【爬虫+数据清洗+可视化分析】Python文本分析《狂飙》电视剧的哔哩哔哩评论
一、背景介绍
把《狂飙》换成其他影视剧,套用代码即可得分析结论!
2023《狂飙》热播剧引发全民追剧,不仅全员演技在线,且符合主旋律,创下多个收视记录!
基于此热门事件,我用python抓取了B站上千条评论,并进行可视化舆情分析。
二、爬虫代码
2.1 展示爬取结果
首先,看下部分爬取数据:
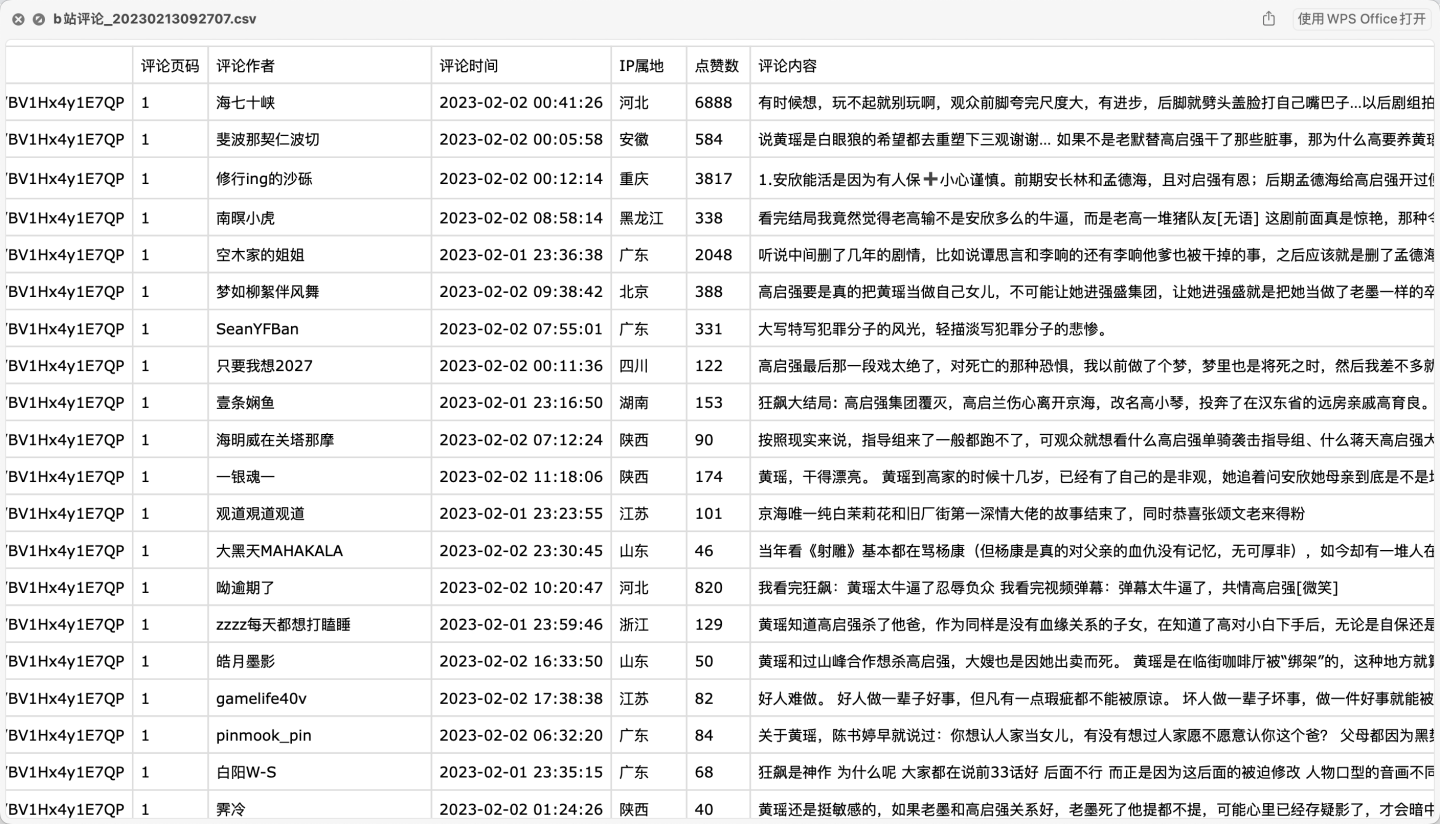
爬取字段含:视频链接、评论页码、评论作者、评论时间、IP属地、点赞数、评论内容。
2.2 爬虫代码讲解
导入需要用到的库:
import requests # 发送请求
import pandas as pd # 保存csv文件
import os # 判断文件是否存在
import time
from time import sleep # 设置等待,防止反爬
import random # 生成随机数
定义一个请求头:
# 请求头
headers = {'authority': 'api.bilibili.com','accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',# 