hadoop兼容性验证
前言
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,主要解决海量数据的存储和海量数据的分析计算问题,广义上来说,Hadoop通常是指一个更广泛的概念–hadoop生态圈
Hadoop优缺点:
-
优点:
1、高可靠性:Hadoop底层维护多个数据版本,所以即使Hadoop某个计算元素或者存储出现故障,也不会导致数据的丢失
2、高扩展性:在集群间分配任务数据,可方便的扩展到数以千计的节点上
3、高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度
4、高容错性:能够自动将失败的任务重新分配 -
缺点:
1、不适合低延时数据访问:毫秒级的数据访问
2、无法高效对大量小文件进行存储:存储大量小文件的话,会占用NameNode大量的内存来存储文件目录和块信息,NameNode的内存总是有限的,小文件的存储的寻址时间会超过读取时间,违反了HDFS的设计目标
3、不支持并发写入、文件随机修改:一个文件只能有一个写,不允许多个线程同时写;仅支持数据追加,不支持文件的随机修改
参考链接:
https://blog.csdn.net/weixin_43842853/article/details/123007306
https://blog.csdn.net/weixin_52112640/article/details/124907147
一、安装启动
配置java环境
yum install java-1.8.0-openjdk-devel
echo export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk >> /etc/profile
source /etc/profile
创建密钥
ssh-keygen -t rsa -P ‘’ -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
下载安装包
mkdir -p /usr/local/hadoop
wget https://mirrors.sonic.net/apache/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz -P /usr/local/hadoop
cd /usr/local/hadoop
tar -xvf hadoop-3.3.4.tar.gz
#配置核心组件core-site.xml
cat <<- EOF > /usr/local/hadoop/hadoop-3.3.4/etc/hadoop/core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://bogon:9000</value></property>
</configuration>
EOF
#配置文件系统配置文件hdfs-site.xml
cat <<- EOF > /usr/local/hadoop/hadoop-3.3.4/etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>1</value></property>
</configuration>
EOF
#配置env定义JAVA_HOME路径
sed -i 's!# export JAVA_HOME=!export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk!' /usr/local/hadoop/hadoop-3.3.4/etc/hadoop/hadoop-env.sh
#hadoop-3.x为了提升安全性,需要指定操作hadoop进程的用户
sed -i "2i HDFS_DATANODE_USER=root\nHDFS_DATANODE_SECURE_USER=hdfs\nHDFS_NAMENODE_USER=root\nHDFS_SECONDARYNAMENODE_USER=root" /usr/local/hadoop/hadoop-3.3.4/sbin/start-dfs.sh
sed -i "2i YARN_RESOURCEMANAGER_USER=root\nHADOOP_SECURE_DN_USER=yarn\nYARN_NODEMANAGER_USER=root" /usr/local/hadoop/hadoop-3.3.4/sbin/start-yarn.sh
#格式化文件系统
cd /usr/local/hadoop/hadoop-3.3.4/
bin/hdfs namenode -format
会看到类似如下的输出:
2023-03-07 16:10:47,309 INFO namenode.FSImage: Allocated new BlockPoolId: BP-512421437-10.130.0.73-1678176647285
2023-03-07 16:10:47,333 INFO common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted.
2023-03-07 16:10:47,402 INFO namenode.FSImageFormatProtobuf: Saving image file /tmp/hadoop-root/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2023-03-07 16:10:47,657 INFO namenode.FSImageFormatProtobuf: Image file /tmp/hadoop-root/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 396 bytes saved in 0 seconds .
2023-03-07 16:10:47,689 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2023-03-07 16:10:47,739 INFO namenode.FSNamesystem: Stopping services started for active state
2023-03-07 16:10:47,740 INFO namenode.FSNamesystem: Stopping services started for standby state
2023-03-07 16:10:47,747 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2023-03-07 16:10:47,748 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at bogon/10.130.0.73
************************************************************/
启动服务
[root@bogon hadoop-3.3.4]# sbin/start-dfs.sh
Starting namenodes on [bogon]
Starting datanodes
Starting secondary namenodes [bogon]
2023-03-07 17:17:19,371 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
[root@bogon hadoop-3.3.4]# sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
二、查看进程
#如果显示SecondaryNameNode、ResourceManager、NameNode、NodeManager、DataNode 进程代表hadoop服务启动成功
[root@bogon hadoop-3.3.4]# jps
127968 NameNode
128672 ResourceManager
128110 DataNode
128816 NodeManager
128306 SecondaryNameNode
129183 Jps
web端访问
http://本机ip:9870

