合并单元格的excel文件转换成json数据格式
github地址: https://github.com/CodeWang-Ay/DataProcess
类型1
需求1:
类似于数据格式: https://blog.csdn.net/qq_44072222/article/details/120884158
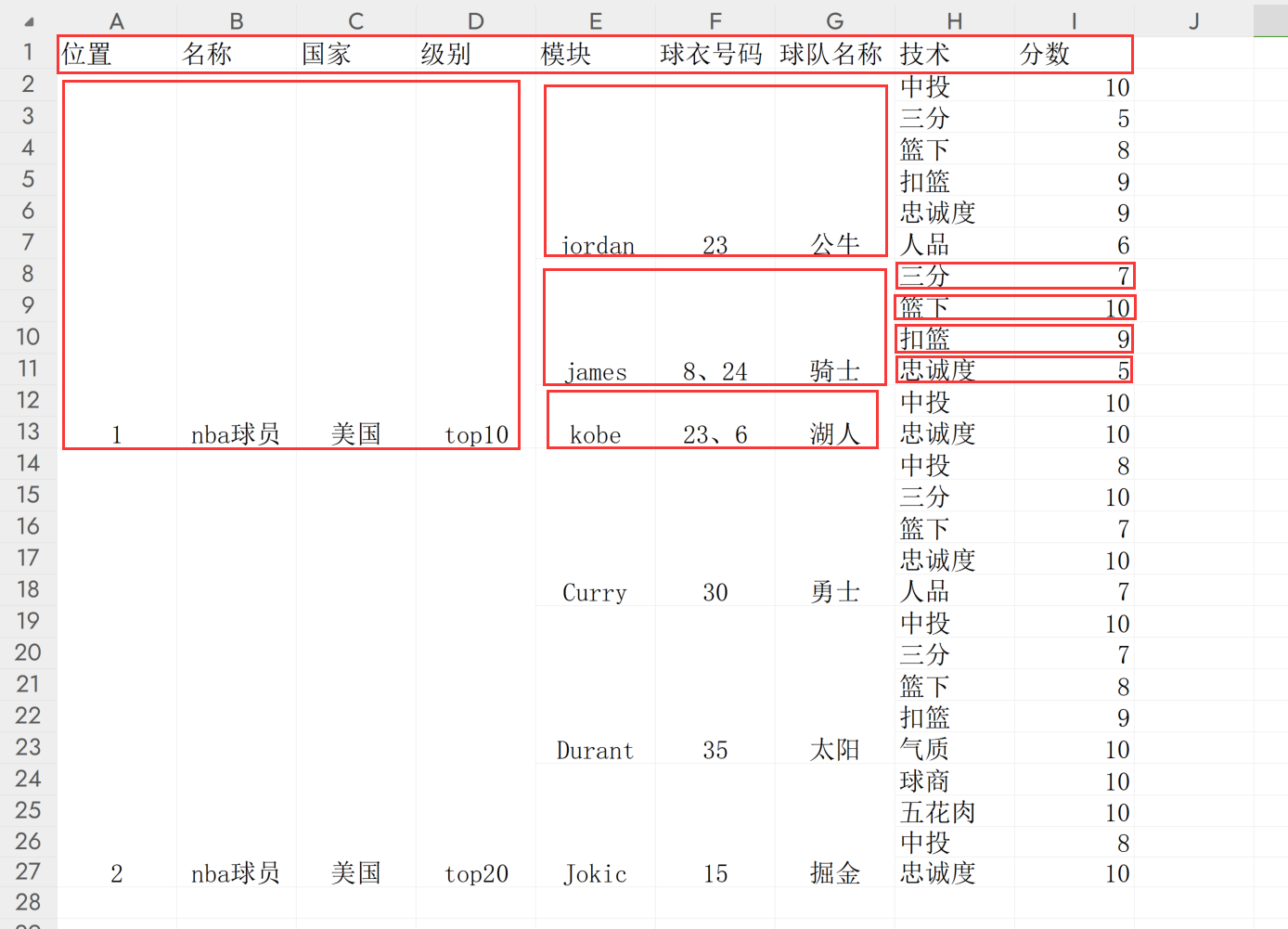
目标json格式
{"位置": 1, "名称": "nba球员", "国家": "美国", "级别": "top10", "level2": [{"模块": "jordan", "球衣号码": 23, "球队名称": "公牛", "level3": [{"技术": "中投", "分数": 10}, {"技术": "三分", "分数": 5}, {"技术": "篮下", "分数": 8}, {"技术": "扣篮", "分数": 9}, {"技术": "忠诚度", "分数": 9}, {"技术": "人品", "分数": 6}]}, {"模块": "james", "球衣号码": "8、24", "球队名称": "骑士", "level3": [{"技术": "三分", "分数": 7}, {"技术": "篮下", "分数": 10}, {"技术": "扣篮", "分数": 9}, {"技术": "忠诚度", "分数": 5}]}, {"模块": "kobe", "球衣号码": "23、6", "球队名称": "湖人", "level3": [{"技术": "中投", "分数": 10}, {"技术": "忠诚度", "分数": 10}]}]}
转json格式链接: https://www.json.cn/#google_vignette

