使用R语言包clusterProfiler做KEGG富集分析时出现的错误及解决方法
使用enrichKEGG做通路富集分析时,一直报错:显示No gene can be mapped....
k <- enrichKEGG(gene = gene, organism = "hsa", pvalueCutoff =1, qvalueCutoff =1)
但是之前用同样的基因做分析是能够成功地富集到通路,即便是网上的数据会更新,也不可能变化的这么大吧,我换了一组基因,出现相同的问题。去B站视频教程的评论去找答案,发现有小伙伴在前几天刚刚评论说出现和我一样的问题,可能这个问题是刚新出的,网上也一直没找到解决这个问题的方法。
我考虑是不是因为clusterProfiler版本的原因,但我没有立刻更换clusterProfiler版本。(先留个扣,到底是不是版本的原因?)
看到了网上很多在本地进行富集分析的教程,于是,便冒着今天科研进度为零的风险,大胆尝试一下把数据下载到本地,进行通路富集分析,因为这么做也有个优点,就是数据库在本地,不会随着网上的更新而导致富集结果的更新,因为这样避免了前期的实验在后期复现不出来的麻烦。
参考了这个方法:
构建自己的R包--KEGG.db
先去上述官方地址找到自己研究的物种在KEGG数据里的3字符缩写,比如:我研究的是人类和玉米,缩写是'hsa'和'zma'。
#安装Y叔的包,
#安装创建KEGG数据库的包的包
remotes::install_github("YuLab-SMU/createKEGGdb")
#创建自己的物种的包create_kegg_db,会自动创建名称为KEGG.db_1.0.tar,gz的包。物种名称的简写,在
createKEGGdb::create_kegg_db('zma') #人类是'hsa'#安装这个包(默认的包的路径在当前工作目录,根据实际情况修改路径)
install.packages("~/KEGG.db_1.0.tar.gz",repos=NULL,type="source")
但是在第二步时出现了小插曲,应该是说我的clusterProfiler有问题,我去安装了最新版本的clusterProfiler,clusterProfiler下载链接,在导入时又出现了麻烦,说最新版的clusterProfiler引入了DOSE,我的DOSE版本太低,我用BiocManager安装DOSE,但是BiocManager安装的DOSE依旧不符合要求,我考虑是否是BiocManager版本太低,又更新了BiocManager在安装DOSE,还是不行。迫不得已,我直接更新了R,从4.2.0更新了4.2.2,重新安装BiocManager、DOSE依旧解决不了问题。机缘巧合下(之前一直用某度,完全找不到官方信息,使用Bing浏览器搜到了这个,仿佛打开了新世界的大门),我找到了官方的DOSE,变下载安装包,在RStudio中手动安装,安装成功,继续导包clusterProfiler,又出现了一下包的关联问题,像GOSemSim, HDO, DO等,用同样的方法去官网下载安装包手动安装,因为BiocManager更新迟后,使用BiocManager不能安装最新版。后面甚至是JSON都需要安装,最后,clusterProfiler导包成功了!!!!
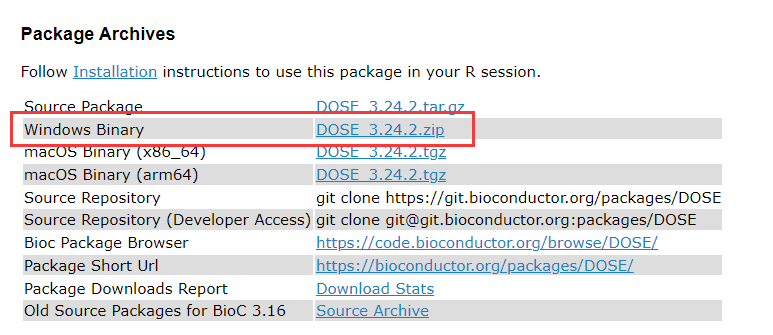
执行第二步和第三步,也都成功了!
还需要把“~/KEGG.db_1.0.tar.gz”手动安装,最后成为KEGG.db包,才可以使用library导入。
附上运行成功的代码(注意本地分析的话use_internal_data = TRUE,线上分析是默认的FALSE):
library("clusterProfiler")
library("org.Hs.eg.db")
library("enrichplot")
library("ggplot2")
library("pathview")
library("ggnewscale")
library("DOSE")
library(stringr)
library(AnnotationHub) #library导入需要使用的数据包
library(eoffice)
library('KEGG.db')
# 以上有些包在共享的代码中没用到,是后续画图用的# 把SYMBOL转成gene_id
EG2SYMBOL=toTable(org.Hs.egSYMBOL)
geneLists=read.table("data/gene_module_5.txt",sep="\t",check.names=F,header=F)
colnames(geneLists) <- c('symbol')
results=merge(geneLists,EG2SYMBOL,by='symbol',all.x=T) # 合并两个数据框
gene <- results$gene_id # 选择一列
# 进行通路分析
k <- enrichKEGG(gene = gene, organism = "hsa", pvalueCutoff =1, qvalueCutoff =1, use_internal_data = TRUE)
# 强制转成数据框,便于查看
KEGG=as.data.frame(k)
本地通路富集分析完成!!!
下面看一下是不是clusterProfiler版本的原因,我运行
k <- enrichKEGG(gene = gene, organism = "hsa", pvalueCutoff =1, qvalueCutoff =1)仍然报错:
那就不是clusterProfiler版本的原因了,是什么也不重要了,过些日子说不定就好了。
知识储备有限,描述不专业,敬请见谅!!!
相关文章:
使用R语言包clusterProfiler做KEGG富集分析时出现的错误及解决方法
使用enrichKEGG做通路富集分析时,一直报错:显示No gene can be mapped....k <- enrichKEGG(gene gene, organism "hsa", pvalueCutoff 1, qvalueCutoff 1)但是之前用同样的基因做分析是能够成功地富集到通路,即便是网上的数据…...
框架——MyBatis的入门案例
框架概述1.1什么是框架框架(Framework)是整个或部分系统的可重用设计,表现为一组抽象构件及构件实例间交与的方法;另一种定义认为,框架是可被应用开发者定制的应用骨架。前者是从应用方面而后者是从目的方面给出的定义…...

