数据应用OneID:ID-Mapping Spark GraphX实现
前言
说明
以用户实体为例,ID 类型包含 user_id 和 device_id。当然还有其他类型id。不同id可以获取到的阶段、生命周期均不相同。
device_id 生命周期通常指的是一个设备从首次被识别到不再活跃的整个时间段。
user_id是用户登录之后系统分配的唯一标识,即使不同的设备只要user_id相同就会识别为一个用户,但 user_id 只能在登录后获取到,所以会损失用户登录前的行为数据。
单体应用单独使用user_id或者device_id都不能完整地表达一个用户,多应用多类id又有差异性。如果可以将不同 ID 进行关联映射,最终通过唯一的 ID 标识用户。所以需要一个解决方案来映射。
用户渠道
- 手机、平板电脑
- 安卓手机、ios手机
- 有PC、APP和小程序
标识情况
(1)cookieid:PC站存在用户cookies中的ID,会被清理电脑时重生成。
(2)unionid:微信提供的唯一身份认证。
(3)mac:手机网卡物理地址。
(4)imei(入网许可证序号):安卓系统可取到。
(5)imsi(手机SIM卡序号):安卓系统可取到。
(6)androidid :安卓系统id。
(7)openid (app自己生成的序号) :卸载重装app就会变更。
(8)idfa(广告跟踪码):用户可重置。
(9)deviceid(app日志采集埋点开发人员自己定义一种逻辑id,可能取自 android,imei,openudid等):逻辑上的id。
还有其他不同应用设定标识用户的ID. . . . . .
设备与登录用户分析
1. device_id 作为唯一
场景
适用登录率比较低的应用。
缺点
- 不同用户登录一个设备,会识别为一个用户。
- 同一个用户使用不同设备,会识别为多个用户。
2. 一个device_id关联一个user_id
场景
同一个设备登陆前(device_id) 和登录后(user_id) 可以绑定。
缺点
- 一个未被绑定的设备登录前的用户和登录后的用户不同,这个时候会被错误地识别为同一个用户。
- 一个被绑定的设备后续被其他用户在未登录状态下使用,也会被错误地识别为之前被绑定的用户。
- 一个被绑定了的用户使用其他设备时,未登录状态下的数据不会标识为该用户数据。
3. 多个device_id关联一个user_id
场景
只要登录后的 user_id 相同,其多个设备上登录前后的数据都可以连通起来。
缺点
一个 device_id只能绑定到一个用户,当其他用户使用同一个已被绑定的设备时,其登录前数据还是会被识别成已绑定到该设备的用户。
4. 多个应用间的不同ID进行关联
场景
当存在多个应用,实现应用间 ID 映射和数据相通时。比如,通过手机号,邮箱号,微信号等等可以统一为一个 ID。
缺点
复杂性高。
5. 行业内方案
网易ID-Mapping
网易产品线:网易云音乐,邮箱,新闻,严选等等,不同的应用有不同的ID,比如:phone,email,yanxuan_id,music_id 等等
思路与方案
- 结合各种应用账号,各种设备型号之间的关系,以及设备使用规律,比如时间和频次。
- 采用规则过滤 和 数据挖掘,判断账号是否属于同一个人。
存在问题和方案
- 用户有多个设备信息:使用一定时间 和 频次才进行关联。
- 设备以后从来不用:设定设备未使用衰减函数。
6. 其他
美团采用手机号、微信、微博、美团账号的登录方式;大众点评采用的手机号、微信、QQ、微博的登录方式;其交集为手机号、微信、微博。最终,对于注册用户账户体系,美团采用了手机号作为用户的唯一标识。
图计算
图计算的核心思想:将数据表达成“点”,点和点之间可以通过某种业务含义建立“边”。然后,我们就可以从点、边上找出各种类型的数据关系。
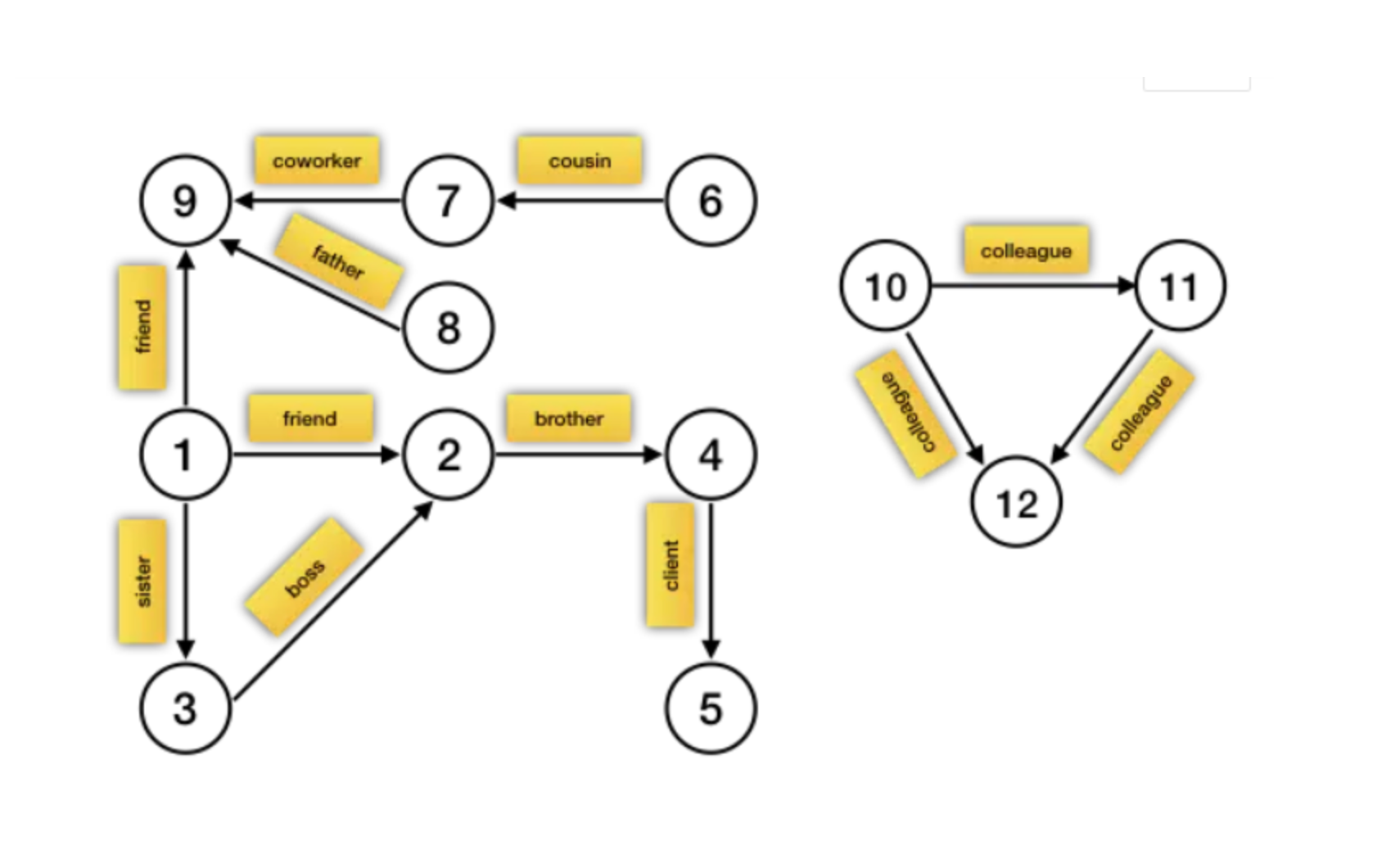
在GraphX中,图由顶点(Vertices)和边(Edges)组成:
- 顶点(Vertices):图中的点,代表实体,例如人、商品或事件。
- 边(Edges):连接两个顶点的线,代表实体之间的关系,例如朋友关系、购买行为或网络连接。
- 边的属性(Edge Attributes):边的附加信息,可以是权重、成本或其他相关数据。
- 顶点的属性(Vertex Attributes):顶点的附加信息,可以是标签、状态或其他相关数据。
首先通过一个案例先认识下图计算。
案例:朋友关系的连通性
首先,需要将这些数据转换为Vertex和Edge对象
假设有以下数据:user_id: A, friend_id: B
user_id: B, friend_id: C
user_id: C, friend_id: D
user_id: D, friend_id: E
user_id: E, friend_id: F
user_id: F, friend_id: G
user_id: G, friend_id: H
user_id: H, friend_id: I
