ELK企业日志分析系统介绍
前言
随着企业级应用系统日益复杂,随之产生的海量日志数据。传统的日志管理和分析手段,难以做到高效检索、实时监控以及深度挖掘潜在价值。在此背景下,ELK日志分析系统应运而生。本文将从ELK 日志分析系统的原理、架构及其在实践中的应用做相关介绍。
目录
一、ELK 简介
1. 概述
2. 组件
2.1 ElasticSearch
2.2 Logstash
2.3 Kiabana
3. ELK架构
4. 完整日志系统基本特征
5. ELK 的工作原理
二、ELK 部署
1. 环境准备
2. ELK Elasticsearch 集群部署
3. 安装 Elasticsearch-head 插件
4. ELK Logstash 部署
5. 收集系统日志 /var/log/messages
6. ELK Kiabana 部署
一、ELK 简介
1. 概述
ELK 和 ElasticStack 实质上指的是同一个概念,ELK 平台是一套完整的日志集中处理方案。其拥有三个组件:ElasticSearch、Logstash 和 Kiabana 配合使用组成一个功能全面的数据平台。另外,当需要处理大量实时数据的场景,ELK 与 Kafka 的集成可以提供一个强大的实时数据收集、存储、分析和可视化解决方案。
2. 组件
2.1 ElasticSearch
提供了一个分布式多用户能力的全文搜索和分析引擎,可以把日志集中化管理。Elasticsearch 是用 Java 开发的,可通过 RESTful Web 接口,让用户可以通过浏览器与 Elasticsearch 通信。
下面是标准的 HTTP 方法与 RESTful 资源管理之间的映射关系:
- GET:获取文档
- POST:创建
- PUT:更新
- DELTET:删除
- GET:搜索值
核心概念:
- 接近实时:一旦索引操作完成(通常在几秒钟内),文档就能几乎立刻被搜索到
- 集群:是由一个或多个节点组成的
- 节点:一个独立运行实例,它可以存储数据、参与文档索引和搜索过程
- 索引:索引(库)——>类型(表)——>文档(记录),可以理解为一种数据库的特性,是一个大的文档的集合
- 分片:允许将索引切分成多个分片,可以在集群的不同节点上独立分布和操作
- 副本:允许为索引的每个分片创建副本,可以分摊读请求、有冗余能力
2.2 Logstash
由 Ruby 语言编写,运行在 Java 虚拟机(JVM)上,是一款强大的数据处理工具。其主要功能是收集日志,输入采集的数据进行加工(如过滤、改写等)以及数据的输出。相关概念有:input(数据采集)、filter(数据过滤)和 output(数据输出)。
主要主件有:
- Shipper:日志收集者,监控微服务日志
- Indexer:日志存储者
- Broker:连接多个收集者,指向 Indexer
- Search and Storage:搜索和存储
- Web Interface:展示可视化数据界面
由于 Logstash 运行在 jvm 虚拟机环境中,比较占用 cpu、内存资源,可以添加其它组件直接在操作系统运行:
- Filebeat:轻量级的开源日志文件数据搜集器,可以直接部署在目标主机上,实时读取日志文件并将数据发送到Elasticsearch、Logstash或其他输出目的地。
- Fluentd:是一个流行的开源数据收集器,可以收集来自各种数据源的日志数据,并将其规范化后输出到多种存储或分析系统中,如Elasticsearch、MongoDB、S3等。
- 缓存/消息队列(redis、kafka、RabbitMQ等):可以对高并发日志数据进行流量削峰和缓冲,这样的缓冲可以一定程度的保护数据不丢失,还可以对整个架构进行应用解耦。
2.3 Kiabana
针对 Elasticsearch 的开源分析及可视化平台,搜索查看索引中的数据。Kibana 通常与 Elasticsearch 一起部署,对接 Es 接口。
3. ELK架构
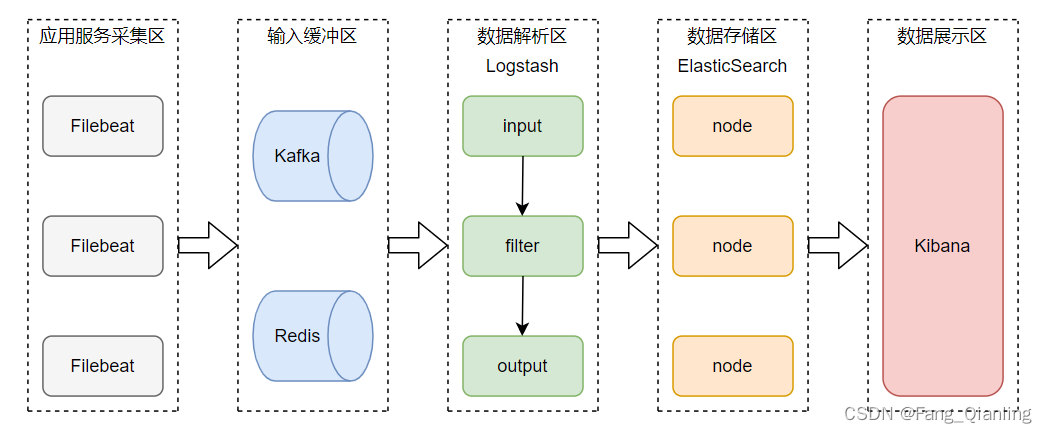
① 日志数据首先由应用程序产生。这些日志可能是应用程序运行时生成的标准输出、错误输出,或者是通过API直接输出的日志事件。例如,Web服务器、数据库服务、微服务等各类应用都会产生日志信息
② Kafka、Redis 可以起到缓冲的作用,暂时存储本地的日志数据直到成功发送出去,避免数据丢失;同时具有抗高并发能力,存储速度快等特点
③ Logstash 接收到来自缓冲区的日志数据后,进入数据解析区。在这里,Logstash通过配置的输入插件(Input Plugins)读取数据,然后经过过滤插件(Filter Plugins)进行解析和转换,最后输出数据(Output)
④ 经过解析和处理后的日志数据,最终被发送到Elasticsearch中存储。Elasticsearch 是一个分布式搜索引擎和分析引擎,它将数据按照索引(index)组织,并将索引进一步划分为多个分片(shards)以实现水平扩展和高可用性
⑤ Kibana 是一个强大的可视化工具,它连接到 Elasticsearch,可以从存储在 Elasticsearch 中的日志数据构建实时仪表板和报表。开发人员和运维团队可以通过 Kibana 的搜索和可视化功能
4. 完整日志系统基本特征
- 收集:能够采集多种来源的日志数据
- 传输:能够稳定的把日志数据解析过滤并传输到存储系统
- 存储:存储日志数据
- 分析:支持 UI 分析
- 警告:能够提供错误报告,监控机制
5. ELK 的工作原理
① 在所有需要收集日志的服务器上部署Logstash;或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署 Logstash
② Logstash 收集日志,将日志格式化并输出到 Elasticsearch 群集中
③ Elasticsearch 对格式化后的数据进行索引和存储
④ Kibana 从 ES 群集中查询数据生成图表,并进行前端数据的展示
总结:logstash 作为日志搜集器,从数据源采集数据,并对数据进行过滤,格式化处理,然后交由Elasticsearch 存储,kibana 对日志进行可视化处理。
二、ELK 部署
1. 环境准备
| 节点名 | ip地址 | 安装软件 |
| node1 | 192.168.190.100 | elasticsearch、kibana |
| node2 | 192.168.190.101 | elasticsearch |
| logstash | 192.168.190.102 | apache、logstash |
systemctl stop firewalld.service
setenforce 0
# 关闭防火墙、核心防护功能
node1节点:hostnamectl set-hostname node1
node2节点:hostnamectl set-hostname node2
logstash节点:hostnamectl set-hostname logstash
# 修改主机名,方便查看
echo 192.168.190.100 node1 >> /etc/hosts
echo 192.168.190.101 node2 >> /etc/hosts
echo 192.168.190.102 logstash >> /etc/hosts
# 编辑域名解析,制作映射
[root@node1 ~]# java -version
openjdk version "1.8.0_131"
[root@node2 ~]# java -version
openjdk version "1.8.0_131"
# 显示 Java 运行时环境版本信息,如果没有:yum -y install java2. ELK Elasticsearch 集群部署
实际生产环境中常常会部署更多的节点来增强冗余能力、高可用性、负载均衡、数据扩容等,这里部署两台(在Node1、Node2节点上操作)。
① 安装 elasticsearch rpm 包
分别在node1、node2节点上操作:
[root@node1 opt]# ls
elasticsearch-5.5.0.rpm # 这里使用 elasticsearch-5.5.0.rpm 包
[root@node1 opt]# rpm -ivh elasticsearch-5.5.0.rpm[root@node1 opt]# systemctl daemon-reload
[root@node1 opt]# systemctl enable elasticsearch.service
# 加载系统服务
② 修改 elasticsearch 主配置文件
[root@node1 ~]# rpm -qc elasticsearch
/etc/elasticsearch/elasticsearch.yml
[root@node1 ~]# cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
# 备份配置文件
[root@node1 ~]# vim /etc/elasticsearch/elasticsearch.yml17 cluster.name: my-application # 取消注释,指定集群名字,名字可以按需修改23 node.name: node1 # 取消注释,指定节点名字:node1、Node233 path.data: /data/elk_data # 取消注释,指定数据存放路径37 path.logs: /var/log/elasticsearch/ # 取消注释,指定日志存放路径43 bootstrap.memory_lock: false # 取消注释,改为在启动的时候不锁定内存55 network.host: 0.0.0.0 # 取消注释,设置监听地址,0.0.0.0代表所有地址59 http.port: 9200 # 取消注释,ES 服务的默认监听端口为920068 discovery.zen.ping.unicast.hosts: ["node1", "node2"] # 取消注释,集群发现通过单播实现,指定要发现的节点 node1、node2[root@node1 ~]# grep -v "^#" /etc/elasticsearch/elasticsearch.yml # 显示去除了注释的配置内容
③ 创建数据存放路径并授权
[root@node1 ~]# mkdir -p /data/elk_data
[root@node1 ~]# chown elasticsearch:elasticsearch /data/elk_data/④ 启动 elasticsearch 是否成功开启
[root@node1 ~]# systemctl start elasticsearch.service
[root@node1 ~]# netstat -antp | grep 9200 # 启动的有点慢需要等一会
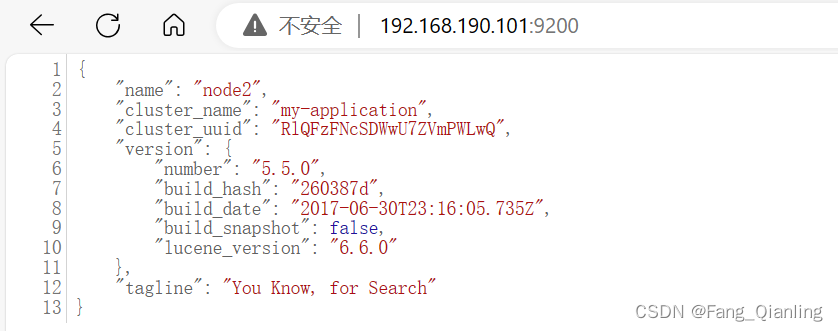
tcp6 0 0 :::9200 :::* LISTEN 2541/java⑤ 查看节点信息
浏览器访问 http://192.168.190.100:9200 、 http://192.168.190.101:9200 查看节点 Node1、Node2 的信息:

浏览器访问查看群集的健康情况
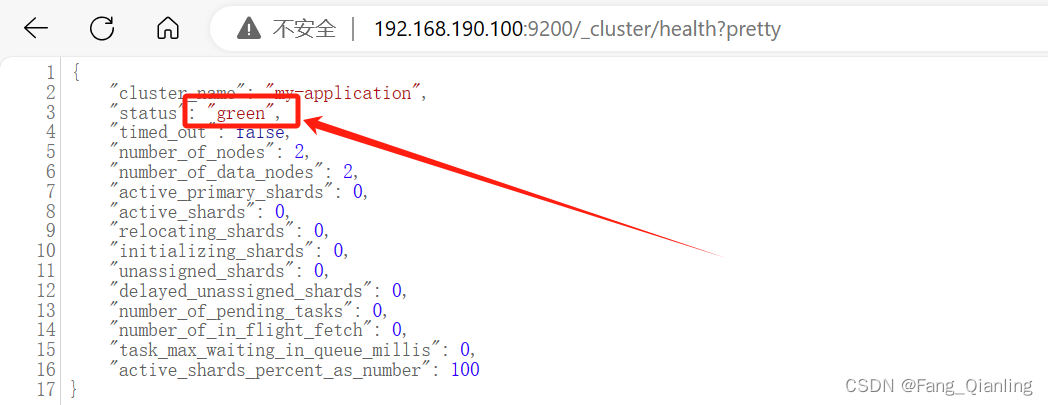
status 值:
- green(绿色):表示节点健康运行
- 绿色:健康 数据和副本 全都没有问题
- 红色:数据都不完整
- 黄色:数据完整,但副本有问题
浏览器访问 http://192.168.190.100:9200/_cluster/state?pretty 可以检查群集状态信息。使用上述方式查看群集的状态对用户并不友好,可以通过安装 Elasticsearch-head 插件,可以更方便地管理群集。
3. 安装 Elasticsearch-head 插件
安装 Elasticsearch-head 插件的主要作用是为 Elasticsearch 提供一个可视化的 Web 界面,方便用户管理和监控 Elasticsearch 集群。
Elasticsearch 在 5.0 版本后,Elasticsearch-head 插件需要作为独立服务进行安装,需要使用npm工具(NodeJS的包管理工具)安装。安装 Elasticsearch-head 需要提前安装好依赖软件 node 和 phantomjs。
- node:是一个基于 Chrome V8 引擎的 JavaScript 运行环境
- phantomjs:是一个基于 webkit 的JavaScriptAPI,可以理解为一个隐形的浏览器,任何基于 webkit 浏览器做的事情,它都可以做到
① 编译安装 node
[root@node1 opt]# yum install gcc gcc-c++ make -y # 安装编译工具
[root@node1 opt]# ls
elasticsearch-5.5.0.rpm node-v8.2.1.tar.gz # 准备软件包 node-v8.2.1.tar.gz
[root@node1 opt]# tar zxvf node-v8.2.1.tar.gz
[root@node1 opt]# cd node-v8.2.1/
[root@node1 node-v8.2.1]# ./configure
[root@node1 node-v8.2.1]# make && make install
② 安装 phantomjs(前端的框架)
[root@node1 opt]# ls
phantomjs-2.1.1-linux-x86_64.tar.bz2 # 准备软件包
[root@node1 opt]# tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
[root@node1 opt]# cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin
[root@node1 bin]# cp phantomjs /usr/local/bin③ 安装 Elasticsearch-head 数据可视化工具
[root@node1 opt]# tar zxvf elasticsearch-head.tar.gz -C /usr/local/src/
[root@node1 opt]# cd /usr/local/src/elasticsearch-head/
[root@node1 elasticsearch-head]# npm install④ 修改 Elasticsearch 主配置文件
[root@node1 ~]# vim /etc/elasticsearch/elasticsearch.yml
http.cors.enabled: true # 开启跨域访问支持,默认为 false
http.cors.allow-origin: "*" # 指定跨域访问允许的域名地址为所有
[root@node1 ~]# systemctl restart elasticsearch⑤ 启动 Elasticsearch-head 服务
必须在解压后的 elasticsearch-head 目录下启动服务,进程会读取该目录下的 gruntfile.js 文件,否则可能启动失败。
[root@node1 ~]# cd /usr/local/src/elasticsearch-head/
[root@node1 elasticsearch-head]# npm run start &
[1] 85478
[root@node1 elasticsearch-head]#
> elasticsearch-head@0.0.0 start /usr/local/src/elasticsearch-head
> grunt serverRunning "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
⑥ 通过 Elasticsearch-head 查看 Elasticsearch 信息
通过浏览器访问 http://192.168.190.100:9100/ 地址并连接群集。如果看到群集健康值为 green 绿色,代表群集很健康。

