yolov8行人识别教程(2023年毕业设计+源码)
yolov8识别视频
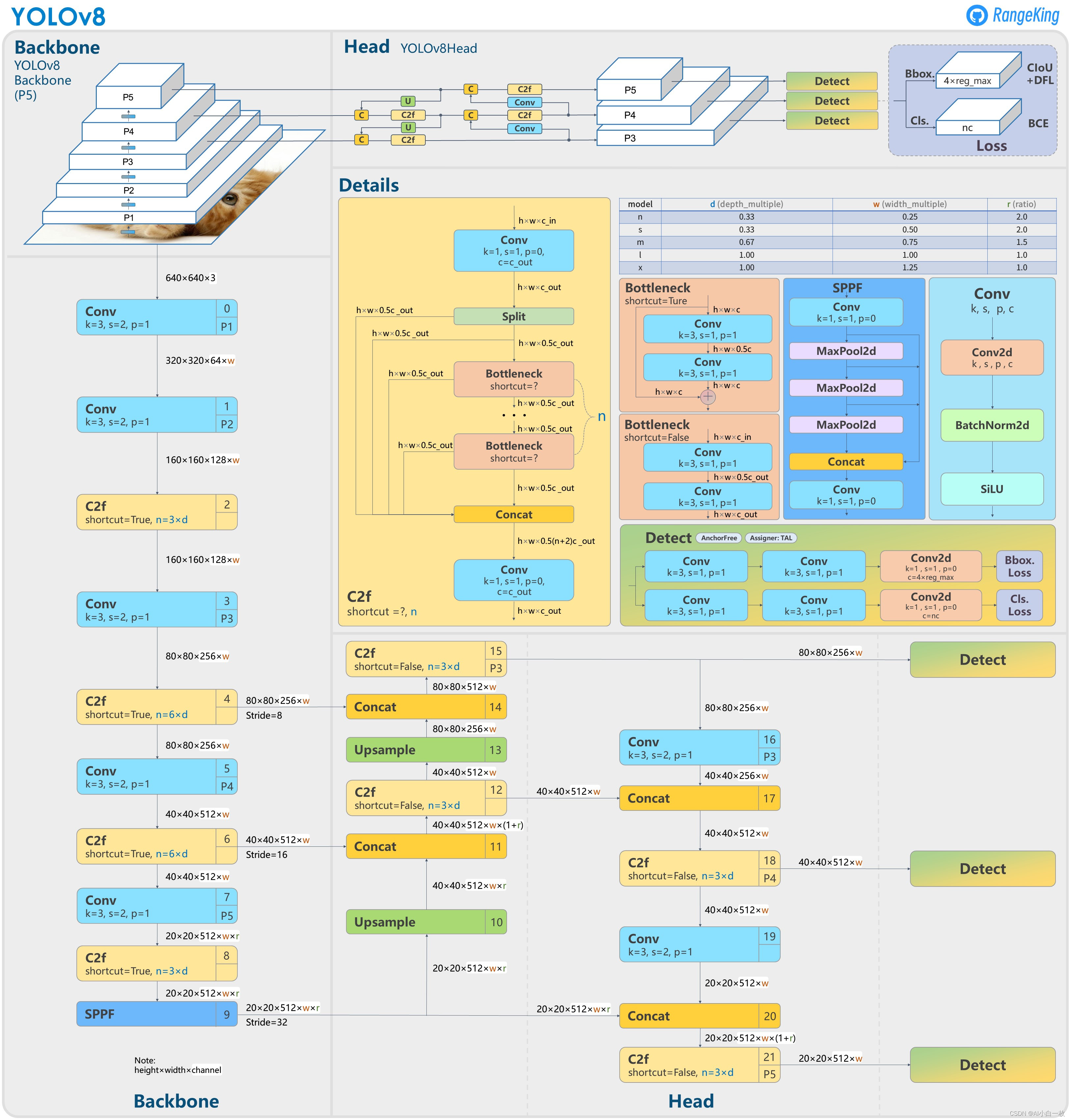
直接上YOLOv8的结构图吧,小伙伴们可以直接和YOLOv5进行对比,看看能找到或者猜到有什么不同的地方?

