TiDB 慢查询日志分析
导读
TiDB 中的慢查询日志是一项 关键的性能监控工具,其主要作用在于协助数据库管理员追踪执行时间较长的 SQL 查询语句。 通过记录那些超过设定阈值的查询,慢查询日志为性能优化提供了关键的线索,有助于发现潜在的性能瓶颈,优化索引以及重构查询语句,从而提升数据库的整体性能。 本文将主要介绍 TiDB 中慢查询日志的功能,并探讨常用的慢查询日志分析方法 。
本文作者 :王勇,中金公司信息技术部高级架构师,负责中金公司盘古 PaaS 、中间件、数据库规划建设以及公司整体信息技术应用创新、开源治理工作,助力多个投行核心系统国产化落地。
慢查询相关参数
- tidb_enable_slow_log :用于控制是否开启 slow log 功能。
- tidb_slow_log_threshold :设置慢日志的阈值,执行时间超过阈值的 SQL 语句将被记录到慢日志中。默认值是 300 ms。
- tidb_query_log_max_len :设置慢日志记录 SQL 语句的最大长度。默认值是 4096 byte。
- tidb_redact_log :设置慢日志记录 SQL 时是否将用户数据脱敏用 ? 代替。默认值是 0 ,即关闭该功能。
- tidb_enable_collect_execution_info :设置是否记录执行计划中各个算子的物理执行信息,默认值是 1 。
慢查询日志原理
TiDB 的慢查询日志原理与 MySQL 一致,在每条 SQL 执行结束时,并且执行时间超过慢日志阈值时,会把 SQL 执行相关信息记录到慢日志中,同样的 SQL 多次执行超过阈值都会记录。
分析慢查询日志
由于 TiDB 是采用存算分离架构的分布式数据库,在这种架构下,每个 TiDB Server 节点都会产生慢日志。为方便查询慢日志,TiDB 提供了内存映射表 INFORMATION_SCHEMA.SLOW_QUERY ,并在 TiDB Dashboard 中提供专门的界面用于搜索和查看慢查询日志。官方文档中也提供了多种常见的慢查询日志查询语句,参考:慢查询日志 ( https://docs.pingcap.com/zh/tidb/v7.1/identify-slow-queries#查询-slow_querycluster_slow_query-示例 )。
然而,在系统高负载或异常情况下,短时间内生成过多慢 SQL 导致慢 SQL 变得难以分析,这也是像 MySQL 等数据库提供慢日志分析工具的原因,例如 mysqldumpslow 、 pt-query-digest 等工具。这些工具通常以某种聚合的方式输出结果,使结果更加清晰易懂。借鉴这些工具的思路,笔者开发了一条常用的慢日志分析 SQL,以更便捷地处理慢查询日志。
1 慢日志聚合查询 SQL
-- 慢查询日志,聚合查询
WITH ss AS
(SELECT s.Digest ,s.Plan_digest,
count(1) exec_count,
sum(s.Succ) succ_count,
round(sum(s.Query_time),4) sum_query_time,
round(avg(s.Query_time),4) avg_query_time,
sum(s.Total_keys) sum_total_keys,
avg(s.Total_keys) avg_total_keys,
sum(s.Process_keys) sum_process_keys,
avg(s.Process_keys) avg_process_keys,
min(s.`Time`) min_time,
max(s.`Time`) max_time,
round(max(s.Mem_max)/1024/1024,4) Mem_max,
round(max(s.Disk_max)/1024/1024,4) Disk_max,
avg(s.Result_rows) avg_Result_rows,
max(s.Result_rows) max_Result_rows,
sum(Plan_from_binding) Plan_from_binding
FROM information_schema.cluster_slow_query s
WHERE s.time>=adddate(now(),INTERVAL -1 DAY)
AND s.time<=now()
AND s.Is_internal =0
-- AND UPPER(s.query) NOT LIKE '%ANALYZE TABLE%'
-- AND UPPER(s.query) NOT LIKE '%DBEAVER%'
-- AND UPPER(s.query) NOT LIKE '%ADD INDEX%'
-- AND UPPER(s.query) NOT LIKE '%CREATE INDEX%'
GROUP BY s.Digest ,s.Plan_digest
ORDER BY sum(s.Query_time) desc
LIMIT 35)
SELECT ss.Digest, -- SQL Digest
ss.Plan_digest, -- PLAN Digest
(SELECT s1.Query FROM information_schema.cluster_slow_query s1 WHERE s1.Digest=ss.digest AND s1.time>=ss.min_time AND s1.time<=ss.max_time LIMIT 1) query, -- SQL文本
(SELECT s2.plan FROM information_schema.cluster_slow_query s2 WHERE s2.Plan_digest=ss.plan_digest AND s2.time>=ss.min_time AND s2.time<=ss.max_time LIMIT 1) plan, -- 执行计划
ss.exec_count, -- SQL总执行次数
