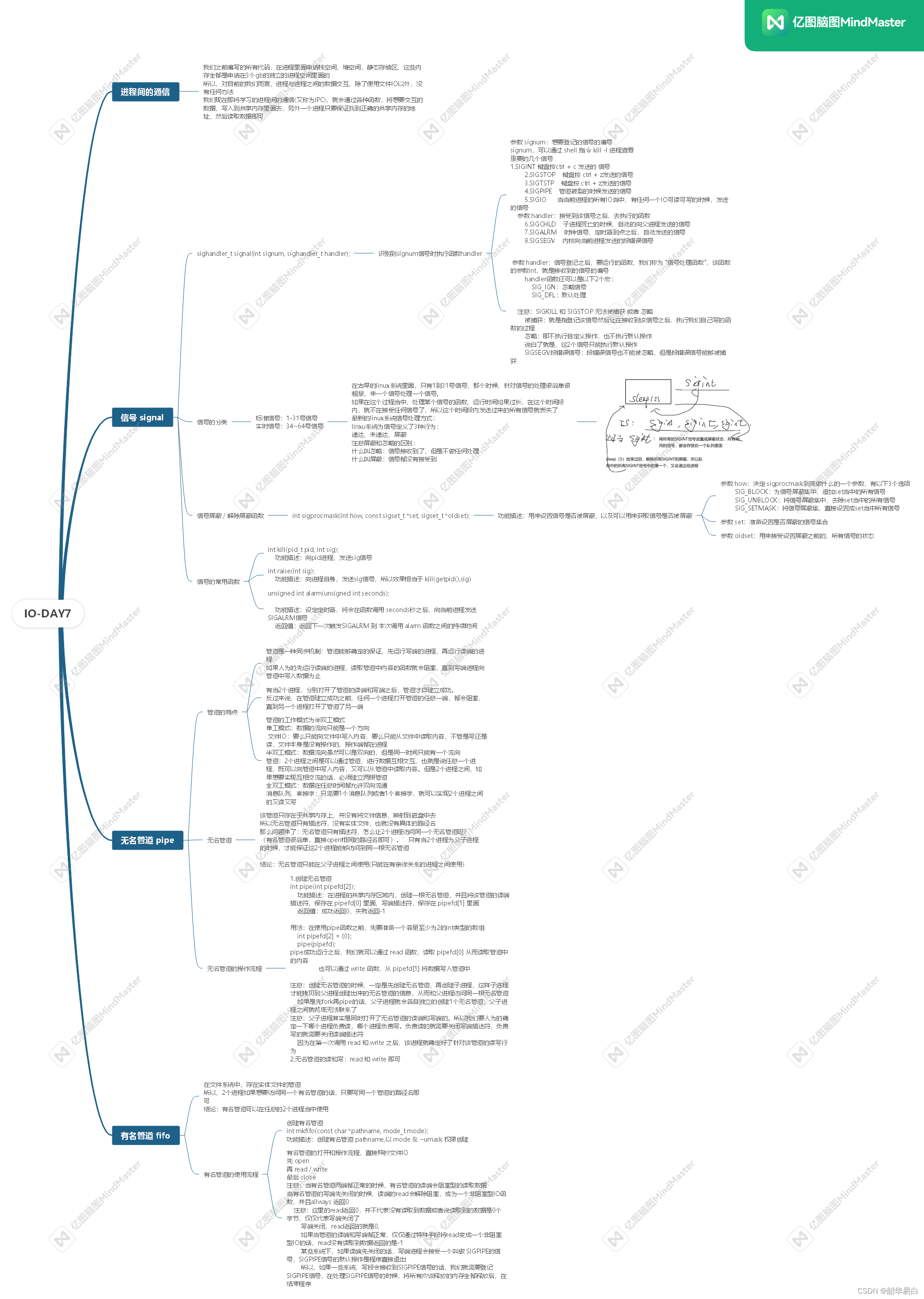
IO_DAY7
1:实现2个终端之间的互相聊天 要求:千万不要做出来2个终端之间的消息发送是读一写的,一定要能够做到,一个终端发送n条消息,另一个终端一条消息都不回复都是没有问题的 终端A: #include<myhead.h> int main(int argc, char…...
大模型学习笔记八:手撕AutoGPT
文章目录 一、功能需求二、演示用例三、核心模块流程图四、代码分析1)Agent类目录创建智能体对象2)开始主流程3)在prompt的main目录输入主prompt和最后prompt4)增加实际的工具集tools(也就是函数)5…...

