Pyspark基础入门5_RDD的持久化方法
Pyspark
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下Pyspark基础入门5
#博学谷IT学习技术支持
`
文章目录
- Pyspark
- 前言
- 一、RDD的缓存
- 二、使用步骤
- 1.演示缓存的使用操作
- 三、RDD的checkpoint检查点
- 四、缓存和检查点区别
- 总结
前言
今天和大家分享的是Spark RDD的持久化方法。
一、RDD的缓存
缓存:
一般当一个RDD的计算非常的耗时|昂贵(计算规则比较复杂),或者说这个RDD需要被重复(多方)使用,此时可以将这个RDD计算完的结果缓存起来, 便于后续的使用, 从而提升效率
通过缓存也可以提升RDD的容错能力, 当后续计算失败后, 尽量不让RDD进行回溯所有的依赖链条, 从而减少重新计算时间
注意:
缓存仅仅是一种临时的存储, 缓存数据可以保存到内存(executor内存空间),也可以保存到磁盘中, 甚至支持将缓存数据保存到堆外内存中(executor以外的系统内容)
由于临时存储, 可能会存在数据丢失, 所以缓存操作, 并不会将RDD之间的依赖关系给截断掉(丢失掉),因为当缓存失效后, 可以基于原有依赖关系重新计算
缓存的API都是LAZY的, 如果需要触发缓存操作, 必须后续跟上一个action算子, 一般建议使用count如果不添加action算子, 只有当后续遇到第一个action算子后, 才会触发缓存
二、使用步骤
设置缓存的API:
rdd.cache(): 执行缓存操作 仅能将数据缓存到内存中
rdd.persist(缓存的级别(位置)): 执行缓存操作, 默认将数据缓存到内存中, 当然也可以自定义缓存位置
手动清理缓存的API:
rdd.unpersist()
默认情况下, 当整个Spark应用程序执行完成后, 缓存也会自动失效的, 自动删除
常用的缓存级别:
MEMORY_ONLY : 仅缓存到内存中
DISK_ONLY: 仅缓存到磁盘
MEMORY_AND_DISK: 内存 + 磁盘 优先缓存到内存中, 当内存不足的时候, 剩余数据缓存到磁盘中
OFF_HEAP: 缓存到堆外内存
最为常用的: MEMORY_AND_DISK
1.演示缓存的使用操作
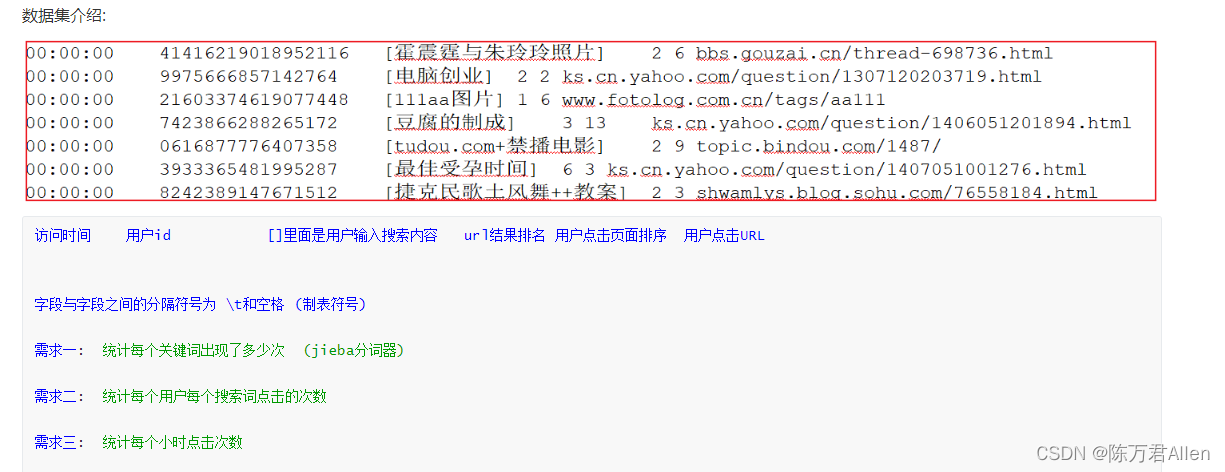
import timeimport jieba
from pyspark import SparkContext, SparkConf, StorageLevel
import os# 锁定远端环境, 确保环境统一
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
"""清洗需求: 需要先对数据进行清洗转换处理操作, 清洗掉为空的数据, 以及数据字段个数不足6个的数据, 并且将每一行的数据放置到一个元组中, 元组中每一个元素就是一个字段的数据
"""def xuqiu1():# 需求一: 统计每个关键词出现了多少次, 获取前10个res = rdd_map \.flatMap(lambda field_tuple: jieba.cut(field_tuple[2])) \.map(lambda keyWord: (keyWord, 1)) \.reduceByKey(lambda agg, curr: agg + curr) \.sortBy(lambda res_tup: res_tup[1], ascending=False).take(10)print(res)def xuqiu2():res = rdd_map \.map(lambda field_tuple: ((field_tuple[1], field_tuple[2]), 1)) \.reduceByKey(lambda agg, curr: agg + curr) \.top(10, lambda res_tup: res_tup[1])print(res)if __name__ == '__main__':print("Spark的Python模板")# 1. 创建SparkContext核心对象conf = SparkConf().setAppName('sougou').setMaster('local[*]')sc = SparkContext(conf=conf)# 2. 读取外部文件数据rdd = sc.textFile(name='file:///export/data/workspace/ky06_pyspark/_02_SparkCore/data/SogouQ.sample')# 3. 执行相关的操作:# 3.1 执行清洗操作rdd_filter = rdd.filter(lambda line: line.strip() != '' and len(line.split()) == 6)rdd_map = rdd_filter.map(lambda line: (line.split()[0],line.split()[1],line.split()[2][1:-1],line.split()[3],line.split()[4],line.split()[5]))# 由于 rdd_map 被多方使用了, 此时可以将其设置为缓存rdd_map.persist(storageLevel=StorageLevel.MEMORY_AND_DISK).count()# 3.2 : 实现需求# 需求一: 统计每个关键词出现了多少次, 获取前10个# 快速抽取函数: ctrl + alt + Mxuqiu1()# 当需求1执行完成, 让缓存失效rdd_map.unpersist().count()# 需求二:统计每个用户每个搜索词点击的次数xuqiu2()time.sleep(100)