-
Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
-
PAN-FPN:毫无疑问YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的卷积结构删除了,同时也将C3模块替换为了C2f模块;
-
Decoupled-Head:是不是嗅到了不一样的味道?是的,YOLOv8走向了Decoupled-Head;
-
Anchor-Free:YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
-
损失函数:YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为分类损失;
-
样本匹配:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式。
-
SPPF改进
SPP结构又被称为空间金字塔池化,能将任意大小的特征图转换成固定大小的特征向量。
接下来我们来详述一下SPP是怎么处理滴~
输入层:首先我们现在有一张任意大小的图片,其大小为w * h。
输出层:21个神经元 -- 即我们待会希望提取到21个特征。
分析如下图所示:分别对1 * 1分块,2 * 2分块和4 * 4子图里分别取每一个框内的max值(即取蓝框框内的最大值),这一步就是作最大池化,这样最后提取出来的特征值(即取出来的最大值)一共有1 * 1 + 2 * 2 + 4 * 4 = 21个。得出的特征再concat在一起。
PAN-FPN改进
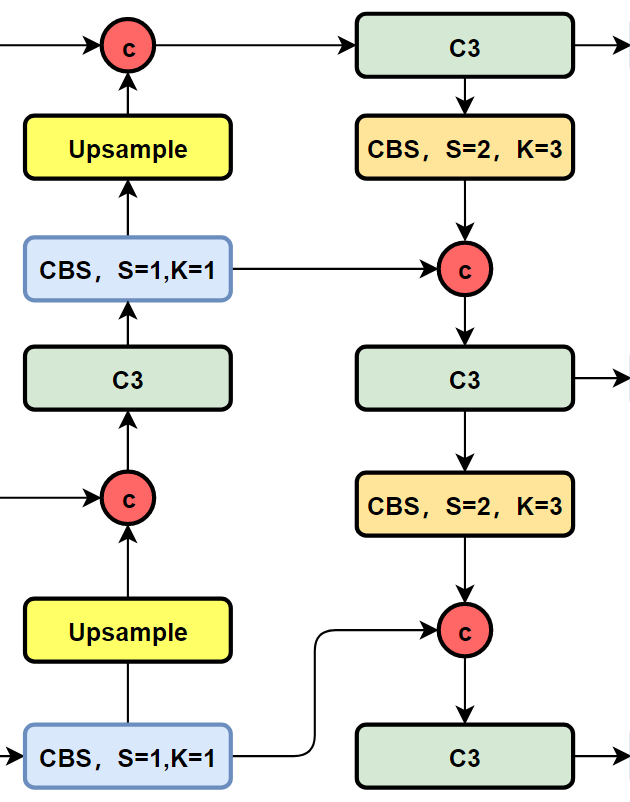
YOLOv6的neck结构图
我们再看YOLOv8的结构图:
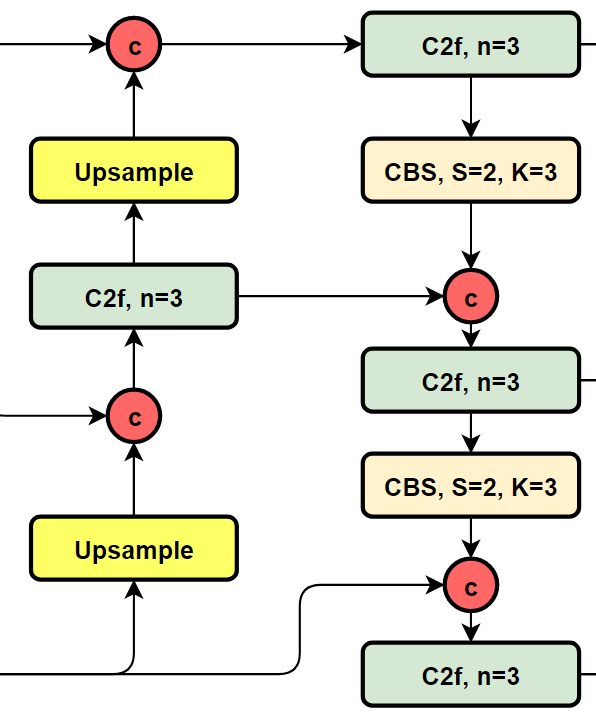
YOLOv8的neck结构图
可以看到,相对于YOLOv5或者YOLOv6,YOLOv8将C3模块以及RepBlock替换为了C2f,同时细心可以发现,相对于YOLOv5和YOLOv6,YOLOv8选择将上采样之前的1×1卷积去除了,将Backbone不同阶段输出的特征直接送入了上采样操作。
2.4、Head部分都变了什么呢?
先看一下YOLOv5本身的Head(Coupled-Head):
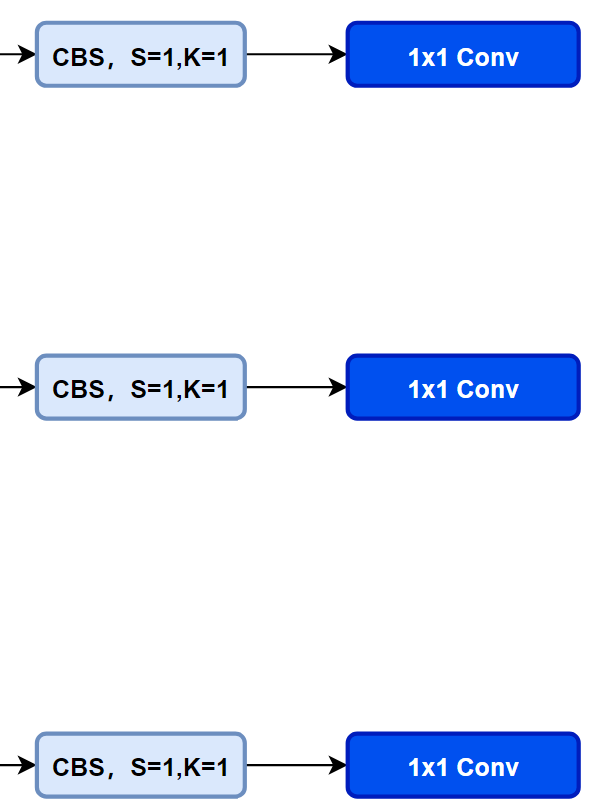
YOLOv5的head结构图
而YOLOv8则是使用了Decoupled-Head,同时由于使用了DFL 的思想,因此回归头的通道数也变成了4*reg_max的形式:
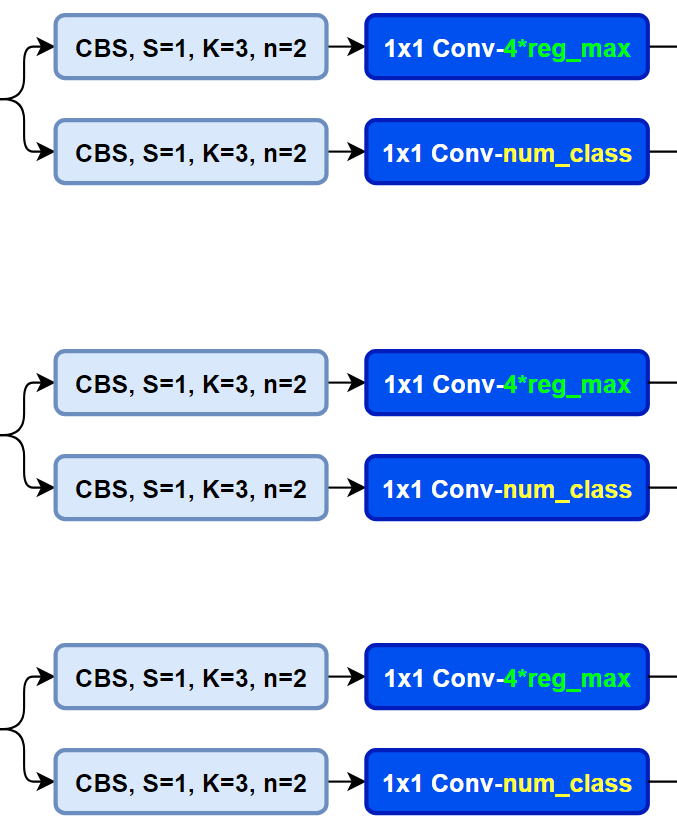
YOLOv8的head结构图
对比一下YOLOv5与YOLOv8的YAML

