[通俗易懂]《动手学强化学习》学习笔记1-第1章 初探强化学习
文章目录
- 前言
- 第1章 初探强化学习
- 1.1 简介
- 序贯决策(sequential decision making)任务:
- 强化学习与有监督学习或无监督学习的**区别**:改变未来
- 1.2 什么是强化学习
- 环境交互
- 与有监督学习的区别1:改变环境 (说法和1.1相当)
- 智能体(agent)的3个关键要素
- 为什么让agent动作随机呢?
- 与有监督学习的区别2:
- 1.3强化学习的环境
- 状态转移(State transition)
- 强化学习中的随机性
- 与有监督学习的区别3
- 1.4 强化学习的目标
- 回报(return)
- 价值(value)
- 关于价值计算
- 与有监督学习的区别4 与相似1
- 1.5 强化学习中的数据
- 与有监督学习的区别5
- 状态动作对(state-action pair)
- 占用度量(occupancy measure)
- 强化学习本质的思维方式
- 1.6 强化学习的独特性
- 总结 与有监督学习的异同
- 1.7 小结
- 视频补充:
- 历史、状态
- 策略
- 价值函数
- 模型
- 迷宫问题
- 强化学习智能体分类(模型上)
- 强化学习智能体分类(价值、策略上)
前言
参考:
《动手学强化学习》作者:张伟楠,沈键,俞勇
动手学强化学习 网页版
动手学强化学习 github代码
动手学强化学习 视频
强化学习入门这一篇就够了!!!万字长文(讲的很好)
我做出的决策:选择了强化学习作为研究方向。
强化学习是人工智能的未来。未来智能系统需要能够在不接受持续监督的情况下自主学习,而强化学习正是其中的最佳代表之一。
第1章 初探强化学习
1.1 简介
我们知道,机器学习分为无监督学习,(有)监督学习,强化学习,迁移学习和深度学习等。(各有说法)
无监督学习分析数据流,发现模式并做出预测,无需任何其他指导。
解决聚类问题
(有)监督学习要求人类首先标记输入数据,主要有两种类型:分类(程序必须学会预测输入属于哪个类别)和回归(程序必须根据数字输入推导出数值函数)。解决分类和回归问题
在强化学习中,智能体因良好的反应而得到奖励,因不良的反应而受到惩罚。智能体学会选择被归类为“良好”的响应。解决决策问题
迁移学习是指将从一个问题中获得的知识应用于一个新问题。
深度学习是一种机器学习,它通过受生物启发的人工神经网络为所有这些类型的学习运行输入。
在机器学习领域,有一类重要的任务和人生选择很相似,即序贯决策(sequential decision making)任务。决策和预测任务不同,决策往往会带来“后果”,因此决策者需要为未来负责,在未来的时间点做出进一步的决策。实现序贯决策的机器学习方法就是本书讨论的主题—强化学习(reinforcement learning)。----《动手学强化学习》
序贯决策(sequential decision making)任务:
参考:序贯决策的理解
马尔可夫决策过程(MDP)wiki
马尔可夫博弈(随机博弈)wiki
序贯决策(Sequential Decision Making)是指在一定的时间顺序下,根据系统的当前状态和预测的未来状态,进行一系列决策的过程。这种决策方式通常用于随机性或不确定性的动态系统中,以实现最优化的目标。
在序贯决策任务中,决策代理(decision agent)(也叫决策智能体)会与一个离散时间的动态系统进行交互。在每个时间步骤开始时,系统会处于某种状态。代理(智能体)根据其决策规则观察当前状态,并从有限的行动集中选择一个行动。然后,动态系统根据这个行动进入下一个新的状态,并获得相应的收益。这个过程循环进行,目的是选择一组行动来最大化总收益。
例:
第一个t 开始
->状态1 (收益=0)
->决策(根据决策规则和此时状态1进行行动)
第二个t 开始
->状态2 (收益+=奖励)
->决策
->… (最大化收益)
序贯决策任务广泛应用于多个领域,如物流配送车辆调度、家电产品运营、应急资源配置等情况。在这些应用中,序贯决策方法可以大大减少计算量,并且能够为动态系统提供一系列平均收益最大化的方案。
此外,序贯决策任务也与强化学习紧密相关。强化学习是一种机器学习方法,它可以解决序贯决策问题,特别是在马尔可夫决策过程(MDP)中。在强化学习中,代理通过与环境的交互来学习如何选择行动,以最大化某种累积奖励。
强化学习与有监督学习或无监督学习的区别:改变未来
预测仅仅产生一个针对输入数据的信号,并期望它和未来可观测到的信号一致,这不会使未来情况发生任何改变。(有监督学习或无监督学习)
而决策则会使未来情况发生改变。(强化学习)
个人拙见:
有监督学习:主要的蕴含的基本算法思想是梯度下降法,来构造一个模型,进行预测。
强化学习:主要的蕴含的基本算法思想是动态规划,有一个智能体,进行决策。(wiki:MDP 可用于研究通过动态规划解决的优化问题)
1.2 什么是强化学习
智能体(agent):决策的机器
强化学习:是机器通过与环境交互来实现目标的一种计算方法。
环境交互
智能体和环境之间具体的交互方式:
在每一轮交互中,智能体感知到环境目前所处的状态,经过自身的计算给出本轮的动作,将其作用到环境中;环境得到智能体的动作后,产生相应的即时奖励信号并发生相应的状态转移。智能体则在下一轮交互中感知到新的环境状态,依次类推。–《动》
例:(与上文 序列决策任务类似)
第一轮交互
->状态1 (收益=0)
->决策(根据决策规则和此时状态1进行行动)
第二轮交互
->状态2 (收益+=奖励)
->决策
->… (最大化收益)
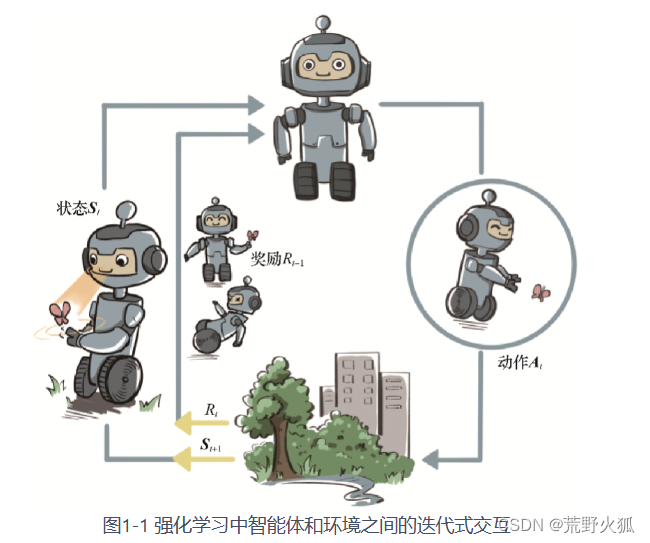
《动》中图,可以这样来看,智能体(此时状态:Si,奖励:Ri-1)先通过动作Ai改变了环境,进而智能体(此时状态:Si+1,奖励:Ri)
类似的,马里奥游戏中的环境交互:

下面这张图比较详细
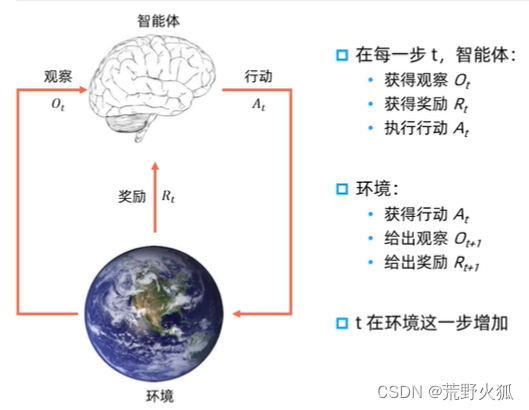
与有监督学习的区别1:改变环境 (说法和1.1相当)
相比于有监督学习中的“模型”,强化学习中的“智能体”强调机器不但可以感知周围的环境信息,还可以通过做决策来直接改变这个环境,而不只是给出一些预测信号。–《动》
有监督学习:(模型为预测模型)
例:第一个epoch(迭代)
-> 随机模型参数 (参数=0)
-> 计算损失值 (loss= loss1)
第二个epoch(迭代)
-> 更新模型参数 (根据评判模型标准损失函数,进行更新)
->计算损失值 (loss+=loss2)
-> …(最小化损失值)
智能体(agent)的3个关键要素
(也有说是4个要素:状态(state),行动/动作(action),决策(policy),奖励(reward))
1、感知(状态):现在自己所处的状态。(可以说这一帧为现在的状态,如下状态图)
状态图如下:

2、决策(决策+动作):
决策:有点相当于有监督学习中要学习的模型函数(例:y = kx+b),这里我们不妨称为要学习的决策函数。
与常见的模型函数中运用到的线性函数,非线性函数不同,决策函数用到的是概率密度函数。
参考:如何通俗的理解概率密度函数?
概率密度函数(Probability Density Function, PDF)):是用于描述连续型随机变量在某个确定值附近的可能性的函数。它是一个非负函数,通常表示为 ( f(x) ),并且满足以下两个条件:
1.非负性,f(x)>=0。(概率为正)
2.归一性,f(x)在整个定义域上的从负无穷到正无穷的积分面积为1。(因为我们要保证总的概率为1)
例如,随机变量 ( X ) 在区间 ( [a, b] ) 上的概率是:
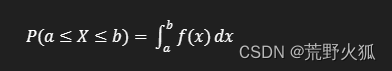
例子:
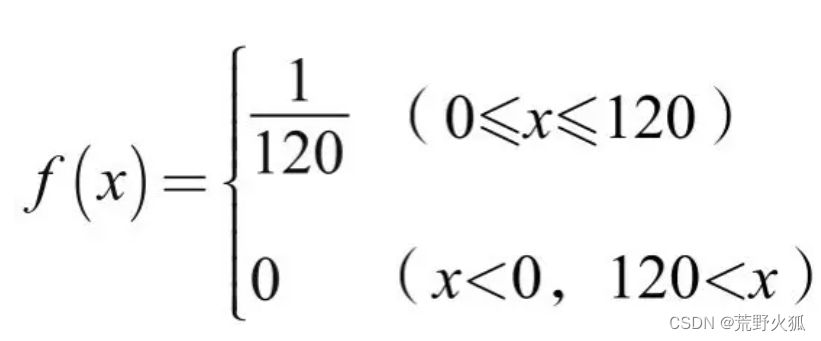
动作:根据决策函数可能做出的动作。
(如下图,动作为左,右,上)
假设情景如下:
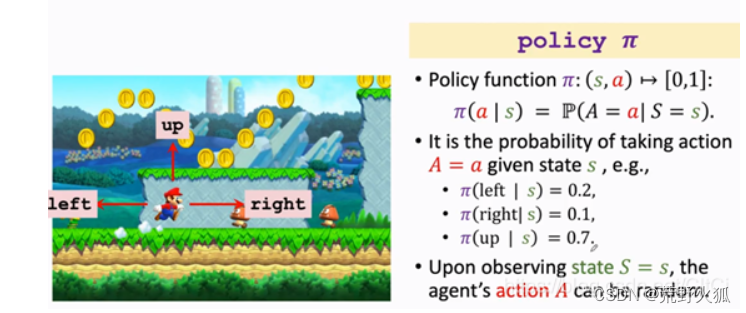
在此状态下,决策函数为左移的概率为0.2,右移的概率为0.1,上跳的概率为0.7,可能的实现方法是进行随机抽样来进行动作。
为什么让agent动作随机呢?
超级玛丽这个游戏里面马里奥的动作不管是随机还是确定都可以,但如果是和人博弈最好还是要随机,要是你的动作很确定别人就有办法赢,我们来想想剪刀石头布的例子,要是你出拳的策略是固定的那就有规律可循了,你的对手就能猜出你下一步要做什么,你很定会输,只有让你的策略随机,别人无法猜测你的下一步动作,你就会赢。–参考
可以看出,有监督学习是学习一个可能的规律,往往我们是根据模型函数得到猫的概率是0.7,则判断为猫,就结束了。
而强化学习是根据决策函数中的概率0.7,再随机进行动作,再学习决策函数。相比而言有了决策。
3、奖励:根据动作来得到奖励反馈。这个标量信号衡量智能体这一轮动作的好坏。
(相当于有监督学习的损失函数)
与有监督学习的区别2:
面向决策任务的强化学习和面向预测任务的有监督学习在形式上的区别:
1、决策任务往往涉及多轮交互,即序贯决策;而预测任务总是单轮的独立任务。如果决策也是单轮的,那么它可以转化为“判别最优动作”的预测任务。
2、因为决策任务是多轮的,智能体就需要在每轮做决策时考虑未来环境相应的改变,所以当前轮带来最大奖励反馈的动作,在长期来看并不一定是最优的。
1.3强化学习的环境
(主要讲上文 为什么让agent动作随机呢?)
环境是动态的,意思就是它会随着某些因素的变化而不断演变,这在数学和物理中往往用随机过程来刻画。
对于一个随机过程,其最关键的要素就是状态以及状态转移的条件概率分布。
状态转移(State transition)
如果在环境这样一个自身演变的随机过程中加入一个外来的干扰因素,即智能体的动作,(这个过程叫做状态转移,例:游戏中马里奥跳了一下)那么环境的下一刻状态的概率分布将由当前状态和智能体的动作来共同决定,用最简单的数学公式表示则是:

假设状态转移函数用p表示:
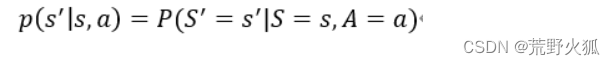
这是一个条件概率密度函数,意思是如果观测到当前的状态s以及动作a,p函数输出s’的概率。(当然也有输出为s’'的概率,这只是说明状态转移的随机性)
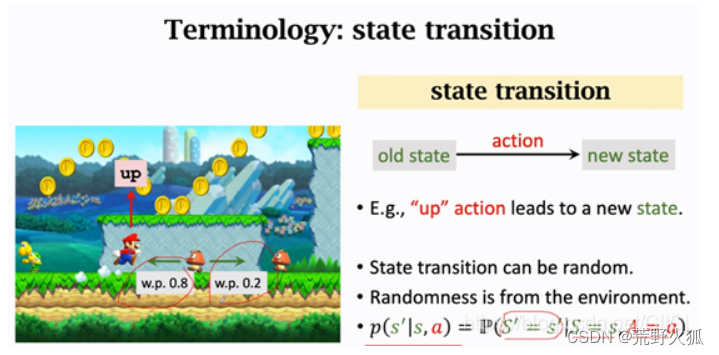
这里环境状态变为了s’,这里假设在s’的状态下蘑菇怪向左概率为0.8,向右为0.2,我们实际上不知道这个状态的概率密度函数,只知道智能体动作的概率密度函数。
(为了好说明环境状态发生了变化,我们也可以假设s状态下,蘑菇怪向左概率为0.7,向右概率为0.3,这是游戏中的程序设定好的,这个游戏中的这个部分的程序,我们可以称为状态的概率密度函数,我们打游戏时,我们不知道这个蘑菇往哪走,对吧。)
由此我们看到,与面向决策任务的智能体进行交互的环境是一个动态的随机过程,其未来状态的分布由当前状态和智能体决策的动作来共同决定,
强化学习中的随机性
并且每一轮状态转移都伴随着两方面的随机性:
一是智能体决策的动作的随机性。(马里奥动作的随机性)
二是环境基于当前状态和智能体动作来采样下一刻状态的随机性。
(假如下个状态有两个情况,第一个是状态s’的概率为0.2,第一个是状态s“的概率为0.8,也是采用随机抽样。)
与有监督学习的区别3
通过对环境的动态随机过程的刻画,我们能清楚地感受到,在动态随机过程中学习和在一个固定的数据分布下学习是非常不同的。
1.4 强化学习的目标
简单来说就是让目标(随着时间推移)获得的奖励总和最高。
回报(return)
整体回报(return),好比一盘游戏最后的分数值。
价值(value)
根据环境的动态性我们可以知道,即使环境和智能体策略不变,智能体的初始状态也不变,智能体和环境交互产生的结果也很可能是不同的,对应获得的回报也会不同。
因此,在强化学习中,我们关注回报的期望,并将其定义为价值(value),这就是强化学习中智能体学习的优化目标。
关于价值计算
价值的计算有些复杂,因为需要对交互过程中每一轮智能体采取动作的概率分布和环境相应的状态转移的概率分布做积分运算。
(后面会讲)
与有监督学习的区别4 与相似1
相似:强化学习和有监督学习的学习目标其实是一致的,即在某个数据分布下优化一个分数值的期望。
区别:强化学习和有监督学习的优化途径是不同的。
1.5 强化学习中的数据
与有监督学习的区别5
在数据层面上,
有监督学习的任务建立在从给定的数据分布中采样得到的训练数据集上,通过优化在训练数据集中设定的目标函数(如最小化预测误差)来找到模型的最优参数。这里,训练数据集背后的数据分布是完全不变的。在强化学习中,数据是在智能体与环境交互的过程中得到的。如果智能体不采取某个决策动作,那么该动作对应的数据就永远无法被观测到,所以当前智能体的训练数据来自之前智能体的决策结果。因此,智能体的策略不同,与环境交互所产生的数据分布就不同,
总结:两者数据集不同,数据分布变化不同,且强化学习的每个智能体的数据分布也不同。
状态动作对(state-action pair)
相当于每个状态下,对应的所有可能的动作。
占用度量(occupancy measure)
参考:
深入理解强化学习——马尔可夫决策过程:占用度量-[基础知识]
数学定义:归一化的占用度量用于衡量在一个智能体决策与一个动态环境的交互过程中,采样到一个具体的状态动作对(state-action pair)的概率分布。
占用度量的性质:给定两个策略及其与一个动态环境交互得到的两个占用度量,那么当且仅当这两个占用度量相同时,这两个策略相同。
也就是说,如果一个智能体的策略有所改变,那么它和环境交互得到的占用度量也会相应改变。
所以,占用度量可以用来评价决策的好坏。
占用度量作用:描述了智能体在不同状态下花费的时间或访问的频率。在棋盘游戏中,占用度量可以帮助我们了解智能体在不同局面下的访问频率。
例子:假设我们的智能体正在学习下棋。占用度量告诉我们,在训练过程中,智能体更频繁地遇到了某些局面。这些局面的占用度量较高,表示智能体更常见地处于这些状态下。
强化学习本质的思维方式
1、强化学习的策略在训练中会不断更新,其对应的数据分布(即占用度量)也会相应地改变。因此,强化学习的一大难点就在于,智能体看到的数据分布是随着智能体的学习而不断发生改变的。
2、由于奖励建立在状态动作对之上,一个策略对应的价值其实就是一个占用度量下对应的奖励的期望,因此寻找最优策略对应着寻找最优占用度量
。
1.6 强化学习的独特性
有监督学习:在一个固定的数据分布上,优化模型,最小化由损失函数计算出来的误差。(当然也有对数据分布的评价)

强化学习:在由占用度量评价的策略上,优化策略,最大化由奖励函数计算出的奖励。准确来说,智能体会根据奖励函数获得即时反馈,并通过价值函数来评估其行为的长期效果,来最大化最终回报