三、RDD的checkpoint检查点
checkpoint比较类似于缓存操作, 只不过缓存是将数据保存到内存 或者 磁盘上, 而checkpoint是将数据保存到磁盘或者HDFS(主要)上
checkpoint提供了更加安全可靠的持久化的方案, 确保RDD的数据不会发生丢失, 一旦构建checkpoint操作后, 会将RDD之间的依赖关系(血缘关系)进行截断,后续计算出来了问题, 可以直接从检查点的位置恢复数据主要作用: 容错 也可以在一定程度上提升效率(性能) (不如缓存)在后续计算失败后, 从检查点直接恢复数据, 不需要重新计算
相关的API:
第一步: 设置检查点保存数据位置
sc.setCheckpointDir(‘路径地址’)
第二步: 在对应RDD开启检查点rdd.checkpoint()rdd.count()注意: 如果运行在集群模式中, checkpoint的保存的路径地址必须是HDFS, 如果是local模式 可以支持在本地路径checkpoint数据不会自动删除, 必须同时手动方式将其删除掉
import timefrom pyspark import SparkContext, SparkConf
import os# 锁定远端环境, 确保环境统一
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("演示checkpoint相关的操作")# 1- 创建SparkContext对象conf = SparkConf().setAppName('sougou').setMaster('local[*]')sc = SparkContext(conf=conf)# 开启检查点, 设置检查点的路径sc.setCheckpointDir('/spark/chk') # 默认的地址为HDFS# 2- 获取数据集rdd = sc.parallelize(['张三 李四 王五 赵六', '田七 周八 李九 老张 老王 老李'])# 3- 执行相关的操作: 以下操作仅仅是为了让依赖链条更长, 并没有太多的实际意义rdd1 = rdd.flatMap(lambda line: line.split())rdd2 = rdd1.map(lambda name: (name, 1))rdd3 = rdd2.map(lambda name_tuple: (f'{name_tuple[0]}_itcast', name_tuple[1]))rdd3 = rdd3.repartition(3)rdd4 = rdd3.map(lambda name_tuple: name_tuple[0])# RDD4设置检查点:rdd4.checkpoint()rdd4.count()rdd5 = rdd4.flatMap(lambda name: name.split('_'))rdd5 = rdd5.repartition(4)rdd6 = rdd5.map(lambda name: (name, 1))rdd_res = rdd6.reduceByKey(lambda agg, curr: agg + curr)print(rdd_res.collect())time.sleep(1000)
四、缓存和检查点区别
1- 存储位置不同:
缓存: 存储在内存或者磁盘 或者 堆外内存中
检查点: 可以将数据存储在磁盘 或者 HDFS上, 在集群模式下, 仅能保存到HDFS上
2- 血缘关系:
缓存: 不会截断RDD之间的血缘关系, 因为缓存数据有可能会失效, 当失效后, 需要重新回溯计算操作
检查点: 会截断RDD的之间的血缘关系, 因为检查点将数据保存到更加安全可靠的位置, 认为数据不会发生丢失问题, 当执行失败的时候, 也不需要重新回溯计算
3- 生命周期:
缓存: 当程序执行完成后, 或者手动调度unpersist 缓存都会被删除
检查点: 即使程序退出后, 检查点的数据依然是存在的, 不会删除, 需要手动删除的
一般建议将两种持久化的方案一同作用于项目环境中, 先设置缓存 然后再设置检查点, 最后统一触发执行(底层: 会将数据先缓存好, 然后将缓存好的数据, 保存到checkpoint对应的路径中, 后续在使用的时候, 优先从缓存中读取, 如果缓存中没有, 会从checkpoint中获取, 同时再把读取数据放置到缓存中)
总结
今天和大家分享了RDD的两种持久化方法。
相关文章:
Pyspark基础入门5_RDD的持久化方法
Pyspark 注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hi…...