[root@node1 ~]# lsof -i:9100 # 列出所有打开指定TCP或UDP端口(这里是9100)的进程信息
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
grunt 85488 root 12u IPv4 98596 0t0 TCP *:jetdirect (LISTEN)
⑦ 插入索引
[root@node1 ~]# curl -X PUT 'localhost:9200/index-demo1/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
{"_index" : "index-demo1","_type" : "test","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 2,"failed" : 0},"created" : true
}
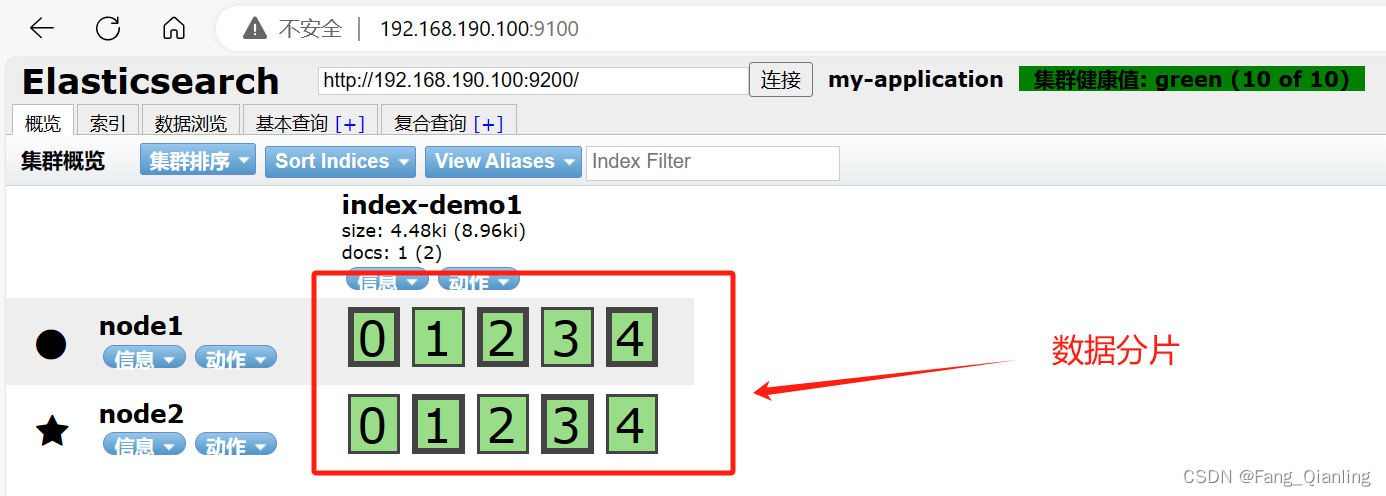
浏览器访问 http://192.168.190.100:9100/ 查看索引信息,可以看见索引默认被分片5个,并且有一个副本。点击“数据浏览”,会发现在node1上创建的索引为 index-demo,类型为 test 的相关信息。

4. ELK Logstash 部署
Logstash 一般部署在需要监控其日志的服务器。
① 安装Apahce服务(httpd)
[root@logstash ~]# yum -y install httpd
[root@logstash ~]# systemctl start httpd.service② 检查安装 Java 环境
[root@logstash ~]# java -version
openjdk version "1.8.0_131"
# 显示 Java 运行时环境版本信息,如果没有:yum -y install java③ 安装 logstash
[root@logstash opt]# ls
logstash-5.5.1.rpm # 准备 logstash-5.5.1.rpm 包
[root@logstash opt]# rpm -ivh logstash-5.5.1.rpm
[root@logstash opt]# systemctl start --now enable logstash.service
[root@logstash opt]# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/④ 测试 Logstash
Logstash 命令常用选项:
-f:通过这个选项可以指定 Logstash 的配置文件,根据配置文件配置 Logstash 的输入和输出流。
-e:从命令行中获取,输入、输出后面跟着字符串,该字符串可以被当作 Logstash 的配置(如果是空,则默认使用 stdin 作为输入,stdout 作为输出)。
-t:测试配置文件是否正确,然后退出。定义输入和输出流:输入采用标准输入,输出采用标准输出(类似管道)
[root@logstash ~]# logstash -e 'input { stdin{} } output { stdout{} }'
www.baidu.com # 键入内容(标准输入)
2024-04-10T13:43:30.574Z logstash www.baidu.com # 输出结果(标准输出)
www.sina.com.cn
2024-04-10T13:44:18.445Z logstash www.sina.com.cn使用 rubydebug 输出详细格式显示,codec 为一种编解码器:
[root@logstash ~]# logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'
www.baidu.com # 键入内容(标准输入)
{"@timestamp" => 2024-04-10T13:48:25.820Z, # 输出结果(处理后的结果)"@version" => "1","host" => "logstash","message" => "www.baidu.com"
}
使用 Logstash 将信息写入 Elasticsearch 中:
[root@logstash ~]# logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.190.100:9200"] } }'
www.baidu.com # 键入内容(标准输入)
结果不在标准输出显示,而是发送至 Elasticsearch 中,可浏览器访问 http://192.168.190.100:9100/ 查看索引信息和数据浏览:

5. 收集系统日志 /var/log/messages
① 定义 logstash 配置文件
Logstash 配置文件基本由三部分组成:input、output 以及 filter(可选,根据需要选择使用)。
input:表示从数据源采集数据,常见的数据源如Kafka、日志文件等
filter:表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式
output:表示将Logstash收集的数据经由过滤器处理之后输出到Elasticsearch。格式如下:
input {...}
filter {...}
output {...}在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下:
input {file { path =>"/var/log/messages" type =>"syslog"}file { path =>"/var/log/httpd/access.log" type =>"apache"}② 修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中
[root@logstash ~]# vim /etc/logstash/conf.d/system.conf
vim /etc/logstash/conf.d/system.conf
input {file{path =>"/var/log/messages" # 指定要收集的日志的位置type =>"system" # 自定义日志类型标识start_position =>"beginning" # 表示从开始处收集}
}
output {elasticsearch { # 输出到 elasticsearchhosts => ["192.168.190.100:9200"] # 指定 elasticsearch 服务器的地址和端口index =>"system-%{+YYYY.MM.dd}" # 指定输出到 elasticsearch 的索引格式}
}
[root@logstash ~]# chmod +r /var/log/messages
[root@logstash ~]# systemctl restart logstash
浏览器访问 http://192.168.190.100:9100/ 查看索引信息:


6. ELK Kiabana 部署
用于可视化和管理Elasticsearch中数据的开源分析和可视化平台。Kibana提供了丰富的图表、仪表盘和数据可视化工具,使用户能够以直观的方式探索和分析数据。(在 Node1 节点上操作)
① 安装 Kiabana
[root@node1 opt]# ls
kibana-5.5.1-x86_64.rpm # 安装包
[root@node1 opt]# rpm -ivh kibana-5.5.1-x86_64.rpm② 设置 Kibana 的主配置文件
[root@node1 opt]# vim /etc/kibana/kibana.yml2 server.port: 5601 # 取消注释,Kiabana 服务的默认监听端口为56017 server.host: "0.0.0.0" # 取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址21 elasticsearch.url: "http://192.168.190.100:9200" # 取消注释,设置和 Elasticsearch 建立连接的地址和端口30 kibana.index: ".kibana" # 取消注释,设置在 elasticsearch 中添加.kibana索引③ 启动 Kibana 服务
[root@node1 opt]# systemctl start --now enable kibana.service
[root@node1 opt]# netstat -natp | grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 2808/node ④ 验证 Kibana
浏览器访问 http://192.168.190.100:5601:
第一次登录需要添加一个 Elasticsearch 索引:
Index name or pattern
//输入:system-* #在索引名中输入之前配置的 Output 前缀“system”单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
数据展示可以分类显示,在“Available Fields”中的“host”,然后单击 “add”按钮,可以看到按照“host”筛选后的结果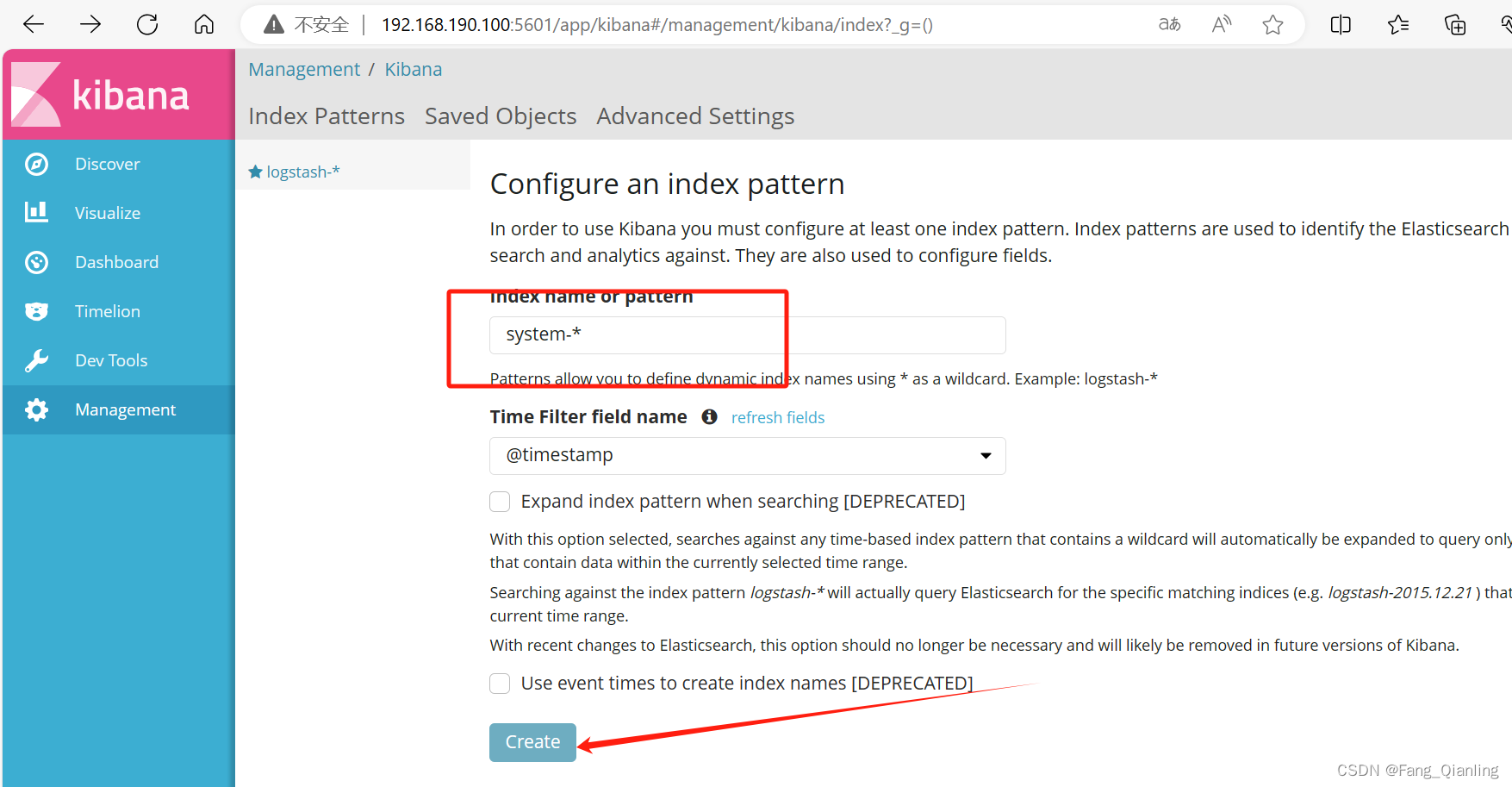

⑤ 将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
[root@logstash ~]# vim /etc/logstash/conf.d/apache_log.conf
input {file{path => "/etc/httpd/logs/access_log"type => "access"start_position => "beginning"}file{path => "/etc/httpd/logs/error_log"type => "error"start_position => "beginning"}
}
output {if [type] == "access" {elasticsearch {hosts => ["192.168.190.100:9200"]index => "apache_access-%{+YYYY.MM.dd}"}}if [type] == "error" {elasticsearch {hosts => ["192.168.190.100:9200"]index => "apache_error-%{+YYYY.MM.dd}"}}
}[root@logstash ~]# cd /etc/logstash/conf.d/
[root@logstash conf.d]# /usr/share/logstash/bin/logstash -f apache_log.conf浏览器访问 http://192.168.190.100:9100 查看索引是否创建:

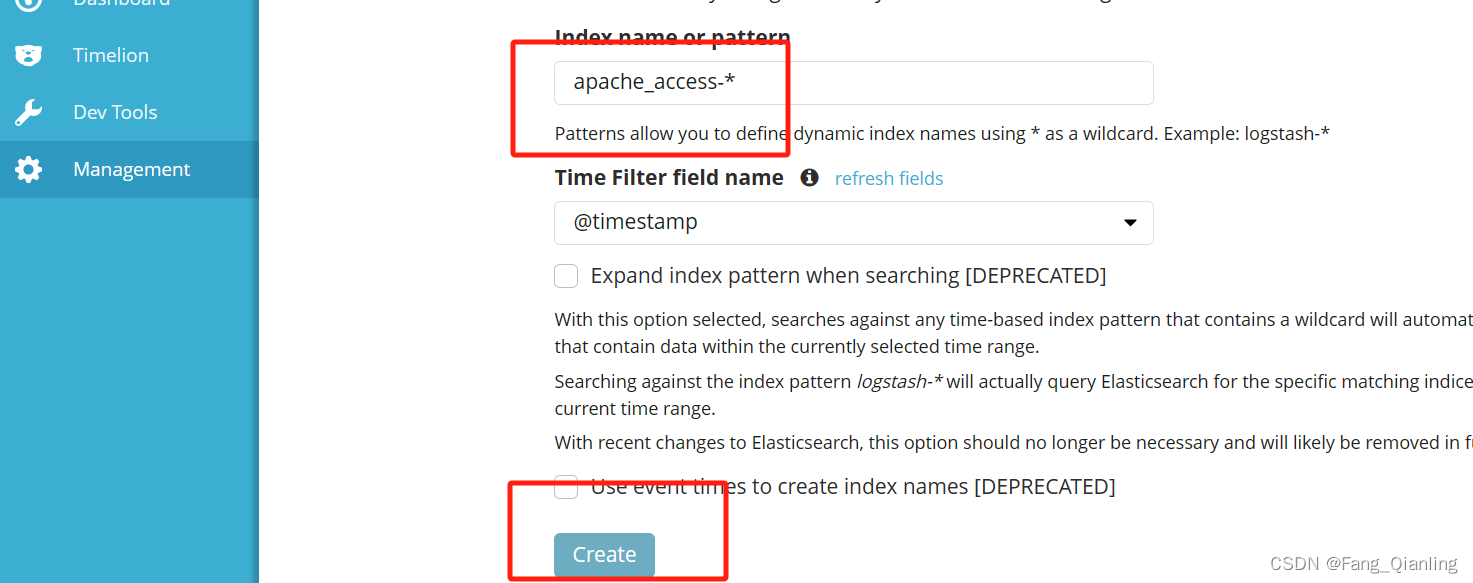
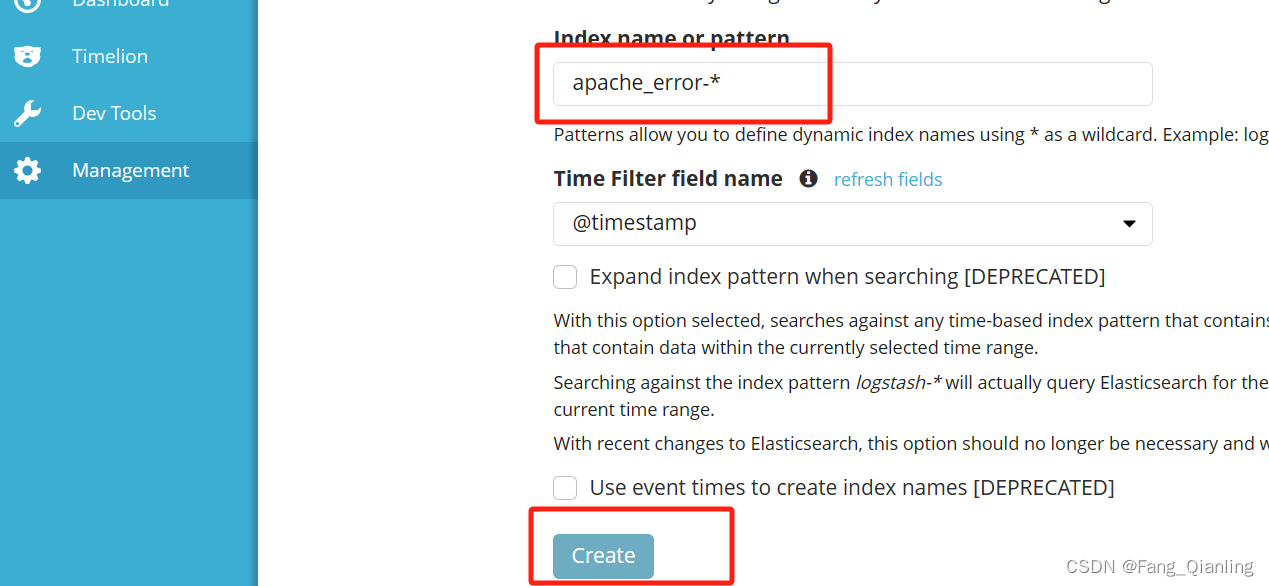
浏览器访问 http://192.168.190.100:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引, 在索引名中输入之前配置的 Output 前缀 apache_access-*,并单击“Create”按钮。在用相同的方法添加 apache_error-*索引。
选择“Discover”选项卡,在中间下拉列表中选择刚添加的 apache_access-* 、apache_error-* 索引, 可以查看相应的图表及日志信息。
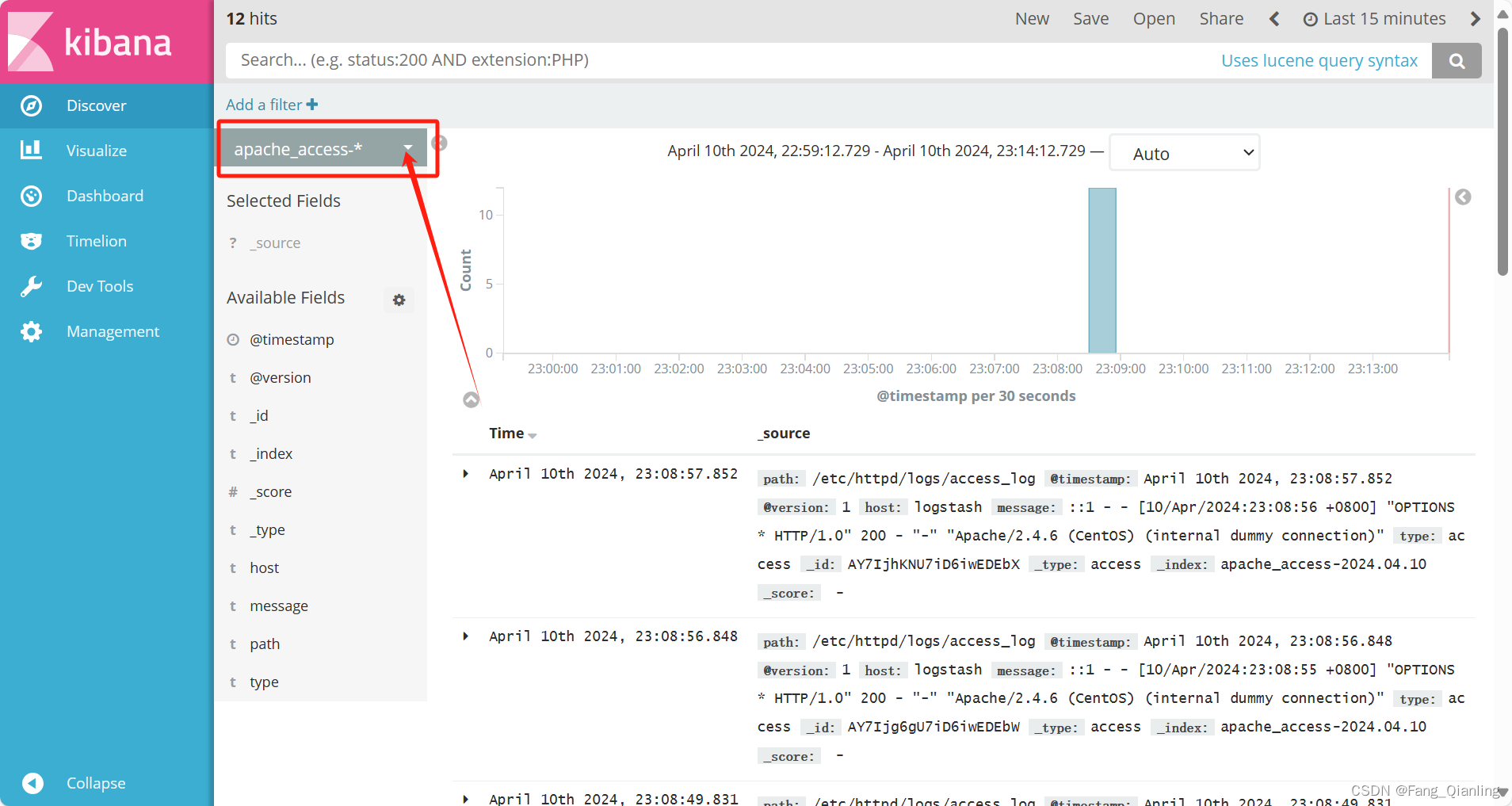

相关文章:
ELK企业日志分析系统介绍
前言 随着企业级应用系统日益复杂,随之产生的海量日志数据。传统的日志管理和分析手段,难以做到高效检索、实时监控以及深度挖掘潜在价值。在此背景下,ELK日志分析系统应运而生。本文将从ELK 日志分析系统的原理、架构及其在实践中的应用做相…...