Java常用API_System——常用方法及代码演示
1.System.exit(int status) 方法的形参int status为状态码,如果是0,说明虚拟机正常停止,如果非0,说明虚拟机非正常停止。需要将程序结束时可以调用这个方法 代码演示: public class Test {public static void main(S…...
neo4j图数据库下载安装配置
neo4j下载地址Index of /doc/neo4j/3.5.8/ 1.说明:jdk 1.8 版本对应的 neo4j 数据库版本 推荐安装3.X版本 2.配置系统环境变量 3.启动 neo4j.bat console 4.访问...

结构化面试-有矛盾的人际沟通题
例题一: 你和小张一起值班,但是小张没来,刚好领导检查发现后批评了他,事后小张埋怨你, 认为你在领导面前表现,并在同事中传播,同事也觉得你不通人情,你怎么处理? 回答&a…...

AI技术创业机会之金融科技
金融科技服务(FinTech)领域正经历着一场由人工智能(AI)技术引领的深刻变革,为创业者提供了无数创新与颠覆传统金融服务模式的机会。以下详述了金融科技服务中AI技术的具体创业机会及其细节与内容,以期为有志于涉足此领域的创业者提供全面的洞察与参考。 一、智能投顾与财…...

Linux动态库版本管理:从链接错误到Soname机制详解
1. 从一次“诡异”的链接错误说起那天在服务器上部署一个自己编译的程序,明明libtest.so就躺在当前目录,执行时却弹出了这个让人摸不着头脑的错误:./a.out: error while loading shared libraries: libtest.so.1: cannot open shared object …...

别再只当脚本小子了:用ArpSpoof搞懂ARP攻击的底层原理与实战防御
从ArpSpoof实战到协议原理:ARP攻击的深度解析与防御实践 在网络安全领域,ARP攻击是最基础却又最容易被忽视的攻击方式之一。许多初学者能够熟练使用Kali Linux中的ArpSpoof工具发起攻击,却对背后的协议机制知之甚少。这种"知其然而不知其…...

PIC16F驱动WS2812:8位MCU实现无限随机动态灯光算法
1. 项目概述与核心思路 几年前,我在捣鼓一个节日南瓜灯项目时,遇到了一个经典难题:手头只有一片资源极其有限的PIC16F1847微控制器,却想驱动一串WS2812(也就是大家常说的NeoPixel)LED,做出那种看…...

自动同步总失败?NotebookLM本地缓存+云端快照双轨备份,手把手配置到上线仅需7分钟
更多请点击: https://intelliparadigm.com 第一章:NotebookLM数据备份方案 NotebookLM 是 Google 推出的基于用户上传文档进行 AI 助理问答的工具,但其本身不提供原生数据导出或持久化存储功能。为防止项目上下文丢失、模型重置或账户异常导…...

抖音批量下载助手:5分钟学会个人主页视频一键批量保存完整指南
抖音批量下载助手:5分钟学会个人主页视频一键批量保存完整指南 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 在当前短视频盛行的时代,抖音作为内容创作的宝库,汇聚了海…...

Polar SI9000实战:从叠层规划到阻抗计算,一次讲清四层板到八层板的阻抗控制核心
Polar SI9000实战:从叠层规划到阻抗计算,一次讲清四层板到八层板的阻抗控制核心 在高速PCB设计中,阻抗控制早已从"锦上添花"变成了"不可或缺"的基础要求。无论是USB3.0的90欧姆差分对,还是DDR4的40欧姆单端走…...

我终于把AI应用拆明白了:Agent、RAG、MCP
本文深入剖析AI应用开发的核心要素,指出仅靠强大的大模型(LLM)不足以构建实用的AI应用。文章详细阐述了Prompt、Skill、RAG、Tool、MCP、Agent等关键模块如何协同工作,使AI能够获取正确资料、调用外部工具、遵循固定流程并稳定交付…...

第7周学习总结:多工具Agent、RAG基础与环境搭建
多工具Agent、RAG基础与环境搭建 本周的学习重点围绕两个方向展开:一是完成了第七周的多工具协同与规划任务,并进入了第八周的流式思考链优化;二是正式启动了RAG(检索增强生成)的系统学习,搭建了知识库和环…...
)
TVA智能体范式的工业视觉革命(3)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

从“早停”到“早退”:深度学习中两种效率优化策略的实战解析
1. 早停机制:训练过程的智能刹车系统 第一次接触早停机制是在处理一个图像分类项目时。当时我的模型在训练集上表现完美,验证集指标却开始下滑——典型的过拟合现象。早停机制就像给训练过程装了个智能刹车,当模型开始"死记硬背"训…...