总结 与有监督学习的异同
同:有监督学习和强化学习的优化目标相似,即都是在优化某个数据分布下的一个分数值的期望。
异:
1、强化学习可以改变环境,有监督学习不能。
2、强化学习往往多轮,有监督学习往往一轮。
3、强化学习的学习是动态的,有监督学习是固定的。
4、强化学习的优化途径与有监督学习不同。
有监督学习直接通过优化模型对于数据特征的输出来优化目标,即修改目标函数(y = kx+b)而数据分布不变;
强化学习则通过改变策略来调整智能体和环境交互数据的分布,进而优化目标,即修改数据分布而目标函数(最大化长期奖励的目标)不变。
5、强化学习的数据集是变化的,数据分布是变化的,有监督学习的数据据是不变的,数据分布是不变的。
综上所述,一般有监督学习和强化学习的范式之间的区别为:
一般的有监督学习关注寻找一个模型,使其在给定数据分布下得到的损失函数的期望最小;
强化学习关注寻找一个智能体策略,使其在与动态环境交互的过程中产生最优的数据分布,即最大化该分布下一个给定奖励函数的期望。
1.7 小结
在大多数情况下,强化学习任务往往比一般的有监督学习任务更难,因为一旦策略有所改变,其交互产生的数据分布也会随之改变,并且这样的改变是高度复杂、不可追踪的,往往不能用显式的数学公式刻画。
这就好像一个混沌系统,我们无法得到其中一个初始设置对应的最终状态分布,而一般的有监督学习任务并没有这样的混沌效应。
视频里加了些新的术语,总的来说,强化学习入门这一篇就够了!!!万字长文这篇博文分的专业术语更细一点,也更好懂一点。书上讲的更专注于与有监督学习的区别和概括,但后面章节会详细讲到。
视频补充:
历史、状态

历史(History):是观察、奖励、行动的序列,即一直到时间t为止的所有可观测变量。
状态(State):是一种用于确定接下来会发生的事情(A,R,O),状态是关于历史的函数。
状态通常是整个环境的, 观察可以理解为是状态的一部分,仅仅是agent可以观察到的那一部分。
策略

策略分为两种:确定性策略,随机策略。
随机策略常用概率密度函数。(条件概率分布是概率密度函数的一种特殊形式)
价值函数

价值函数:(分为状态价值函数V(s),动作价值函数Q(s))
评估在给定策略(policy)下,以 后面几步的价值和的期望值(状态价值),来判断当前状态的好坏,来定义对于长期来水,什么是好的。
这里y为折扣率,即对未来的奖励打折。
模型
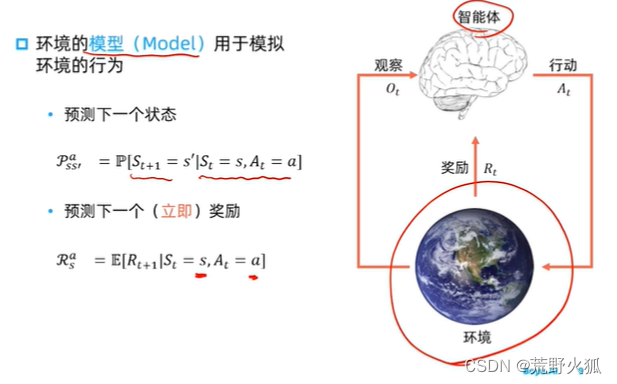
在强化学习中,环境称为模型。
预测下一个(立即)奖励 为奖励函数。
迷宫问题
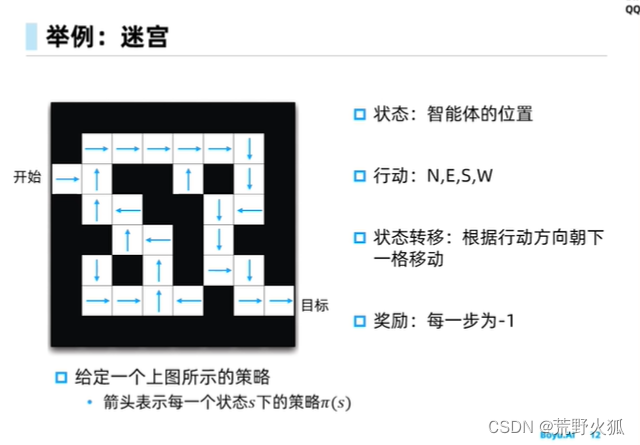
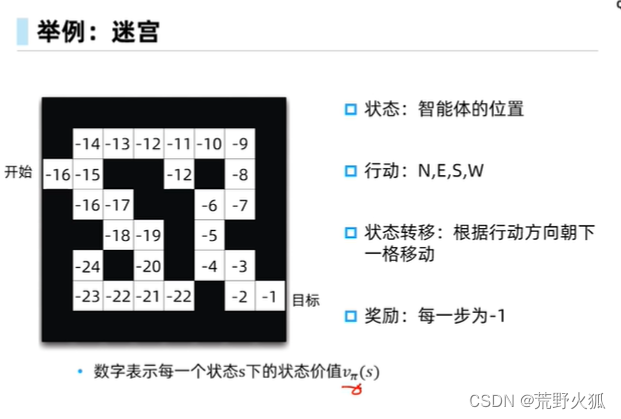
在迷宫问题中,策略和状态价值函数是绑定的。
强化学习智能体分类(模型上)

真正意义上的强化学习是下一种,不知道环境模型是什么样的。
强化学习智能体分类(价值、策略上)

相关文章:
[通俗易懂]《动手学强化学习》学习笔记1-第1章 初探强化学习
文章目录 前言第1章 初探强化学习1.1 简介序贯决策(sequential decision making)任务:强化学习与有监督学习或无监督学习的**区别**:改变未来 1.2 什么是强化学习环境交互与有监督学习的区别1:改变环境 (说…...
centOS如何升级python
centOS下升级python版本的详细步骤 1、可利用linux自带下载工具wget下载,如下所示: 笔者安装的是最小centos系统,所以使用编译命令前,必须安装wget服务,读者如果安装的是界面centos系统,或者使用过编译工具…...