相关文章:
hadoop兼容性验证
前言 Hadoop是一个由Apache基金会所开发的分布式系统基础架构,主要解决海量数据的存储和海量数据的分析计算问题,广义上来说,Hadoop通常是指一个更广泛的概念–hadoop生态圈 Hadoop优缺点: 优点: 1、高可靠性&#x…...
运维提质增效,有哪些办法可以做
凡是代码,难免有 bug。 开发者们的日常,除了用一行行代码搭产品外,便是找出代码里的虫,俗称 debug。 随着移动互联网的快速发展,App 已经成为日常生活中不可或缺的一部分。但是在开发者/运维人员的眼里简直就是痛苦的…...

c++基础——结构体
结构体结构体(struct),可以看做是一系列称为成员元素的组合体。可以看做是自定义的数据类型。定义结构体struct abc {int x;int y; } e[array_length];const abc a; abc b, B[array_length], tmp; abc *c;上例中定义了一个名为 abc 的结构体&…...

applicationContext相关加载
spring refresh 概述 refresh是一个方法,spring中所有的ApplicationContext容器都需要通过refresh方法初始化; 处理步骤 其中refresh方法包含12个主要的处理步骤: 1、第1个步骤做前置准备 2、第2~6步骤创建BeanFactory(Appl…...
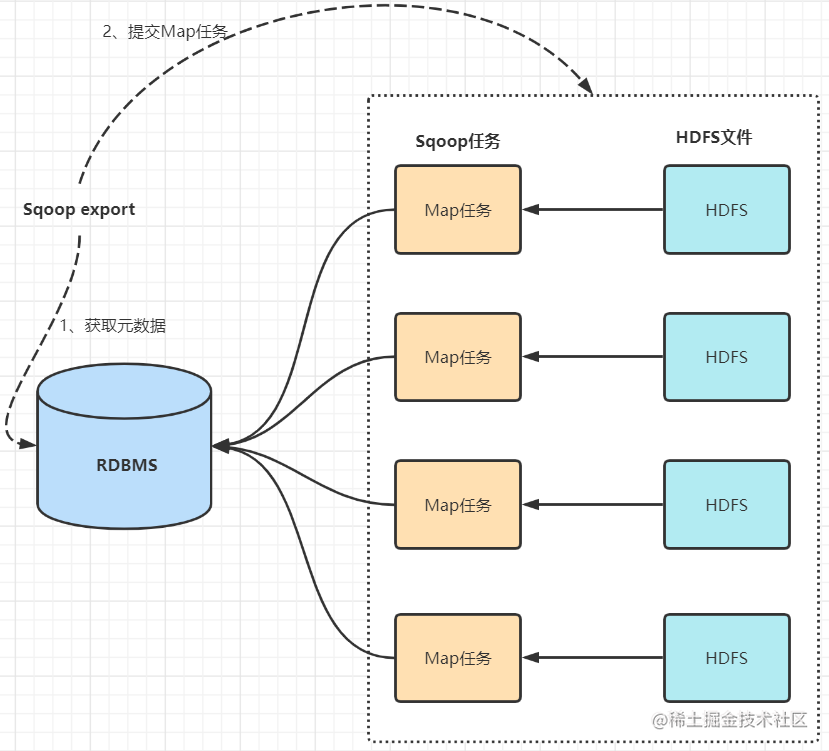
数据同步工具Sqoop
大数据Hadoop之——数据同步工具SqoopSqoop基本原理及常用方法 1 概述 Apache Sqoop(SQL-to-Hadoop)项目旨在协助RDBMS(Relational Database Management System:关系型数据库管理系统)与Hadoop之间进行高效的大数据交…...