整体思路
数据格式相等于是一个三层的的树,一次遍历第一层,第二层, 第三层然后构建一颗树即可
第一层: 列范围 1-4
第二层: 列范围 5-7
第三层: 列范围 8-9
关键参数
表示三层
每次定位到第一层然后范围依次缩小取位置
col_level_index = [1, 5, 8, 10] # level1, level2, level3, level4
使用 openpyxl 工具包
openpyxl 中文文档: https://openpyxl-chinese-docs.readthedocs.io/zh-cn/latest/tutorial.html
解决代码:
import jsonimport openpyxl as xl
import pandas as pddef get_merge_cell_by_no(sheet_, column_no):""":param sheet: sheet对象:param column_no: 列索引 从1开始:return: 返回给定的索引下的所有合并单元格"""merger_cell = [] # 第一列合并的单元格merged_ranges = sheet_.merged_cells.ranges # 获取当前工作表的所有合并区域列表for merged_cell_range in merged_ranges:if merged_cell_range.min_col == column_no and merged_cell_range.max_col == column_no:merger_cell.append(merged_cell_range)return sorted(merger_cell, key=lambda x: x.min_row) # 排序返回 默认不排序def get_merge_cell_by_special(sheet, start_row, end_row, start_col, end_col):"""在特定范围内的合并单元格坐标:param sheet::param start_row::param end_row::param start_col::param end_col::return:"""merger_cell = [] # 第一列合并的单元格merged_ranges = sheet.merged_cells.ranges # 获取当前工作表的所有合并区域列表for merged_cell_range in merged_ranges:up = merged_cell_range.min_row >= start_rowdown = merged_cell_range.max_row <= end_rowleft = merged_cell_range.min_col >= start_colright = merged_cell_range.max_col <= end_colif up and down and left and right:merger_cell.append(merged_cell_range)return sorted(merger_cell, key=lambda x: x.min_row) # 排序返回 默认不排序def get_filed_by_row_id(sheet_, keys, row_id, col_level_index):"""get_filed_by_row_id 通过行id得到所有的json"""# for row_id in row_list:filed_json = {}for row in sheet_.iter_rows(min_row=row_id, max_row=row_id, min_col=col_level_index[2], max_col=col_level_index[3], values_only=True):filed_json = get_dict_by_list(keys, row)# print(row)return filed_jsondef get_dict_by_list(keys, values):"""get_dict_by_list"""data_dict = {}for key, value in zip(keys, values):data_dict[key] = valuereturn data_dictdef save_jsonline_json(json_list, target_path):"""json_list ---> jsonline:param json_list::param target_path::return:"""with open(target_path, 'w', encoding="utf-8") as json_file:for item in json_list:json.dump(item, json_file, ensure_ascii=False)json_file.write("\n")print("Json列表已经保存到 {} 文件中。 每一行为一个json对象".format(target_path))def excel_to_json_tree_e2e(sheet_, col_level_index):alphabet = " ABCDEFGHIJKLMNOPQRSTUVWXYZ"level_merge_list = get_merge_cell_by_no(sheet_, col_level_index[0]) # 一级逻辑关系所有的列\json_list = []for index_level1, merge_level1 in enumerate(level_merge_list):start_row_level1 = merge_level1.min_rowend_row_level1 = merge_level1.max_rowlevel1_map = {}for col in range(col_level_index[0], col_level_index[1]): # 列A是1,列D是4key = sheet_[alphabet[col] + str(1)].valuecell_ref = sheet_[alphabet[col] + str(start_row_level1)].value # 因为第二行,所以+1level1_map[key] = cell_ref # 第一个阶段结束level1_map["level2"] = []level2_merge_list = get_merge_cell_by_special(sheet_, start_row_level1, end_row_level1,col_level_index[1], col_level_index[1])level2_list = []for index_level2, merge_cell_level2 in enumerate(level2_merge_list):start_row_level2 = merge_cell_level2.min_rowend_row_level2 = merge_cell_level2.max_rowlevel2_list.append([i for i in range(start_row_level2, end_row_level2 + 1)])level2_map = {}for col in range(col_level_index[1], col_level_index[2]): # 列A是1,列D是4key = sheet_[alphabet[col] + str(1)].valuecell_ref = sheet_[alphabet[col] + str(start_row_level2)].value # 因为第二行,所以+1level2_map[key] = cell_ref # 