人工智能——深度学习
4. 深度学习
4.1. 概念
深度学习是一种机器学习的分支,旨在通过构建和训练多层神经网络模型来实现数据的高级特征表达和复杂模式识别。与传统机器学习算法相比,深度学习具有以下特点:
- 多层表示学习:深度学习使用深层神经网络,允许多个层次的特征表达和抽象,从而能够自动发现和提取输入数据中的重要特征。
- 端到端学习:通过将输入直接映射到输出,深度学习可以实现端到端的学习,无需手工设计特征提取器或预处理步骤。
- 大规模并行计算:深度学习模型通常需要进行大量的矩阵运算,在现代硬件(如GPU)上可以进行高效的并行计算,加快了训练和推断的速度。
- 梯度下降优化:深度学习模型通常使用梯度下降等优化算法来最小化损失函数,并通过反向传播算法有效地更新网络参数。
- 泛化能力强:深度学习模型具有很强的泛化能力,能够在未见过的数据上进行准确的预测和分类。
深度学习在各个领域都取得了重大突破,包括计算机视觉、自然语言处理、语音识别等。它已经应用于图像分类、目标检测、机器翻译、智能助手等众多任务中,并在许多比赛和实际应用中取得优秀的结果。
神经网络功能强大,并且深度学习则是优化了数据分析,建模过程,因此基于神经网络的深度学习可以统一原来的传统机器学习。AlphaGo是深度学习战胜了世界围棋第一人李世石。2016年Google翻译基于深度学习更新,翻译能力得到大幅提升。最新的Google翻译是基于大语言模型。
4.2. 神经网络
4.2.1. 定义
4.2.1.1. 概念
深度学习是一种基于人工神经网络的机器学习方法,其核心思想是通过多层次的神经网络来模拟人脑的神经元之间的连接。深度学习的特点是可以通过大规模的数据来训练模型,并且可以自动学习到数据的特征表示。
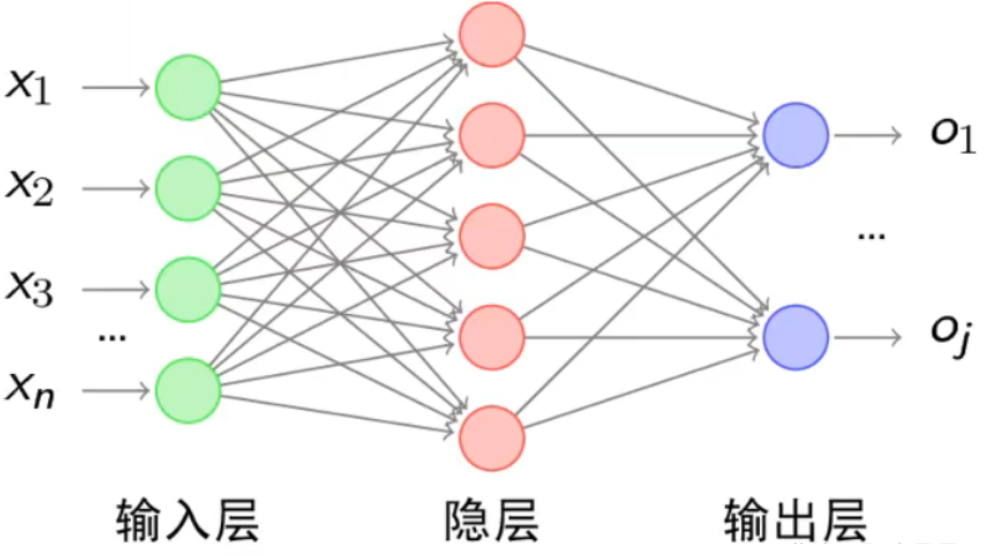
上图就是一个神经网络的基本结构图,X1到Xn是输入,O1到Oj是输出,圆圈是神经元(也称感知机),连线带权重参与计算生成下一个神经元。隐层在实际的神经网络中可能会多层,并且都是全连接,所以计算量巨大,所以需要AI CPU、AI GPT等。
4.2.1.2. 感知机