Kafka 版本
kafka-2.11-2.1.1 : Kafka 1.0.0 后,Kafka 版本命名规则从 4 位到 3 位Kafka版本号是 2.1.1前 2 : 大版本号 (MajorVersion)中 1 : 小版本号或次版本号 (Minor Version)后 1 : 修订版本号 (Patch) Kafka 0.7 最早开源版本 : 只提供最基础的消息队列功…...
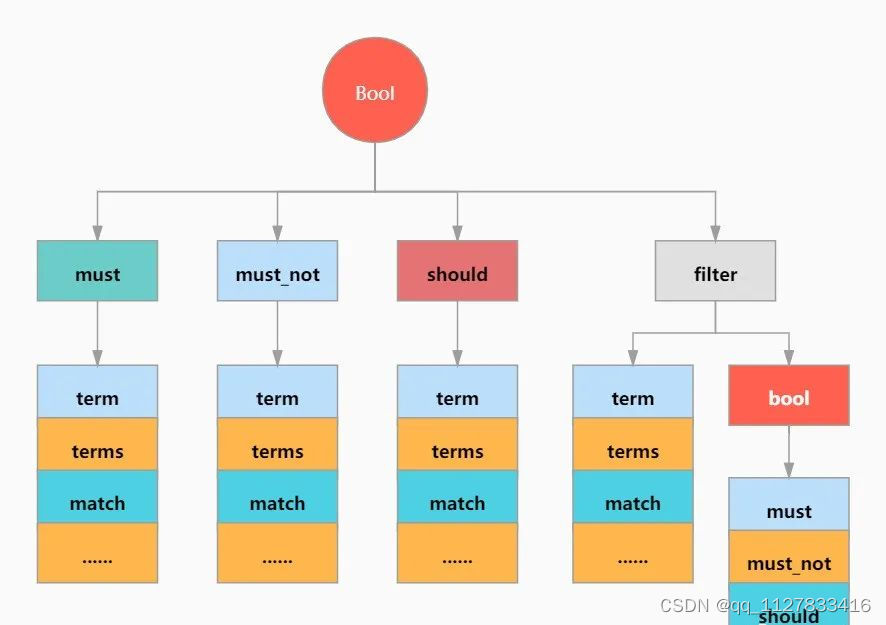
ElasticSearch 在Java中的各种实现