二、下载yolov8源码
yolov8源码链接:https://github.com/ultralytics/ultralytics
三、环境准备
环境如下:
Ubuntu18.04
cuda11.3
pytorch:1.11.0
torchvision:0.12.0
准备好环境后,先进入自己带pytorch的虚拟环境,与之前的yolo系列安装都不太一样,yolov8仅需要安装ultralytics这一个库就ok了。
pip install ultralytics另一种方法稍显麻烦,需要先克隆git仓库,再进行安装;二者取其一即可。
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
pip install -e .
测试:
运行之后出现两张预测完的图片说明已经成功:
四、数据处理
在yolov8/data目录下新建Annotations, images, ImageSets, labels 四个文件夹
images目录下存放数据集的图片文件
Annotations目录下存放图片的xml文件(labelImg标注) 
将xml文件转换成YOLO系列标准读取的txt文件
在同级目录下再新建一个文件XML2TXT.py
注意classes = [“…”]一定需要填写自己数据集的类别,在这里我是一个类别"fall",因此classes = [“fall”],代码如下所示:
如果数据集中的类别比较多不想手敲类别的,可以使用(4)中的脚本直接获取类别,同时还能查看各个类别的数据量,如果不想可以直接跳过(4)。
# -*- coding: utf-8 -*-
# xml解析包
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import joinsets = ['train', 'test', 'val']
classes = ['fall']# 进行归一化操作
def convert(size, box): # size:(原图w,原图h) , box:(xmin,xmax,ymin,ymax)dw = 1./size[0] # 1/wdh = 1./size[1] # 1/hx = (box[0] + box[1])/2.0 # 物体在图中的中心点x坐标y = (box[2] + box[3])/2.0 # 物体在图中的中心点y坐标w = box[1] - box[0] # 物体实际像素宽度h = box[3] - box[2] # 物体实际像素高度x = x*dw # 物体中心点x的坐标比(相当于 x/原图w)w = w*dw # 物体宽度的宽度比(相当于 w/原图w)y = y*dh # 物体中心点y的坐标比(相当于 y/原图h)h = h*dh # 物体宽度的宽度比(相当于 h/原图h)return (x, y, w, h) # 返回 相对于原图的物体中心点的x坐标比,y坐标比,宽度比,高度比,取值范围[0-1]# year ='2012', 对应图片的id(文件名)
def convert_annotation(image_id):'''将对应文件名的xml文件转化为label文件,xml文件包含了对应的bunding框以及图片长款大小等信息,通过对其解析,然后进行归一化最终读到label文件中去,也就是说一张图片文件对应一个xml文件,然后通过解析和归一化,能够将对应的信息保存到唯一一个label文件中去labal文件中的格式:calss x y w h 同时,一张图片对应的类别有多个,所以对应的bunding的信息也有多个'''# 对应的通过year 找到相应的文件夹,并且打开相应image_id的xml文件,其对应bund文件in_file = open('data/Annotations/%s.xml' % (image_id), encoding='utf-8')# 准备在对应的image_id 中写入对应的label,分别为# <object-class> <x> <y> <width> <height>out_file = open('data/labels/%s.txt' % (image_id), 'w', encoding='utf-8')# 解析xml文件tree = ET.parse(in_file)# 获得对应的键值对root = tree.getroot()# 获得图片的尺寸大小size = root.find('size')# 如果xml内的标记为空,增加判断条件if size != None:# 获得宽w = int(size.find('width').text)# 获得高h = int(size.find('height').text)# 遍历目标objfor obj in root.iter('object'):# 获得difficult ??difficult = obj.find('difficult').text# 获得类别 =string 类型cls = obj.find('name').text# 如果类别不是对应在我们预定好的class文件中,或difficult==1则跳过if cls not in classes or int(difficult) == 1:continue# 通过类别名称找到idcls_id = classes.index(cls)# 找到bndbox 对象xmlbox = obj.find('bndbox')# 获取对应的bndbox的数组 = ['xmin','xmax','ymin','ymax']b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))print(image_id, cls, b)# 带入进行归一化操作# w = 宽, h = 高, b= bndbox的数组 = ['xmin','xmax','ymin','ymax']bb = convert((w, h), b)# bb 对应的是归一化后的(x,y,w,h)# 生成 calss x y w h 在label文件中out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')# 返回当前工作目录
wd = getcwd()
print(wd)for image_set in sets:'''对所有的文件数据集进行遍历做了两个工作:1.将所有图片文件都遍历一遍,并且将其所有的全路径都写在对应的txt文件中去,方便定位2.同时对所有的图片文件进行解析和转化,将其对应的bundingbox 以及类别的信息全部解析写到label 文件中去最后再通过直接读取文件,就能找到对应的label 信息'''# 先找labels文件夹如果不存在则创建if not os.path.exists('data/labels/'):os.makedirs('data/labels/')# 读取在ImageSets/Main 中的train、test..等文件的内容# 包含对应的文件名称image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()# 打开对应的2012_train.txt 文件对其进行写入准备list_file = open('data/%s.txt' % (image_set), 'w')# 将对应的文件_id以及全路径写进去并换行for image_id in image_ids:list_file.write('data/images/%s.jpg\n' % (image_id))# 调用 year = 年份 image_id = 对应的文件名_idconvert_annotation(image_id)# 关闭文件list_file.close()
查看自定义数据集标签类别及数量
在yolov8目录下再新建一个文件ViewCategory.py,将代码复制进去
import os
from unicodedata import name
import xml.etree.ElementTree as ET
import globdef count_num(indir):label_list = []# 提取xml文件列表os.chdir(indir)annotations = os.listdir('.')annotations = glob.glob(str(annotations) + '*.xml')dict = {} # 新建字典,用于存放各类标签名及其对应的数目for i, file in enumerate(annotations): # 遍历xml文件# actual parsingin_file = open(file, encoding='utf-8')tree = ET.parse(in_file)root = tree.getroot()# 遍历文件的所有标签for obj in root.iter('object'):name = obj.find('name').textif (name in dict.keys()):dict[name] += 1 # 如果标签不是第一次出现,则+1else:dict[name] = 1 # 如果标签是第一次出现,则将该标签名对应的value初始化为1# 打印结果print("各类标签的数量分别为:")for key in dict.keys():print(key + ': ' + str(dict[key]))label_list.append(key)print("标签类别如下:")print(label_list)if __name__ == '__main__':# xml文件所在的目录,修改此处indir = 'data/Annotations'count_num(indir) # 调用函数统计各类标签数目
修改数据加载配置文件
进入data/文件夹,新建fall.yaml,内容如下,注意txt需要使用绝对路径
train: /home/xxx/yolov8/data/train.txt
val: /home/xxx/yolov8/data/val.txt
test: /home/xxx/yolov8/data/test.txt# number of classes
nc: 1# class names
names: ['fall']
五、模型训练
打开终端(或者pycharm等IDE),进入虚拟环境,随后进入yolov8文件夹,在终端中输入下面命令,即可开始训练。
yolo task=detect mode=train model=yolov8n.pt data=data/fall.yaml batch=32 epochs=100 imgsz=640 workers=16 device=0
六、模型验证
yolo task=detect mode=val model=runs/detect/train3/weights/best.pt data=data/fall.yaml device=0
七、模型预测
yolo task=detect mode=predict model=runs/detect/train3/weights/best.pt source=data/images device=0
八、模型导出
yolo task=detect mode=export model=runs/detect/train3/weights/best.pt
订阅专栏获得源码
相关文章:
yolov8行人识别教程(2023年毕业设计+源码)
yolov8识别视频直接上YOLOv8的结构图吧,小伙伴们可以直接和YOLOv5进行对比,看看能找到或者猜到有什么不同的地方? Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻…...

