如何通过OceanBase V4.2 动态采样优化查询性能
OceanBase v4.2 推出了优化器动态采样的功能,在SQL运行过程中,该功能会收集需要的统计信息,协助优化器制定出更好的执行计划,进一步提升了查询性能。
影响查询性能的因素是什么?为何你的优化器效果不佳?
执行 SQL 查询的过程中,为了选出最优的执行计划,OceanBase 优化器需收集关于表和索引的统计信息。若这些统计信息存在误差或缺失,可能导致选择的执行计划不是最优的,进而影响查询性能下降。通常,基本的统计信息可通过自动或手动方式收集。但是,有些情况下统计信息可能不准确,例如,数据分布发生变化、没有收集统计信息或者遇到一些复杂的SQL 查询。
例如,这里有 两张1000 行数据的表 t1和t2,假如两个表都没有收集统计信息。
create table t1(c1 int, c2 int, c3 int);
create table t2(c1 int, c2 int, c3 int);
create index idx_c1 on t2(c1);
insert into t1 select level,level,level from dual connect by level<=1000;
insert into t2 select level,level,level from dual connect by level<=1000;我们看看查询 “select * from t1, t2 where t1.c1 = t2.c1 and t1.c2 = 1000” 的计划情况:
| =========================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ------------------------------------------- |
| |0 |HASH JOIN | |98 |199 | |
| |1 | TABLE SCAN|T1 |10 |44 | |
| |2 | TABLE SCAN|T2 |1000 |61 | |
| =========================================== |可以看到上述两表JOIN的方式选择的是 HASH JOIN。但是真实情况是,满足 t1.c2 = 1000 的数据只有一行,此时,我们可以选择走 NESTED-LOOP JOIN,将连接条件 t1.c1 = t2.c1 下压到基表 t2 上,从而 t2 表也可以选择索引 idx_c1,整个计划执行性能也会更快。形如下面的查询计划,这个计划的执行性能会更好:
============================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------------- |
| |0 |NESTED-LOOP JOIN | |1 |21 | |
| |1 | TABLE SCAN |T1 |1 |2 | |
| |2 | DISTRIBUTED TABLE SCAN|T2(IDX_C1)|1 |18 | |
| =============================================================综上,我们需要一种技术手段来辅助获取更准确的统计信息,帮助优化器选择更好的执行计划。在业界当中,提出了一种动态采样的优化技术手段,为了使优化器得到足够多的统计信息,动态采样会在计划生成阶段针对数据库对象进行提前采样,通过采样的方式进行行数估计,从而用于代价模型中,生成更好的执行计划。
OceanBase 4.2 提供了全新的动态采样功能,帮助解决上述痛点。它有着如下的优点:
- 可以在缺乏统计信息的情况下获得更准确的统计信息;
- 可以在包含复杂谓词、关联谓词等查询中提供更加准确的统计信息;
- 可以减少统计数据收集的时间和成本,比如针对大宽表,常规的统计信息收集可能会非常耗时和资源;
- 可以提高查询的时效性,因为动态采样可以在查询时动态调整执行计划,以适应数据的变化。
如何最大化利用动态采样?如何将动态采样用到极致?
你只要升级到 OceanBase v4.2,无需任何额外操作,就会自动拥有全新的动态采样功能。升级之后,优化器会根据 SQL 查询语句决定是否开启动态采样功能,以使得生成的计划更加精准,执行更加高效。
应用动态采样的三个场景
目前动态采样功能默认生效于用户SQL,当前只支持基表的动态采样。在没有关闭动态采样功能时,以下场景会尝试在计划生成阶段使用动态采样:
- 没有任何统计信息可用。
- 查询条件中存在复杂谓词,比如 "c1 like '%test%' ",无法用选择率计算公式进行行数估计。
- 用户指定使用动态采样。
动态采样的三种控制手段
OceanBase v4.2 提供了系统变量、查询 HINT及系统配置项三种方式进行动态采样功能的控制,同时动态采样的采样集大小受限于并行度的控制。
方式一:系统变量控制。
optimizer_dynamic_sampling 系统变量当前实现仅仅做如下划分:
- 0:==> 关闭动态采样功能;
- 1:==> 开启动态采样功能;
"optimizer_dynamic_sampling": {"name": "optimizer_dynamic_sampling","value": "1","data_type": "int","info": "control dynamic sample level","flags": "GLOBAL | SESSION | NEED_SERIALIZE","min_val": "0","max_val": "1",}方式二:查询 HINT 控制。
动态采样支持指定 HINT 来控制查询是否使用动态采样,具体的用法如下:
DYNAMIC_SAMPLING '(' dynamic_sampling_hint ')'dynamic_sampling_hint:
INTNUM1
| qb_name_option relation_factor_in_hint opt_comma INTNUM为了便于大家理解,对上述命令中的专有名词作简要介绍。
- qb_name_option:Query Block的名字(可选)。
- relation_factor_in_hint:控制动态采样的表名(可选,为空表示整个查询使用动态采样)。
- INTNUM:指定采样的LEVEL(目前只支持0或者1,参考系统变量定义)。
方式三:系统配置项控制。
动态采样的最大可用查询时间默认是当前查询时间的1/10,比如一个查询的超时时间是10s,那么动态采样的最大时间是1s,同时为了防止动态采样的时间过大,增加了一个默认配置项(_optimizer_ads_time_limit)来控制动态采样的一个时间上限,默认时间上限是10秒,如果配置为0,即关闭动态采样功能。
DEF_INT(_optimizer_ads_time_limit, OB_TENANT_PARAMETER, "10", "[0, 300]","the maximum optimizer dynamic sampling time limit. Range: [0, 300]",ObParameterAttr(Section::TENANT, Source::DEFAULT, EditLevel::DYNAMIC_EFFECTIVE));动态采样原理介绍
为了方便大家更容易理解动态采样的原理,列举如下例子说明。
create table t1(c1 int, c2 int, c3 int, c4 int);
create index idx_c1 on t1(c1);Q1: select c4 from t1 where c1 > 1 and c2 > 1 and c3 > 1 group by c4;首先基表路径会生成3条路径:
- 主表路径;
- 索引表路径 idx_c1;
然后动态采样基于上述3条路径构建采样SQL:
- 基表的行数估计:count(*);