汽车娱乐系统解决方案
Danlaw在汽车和航空航天行业里是全球知名的技术和服务供应商,致力于提供更加安全与智能的系统。Danlaw以突破性技术和高效开发、动态环境的自适应解决方案而闻名。Danlaw优秀的联网汽车解决方案使之成为全球大型互联设备供应商之一。 一 信息娱乐系统测试 | 风丘科…...

Go语言结构体,这一篇就够了
Go语言结构体,这一篇就够了1.结构体的概念2.结构体的定义3.结构体的实例化4.结构体初始化5.构造函数6.方法和接收者方法接收者7.嵌套结构体8.结构体的“继承”9.结构体与JSON序列化10.结构体标签(Tag)Go语言中没有“类”的概念,也…...

【python】各种排序算法代码大集合
超级好用的口诀: 时间复杂度:快些以nlogn的速度归队。 稳定性:心情不稳定,快些选一堆好友来聊天吧。 直接插容易插变O(N),起泡起得好变O(N).(初始序列已经有序) 插入排序法在近乎有序的情况下,效率特别高,通过插入排序,可以引申出希尔排序 归并排序:左半部分排好序…...
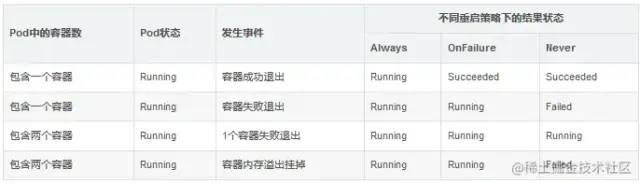
K8S Pod健康检查
因为 k8s 中采用大量的异步机制、以及多种对象关系设计上的解耦,当应用实例数 增加/删除、或者应用版本发生变化触发滚动升级时,系统并不能保证应用相关的 service、ingress 配置总是及时能完成刷新。在一些情况下,往往只是新的 Pod 完成自身…...
NFS服务器与CGI程序详解
目录 NFS 服务器 一,NFS 服务器简介 二,NFS的使用 三,客户端使用 autofs 自动挂载 1,autofs产生的原因 四,autofs的安装与配置文件 五,autofs的使用 www服务器---cgi程序 CGI程序的应用 NFS 服务器 一&a…...