需定期更换cookie,否则location爬不到'cookie': "需换成自己的cookie值",'origin': 'https://www.bilibili.com','referer': 'https://www.bilibili.com/video/BV1FG4y1Z7po/?spm_id_from=333.337.search-card.all.click&vd_source=69a50ad969074af9e79ad13b34b1a548','sec-ch-ua': '"Chromium";v="106", "Microsoft Edge";v="106", "Not;A=Brand";v="99"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-site','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.47'
}
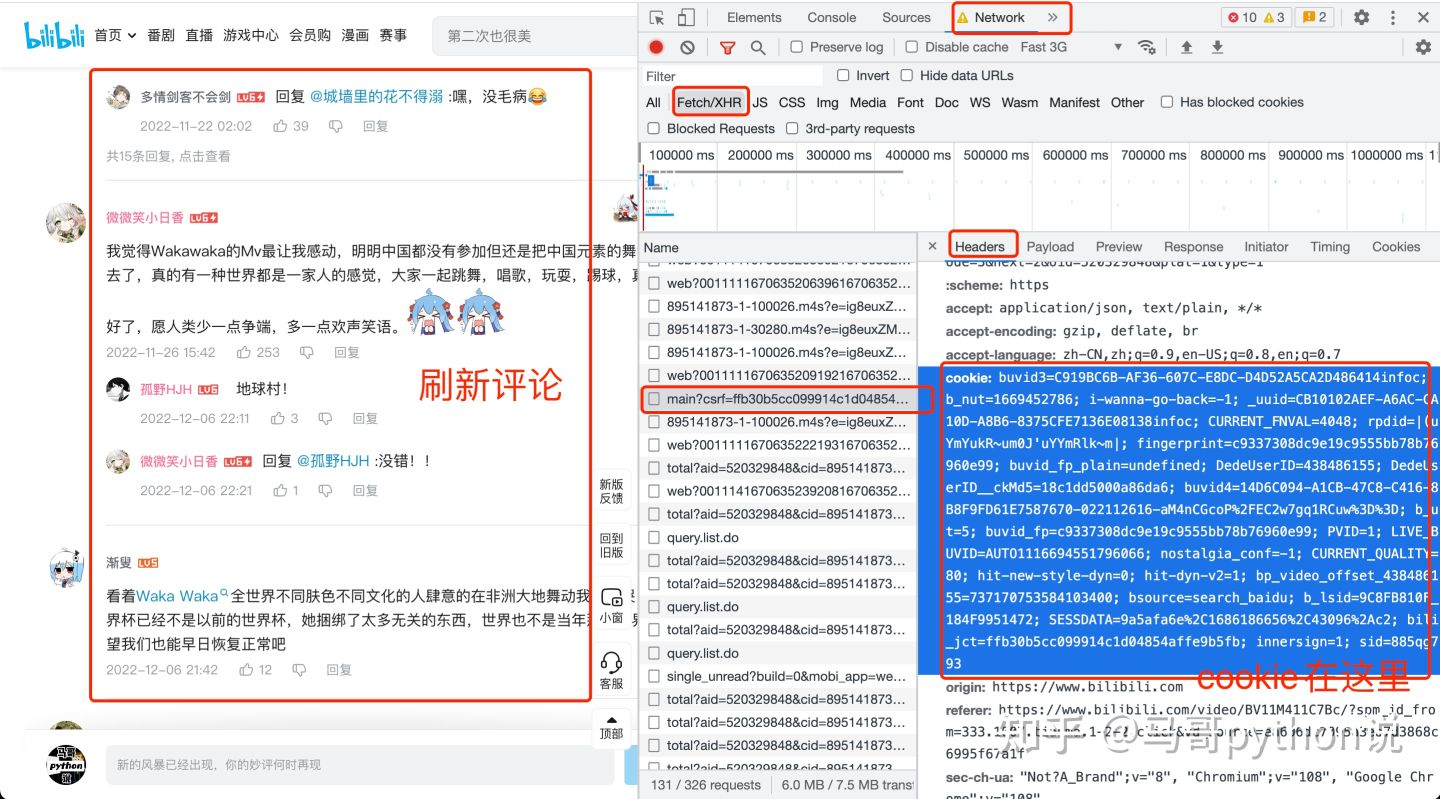
请求头中的cookie是个很关键的参数,如果不设置cookie,会导致数据残缺或无法爬取到数据。
那么cookie如何获取呢?打开开发者模式,见下图:
由于评论时间是个十位数:
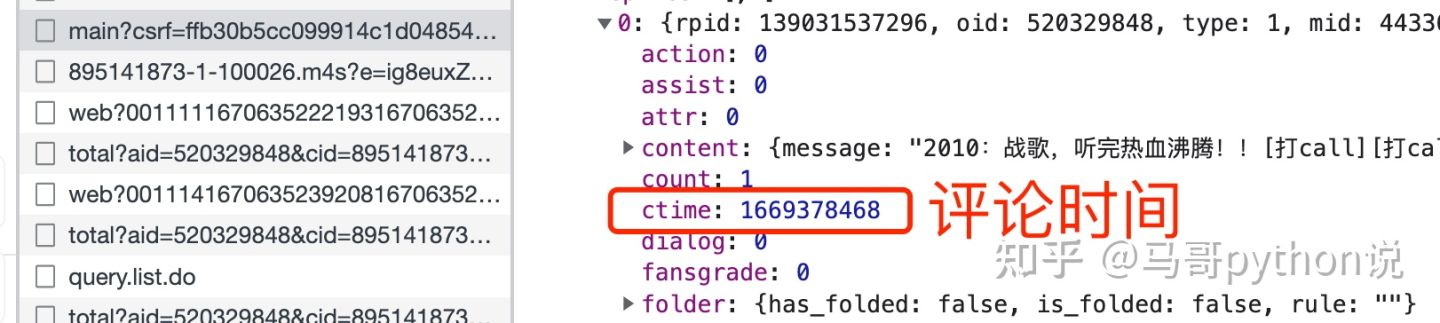
所以开发一个函数用于转换时间格式:
def trans_date(v_timestamp):"""10位时间戳转换为时间字符串"""timeArray = time.localtime(v_timestamp)otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)return otherStyleTime
向B站发送请求:
response = requests.get(url, headers=headers, ) # 发送请求
接收到返回数据了,怎么解析数据呢?看一下json数据结构:
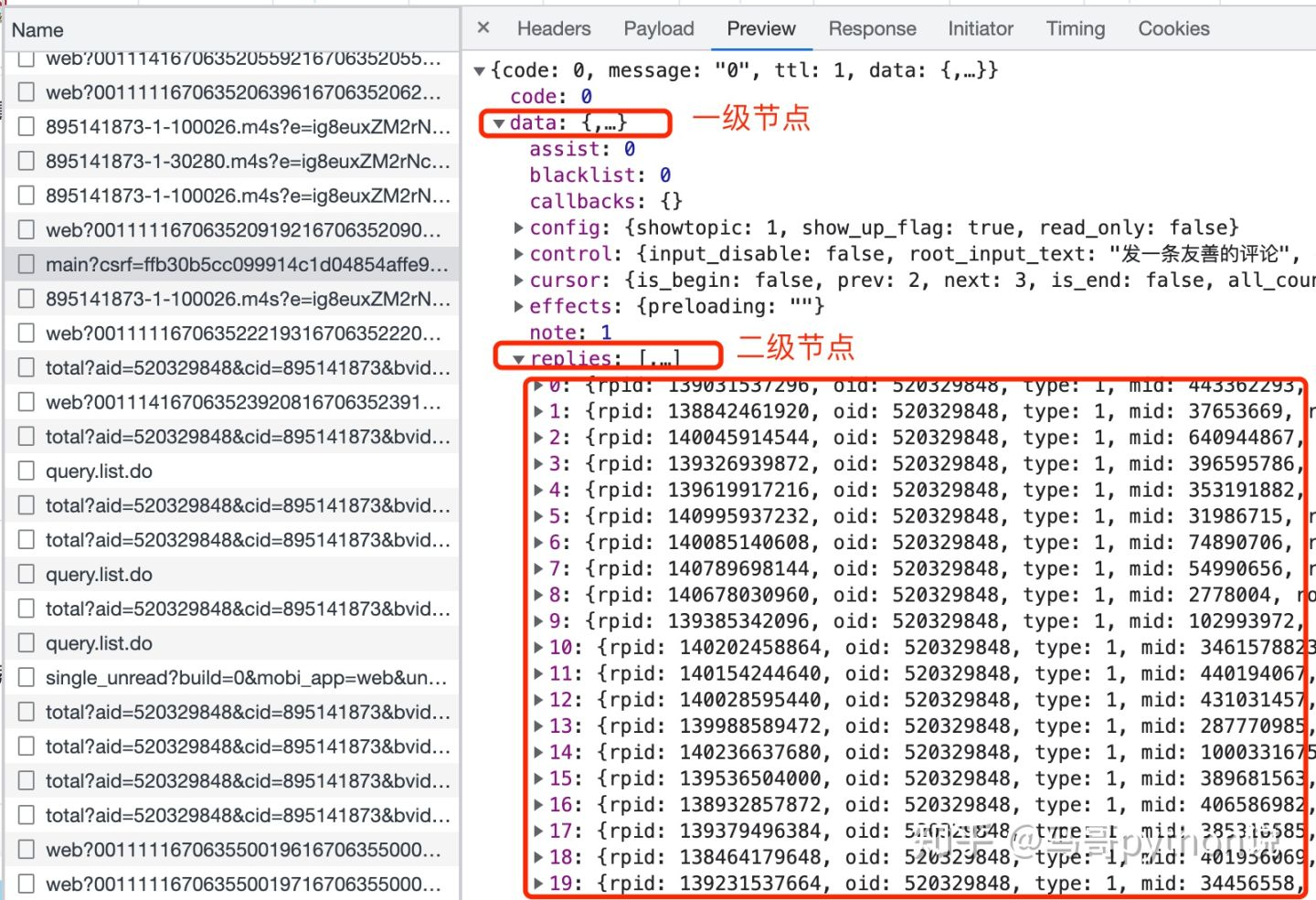
0-19个评论,都存放在replies下面,replies又在data下面,所以,这样解析数据:
data_list = response.json()['data']['replies'] # 解析评论数据
这样,data_list里面就是存储的每条评论数据了。
接下来吗,就是解析出每条评论里的各个字段了。
我们以评论内容这个字段为例:
comment_list = [] # 评论内容空列表
# 循环爬取每一条评论数据
for a in data_list:# 评论内容comment = a['content']['message']comment_list.append(comment)
其他字段同理,不再赘述。
最后,把这些列表数据保存到DataFrame里面,再to_csv保存到csv文件,持久化存储完成:
# 把列表拼装为DataFrame数据
df = pd.DataFrame({'视频链接': 'https://www.bilibili.com/video/' + v_bid,'评论页码': (i + 1),'评论作者': user_list,'评论时间': time_list,'IP属地': location_list,'点赞数': like_list,'评论内容': comment_list,
})
# 把评论数据保存到csv文件
df.to_csv(outfile, mode='a+', encoding='utf_8_sig', index=False, header=header)
注意,加上encoding=‘utf_8_sig’,否则可能会产生乱码问题!