- c4 列的基础统计信息:approx_count_distinct(c4)、sum(case when c4 is null then 1 else 0 end);
- 满足所有谓词的行数估计:sum(case when c1 > 1 and c2 > 1 and c3 > 1 then 1 else 0 end);
- 满足索引表路径 idx_c1 的query range行数估计:sum(case when c1 > 1 then 1 else 0 end);
同时基于微块个数(默认采样微块个数:32)计算其采样率,假设Q1的采样率为 ratio;构建如下采样的SQL:
DYNAMIC SAMPLING Q1:
SELECT
/*+ NO_REWRITENO_PARALLELDYNAMIC_SAMPLING(0)QUERY_TIMEOUT(1000000)
*/
count(*),
approx_count_distinct("C4"),
Sum(CASE WHEN "C4" IS NULL THEN 1 ELSE 0 END),
Sum(CASE WHEN ( "C1" > 1 ) AND ( "C2" > 1 ) AND ( "C3" > 1 ) THEN 1 ELSE 0 END),
Sum(CASE WHEN ( "C1" > 1 ) THEN 1 ELSE 0 END)
FROM "TEST"."T1" SAMPLE BLOCK(ratio) SEED(seed);为了便于大家理解,对上述命令中的专有名词作简要介绍。
- NO_REWRITE:不需要走改写路径,基表扫描,没有必要。
- NO_PARALLEL:不开启并行,由于原始SQL未显示指定,默认不走并行采样。
- DYNAMIC_SAMPLING(0):动态采样SQL不能走动态采样。
- QUERY_TIMEOUT:采样时间SQL的查询时间上限。
从以上的例子中可以看到,动态采样会结合当前 SQL 查询的具体情况采样该 SQL计划生产必要的统计信息;比如,采样满足索引路径的行数用于计划路径的选择,同时采样了 c4 列的 NDV(不同值个数)用于准确的 group by 分组数估计等。
动态采样典型示例
以 100G TPCH 的 Q9 查询为例:
SELECT /*TPC-H Q9*/ nation,o_year,SUM(amount) AS SUM_PROFIT
FROM (SELECT n_nameASNATION,Date_format(o_orderdate, '%Y')ASO_YEAR,l_extendedprice * ( 1 - l_discount ) - ps_supplycost * l_quantityASAMOUNTFROM part,supplier,lineitem,partsupp,orders,nationWHERE s_suppkey = l_suppkeyAND ps_suppkey = l_suppkeyAND ps_partkey = l_partkeyAND p_partkey = l_partkeyAND o_orderkey = l_orderkeyAND s_nationkey = n_nationkeyAND p_name LIKE '%%green%%') AS PROFIT
GROUP BY nation,o_year
ORDER BY nation,o_year DESC; Q9 查询中 part 表有一个 like 条件: p_name LIKE '%%green%%';由于是前缀为 '%' 的 like 条件,即使在有统计信息直方图存在的情况下也无法使用直方图估计出准确的行数,如下是有统计信息,未使用动态采样的一个计划:
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ============================================================================================== |
| |ID|OPERATOR |NAME |EST.ROWS |EST.TIME(us)| |
| ---------------------------------------------------------------------------------------------- |
| |0 |PX COORDINATOR MERGE SORT | |40535 |3585766951 | |
| |1 |└─EXCHANGE OUT DISTR |:EX10005|40535 |3585737336 | |
| |2 | └─SORT | |40535 |3585670790 | |
| |3 | └─HASH GROUP BY | |40535 |3585651224 | |
| |4 | └─EXCHANGE IN DISTR | |40535 |3585635622 | |
| |5 | └─EXCHANGE OUT DISTR (HASH) |:EX10004|40535 |3585606007 | |
| |6 | └─HASH GROUP BY | |40535 |3585539461 | |
| |7 | └─HASH JOIN | |191316128|3565126187 | |
| |8 | ├─PX PARTITION ITERATOR | |150000000|7498533 | |
| |9 | │ └─TABLE FULL SCAN |ORDERS |150000000|7498533 | |
| |10| └─EXCHANGE IN DISTR | |191316128|3499839258 | |
| |11| └─EXCHANGE OUT DISTR (PKEY) |:EX10003|191316128|3237072719 | |
| |12| └─HASH JOIN | |191316128|2646062477 | |
| |13| ├─HASH JOIN | |25507206 |183664333 | |
| |14| │ ├─TABLE FULL SCAN |NATION |25 |5 | |
| |15| │ └─EXCHANGE IN DISTR | |25507206 |180401231 | |
| |16| │ └─EXCHANGE OUT DISTR |:EX10001|25507206 |150431919 | |
| |17| │ └─HASH JOIN | |25507206 |83037644 | |
| |18| │ ├─PX PARTITION ITERATOR | |1000000 |58063 | |
| |19| │ │ └─TABLE FULL SCAN |SUPPLIER|1000000 |58063 | |
| |20| │ └─EXCHANGE IN DISTR | |26792540 |79377144 | |
| |21| │ └─EXCHANGE OUT DISTR (PKEY)|:EX10000|26792540 |58029448 | |
| |22| │ └─PX PARTITION ITERATOR | |26792540 |10051824 | |
| |23| │ └─MERGE JOIN | |26792540 |10051824 | |
| |24| │ ├─TABLE FULL SCAN |PART |6666667 |1536384 | |
| |25| │ └─TABLE FULL SCAN |PARTSUPP|80000000 |6419953 | |
| |26| └─EXCHANGE IN DISTR | |600037902|2380208653 | |
| |27| └─EXCHANGE OUT DISTR |:EX10002|600037902|1675203055 | |