user_id: I, friend_id: Jimport org.apache.spark._
import org.apache.spark.graphx._val conf = new SparkConf().setAppName("Graph Example").setMaster("local[*]")
val sc = new SparkContext(conf)// 将原始数据转换为Vertex和Edge对象
val vertices: RDD[(VertexId, String)] = sc.parallelize(Seq((1L, "A"), (2L, "B"), (3L, "C"), (4L, "D"), (5L, "E"),(6L, "F"), (7L, "G"), (8L, "H"), (9L, "I"), (10L, "J"))
)val edges: RDD[Edge[String]] = sc.parallelize(Seq(Edge(1L, 2L,"friend"), Edge(2L, 3L,"friend"), Edge(3L, 4L,"friend"),Edge(4L, 5L,"friend"), Edge(5L, 6L,"friend"), Edge(6L, 7L,"friend"),Edge(7L, 8L,"friend"), Edge(8L, 9L,"friend"),Edge(9L, 10L,"friend"), Edge(10L, 1L,"friend")
))// 创建图
val graph: Graph[String,String] = Graph(vertices, edges)
// triplets同时存储了边属性和对应顶点信息
graph.triplets.foreach(println)((4,D),(5,E),friend)
((5,E),(6,F),friend)
((9,I),(10,J),friend)
((10,J),(1,A),friend)
......// 连通性:可以将每个顶点都关联到连通图里的最小顶点
val value = graph.connectedComponents()
value.vertices.map(tp => (tp._2, tp._1)).groupByKey().collect().foreach(println)结果:(1,CompactBuffer(8, 1, 9, 10, 2, 3, 4, 5, 6, 7))如果修改:Edge(5L, 1L,"friend") Edge(10L, 5L,"friend")val edges: RDD[Edge[String]] = sc.parallelize(Seq(Edge(1L, 2L,"friend"), Edge(2L, 3L,"friend"), Edge(3L, 4L,"friend"),Edge(4L, 5L,"friend"), Edge(5L, 1L,"friend"), Edge(6L, 7L,"friend"),Edge(7L, 8L,"friend"), Edge(8L, 9L,"friend"),Edge(9L, 10L,"friend"), Edge(10L, 5L,"friend")
))结果:
(1,CompactBuffer(1, 2, 3, 4))
(5,CompactBuffer(8, 9, 10, 5, 6, 7))ID-Mapping 简单实现
val conf = new SparkConf().setAppName("Graph Example").setMaster("local[*]")
val sc = new SparkContext(conf)
// 假设我们有三个数据集
val userMappingData = sc.parallelize(Seq((11L,111L), // phone,device_id(22L,222L)
))val userInfoData = sc.parallelize(Seq((11L, 1111L), // phone,open_id,这里把phone当作user_id(22L, 2222L)
))val userLoginData = sc.parallelize(Seq((1111L, 11111L, 111111L), // open_id,idfa,idfy(2222L, 22222L, 222222L)
))// 为每个数据集创建顶点RDD
// val userVertices = userMappingData.flatMap(item =>{
// for (element <- item.productIterator)
// yield (element,element)
// })val phoneVertices = userMappingData.map { case (phone, _) => (phone, "phone") }