ss.succ_count, -- SQL执行成功次数
ss.sum_query_time, -- 总执行时间(秒)
ss.avg_query_time, -- 平均单次执行时间(秒)
ss.sum_total_keys, -- 总扫描key数量
ss.avg_total_keys, -- 平均单次扫描key数量
ss.sum_process_keys, -- 总处理key数量
ss.avg_process_keys, -- 平均单次处理key数量
ss.min_time, -- 查询时间段内第一次SQL执行结束时间
ss.max_time, -- 查询时间段内最后一次SQL执行结束时间
ss.Mem_max, -- 单次执行中内存占用最大值(MB)
ss.Disk_max, -- 单次执行中磁盘占用最大值(MB)
ss.avg_Result_rows, -- 平均返回行数
ss.max_Result_rows, -- 单次最大返回行数
ss.Plan_from_binding -- 走SQL binding的次数
FROM ss;这条 SQL 是笔者常用的一条慢查询分析语句,大家可以根据个人需要灵活地调整排序字段、查询字段和查询条件,以满足不同场景下的分析需求。
在这个 SQL 中,query 和 plan 字段是使用标量子查询的方式获取。经过测试,这种写法相比直接使用 group by,能够节省大量内存,所以能够分析更长时间段的慢查询。
既然是聚合查询,为什么不直接用 statements_summary_history 表呢?笔者觉得有三点原因,一是 statements_summary_history 由于本身是半小时的聚合数据,在应对短时间段的性能分析时可能不够精细。二是早期版本的 statements_summary_history 是纯内存表,可能由于 TiDB Server OOM 重启而导致数据丢失,而慢查询日志是存储在文件中的,因此 TiDB Server OOM 重启不会导致慢查询日志丢失。三是 statements_summary_history 有容量限制,记录的 SQL 可能被驱逐出去,而慢查询日志默认记录超过 300 毫秒的查询,已满足分析需求了。
2 单条 SQL 执行历史
SELECT
date_format(adddate(s.Time,interval - s.Query_time second),'%Y-%m-%d %H') sql_exec_start,
count(1) exec_cnt,
sum(s.Succ) succ_cnt,
count(distinct s.Plan_digest) plan_cnt,
case when count(distinct s.Plan_digest)<5 then group_concat(distinct substr( s.Plan_digest,1,4)) else null end plan_digest,
round(sum(s.Query_time),4) sum_q_time,
round(avg(s.Query_time),4) avg_q_time,
sum(s.Total_keys) sum_t_keys,
round(avg(s.Total_keys),4) avg_t_keys,
sum(s.Process_keys) sum_p_keys,
avg(s.Process_keys) avg_p_keys,
round(max(s.Mem_max/1024/1024),2) Mem_max_m,
round(max(s.Disk_max/1024/1024),2) Disk_max_m,
round(avg(s.Result_rows),4) avg_rows,
max(s.Result_rows) max_rows,
sum(Plan_from_binding) PFB
from information_schema.cluster_slow_query s
where s.digest='a0adeeb79b71315ac13a77f3f11162106b5ec7b48212cf17c20c754263ab9228'
and time>=adddate(now(),interval -3 day)
and time<=now()
group by date_format(adddate(s.Time,interval - s.Query_time second),'%Y-%m-%d %H')
order by 1 desc;这条 SQL 是笔者常用的另一条慢查询分析语句,用于分析单个 SQL 的历史执行情况。通过这个查询,可以清晰地了解特定 SQL 在历次执行中的变化,包括执行计划、扫描数据量、执行时间等方面的情况。
收集慢查询日志脚本
这个脚本用于生成 HTML 格式的慢日志分析结果,结合定时任务和 Nginx 的自动索引功能,可以轻松地收集和查看各个 TiDB 集群的慢日志。
脚本请在这个链接取: https://asktug.com/t/topic/1022684
效果展示:
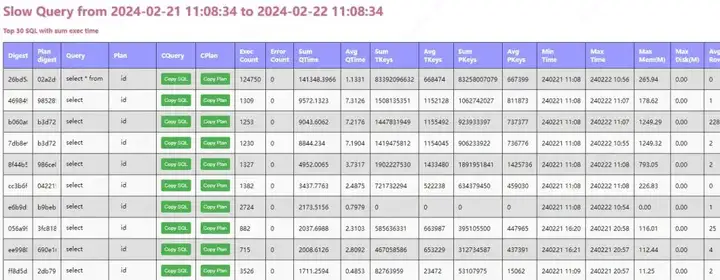
总结
本文阐述了 TiDB 慢查询日志的相关配置和原理,并分享了笔者在实际工作中使用的慢查询日志分析 SQL。为读者提供了一种实际而有效的慢查询日志分析思路。
相关文章:
TiDB 慢查询日志分析
导读 TiDB 中的慢查询日志是一项 关键的性能监控工具,其主要作用在于协助数据库管理员追踪执行时间较长的 SQL 查询语句。 通过记录那些超过设定阈值的查询,慢查询日志为性能优化提供了关键的线索,有助于发现潜在的性能瓶颈,优化…...
网页文件批量下载工具有哪些 网页文件批量下载工具推荐 IDM免费激活 网络下载加速器
把任务丢给软件,把时间还给自己,批量下载功能让下载变得更高效。它可以有效减少重复性操作,只需要一次简单的设置,就能把大量文件下载到电脑。有关网页文件批量下载工具有哪些,网页文件批量下载工具推荐的问题…...