| |28| └─PX PARTITION ITERATOR | |600037902|89803225 | |
| |29| └─TABLE FULL SCAN |LINEITEM|600037902|89803225 | |
| ============================================================================================== 计划中的 No.24 TABLE FULL SCAN 算子即是当前利用统计信息估算的一个 part 满足条件 sp_name LIKE '%%green%%'的行数,估计结果是 6666667;继续看看满足条件的真实行数:
obclient> select count(*) from part;
+----------+
| COUNT(*) |
+----------+
| 20000000 |
+----------+
1 row in set (0.08 sec)obclient> select count(*) from part where p_name LIKE '%%green%%';
+----------+
| COUNT(*) |
+----------+
| 1087982 |
+----------+
1 row in set (1.92 sec)可以看见,上述通过统计信息估算的行数和真实的值是偏差很大的,主要原因是由于前缀为 '%' 的 like 条件不能直接利用直方图估计行数,只能使用默认的一个 like 条件选择率来进行估算,导致出现了如此大的偏差。
接下来看看开启动态采样之后的计划:
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ============================================================================================== |
| |ID|OPERATOR |NAME |EST.ROWS |EST.TIME(us)| |
| ---------------------------------------------------------------------------------------------- |
| |0 |PX COORDINATOR MERGE SORT | |40535 |2690273793 | |
| |1 |└─EXCHANGE OUT DISTR |:EX10005|40535 |2690244178 | |
| |2 | └─SORT | |40535 |2690177632 | |
| |3 | └─HASH GROUP BY | |40535 |2690158066 | |
| |4 | └─EXCHANGE IN DISTR | |40535 |2690142464 | |
| |5 | └─EXCHANGE OUT DISTR (HASH) |:EX10004|40535 |2690112849 | |
| |6 | └─HASH GROUP BY | |40535 |2690046303 | |
| |7 | └─HASH JOIN | |35817406 |2686210979 | |
| |8 | ├─EXCHANGE IN DISTR | |35817406 |2648259525 | |
| |9 | │ └─EXCHANGE OUT DISTR (PKEY) |:EX10003|35817406 |2599065472 | |
| |10| │ └─HASH JOIN | |35817406 |2488419004 | |
| |11| │ ├─HASH JOIN | |4775353 |41041962 | |
| |12| │ │ ├─TABLE FULL SCAN |NATION |25 |5 | |
| |13| │ │ └─EXCHANGE IN DISTR | |4775353 |40431048 | |
| |14| │ │ └─EXCHANGE OUT DISTR |:EX10001|4775353 |34820319 | |
| |15| │ │ └─HASH JOIN | |4775353 |22203044 | |
| |16| │ │ ├─PX PARTITION ITERATOR | |1000000 |58063 | |
| |17| │ │ │ └─TABLE FULL SCAN |SUPPLIER|1000000 |58063 | |
| |18| │ │ └─EXCHANGE IN DISTR | |5015988 |21290037 | |
| |19| │ │ └─EXCHANGE OUT DISTR (PKEY)|:EX10000|5015988 |17293410 | |
| |20| │ │ └─PX PARTITION ITERATOR | |5015988 |8311240 | |
| |21| │ │ └─MERGE JOIN | |5015988 |8311240 | |
| |22| │ │ ├─TABLE FULL SCAN |PART |1248106 |1326869 | |
| |23| │ │ └─TABLE FULL SCAN |PARTSUPP|80000000 |6419953 | |
| |24| │ └─EXCHANGE IN DISTR | |600037902|2380208653 | |
| |25| │ └─EXCHANGE OUT DISTR |:EX10002|600037902|1675203055 | |
| |26| │ └─PX PARTITION ITERATOR | |600037902|89803225 | |
| |27| │ └─TABLE FULL SCAN |LINEITEM|600037902|89803225 | |
| |28| └─PX PARTITION ITERATOR | |150000000|7498533 | |
| |29| └─TABLE FULL SCAN |ORDERS |150000000|7498533 | |
| ============================================================================================== 可以看到利用动态采样估算出来的 No.22 TABLE FULL SCAN算子的行数为:1248106,和真实的行数是接近的,是会优于使用统计信息去估算行数的。
动态采样会影响硬解析时间吗?
由于动态采样需要在计划生成的时候进行数据采样、统计信息收集,这势必会增大SQL的硬解析时间。通过内部测试来看,使用动态采样的额外解析时间在毫秒级别。为了减少采样的次数,避免频繁采样,也引入了动态采样的 cache 机制。针对每次采样的结果会缓存下来,优先利用缓存的采样结果,避免无效的采样,增大 SQL 硬解析的时间。同时,针对缓存的结果会结合每个表的增删改情况,弃用已经失效的采样结果,保证采样的准确性。因此整体来看动态采样对于硬解析的额外开销还是相对可控的。
总结
动态采样为了使优化器得到足够多的统计信息,会在计划生成阶段提前对数据库对象进行采样,通过采样的方式进行行数估计,从而用于代价模型中,生成更好的计划。动态采样丰富了优化器获取统计信息的手段,在统计信息不可用或者无法提供准确的行数估计时,提供一种更好的解决方案。但是在使用动态采样功能的时候,需要注意以下几点:
- 由于动态采样默认使用的是块采样,因此建议导入数据之后做相应的转储合并变更,以获得更好的采样效果。
- 动态采样难免带来部分硬解析的时间额外开销,部分 TP 场景的业务如果无法忍受,可以选择关闭该功能。
- 动态采样仅作为统计信息收集的一种补充手段,业务场景不要完全依赖于该功能,基础的统计信息收集还是需要做的。
相关文章:

如何通过OceanBase V4.2 动态采样优化查询性能
OceanBase v4.2 推出了优化器动态采样的功能,在SQL运行过程中,该功能会收集需要的统计信息,协助优化器制定出更好的执行计划,进一步提升了查询性能。 影响查询性能的因素是什么?为何你的优化器效果不佳? …...
Vue3---基础1(认识,创建)
变化 相对于Vue2,Vue3的变化: 性能的提升 打包大小减少 41% 初次渲染快 55%,更新渲染快133% 内存减少54% 源码的升级 使用 proxy 代替 defineProperty 实现响应式 重写虚拟 DOM 的实现和 Tree-shaking TypeScript Vue3就可以更好的支持TypeSc…...

JAVA集合ArrayList
目录 ArrayList概述 add(element) 用法 add(index, element)用法 remove(element)用法 remove(index)用法 get(index)用法 set(index,element) 练习 test1 定义一个集合,添加字符串,并进行遍历&…...

Bitmap OOM
老机器Bitmap预读仍然OOM,无奈增加一段,终于不崩溃了。 if (Build.VERSION.SDK_INT < 21)size 2; 完整代码: Bitmap bitmap; try {//Log.e(Thread.currentThread().getStackTrace()[2] "", surl);URL url new URL(surl);…...