下面,是主函数循环爬取部分代码:(支持多个视频的循环爬取)
# 随便找了几个"狂飙"相关的视频ID
bid_list = ['BV1Hx4y1E7QP', 'BV1Ev4y1r737', 'BV19x4y177ni']
# 评论最大爬取页(每页20条评论)
max_page = 50
# 循环爬取这几个视频的评论
for bid in bid_list:# 输出文件名outfile = 'b站评论_{}.csv'.format(now)# 转换aidaid = bv2av(bid=bid)# 爬取评论get_comment(v_aid=aid, v_bid=bid)
三、可视化代码
为了方便看效果,以下代码采用jupyter notebook进行演示。
3.1 读取数据
用read_csv读取刚才爬取的B站评论数据:
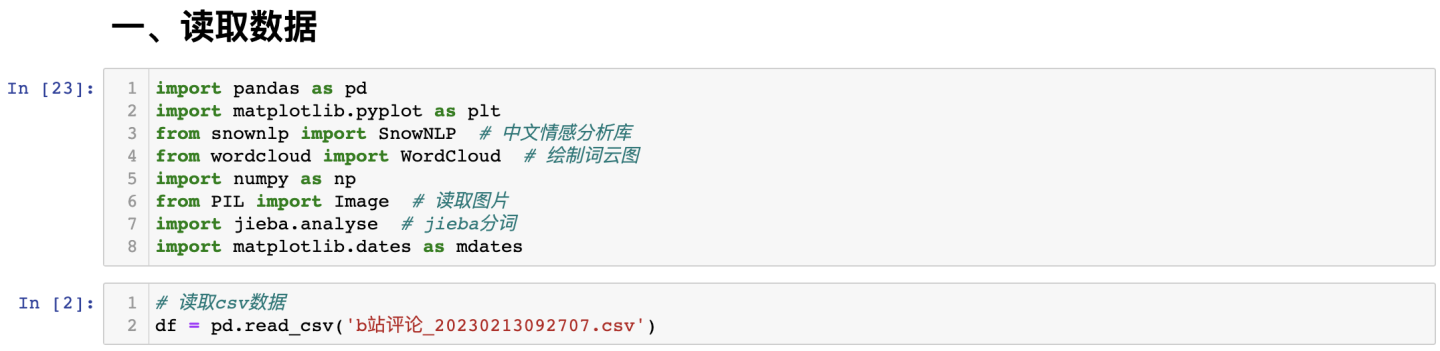