第一个阶段结束column_name_list = []for col in range(col_level_index[2], col_level_index[3]): # 列A是1,列D是4key = sheet_[alphabet[col] + str(1)].valuecolumn_name_list.append(key)level2_map["level3"] = []for row_id in range(start_row_level2, end_row_level2+1):current_filed_json = get_filed_by_row_id(sheet_, column_name_list, row_id, col_level_index)level2_map["level3"].append(current_filed_json)level1_map["level2"].append(level2_map)json_list.append(level1_map)return json_listif __name__ == '__main__':excel_file = "excel/merge_new.xlsx"output_path = "output/nba_json.json"wb = xl.load_workbook(excel_file)sheet = wb["nba"]col_level_index = [1, 5, 8, 10] # level1, level2, level3, level4json_list = excel_to_json_tree_e2e(sheet, col_level_index)save_jsonline_json(json_list, output_path)类型2
需求2:
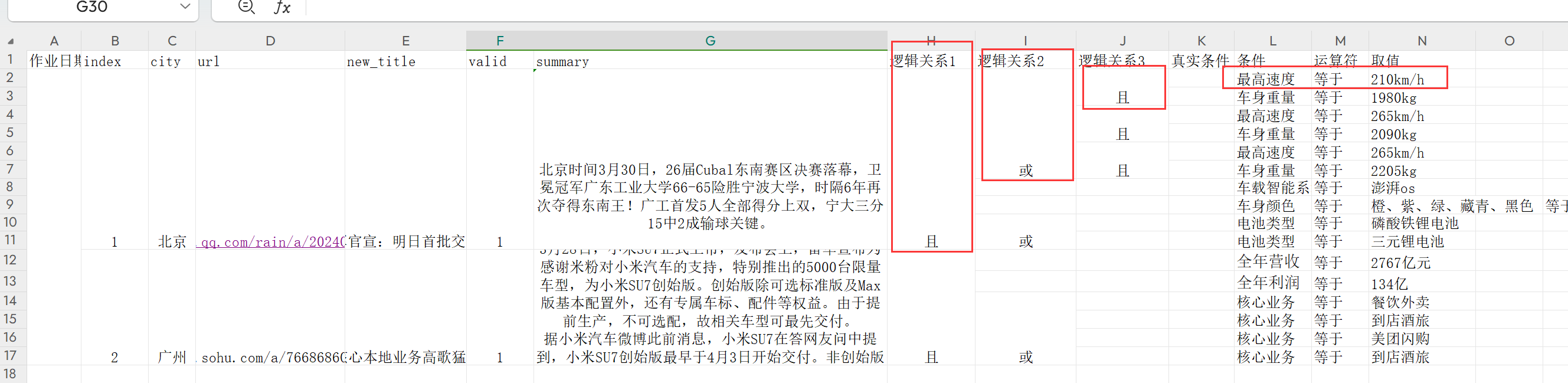
转成:
数据格式相等于是一个三层的的树,一次遍历第一层,第二层, 第三层然后构建一颗树即可
第一层: 列范围 H
第二层: 列范围 I
第三层: 列范围 J
第四层: 列范围 KLMN
关键参数
每次定位到第一层然后范围依次缩小取位置
{"source": "北京时间3月30日,26届Cubal东南赛区决赛落幕,卫冕冠军广东工业大学66-65险胜宁波大学,时隔6年再次夺得东南王!广工首发5人全部得分上双,宁大三分15中2成输球关键。\n", "label": {"relation": "且", "conditions": [{"relation": "或", "conditions": [{"relation": "且", "conditions": [{"description": "最高速度", "option": "等于", "requirement": "210km/h"}, {"description": "车身重量", "option": "等于", "requirement": "1980kg"}]}, {"relation": "且", "conditions": [{"description": "最高速度", "option": "等于", "requirement": "265km/h"}, {"description": "车身重量", "option": "等于", "requirement": "2090kg"}]}, {"relation": "且", "conditions": [{"description": "最高速度", "option": "等于", "requirement": "265km/h"}, {"description": "车身重量", "option": "等于", "requirement": "2205kg"}]}]}, {"description": "车载智能系统", "option": "等于", "requirement": "澎湃os"}, {"description": "车身颜色", "option": "等于", "requirement": "橙、紫、绿、藏青、黑色"}, {"relation": "或", "conditions": [{"description": "电池类型", "option": "等于", "requirement": "磷酸铁锂电池"}, {"description": "电池类型", "option": "等于", "requirement": "三元锂电池"}]}]}}
解决代码:
import openpyxl as xl
import json
import itertools
import copydef get_merge_cell_by_no(sheet_, column_no):""":param sheet::param column_no::return:"""merger_cell = [] # 第一列合并的单元格merged_ranges = sheet_.merged_cells.ranges # 获取当前工作表的所有合并区域列表for merged_cell_range in merged_ranges:if merged_cell_range.min_col == column_no and merged_cell_range.max_col == column_no:merger_cell.append(merged_cell_range)return sorted(merger_cell, key=lambda x: x.min_row) # 排序返回 默认不排序def get_merge_cell_by_special(sheet, start_row, end_row, start_col, end_col):"""在特定范围内的合并单元格坐标:param sheet::param start_row::param end_row::param start_col::param end_col::return:"""merger_cell = [] # 第一列合并的单元格merged_ranges = sheet.merged_cells.ranges # 获取当前工作表的所有合并区域列表for merged_cell_range in merged_ranges:up = merged_cell_range.min_row >= start_rowdown = merged_cell_range.max_row <= end_rowleft = merged_cell_range.min_col >= start_colright = merged_cell_range.max_col <= end_colif up and down and left and right:merger_cell.append(merged_cell_range)return sorted(merger_cell, key=lambda x: x.min_row) # 排序返回 默认不排序def get_dict_by_list(keys, values):"""get_dict_by_list"""data_dict = {}for key, value in zip(keys, values):data_dict[key] = valuereturn data_dictdef get_filed_by_row_id(sheet_, keys, row_id, use_align):"""get_filed_by_row_id 通过行id得到所有的json"""# for row_id in row_list:filed_json = {}for row in sheet_.iter_rows(min_row=row_id, max_row=row_id, min_col=11, max_col=14, values_only=True):if use_align:row = [row[0], row[2], row[3]] # 取数配置那一列不要else:row = [row[1], row[2], row[3]] # 取数配置那一列不要filed_json = get_dict_by_list(keys, row)# print(row)return filed_jsondef custom_sort_key(item):"""合并单元格排序"""if isinstance(item, list):return item[0]else:return itemdef excel_to_json_tree_e2e(sheet_, column_name_list, logic_level, level1_col_index, isvalid_col, use_align):"""excel_to_json_tree. 