val deviceVertices = userMappingData.map { case (_, deviceId) => (deviceId, "deviceId") }val userPhoneVertices = userInfoData.map { case (phone,_) => (phone, "phone") }
val openidVertices = userInfoData.map { case (_, openId) => (openId, "openId") }val idfaVertices = userLoginData.flatMap { case (openId, idfa, _) => Seq((openId, "openid"), (idfa, "idfa")) }
val idfvVertices = userLoginData.flatMap { case (openId, _, idfv) => Seq((openId, "openid"), (idfv, "idfv")) }// 合并所有顶点RDD
val allVertices = phoneVertices.union(deviceVertices).union(userPhoneVertices).union(openidVertices).union(idfaVertices).union(idfvVertices)// 创建边RDD
val mappingEdges = userMappingData.map { case (phone, deviceId) => Edge(phone, deviceId, "maps_to") }
val infoEdges = userInfoData.map { case (phone, openid) => Edge(phone, openid, "linked_to") }
val loginEdges = userLoginData.flatMap { case (openid, idfa, idfv) =>Seq(Edge(openid, idfa, "logins_with"), Edge(openid, idfv, "logins_with"))
}// 合并所有边RDD
val allEdges = mappingEdges.union(infoEdges).union(loginEdges)val graph = Graph(allVertices, allEdges)graph.triplets.map(item=> "点 and 边:"+item).foreach(println)点 and 边:((22,phone),(222,deviceId),maps_to)
点 and 边:((11,phone),(111,deviceId),maps_to)
点 and 边:((11,phone),(1111,openId),linked_to)
点 and 边:((22,phone),(2222,openId),linked_to)
点 and 边:((1111,openId),(11111,idfa),logins_with)
点 and 边:((1111,openId),(111111,idfv),logins_with)
点 and 边:((2222,openId),(22222,idfa),logins_with)
点 and 边:((2222,openId),(222222,idfv),logins_with)val value = graph.connectedComponents()
value.vertices.map(tp => (tp._2, tp._1)).groupByKey().collect().foreach(println)(11,CompactBuffer(1111, 11, 111, 11111, 111111))
(22,CompactBuffer(2222, 22, 222, 222222, 22222))说明
真实的数据可能不会都是Long型,需要你特殊处理计算,计算出结果再转换为明文。案例中,数据连通性后,可以生成统一ID。
上面只是简单案例,在最上面分析过会出现不同的情况,更复杂的需要更复杂的逻辑处理。
除了图计算,直接SQL JOIN也即可。
相关文章:
数据应用OneID:ID-Mapping Spark GraphX实现
前言 说明 以用户实体为例,ID 类型包含 user_id 和 device_id。当然还有其他类型id。不同id可以获取到的阶段、生命周期均不相同。 device_id 生命周期通常指的是一个设备从首次被识别到不再活跃的整个时间段。 user_id是用户登录之后系统分配的唯一标识ÿ…...
第6章 6.2.3 : readlines和writelines函数 (MATLAB入门课程)
讲解视频:可以在bilibili搜索《MATLAB教程新手入门篇——数学建模清风主讲》。 MATLAB教程新手入门篇(数学建模清风主讲,适合零基础同学观看)_哔哩哔哩_bilibili 在MATLAB的文本数据处理任务中,导入和导出文件是常…...