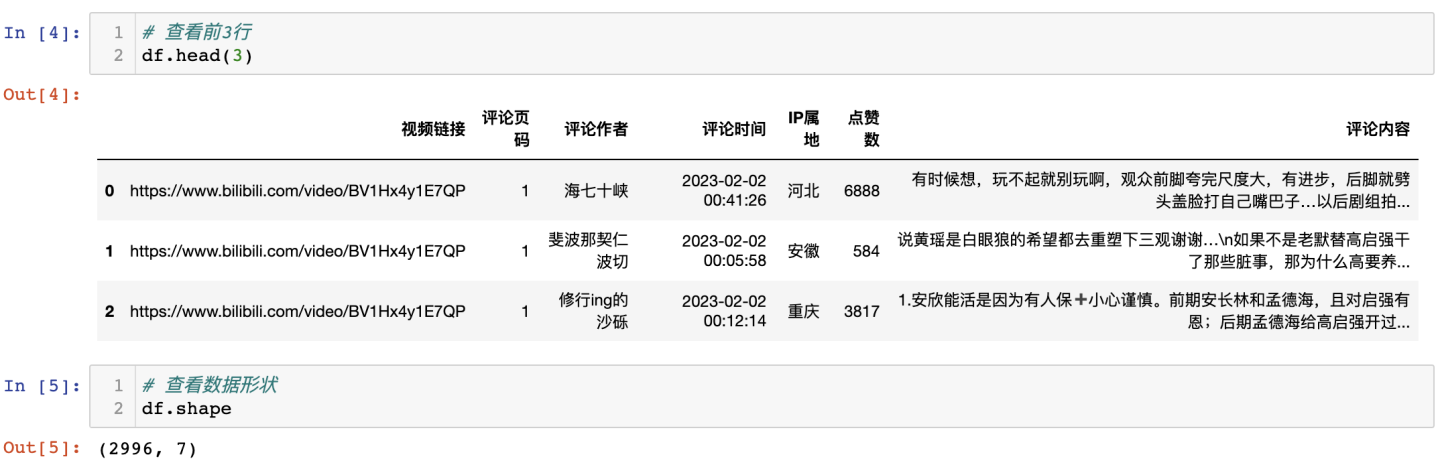
查看前3行及数据形状:
3.2 数据清洗
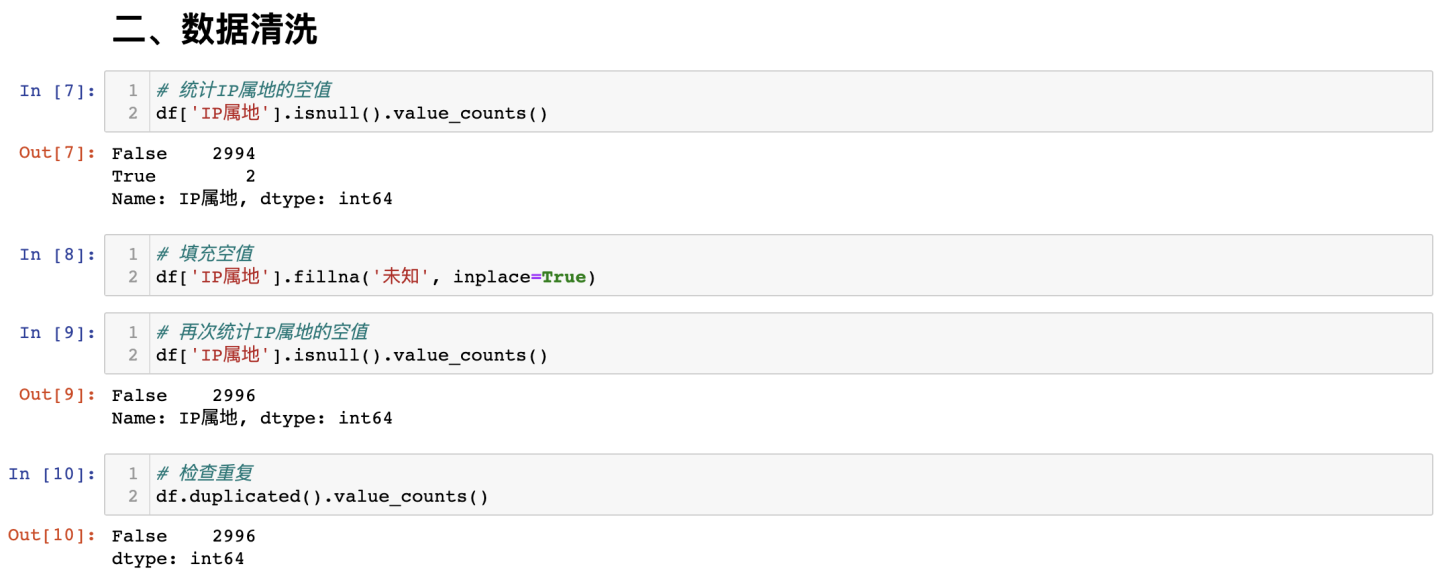
处理空值及重复值:
3.3 可视化
3.3.1 IP属地分析-柱形图
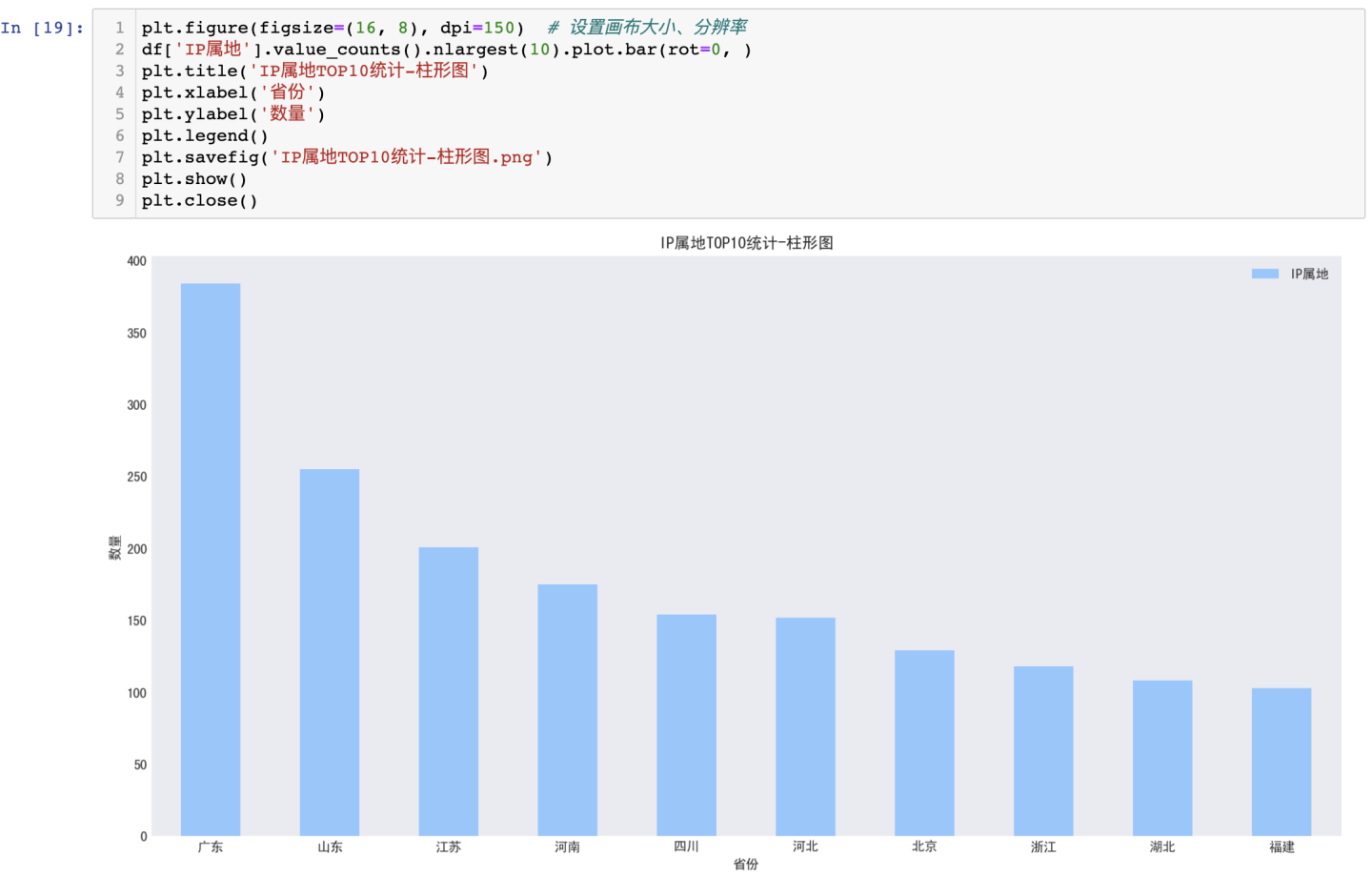
可得结论:TOP10地区中,评论里关注度最高为广东、山东、江苏等地区,其中,广东省的关注度最高。