hadoop兼容性验证
前言 Hadoop是一个由Apache基金会所开发的分布式系统基础架构,主要解决海量数据的存储和海量数据的分析计算问题,广义上来说,Hadoop通常是指一个更广泛的概念–hadoop生态圈 Hadoop优缺点: 优点: 1、高可靠性&#x…...
运维提质增效,有哪些办法可以做
凡是代码,难免有 bug。 开发者们的日常,除了用一行行代码搭产品外,便是找出代码里的虫,俗称 debug。 随着移动互联网的快速发展,App 已经成为日常生活中不可或缺的一部分。但是在开发者/运维人员的眼里简直就是痛苦的…...

c++基础——结构体
结构体结构体(struct),可以看做是一系列称为成员元素的组合体。可以看做是自定义的数据类型。定义结构体struct abc {int x;int y; } e[array_length];const abc a; abc b, B[array_length], tmp; abc *c;上例中定义了一个名为 abc 的结构体&…...

applicationContext相关加载
spring refresh 概述 refresh是一个方法,spring中所有的ApplicationContext容器都需要通过refresh方法初始化; 处理步骤 其中refresh方法包含12个主要的处理步骤: 1、第1个步骤做前置准备 2、第2~6步骤创建BeanFactory(Appl…...
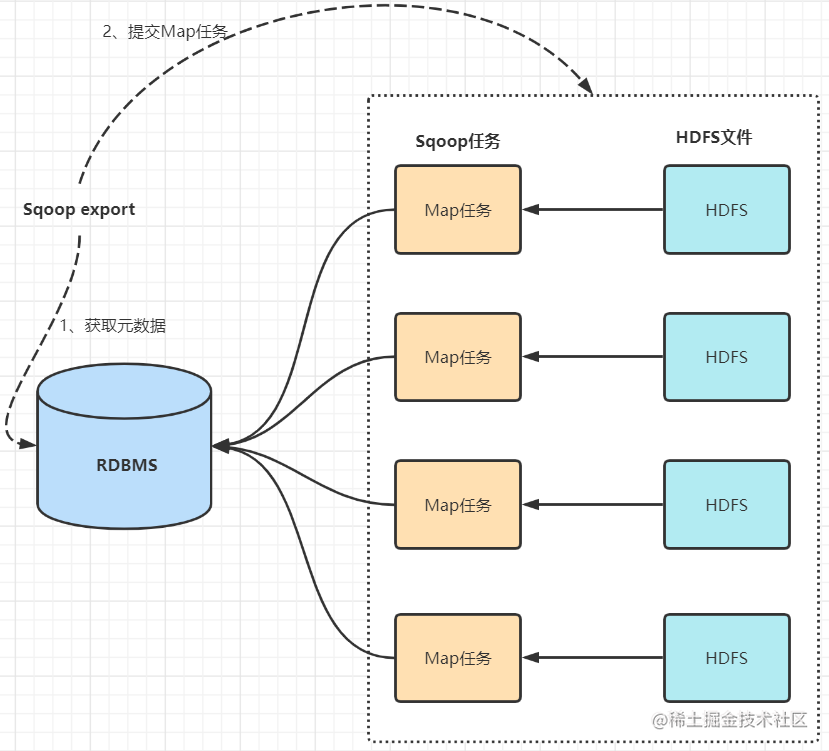
数据同步工具Sqoop
大数据Hadoop之——数据同步工具SqoopSqoop基本原理及常用方法 1 概述 Apache Sqoop(SQL-to-Hadoop)项目旨在协助RDBMS(Relational Database Management System:关系型数据库管理系统)与Hadoop之间进行高效的大数据交…...