读取excel文件,转换成json树结构:param sheet_::param column_name_list: key_list:param logic_level: summary, 一级, 二级, 三级列名:param level1_col_index: 第一级逻辑关系的索引 8:param isvalid_col: 是否有效列, 有效我们才进行转化:return:"""level_merge_list = get_merge_cell_by_no(sheet_, level1_col_index) # 一级逻辑关系所有的列e2e_json_list = []pre_json_list = []post_json_list = []relation_key = "relation"condition_key = "conditions"for index_level1, merge_cell_level1 in enumerate(level_merge_list):e2e_json = {}pre_json_total = {}post_json_label = {}post_json_total = {}start_row_level1 = merge_cell_level1.min_rowend_row_level1 = merge_cell_level1.max_rowlevel1_merge = [i for i in range(start_row_level1, end_row_level1 + 1)] # level的所有列索引summary_content = sheet_[logic_level[0] + str(start_row_level1)].value # G2 内容用于构建 source: target使用level1_json = {}level1_logic = sheet_[logic_level[1] + str(start_row_level1)].value # H2level1_json[relation_key] = level1_logic # relation : logiclevel1_json[condition_key] = [] #level1_json_pre = copy.deepcopy(level1_json) # 拷贝isvalid = sheet_[isvalid_col + str(start_row_level1)].value # F2 验证有效字段是否有效 无效则直接跳过if isvalid != 1: # 验证是否有效字段continue# postpost_json_label[condition_key] = []for row_id in level1_merge:current_post_json = get_filed_by_row_id(sheet_, column_name_list, row_id, use_align)post_json_label[condition_key].append(current_post_json)level2_merge = []level2_merge_cell_list = get_merge_cell_by_special(sheet_, start_row_level1, end_row_level1,level1_col_index + 1, level1_col_index + 1)for index_level2, merge_cell_level2 in enumerate(level2_merge_cell_list):start_row_level2 = merge_cell_level2.min_rowend_row_level2 = merge_cell_level2.max_rowlevel2_merge.append([i for i in range(start_row_level2, end_row_level2 + 1)])level2_merge_one_dimension = list(itertools.chain.from_iterable(level2_merge))level2_single = [i for i in level1_merge if i not in level2_merge_one_dimension]level2 = level2_merge + level2_singlelevel2 = sorted(level2, key=custom_sort_key) # 为了保证顺序for element in level2:if type(element) is int:# 没有二级逻辑关系row_id = elementcurrent_filed_json = get_filed_by_row_id(sheet_, column_name_list, row_id, use_align)level1_json[condition_key].append(current_filed_json)value = current_filed_json[column_name_list[0]] # pre datasetlevel1_json_pre[condition_key].append(value)elif type(element) is list:# 二级逻辑关系current_level2_merge = elementstart = element[0]end = element[-1]level3_merge_list = get_merge_cell_by_special(sheet_, start, end,level1_col_index + 2, level1_col_index + 2)level2_json = {}level2_logic = sheet_[logic_level[2] + str(start)].valuelevel2_json[relation_key] = level2_logiclevel2_json[condition_key] = []level2_json_pre = copy.deepcopy(level2_json)if len(level3_merge_list) == 0:# 没有三级逻辑关系for row_id in element:current_filed_json = get_filed_by_row_id(sheet_, column_name_list, row_id, use_align)level2_json[condition_key].append(current_filed_json)level2_json_pre[condition_key].append(current_filed_json[column_name_list[0]])else:# 有三级逻辑关系level3_merge = []for merge_cell_level3 in