ES JavaAPI的相关体系: 词条查询 所谓词条查询,也就是ES不会对查询条件进行分词处理,只有当词条和查询字符串完全匹配时,才会被查询到。 等值查询-term 等值查询,即筛选出一个字段等于特定值的所有记录。 【SQL】 s…...
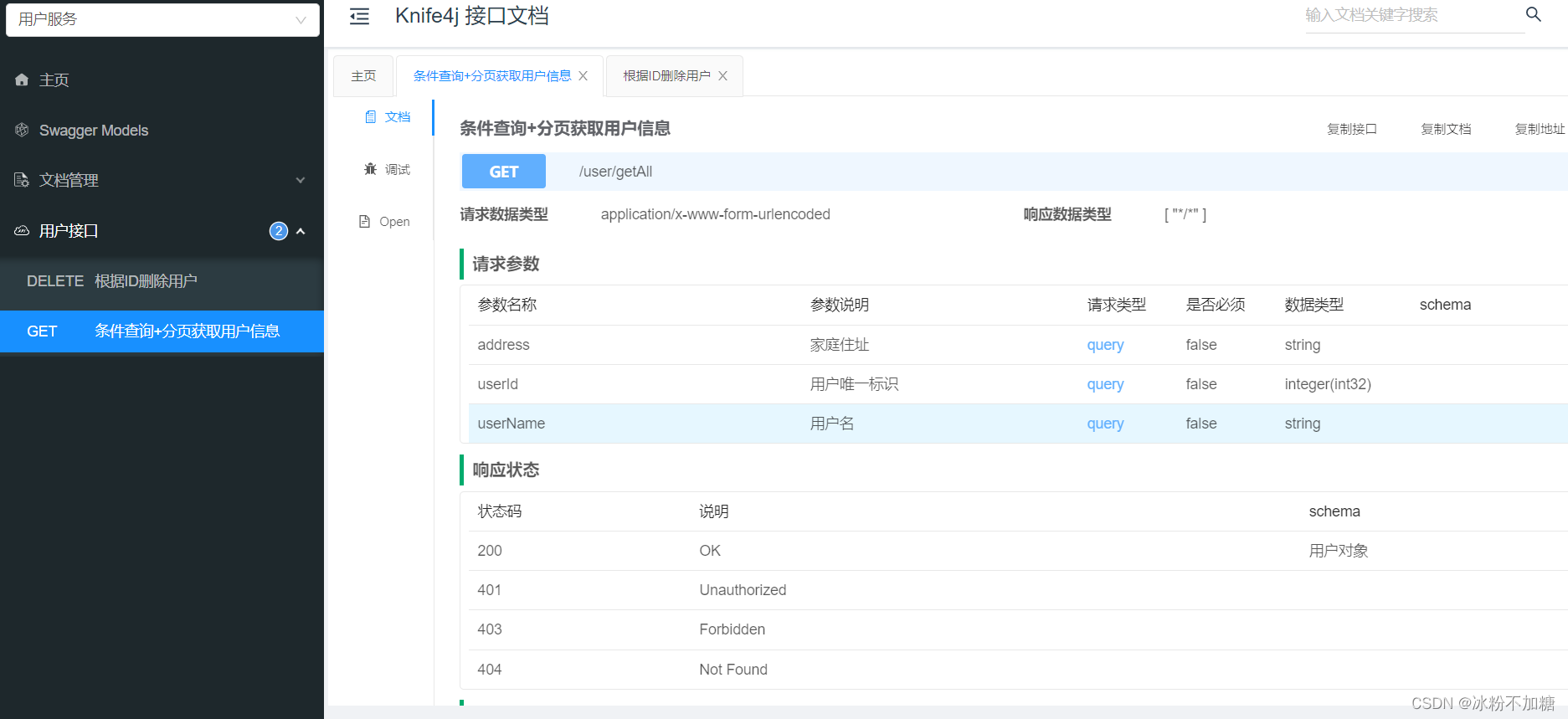
SpringBoot整合Knife4j
文章目录前言一、Knife4j是什么?二、使用步骤1.导入依赖2.编写配置文件3.编写controller和实体类4.测试总结前言 接上篇整合Swagger链接奉上http://t.csdn.cn/9mXSu 一、Knife4j是什么? 官方文档:https://doc.xiaominfo.com/ knife4j可以理解…...