嵌入式算法开发系列之图像处理算法
嵌入式系统中的图像处理算法及其应用 文章目录 嵌入式系统中的图像处理算法及其应用前言一、图像处理算法的原理二、图像处理算法的应用三、C 语言实现总结 前言 在嵌入式系统中,图像处理算法是一项重要的技术,用于实现各种视觉应用,如机器视…...

HarmonyOS4-ArkUI组件动画
一、ArkUI组件属性动画和显示动画 显示动画: 案例:上下左右箭头控制小鱼的游动 具体代码如下: import router from ohos.routerEntry Component struct AnimationPage {// 小鱼坐标State fishX: number 200State fishY: number 180// 小鱼…...

模块化——如何导入模块?(内置模块与自定义模块)
在Node.js中,要导入另一个模块,我们可以使用require函数。这个函数接受一个文件路径参数,并返回导入的模块。 注意:require导入包场景:内置模块、自定义模块、npm包的导入... 下面介绍内置模块与自定义模块。npm包的…...

element-ui的按需引入报错解决:MoudleBuildFailed,完整引入和按需引入
官网: Element - The worlds most popular Vue UI framework 1.完整引入 (1)下载: npm i element-ui -S (2)引入: 在 main.js 中写入以下内容: import Vue from vue; impor…...
面向低碳经济运行目标的多微网能量互联优化调度matlab程序
微❤关注“电气仔推送”获得资料(专享优惠) 运用平台 matlabgurobi 程序简介 该程序为多微网协同优化调度模型,系统在保障综合效益的基础上,调度时优先协调微网与微网之间的能量流动,将与大电网的互联交互作为备用…...
FORM的引入与使用
FORM的引入与使用 【0】引入 表单(Form)是网页中用于收集用户输入数据的一种交互元素。通过表单,用户可以输入文本、选择选项、上传文件等操作。表单通常由一个或多个输入字段(Input Field)组成,每个字…...