Matlab应用层生成简述
基础软件层 目前接触到的几款控制器,其厂商并没有提供simulink的基础软件库一般为底层文件被封装为lib,留有供调用API接口虽然能根据API接口开发基础软件库,但耗费时间过长得不偿失 应用层 所以可以将应用层封装为一个子系统,其…...

每日一题(leetcode1702):修改后的最大二进制字符串--思维
找到第一个0之后,对于后面的子串(包括那个0),所有的0都能调上来,然后一一转化为10,因此从找到的第一个0的位置开始,接下来是(后半部分子串0的个数-1)个1,然后…...
PHP自助建站系统,小白也能自己搭建网站
无需懂代码,用 自助建站 做企业官网就像做PPT一样简单,您可以亲自操刀做想要的效果! 自助建站是一款简单、快捷、高效的工具,可以帮助您制作响应式网站。我们的自助建站系统,将传统的编码工作转化为直观的拖拽操作和文…...

计算机视觉 | 基于 ORB 特征检测器和描述符的全景图像拼接算法
Hi,大家好,我是半亩花海。本项目实现了基于 ORB 特征检测器和描述符的全景图像拼接算法,能够将两张部分重叠的图像拼接成一张无缝连接的全景图像。 文章目录 一、随机抽样一致算法二、功能实现三、代码解析四、效果展示五、完整代码 一、随机…...
)
Scala - 函数柯里化(Currying)
柯里化(Currying)指的是将原来接受两个参数的函数变成新的接受一个参数的函数的过程。新的函数返回一个以原有第二个参数为参数的函数。 实例 首先我们定义一个函数: def add(x:Int,y:Int)xy 那么我们应用的时候,应该是这样用:add(1,2) 现在我们把这…...