MyISAM和InnoDB存储引擎的区别
目录前言存储引擎区别事务外键表单的存储数据查询效率数据更新效率如何选择前言 MyISAM和InnoDB是使用MySQL最常用的两种存储引擎,在5.5版本之前默认采用MyISAM存储引擎,从5.5开始采用InnoDB存储引擎。 存储引擎 存储引擎是:数据库管理系统…...

SpringMVC自定义处理多种日期格式的格式转换器
package cn.itcast.utils;import org.springframework.core.convert.converter.Converter;import java.text.DateFormat;import java.text.SimpleDateFormat;import java.util.Date;/*** 把字符串转换日期*/public class StringToDateConverter implements Converter<String…...
NYUv2生成边界GT(1)
看了cityscape和NYUv2生成边界GT的代码后,因为自己使用的是NYUv2数据集,所以需要对自己的数据集进行处理。CASENet生成边界GT所使用的代码是MATLAB,所以又重新看了一下MATLAB的代码,并进行修改,生成了自己的边界代码。…...
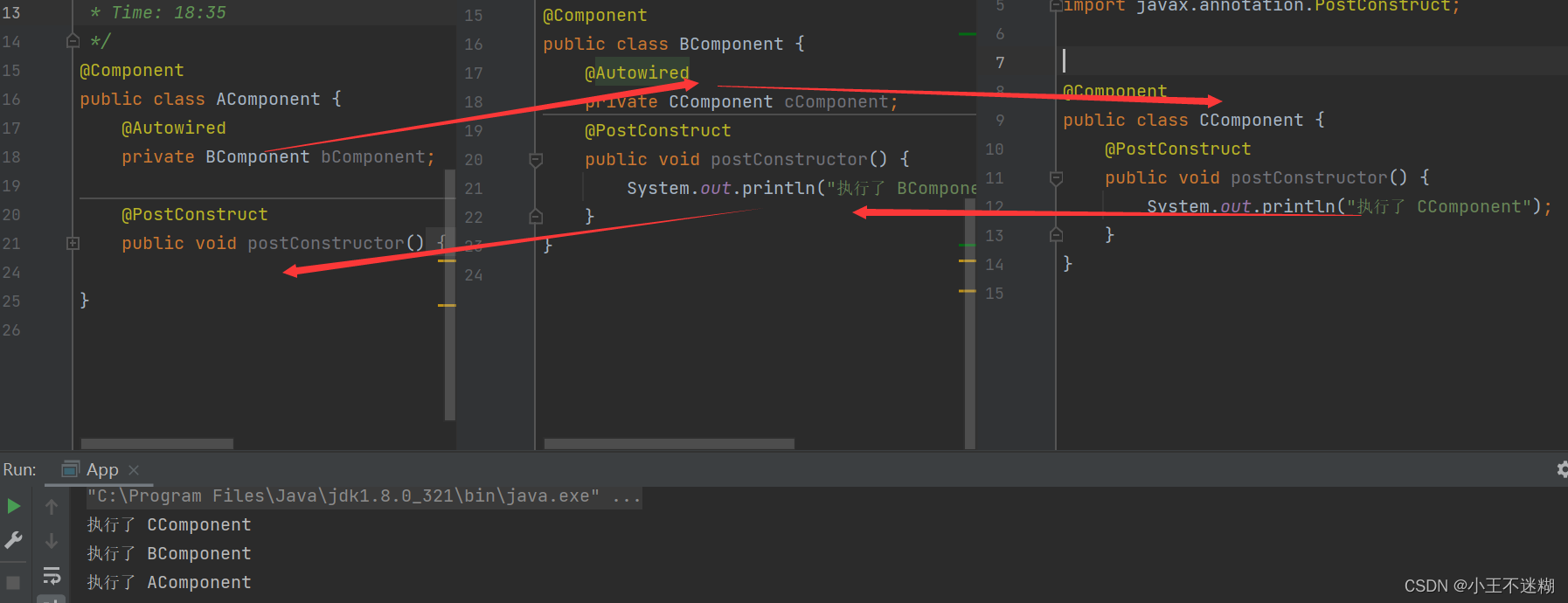
Spring基本概念与使用
文章目录一、Spring概念1.容器2.IoC3.DI4.Ioc与DI的关系二、Spring创建与使用1.Maven2.添加Spring框架支持注:国内的Maven源配置3.简单实例(1)创建一个Bean对象。(2)将Bean对象存储到Spring当中(3ÿ…...

安恒信息java实习面经
目录1.Java ME、EE、SE的区别,Java EE相对于SE多了哪些东西?2.jdk与jre的区别3.说一下java的一些命令,怎么运行一个jar包4.简单说一下java数据类型及使用场景5.Map跟Collection有几种实现?6.面向对象的特性7.重载和重写的区别8.重…...

第八章:枚举类与注解
第八章:枚举类与注解 8.1:枚举类的使用 类的对象只有有限个,确定的。我们称此类为枚举类。当需要定义一组常量是,强烈建议使用枚举类。如果枚举类中只有一个对象,则可以作为单例模式的实现方式。 如何定义枚举类 …...
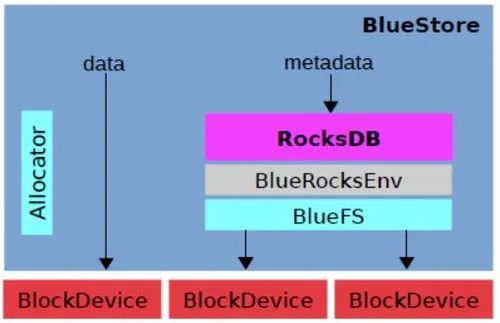
Ceph介绍
分布式存储概述 常用的存储可以分为DAS、NAS和SAN三类 DAS:直接连接存储,是指通过SCSI接口或FC接口直接连接到一台计算机上,常见的就是服务器的硬盘NAS:网络附加存储,是指将存储设备通过标准的网络拓扑结构ÿ…...