CAD指令框找不到了怎么调出来?CAD指令框调出方法
CAD制图过程中,为了提高设计师的绘图效率,经常会用到各种CAD命令快捷键,可是CAD指令框突然不见了,这就让人很头疼了。CAD指令框找不到了怎么调出来呢?本节内容小编以浩辰CAD软件为例来给大家分享一下CAD指令框调出方法…...
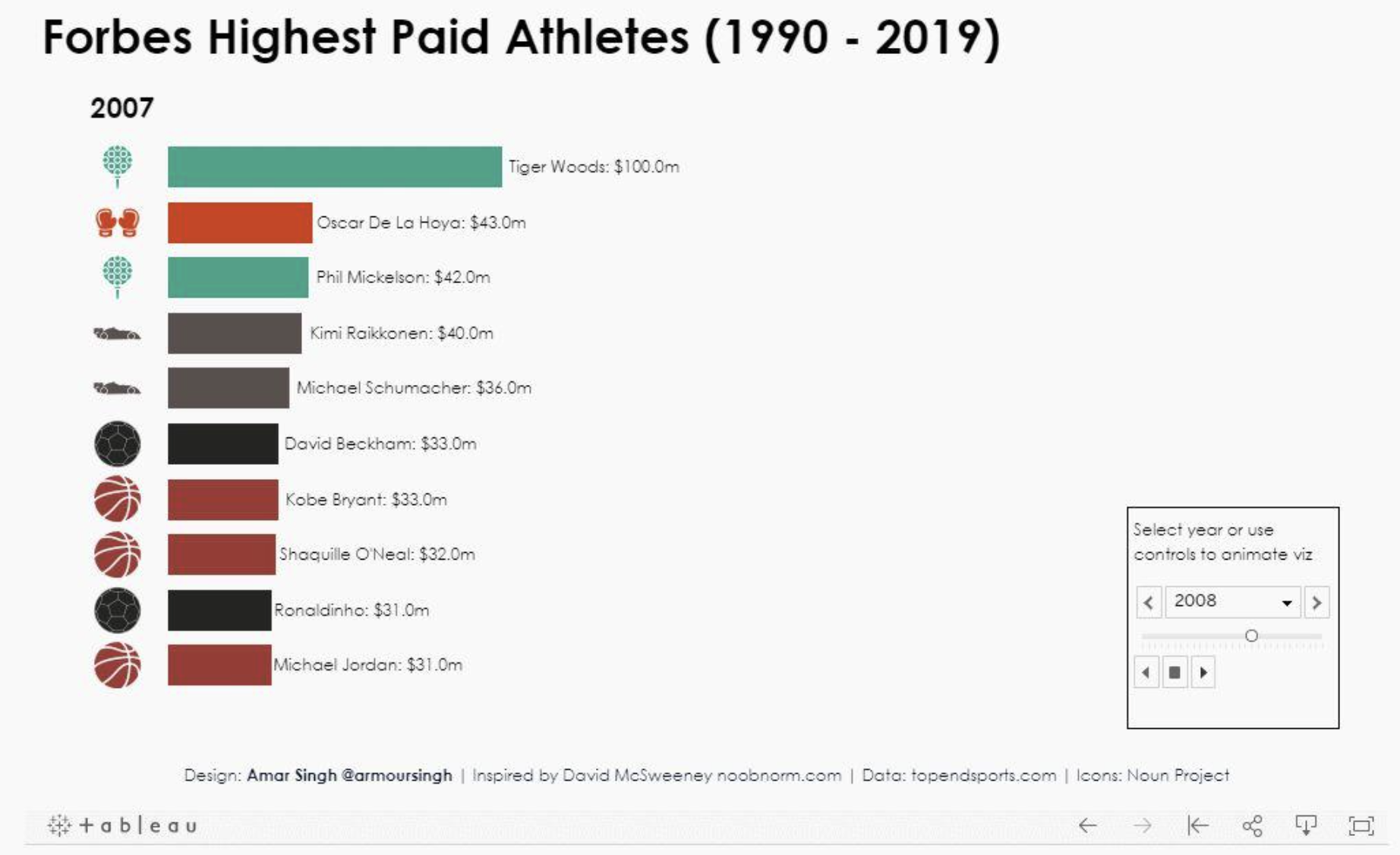
一般用哪些工具做大数据可视化分析?
做数据分析这些年来,从刚开始的死磕excel,到现在成为数据分析行业的偷懒大户,使用过的工具还真不少! 这篇分享一些我在可视化工具上的使用心得,由简单到复杂,按照可视化类型一共分为纯统计图表类、GIS地图…...