Switch-case
Java switch case 语句 switch case 语句判断一个变量与一系列值中某个值是否相等,每个值称为一个分支。 语法 switch case 语句语法格式如下: switch(expression){case value ://语句break; //可选case value ://语句break; //可选//你可以有任意数量…...

蓝桥杯-单片机基础16——利用定时计数中断进行动态数码管的多窗口显示
综合查阅了网络上目前能找到的所有关于此技能的代码,最终找到了下述方式比较可靠,且可以自定义任意显示的数值。 传统采用延时函数的方式实现动态数码管扫描,在题目变复杂时效果总是会不佳,因此在省赛中有必要尝试采用定时计数器中…...
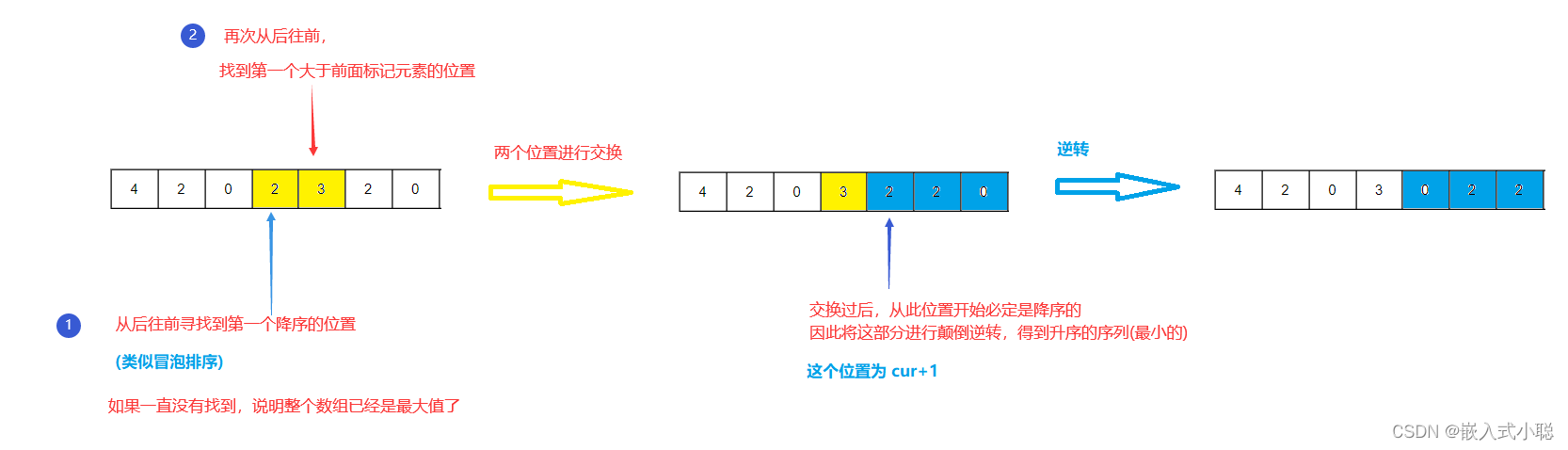
2024/4/5—力扣—下一个排列
代码实现: 思路:两遍扫描 void swap(int *a, int *b) {int t *a;*a *b;*b t; }void reverse(int *nums, int l, int r) {while (l < r) {swap(nums l, nums r);l;r--;} }void nextPermutation(int *nums, int numsSize) {int i numsSize - 2;wh…...
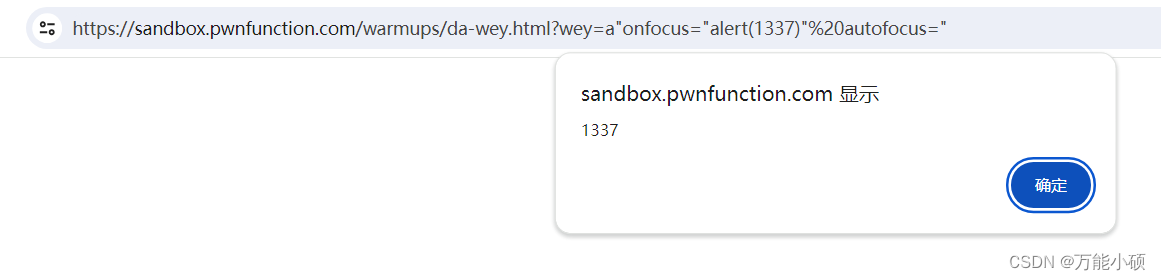
xss.pwnfunction-Ugandan Knuckles
这个是把<>过滤掉了所以只能用js的事件 ?weya"onfocus"alert(1337)" autofocus"...