在C#中读取写入字节流与读取写入二进制数据, 有何差异?
在C#中,读取和写入字节流与读取和写入二进制数据有些许不同,尽管它们在某些情况下可能会重叠使用。以下是它们之间的主要区别: 读取和写入字节流: 读取和写入字节流通常指的是处理文件或流中的原始字节数据。在C#中,可…...
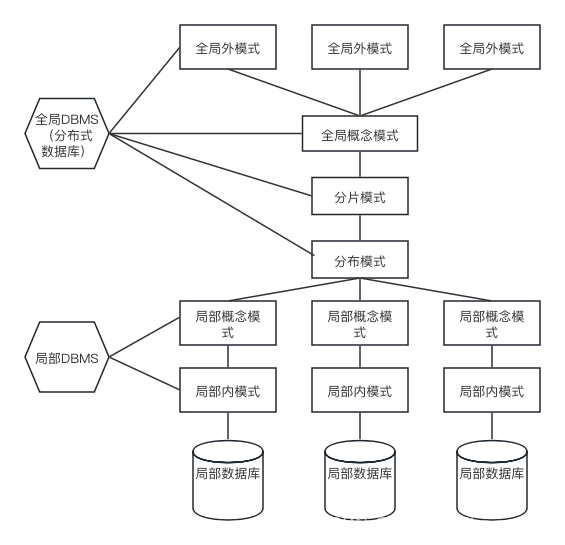
数据库相关知识总结
一、数据库三级模式 三个抽象层次: 1. 视图层:最高层次的抽象,描述整个数据库的某个部分的数据 2. 逻辑层:描述数据库中存储的数据以及这些数据存在的关联 3. 物理层:最低层次的抽象,描述数据在存储器中时如…...
【汇编语言实战】输出数组中特定元素
C语言描述: #include <stdio.h> int main() {int a[]{1,2,3,4,5,6};printf("%d",a[3]); }汇编语言: include irvine32.inc .data arr dword 1,2,3,4,5,6 num dword 1 ;输出第二个元素 .code main proc mov esi,offset arr mov edx,nu…...
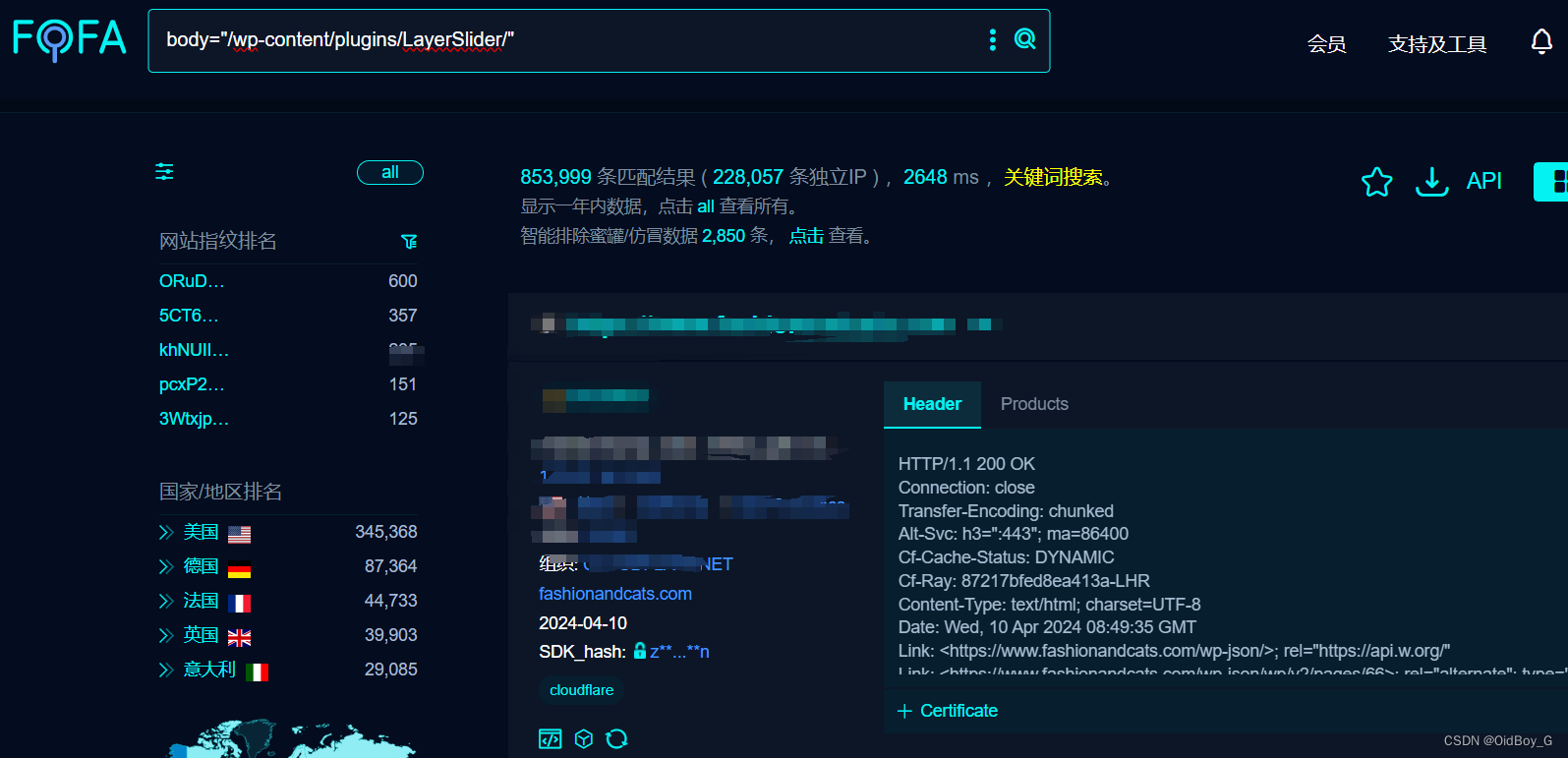
WordPress LayerSlider插件SQL注入漏洞复现(CVE-2024-2879)
0x01 产品简介 WordPress插件LayerSlider是一款可视化网页内容编辑器、图形设计软件和数字视觉效果应用程序,全球活跃安装量超过 1,000,000 次。 0x02 漏洞概述 WordPress LayerSlider插件版本7.9.11 – 7.10.0中,由于对用户提供的参数转义不充分以及缺少wpdb::prepare(),…...
MOS管的判别符号记忆与导通条件
参考链接 MOS管的判别与导通条件 (qq.com)https://mp.weixin.qq.com/s?__bizMzU3MDU1Mzg2OQ&mid2247520228&idx1&sn5996780179fbf01f66b5db0c71622ac3&chksmfcef6c86cb98e590e3d3734ee27797bdded17b6b648b3b0d3b1599e8a4496a1fa4e457be6516&mpshare1&…...