Python每日一练(20230308)
目录 1. Excel表列名称 ★ 2. 同构字符串 ★★ 3. 分割回文串 II ★★★ 🌟 每日一练刷题专栏 C/C 每日一练 专栏 Python 每日一练 专栏 1. Excel表列名称 给你一个整数 columnNumber ,返回它在 Excel 表中相对应的列名称。 例如࿱…...
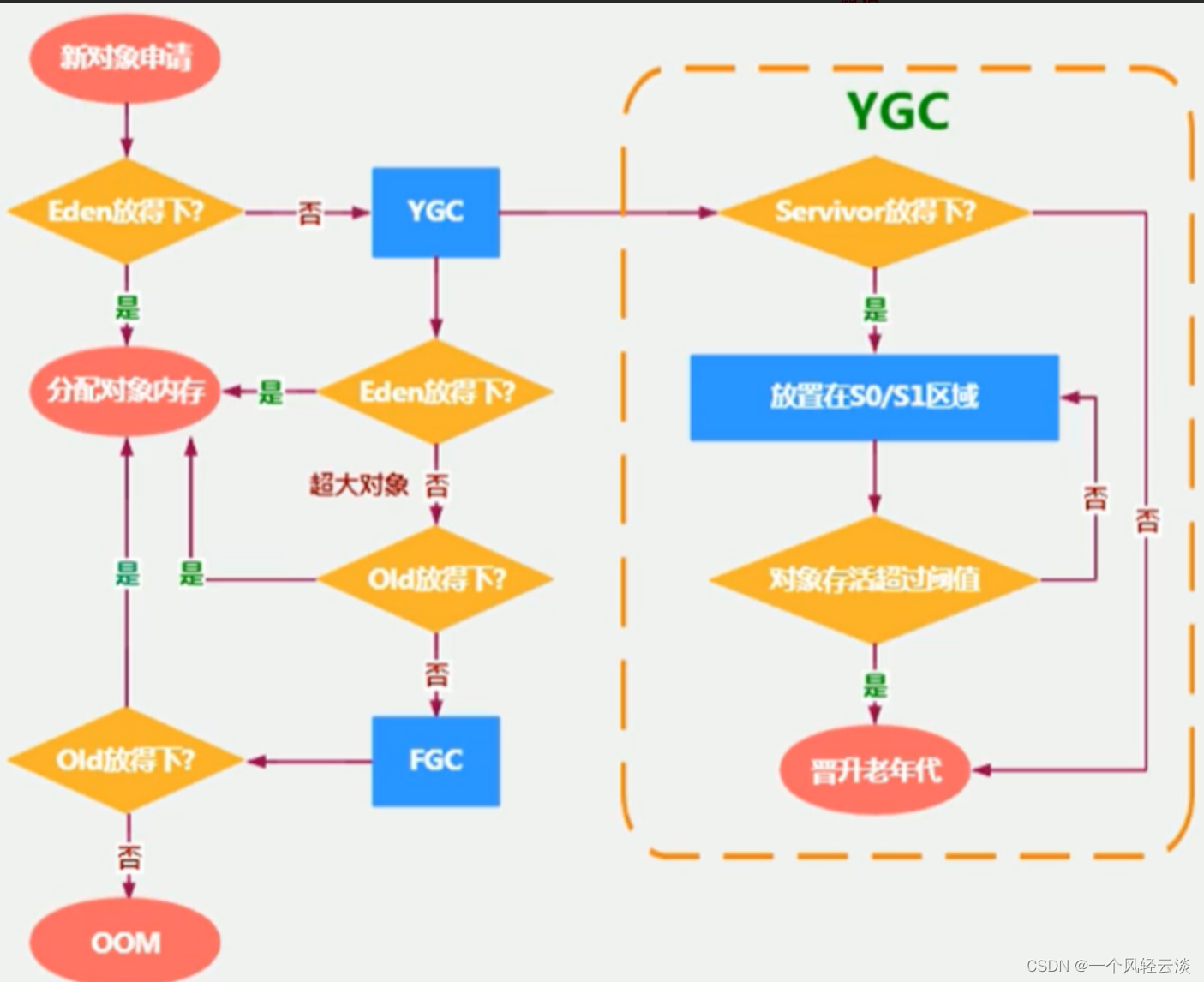
jvm之堆解读
堆(Heap)的核心概述 堆针对一个JVM进程来说是唯一的,也就是一个进程只有一个JVM,但是进程包含多个线程,他们是共享同一堆空间的。 一个JVM实例只存在一个堆内存,堆也是Java内存管理的核心区域。 Java堆区…...