LabVIEW和2D激光扫描的受电弓滑板磨耗精确测量
LabVIEW和2D激光扫描的受电弓滑板磨耗精确测量 在电气化铁路运输中,受电弓滑板的健康状况对于保障列车安全行驶至关重要。受电弓滑板作为连接电网与列车的直接介质,其磨损情况直接影响到电能的有效传输及列车的稳定运行。精确、快速测量受电弓滑板磨损情…...
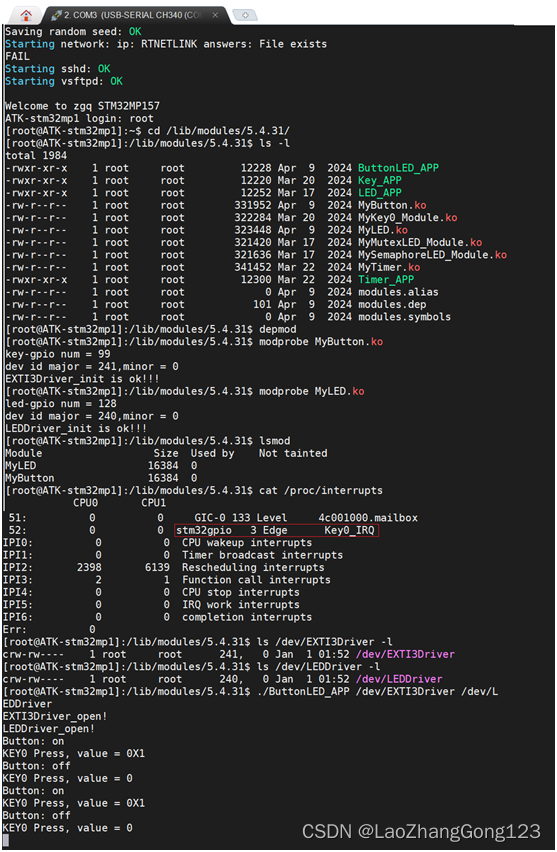
Linux第87步_阻塞IO实验
阻塞IO是“应用程序”对“驱动设备”进行操作,若不能获取到设备资源,则阻塞IO应用程序的线程会被“挂起”,直到获取到设备资源为止。 “挂起”就是让线程进入休眠,将CPU的资源让出来。线程进入休眠后,当设备文件可以操…...
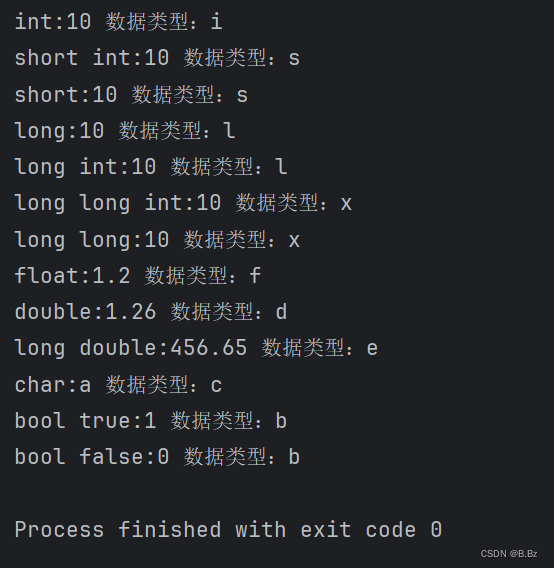
C/C++基础----常量和基本数据类型
HelloWorld #include <iostream>using namespace std;int main() {// 打印cout << "Hello,World!" << endl;return 0; }c/c文件和关系 c和c是包含关系,c相当于是c的plus版本c的编译器也可以编译c语言c文件.cpp结尾.h为头文件.c为c语言…...