如下图是一个神经元,其有3个输入数据x附加不同的权重w,另外有一个偏置(可以理解为线性函数中的截距)。
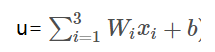
h = f(u + b)
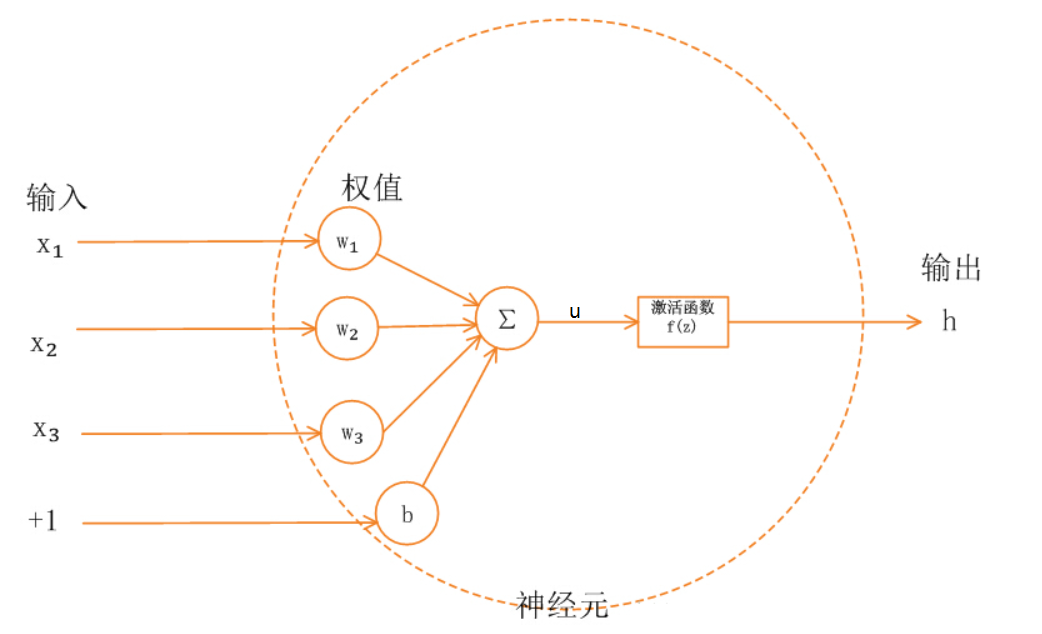
我们先假设没有激活函数,来看下神经元的效果。
- 如下图,单层单个元神经元可以用来作为分类。
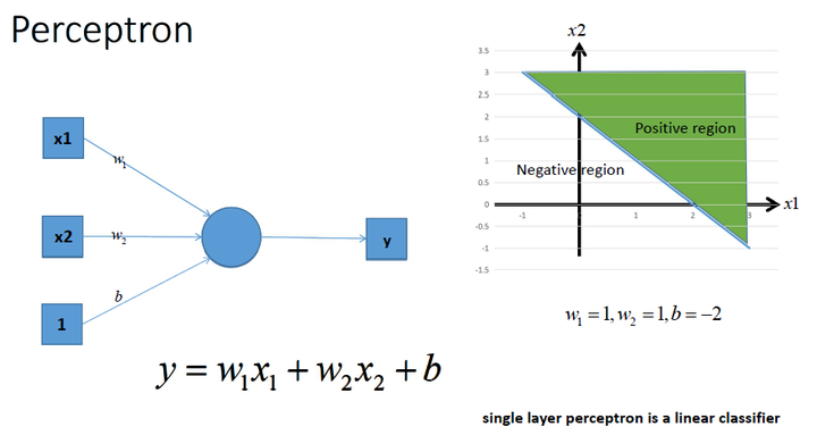
- 如下图,单层多个神经元可以完全更精细的线性分类分类
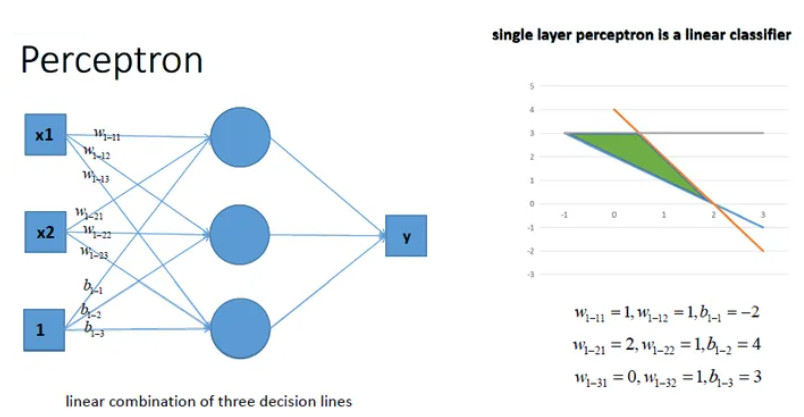
通过上面的示例可以看出,在没有激活函数的情况下,无论在多少个神经元作用下,其都是使用累加计算的,总是一阶的,总是线性的。线性函数只能处理一些简单的场景,复杂场景多是需要用曲线或曲面来区分的。如下图,用线段无法区分大小写字母。
我们就需要在神经元加一个函数来加强其能力,这就是激活函数的作用,它让神经元具备非线性表达能力。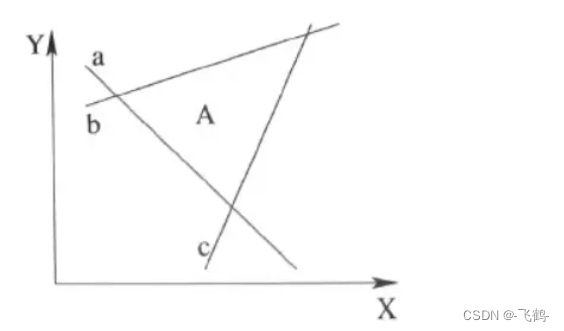
我们让激活函数为Sigmoid函数,那么直线与Sigmoid函数相乘,就变成了曲线。
那么在3个神经元在3个激活函数的作用下,就可以形成3条曲线。
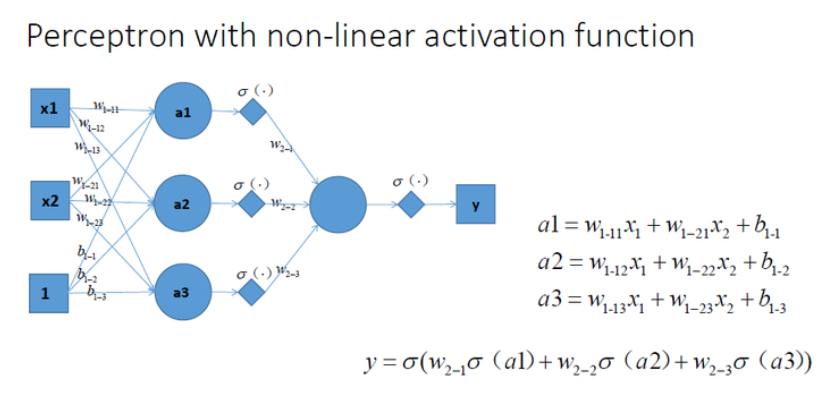
3条曲线在不同的权重作用下,可以拟合为一条新的形状,可以达到区分大小写字母的能力。
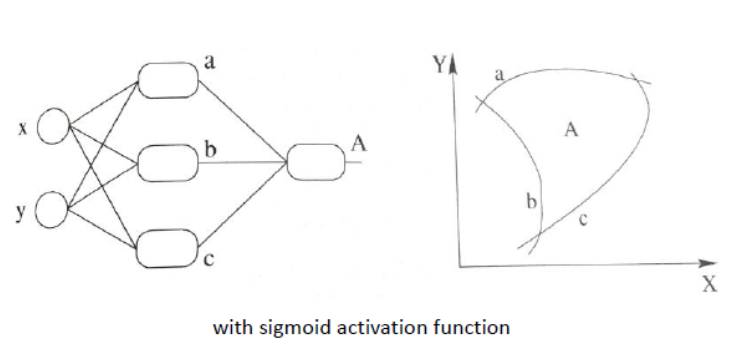
理论上来说,只要神经元足够多,无论多么复杂的分类都可以实现。
激活函数
激活函数可以选择不同的函数,Sigmoid是以前比较受欢迎的激活函数,但是其存在一些问题。当权重很小时,Sigmoid函数的作用也很小,容易导致梯度消失(简单讲是指区别度不大,导致学习的效率不佳)。ReLU系列的激活函数包括ReLU、Leaky ReLU、PReLU、ELU。
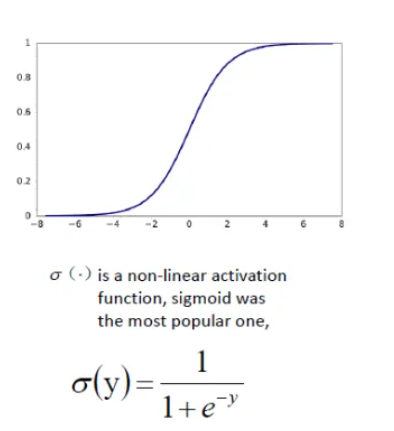
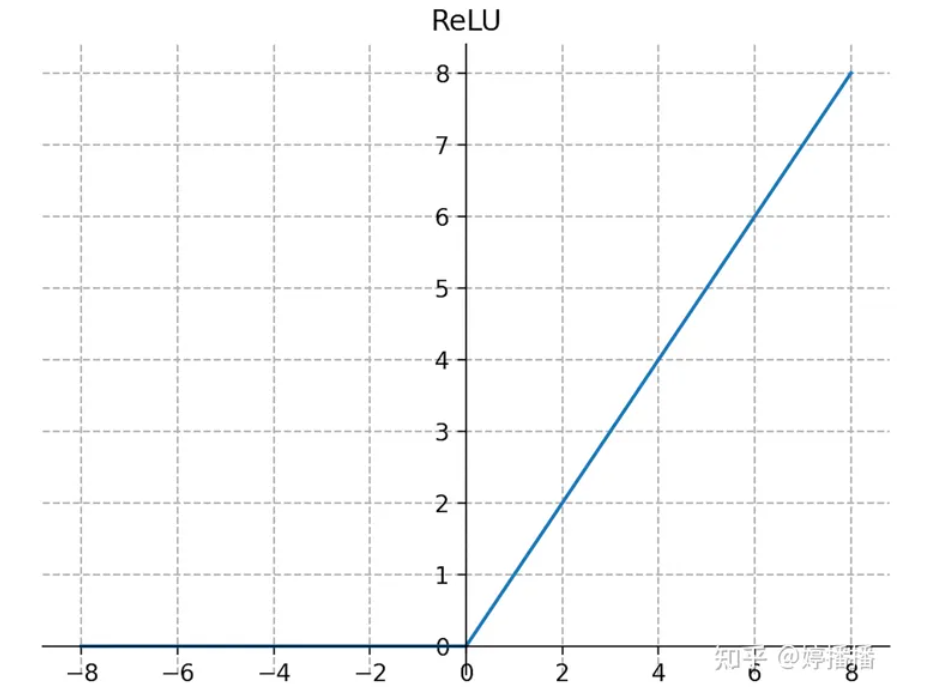