重构·改善既有代码的设计.02
前言之前在《重构改善既有代码的设计.01》中初步了解了重构的基本前提,基础原则等入门知识。今天我们继续第二更......识别代码的坏味道Duplicated Code 重复代码。最单纯的Duplicated Code就是“同一个类中含有相同的表达式”或“两个互为兄弟的子类内含有相同表达…...

脑电信号处理总成
目录一. EEG(脑电图)1.1 脑波1.2 伪迹1.2.1 眼动伪迹1.2.2 肌电伪迹1.2.3 运动伪迹1.2.4 心电伪迹1.2.5 血管波伪迹1.2.6 50Hz和静电干扰1.3 伪迹去除方法1.3.1 避免伪迹产生法1.3.2 直接移除法1.3.3 伪迹消除法一. EEG(脑电图) 1.1 脑波 脑波(英语:br…...
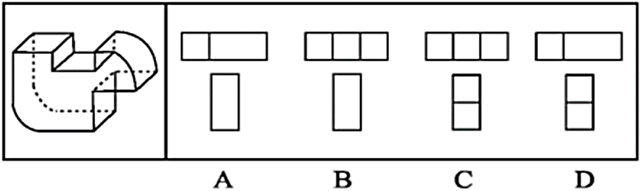
判断推理之图形推理
考点一动态位置变化(一)平移1.特征:图形在平面上的移动,图形本身的大小和形状不发生改变。2.方向:直线(上下、左右、斜对角线),绕圈(顺时针、逆时针)3.距离&a…...

【预告】ORACLE Unifier v22.12 虚拟机发布
引言 离ORACLE Primavera Unifier 最新系统 v22.12已过去了3个多月,应盆友需要,也为方便大家体验,我近日将构建最新的Unifier的虚拟环境,届时将分享给大家,最终可通过VMWare vsphere (esxi) / workstation 或Oracle …...
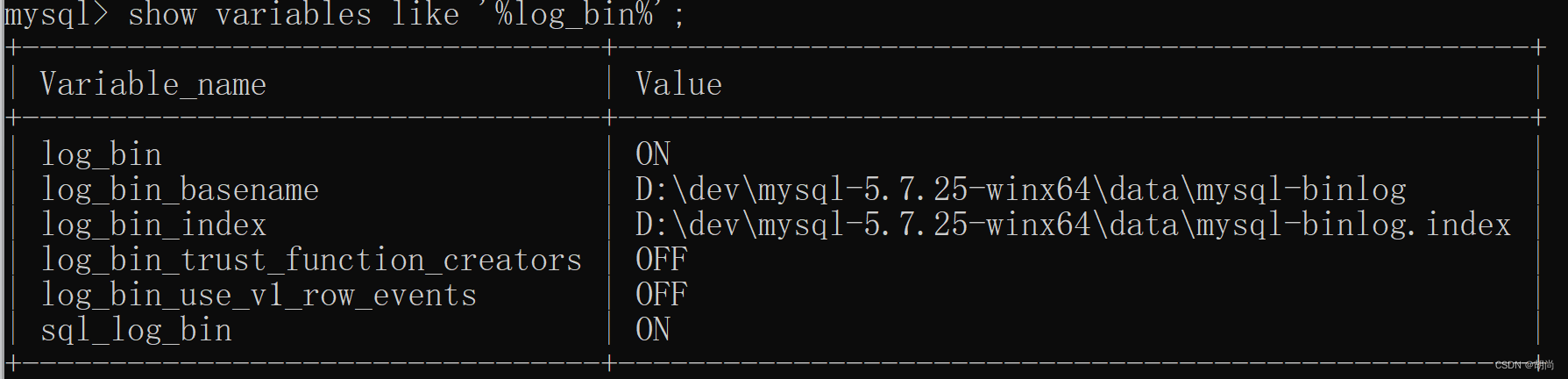
Sql执行流程与Redo log、 Undo log、 Bin log日志文件
文章目录Sql执行流程与日志文件Sql的执行流程Redo LogBin logUndo logSql执行流程与日志文件 Sql的执行流程 mysql的内部组件结构如下图所示 连接器 与客户端建立连接,检验登录密码,分配相应权限 查询缓存 执行sql语句时会先从这里找一下,…...