什么是生成式AI?有哪些特征类型
生成式AI是人类一种人工智能技术,可以生成各种类型的内容,包括文本、图像、音频和合成数据。那么什么是人工智能?人工智能和机器学习之间的区别是什么?有哪些技术特征? 人工智能是一门学科,是计算机科学的一…...

《Linux C/C++服务器开发实践》之第7章 服务器模型设计
《Linux C/C服务器开发实践》之第7章 服务器模型设计 7.1 I/O模型7.1.1 基本概念7.1.2 同步和异步7.1.3 阻塞和非阻塞7.1.4 同步与异步和阻塞与非阻塞的关系7.1.5 采用socket I/O模型的原因7.1.6(同步)阻塞I/O模型7.1.7(同步)非阻…...
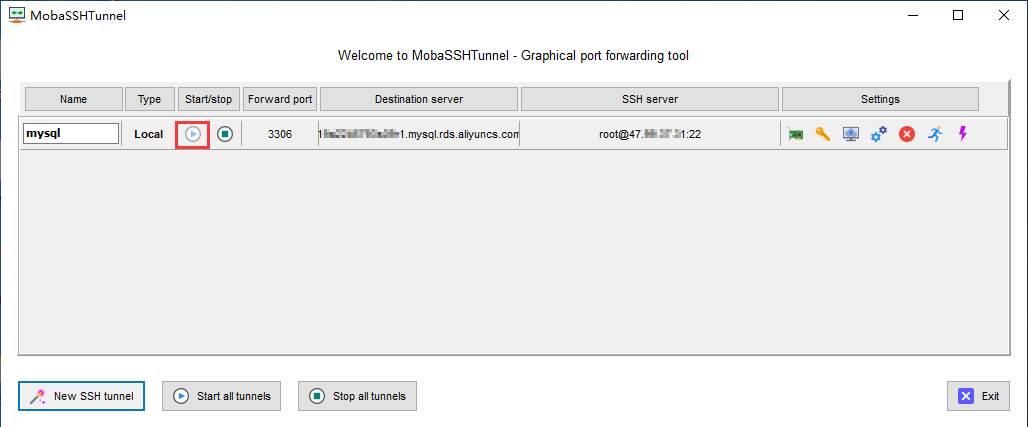
SSH穿透ECS访问内网RDS数据库
处于安全考虑,RDS一般只会允许指定的IP进行访问,而我们开发环境的IP往往是动态的,每次IP变动都需要去修改RDS的白名单,为我们的工作带来很大的不便。 那么如何去解决这个问题? 假如我们有一台ESC服务器,E…...

python 有哪些函数
Python内置的函数及其用法。为了方便记忆,已经有很多开发者将这些内置函数进行了如下分类: 数学运算(7个) 类型转换(24个) 序列操作(8个) 对象操作(7个) 反射操作(8个) 变量操作(2个) 交互操作(2个) 文件操作(1个) 编译执行(4个) 装饰器(3个) …...

ubuntu web端远程桌面控制
本方案采用x11vncnovnc来实现x11vnc的安装和配置可以参考UOS搭建VNC及连接教程_uos安装vnc-CSDN博客;并把/lib/systemd/system/x11vnc.service内容修改为如下: [Unit]DescriptionStart x11vnc at startup.Aftermulti-user.target[Service]TypesimpleExecStart/usr/bin/x11vnc …...
PCL 点到三角形的距离(3D)
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 给定三角形ABC和点P,设Q为描述ABC上离P最近的点。求Q的一个方法:如果P在ABC内,那么P的正交投影点就是离P最近的点Q。如果P投影在ABC之外,最近的点则必须位于它的一条边上。在这种情况下,Q可以通过计算线段AB、…...