remove 和 erase 的区别
remove 和 erase 的区别 以容器vector来说明remove和erase的区别 在STL中,vector容器也提供了remove()和erase()函数,用于从vector中删除元素。虽然这两个函数都可以实现删除元素的功能,但是它们之间还是有一些区别的。 remove() remove(…...
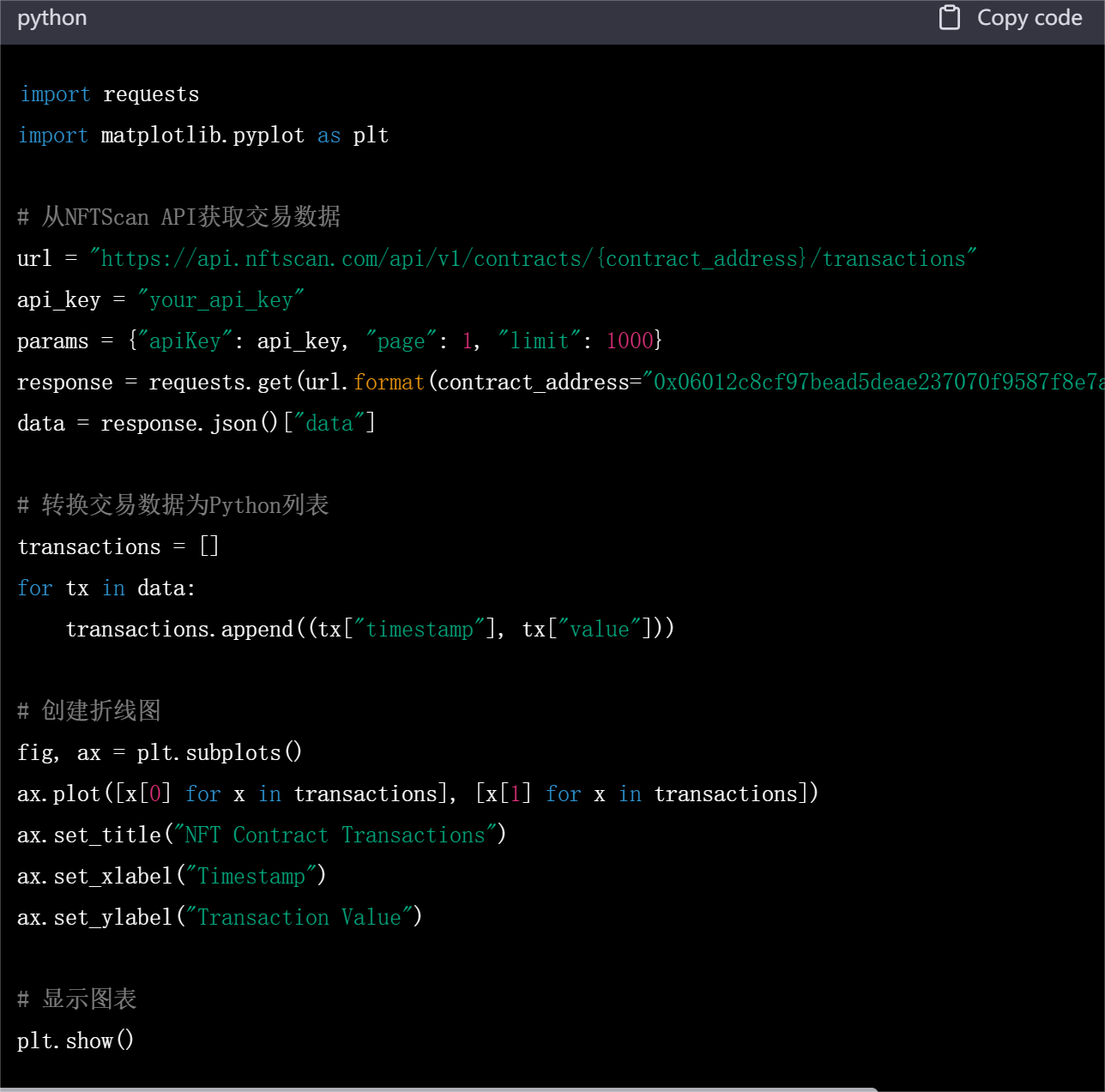
NFTScan:怎么使用 NFT API 开发一个 NFT 数据分析平台?
对很多开发者来说,在 NFT 数据海洋中需要对每个 NFT 进行索引和筛选是十分困难且繁琐的,NFT 数据获取仍是一大问题。而数据平台提供的 API 使得开发者可以通过接口获取区块链上 NFT 的详细信息,并对其进行分析、处理、统计和可视化。在本篇文…...