如何提高软件测试执行力
高效的测试执行力 不管在哪个行业,高校的执行力都是不可或缺的。在软件测试行业更是这样。有些测试人员,很勤奋也很吃苦,但是可能最终不能很好的完成测试任务。究其原因就是一个测试执行力的问题。 高效执行就是有目标,有计划&…...

Open3D 计算点到平面的距离
目录 一、算法原理二、代码实现三、结果展示一、算法原理 平面外一点 ( x 1 , y 1 , z 1 ) (x_1,y_1,z_1) (x...
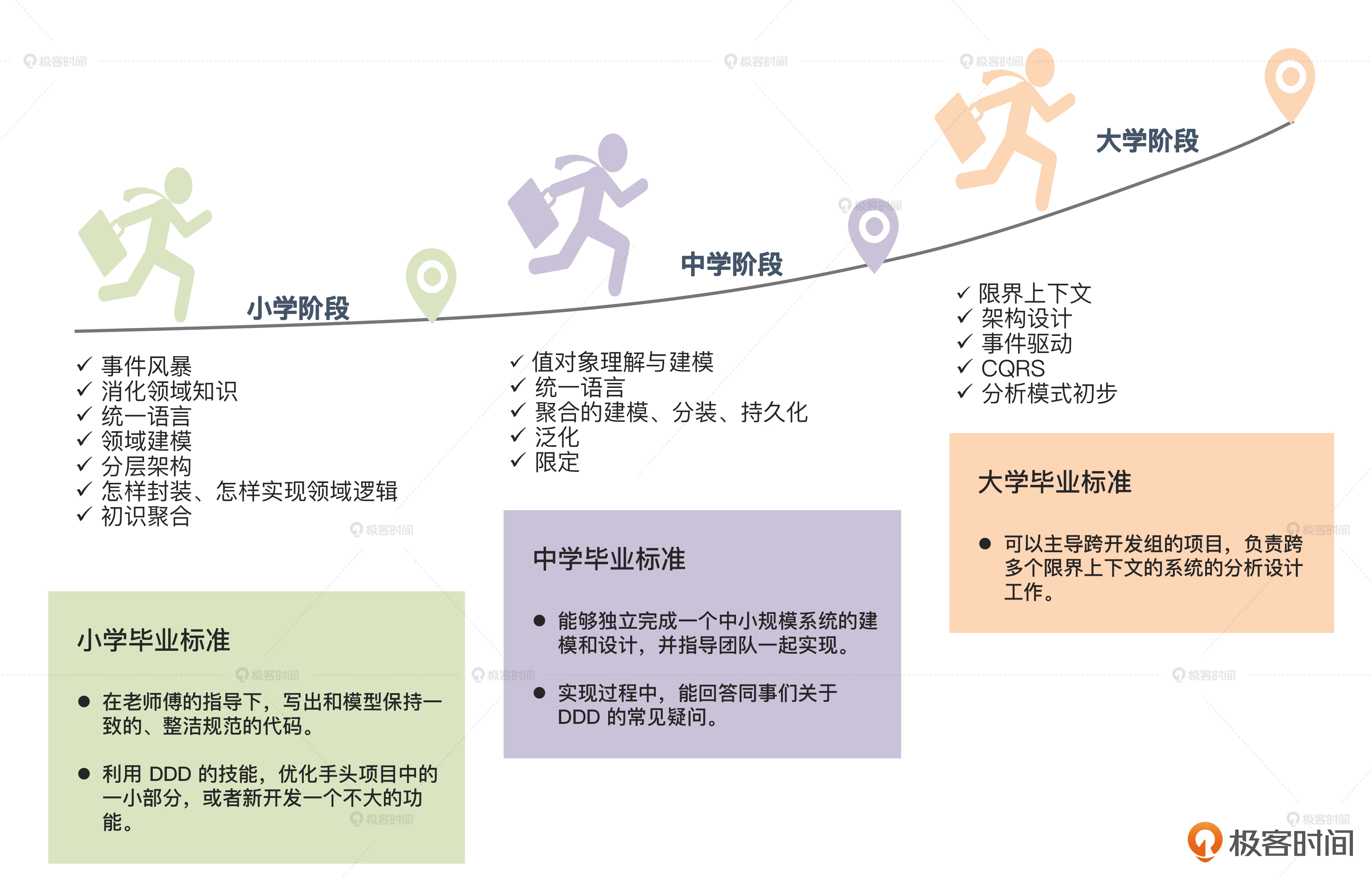
DDD领域驱动设计初探
DDD 强调领域模型要兼顾业务和技术两个视角。 我们怎么用一套系统化的方法,抽丝剥茧、一步一步地把需求落实到代码呢?咱们看看下面这张图,它表示了领域驱动设计中的主要流程。 领域驱动设计主要的开发流程你可以看到,在整个开发流…...
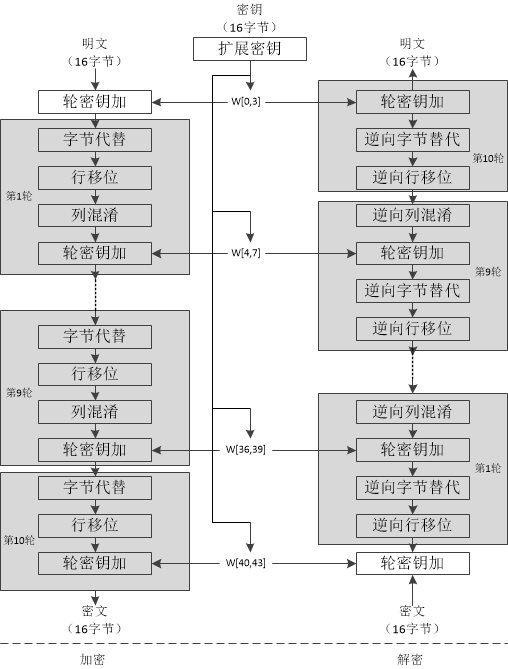
C中AES_cbc_encrypt加密对应java中的解密
前言知识: 1.AES(Advanced Encryption Standard)高级加密标准,作为分组密码(把明文分成一组一组的,每组长度相等,每次加密一组数据,直到加密完整个明文)。 2.在AES标准…...

