Selenium+Chrome Driver 爬取搜狐页面信息
进行selenium包和chromedriver驱动的安装
安装selenium包
在命令行或者anaconda prompt 中输入 pip install Selenium
安装 chromedriver
先查看chrome浏览器的版本
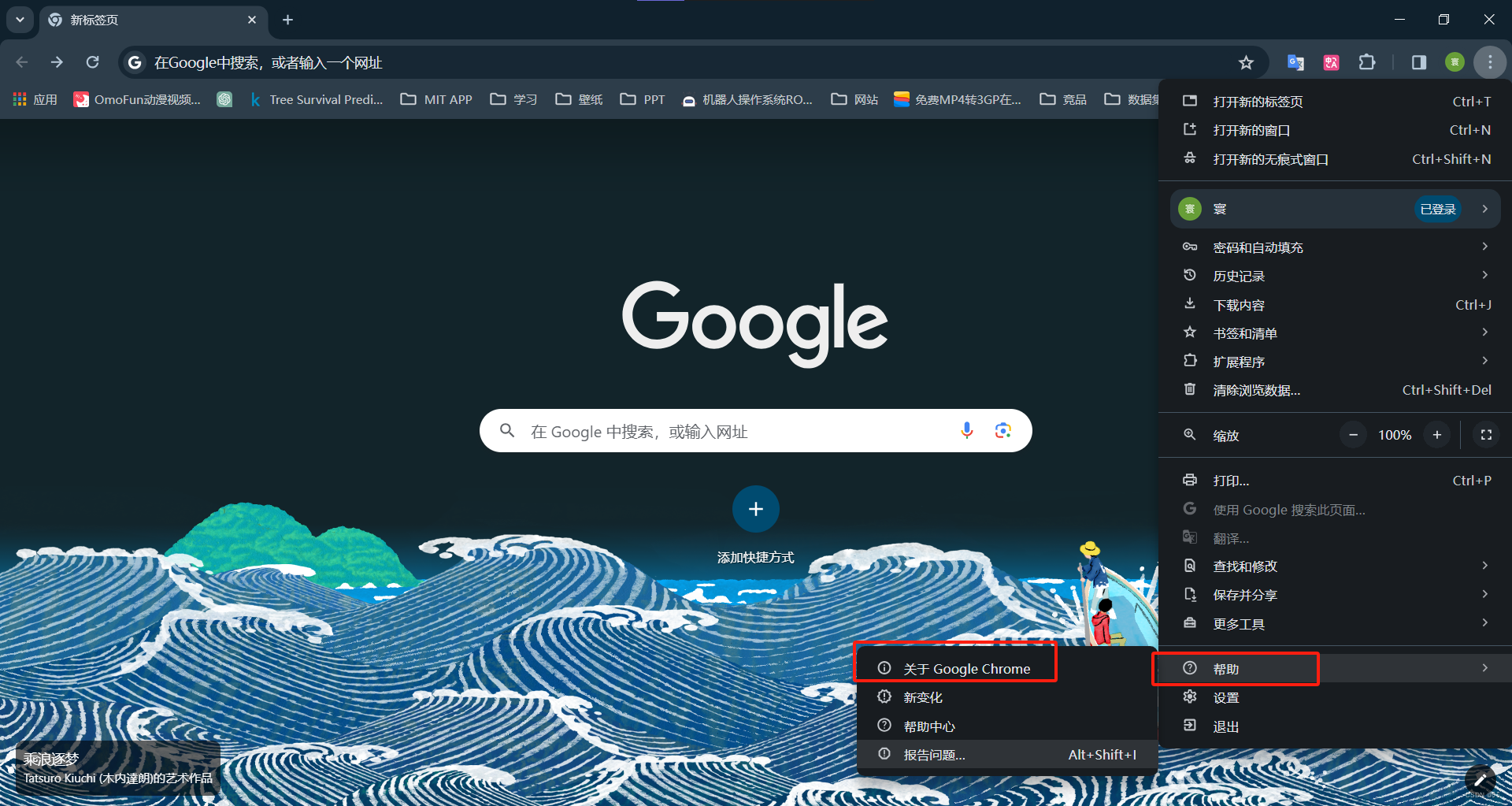

这里是 123.0.6312.106 版
然后在http://npm.taobao.org/mirrors/chromedriver/或者https://googlechromelabs.github.io/chrome-for-testing/
中下载对应版本的chromediver
由于没有106版的这里下的是105版