基于深度学习的人脸表情识别系统(PyQT+代码+训练数据集)
基于深度学习的人脸表情识别系统(PyQT代码训练数据集) 前言一、数据集1.1 数据集介绍1.2 数据预处理 二、模型搭建三、训练与测试3.1 模型训练3.2 模型测试 四、PyQt界面实现 前言 本项目是基于mini_Xception深度学习网络模型的人脸表情识别系统&#x…...

Qt 中的项目文件解析和命名规范
🐌博主主页:🐌倔强的大蜗牛🐌 📚专栏分类:QT❤️感谢大家点赞👍收藏⭐评论✍️ 目录 一、Qt项目文件解析 1、.pro 文件解析 2、widget.h 文件解析 3、main.cpp 文件解析 4、widget.cpp…...

【chatGPT】我:在Cadence Genus软件中,出现如下问题:......【4】
我 在Cadence Genus中,tcl代码为:foreach clk $clk_list{ set clkName [lindex $clk_list 0] set targetFreq [lindex $clk_list 1] set uncSynth [lindex $clk_list 4] set clkPeriod [lindex “%.3f” [expr 1 / $targetFreq]] … } 以上代码出现如下…...
在JAVA中的应用)
单例模式(Singleton Pattern)在JAVA中的应用
在软件开发中,设计模式是解决特定问题的一种模板或者指南。它们是在多年的软件开发实践中总结出的有效方法。JAVA设计模式广泛应用于各种编程场景中,以提高代码的可读性、可维护性和扩展性。本文将介绍单例模式,这是一种常用的创建型设计模式…...