演化算法:乌鸦搜索算法 (Crow Search Algorithm)
前言 如果你对这篇文章感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。 在机器学习中,我们所要优化的问题很多时候难以求导,因此通常会采用一些演化算法(又称零…...

基于open62541的OPC UA服务器和客户端开发技术
一、OPC UA的基本概念 1、OPC(OLE for Process Control),是一个工业标准,管理这个标准的国际组织是OPC基金会; 2、OPC通信结构:是指包含一个或多个OPC客户端与服务器相互通信的集合。以下是一个简单的流程图:标准的C/S结构。 3、OPC服务器:TOPC基金会定义了四种;...
测试测开面试要知道的那些事01
列表与元组的区别列表是动态数组,它们可变且可以重设长度(改变其内部元素的个数)。元组是静态数组,它们不可变,且其内部数据一旦创建便无法改变。元组缓存于Python运行时环境,这意味着我们每次使用元组时无…...
物联网毕设 -- 智能厨房监测系统(改)
前言 在家庭生活中,厨房是必不可少的,所以厨房的安全问题关乎着我们大家的生命,所以提出智能厨房监测系统,目的就是为我们减少不必要的安全问题 ⚠️⚠️(本文章仅提供思路和实现方法,并不包含代码&#x…...

macOS 13.3 Beta 3 (22E5236f)发布
系统介绍3 月 8 日消息,苹果今日向 Mac 电脑用户推送了 macOS 13.3 开发者预览版 Beta 3 更新(内部版本号:22E5236f),本次更新距离上次发布隔了 7 天。macOS Ventura 带来了台前调度、连续互通相机、FaceTime 通话接力…...

Failed to configure a DataSource: ‘url‘ attribute
一 完整的错误信息 *************************** APPLICATION FAILED TO START *************************** Description: Failed to configure a DataSource: url attribute is not specified and no embedded datasource could be configured. Reason: Failed to dete…...

404 Not Found 与 500 Internal Server Error 全方位解析
前言在日常开发与运维中,HTTP 状态码是我们最常打交道的一类信号。其中,404 与 500 两类错误几乎占据了线上问题的一半以上。你是否遇到过:用户反馈页面打不开,浏览器提示 404 Not Found,但实际上资源明明存在…...
)
UWB-IMU、UWB定位对比研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

对比直接使用官方 API,Taotoken 在批量处理任务中的用量可视化优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API,Taotoken 在批量处理任务中的用量可视化优势 当开发团队或个人开发者需要处理大量文本生成任务时…...

一键下载国家中小学智慧教育平台电子课本:让教育资源获取更简单高效
一键下载国家中小学智慧教育平台电子课本:让教育资源获取更简单高效 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容…...

2026毕业季必看!告别求职死循环,这两个高薪赛道让你稳上岸!
家人们谁都没想到,2026年毕业季求职难度直接拉满,堪称历年最难就业季!全国1270万高校毕业生扎堆涌入求职市场,岗位僧多粥少、竞争内卷到极致,无数应届生陷入一模一样的求职困境:精心打磨的简历海投出去&…...

Lumi Diary:基于OpenClaw Skill的本地AI记忆伴侣设计与实践
1. 项目概述:一个住在你设备里的记忆精灵如果你和我一样,对把生活点滴交给云端总有点不放心,但又渴望有一个能懂你、能帮你把碎片记忆编织成故事的伙伴,那么 Lumi Diary 的出现,可能正是时候。这不是又一个需要你手动打…...
)
ChatGPT 2026新增“因果推理引擎”功能(OpenAI内部白皮书首次公开)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT 2026“因果推理引擎”功能全景概览 ChatGPT 2026 引入的“因果推理引擎”(Causal Reasoning Engine, CRE)标志着大语言模型从关联统计迈向可解释性因果建模的关键跃迁。…...

生成式AI破解基因型-表型关联:AIPheno项目实战解析
1. 项目概述:当生成式AI遇见基因表型 如果你在生物信息学或者遗传育种领域工作,最近几年一定被“基因型-表型关联”这个老大难问题折磨过。我们手里有海量的基因组测序数据(基因型),也积累了大量的生物体性状数据&…...

NodeMCU PyFlasher:ESP8266图形化固件烧录终极解决方案
NodeMCU PyFlasher:ESP8266图形化固件烧录终极解决方案 【免费下载链接】nodemcu-pyflasher Self-contained NodeMCU flasher with GUI based on esptool.py and wxPython. 项目地址: https://gitcode.com/gh_mirrors/no/nodemcu-pyflasher 对于ESP8266开发者…...

数据分析进阶——【连载 5/9】《Power BI数据分析与可视化案例教程》项目5 数据建模
Power BI 数据建模教程|推介总结 适应人群:数据分析师、业务分析人员、财务 / 运营 / 销售岗、高校学生、企业内训学员、Power BI 进阶学习者。 重要性总结:本文档是 Power BI 数据建模核心实操教程,系统讲解数据建模全流程&#…...