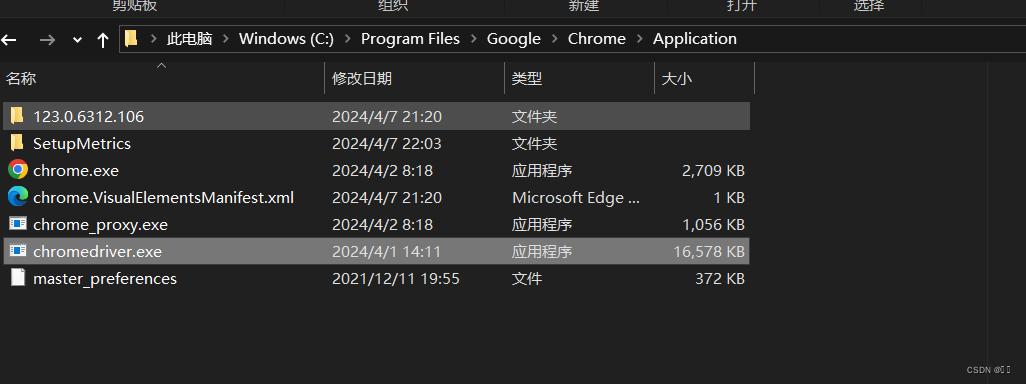
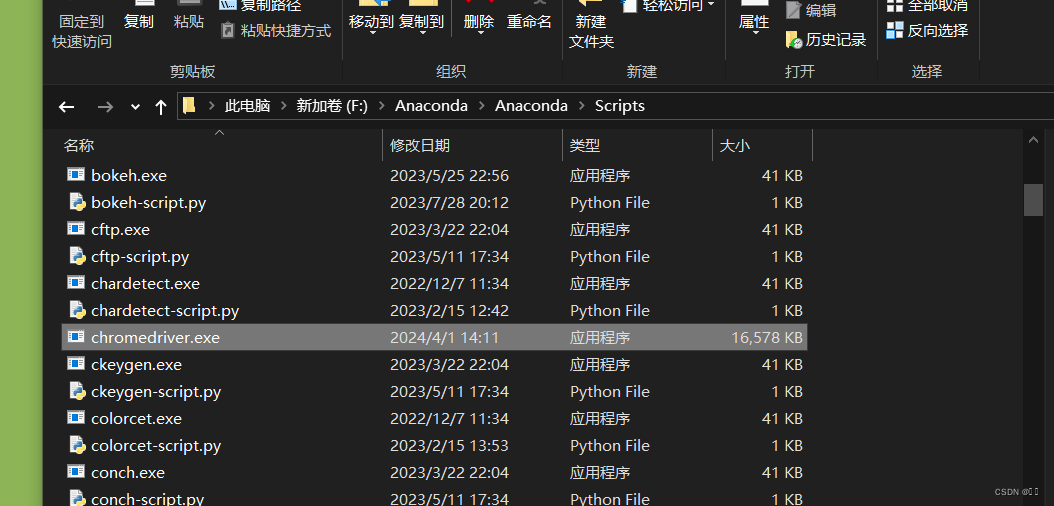
下载解压后
把exe文件复制到chrome浏览器的安装目录和
python的安装目录scripts文件夹下 或者 放到Anaconda的scripts文件夹下
或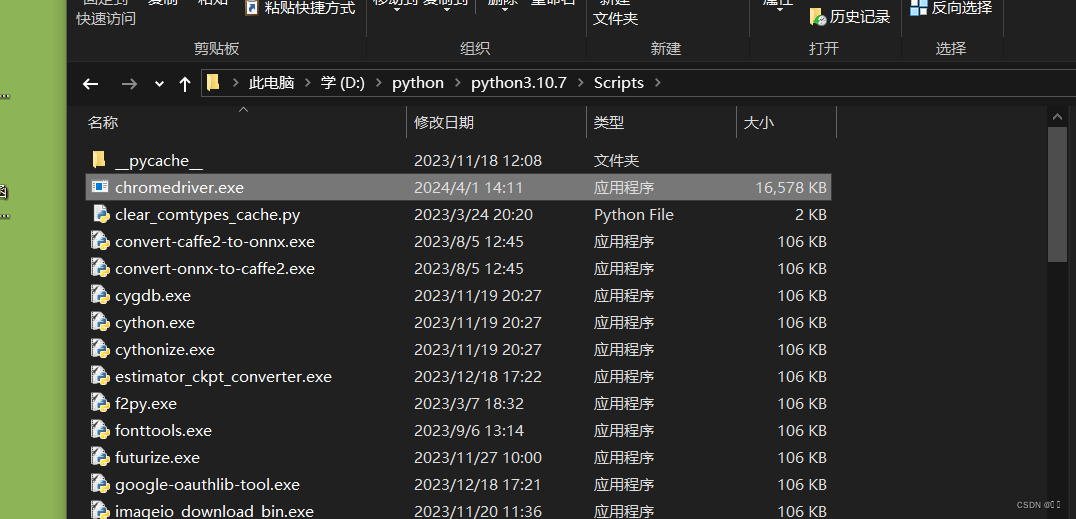
测试
from selenium import webdriver
browser=webdriver.Chrome()
browser.get('https://www.sohu.com/')
自动打开搜狐页面即可