level3_merge_list:start_row_level3 = merge_cell_level3.min_rowend_row_level3 = merge_cell_level3.max_rowlevel3_merge.append([i for i in range(start_row_level3, end_row_level3 + 1)])level3_merge_one_dimension = list(itertools.chain.from_iterable(level3_merge))level3_single = [i for i in current_level2_merge if i not in level3_merge_one_dimension]level3 = level3_single + level3_mergelevel3 = sorted(level3, key=custom_sort_key)for element_level3 in level3:if type(element_level3) is int:current_filed_json = get_filed_by_row_id(sheet_, column_name_list, element_level3, use_align)level2_json[condition_key].append(current_filed_json)level2_json_pre[condition_key].append(current_filed_json[column_name_list[0]])elif type(element_level3) is list:level3_start = element_level3[0]level3_end = element_level3[-1]level3_json = {}level3_logic = sheet_[logic_level[3] + str(level3_start)].valuelevel3_json[relation_key] = level3_logiclevel3_json[condition_key] = []level3_json_pre = copy.deepcopy(level3_json)for row_id in element_level3:current_filed_json = get_filed_by_row_id(sheet_, column_name_list, row_id, use_align)level3_json[condition_key].append(current_filed_json)field = current_filed_json[column_name_list[0]]level3_json_pre[condition_key].append(field)level2_json[condition_key].append(level3_json)level2_json_pre[condition_key].append(level3_json_pre)level1_json[condition_key].append(level2_json)level1_json_pre[condition_key].append(level2_json_pre)e2e_json["source"] = summary_contente2e_json["label"] = level1_jsonpre_json_total["source"] = summary_contentpre_json_total["label"] = level1_json_prepost_json_total["source"] = summary_contentpost_json_total["label"] = post_json_label# print(json.dumps(e2e_json, ensure_ascii=False))# print(json.dumps(pre_json_total, ensure_ascii=False))# print(json.dumps(post_json_total, ensure_ascii=False))e2e_json_list.append(e2e_json)pre_json_list.append(pre_json_total)post_json_list.append(post_json_total)return e2e_json_list, pre_json_list, post_json_listdef save_jsonline_json(json_list, target_path):"""json_list ---> jsonline:param json_list::param target_path::return:"""with open(target_path, 'w', encoding="utf-8") as json_file:for item in json_list:json.dump(item, json_file, ensure_ascii=False)json_file.write("\n")print("Json列表已经保存到 {} 文件中。 每一行为一个json对象".format(target_path))# 按顺序读取
"""
openpyxl 中文文档
https://openpyxl-chinese-docs.readthedocs.io/zh-cn/latest/tutorial.html
"""if __name__ == "__main__":source_file = "excel/merge_new.xlsx" # excel pathwb = xl.load_workbook(source_file)sheet = wb["news"] # 子表对象key_name_list = ["description", "option", "requirement"]target_e2e_path = "output/train_e2e.json"target_pre_path = "output/train_pre.json"target_post_path = "output/train_post.json"target_logic_level = ["G", "H", "I", "J"] # 逻辑关系所对应的列valid_col = "F" # 是否有效列的字母align_flag = 0 # 是否使用对齐列e2e_list, pre_list, post_list = excel_to_json_tree_e2e(sheet, key_name_list, target_logic_level,8, valid_col, align_flag)# json_list = excel_to_json_tree_post(sheet, key_name_list, target_logic_level, 8, isvalid_col)save_jsonline_json(e2e_list, target_e2e_path)save_jsonline_json(pre_list, target_pre_path)save_jsonline_json(post_list, target_post_path)相关文章:
合并单元格的excel文件转换成json数据格式
github地址: https://github.com/CodeWang-Ay/DataProcess 类型1 需求1: 类似于数据格式: https://blog.csdn.net/qq_44072222/article/details/120884158 目标json格式 {"位置": 1, "名称": "nba球员", "国家": "美国"…...