Kafka 版本
kafka-2.11-2.1.1 : Kafka 1.0.0 后,Kafka 版本命名规则从 4 位到 3 位Kafka版本号是 2.1.1前 2 : 大版本号 (MajorVersion)中 1 : 小版本号或次版本号 (Minor Version)后 1 : 修订版本号 (Patch) Kafka 0.7 最早开源版本 : 只提供最基础的消息队列功…...
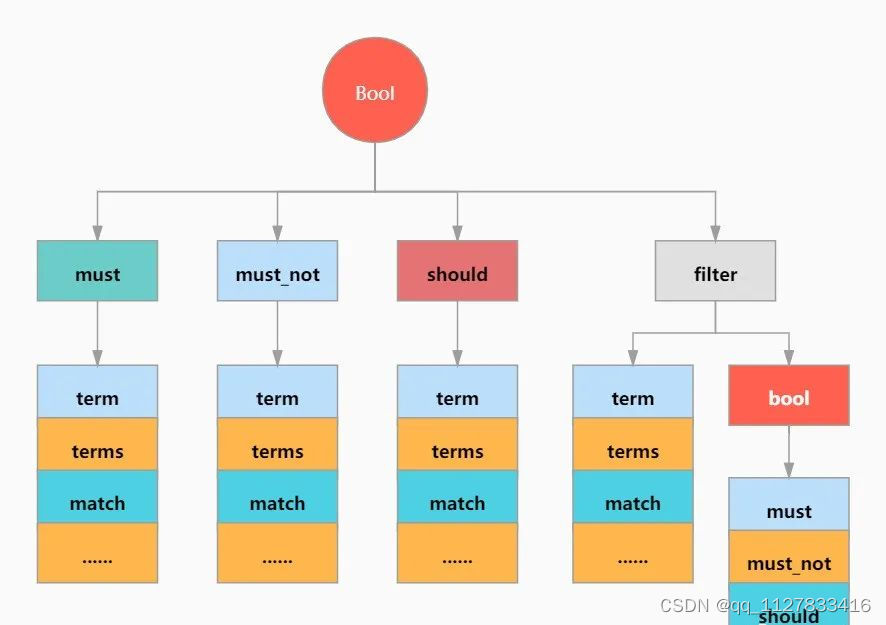
ElasticSearch 在Java中的各种实现