注: 浏览器自动更新后,chromediver 也需要重新下载,并按以上路径配置
Selenium+Chrome Driver 爬取搜狐页面信息
在selenium中不同的版本,语法的用法具有差异
按照书上的用chromedriver访问搜狐页面代码报错如下
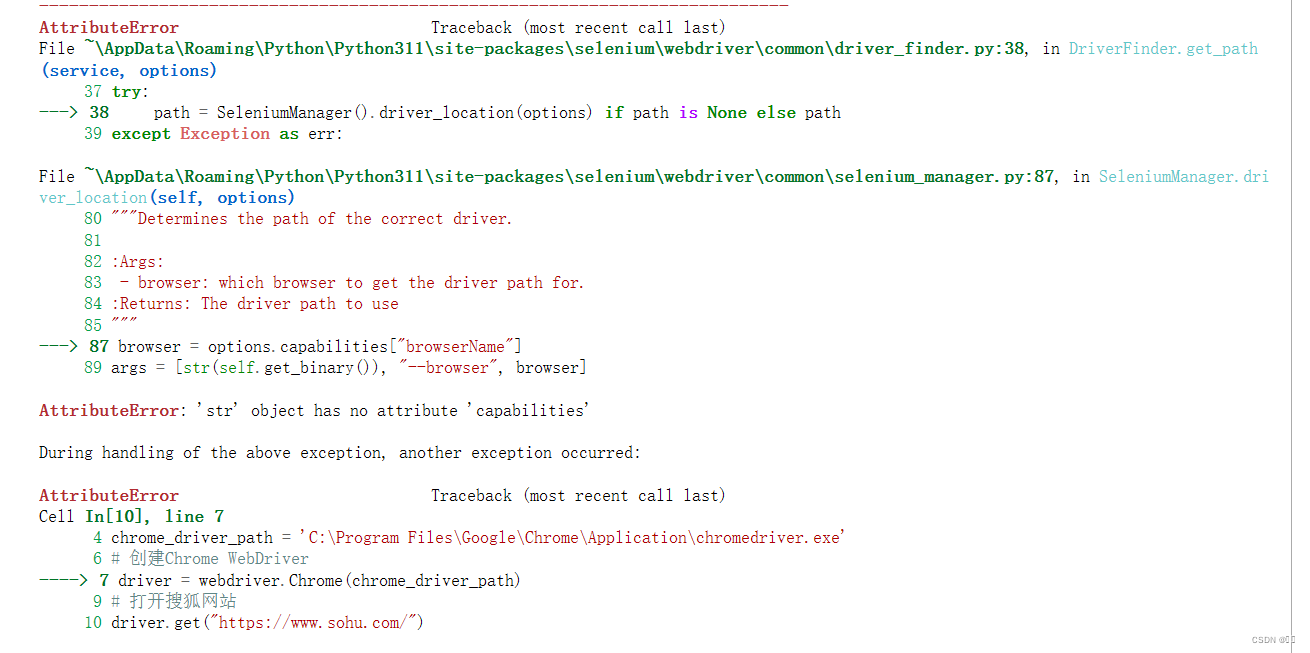
chrome_driver_path传给webdriver.Chrome()时方式不对
可参考下面这位博主的语法进行修改
http://t.csdnimg.cn/xxGhp
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
chrome_driver_path = 'F:/chromedriver/chromedriver-win64/chromedriver.exe'# 创建 Chrome WebDriver
service = Service(chrome_driver_path)
driver = webdriver.Chrome(service=service)
代码实现
导入包
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium import webdriver:
导入了Selenium库中的webdriver模块,它包含了各种WebDriver的实现,用于模拟不同的浏览器行为。
from selenium.webdriver.chrome.service import Service:
导入了Service类,它用于配置和启动ChromeDriver服务。
from selenium.webdriver.chrome.options import Options:
导入了Options类,它用于配置Chrome浏览器的选项,例如设置浏览器的头less模式等。
from selenium.webdriver.common.by import By:
导入了By类,它定义了一些用于查找元素的方法,例如通过class name、id等。
配置ChromeDriver 的路径并启动浏览器
# 设置 ChromeDriver 的路径
chrome_driver_path = 'F:/chromedriver/chromedriver-win64/chromedriver.exe'# 创建 Chrome WebDriver# # 创建 Chrome Options 对象
# chrome_options = Options()
# chrome_options.add_argument('--headless') # 无头模式,即不显示浏览器窗口service = Service(chrome_driver_path)
driver = webdriver.Chrome(service=service)# 打开搜狐网站
driver.get("https://www.sohu.com/")
获取当前页面的Html源码
# 获取当前网页的 HTML 源码
html_source = driver.page_source
print("HTML 源码:")
print(html_source)
运行结果如图所示

获取当前页面的URL
# 获取当前网页的 URL
current_url = driver.current_url
print("\n当前网页的 URL:")
print(current_url)
运行结果如图所示

获取classname为‘txt’的页面元素
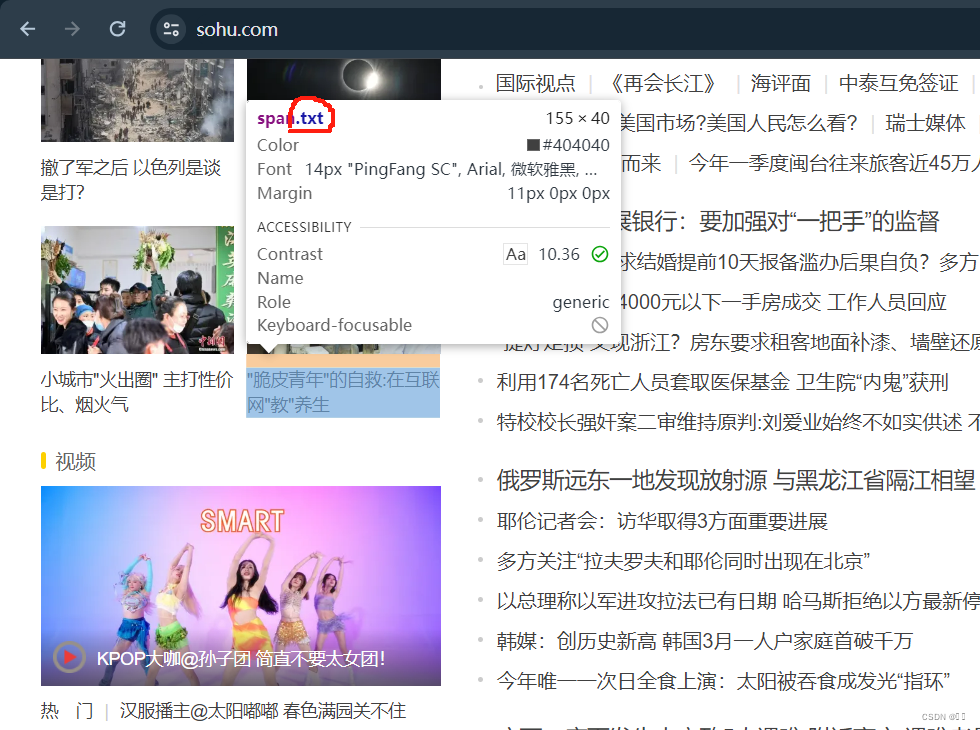

# 使用 find_elements 方法查找 class 属性为 'txt' 的元素
txt_elements = driver.find_elements(By.CLASS_NAME, "txt")# 遍历输出每个元素的文本内容
for element in txt_elements:print(element.text)
运行结果如图所示