手把手教你创建新的OpenHarmony 三方库
创建新的三方库 创建 OpenHarmony 三方库,建议使用 Deveco Studio,并添加 ohpm 工具的环境变量到 PATH 环境变量。 创建方法 1:IDE 界面创建 在现有应用工程中,新创建 Module,选择"Static Library"模板&a…...

从零开始,如何成功进入IT行业?
0基础如何进入IT行业? 简介:对于没有任何相关背景知识的人来说,如何才能成功进入IT行业?是否有一些特定的方法或技巧可以帮助他们实现这一目标? 在当今数字化时代,IT行业无疑是一个充满活力和机遇的领域。…...
【数组】5螺旋矩阵
这里写自定义目录标题 一、题目二、解题精髓-循环不变量三、代码 一、题目 给定⼀个正整数 n,⽣成⼀个包含 1 到 n^2 所有元素,且元素按顺时针顺序螺旋排列的正⽅形矩阵。 示例: 输⼊: 3 输出: [ [ 1, 2, 3 ], [ 8, 9, 4 ], [ 7, 6, 5 ] ] 二、解题精髓…...

Sora视频生成模型:开启视频创作新纪元
随着人工智能技术的飞速发展,视频生成领域也迎来了前所未有的变革。Sora视频生成模型作为这一领域的佼佼者,凭借其卓越的性能和创新的应用场景,受到了广泛的关注与好评。本文将对Sora视频生成模型进行详细介绍,带您领略其魅力所在…...
OpenAI现已普遍提供带有视觉应用程序接口的GPT-4 Turbo
OpenAI宣布,其功能强大的GPT-4 Turbo with Vision模型现已通过公司的API全面推出,为企业和开发人员将高级语言和视觉功能集成到其应用程序中开辟了新的机会。 PS:使用Wildcard享受不受网络限制的API调用,详情查看教程 继去年 9 月…...

Swift中的元组属性
在Swift中,元组属性指的是一个元组作为结构体、类或枚举的属性。可以将一个元组作为属性来存储和访问多个值。 例如,考虑以下的Person类: class Person {var name: Stringvar age: Intvar address: (String, Int)init(name: String, age: I…...

【go从入门到精通】作用域,包详解
作者简介: 高科,先后在 IBM PlatformComputing从事网格计算,淘米网,网易从事游戏服务器开发,拥有丰富的C,go等语言开发经验,mysql,mongo,redis等数据库,设计模…...
利用SARscape对日本填海造陆和天然气开采进行地表形变监测
日本千叶市,是日本南部重要的工业港市。位于西部的浦安市是一个典型的"填海造田"城市,东南部的东金区有一片天然气开采区域,本文利用SARscape,用干涉叠加的方法,即PS和SBAS,对这两个区域进行地表…...