ES JavaAPI的相关体系: 词条查询 所谓词条查询,也就是ES不会对查询条件进行分词处理,只有当词条和查询字符串完全匹配时,才会被查询到。 等值查询-term 等值查询,即筛选出一个字段等于特定值的所有记录。 【SQL】 s…...
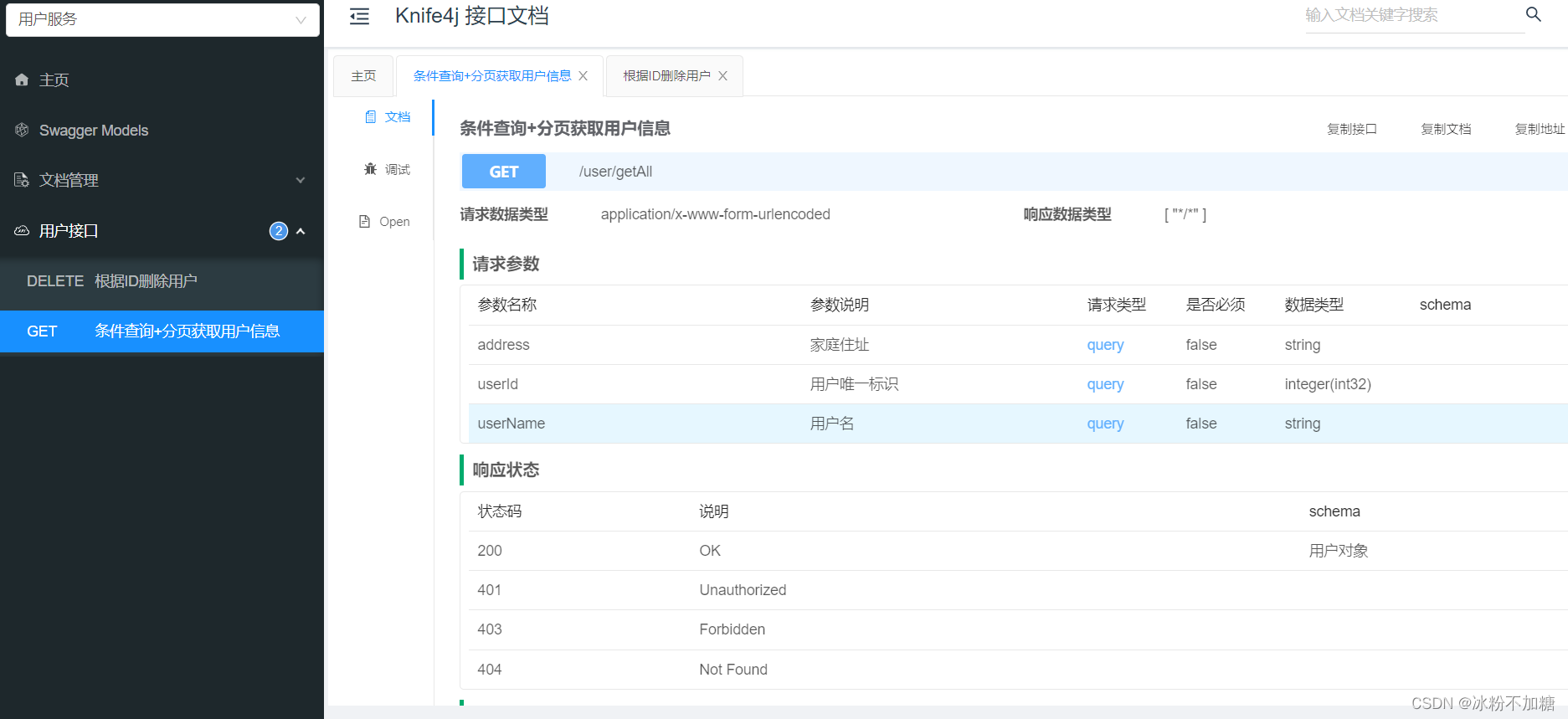
SpringBoot整合Knife4j
文章目录前言一、Knife4j是什么?二、使用步骤1.导入依赖2.编写配置文件3.编写controller和实体类4.测试总结前言 接上篇整合Swagger链接奉上http://t.csdn.cn/9mXSu 一、Knife4j是什么? 官方文档:https://doc.xiaominfo.com/ knife4j可以理解…...