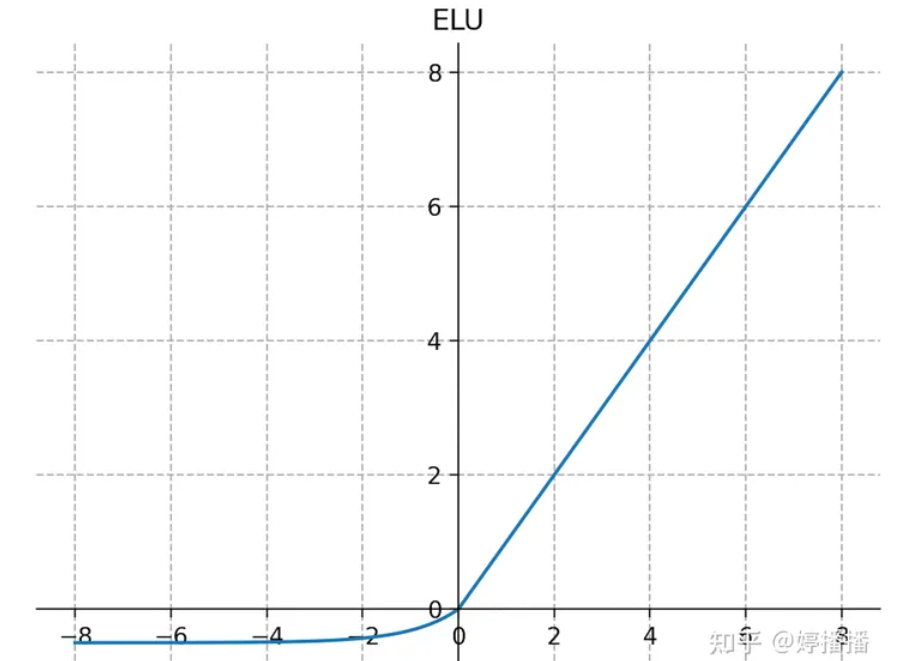
不同的激活函数有不同的应用场景,不同的计算量,需要根据经验进行选择调整。
softmax回归
为了结果更清晰,好对比,我们可能需要将结果进行归一化处理(归一化也被称为单位化,即所有结果之和为1)。