探秘书匠策AI:毕业论文写作的“智慧引擎”
在学术探索的征途中,毕业论文如同一座巍峨的山峰,让无数学生既敬畏又向往。它不仅是对所学知识的综合检验,更是学术生涯的重要里程碑。然而,面对这座大山,许多人常常感到力不从心,选题迷茫、文献难觅、结构…...

KOReader 2025.04:重新定义电子墨水屏阅读
KOReader 2025.04:重新定义电子墨水屏阅读 【免费下载链接】koreader An ebook reader application supporting PDF, DjVu, EPUB, FB2 and many more formats, running on Cervantes, Kindle, Kobo, PocketBook and Android devices 项目地址: https://gitcode.co…...

实战指南:基于快马平台与Playwright打造自动化的网站内容监测应用
今天想和大家分享一个非常实用的自动化监测方案——基于Playwright和InsCode(快马)平台搭建的新闻网站更新监测系统。这个项目特别适合需要追踪行业动态或竞品资讯的朋友,整个过程不需要复杂的服务器配置,用快马平台就能轻松实现部署和定时运行。 项目背…...

QT图形界面开发集成Phi-4-mini-reasoning:打造智能桌面应用
QT图形界面开发集成Phi-4-mini-reasoning:打造智能桌面应用 1. 智能桌面应用的新可能 传统桌面应用开发正在经历一场智能化变革。想象一下,你的QT应用不仅能响应用户操作,还能理解用户意图、自动生成内容、提供智能建议——这就是集成Phi-4…...

RK3568 Serdes方案调试:基于THCV244的I2C透传与MIPI CSI链路配置
1. RK3568与THCV244 Serdes方案概述 在车载摄像头和工业视觉应用中,Serdes(串行器/解串器)技术正变得越来越重要。RK3568作为一款高性能处理器,配合THCV244 Serdes芯片,能够实现远距离传感器数据的稳定传输。这套方案的…...

为什么数据质量成为人工智能领域最重要的问题
简而言之:传统的基于人工编写规则和被动检查的数据质量体系,从未针对智能体人工智能进行设计。到2026年,当自主代理处理错误数据时,没有人会介入以发现问题。那些在人工智能领域取得成功的组织,并非从更好的模型入手&a…...

League-Toolkit:告别繁琐操作,让英雄联盟玩家效率提升300%的智能助手
League-Toolkit:告别繁琐操作,让英雄联盟玩家效率提升300%的智能助手 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 副…...

WHUCS—OS—lab实验:从零实现一个用户态定时器
1. 用户态定时器实现原理 在操作系统中,定时器是一个非常重要的基础功能。想象一下你每天早上依赖的闹钟 - 它会在特定时间准时响起,提醒你该起床了。用户态定时器的工作原理与此类似,只不过它是在程序运行时提供定时提醒功能。 xv6作为一个…...

intv_ai_mk11部署避坑指南:端口映射失败、响应延迟、乱码重复等问题解决方案
intv_ai_mk11部署避坑指南:端口映射失败、响应延迟、乱码重复等问题解决方案 1. 环境准备与快速部署 1.1 系统要求 操作系统:Ubuntu 20.04/22.04 LTSGPU:NVIDIA显卡(至少16GB显存)内存:32GB以上存储&…...
及使用vcs管理多仓库)
MoveIt2新手必看:如何正确选择安装分支(main vs. tutorials)及使用vcs管理多仓库
MoveIt2分支选择与多仓库管理实战指南 当你在ROS2生态中开始使用MoveIt2时,第一个拦路虎往往不是算法理解或代码编写,而是如何正确搭建开发环境。MoveIt2作为由数十个独立Git仓库组成的复杂项目,其分支管理和版本协同问题困扰着许多中级开发者…...