【MYSQL锁】透彻地理解MYSQL锁
🔥作者主页:小林同学的学习笔录 🔥mysql专栏:小林同学的专栏 目录 1.锁 1.1 概述 1.2 全局锁 1.2.1 语法 1.2.1.1 加全局锁 1.2.1.2 数据备份 1.2.1.3 释放锁 1.2.1.4 特点 1.2.1.5 演示 1.3 表级锁 1.3.1 介绍 …...
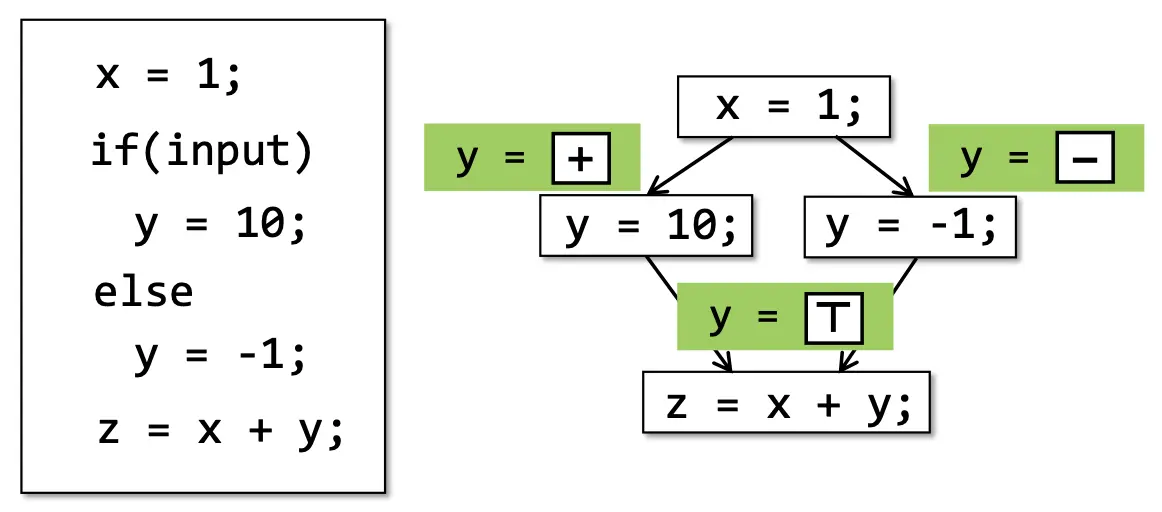
【静态分析】静态分析笔记01 - Introduction
参考: BV1zE411s77Z [南京大学]-[软件分析]课程学习笔记(一)-introduction_南京大学软件分析笔记-CSDN博客 ------------------------------------------------------------------------------------------------------ 1. program language and static analysis…...

使用的sql
根据CODE去重 SELECT * FROM ( SELECT count( camera_code ) AS count, camera_code FROM n_camera_basic GROUP BY camera_code ) t WHERE t.count >1 DELETE FROM n_camera_basic WHERE camera_id NOT IN (SELECT dt.minno…...
)
【ZZULIOJ】1052: 数列求和4(Java)
目录 题目描述 输入 输出 样例输入 Copy 样例输出 Copy code 题目描述 输入n和a,求aaaaaa…aa…a(n个a),如当n3,a2时,222222的结果为246 输入 包含两个整数,n和a,含义如上述,你可以假定n和a都是小于10的非负整…...
【Linux】tcpdump P3 - 过滤和组织返回信息
文章目录 基于TCP标志的过滤器格式化 -X/-A额外的详细选项按协议(udp/tcp)过滤低详细输出 -q时间戳选项 本文继续展示帮助你过滤和组织tcpdump返回信息的功能。 基于TCP标志的过滤器 可以根据各种TCP标志来过滤TCP流量。这里是一个基于tcp-ack标志进行过滤的例子。 # tcpdump…...

vscode免费登录ssh ,linux git配置免密码
1、vscode远程ssh免密 在windows下生成密钥 , cmd窗口下执行 ssh-keygen -t rsa 在C:\Users\xxxx\.ssh目录下生成 在linux下面 cd .ssh 创建authorized_keys 文件, 把之前windows下生成的 id_rsa.pub内容复制进去 2、gitlab 配置。 在linux下面 ssh-keygen -t rs…...
——服务源码剖析(上)(四十一))
Netty 心跳(heartbeat)——服务源码剖析(上)(四十一)
剖析目的 Netty 作为一个网络框架,提供了诸多功能,比如编码解码等,Netty 还提供了非常重要的一个服务----心跳机制 heartbeat.通过心跳检査对方是否有效,这是 RPC 框架中是必不可少的功能。下面我们分析一下 Netty 内部心跳服务源码实现。 源…...