“Python爬虫实战:高效获取网上公开美图“
如何通过Python创建一个简单的网络爬虫,以爬取网上的公开图片。网络爬虫是一种自动化工具,能够浏览互联网、下载内容并进行处理。请注意,爬取内容时应遵守相关网站的使用条款,尊重版权和隐私权。 ### 网络爬虫简介 网络爬虫&…...
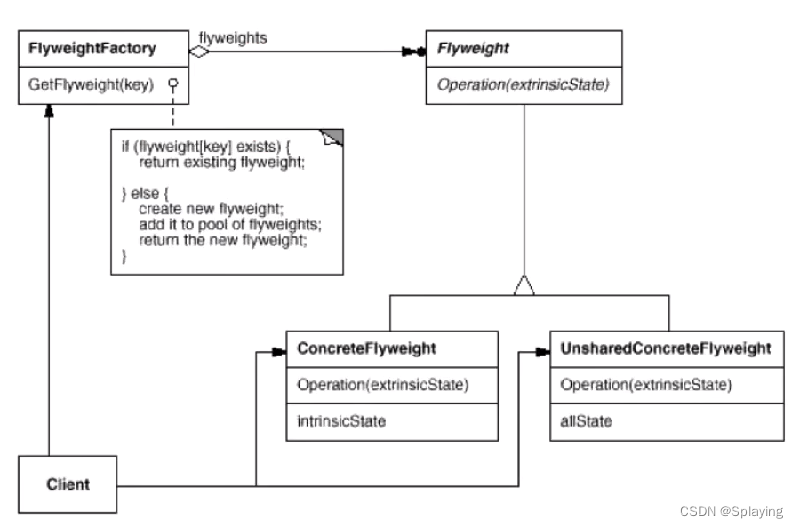
C++设计模式:享元模式(十一)
1、定义与动机 概述:享元模式和单例模式一样,都是为了解决程序的性能问题。面向对象很好地解决了"抽象"的问题,但是必不可免得要付出一定的代价。对于通常情况来讲,面向对象的成本大豆可以忽略不计。但是某些情况&#…...
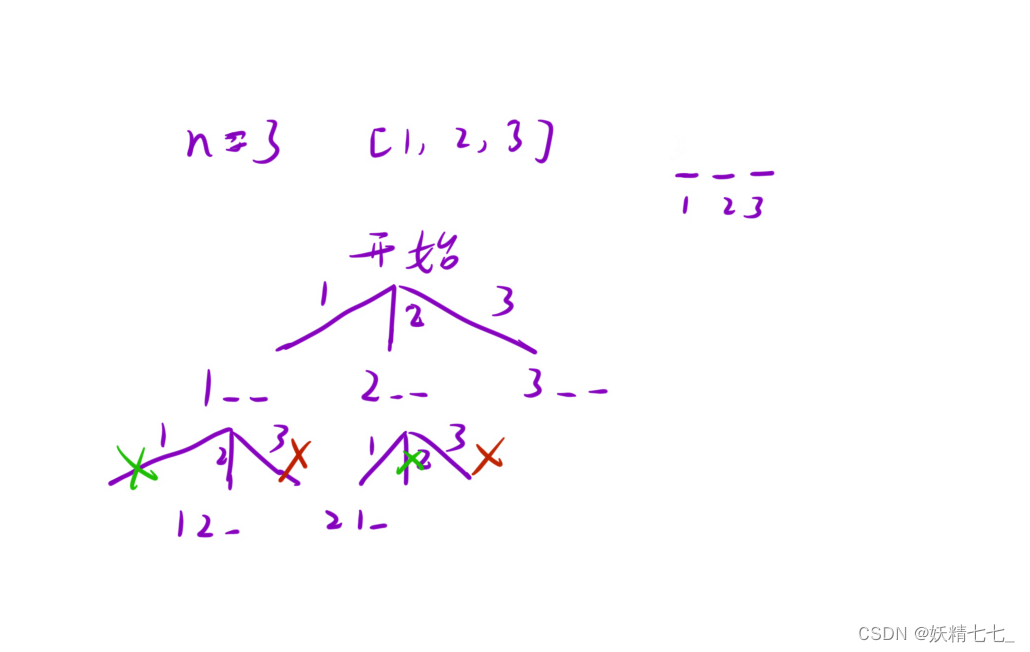
【三十六】【算法分析与设计】综合练习(3),39. 组合总和,784. 字母大小写全排列,526. 优美的排列
目录 39. 组合总和 对每一个位置进行枚举 枚举每一个数出现的次数 784. 字母大小写全排列 526. 优美的排列 结尾 39. 组合总和 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不…...
——架构简介)
ARM Cordio WSF(一)——架构简介
1. 关于WSF WSF(wireless Software Foundation API),是一个RTOS抽象层。Wireless Software Foundation software service and porting layer,提供实时操作系统所需的基础服务,可基于不同平台进行实现,移植…...