获取 标签 属性为 ‘footer’ 的元素文本
# 使用 find_elements 方法查找 标签 属性为 'footer' 的元素
txt_elements = driver.find_elements(By.TAG_NAME, "footer")# 遍历输出每个元素的文本内容
for element in txt_elements:print(element.text)
运行结果如下图所示

获取 class 属性为 ‘titleStyle’ 的元素的文本及href链接
# 使用 find_elements 方法查找 class 属性为 'titleStyle' 的元素
title_elements = driver.find_elements(By.CLASS_NAME, "titleStyle")# 遍历输出每个元素的文本内容
for element in title_elements:text = element.texthref = element.get_attribute("href")print(f"Text: {text}, Href: {href}")
运行结果如下图所示

获取 xpath 搜狐首页的导航栏标签 及 href链接
# 使用 find_elements 方法查找 xpath 搜狐首页的导航栏标签
title_elements = driver.find_elements(By.XPATH, "/html/body/div[2]/div/nav[@class='nav area']//a")# 遍历输出每个元素的文本内容
for element in title_elements:text = element.get_attribute("innerHTML").strip()if text:href = element.get_attribute("href")print(f"Text: {text}, Href: {href}")
运行结果如下图示
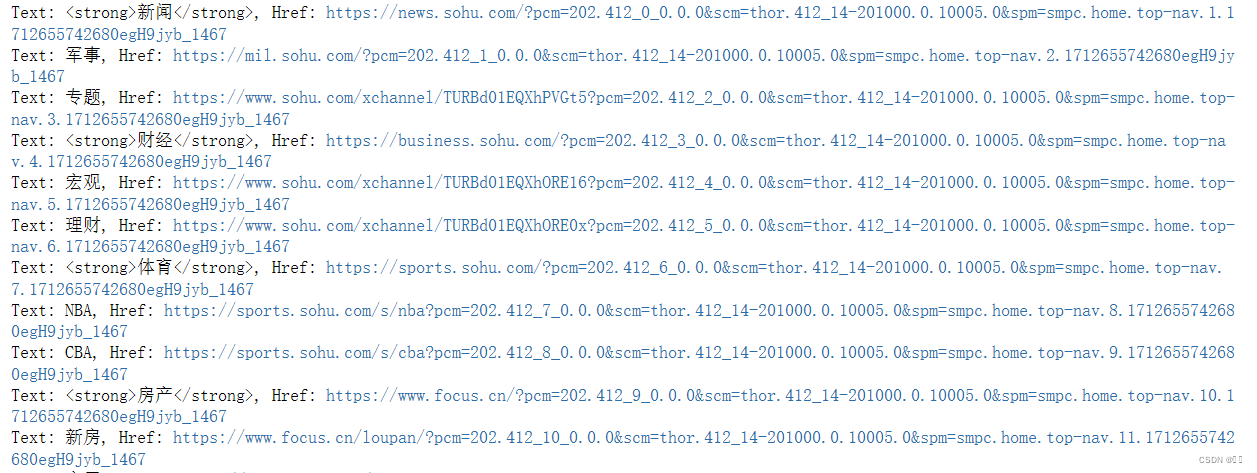
这里运行出来后大的标签会有<strong></strong>
可以通过正则表达式进行优化
优化代码如下
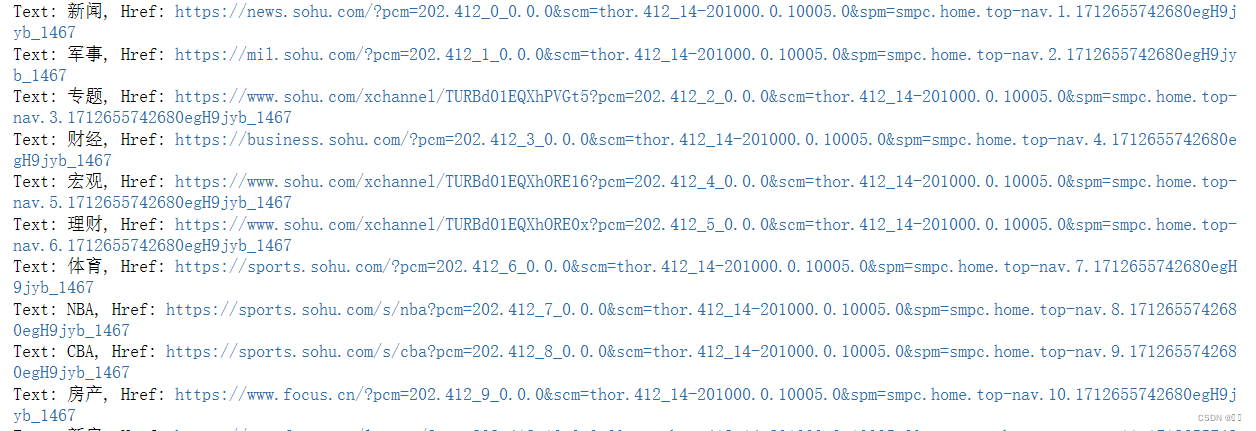
import re# 使用 find_elements 方法查找 xpath 搜狐首页的导航栏标签
title_elements = driver.find_elements(By.XPATH, "/html/body/div[2]/div/nav[@class='nav area']//a")# 遍历输出每个元素的文本内容
for element in title_elements:inner_html = element.get_attribute("innerHTML")text = re.sub(r'<[^>]*>', '', inner_html).strip()if text:href = element.get_attribute("href")print(f"Text: {text}, Href: {href}")
<:匹配左尖括号,表示 HTML 标签的开始。
[^>]:匹配除了右尖括号之外的任何字符。
*:匹配前面的字符零次或多次,即匹配任意数量的除右尖括号之外的字符。 >:匹配右尖括号,表示 HTML 标签的结束。
re.sub(pattern, repl, string)
pattern:要匹配的正则表达式模式。
repl:用于替换匹配文本的字符串。
string:要进行替换操作的原始字符串。
运行结果如下图所示
关闭 WebDriver
# 关闭 WebDriver
driver.quit()
完整代码
import re
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By# 设置 ChromeDriver 的路径
chrome_driver_path = 'F:/chromedriver/chromedriver-win64/chromedriver.exe'# 创建 Chrome WebDriver# # 创建 Chrome Options 对象
# chrome_options = Options()
# chrome_options.add_argument('--headless') # 无头模式,即不显示浏览器窗口service = Service(chrome_driver_path)
driver = webdriver.Chrome(service=service)# 打开搜狐网站