经过softmax回归计算之后,输出的结果可能是这样的:
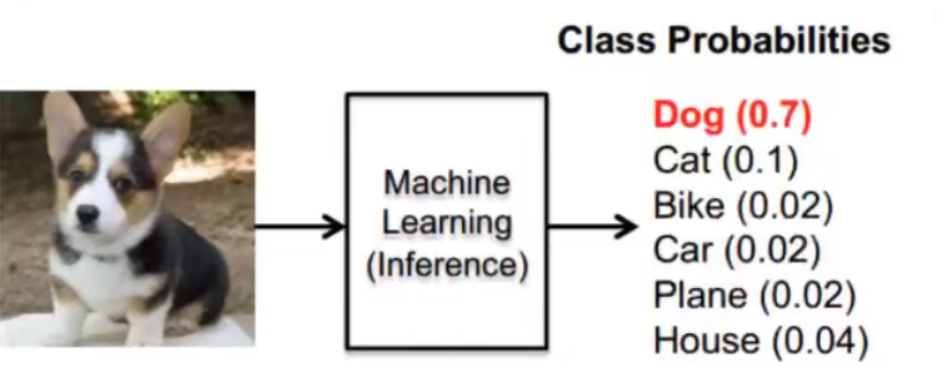
4.2.2. 损失函数
如何评估神经网络的效果,我们就需要用到损失函数。损失函数(Loss Function)用来估量模型的预测值 f(x) 与真实值 y 的偏离程度。因为误差有正有负,所以可以采用平均绝对误差,均方误差(平均平方误差, Mean Squared Error ,MSE),这些多用于回归问题。用于二分类问题(是/否,对与错),多用交叉熵损失函数(CrossEntropy Loss)。多分类问题,可以用softmax函数,如上图的动物分类。
交叉熵损失函数(CrossEntropy Loss)
熵是用来描述物体混乱程度的概念,越混乱熵越大,也可以理解为数据越随机熵就越大。信息熵越大,事物越具不确定性,事物越复杂。
信息熵公式:

交叉熵主要用于度量两个概率分布之间的差异性。交叉熵越小,表示模型输出分布越接近真实值分布。
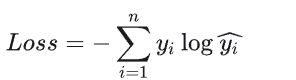
在机器学习框架中,交叉熵都有直接提供接口,我们只需要知道交叉熵的概念及其应用场景,知道使用即可。
4.2.3. 计算
4.2.3.1. 前向传播
有如下一个神经网络,3个输入,2个输出,单层神经网络有4个神经元。
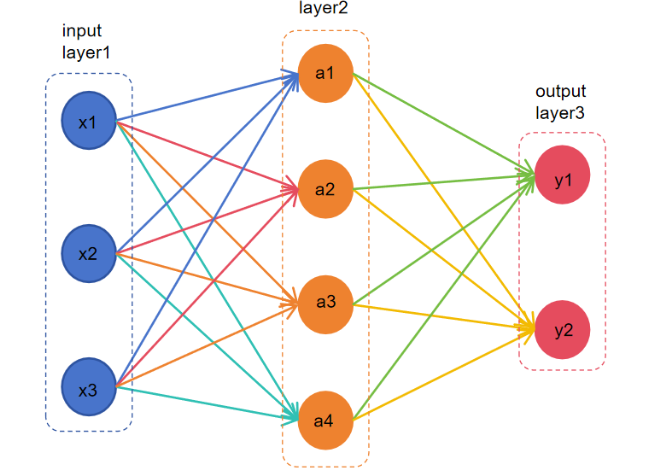
转换为数学形式:
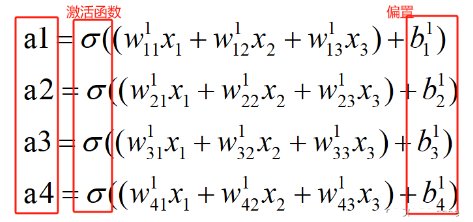
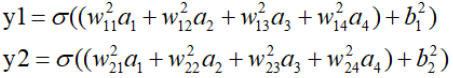
一步步从前往后进行计算,这就是前向传播计算。x1、x2、x3总是一起参与计算,其总的输出可以用一个矩阵[x1, x2, x3]表示,所以在神经网络的计算是,需要大量的矩阵计算。所以现在有很专用用于神经网络计算的神经网络处理器(Neural network Processing Unit, NPU)。
前向传播主要用于预测结果。
4.2.3.2. 反向传播
在神经网络学习的过程中,我们通过误差函数来求一个最小误差时的权重和截距(神经网络中叫偏置)。我们可以使用最小二乘法,也可以使用梯度下降法。使用最小二乘法效果好,但是计算量非常大,尤其是在大型神经网络中,如果使用最小二乘法计算量巨大,所以一般使用梯度下降法,梯度下降使用学习率(权重的步进值)这个超参数来控制下降的速度,来提升计算速度。
梯度下降是通过误差函数反向往前推的,所以也被称为反向传播。反向传播主要用于学习(训练)。
4.2.2. 分类
深度学习的主要方法包括卷积神经网络(CNN)、循环神经网络(RNN)和生成对抗网络(GAN)等。
1. 卷积神经网络:
卷积神经网络是一种专门用于处理具有网格结构的数据(如图像和语音)的神经网络。卷积神经网络通过卷积层、池化层和全连接层等组件来提取图像的特征表示,从而实现图像分类、目标检测和图像生成等任务。
2. 循环神经网络:
循环神经网络是一种可以处理序列数据(如语言和时间序列)的神经网络。循环神经网络通过循环连接来处理序列数据的时序信息,并且可以自动学习到序列数据的上下文信息。循环神经网络在自然语言处理、语音识别和机器翻译等领域有广泛应用。
传统的循环神经网络是全连接的,并不关注数据的前后顺序(如语言的前后顺序或时间序列等)。RNN中每个神经元的输出,不仅仅有上一层神经元的输出,还可能把数据序列前处理神经元的输出作为输入。
因为CNN增加了输入,计算量增加了。为了优化RNN,引入了LSTM(长短期记忆网络),减少计算量,并优化了前后依赖关系。
3. 生成对抗网络:
生成对抗网络是一种由生成器和判别器组成的对抗性模型。生成器通过学习训练数据的分布,生成与训练数据相似的新样本;判别器则通过学习区分真实样本和生成样本。生成对抗网络在图像生成、图像修复和文本生成等任务中取得了重要的突破。
4.3. 学习过程
4.3.1. 步骤
- 数据准备:收集和预处理数据,使其适合神经网络训练。这可能包括清理数据、删除异常值和对数据进行编码。
- 网络架构:设计神经网络的架构,包括层数、神经元数和连接方式。
- 初始化权重和偏差:为网络中的权重和偏差分配初始值。
- 前向传播:将输入数据通过网络,计算每个神经元的输出。
- 计算损失:将网络输出与预期输出进行比较,计算损失函数的值。
- 反向传播:使用链式法则计算损失函数相对于网络权重和偏差的梯度。
- 权重更新:使用梯度下降或其他优化算法更新网络权重和偏差,以减少损失。
- 重复步骤 4-7:重复前向传播、计算损失和反向传播的步骤,直到损失函数达到最小值或达到预定义的训练迭代次数。
4.3.2. 超参数
超参数(Hyperparameter)是机器学习模型中需要人为设定的参数,它们不是通过训练数据自动学习得到的,而是需要人工指定的参数。训练深度神经网络涉及调整以下超参数:
- 学习率:控制权重更新的步长。
- 批大小:每次前向和反向传播处理的数据样本数。
- 正则化:防止过拟合的技术,例如权重衰减和 dropout。
- 激活函数:神经元输出的非线性函数。
- 优化器:用于更新权重的算法,例如梯度下降和 Adam。每次训练完成需要更新权重参数,直到损失函数达到要求,退出训练。
4.3.3. 挑战
训练深度神经网络的挑战:
- 过拟合:网络在训练数据上表现良好,但在新数据上表现不佳。
- 欠拟合:网络无法从训练数据中学到足够的模式。
- 梯度消失和爆炸:在反向传播过程中,梯度可能变得非常小或非常大,这会阻碍训练。
- 局部最小值:优化算法可能收敛到局部最小值,而不是全局最小值。
4.3.4. 最佳实践
训练深度神经网络的最佳实践:
- 使用交叉验证来防止过拟合。
- 使用正则化技术来减少过拟合。
- 仔细调整超参数以获得最佳性能。
- 使用早期停止来防止过拟合。
- 使用权重初始化技术来防止梯度消失和爆炸。
4.4. 应用
深度学习理论上可以完全替代传统的机器学习算法,只要神经元足够,训练数据足够。传统机器学习能够达到的效果,深度学习都可以达到,并且可以拟合得更好。大力出奇迹在深度学习中完美体现。
4.4.1. 多元线性回归
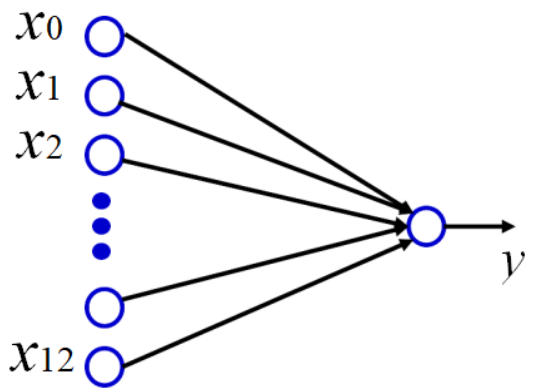
如下13个自变量(输入),一个因变量(输出),因为是线性回归,只用一个神经元,且不需要激活函数。训练完成生成模型之后,可以保存模型,下次就直接使用模型来进行预测了。
4.4.2. 其他
深度神经网络推荐使用Pytorch。
Github上的代码示例:GitHub - yunjey/pytorch-tutorial: PyTorch Tutorial for Deep Learning Researchers
GitHub - zergtant/pytorch-handbook: pytorch handbook是一本开源的书籍,目标是帮助那些希望和使用PyTorch进行深度学习开发和研究的朋友快速入门,其中包含的Pytorch教程全部通过测试保证可以成功运行
GitHub - chenyuntc/pytorch-book: PyTorch tutorials and fun projects including neural talk, neural style, poem writing, anime generation (《深度学习框架PyTorch:入门与实战》)
GPU测试平台,可以利用Google的免费在线虚拟机器:https://colab.research.google.com/
或阿里云魔搭社区虚拟机,GPT免费36小时:魔搭社区
相关文章:
人工智能——深度学习
4. 深度学习 4.1. 概念 深度学习是一种机器学习的分支,旨在通过构建和训练多层神经网络模型来实现数据的高级特征表达和复杂模式识别。与传统机器学习算法相比,深度学习具有以下特点: 多层表示学习:深度学习使用深层神经网络&a…...

