使用YOLOv8训练自己的【目标检测】数据集
文章目录
- 1.收集数据集
- 1.1 使用开源已标记数据集
- 1.2 爬取网络图像
- 1.3 自己拍摄数据集
- 1.4 使用数据增强生成数据集
- 1.5 使用算法合成图像
- 2.标注数据集
- 2.1确认标注格式
- 2.2 开始标注
- 3.划分数据集
- 4.配置训练环境
- 4.1获取代码
- 4.2安装环境
- 5.训练模型
- 5.1新建一个数据集yaml文件
- 5.2预测模型
- 5.3训练模型
- 6.验证模型
- 7.导出模型
1.收集数据集
随着深度学习技术在计算机视觉领域的广泛应用,行人检测和车辆检测等任务已成为热门研究领域。然而,实际应用中,可用的预训练模型可能并不适用于所有应用场景。
例如,虽然预先训练的模型可以检测出行人,但它无法区分“好人”和“坏人”,因为它没有接受相关的训练。因此,我们需要为自定义检测模型提供足够数量的带有标注信息的图像数据,来训练模型以区分“好人”和“坏人”
1.1 使用开源已标记数据集
使用开源数据集是收集数据的最简便方式之一。例如,ImageNet 是一个大型图像数据库,包含超过 1400 万张图像,可用于深度学习模型的训练。此外,像 COCO 、PASCAL VOC 这样的数据集也经常用于目标检测模型的训练和评估。但是这些数据库中的图像通常来自不同的领域和应用场景,因此可能无法完全满足特定研究的需求。

1.2 爬取网络图像
另一种选择是通过网络搜索图像,并手动选择要下载的图像。然而,由于需要收集大量数据,因此此方法的效率较低。需要注意的是,网络上的图像可能受到版权保护。在使用这些图像之前,务必检查图像的版权信息。
或者,您可以编写一个程序来爬取网络并下载所需的图像。但是这需要对数据进行清洗。以确保数据质量。同样需要注意检查每个图像的版权信息。
1.3 自己拍摄数据集
对于一些特定的应用场景,如自动驾驶和安防监控等,需要收集特定场景下的数据,这时候就需要进行自主拍摄。可以在实际场景中拍摄图像或视频,并对其进行标注,以获得适用于特定场景的高质量数据集。

1.4 使用数据增强生成数据集
我们知道深度学习模型需要大量的数据。当我们只有一个小数据集时,可能不足以训练一个好的模型。在这种情况下,我们可以使用数据增强来生成更多训练数据。
常见的增强方式就是几何变换,类似翻转、裁剪、旋转和平移这些。

1.5 使用算法合成图像
最后一种获取目标检测数据集的方法是使用合成图像。合成图像是通过使用图像处理软件(例如 Photoshop)在图像中添加对象、更改背景或合成多个图像以创建新的图像。这种方法可以提供一些特殊情况或无法通过其他方式获得的图像,但是合成图像通常无法完全代替真实场景的数据,可能会对模型的准确性产生一定的影响
或者我们可以使用生成对抗网络 (GAN )来生成数据集,