ECOLOY直接更换流程表单后导致历史流程中数据为空白的解决方案
用户反馈流历史流程打开是空白了没有内容。 一、问题调查分析: 工作流“XX0204 员工培训协议审批流程”workflowId37166产生的7个具体流程中,创建日期为2021年的4个具体流程原先引用的数据库表单应该是“劳动合同签订审批表”(formtable_main_190)&…...

mysql中的共享锁,排他锁,间隙锁,意向锁及死锁机制
一、前言(以下均为读完 高性能Mysql第四版 后的个人理解,建议阅读,挺不错的)在写锁机制前先简单贴出mysql InnoDB引擎中的事务特性与隔离级别:事务的ACID标准(1)原子性-atomicity:一个事务作为一个不可分割…...
SpringBoot整合MybatisPlus
文章目录前言一、MybatisPlus是什么?二、使用步骤1.导入依赖2.编写配置文件3.编写Controller和实体类4.编写持久层接口mapper5.启动类加包扫描注解6.测试总结前言 本篇记录一下SpringBoot整合MybatisPlus 一、MybatisPlus是什么? MyBatis-Plusÿ…...

【2026 AI大会签到终极指南】:3大预检漏洞、5步零失败通关、24小时倒计时避坑清单
更多请点击: https://intelliparadigm.com 第一章:2026年AI技术大会签到流程全景概览 2026年AI技术大会全面启用无感化、多模态融合签到系统,覆盖人脸识别、NFC工牌扫描、二维码核验及离线应急通道四大核心路径。所有参会者需提前72小时完成…...

告别黄牛票困扰:Python自动化抢票工具DamaiHelper深度解析
告别黄牛票困扰:Python自动化抢票工具DamaiHelper深度解析 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为心仪演唱会的门票一秒钟售罄而烦恼吗?是否厌倦了高价从黄…...

如何利用Taotoken模型广场为你的特定应用场景选择性价比最优的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何利用Taotoken模型广场为你的特定应用场景选择性价比最优的模型 为你的应用选择一个合适的大语言模型,往往需要在性…...

3大技术突破重塑抢购体验:JDspyder如何让秒杀从运气变成技术活
3大技术突破重塑抢购体验:JDspyder如何让秒杀从运气变成技术活 【免费下载链接】JDspyder 京东预约&抢购脚本,可以自定义商品链接 项目地址: https://gitcode.com/gh_mirrors/jd/JDspyder 你是否也曾遇到过这样的场景:盯着手机屏幕…...

观察taotoken平台在多模型聚合调用下的路由稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 平台在多模型聚合调用下的路由稳定性 在构建依赖大模型能力的生产应用时,服务的持续可用性是核心诉求之…...

从论文到工具:如何快速复现一篇OCT图像分割的顶会算法?
从论文到工具:OCT图像分割算法的工程化实践指南 在眼科医学影像研究领域,光学相干断层扫描(OCT)已成为视网膜疾病诊断的重要工具。当一篇关于OCT图像自动分割的顶会论文引起你的注意时,如何将那些令人印象深刻的量化指标转化为能处理你手中数…...

【AIAgent权限管理黄金法则】:SITS2026标准落地的5大致命误区与3步合规闭环
更多请点击: https://intelliparadigm.com 第一章:AIAgent权限管理:SITS2026标准的核心定位与演进逻辑 SITS2026 是首个面向自主智能体(AIAgent)全生命周期治理的国际协同标准草案,其核心突破在于将传统 R…...

《文字定律》随笔-AI们聊“艺术”-Deepseek、Grok、ChatGPT、Geminni
AI们总结和感悟了:艺术的由来、艺术的作用、艺术的演变、艺术的偏离,以及聊天后的感受。一下是我分享他们的总结和各自的感悟。Deepseek的总结:从种植到收割,以及我们遗忘的那些事:艺术,是文字之外的另一种…...

告别论文终稿噩梦:百考通AI如何让本科毕业设计成为“一次过”的顺畅体验
深夜的电脑蓝光映着布满血丝的眼睛,文档里满是批注与飘红——这是许多本科生在论文终稿前的常态。而一个智能工具正在悄然改变这场折磨。 凌晨三点的大学宿舍,键盘敲击声逐渐稀疏,取而代之的是此起彼伏的叹息。电脑屏幕上,Word文档…...

终极指南:TPFanCtrl2 深度解析与ThinkPad风扇控制优化
终极指南:TPFanCtrl2 深度解析与ThinkPad风扇控制优化 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 TPFanCtrl2 是一款专为ThinkPad用户设计的开源风扇控…...