MyISAM和InnoDB存储引擎的区别
目录前言存储引擎区别事务外键表单的存储数据查询效率数据更新效率如何选择前言 MyISAM和InnoDB是使用MySQL最常用的两种存储引擎,在5.5版本之前默认采用MyISAM存储引擎,从5.5开始采用InnoDB存储引擎。 存储引擎 存储引擎是:数据库管理系统…...

SpringMVC自定义处理多种日期格式的格式转换器
package cn.itcast.utils;import org.springframework.core.convert.converter.Converter;import java.text.DateFormat;import java.text.SimpleDateFormat;import java.util.Date;/*** 把字符串转换日期*/public class StringToDateConverter implements Converter<String…...
NYUv2生成边界GT(1)
看了cityscape和NYUv2生成边界GT的代码后,因为自己使用的是NYUv2数据集,所以需要对自己的数据集进行处理。CASENet生成边界GT所使用的代码是MATLAB,所以又重新看了一下MATLAB的代码,并进行修改,生成了自己的边界代码。…...
Spring基本概念与使用
文章目录一、Spring概念1.容器2.IoC3.DI4.Ioc与DI的关系二、Spring创建与使用1.Maven2.添加Spring框架支持注:国内的Maven源配置3.简单实例(1)创建一个Bean对象。(2)将Bean对象存储到Spring当中(3ÿ…...

安恒信息java实习面经
目录1.Java ME、EE、SE的区别,Java EE相对于SE多了哪些东西?2.jdk与jre的区别3.说一下java的一些命令,怎么运行一个jar包4.简单说一下java数据类型及使用场景5.Map跟Collection有几种实现?6.面向对象的特性7.重载和重写的区别8.重…...

第八章:枚举类与注解
第八章:枚举类与注解 8.1:枚举类的使用 类的对象只有有限个,确定的。我们称此类为枚举类。当需要定义一组常量是,强烈建议使用枚举类。如果枚举类中只有一个对象,则可以作为单例模式的实现方式。 如何定义枚举类 …...
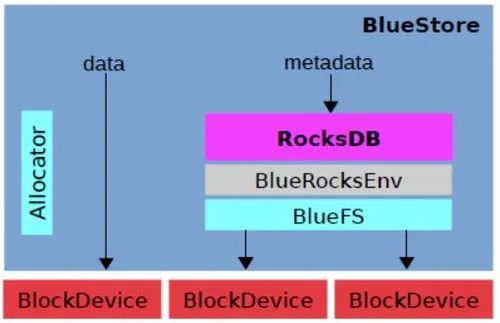
Ceph介绍
分布式存储概述 常用的存储可以分为DAS、NAS和SAN三类 DAS:直接连接存储,是指通过SCSI接口或FC接口直接连接到一台计算机上,常见的就是服务器的硬盘NAS:网络附加存储,是指将存储设备通过标准的网络拓扑结构ÿ…...

remove 和 erase 的区别
remove 和 erase 的区别 以容器vector来说明remove和erase的区别 在STL中,vector容器也提供了remove()和erase()函数,用于从vector中删除元素。虽然这两个函数都可以实现删除元素的功能,但是它们之间还是有一些区别的。 remove() remove(…...
NFTScan:怎么使用 NFT API 开发一个 NFT 数据分析平台?
对很多开发者来说,在 NFT 数据海洋中需要对每个 NFT 进行索引和筛选是十分困难且繁琐的,NFT 数据获取仍是一大问题。而数据平台提供的 API 使得开发者可以通过接口获取区块链上 NFT 的详细信息,并对其进行分析、处理、统计和可视化。在本篇文…...