数据指标与经营智慧:构建有洞见的经营分析报告
经营分析报告不仅仅是数字的堆砌,它是企业运营状况的“晴雨表”,能够反映企业的健康状况和发展潜力。一个有洞见的经营分析报告能够帮助管理层识别问题、评估风险、发现机会,并据此制定相应的战略和行动计划。 关注【数据化运营圈】共同探讨…...
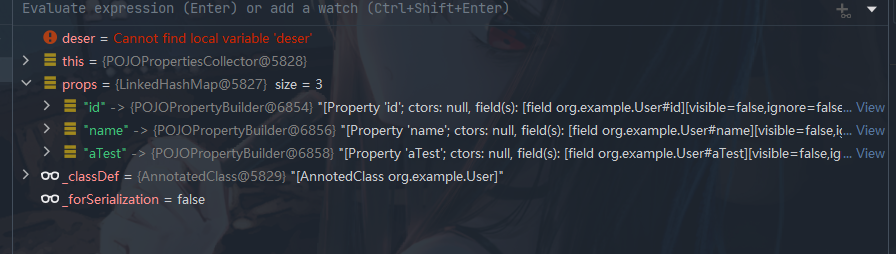
Spring 中类似 aBbb 单字母单词序列化与反序列问题
文章目录 前言代码准备问题排查lombok自定义生成 get、set 结合源码解析使用 lombok使用 lombok 自定义生成 user 对象 get、set 方法 如何解决使用注解 JsonProperty("aTest")自定义实现符合 Spring 规范的 get set 方法 个人简介 前言 最近在使用 spring boot mvc…...
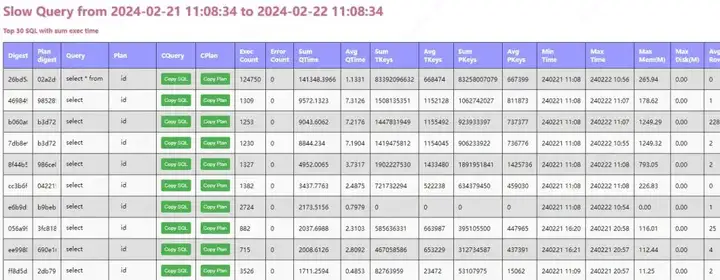
TiDB 慢查询日志分析
导读 TiDB 中的慢查询日志是一项 关键的性能监控工具,其主要作用在于协助数据库管理员追踪执行时间较长的 SQL 查询语句。 通过记录那些超过设定阈值的查询,慢查询日志为性能优化提供了关键的线索,有助于发现潜在的性能瓶颈,优化…...
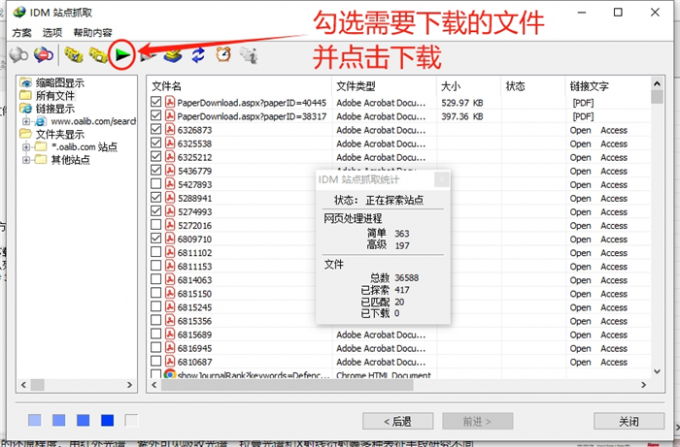
网页文件批量下载工具有哪些 网页文件批量下载工具推荐 IDM免费激活 网络下载加速器
把任务丢给软件,把时间还给自己,批量下载功能让下载变得更高效。它可以有效减少重复性操作,只需要一次简单的设置,就能把大量文件下载到电脑。有关网页文件批量下载工具有哪些,网页文件批量下载工具推荐的问题…...

嵌入式算法开发系列之图像处理算法
嵌入式系统中的图像处理算法及其应用 文章目录 嵌入式系统中的图像处理算法及其应用前言一、图像处理算法的原理二、图像处理算法的应用三、C 语言实现总结 前言 在嵌入式系统中,图像处理算法是一项重要的技术,用于实现各种视觉应用,如机器视…...

HarmonyOS4-ArkUI组件动画
一、ArkUI组件属性动画和显示动画 显示动画: 案例:上下左右箭头控制小鱼的游动 具体代码如下: import router from ohos.routerEntry Component struct AnimationPage {// 小鱼坐标State fishX: number 200State fishY: number 180// 小鱼…...

模块化——如何导入模块?(内置模块与自定义模块)
在Node.js中,要导入另一个模块,我们可以使用require函数。这个函数接受一个文件路径参数,并返回导入的模块。 注意:require导入包场景:内置模块、自定义模块、npm包的导入... 下面介绍内置模块与自定义模块。npm包的…...

element-ui的按需引入报错解决:MoudleBuildFailed,完整引入和按需引入
官网: Element - The worlds most popular Vue UI framework 1.完整引入 (1)下载: npm i element-ui -S (2)引入: 在 main.js 中写入以下内容: import Vue from vue; impor…...
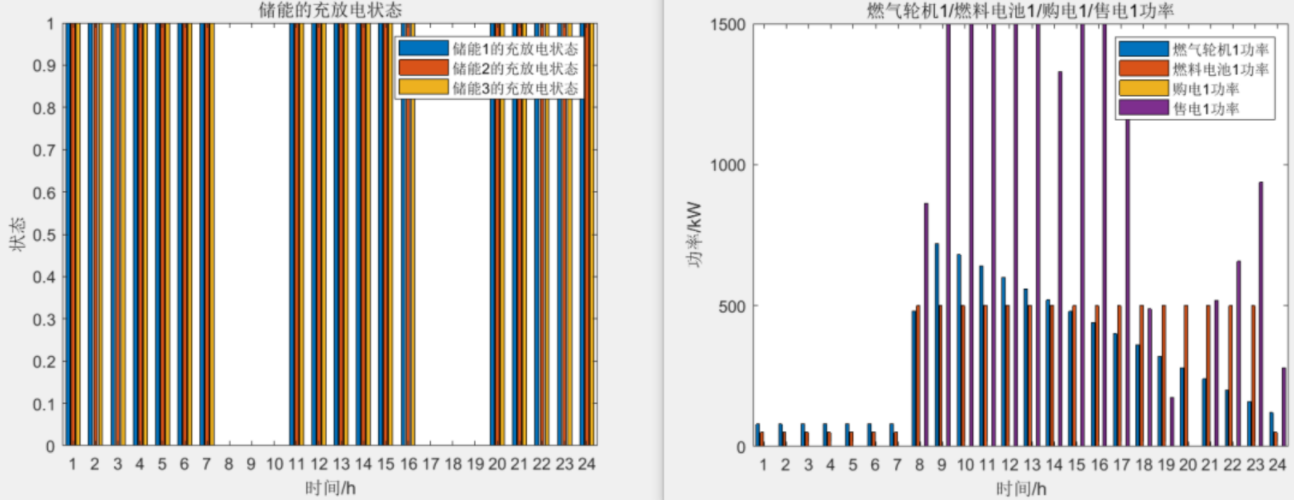
面向低碳经济运行目标的多微网能量互联优化调度matlab程序
微❤关注“电气仔推送”获得资料(专享优惠) 运用平台 matlabgurobi 程序简介 该程序为多微网协同优化调度模型,系统在保障综合效益的基础上,调度时优先协调微网与微网之间的能量流动,将与大电网的互联交互作为备用…...
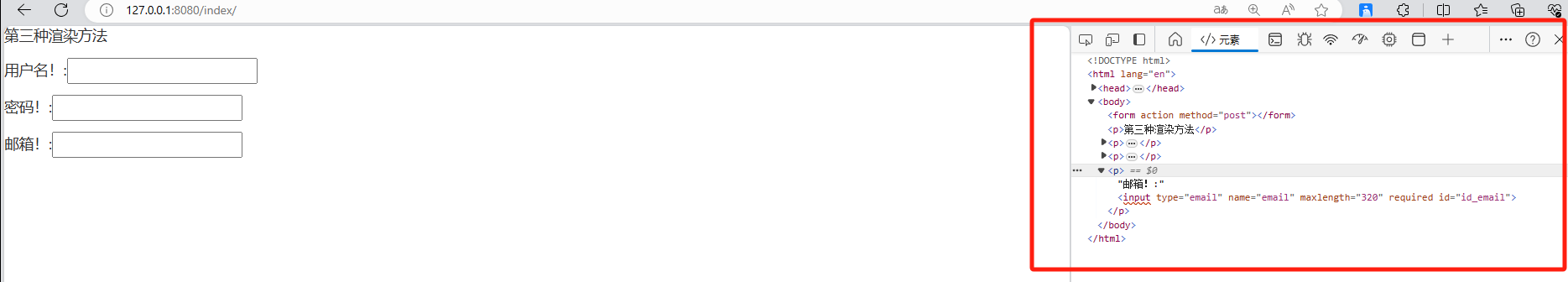
FORM的引入与使用
FORM的引入与使用 【0】引入 表单(Form)是网页中用于收集用户输入数据的一种交互元素。通过表单,用户可以输入文本、选择选项、上传文件等操作。表单通常由一个或多个输入字段(Input Field)组成,每个字…...