告别top!用htop监控Linux进程,这10个高效用法运维新手必看
告别top!用htop监控Linux进程,这10个高效用法运维新手必看 如果你还在用top命令监控Linux服务器状态,就像拿着算盘处理大数据——虽然能用,但效率实在堪忧。作为top的现代化替代品,htop以其彩色界面、鼠标支持和直观的…...

工业DC-DC电源模块性能选型解析|钡特电源 VB15-48S24MD 与 URB4824YMD-15WR3 封装互通
在工业控制、通信设备、仪器仪表等领域,工业 DC-DC 模块电源作为核心供电单元,其稳定性、兼容性与性价比直接影响系统整体可靠性。随着国产化进程加速,国产工业电源模块在技术、品质上已达到国际先进水平,成为硬件工程师选型的重要…...

PiliPlus:如何用第三方B站客户端解锁终极观影体验?
PiliPlus:如何用第三方B站客户端解锁终极观影体验? 【免费下载链接】PiliPlus PiliPlus 项目地址: https://gitcode.com/gh_mirrors/pi/PiliPlus 你是否厌倦了官方B站客户端的广告轰炸?是否想要更纯净、更流畅的观影体验?P…...

怎样高效使用Mac微信插件:5大实用功能完全指南
怎样高效使用Mac微信插件:5大实用功能完全指南 【免费下载链接】WeChatExtension-ForMac A plugin for Mac WeChat 项目地址: https://gitcode.com/gh_mirrors/we/WeChatExtension-ForMac 想让你的Mac微信变得更加强大吗?WeChatExtension-ForMac正…...

用STM32+NRF24L01模拟蓝牙广播,手机能搜到设备了!附完整代码
用STM32NRF24L01模拟蓝牙低功耗广播的实战指南 当我在实验室里第一次看到手机蓝牙搜索列表中出现自己用NRF24L01模块模拟的设备名称时,那种成就感至今难忘。这个看似简单的实验背后,其实隐藏着无线通信协议栈的巧妙设计。本文将带你从零开始,…...

反AI招聘平台hire-humans:重塑以人为本的招聘体验
1. 项目概述:当AI遇见“真人”招聘最近在GitHub上看到一个挺有意思的项目,叫“hire-humans”。光看名字,你可能会觉得这是个普通的招聘网站模板或者人力资源工具。但点进去仔细琢磨,你会发现它的内核远不止于此。这个项目本质上是…...
)
软考 系统架构设计师历年真题集萃(253)
接前一篇文章:软考 系统架构设计师历年真题集萃(252) 第505题 给出关系R(U, F), U = {A,B,C,D,E}, F={A->B, D->C, BC->E, AC->B},求属性闭包的等式成立的是( )。R的候选关键字为( )。 第1空 A. B. C. D. 正确答案:D。 第2空 A. AD B. AB C…...

63岁黄仁勋再添博士头衔、英特尔CEO为其披袍,最新演讲刷屏:人类编写软件、计算机执行指令的范式已终结!
整理 | 苏宓 出品 | CSDN(ID:CSDNnews) 日前,在卡内基梅隆大学(CMU)的 2026 届毕业典礼上,英伟达 CEO 黄仁勋的头衔再加一,最新获得 CMU 科学与技术荣誉博士学位,而这也是…...

怎样高效管理微信社交网络:5个微信工具箱实用技巧完整指南
怎样高效管理微信社交网络:5个微信工具箱实用技巧完整指南 【免费下载链接】wechat-toolbox WeChat toolbox(微信工具箱) 项目地址: https://gitcode.com/gh_mirrors/we/wechat-toolbox 微信工具箱(wechat-toolbox…...

好用的AI软件开发选哪家
在当今数字化飞速发展的时代,AI软件已经成为众多企业和个人提升效率、创新业务的重要工具。然而,面对市场上众多的AI软件开发公司,如何选择一家靠谱且好用的公司成为了许多人的困扰。今天,我就为大家推荐广州飞进信息科技有限公司…...