postgresql uuid
示例数据库版本PG16,对于参照官方文档截图,可以在最上方切换到对应版本查看,相差不大。 方法一:自带函数 select gen_random_uuid(); 去掉四个斜杠,简化成32位 select replace(gen_random_uuid()::text, -, ); 官网介绍…...
【azure笔记 1】容器实例管理python sdk封装
容器实例管理python sdk封装 测试结果 说明 这是根据我的需求写的,所以有些参数是写死的,比如cpu核数和内存,你可以根据你的需要自行修改。前置条件: 当前环境已安装python3.8以上版本和azure cli并且已经登陆到你的账户 依赖安…...
和又可以异常(Exception)的过滤器)
Nestjs 中定义既可以捕获错误(Error)和又可以异常(Exception)的过滤器
Nestjs 中,使用基于 HttpException 定义过滤器的话,只能捕获 Http 带状态码(statusCode)的 Exception,不能捕获 throw new Error(‘xxx’) 抛出的错误。 以下是使用实现 ExceptionFilter 接口定义的一个不特定于平台(express 或 fastify,即无论使用这两个web服务框架的…...

GitHub 仓库 (repository) Branch - SSH clone URL - Clone in Desktop - Download ZIP
GitHub 仓库 [repository] Branch - SSH clone URL - Clone in Desktop - Download ZIP 1. Branch2. SSH clone URL3. Clone in Desktop4. Download ZIPReferences 1. Branch 显示当前分支的名称。从这里可以切换仓库内分支,查看其他分支的文件。 2. SSH clo…...
Training - 使用 WandB 配置 可视化 模型训练参数
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/137529140 WandB (Weights&Biases) 是轻量级的在线模型训练可视化工具,类似于 TensorBoard,可以帮助用户跟踪…...

N1922A是德科技N1922A功率传感器
181/2461/8938产品概述: N192XA 传感器是首款通过将直流参考源和开关电路集成到功率传感器中来提供内部调零和校准的传感器。此功能消除了与使用外部校准源相关的多个连接,从而最大限度地减少了连接器磨损、测试时间和测量不确定性。 连接到 DUT 时进行…...

最简洁的Docker环境配置
Docker环境配置 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Mac、Linux或Windows操作系统的机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不…...
Docker内更新Jenkins详细讲解
很多小伙伴在Docker中使用Jenkins时更新遇到困难,本次结合自己的实际经验,详细讲解。根据官网Jenkins了解以下内容: 一、Jenkins 是什么? Jenkins是一款开源 CI&CD 软件,用于自动化各种任务,包括构建、测…...

基于遗传模拟退火混合优化算法的车间作业最优调度matlab仿真,输出甘特图
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 4.1遗传算法与模拟退火算法简介 4.2 GSAHO算法应用于JSSP 5.完整程序 1.程序功能描述 车间作业调度问题(Job Shop Scheduling Problem, JSSP)是一种典型的生产调度问…...

Mac 安装 brew brew cask 遇到的问题以及解决办法
安装Homebrew和Homebrew Cask是在Mac上管理软件包的常用方法。虽然大多数情况下安装这两个工具是比较简单的,但有时候也可能遇到一些问题。下面是一些常见的问题以及解决办法: 问题1:无法安装Homebrew 解决办法: 1.确保你的Mac已连…...