可视化项目管理,控制项目进度,项目经理需要做好以下工作
对于项目的管理者来说,项目信息透明,能够更容易让管理者发现项目中的问题,及时找到问题的原因和相关任务的责任人。 当项目信息能相对精准地呈现给管理者时,也能促进项目成员也能更加认真负责的完成任务,不会找借口推…...
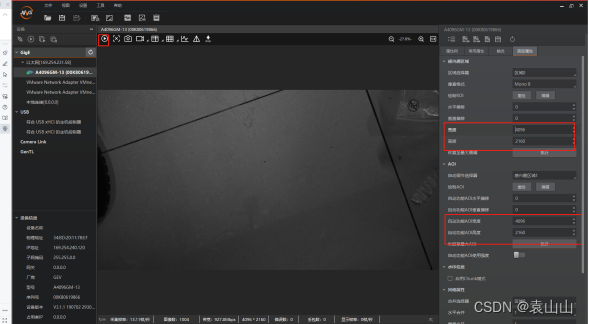
海康工业相机使用教程
工业相机使用一、硬件连接1、准备材料2、相机供电(1)区分电源适配器正负极(2)连接相机电源线缆(3)连接完成后,相机蓝色灯常亮则成功3、软件连接(1)MVS客户端下载地址&…...

java开发手册之安全规约
安全规约隶属于用户个人的页面或者功能必须进行权限控制校验。 说明:防止没有做水平权限校验就可随意访问、修改、删除别人的数据,比如查看他人的私信内容、修改他人的订单。 用户敏感数据禁止直接展示,必须对展示数据进行脱敏。 说明&#x…...

python模块引入问题和解决方案_真方案不骗人
1.pycharm运行python脚本的过程 使用pycharm等编辑器run/debug运行python脚本时,编辑器会通过本地python命令全路径执行脚本,例如 D:\DevelopTools\Python\python.exe D:/Codes/一长串路径/bbss_nature_python/demo/test_no_param_in.py 并且会在pyth…...
--Unit Testing)
Read book Netty in action(Chapter X)--Unit Testing
序言 ChannelHandler 是Netty 应用程序的关键元素,所以彻底地测试它们应该是你的开发过程的一个标准部分。最佳实践要求你的测试不仅要能够证明你的实现是正确的,而且还要能够很容易地隔离那些因修改代码而突然出现的问题。这种类型的测试叫作单元测试。…...
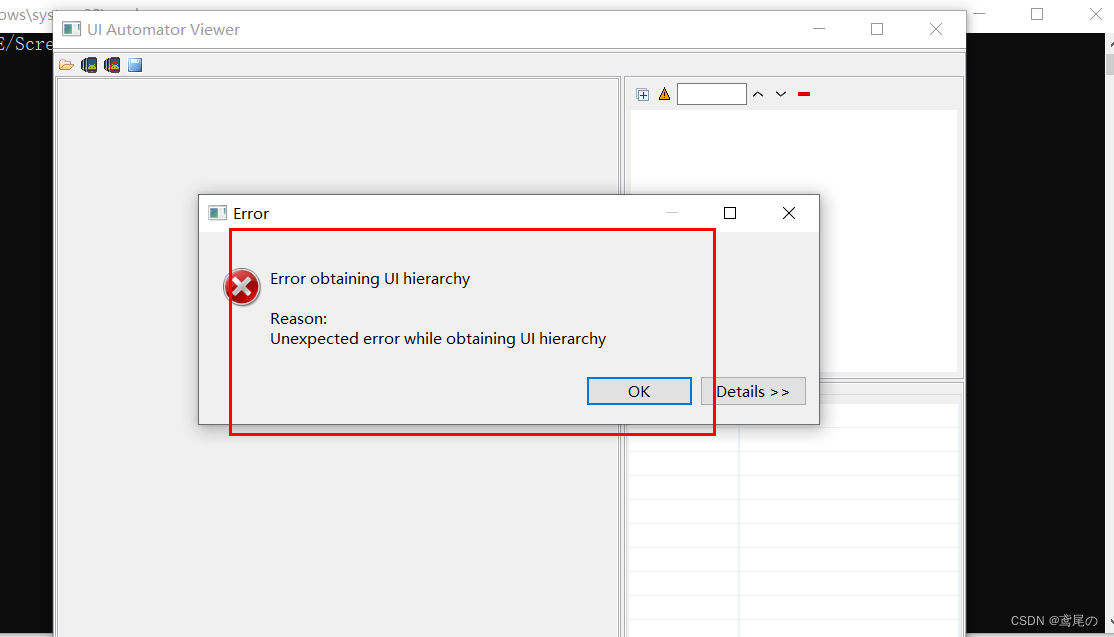
Appium+Python连接真机、跳过登录页、Unexpected error while obtaining UI hierarchy问题
Appium连接真机 使用数据线连接电脑,然后选择文件传输方式 打开手机设置拉至底部,点击关于手机,连续点击7次版本号打开开发者模式 点击设置中的系统与更新,找到开发者选项----> 打开USB调试即可 在终端中输入adb devices确定…...