driver.get("https://www.sohu.com/")# 获取当前网页的 HTML 源码
html_source = driver.page_source
print("HTML 源码:")
print(html_source)# 获取当前网页的 URL
current_url = driver.current_url
print("\n当前网页的 URL:")
print(current_url)# 使用 find_elements 方法查找 class 属性为 'txt' 的元素
txt_elements = driver.find_elements(By.CLASS_NAME, "txt")# 遍历输出每个元素的文本内容
for element in txt_elements:print(element.text)# 使用 find_elements 方法查找 标签 属性为 'footer' 的元素
txt_elements = driver.find_elements(By.TAG_NAME, "footer")# 遍历输出每个元素的文本内容
for element in txt_elements:print(element.text)# 使用 find_elements 方法查找 class 属性为 'titleStyle' 的元素
title_elements = driver.find_elements(By.CLASS_NAME, "titleStyle")# 遍历输出每个元素的文本内容
for element in title_elements:text = element.texthref = element.get_attribute("href")print(f"Text: {text}, Href: {href}")# # 使用 find_elements 方法查找 xpath 搜狐首页的导航栏标签
# title_elements = driver.find_elements(By.XPATH, "/html/body/div[2]/div/nav[@class='nav area']//a")# # 遍历输出每个元素的文本内容
# for element in title_elements:
# text = element.get_attribute("innerHTML").strip()
# if text:
# href = element.get_attribute("href")
# print(f"Text: {text}, Href: {href}")# 使用 find_elements 方法查找 xpath 搜狐首页的导航栏标签
title_elements = driver.find_elements(By.XPATH, "/html/body/div[2]/div/nav[@class='nav area']//a")# 遍历输出每个元素的文本内容
for element in title_elements:inner_html = element.get_attribute("innerHTML")text = re.sub(r'<[^>]*>', '', inner_html).strip()if text:href = element.get_attribute("href")print(f"Text: {text}, Href: {href}")# 关闭 WebDriver
driver.quit()
相关文章:
Selenium+Chrome Driver 爬取搜狐页面信息
进行selenium包和chromedriver驱动的安装 安装selenium包 在命令行或者anaconda prompt 中输入 pip install Selenium 安装 chromedriver 先查看chrome浏览器的版本 这里是 123.0.6312.106 版 然后在http://npm.taobao.org/mirrors/chromedriver/或者https://googlechrom…...
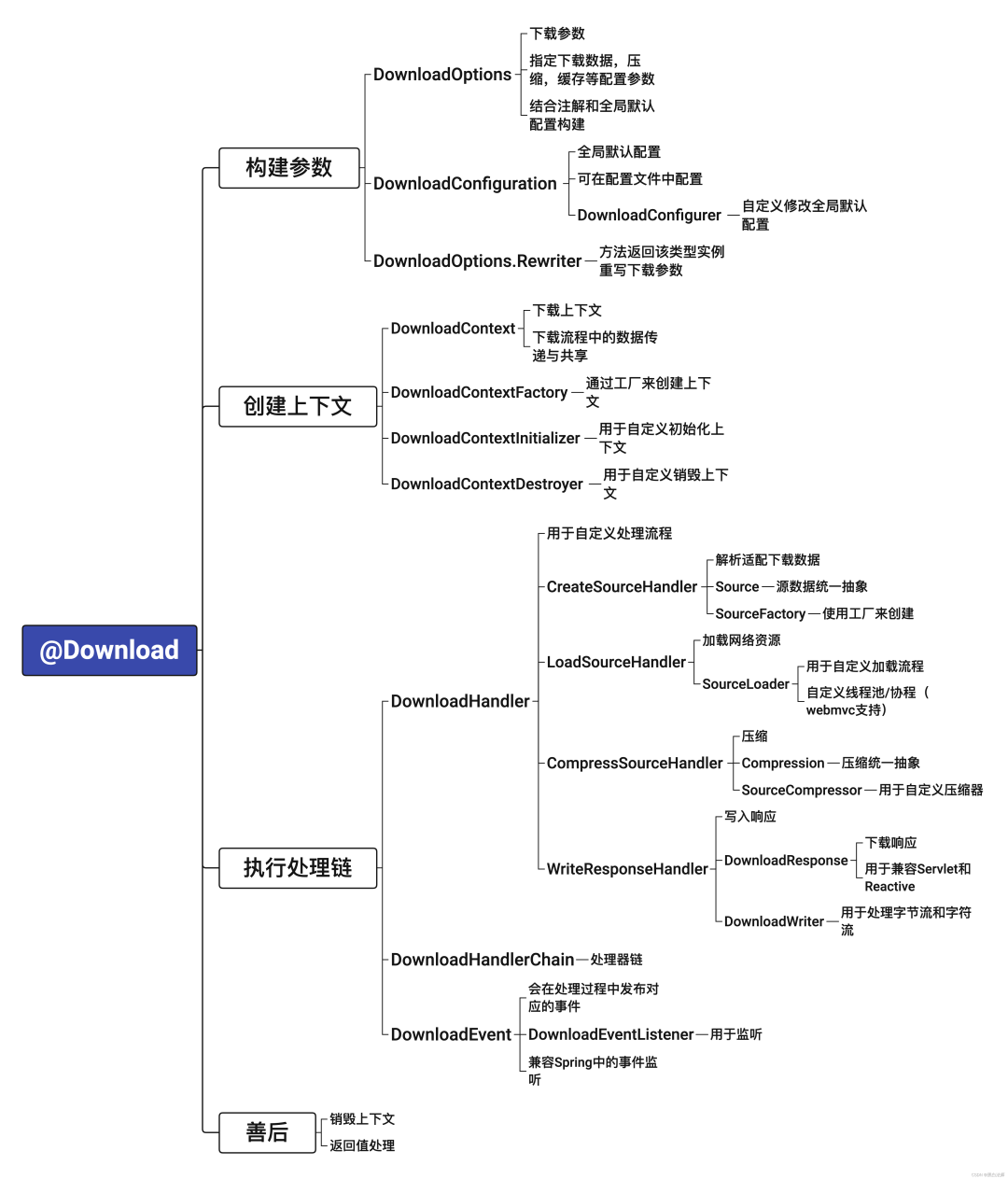
SpringBoot:一个注解就能帮你下载任意对象
介绍 下载功能应该是比较常见的功能了,虽然一个项目里面可能出现的不多,但是基本上每个项目都会有,而且有些下载功能其实还是比较繁杂的,倒不是难,而是麻烦。 所以结合之前的下载需求,我写了一个库来简化…...