C语言—每日选择题—Day65
前言 我们的刷题专栏又又又开始了,本专栏总结了作者做题过程中的好题和易错题。每道题都会有相应解析和配图,一方面可以使作者加深理解,一方面可以给大家提供思路,希望大家多多支持哦~ 第一题 1、如下代码输出的是什么…...
【环境变量】基本概念理解 | 查看环境变量echo | PATH的应用和修改
目录 前言 基本概念&理解 注意的点 查看环境变量的方法 PATH环境变量 PTAH应用系统指令 PTAH应用用户程序 命令行参数的修改(内存级) 配置文件的修改 windows环境变量 大家天天开心🙂 bash进程的流程。环境变量在系统指…...

5.7Python之元组
元组(Tuple)是Python中的一种数据类型,它是一个有序的、不可变的序列。元组使用圆括号 () 来表示,其中的元素可以是任意类型,并且可以包含重复的元素。 与列表(List)不同,元组是不可…...

Python 基于 OpenCV 视觉图像处理实战 之 OpenCV 简单视频处理实战案例 之一 简单视频放大抖动效果
Python 基于 OpenCV 视觉图像处理实战 之 OpenCV 简单视频处理实战案例 之一 简单视频放大抖动效果 目录 Python 基于 OpenCV 视觉图像处理实战 之 OpenCV 简单视频处理实战案例 之一 简单视频放大抖动效果 一、简单介绍 二、简单视频放大抖动效果实现原理 三、简单视频放大…...

如何通过VPN访问内网?
VPN(Virtual Private Network)是一种通过公共网络建立私有网络连接的技术,可以在不同地点的网络中建立安全通道,实现远程访问内网资源的目的。本文将介绍如何通过VPN访问内网,并介绍一款名为“天联”的VPN服务。 什么是…...
RabbitMQ3.13.0起支持MQTT5.0协议及MQTT5.0特性功能列表
RabbitMQ3.13.0起支持MQTT5.0协议及MQTT5.0特性功能列表 文章目录 RabbitMQ3.13.0起支持MQTT5.0协议及MQTT5.0特性功能列表1. MQTT概览2. MQTT 5.0 特性1. 特性概要2. Docker中安装RabbitMQ及启用MQTT5.0协议 3. MQTT 5.0 功能列表1. 消息过期1. 描述2. 举例3. 实现 2. 订阅标识…...

常用脚本01 - 生成证书
1 生成证书 第一步、准备脚本文件 [rootharbor-01 ssl]# vim gencert.sh #!/usr/bin/env bash set -eDOMAIN"$1" IP"$2" WORK_DIR"$(mktemp -d)"if [ -z "$DOMAIN" ]; thenecho "Domain name needed."exit 1 fiecho "…...

【jQuery】jQuery框架
目录 1.jQuery基本用法 1.1选择器 1.2jQuery对象 1.3事件绑定 1.4链式编程 1.5过滤方法 1.6样式操纵 1.6属性操纵 1.7操作value 1.8查找方法 1.9类名操纵 1.10事件进阶 1.11触发事件 1.12window事件绑定 2.节点操作与动画 2.1获取位置 2.2滚动距离 2.3显示/隐…...
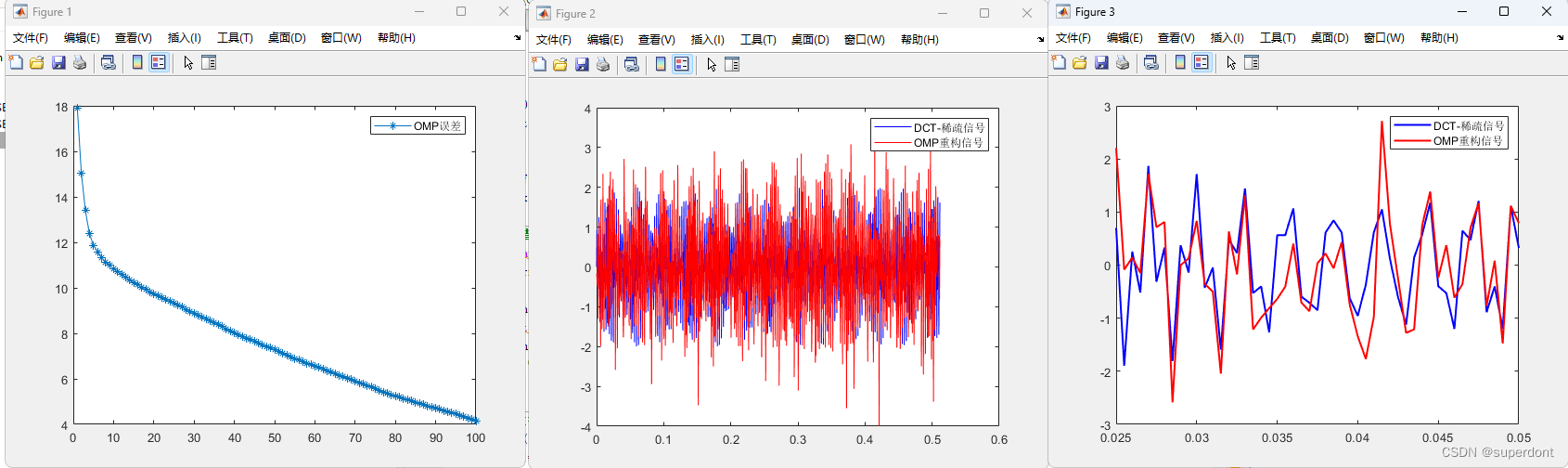
使用OMP复原一维信号(MATLAB)
参考文献 https://github.com/aresmiki/CS-Recovery-Algorithms/tree/master MATLAB代码 %% 含有噪声 % minimize ||x||_1 % subject to: (||Ax-y||_2)^2<eps; % minimize : (||Ax-y||_2)^2lambda*||x||_1 % y传输中可能含噪 yyw % %% clc;clearvars; close all; %% 1.构…...