ES6模块化
目录 一、什么是 ES6 模块化规范 二、ES6 模块化的基本语法 2.1默认导出 2.1默认导入 2.1 注意事项 2.2按需导出 2.2按需导入 2.2按需导出与按需导入的注意事项 2.3直接导入并执行模块中的代码 一、什么是 ES6 模块化规范 ES6 模块化规范是浏览器端与服务器端通用的…...

201809-3 CCF 元素选择器 满分题解(超详细注释代码) + 解题思路(超详细)
问题描述 解题思路 根据题意可以知道在查询中可以分为两种情况 第一种是查询一个标签选择器或者id选择器(可以称为一级查询) 第二种就是存在大于两级的查询(可以称为多级查询) 显然第一种查询需要存储每一种元素在内容中所有出现…...
)
证书拓展域(1)
证书拓展定义了数字证书的标准拓展,每个拓展域GB/T 16264.8-200X中定义的一个OID相关。 这些OID都是id-ce的成员,其定义如下: id-ce OBJECT IDENTIFIER :: { joint-iso-ccitt(2) ds(5) 29 }1.证书策略 certificatePolicies 1.1 定义 本…...
浅谈ChatGPT 和 对AI 的思考
新世纪以来,人工智能作为一个非常热门话题,一直收到大众的广泛的关注。从一开始的图像的分类,检测,到人脸的识别,到视频分析分类,到事件的监测,到基于图片的文本生成,到AI自动写小说…...

NCRE计算机等级考试Python真题(十二)
第十二套试题1、以下关于程序设计语言的描述,错误的选项是:A.Python语言是一种脚本编程语言B.汇编语言是直接操作计算机硬件的编程语言C.程序设计语言经历了机器语言、汇编语言、脚本语言三个阶段D.编译和解释的区别是一次性翻译程序还是每次执行时都要翻…...

Java并发类库提供的线程池有哪几种? 分别有什么特点?
第21讲 | Java并发类库提供的线程池有哪几种? 分别有什么特点? 我在专栏第 17 讲中介绍过线程是不能够重复启动的,创建或销毁线程存在一定的开销,所以利用线程池技术来提高系统资源利用效率,并简化线程管理,…...
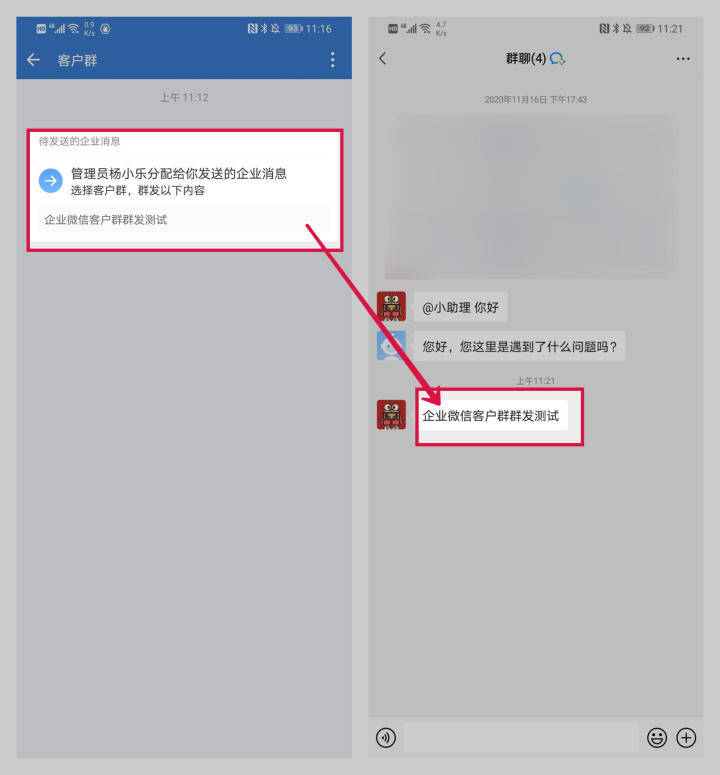
企业微信如何群发消息到客户群?
为提升工作效率,工作中,企业常常会借助企业微信的群发功能一键发送多个客户。那么企业微信如何群发消息呢? 其中成员个人支持群发消息到客户群,企业也可以创建内容提醒成员进行执行群发。 管理员支持在管理端或在手机端创建企业…...
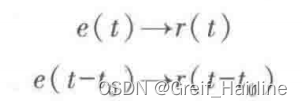
【信号与系统笔记】第一章 绪论
1.1信号传输系统 信息传输的任务 将带有信息的信号,通过某种系统由发送者传送给接收者。 通信系统的组成 转换器:把消息转换为电信号或者把电信号还原成消息信道:信号传输的通道,广义上来说。发射机和接收机也可以是信道的一部分…...