值得注意的是,收集训练数据集只是我们训练自定义检测模型的第一步。。。接下来我们要个绍如何标注数据集。当然这一步是假设你的图片已经准备完成。
本次案例使用我个人的 月饼数据集
链接: https://pan.baidu.com/s/1-DwTH6roNDSqW4NyqoA3BQ?pwd=25rt 提取码: 25rt
2.标注数据集
为什么要标注数据集?标注好的数据集有什么作用呢?答:为了让计算机学会正确地识别物体,我们需要提供大量的标注数据集,这些数集包含了图像或视频中物体的位置和类别信标注数据集的作用在干,它可以帮助计算机学习到如何识别不同种类的物体,并且能够正确地定位它们的位置。通过标注数据集我们可以让计算机逐渐学会如何识别和分类不同种类的物体,例如人、车、动物等等。这些数据集可以被用来训练深度学习模型让模型学会如何识别新的图像或视频中的物体。
举个简单例子:比如说,我们想要让计算机自动识别图像中的猫和狗。为了让计算机学会如何识别这两个物体,我们需要提供一些图像样本,并在这些样本上标注猫和狗的位置。如果我们没有标注数据集,计算机就无法学习到如何识别猫和狗。即使我们给计算机提供了大量的图像,它也无法准确地区分这两个物体。但是,如果我们有了标注数据集,计算机就可以通过学习这些数据来理解猫和狗之间的差异,并且可以在新的图像中准确地识别它们。
(当然这个例子指的是监督学习)
2.1确认标注格式
YOLOv8 所用数据集格式与 YOLOv5 YOLOv7 相同,采用格式如下:
<object-class-id> <x> <y> <width> <height>
常用的标注工具有很多,比如LabeLImg 、LabeUMe 、VIA等,但是这些工具都需要安装使用,我这里给大家介绍一款在线标注数据集的工具 Make Sense,打开即用,非常的便捷,在标注之前,我们来看一下一般情况下遵循的标注规则:
1.目标框必须框住整个目标物体,不能有遗漏和重叠。
2.目标框应该与目标物体尽可能接近,但不能与目标物体重合
3.目标框的宽度和高度应该为正数,不能为零或负数。
4.如果一张图片中有多个目标物体,每个目标物体应该用一个独立的目标框进行标注,不允许多个目标共用一个框.
5.如果目标物体的形状不规则,可以使用多个框进行标注,但必须框住整个目标物体。
6.目标框的坐标必须在数据集中统一。
2.2 开始标注
确认好标注格式后我们就可以开始标注了,进入网页后点击 Get started 开始使用。
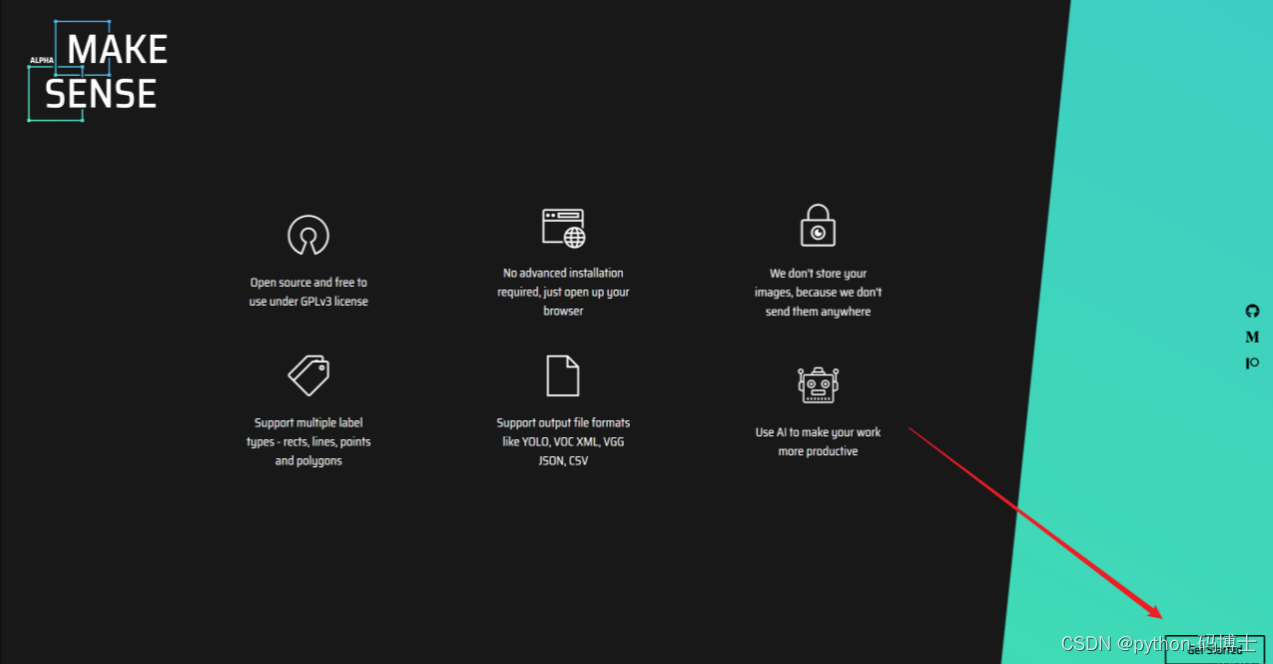
首先点击 Drop images 然后 ctrl+A 选中整个数据集里面的图片。
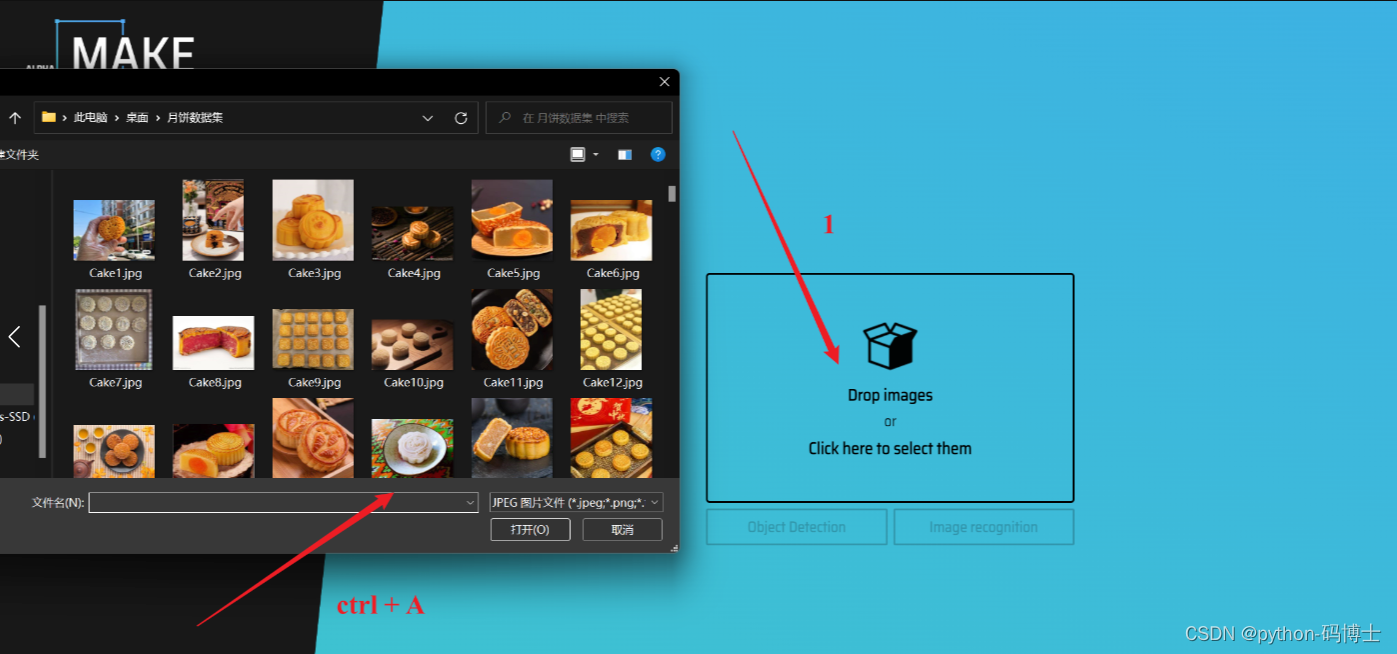
随后添加标签信息,有几类就添加几个,因为我这里只检测月饼一类,所以只添加一个标签 Moon Cake.
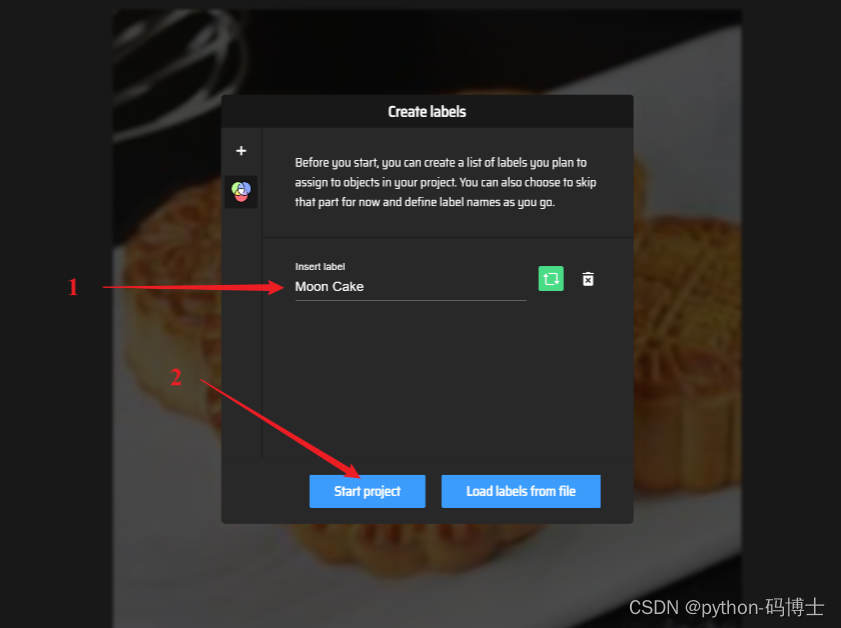
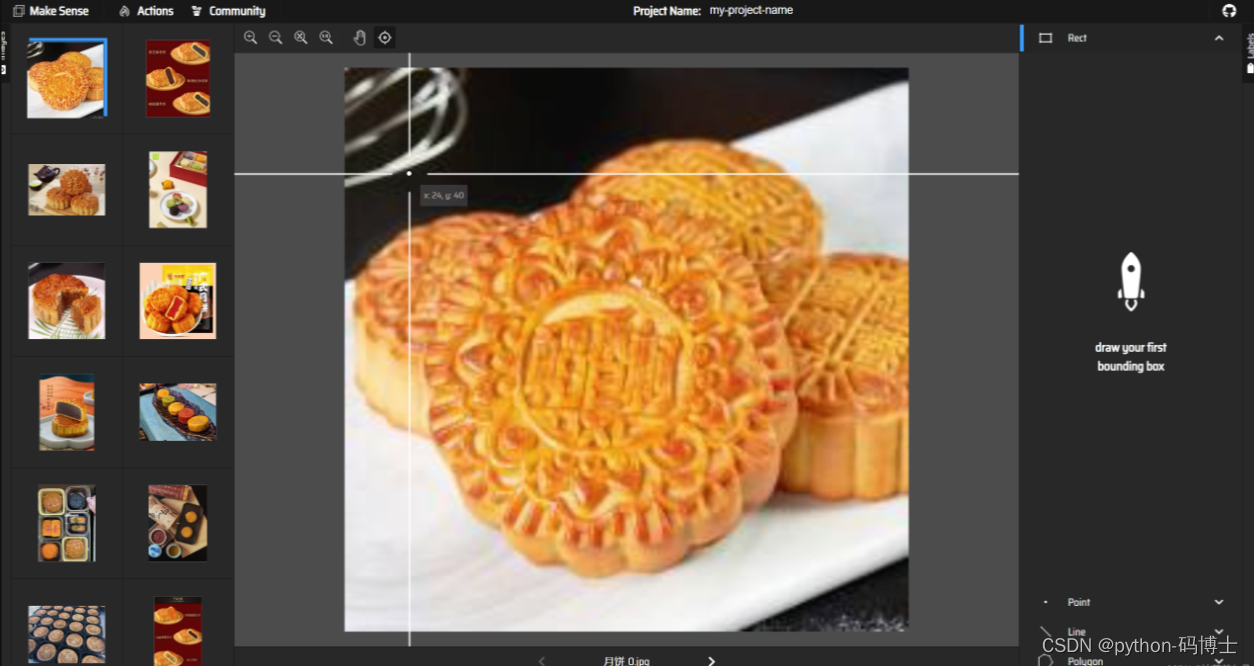
随后就进入了漫长的标注环节,这里大家一定要认真标注,不然对最终模型的影响还是很大的。
标注完成后我们点击 Action -> Export Annotation 导出 yolo 格式的标签文件。
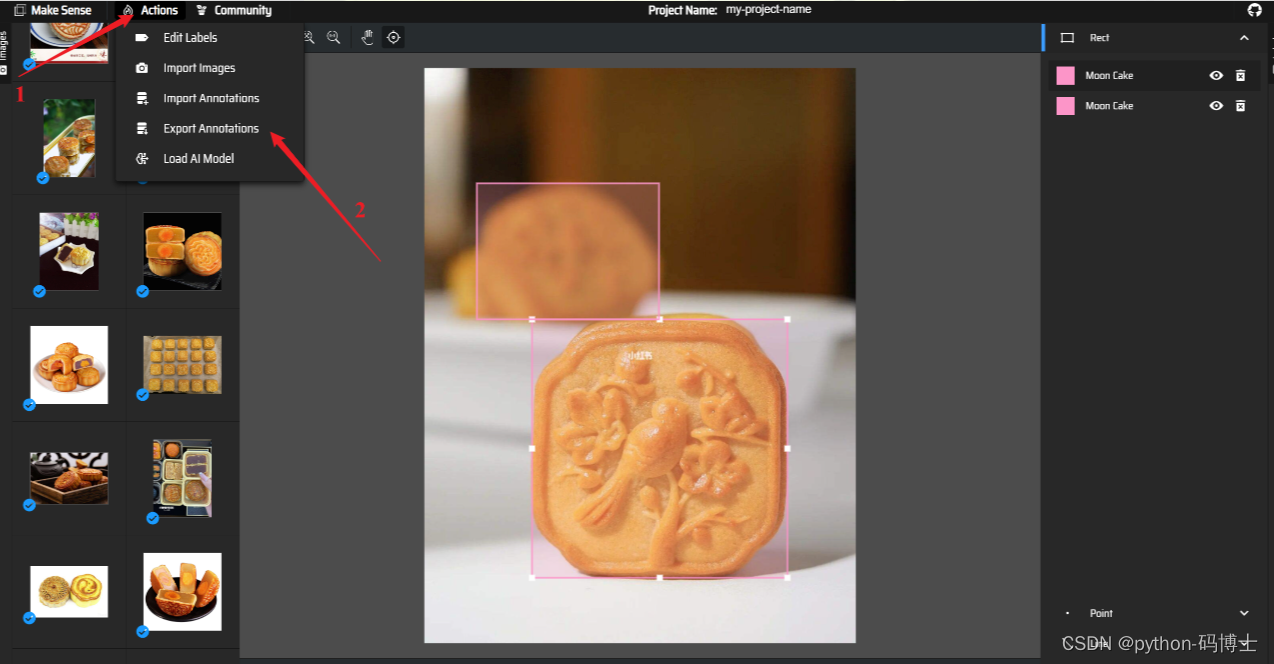
导出之后的标签文件就是这个样子的,我们可以随机抽查几个看看有没有问题。