Linux安装最新版Docker完整教程
参考官网地址:Install Docker Engine on CentOS | Docker Docs 一、安装前准备工作 1.1 查看服务器系统版本以及内核版本 cat /etc/redhat-release1.2 查看服务器内核版本 uname -r这里我们使用的是CentOS 7.6 系统,内核版本为3.10 1.3 安装依赖包 …...

iOS object-c self关键字总结
在Objective-C中,self 关键字是一个指向当前对象的指针。它是对象自身实例的别名,通常在对象内部的方法中使用,以提供一个指向当前对象的引用。使用 self 可以帮助你访问对象的属性和方法,特别是在处理消息传递和方法调用时。 以…...

2025最权威的五大降重复率方案推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 处于学术探索的终点之处,一篇出色的毕业论文乃是知识跟汗水所凝结而成的&#x…...

深度学习篇---向量空间
向量空间(或称线性空间)是一个很美妙的数学结构。它不仅是线性代数的核心,更是我们理解很多高级概念(比如深度学习中的词向量、特征空间)的基础。简单说,向量空间就是一个定义了向量加法和数乘运算…...

Windows11下DOSBox从零到精通的完整配置与实战指南
1. 为什么要在Windows11上使用DOSBox? 很多年轻朋友可能都没见过DOS系统长什么样。作为上世纪80年代到90年代的主流操作系统,DOS虽然界面简陋,但它孕育了无数经典软件和游戏。直到今天,学习汇编语言、运行老式工业控制程序、怀旧经…...

从逻辑门到加法器:Verilog实现半加器与全加器的三种抽象层级
1. 项目概述:从逻辑门到加法器的数字世界基石在数字电路和芯片设计的入门路上,加法器是一个绕不开的经典课题。它不仅是算术逻辑单元(ALU)的核心组件,更是理解数字系统如何执行基本运算的关键。今天,我们不…...

GO Feature Flag通知系统详解:Slack、Webhook实时告警
GO Feature Flag通知系统详解:Slack、Webhook实时告警 【免费下载链接】go-feature-flag GO Feature Flag is a simple, complete and lightweight self-hosted cloud native feature flag solution 100% Open Source. 🎛️ 项目地址: https://gitcode…...

从warmup_csaw_2016看栈溢出利用的本质:绕过NX/ASLR?不,这次我们先学‘计算’
从warmup_csaw_2016看栈溢出利用的本质:计算的艺术 在二进制安全领域,栈溢出常被初学者视为"魔法攻击"——只需覆盖返回地址就能获得控制权。但当我们剥开NX/ASLR等现代保护机制的外衣,会发现精确计算才是漏洞利用的永恒核心。2016…...
)
手把手教你用STC89C52单片机驱动DS1302时钟模块(附完整代码)
STC89C52与DS1302时钟模块实战指南:从硬件搭建到代码实现 1. 项目概述与硬件准备 在嵌入式系统开发中,实时时钟(RTC)功能是许多项目的核心需求。STC89C52作为经典的51系列单片机,与DS1302时钟模块的组合,为开发者提供了经济实惠且…...
)
为什么92%的斯里兰卡项目在ElevenLabs僧伽罗文语音上失败?——2024最新L10n兼容性白皮书首发(附实测RTT延迟对比数据)
更多请点击: https://intelliparadigm.com 第一章:为什么92%的斯里兰卡项目在ElevenLabs僧伽罗文语音上失败? ElevenLabs 官方文档明确声明支持僧伽罗文(Sinhala),但实际部署中,斯里兰卡本地政…...

实验室里的“学霸”与街头上的“全才”:深度解析 PaLM 与 ChatGPT
在 AI 的史诗级进程中,2022 年是一个被历史铭记的分水岭。那一年,Google 推出了参数量惊人的 PaLM,展示了“暴力美学”的巅峰;而几个月后,OpenAI 的 ChatGPT 横空出世,彻底改变了人类与机器交互的方式。 很…...
CircuitPython驱动NeoPixel与DotStar:从原理到炫彩动画实战
1. 项目概述与核心价值在嵌入式开发和物联网项目中,灯光不仅仅是简单的“亮”与“灭”,它更是设备与用户沟通的语言,是项目灵魂的直观体现。无论是智能家居的氛围灯带、可穿戴设备的动态提示,还是艺术装置的视觉表达,可…...