oracle全量、增量备份
采用0221222增量备份策略,7天一个轮回 也就是周日0级备份,周1 2 4 5 6 采用2级增量备份,周3采用1级增量备份 打开控制文件自动备份 CONFIGURE CONTROLFILE AUTOBACKUP ON; 配置控制文件备份路径 CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVI…...

React Router 5 vs 6:使用上的主要差异与升级指南
React Router 5 的一些API 在 React Router 6 上有时可能找不到,可能会看到如下画面:export ‘useHistory’ was not found in ‘react-router-dom’ … React Router目前有两个大的版本,即React Router 5、6。React Router 6 在设计上更加简…...

基于LNMP部署wordpress
目录 一.环境准备 二.配置源并安装 三.配置Nginx 四.配置数据库 五.上传源码并替换 六.打开浏览器,输入虚拟机ip访问安装部署 七.扩展增加主题 一.环境准备 centos7虚拟机 关闭防火墙和seliunx stop firewalld #关闭防火墙 setenforce 0 …...
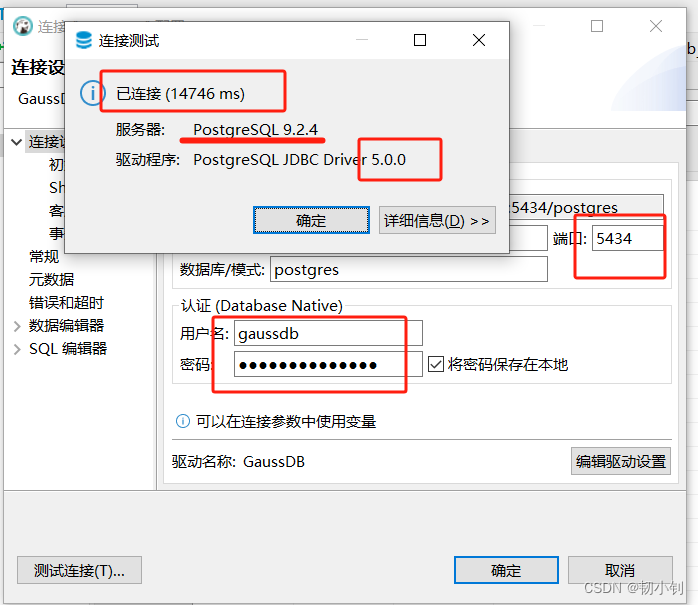
openGauss_5.1.0 企业版快速安装及数据库连接:单节点容器化安装
目录 📚第一章 官网信息📚第二章 安装📗下载源码📗下载安装包📗修改版本📗解压安装包📗运行buildDockerImage.sh脚本📗docker操作📕查看docker镜像📕启动dock…...
微信小程序 uniapp+vue城市公交线路查询系统dtjl3
小程序Android端运行软件 微信开发者工具/hbuiderx uni-app框架:使用Vue.js开发跨平台应用的前端框架,编写一套代码,可编译到Android、小程序等平台。 前端:HTML5,CSS3 VUE 后端:java(springbootssm)/python(flaskdja…...

2024年MathorCup数模竞赛B题问题一二三+部分代码分享
inputFolderPath E:\oracle\images\; outputFolderPath E:\oracle\process\; % 获取文件夹中所有图片的文件列表 imageFiles dir(fullfile(inputFolderPath, *.jpg)); % 设置colorbar范围阈值 threshold 120; % 遍历每个图片文件 for i 1:length(imageFiles) % 读…...
Ubuntu日常配置
目录 修改网络配置 xshell连不上怎么办 解析域名失败 永久修改DNS方法 临时修改DNS方法 修改网络配置 1、先ifconfig确认本机IP地址(刚装的机子没有ifconfig,先apt install net-tools) 2、22.04版本的ubuntu网络配置在netplan目录下&…...
GMSSL-通信
死磕GMSSL通信-C/C++系列(一) 最近再做国密通信的项目开发,以为国密也就简单的集成一个库就可以完事了,没想到能有这么多坑。遂写下文章,避免重复踩坑。以下国密通信的坑有以下场景 1、使用GMSSL guanzhi/GmSSL进行通信 2、使用加密套件SM2-WITH-SMS4-SM3 使用心得 …...
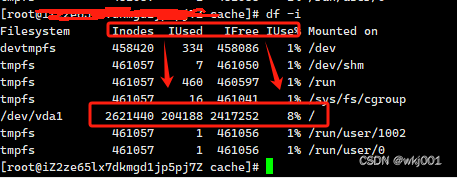
linux 磁盘分区Inode使用率达到100%,导致网站无法创建文件报错 failed:No space leftondevice(
linux 磁盘分区Inode使用率达到100%,导致网站无法创建文件报错 failed:No space left on device 由于这问题直接导致了,网站无法正常运行! 提交工单求助阿里后,得到了答案! 工程师先让我执行 df -h 和 df -i 通过分析…...