Vitalik Buterin香港主旨演讲:协议过去10年迅速发展,但存在效率、安全两大问题
2024 香港 Web3 嘉年华期间,以太坊联合创始人 Vitalik Buterin 在由DRK Lab主办的“Web3 学者峰会 2024”上发表主旨演讲《Reaching the Limits of Protocol Design》。 他介绍到,2010年代,基于基本密码学的协议是哈希、签名。随后ÿ…...

【leetcode】大数相加
题目链接:415. 字符串相加 - 力扣(LeetCode) 计算两个大数的和,从末尾开始逐个字符相加,记录进位 class Solution { public:string addStrings(string num1, string num2) {int i num1.size() - 1, j num2.size() …...

数据检索的优化之道:B树与B+树的深度解析与应用探索
1、引言 在信息时代,数据检索的速度和效率对于任何依赖数据处理的系统来说都至关重要。无论是在线搜索引擎、数据库管理系统还是文件存储系统,快速准确地检索所需数据都是核心需求。传统的线性数据结构在处理大规模数据集时往往力不从心,因此…...

替换服务器的SSL证书有什么影响?
SSL证书是保护网站和用户数据安全的重要组成部分。然而,出于一些原因,网站管理员可能需要替换服务器的SSL证书。替换SSL证书可能会对网站的运行和安全产生一些影响。本文旨在介绍替换服务器SSL证书的影响和相关注意事项,帮助网站管理员更好地…...

java中可变参数和简单游戏
可变参数: 就是一种特殊形参,定义在方法,构造器的形参列表中,格式是:数据类型...参数名称 可变参数的好处: 灵活的接收数据 特点:可以不传数据给它,可以传一个数据或者多个数据给它…...

软考高级架构师:TCP/IP 协议 和 OSI 七层模型
一、AI 讲解 TCP/IP 协议族是一组计算机网络通信协议的集合,其中TCP和IP是两个核心协议。TCP/IP 协议族通常被用来参照互联网的基础通信架构。与之相对的OSI七层模型,是一个更为理论化的网络通信模型,它将网络通信分为七个层次。 TCP/IP 与…...
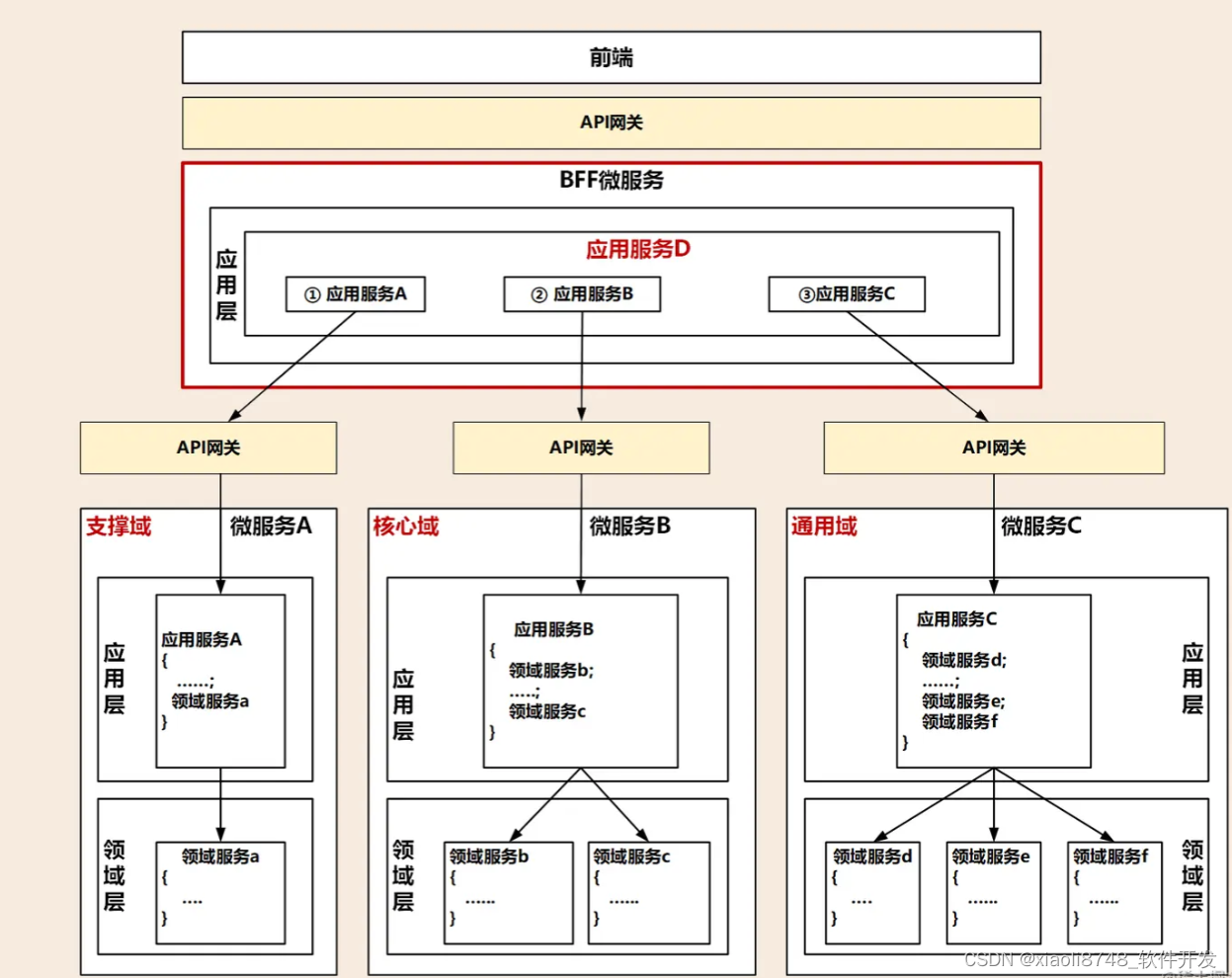
【微服务】------常见模型的分析与比较
DDD 分层架构 整洁架构 整洁架构又名“洋葱架构”。为什么叫它洋葱架构?看看下面这张图你就明白了。整洁架构的层就像洋葱片一样,它体现了分层的设计思想。 整洁架构最主要的原则是依赖原则,它定义了各层的依赖关系,越往里依赖越…...