酷开会员丨古偶悬疑剧《花间令》在酷开系统热播中!
酷开系统一直致力于为用户提供卓越的大屏娱乐体验。随着三月新剧《花间令》的上线,酷开系统再次展现了其在内容更新上的迅速响应能力和对高质量视听体验的不懈追求。 《花间令》的故事背景设定在一个充满神秘色彩的古代王朝,鞠婧祎饰演的女主角与刘学义饰…...

html骨架以及常见标签
推荐一个网站mdn。 html语法 双标签:<标签 属性"属性值">内容</标签> 属性:给标签提供附加信息。大多数属性以键值对的形式存在。如果属性名和属性值一样,可以致谢属性值。 单标签:<标签 属性"属…...
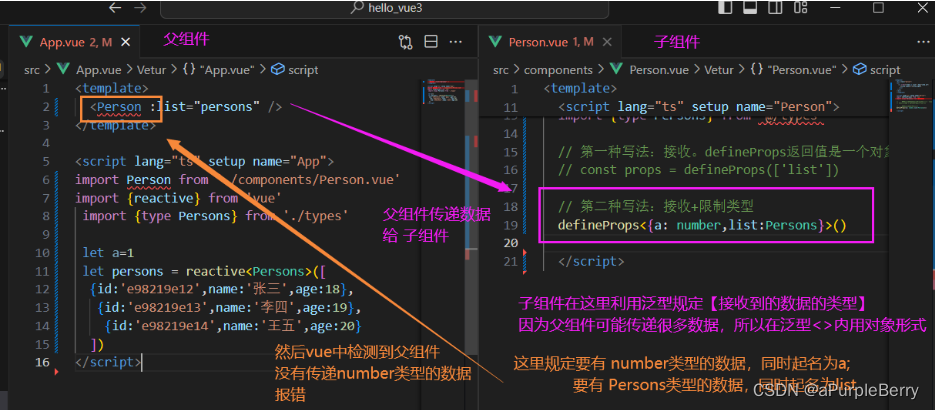
Vue3学习01 Vue3核心语法
Vue3学习 1. Vue3新的特性 2. 创建Vue3工程2.1 基于 vue-cli 创建项目文件说明 2.2 基于 vite 创建具体操作项目文件说明 2.3 简单案例(vite) 3. Vue3核心语法3.1 OptionsAPI 与 CompositionAPIOptions API 弊端Composition API 优势 ⭐3.2 setup小案例setup返回值setup 与 Opt…...

Spring Boot实现跨域的5种方式
Spring Boot实现跨域的5种方式 为什么会出现跨域问题什么是跨域非同源限制java后端实现CORS跨域请求的方式返回新的CorsFilter(全局跨域)重写WebMvcConfigurer(全局跨域)使用注解(局部跨域)手动设置响应头(局部跨域)使用自定义filter实现跨域 为什么会出现跨域问题 出于浏览器…...

OpenClaw-DingTalk终极指南:Stream模式钉钉机器人企业级部署实战
OpenClaw-DingTalk终极指南:Stream模式钉钉机器人企业级部署实战 【免费下载链接】openclaw-channel-dingtalk Dingtalk channel plugin for OpenClaw 项目地址: https://gitcode.com/gh_mirrors/op/openclaw-channel-dingtalk OpenClaw-DingTalk是一款专为O…...
)
深入浅出:从原理到实践,手把手教你理解并校准RV1126 ISP的黑电平(BLC)
深入浅出:从原理到实践,手把手教你理解并校准RV1126 ISP的黑电平(BLC) 在数字图像处理领域,黑电平校准(Black Level Calibration, BLC)是一个看似简单却至关重要的环节。想象一下,当你用专业相机拍摄星空时…...

如何快速掌握正则表达式示例生成器:从入门到精通的完整指南
如何快速掌握正则表达式示例生成器:从入门到精通的完整指南 【免费下载链接】regexp-examples Generate strings that match a given regular expression 项目地址: https://gitcode.com/gh_mirrors/re/regexp-examples 正则表达式示例生成器(reg…...
前端路由缓存:include与exclude配置策略)
cool-admin(midway版)前端路由缓存:include与exclude配置策略
cool-admin(midway版)前端路由缓存:include与exclude配置策略 【免费下载链接】cool-admin-midway 🔥 cool-admin(midway版)一个很酷的后台权限管理框架,模块化、插件化、CRUD极速开发,永久开源免费,基于midway.js 3.x…...

阿里云省钱攻略:优惠券领取与使用一看就会
阿里云是阿里巴巴集团旗下云计算品牌,凭借其强大的计算能力和丰富的云服务产品,成为众多企业和个人开发者的首选。然而,如何在享受云服务的同时有效控制成本,成为大家关注的焦点。本文将详细介绍阿里云优惠券的领取与使用技巧&…...

PyTorch模型转ONNX避坑指南:从repeat_interleave到Concat类型匹配的实战解决方案
PyTorch模型转ONNX避坑指南:从动态张量到类型匹配的深度解决方案 在模型部署的最后一公里,PyTorch到ONNX的转换常常成为绊倒开发者的隐蔽陷阱。当你在本地训练环境获得完美指标后,准备将模型推向生产时,各种意想不到的导出错误可能…...

从零搭建PointRCNN:Linux环境配置与3D检测可视化实战
1. 环境准备:从零搭建Linux深度学习工作站 第一次在Linux系统上配置深度学习环境时,我盯着命令行界面手足无措的样子还历历在目。现在回想起来,其实只要掌握几个关键步骤,就能快速搭建好PointRCNN所需的运行环境。我们以配备NVIDI…...

Qwen3.5-9B镜像免配置实战:Docker化迁移与端口映射最佳实践
Qwen3.5-9B镜像免配置实战:Docker化迁移与端口映射最佳实践 1. 项目概述 Qwen3.5-9B是一个拥有90亿参数的开源大语言模型,具备强大的逻辑推理、代码生成和多轮对话能力。该模型支持多模态理解(图文输入)和长上下文处理ÿ…...

Phi-3-mini-4k-instruct-gguf步骤详解:supervisor服务管理与错误日志定位方法
Phi-3-mini-4k-instruct-gguf步骤详解:supervisor服务管理与错误日志定位方法 1. 模型概述 Phi-3-mini-4k-instruct-gguf是微软Phi-3系列中的轻量级文本生成模型GGUF版本,特别适合问答、文本改写、摘要整理和简短创作等场景。这个开箱即用的解决方案已…...

Win11共享打印机连接失败?绕过安全策略的终极指南
1. Win11共享打印机连接失败的真相 最近帮朋友处理Win11共享打印机的问题时,发现这个看似简单的操作居然能卡住这么多人。明明按照传统方法一步步操作,却总是提示各种错误。其实这背后是微软在Win11 22H2版本后引入的新安全策略在作祟 - 他们默认关闭了S…...