云平台和云原生
目录 1.0 云平台 1.1.0 私有云、公有云、混合云 1.1.1 私有云 1.1.2 公有云 1.1.3 混合云 1.2 常见云管理平台 1.3 云管理的好处 1.3.1 多云的统一管理 1.3.2 跨云资源调度和编排需要 1.3.3 实现多云治理 1.3.4 多云的统一监控和运维 1.3.5 统一成本分析和优化 1.…...

ES6 => 箭头函数
目录 语法基本形式 参数 函数体 特点 箭头函数(Arrow Function)是ES6(ECMAScript 2015)中引入的一种新的函数语法,它提供了一种更简洁的方式来编写函数。箭头函数有几个显著的特点和优势,下面我们来详细…...

vue将html生成pdf并分页
jspdf html2canvas 此方案有很多的css兼容问题,比如虚线边框、svg、页数多了内容显示不全、部分浏览器兼容问题,光是解决这些问题就耗费了我不少岁月和精力 后面了解到新的技术方案: jspdf html-to-image npm install --save html-to-i…...

数字社会下的智慧公厕:构筑智慧城市的重要组成部分
智慧城市已经成为现代城市发展的趋势,而其中的数字化转型更是推动未来社会治理体系和治理能力现代化的必然要求。在智慧城市建设中,智慧公厕作为一种新形态的信息化公共厕所,扮演着重要角色。本文智慧公厕源头实力厂家广州中期科技有限公司&a…...
比较好玩的车子 高尔夫6
https://www.sohu.com/a/484063087_221273 四万多如愿收获手动挡高尔夫6,可靠性、经济性、操控性兼顾_搜狐汽车_搜狐网 2.基本上其他人也不知道到底是什么相关的车子信息...

智过网:非安全专业能否报考注安?哪些专业可以报考?
近年来,随着社会对安全生产管理的日益重视,注册安全工程师(简称注安)这一职业逐渐受到广大从业人员的青睐。然而,对于许多非安全专业的朋友来说,他们可能会困惑:非安全专业是否可以报考注安&…...