3.划分数据集
也就是说,我们现在导出后的图片和标签是这个样子的:
Moon_Cake├─images└─all└─labels└─all
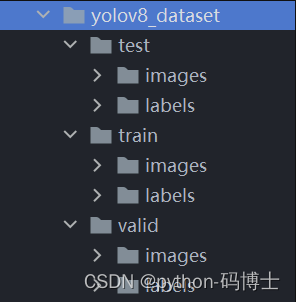
但是 YOLO8 所需要的数据集路径的格式是下面这样子的(YOLOv8 支持不止这一种格式),我们接下来要通过脚本来来划分一下数据集。
├── yolov8_dataset└── train└── images (folder including all training images)└── labels (folder including all training labels)└── test└── images (folder including all testing images)└── labels (folder including all testing labels)└── valid└── images (folder including all testing images)└── labels (folder including all testing labels)具体其实只要修改路径就行了,代码我都做了注释。
import os
import random
import shutildef copy_files(src_dir, dst_dir, filenames, extension):os.makedirs(dst_dir, exist_ok=True)missing_files = 0for filename in filenames:src_path = os.path.join(src_dir, filename + extension)dst_path = os.path.join(dst_dir, filename + extension)# Check if the file exists before copyingif os.path.exists(src_path):shutil.copy(src_path, dst_path)else:print(f"Warning: File not found for {filename}")missing_files += 1return missing_filesdef split_and_copy_dataset(image_dir, label_dir, output_dir, train_ratio=0.7, valid_ratio=0.15, test_ratio=0.15):# 获取所有图像文件的文件名(不包括文件扩展名)image_filenames = [os.path.splitext(f)[0] for f in os.listdir(image_dir)]# 随机打乱文件名列表random.shuffle(image_filenames)# 计算训练集、验证集和测试集的数量total_count = len(image_filenames)train_count = int(total_count * train_ratio)valid_count = int(total_count * valid_ratio)test_count = total_count - train_count - valid_count# 定义输出文件夹路径train_image_dir = os.path.join(output_dir, 'train', 'images')train_label_dir = os.path.join(output_dir, 'train', 'labels')valid_image_dir = os.path.join(output_dir, 'valid', 'images')valid_label_dir = os.path.join(output_dir, 'valid', 'labels')test_image_dir = os.path.join(output_dir, 'test', 'images')test_label_dir = os.path.join(output_dir, 'test', 'labels')# 复制图像和标签文件到对应的文件夹train_missing_files = copy_files(image_dir, train_image_dir, image_filenames[:train_count], '.jpg')train_missing_files += copy_files(label_dir, train_label_dir, image_filenames[:train_count], '.txt')valid_missing_files = copy_files(image_dir, valid_image_dir, image_filenames[train_count:train_count + valid_count], '.jpg')valid_missing_files += copy_files(label_dir, valid_label_dir, image_filenames[train_count:train_count + valid_count], '.txt')test_missing_files = copy_files(image_dir, test_image_dir, image_filenames[train_count + valid_count:], '.jpg')test_missing_files += copy_files(label_dir, test_label_dir, image_filenames[train_count + valid_count:], '.txt')# Print the count of each datasetprint(f"Train dataset count: {train_count}, Missing files: {train_missing_files}")print(f"Validation dataset count: {valid_count}, Missing files: {valid_missing_files}")print(f"Test dataset count: {test_count}, Missing files: {test_missing_files}")# 使用例子
image_dir = 'datasets/coco128/images/train2017'
label_dir = 'datasets/coco128/labels/train2017'
output_dir = './my_dataset'split_and_copy_dataset(image_dir, label_dir, output_dir)
运行完脚本后我们的数据集就会划分成这个格式了,现在数据准备工作就彻底完成了,接下来我们开始着手训练模型。
4.配置训练环境
4.1获取代码
git clone https://github.com/ultralytics/ultralytics
针对网络不好的同学,我这里上传了一份:
链接: https://pan.baidu.com/s/1crFGhcmvik-sZJfXY3ixkw?pwd=xma5 提取码: xma5
4.2安装环境
cd ultralytics
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
5.训练模型
5.1新建一个数据集yaml文件
这个是我新建的,里面写绝对路径 (主要是怕出错):
# moncake
train: D:\Pycharm_Projects\ultralytics\ultralytics\datasets\mooncake\train # train images (relative to 'path') 128 images
val: D:\Pycharm_Projects\ultralytics\ultralytics\datasets\mooncake\valid # val images (relative to 'path') 128 images
test: D:\Pycharm_Projects\ultralytics\ultralytics\datasets\mooncake\test # test images (optional)# Classes
names:0: MoonCake
这个是自带的,里面写相对路径,和我们的写法不同,但是都可以使用,据我所只还有很多种数据集读取方式:
# coco128
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)# Classes
names:0: person1: bicycle2: car''''''79: toothbrush
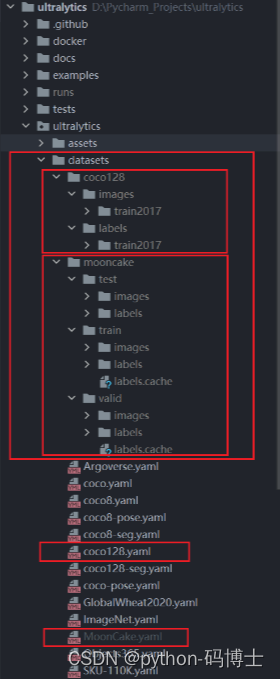
相应的数据集位置就在这里,我们可以和 coco128 对比一下,这两种划分格式都可以的,这里一定要注意路径问题!
5.2预测模型
python 指令推理方式
from ultralytics import YOLO# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom model# Predict with the model
results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
终端中直接键入以下指令就可以实现对图进行推理了,推理后如果不指定文件夹,就会默认保存到 runs/detect/predict下。
yolo task=detect mode=predict model=yolov8n.pt source=data/images device=0 save=True

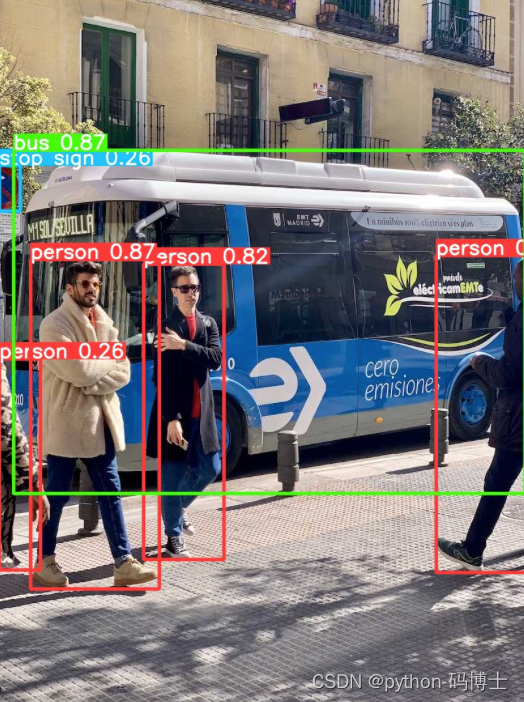
就这张图来说,v8 确实比v5 牛左上角的标志都检测出来了,但是阳台上的自行车还是没检测出来。
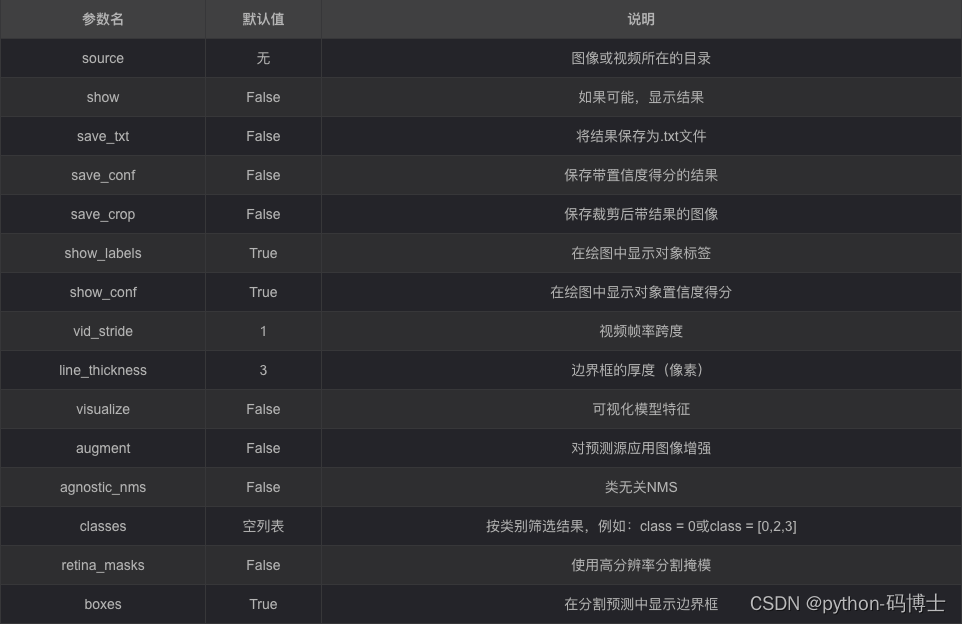
YOLOv8 关于模型的各种参数其实都写到了一起,在ultralytics/yolo/cfg/default.yaml,这些指令我们就可以实现各种我们所需的操作。