SmartNIC如何优化AI流水线与网络计算卸载
1. SmartNIC与AI流水线的联姻:网络计算卸载的技术革命 在分布式AI推理场景中,我们常常遇到一个令人头疼的现象:当GPU计算单元满载运行时,CPU利用率也常常飙升至90%以上。这种资源争用并非来自模型推理本身,而是源于那些…...

告别网盘限速困扰:网盘直链下载助手全面解析与应用指南
告别网盘限速困扰:网盘直链下载助手全面解析与应用指南 【免费下载链接】baiduyun 油猴脚本 - 一个免费开源的网盘下载助手 项目地址: https://gitcode.com/gh_mirrors/ba/baiduyun 还在为网盘下载速度缓慢而烦恼吗?网盘直链下载助手作为一款免费…...

MTKClient实战指南:联发科设备刷机与逆向工程全面解决方案
MTKClient实战指南:联发科设备刷机与逆向工程全面解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient是一款专为联发科芯片设备设计的开源逆向工程与刷机工具&am…...

Cerebro:为AI构建持久记忆与认知能力的本地化MCP工具系统
1. 项目概述:为AI赋予持久记忆与认知能力如果你和我一样,每天都在和Claude、ChatGPT这类大语言模型打交道,那你一定遇到过这个让人头疼的问题:每次开启一个新的对话会话,AI就像得了“健忘症”,之前聊过的项…...
研究(Matlab代码实现))
【CPO三维路径规划】豪猪算法CPO多无人机协同集群避障路径规划(目标函数:最低成本:路径、高度、威胁、转角)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

云雾栖茶山,在云顶山读懂一片茶叶的蜕变旅程
位于福建省安溪县西坪镇的云顶山茶园,是一处融合了茶叶种植与传统制茶工艺的生态旅游区。该区域海拔约800米,常年云雾缭绕,土壤富含矿物质,为茶树生长提供了适宜的自然条件。景区以乌龙茶种植为核心,围绕“从叶片到茶杯…...

taotoken模型广场功能体验与主流模型选型建议
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken模型广场功能体验与主流模型选型建议 1. 平台入口与模型广场概览 登录Taotoken控制台后,最直观的功能入口之一…...

通过curl命令快速测试Taotoken提供的各类大模型API响应效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken提供的各类大模型API响应效果 对于习惯命令行操作或需要在无SDK环境中验证集成的开发者而言…...

一图定胜负|虎贲等考 AI 科研绘图:零代码画出期刊级学术图,让论文颜值与专业度双在线
据 Nature 统计,超 90% 的审稿人先看图表,65% 的初审意见直接来自图表质量,一张规范、清晰、专业的学术图,直接影响论文录用与答辩评分。可现实是:Origin、Visio 难学难精通,PPT 做图粗糙不规范,…...

嵌入式系统开发实战:从架构设计到量产部署的工程指南
1. 从一场顶级技术盛会看嵌入式开发的演进与实战十多年前,也就是2010年的6月,芝加哥嵌入式系统大会(ESC Chicago)的第一天,被当时的媒体形容为“全明星阵容”的聚会。Dan Saks、Christian Legare、Bill Gatliff、David…...