ECOLOY直接更换流程表单后导致历史流程中数据为空白的解决方案
用户反馈流历史流程打开是空白了没有内容。 一、问题调查分析: 工作流“XX0204 员工培训协议审批流程”workflowId37166产生的7个具体流程中,创建日期为2021年的4个具体流程原先引用的数据库表单应该是“劳动合同签订审批表”(formtable_main_190)&…...

WarcraftHelper魔兽争霸III优化工具:让你的经典游戏重获新生
WarcraftHelper魔兽争霸III优化工具:让你的经典游戏重获新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔兽争霸III》…...

一键下载国家中小学智慧教育平台电子课本:让教育资源获取更简单高效
一键下载国家中小学智慧教育平台电子课本:让教育资源获取更简单高效 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容…...

日本电子产业转型启示:从技术过剩到商业模式创新
1. 日本电子产业的十字路口:一场箱根闭门会背后的行业剧痛2013年的春天,当全球电子产业的聚光灯都打在硅谷和深圳时,日本箱根的一家温泉旅馆里,正进行着一场鲜为人知却意义深远的对话。索尼、瑞萨、NEC、日立、松下、富士通、Mega…...

对lsof、tcpdump、strace命令的简单记录
1. lsof (List Open Files) —— “谁占用了资源?” 核心哲学:Linux 中一切皆文件(包括磁盘文件、网络 Socket、设备)。 常用操作:lsof -i :15000:查看指定端口的进程占用及连接状态(LISTEN/EST…...

AI编程助手效率革命:结构化配置与提示词工程实战
1. 项目概述:一个为AI编程时代量身定制的开发者工具箱如果你和我一样,日常开发已经离不开像 Cursor 和 Claude 这样的 AI 编程助手,那你肯定也遇到过类似的困扰:每次开启一个新项目,或者在不同项目间切换时,…...

AMD Ryzen硬件调试终极指南:深入SMU Debug Tool的完整实战应用
AMD Ryzen硬件调试终极指南:深入SMU Debug Tool的完整实战应用 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

Hermes Agent 可视化监控与文档生成工具 hermes-dashboard 详解
1. 项目概述与核心价值如果你正在使用 Hermes Agent 进行 AI 智能体开发,或者对 Agent 的内部运行状态感到好奇,那么你很可能需要一个“上帝视角”。hermes-dashboard正是这样一个工具,它为你提供了一个实时的监控仪表盘和一个自动生成的、可…...

全景视频会议核心技术解析:从200°视场角到实时图像拼接
1. 项目概述:全景视频会议如何从概念走向现实视频会议这玩意儿,我们搞通信和消费电子这行的,这些年见得多了。从最早模糊不清的像素块,到后来高清但视角固定的摄像头,大家总觉得少了点什么。没错,少的就是那…...

认知神经科学研究报告【20260055】
文章目录VAR 平稳向量自回归任务:L3 自适应涌现与 L4 经验迁移实验报告一、实验目标二、实验设计三、核心成果3.1 自主模型发现3.2 L4 跨任务经验迁移3.3 自主因果推断四、涌现层级评估六、结论VAR 平稳向量自回归任务:L3 自适应涌现与 L4 经验迁移实验报…...

构建多模型对比评测工具时集成Taotoken的统一接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建多模型对比评测工具时集成Taotoken的统一接口 在模型选型、效果验证或学术研究过程中,开发者或研究者常常需要并行…...