5.3训练模型
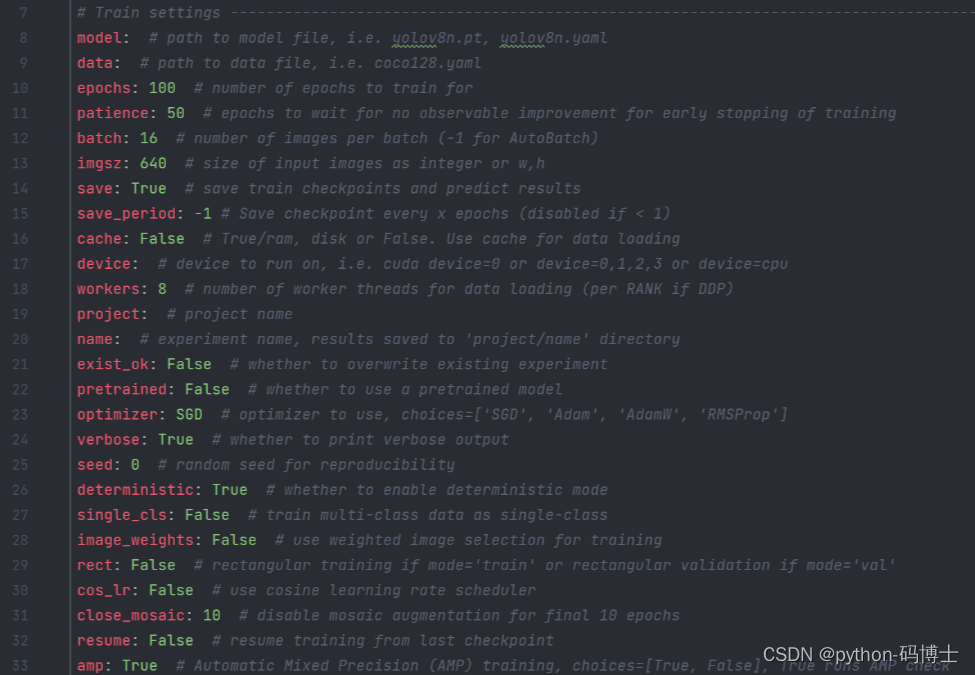
模型训练阶段的原理和预测步骤一致,都可以直接通过命令行搞定,关于这部分参数依然在ultralytics/yolo/cfg/default,yanl中,但我们要训练自己的数据集时记得在 data 参数后指定我们自己的数据集 yamL 文件路径哦。
以下提供两种指令,分别对应了不同的需求。(这里有一点值得注意,我直接写 data=MoonCake.yal 是报错的! 这个涉及到一个坑的问题,没遇到的同学暂且忽略)
python指令训练方式
from ultralytics import YOLO# Load a model
model = YOLO('yolov8n.yaml') # build a new model from YAML
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights# Train the model
model.train(data='coco128.yaml', epochs=100, imgsz=640)
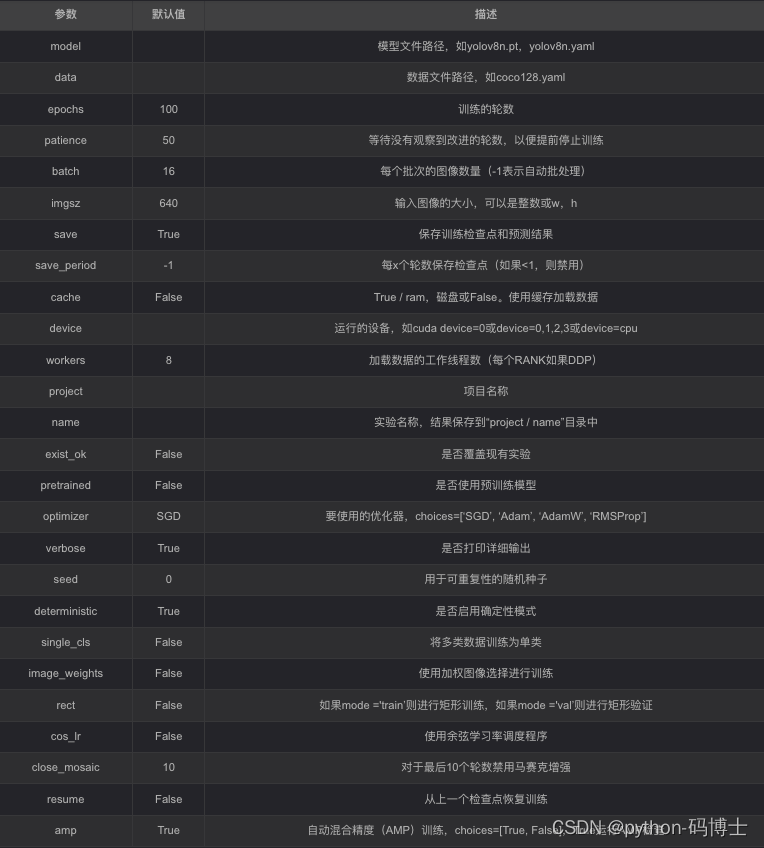
在训练过程中(训练结束后也可以看》我们可以通过 Tensorboard实时查看模型的训练进度,只需要在终端中键入如下的指令,这个在我们每次训练时候都会有提示:
tensorboard --logdir runs\detect\train2
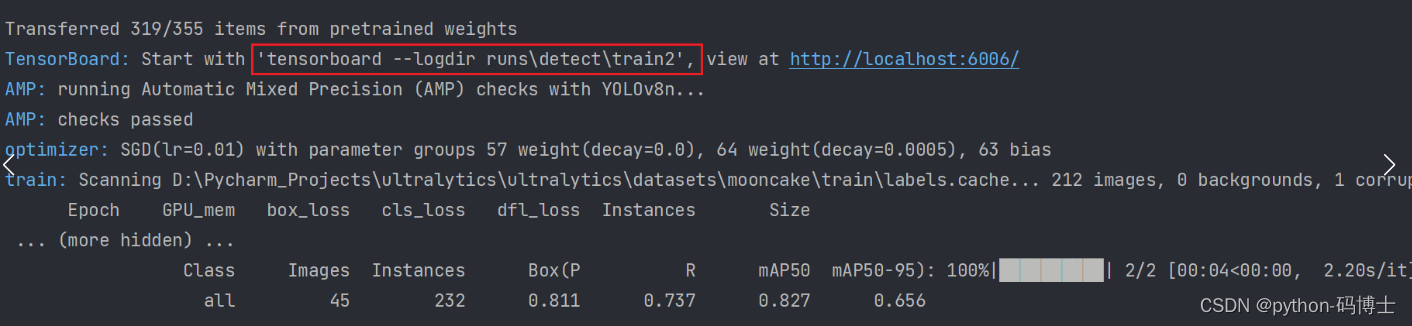
训练结束后我们可以查看得到的一些指标数据:

我这里展示一张 PR 曲线图。
6.验证模型
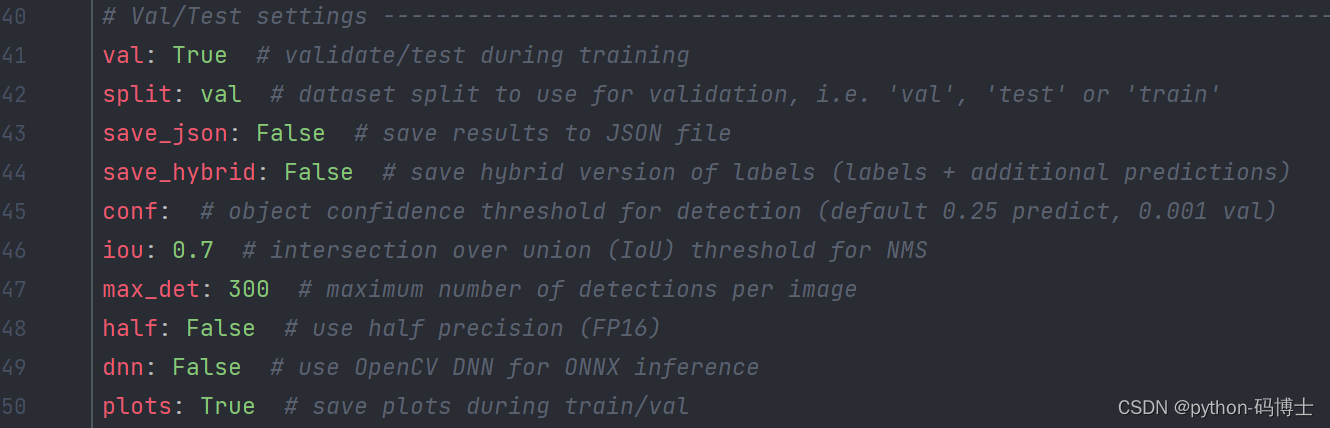
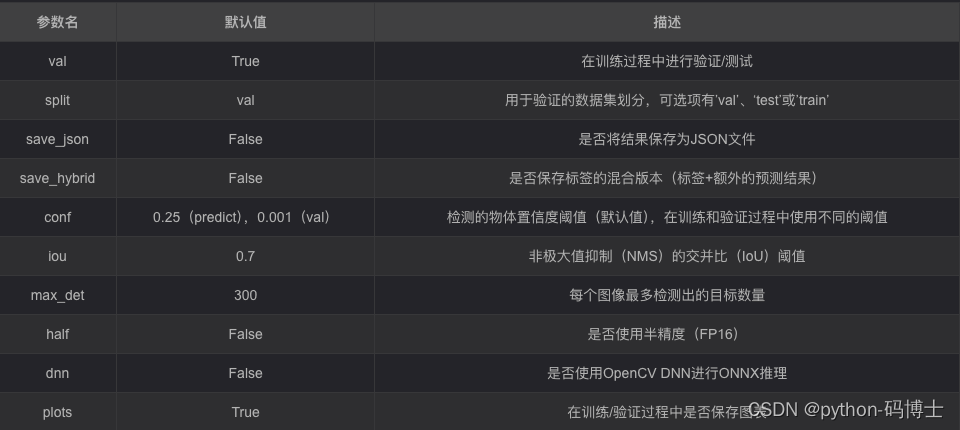
验证模型同样是简单命令行即可实现,如果没有修改中的 ultralytics/yolo/cfg/default,yamL 默认值,同样别忘了指定自己数据集的 yaml ,即 data=ultralytics/datasets/MoonCake.yaml
python 指令验证方式
from ultralytics import YOLO# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom model# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category
同样的,我们验证完后依然可以得到一个文件夹:
我们可以看一下检测效果:

7.导出模型
python指令方式导出
from ultralytics import YOLO# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom trained# Export the model
model.export(format='onnx')
导出有关的具体参数如下:

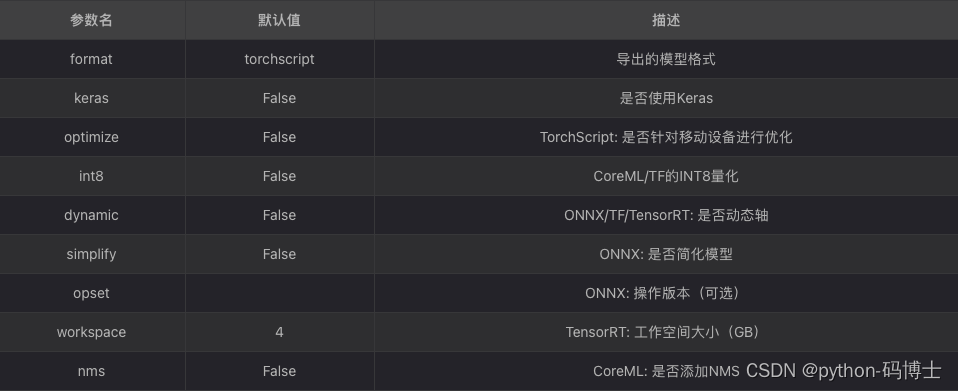
注: TorchScript是PVTorch的模型导出工具。INT8(8位整数量化)是一种量化方法,可将神经网络参数表示为8位整数,以降低存储和计算
成本。ONNX(Open NeuralNetwork Exchange) 是一种跨平台、开放式的机器学习框架。TensorRT是一种用于加速深度学习推理的高性能
引擎。CoreML是苹果公司推出的机器学习框架。Keras是一种流行的深度学习框架。
至此使用 YOLOv8 训练自己的目标检测数据集七大步完结撒花!!!
相关文章:
使用YOLOv8训练自己的【目标检测】数据集
文章目录 1.收集数据集1.1 使用开源已标记数据集1.2 爬取网络图像1.3 自己拍摄数据集1.4 使用数据增强生成数据集1.5 使用算法合成图像 2.标注数据集2.1确认标注格式2.2 开始标注 3.划分数据集4.配置训练环境4.1获取代码4.2安装环境 5.训练模型5.1新建一个数据集yaml文件5.2预测…...
)
rust学习(recursive mutex 实现)
问题: 编写如下代码的时候出现死锁: pub fn test_double_lock() {let t Arc::new(Mutex::new(1));let t1 t.clone();let t2 t.clone();let h std::thread::spawn(move || {println!("hello trace1");let l1 t1.lock().unwrap();println…...

DasViewer可以添加照片到里面吗?点开就可以看照片?
DasViewer主要是三维模型浏览器,二维可以添加矢量和正射影像,航片暂不支持。 DasViewer是由大势智慧自主研发的免费的实景三维模型浏览器,采用多细节层次模型逐步自适应加载技术,让用户在极低的电脑配置下,也能流畅的加载较大规模实景三维模型,提供方便…...

python蓝桥杯选数
文章目录 前言一、题意二、代码1.代码的实现2.读入数据 总结 前言 本题涉及到很多python中的知识点,比如combinations(列表的组合)应用,以及素数的判断 一、题意 已知 n 个整数 x1,x2,…,xn,以及一个整数 k(k&#x…...
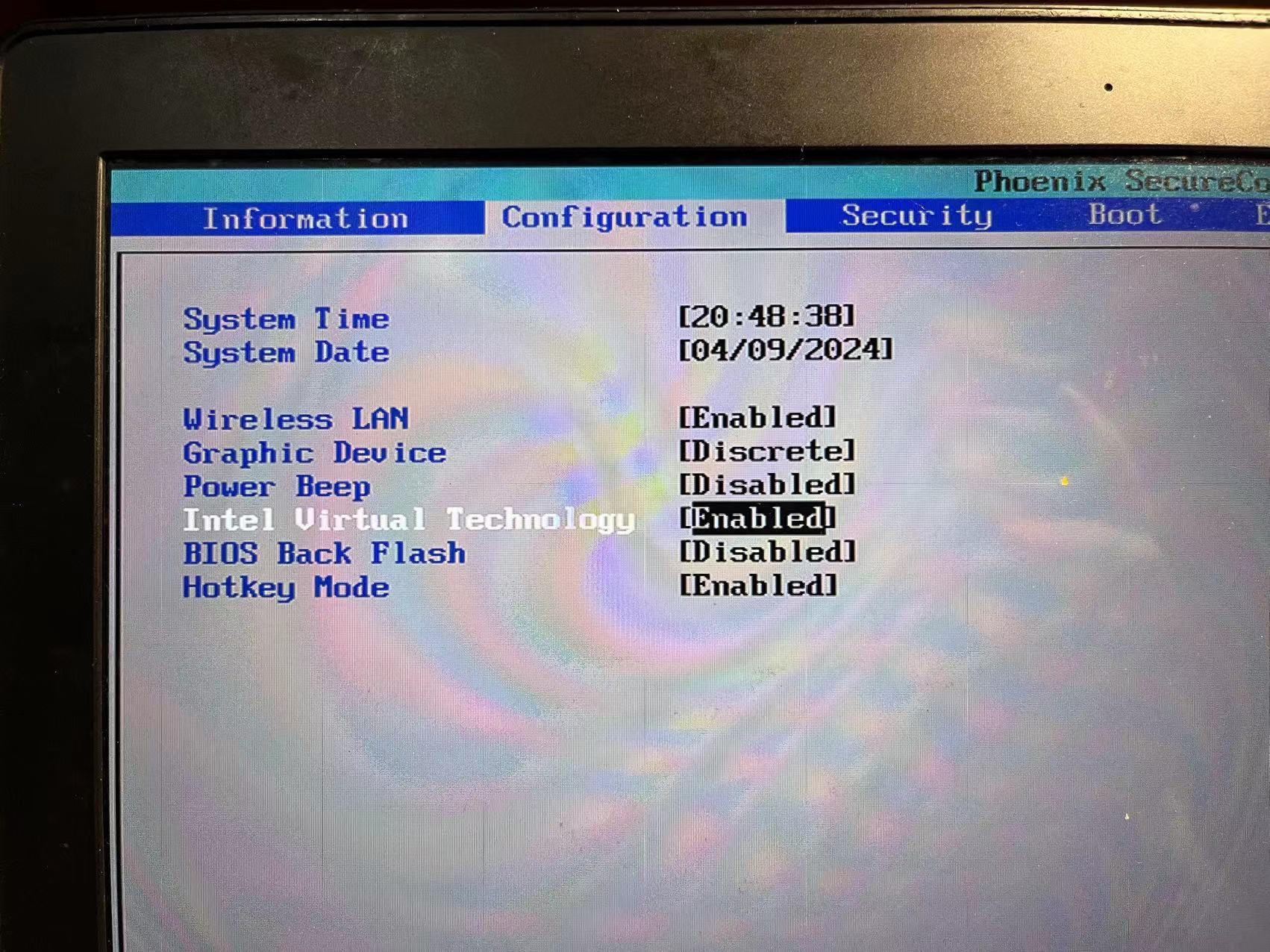
联想电脑开启虚拟化失败,开启虚拟化却提示还没有开启虚拟化
安装虚拟机的时候, 电脑要开启虚拟化, Intel VT, 去BIOS开启了, 但是依然报错,说虚拟化处于禁用状态。 解决方案: 去联想官方,下载BIOS更新包,更新BIOS。 更新文档: 联…...