探索Python库的奇妙世界
探索Python库的奇妙世界 Python作为一种流行的编程语言,因其简洁的语法、强大的库支持和广泛的应用场景而备受开发者青睐。在这篇文章中,我们将深入探讨Python库的世界,了解它们如何帮助我们更高效地编写代码,并展示一些最有用的…...
SQL Server 存储函数(funGetId):唯一ID
系统测试时批量生成模拟数据,通过存储函数生成唯一ID。 根据当前时间生成唯一ID(17位) --自定义函数:根据当前时间组合成一个唯一ID字符串:yearmonthdayhourminutesecondmillisecond drop function funGetId;go--自定义函数&…...

当你的项目体积比较大?你如何做性能优化
在前端开发中,项目体积优化是一个重要的环节,它直接影响到网页的加载速度和用户体验。随着前端项目越来越复杂,引入的依赖也越来越多,如何有效地减少最终打包文件的大小,成为了前端工程师需要面对的挑战。以下是一些常…...

第6章:6.3.2 一张表总结正则表达式的语法 (MATLAB入门课程)
讲解视频:可以在bilibili搜索《MATLAB教程新手入门篇——数学建模清风主讲》。 MATLAB教程新手入门篇(数学建模清风主讲,适合零基础同学观看)_哔哩哔哩_bilibili 本节我们用一张表来回顾和总结MATLAB正则表达式的基本语法。这个…...
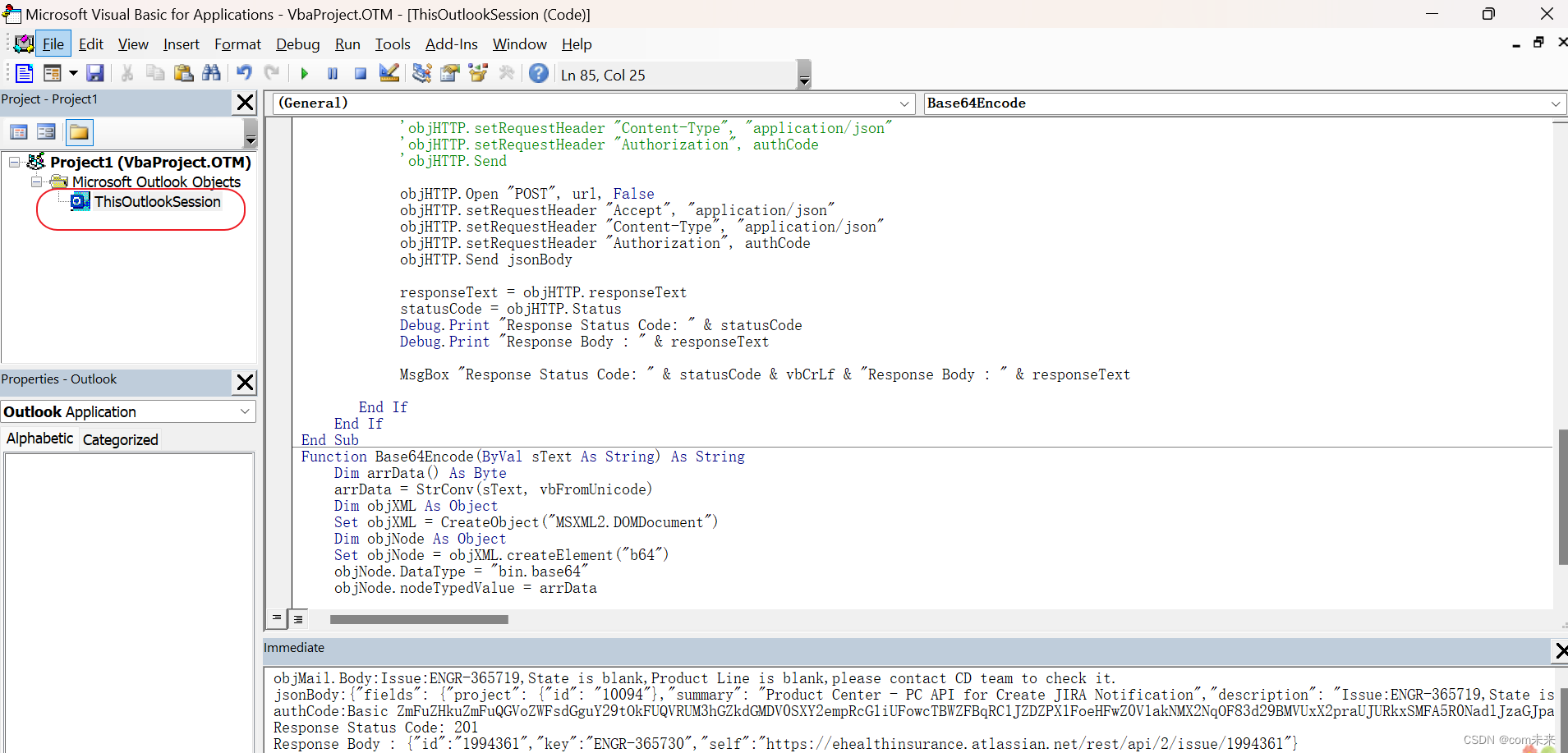
VBA 实现outlook 当邮件设置category: red 即触发自动创建jira issue
1. 打开: Outlook VBA(Visual Basic for Applications) 方法一: 在邮件直接搜索:Visual Basic editor 方法二: File -> Options -> Customize Ribbon-> 打钩 如下图: 2.设置运行VBA 脚本: File -> Options -> Trust center -> Trus…...
办公软件巨头CCED、WPS迎来新挑战,新款办公软件已形成普及之势
办公软件巨头CCED、WPS的成长经历 CCED与WPS,这两者均是中国办公软件行业的佼佼者,为人们所熟知。 然而,它们的成功并非一蹴而就,而是经过了长时间的积累与沉淀。 CCED,这款中国大陆早期的文本编辑器,在上…...
架构设计-订单系统之订单系统的架构进化
1、单数据库架构 产品初期,技术团队的核心目标是:“快速实现产品需求,尽早对外提供服务”。 彼时的专车服务都连同一个 SQLServer 数据库,服务层已经按照业务领域做了一定程度的拆分。 这种架构非常简单,团队可以分开…...