酷开会员丨古偶悬疑剧《花间令》在酷开系统热播中!
酷开系统一直致力于为用户提供卓越的大屏娱乐体验。随着三月新剧《花间令》的上线,酷开系统再次展现了其在内容更新上的迅速响应能力和对高质量视听体验的不懈追求。 《花间令》的故事背景设定在一个充满神秘色彩的古代王朝,鞠婧祎饰演的女主角与刘学义饰…...

html骨架以及常见标签
推荐一个网站mdn。 html语法 双标签:<标签 属性"属性值">内容</标签> 属性:给标签提供附加信息。大多数属性以键值对的形式存在。如果属性名和属性值一样,可以致谢属性值。 单标签:<标签 属性"属…...
Vue3学习01 Vue3核心语法
Vue3学习 1. Vue3新的特性 2. 创建Vue3工程2.1 基于 vue-cli 创建项目文件说明 2.2 基于 vite 创建具体操作项目文件说明 2.3 简单案例(vite) 3. Vue3核心语法3.1 OptionsAPI 与 CompositionAPIOptions API 弊端Composition API 优势 ⭐3.2 setup小案例setup返回值setup 与 Opt…...

Spring Boot实现跨域的5种方式
Spring Boot实现跨域的5种方式 为什么会出现跨域问题什么是跨域非同源限制java后端实现CORS跨域请求的方式返回新的CorsFilter(全局跨域)重写WebMvcConfigurer(全局跨域)使用注解(局部跨域)手动设置响应头(局部跨域)使用自定义filter实现跨域 为什么会出现跨域问题 出于浏览器…...
Elasticsearch:从 ES|QL 到 PHP 对象
作者:来自 Elastic Enrico Zimuel 从 elasticsearch-php v8.13.0 开始,你可以执行 ES|QL 查询并将结果映射到 stdClass 或自定义类的 PHP 对象。 ES|QL ES|QL 是 Elasticsearch 8.11.0 中引入的一种新的 Elasticsearch 查询语言。 目前,它在…...
Stm32 HAL库 访问内部flash空间
Stm32 HAL库 访问内部flash空间 代码的部分串口配置申明文件main函数 在一些时候,需要存储一些数据,但是又不想接外部的flash,那我们可以知道,其实还有内部的flash可以使用, 需要注意的是内部flash,读写次数…...

线程池详解
线程池 什么是线程池:线程池就是管理一系列线程的资源池。 当有任务要处理时,直接从线程池中获取线程来处理,处理完之后线程并不会立即被销毁,而是等待下一个任务。 为什么要用线程池 / 线程池的好处: **降低资源消…...

mybatis(5)参数处理+语句查询
参数处理+语句查询 1、简单单个参数2、Map参数3、实体类参数4、多参数5、Param注解6、语句查询6.1 返回一个实体类对象6.2 返回多个实体类对象 List<>6.3 返回一个Map对象6.4 返回多个Map对象 List<Map>6.5 返回一个大Map6.6 结果映射6.6.1 使用resultM…...
数据应用OneID:ID-Mapping Spark GraphX实现
前言 说明 以用户实体为例,ID 类型包含 user_id 和 device_id。当然还有其他类型id。不同id可以获取到的阶段、生命周期均不相同。 device_id 生命周期通常指的是一个设备从首次被识别到不再活跃的整个时间段。 user_id是用户登录之后系统分配的唯一标识ÿ…...
第6章 6.2.3 : readlines和writelines函数 (MATLAB入门课程)
讲解视频:可以在bilibili搜索《MATLAB教程新手入门篇——数学建模清风主讲》。 MATLAB教程新手入门篇(数学建模清风主讲,适合零基础同学观看)_哔哩哔哩_bilibili 在MATLAB的文本数据处理任务中,导入和导出文件是常…...

Matlab应用层生成简述
基础软件层 目前接触到的几款控制器,其厂商并没有提供simulink的基础软件库一般为底层文件被封装为lib,留有供调用API接口虽然能根据API接口开发基础软件库,但耗费时间过长得不偿失 应用层 所以可以将应用层封装为一个子系统,其…...