物联网农业四情在线监测系统
TH-Q2随着科技的飞速发展和信息化时代的来临,物联网技术在各个领域都取得了显著的应用成果。其中,物联网农业四情在线监测系统作为农业现代化的重要组成部分,正在为农业生产带来革命性的变革。 一、物联网农业四情在线监测系统的概念 物联网…...
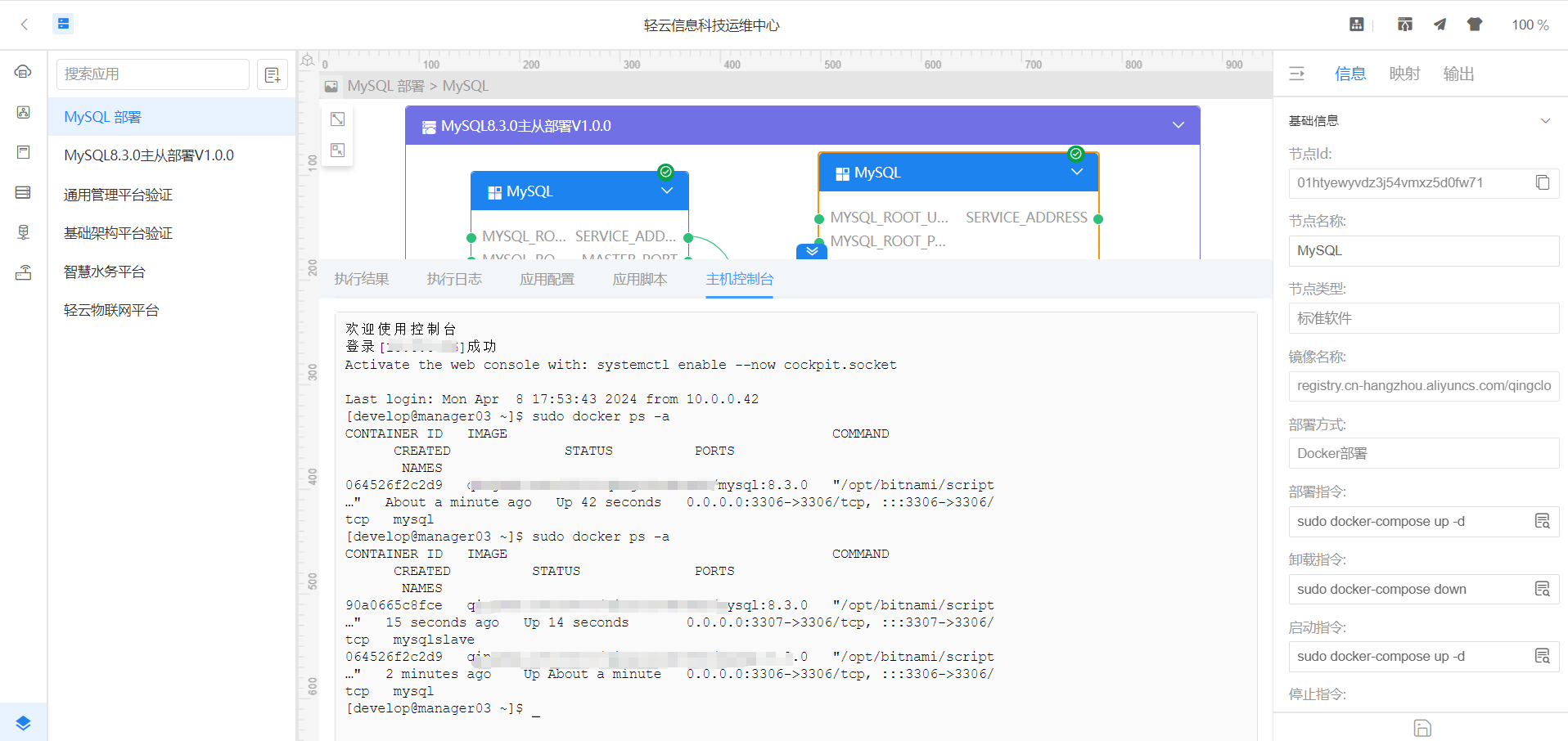
MySQL8.3.0 主从复制方案(master/slave)
一 、什么是MySQL主从 MySQL主从(Master-Slave)复制是一种数据复制机制,用于将一个MySQL数据库服务器(主服务器)的数据复制到其他一个或多个MySQL数据库服务器(从服务器)。这种复制机制可以提供…...
大数据相关组件安装及使用
自学大数据相关组件 持续更新中。。。 一、linux安装docker 1、更新yum sudo yum update2、卸载docker旧版本 sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine3、…...

【攻防世界】web2(逆向解密)
进入题目环境,查看页面信息: <?php $miwen"a1zLbgQsCESEIqRLwuQAyMwLyq2L5VwBxqGA3RQAyumZ0tmMvSGM2ZwB4tws";function encode($str){$_ostrrev($str);// echo $_o;for($_00;$_0<strlen($_o);$_0){$_csubstr($_o,$_0,1);$__ord($_c)1;…...

Linux文件查找命令详解——以CentOS为例
Linux文件查找命令详解——以CentOS为例 在Linux系统中,文件查找是一项非常重要的任务。无论是系统管理员还是普通用户,都需要掌握一些基本的文件查找命令。本文将详细介绍Linux中常用的文件查找命令,并以CentOS为例,展示如何使用…...

【JavaEE】浅谈线程(一)
线程 前言线程的由来线程是什么线程的属性线程更高效的原因举个例子(线程便利性的体现) 多线程代码线程并发执行的代码jconsole(观测多线程) 线程的调度问题创建线程的几种方法1)通过继承Thread 重写run2)使用Runnable接口 重写ru…...

深度解析SPARK的基本概念
关联阅读博客文章: 深入理解MapReduce:从Map到Reduce的工作原理解析 引言: 在当今大数据时代,数据处理和分析成为了企业发展的重要驱动力。Apache Spark作为一个快速、通用的大数据处理引擎,受到了广泛的关注和应用。…...
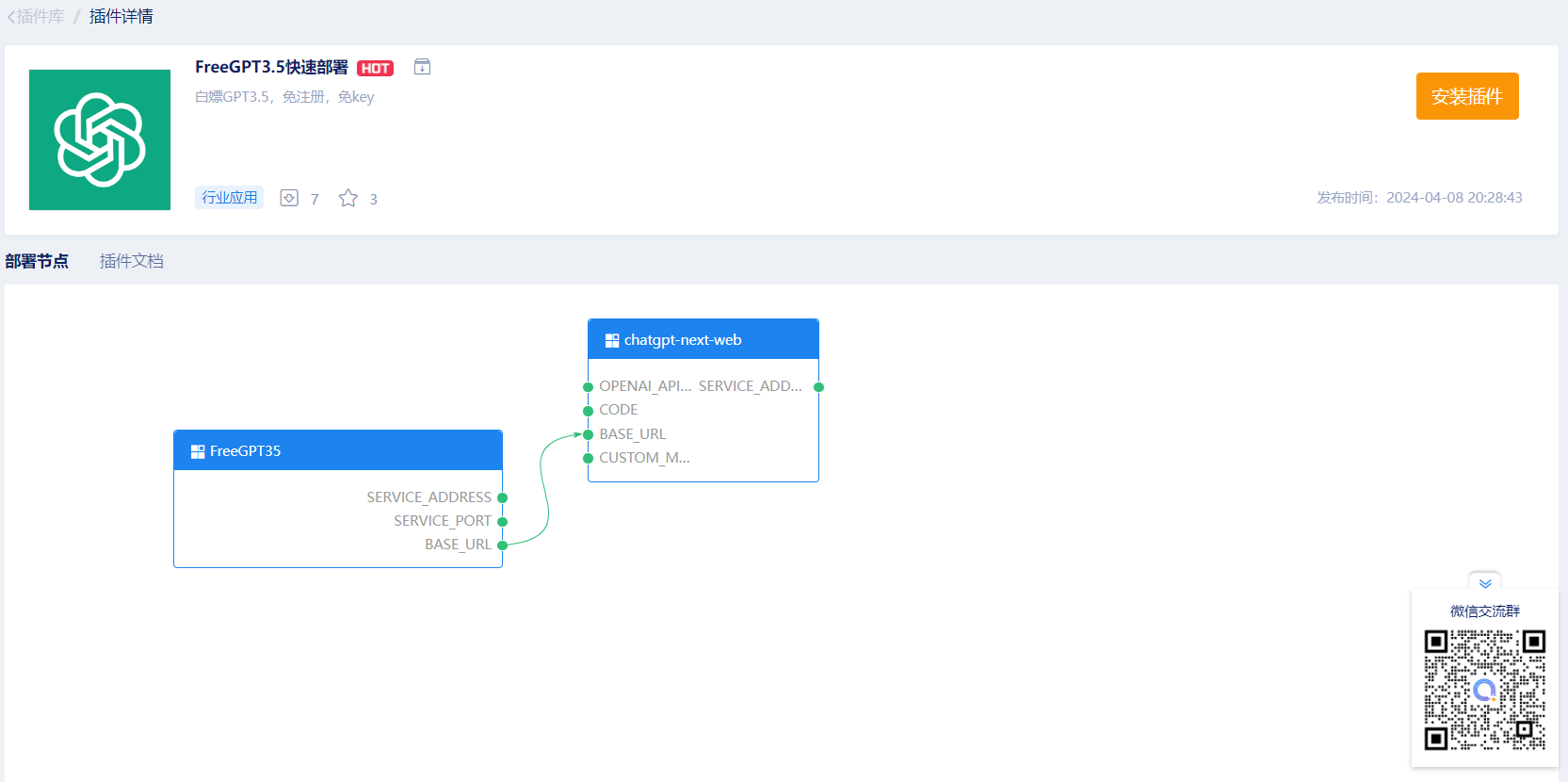
FreeGPT3.5 开源软件
GPT-3.5不需要付费,也不需要注册用户,可以直接使用了,官方彻底开放了API接口。 该API政策一放开,GitHub很快就已经出现了一个开源项目FreeGPT35,可以自动生成key调用GPT3.5的API接口,再也用不着注册账号和申…...