基于Whisper语音识别的实时视频字幕生成 (一): 流式显示视频帧和音频帧
Whishow Whistream(微流)是基于Whisper语音识别的的在线字幕生成工具,支持rtsp/rtmp/mp4等视频流在线语音识别 1. whishow介绍 whishow(微秀)是在线音视频流播放python实现,支持rtsp/rtmp/mp4等输入&…...
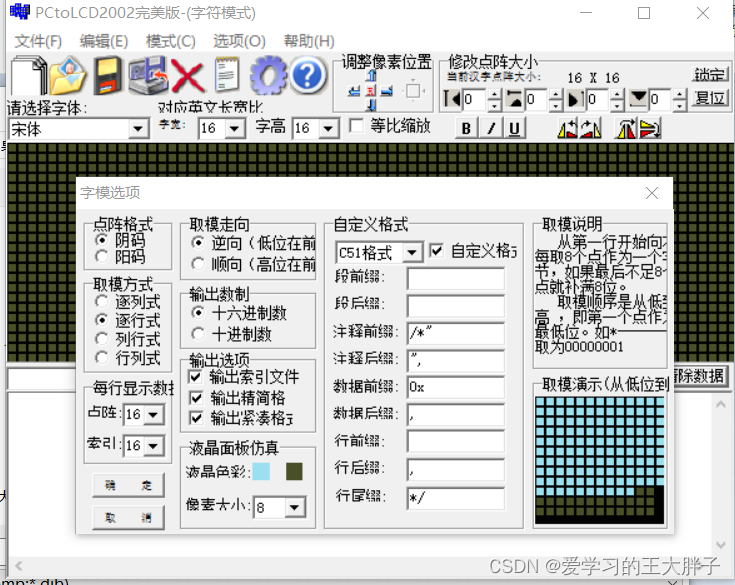
STM32+ESP8266水墨屏天气时钟:文字取模和图片取模教程
项目背景 本次的水墨屏幕项目需要显示一些图片和文字,所以需要对图片和文字进行取模。 取模步骤 1.打开取模软件 2.选择图形模式 3.设置字模选项 注意:本次项目采用的是水墨屏,并且是局部刷新的代码,所以设置字模选项可能有点…...

华为机试题
目录 第一章、HJ1计算字符串最后一个单词的长度,单词以空格隔开。1.1)描述1.2)解题第二章、算法题HJ2 计算某字符出现次数1.1)题目描述1.2)解题思路与答案第三章、算法题HJ3 明明的随机数1.1)题目描述1.2&a…...

【VUE】Vue3+Element Plus动态间距处理
目录 1. 动态间距调整1.1 效果演示1.2 代码演示 2. 固定间距2.1 效果演示2.2 代码演示 其他情况 1. 动态间距调整 1.1 效果演示 并行效果 并列效果 1.2 代码演示 <template><div style"margin-bottom: 15px">direction:<el-radio v-model"d…...
华为 2024 届校园招聘-硬件通⽤/单板开发——第一套(部分题目分享,完整版带答案,共十套)
华为 2024 届校园招聘-硬件通⽤/单板开发——第一套 部分题目分享,完整版带答案(有答案和解析,答案非官方,未仔细校正,仅供参考)(共十套)获取(WX:didadidadidida313,加我…...

自己整理的ICT云计算题库四
14. 【多选题】 CIFS 支持的认证方式是以下哪些选项? A: A 全局认证 B: B LADP 域 C: C 本地认证 D: D AD 域 答案 正确答案:ACD 解释 全局认证为先本地,后AD,再LADP 15. 【单选题】 华为 oceanstor v3 smarterase 在使用时…...

5.消息队列
消息队列 消息队列是一种常用的线程间通讯方式,用来传输数据。使用消息队列传输数据时有两种方法:拷贝:把数据、把变量的值复制进消息队列里;引用:把数据、把变量的地址复制进消息队列里。rtt使用拷贝值的方法。 …...