每日一题(leetcode1702):修改后的最大二进制字符串--思维
找到第一个0之后,对于后面的子串(包括那个0),所有的0都能调上来,然后一一转化为10,因此从找到的第一个0的位置开始,接下来是(后半部分子串0的个数-1)个1,然后…...

即时通讯私有化,BeeWorks让每一次内网沟通都安全、安心、高效
BeeWorks以全维度安全防护体系为支撑,将安全设计深度融入每一项核心功能,让员工在日常办公中既能享受高效协同,又能全程守护企业核心数据安全。同时,规范的使用操作是发挥安全优势的关键,本文将重点介绍BeeWorks核心功…...

UE4实战:利用VaRest与VictoryBPLibrary实现高效本地文件读写
1. 为什么需要本地文件读写 在虚幻引擎4开发过程中,我们经常需要保存游戏配置、玩家进度或者关卡数据。想象一下你正在开发一个RPG游戏,需要记录玩家背包里的所有物品、当前任务进度和角色属性。如果每次退出游戏这些数据都消失,玩家肯定会抓…...

基于SpringBoot + Vue的校园流浪动物救助平台
文章目录前言一、详细操作演示视频二、具体实现截图三、技术栈1.前端-Vue.js2.后端-SpringBoot3.数据库-MySQL4.系统架构-B/S四、系统测试1.系统测试概述2.系统功能测试3.系统测试结论五、项目代码参考六、数据库代码参考七、项目论文示例结语前言 💛博主介绍&#…...

Linux环境下Oracle 19C补丁安装保姆级教程:从下载到验证的完整流程
Linux环境下Oracle 19C补丁安装全流程实战指南 在数据库运维工作中,补丁管理是确保系统安全稳定运行的关键环节。Oracle 19C作为当前长期支持版本,其补丁安装过程虽然标准化程度高,但实际操作中仍存在不少容易踩坑的细节。本文将基于实战经验…...
)
告别手动爆肝:用AiScan-N自动化你的CTF Web漏洞测试(SQL注入/文件上传实战)
智能渗透测试革命:AiScan-N在CTF中的实战应用与效率跃升 当凌晨三点的CTF比赛进入白热化阶段,你的眼皮开始打架,而对手却像永动机般不断提交flag——这种场景下,传统手动渗透测试的局限性暴露无遗。我曾亲眼见证一位资深红队成员…...
你了解吗?)
从IPv4到IPv6:除了地址变长,这些‘隐藏’特性(流标签、扩展头、无状态配置)你了解吗?
从IPv4到IPv6:除了地址变长,这些‘隐藏’特性(流标签、扩展头、无状态配置)你了解吗? 当大多数人谈论IPv6时,第一反应往往是"地址长度从32位扩展到128位"。但地址空间的扩展只是IPv6最表层的改进…...

如何高效使用开源工具EnergyStarX提升Windows 11电池续航:完整实战指南
如何高效使用开源工具EnergyStarX提升Windows 11电池续航:完整实战指南 【免费下载链接】EnergyStarX 🔋 Improve your Windows 11 devices battery life. A WinUI 3 GUI for https://github.com/imbushuo/EnergyStar. 项目地址: https://gitcode.com/…...

逆向思维:从资源困境到自由获取,猫抓如何重塑你的网页体验
逆向思维:从资源困境到自由获取,猫抓如何重塑你的网页体验 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾面对心仪…...
)
vue路由跳转打开新窗口并携带参数(vue2/vue3)
概要 在一些需求中经常遇到跳转页面,但是产品让跳转页面的同时打开一个新窗口方便用户进行对比数据,接下来就是跳转页面打开新窗口的方法 vue2的写法 const routeUrl this.$router.resolve({path: "/页面路由",query: { id: xx参数 },});wi…...

GyverDS18库:工业级DS18B20单总线温度驱动设计与实践
1. GyverDS18库深度解析:面向工业级应用的DS18B20全功能驱动设计Dallas DS18B20是业界最成熟的单总线数字温度传感器之一,凭借其独特的1-Wire协议、无需外部ADC、支持多点组网及寄生供电能力,在工业监控、环境监测、智能家电等领域广泛应用。…...