AI绘本生成解决方案,快速生成高质量的AI绘本视频
美摄科技凭借其深厚的技术积累和前瞻性的市场洞察力,近日推出了一款面向企业的AI绘本生成解决方案,旨在通过智能化、自动化的方式,帮助企业快速将文字内容转化为生动有趣的绘本视频,从而提升内容传播效率,增强品牌影响…...
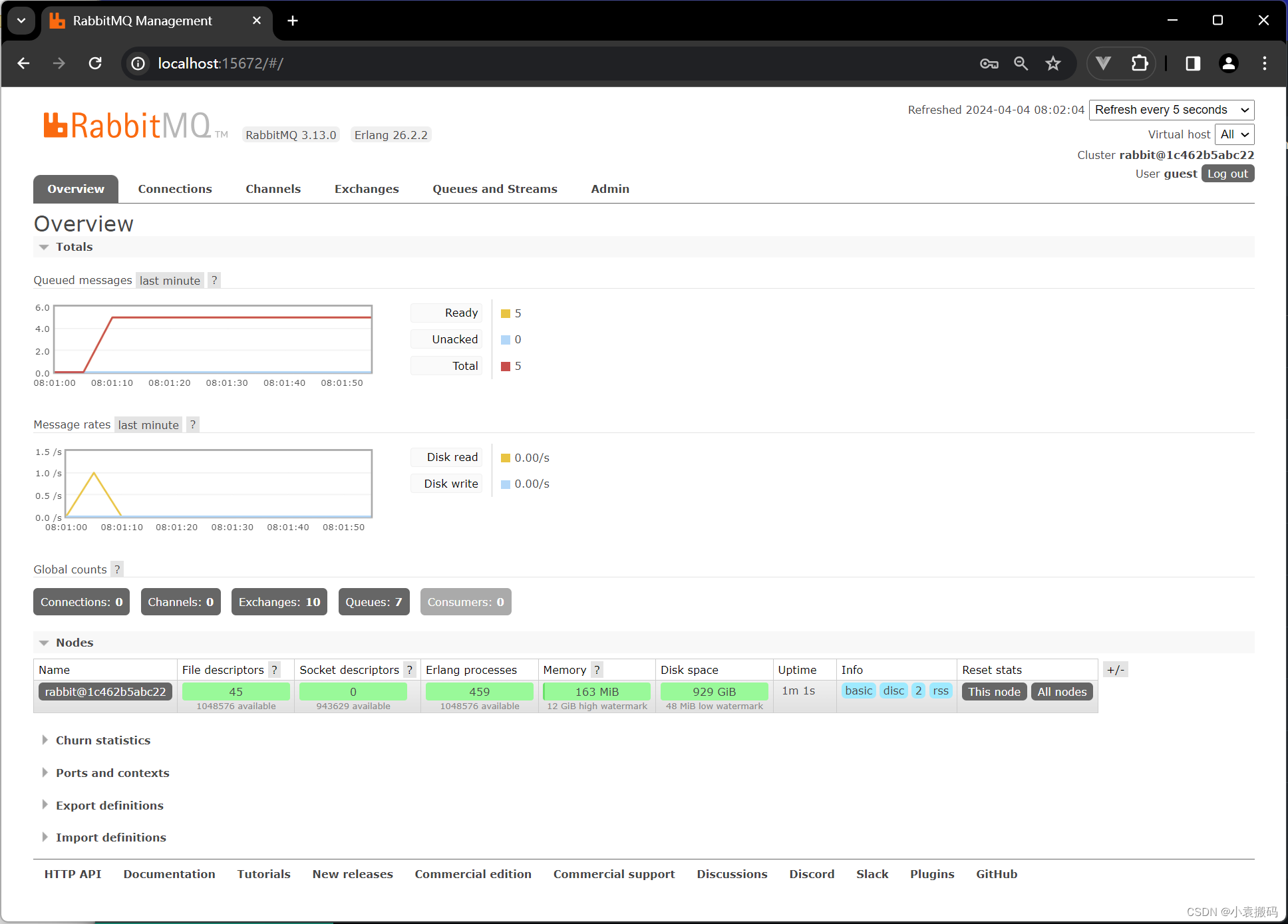
RabbitMQ3.13.x之九_Docker中安装RabbitMQ
RabbitMQ3.13.x之_Docker中安装RabbitMQ 文章目录 RabbitMQ3.13.x之_Docker中安装RabbitMQ1. 官网2. 安装1 .拉取镜像2. 运行容器 3. 访问 1. 官网 rabbitmq - Official Image | Docker Hub 2. 安装 1 .拉取镜像 docker pull rabbitmq:3.13.0-management2. 运行容器 # lates…...
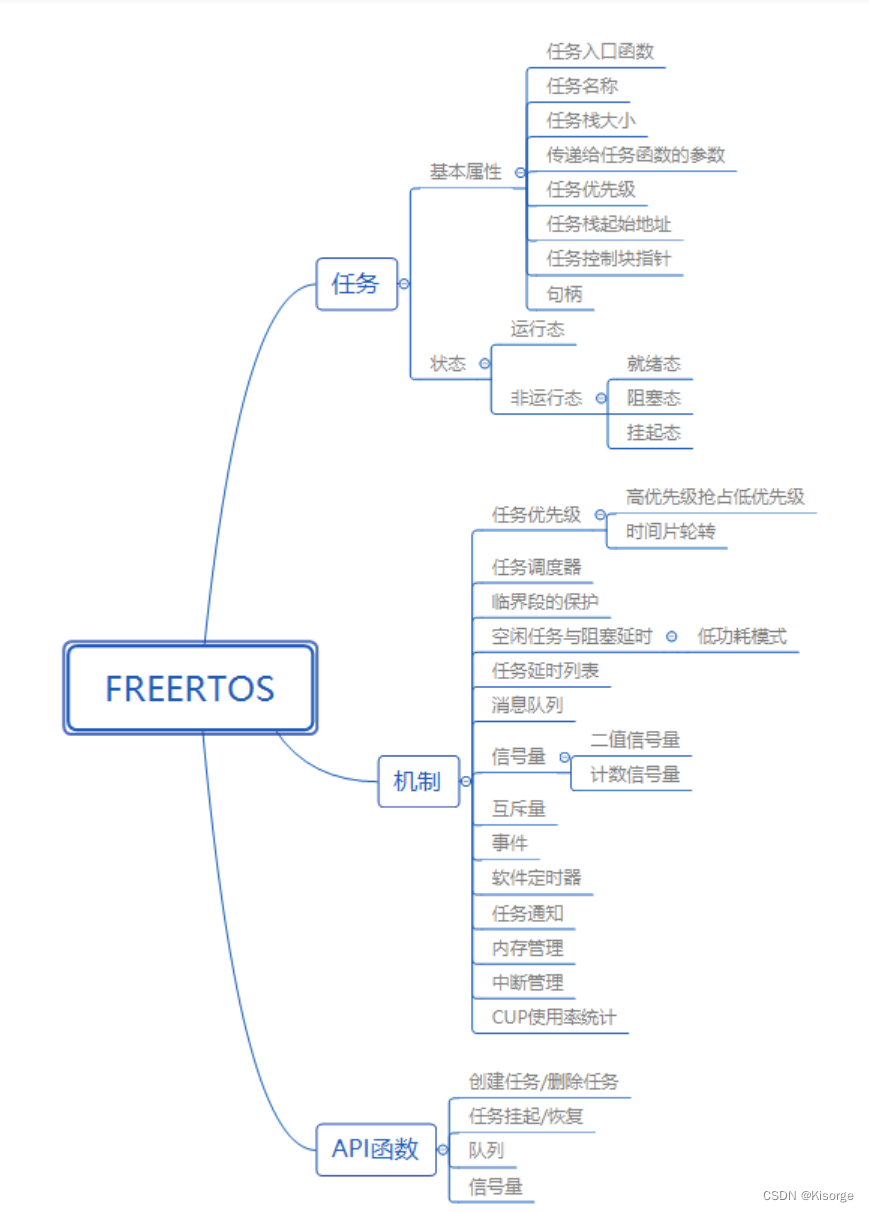
【操作系统】STM32-操作系统——持续更新
【操作系统】STM32-操作系统——持续更新 文章目录 前言一、ucosii二、freertos1.介绍2.移植 总结 前言 提示:以下是本篇文章正文内容,下面案例可供参考 一、ucosii UCOSII移植到STM32F103C8T6上之移植记录(一) UCOSII移植到ST…...
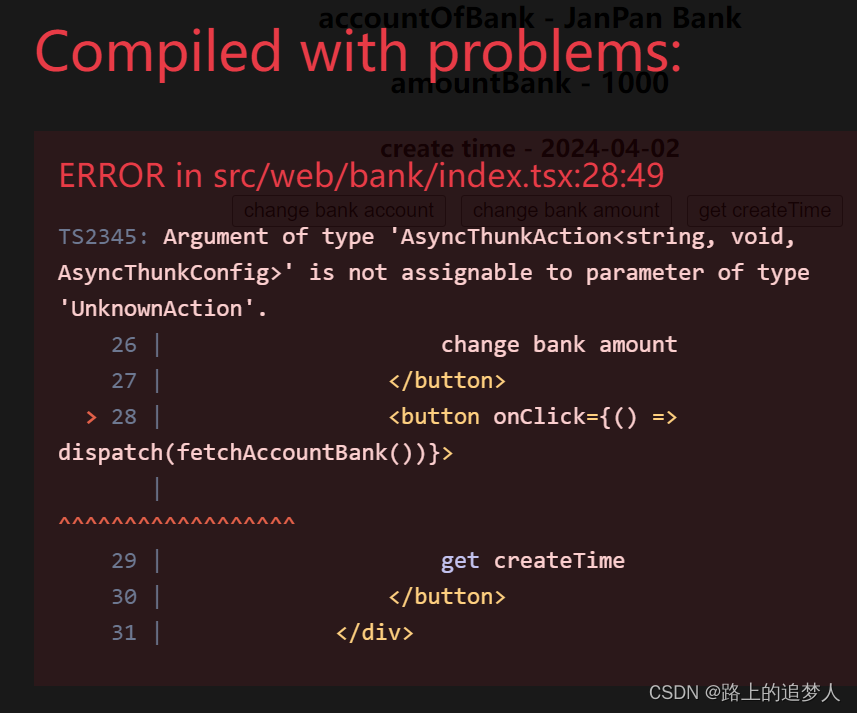
Redux Toolkit+TypeScript最佳实践
Redux-Toolkit是为了简化使用Redux繁琐的步骤,可以j降低使用useReducer与useContext管理状态的频率,而且起到项目中状态管理规范和约束化的效果。 阅读本文需要的前置知识:React、Redux、Typescript、Redux hooks。 Redux-Toolkit使用步骤 …...
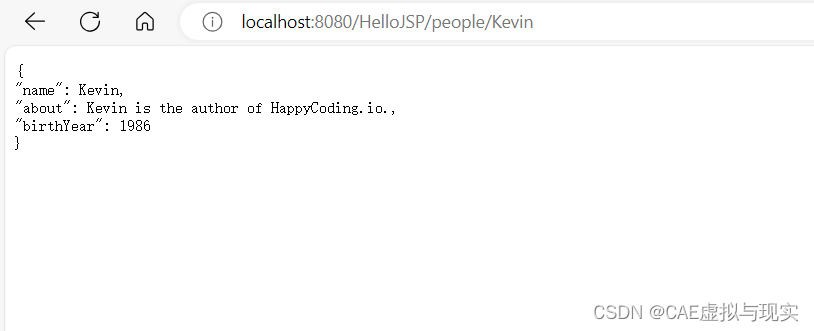
假期别闲着:REST API实战演练之创建Rest API
1、创建实体类,模拟实体对象 创建一个类,模拟数据数据库来存储数据,这个类就叫Person。 其代码如下: package com.restful;public class Person {private String name;private String about;private int birthYear;public Perso…...
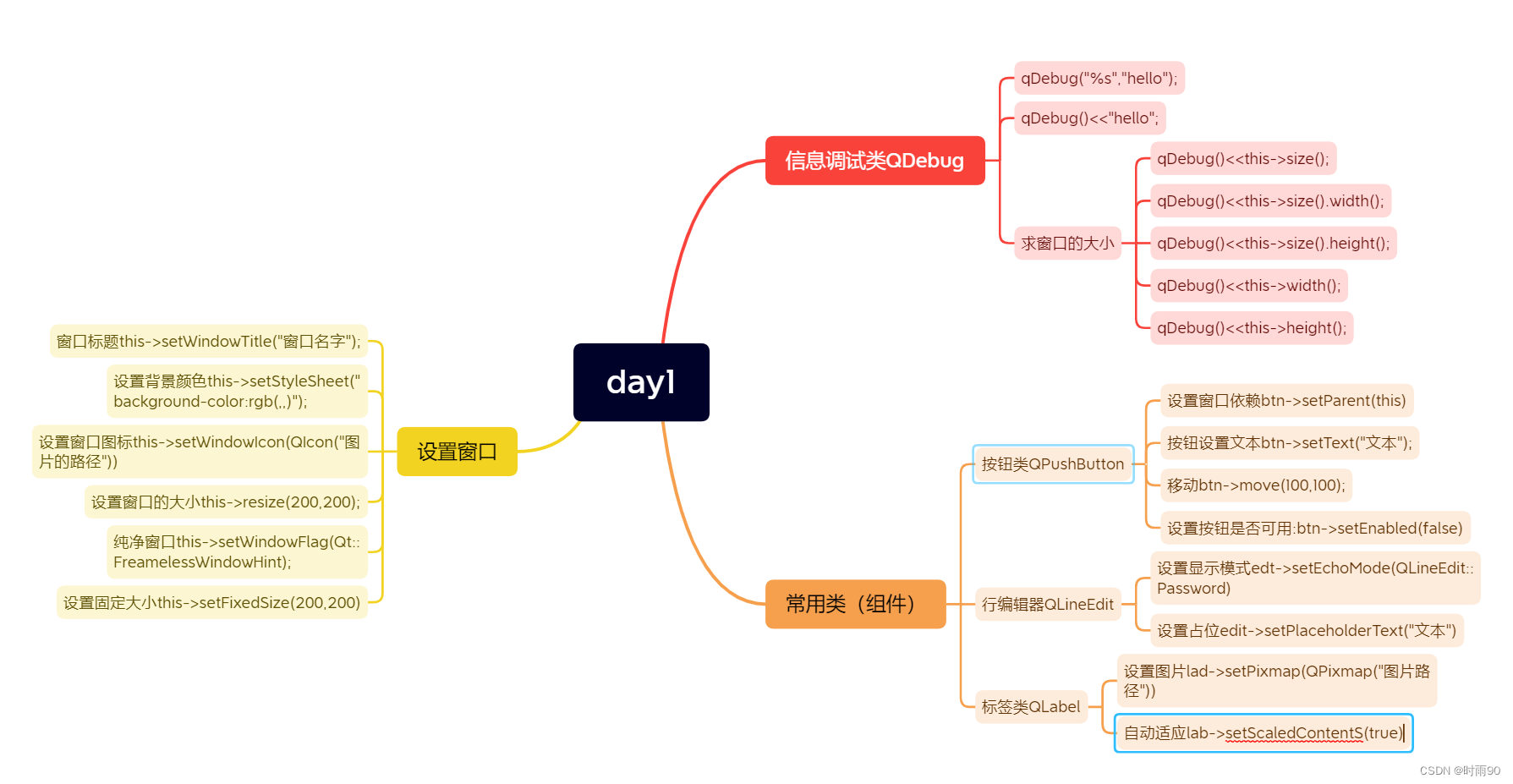
C++模仿qq界面
#include "mywidget.h"MyWidget::MyWidget(QWidget *parent): QWidget(parent) {//设置窗口的大小this->resize(645,497);//设置窗口名字this->setWindowTitle("QQ");//设置窗口图标this->setWindowIcon(QIcon("C:\\zhouzhouMyfile\\qt_proj…...