C#实现HTTP上传文件的方法
/// <summary> /// Http上传文件 /// </summary> public static string HttpUploadFile(string url, string path) {// 设置参数HttpWebRequest request WebRequest.Create(url) as HttpWebRequest;CookieContainer cookieContainer new CookieContainer();reque…...
pdffactory pro 8注册码序列号下载 附教程
PdfFactory Pro可以说是一款行业专业且技术领先的的PDF虚拟打印机软件。其不仅占用系统内存小巧,功能强大,可支持用户无需使用Acrobat来创建Adobe PDF即可以进行PDF组件的创建和打印。同时,现在全新的PdfFactory Pro 8也正式上线来袭…...

技术视角:分布式投票系统的异步解耦架构与多语言协同实践
技术视角:分布式投票系统的异步解耦架构与多语言协同实践 【免费下载链接】example-voting-app Example Docker Compose app 项目地址: https://gitcode.com/gh_mirrors/exa/example-voting-app 在当今企业级应用架构设计中,如何平衡高并发处理、…...

VSCode光标主题定制指南:从颜色令牌到扩展开发
1. 项目概述:一个为开发者定制的光标主题集合如果你和我一样,每天有超过8小时的时间都泡在代码编辑器里,那么你一定会对编辑器里那个千篇一律的、闪烁的竖线光标感到审美疲劳。warrenwoodhouse/cursors这个项目,就是来解决这个“小…...

穿越机老鸟踩坑实录:MPU6000传感器在F4飞控上的IMU方向“玄学”配置
穿越机IMU方向配置实战:从MPU6000异常自旋到飞控底层校准 当你的穿越机在通电瞬间像被无形大手狠狠抽了一记耳光般疯狂自旋,而Betaflight地面站里陀螺仪数据却显示"一切正常"时,这往往意味着你正遭遇IMU方向配置的"量子纠缠态…...

LearningX:构建结构化开发者知识体系,从基础到架构的实践指南
1. 项目概述:一个面向开发者的系统性学习仓库最近在GitHub上看到一个挺有意思的项目,叫“LearningX”。光看名字,你可能会觉得这又是一个普通的“Awesome-XXX”列表,或者是一堆学习资料的简单堆砌。但当我点进去,花了一…...

智能路由器项目解析:基于策略路由实现多线路流量智能调度
1. 项目概述:一个“聪明”的路由器能做什么?最近在GitHub上看到一个挺有意思的项目,叫smart-router,作者是c0nSpIc0uS7uRk3r。光看名字,你可能会觉得这又是一个关于家庭网络优化的工具,但点进去仔细研究后&…...

SmarterRouter:基于软件定义与模块化构建智能路由器系统
1. 项目概述:一个更聪明的路由器,它到底想做什么?如果你和我一样,折腾过家里的网络,从刷第三方固件到组软路由,那你肯定对“路由器”这三个字有复杂的感情。它本该是默默无闻的网络基石,却常常因…...

从分布式到可分发:大规模软件制品分发架构设计与实践
1. 项目概述:从“分布式”到“可分发”的思维跃迁最近在梳理团队内部的基础设施时,又翻出了distr-sh/distr这个项目。说实话,第一次看到这个仓库名,我下意识地把它归类为又一个“分布式系统”框架。但当我真正点进去,花…...

别再只盯着CSI-2了!用示波器实测MIPI D-PHY波形,手把手教你排查Camera不通的硬件问题
别再只盯着CSI-2了!用示波器实测MIPI D-PHY波形,手把手教你排查Camera不通的硬件问题 调试Camera模块时,MIPI信号问题往往是硬件工程师最头疼的挑战之一。当系统出现图像异常、花屏或无法识别时,大多数工程师的第一反应是检查CSI-…...

3步强力清理:Pearcleaner让你轻松解决Mac应用残留文件问题
3步强力清理:Pearcleaner让你轻松解决Mac应用残留文件问题 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾删除Mac应用后,发…...

用C++和RealSense D435i搞个3D手势识别?从像素坐标到相机坐标的保姆级避坑指南
3D手势识别实战:用RealSense D435i实现像素到相机坐标的高精度转换 当你的手指在空气中划出一道弧线,计算机能否精准捕捉这个三维动作?这正是3D手势识别技术试图解决的问题。作为人机交互领域的前沿方向,3D手势识别正在VR游戏、医…...