基于强化学习的对抗意图识别
源自:指挥与控制学报 作者:白亮, 肖延东, 齐景涛 “人工智能技术与咨询” 发布 摘 要 未来智能化战争复杂多变,敌我双方往往以对抗博弈情况出现,当我方作为攻击者时,如何有效隐藏我方意图实…...

vue canvas绘制信令图,动态显示标题、宽度、高度
需求: 1、 根据后端返回的数据,动态绘制出信令图 2、根据 dataStatus 返回值: 0 和 1, 判断 文字内容的颜色,0:#000,1:red 3.、根据 lineType 返回值: 0 和 1, 判断 箭…...
无影云电脑不能连接到本机的调试串口的解决方案
目录 概述 解决方案 云端电脑中的操作 本地USBDK驱动程序的更新 概述 我从1月份开始使用阿里的无影云电脑进行嵌入式开发板的测试,主要的原因有两个:一是平时使用的笔记本资源过于紧张,二是方便移动办公,这样我只要平时拿着开…...

gpt科普1 GPT与搜索引擎的对比
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的自然语言处理模型。它通过大规模的无监督学习来预训练模型,在完成这个阶段后,可以用于各种NLP任务,如文本生成、机器翻译、文本分类等。 以下是关…...

Element-plus使用中遇到的问题
el-input 设置typenumber,会出现上下箭头,在全局配置css样式即可解决,在app.vue中的css中加入:.table-clear-row {input::-webkit-outer-spin-button,input::-webkit-inner-spin-button {-webkit-appearance: none;}input[type&q…...

如何使用Arduino IDE对STM32F103C8T6进行编程
使用Arduino IDE对STM32F103C8T6进行编程调试,你需要进行一些准备工作和设置。以下是详细的操作步骤: 准备工作: 安装Arduino IDE:确保你已经安装了最新版本的Arduino IDE。可以从官方网站 https://www.arduino.cc/en/software 下…...

基于AI智能体的渗透测试框架:从自动化到智能协同的范式转变
1. 项目概述:一个面向渗透测试的智能体框架最近在整理自己的工具链时,发现了一个挺有意思的项目,叫GH05TCREW/pentestagent。乍一看这个名字,你可能会觉得这又是一个“缝合怪”式的自动化渗透工具,把Nmap、SQLmap之类的…...

5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南
5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否遇到过这样的困扰?精心编写的A…...

Python与ChatGPT构建智能办公自动化:从任务分解到智能体系统
1. 项目概述:用Python与ChatGPT联手,让办公自动化“开口说话”如果你每天还在重复着打开Excel、复制粘贴数据、手动写邮件、整理报告这些枯燥的活儿,那这个项目可能就是你的“数字员工”入职通知书。Sven-Bo/automate-office-tasks-using-cha…...

Windows Android子系统深度优化:WSABuilds项目架构解析与实战部署指南
Windows Android子系统深度优化:WSABuilds项目架构解析与实战部署指南 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or Ker…...

轻量级配置管理框架zcf:多环境配置、敏感信息加密与云原生集成实践
1. 项目概述:一个面向开发者的轻量级配置管理框架最近在梳理团队内部工具链时,发现一个挺普遍的问题:不同项目、不同环境(开发、测试、生产)的配置管理总是乱糟糟的。.env文件满天飞,敏感信息一不小心就提交…...

轻量级配置中心zcf:中小团队微服务配置管理实战指南
1. 项目概述:一个轻量级、高可用的配置中心最近在梳理团队内部的技术栈,发现一个挺有意思的现象:很多中小型项目,甚至是一些快速迭代的业务线,在配置管理上依然处于一种“原始”状态。要么是各种application.yml、appl…...

Vibe Coding Playbook:从环境到心流,打造高效愉悦的编程系统
1. 项目概述:一个关于“氛围感编程”的实践指南最近在GitHub上看到一个挺有意思的项目,叫“Vibe Coding Playbook”。乍一看这个标题,可能会有点摸不着头脑——“Vibe Coding”是什么?是某种新的编程范式吗?还是某种神…...

WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南
WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为魔兽争…...

多智能体涌现环境:从局部交互到群体智能的深度解析与实践
1. 项目概述:多智能体涌现环境的深度探索最近在复现和深入研究一个名为“multi-agent-emergence-environments”的开源项目,它来自OpenAI。这个项目名听起来有点学术,但它的核心思想非常迷人:在一个模拟的物理沙盒环境中ÿ…...

Helm Diff插件:可视化Kubernetes部署变更,保障发布安全
1. 项目概述:Helm Diff,一个让Kubernetes部署变更“可视化”的利器 如果你和我一样,长期在Kubernetes(K8s)环境中摸爬滚打,使用Helm来管理复杂的应用部署,那么你一定经历过这样的场景࿱…...