3D模型在线轻量化工具
在计算机图形学领域,3D模型简化工具是一种强大的工具,用于减少模型的面数,以提高模型在渲染和处理过程中的性能。本文将全面介绍为何需要简化模型、简化的方法、常见的简化算法以及一款三维模型优化产品 的使用方法,帮助读者更好地…...

多智能体系统架构设计:从核心原理到AgentOrg工程实践
1. 项目概述:从“AgentOrg”看智能体组织架构的工程实践最近在开源社区里看到一个挺有意思的项目,叫“Angelopvtac/AgentOrg”。光看这个名字,可能有点抽象,但如果你正在捣鼓大语言模型应用,尤其是想构建一个能协同工作…...

MCP服务器生产级部署:从Docker到Kubernetes的完整工程化实践
1. 项目概述:一个为MCP服务器量身定制的部署蓝图如果你正在开发或使用一个基于模型上下文协议(Model Context Protocol, MCP)的服务器,并且为如何将其优雅、可靠地部署到生产环境而头疼,那么你很可能需要的…...

Linux系统信息查询全攻略:从内核到发行版的深度解析与脚本实践
1. 项目概述:一个看似简单却暗藏玄机的基础操作“查看Linux系统版本”,这几乎是每个运维工程师、开发人员乃至普通用户在接触Linux系统时,第一个需要掌握的命令。它简单到常常被新手教程一笔带过,却又复杂到足以让老手在排查问题时…...

零售行业 Multi-Agent 案例:智能导购与库存管理的协同系统拆解
零售行业 Multi-Agent 案例:智能导购与库存管理的协同系统拆解 摘要/引言 开门见山 “叮咚——您的专属导购Luna上线啦!请问今天想找什么风格的连衣裙?要不要看看系统为您推荐的通勤款A字裙,您上周收藏的碎花衫刚好可以搭配&#…...

别再只怪USB线了!i.MX6Q用Mfgtools烧录rootfs.tar.bz2报错的深层硬件排查指南
i.MX6Q烧录故障的硬件级诊断:从USB OTG冲突到电源完整性排查 当Mfgtools在rootfs.tar.bz2传输阶段突然报错"Push error"或"No Device Connected"时,多数开发者会本能地检查USB线缆或驱动配置。但真正棘手的故障往往潜伏在硬件交互层…...

解放你的文档下载焦虑:一键保存30+平台内容的神器
解放你的文档下载焦虑:一键保存30平台内容的神器 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为了解决您…...

基于RP2040 PIO与CircuitPython的IBM Model F键盘USB转接方案
1. 项目概述:让经典IBM键盘在现代电脑上重生如果你和我一样,对老式机械键盘那种扎实、清脆的“咔嗒”声和独特手感念念不忘,同时又对它们无法直接插在现代电脑上感到惋惜,那么这个项目就是为你准备的。我最近从朋友的一堆旧物里淘…...

【职场】职场中你可以坚强,但不必逞强
职场中你可以坚强,但不必逞强 ——写给那些咬牙撑着、却不知道为什么要撑的人我见过太多这样的人。 凌晨两点还在改PPT,眼睛里布满血丝,手边的咖啡已经凉了。有人问他"还好吗",他抬起头,挤出一个笑ÿ…...
GalTransl代码架构分析:理解多进程插件系统的设计原理
GalTransl代码架构分析:理解多进程插件系统的设计原理 【免费下载链接】GalTransl 支持GPT-4/Claude/Deepseek/Sakura等大语言模型的Galgame自动化翻译解决方案 Automated translation solution for visual novels supporting GPT-4/Claude/Deepseek/Sakura 项目地…...

从MHC到MCC:PIC32项目迁移实战指南与问题排查
1. 项目概述:从MHC到MCC的迁移之路如果你是一位长期使用Microchip PIC32系列微控制器的嵌入式开发者,那么“MPLAB Harmony配置器(MHC)”这个名字你一定不陌生。它曾经是Harmony框架下图形化配置工具的核心,帮助我们快速…...