性能升级,INDEMIND机器人AI Kit助力产业再蜕变
随着机器人进入到越来越多的生产生活场景中,作业任务和环境变得更加复杂,机器人需要更精准、更稳定、更智能、更灵敏的自主导航能力。 自主导航技术作为机器人技术的核心,虽然经过了多年发展,取得了长足进步,但在实践…...

2024年妈妈杯数学建模C题思路分析-物流网络分拣中心货量预测及人员排班
# 1 赛题 C 题 物流网络分拣中心货量预测及人员排班 电商物流网络在订单履约中由多个环节组成,图 ’ 是一个简化的物流 网络示意图。其中,分拣中心作为网络的中间环节,需要将包裹按照不同 流向进行分拣并发往下一个场地,最终使包裹…...

HBase集群启动后秒退?手把手教你排查ZooKeeper路径配置与htrace-core缺失问题
HBase集群启动后秒退?深度排查ZooKeeper路径与依赖缺失问题 当你在深夜部署HBase集群时,看到服务启动后几秒钟内突然消失,那种感觉就像在黑暗中摸索开关。这不是简单的配置错误,而是系统在向你发出求救信号。让我们像侦探一样&…...

Hive内部表 vs 外部表:选错一次,数据全丢?结合HDFS路径详解核心区别与选型指南
Hive内部表与外部表:数据安全与架构设计的深度抉择 在数据仓库与大数据分析领域,Hive作为构建在Hadoop之上的数据仓库工具,其表类型的选择往往被初学者视为简单的语法差异。然而,当生产环境中TB级的数据因为一个DROP TABLE命令而永…...

NCM音乐解锁终极指南:3步实现网易云音乐格式自由转换
NCM音乐解锁终极指南:3步实现网易云音乐格式自由转换 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密文件无法在其他播放器使用而烦恼吗?ncmdump解密工具让你轻松突破格式限制&…...

暗黑破坏神2存档编辑器:d2s-editor网页版深度体验指南
暗黑破坏神2存档编辑器:d2s-editor网页版深度体验指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 想要自由定制暗黑破坏神2的角色成长路径,却苦于找不到合适的工具?d2s-editor作为一款基于…...

CANN/asc-devkit bfloat16转half API
__bfloat162half_ru 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://git…...

Notero:终极Zotero与Notion同步插件,简单快速实现文献管理一体化
Notero:终极Zotero与Notion同步插件,简单快速实现文献管理一体化 【免费下载链接】notero A Zotero plugin for syncing items and notes into Notion 项目地址: https://gitcode.com/gh_mirrors/no/notero 你是否正在为文献管理与笔记整理之间的…...

从‘前后台’到‘多任务’:用UCOSIII官方例程理解RTOS内核如何接管你的单片机
从裸机到实时操作系统:UCOSIII内核如何重构单片机开发思维 第一次接触实时操作系统(RTOS)的嵌入式开发者,往往会被那些看似复杂的任务调度、优先级机制搞得一头雾水。我们习惯了在main函数里写一个无限循环,在中断服务例程(ISR)里处理紧急事件…...

终极跨平台桌面待办工具:My-TODOs如何重塑你的任务管理体验
终极跨平台桌面待办工具:My-TODOs如何重塑你的任务管理体验 【免费下载链接】My-TODOs A cross-platform desktop To-Do list. 跨平台桌面待办小工具 项目地址: https://gitcode.com/gh_mirrors/my/My-TODOs 你是否厌倦了复杂的任务管理软件?是否…...
)
告别I2C的龟速:用STM32的SPI接口榨干ICM20948的性能(实测对比与配置优化)
突破传感器性能瓶颈:STM32 SPI驱动ICM20948的极致优化实践 在无人机飞控、姿态解算和高频数据采集领域,传感器接口的选择往往成为系统性能的决定性因素。当开发者面对ICM20948这款集成了三轴陀螺仪、加速度计和磁力计的9轴运动传感器时,一个关…...

Moveit2 automaticaddison mycobot_ros2 代码讲解
github地址 https://github.com/automaticaddison/mycobot_ros2/tree/jazzy 一.mycobot_moveit_config 1.moveit2基本控制 在mycobot_moveit_config下面创建config/mycobot_280 initial_positions.yaml 定义了机械臂所有关节的初始位置 joint_limits.yaml 定义每个关节的…...