3.3.2 评论时间分析-折线图
分析出评论时间的分布情况:
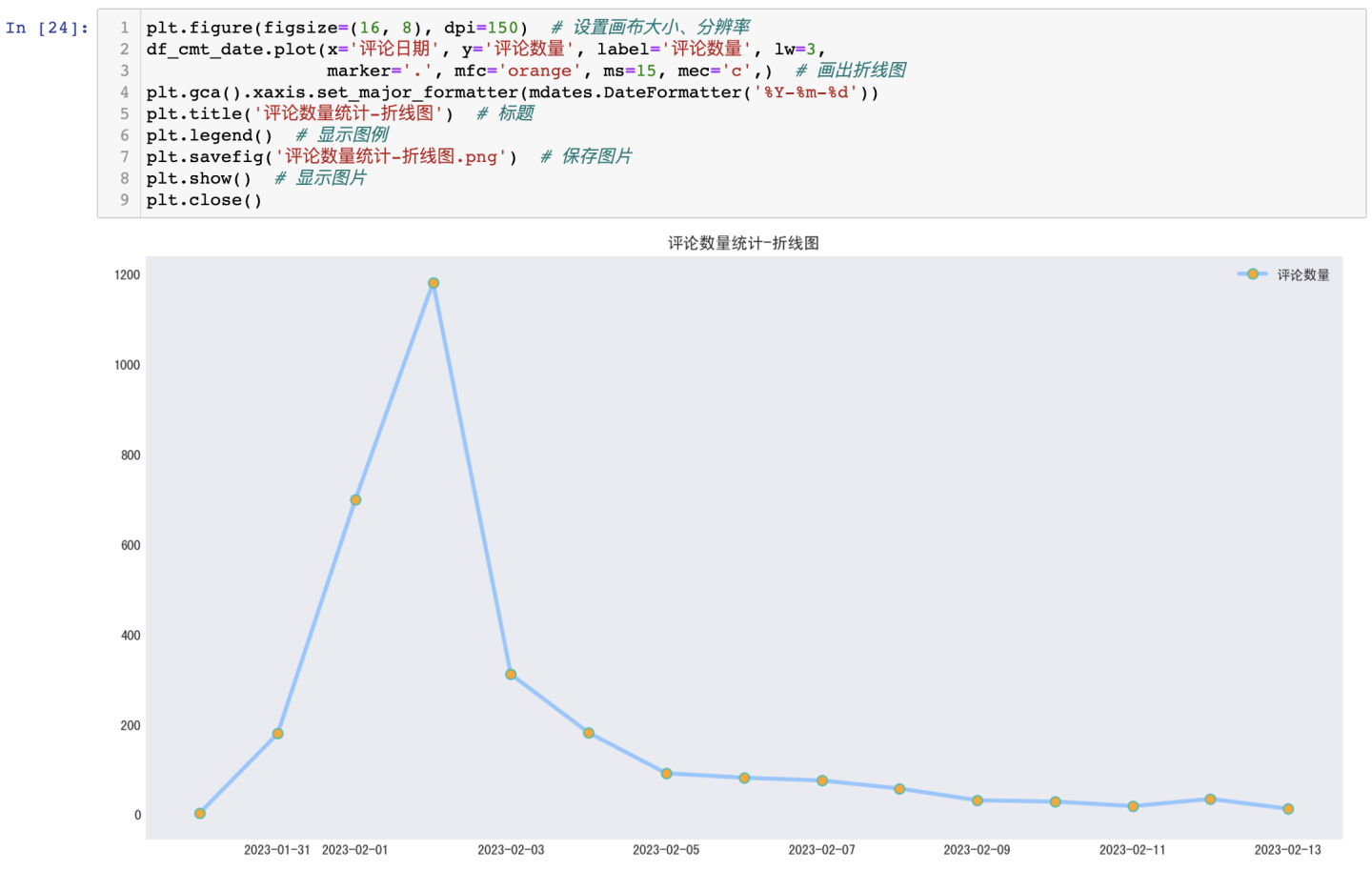
可得结论:关于"狂飙"这个话题,在抓取到的数据范围内,2月2日的评论数据量最大,网友讨论最热烈,达到了将近1200的数量峰值。
3.3.3 点赞数分布-直方图
由于点赞数大部分为0或个位数情况,个别点赞数到达成千上万,直方图展示效果不佳,因此,仅提取点赞数<30的数据绘制直方图。
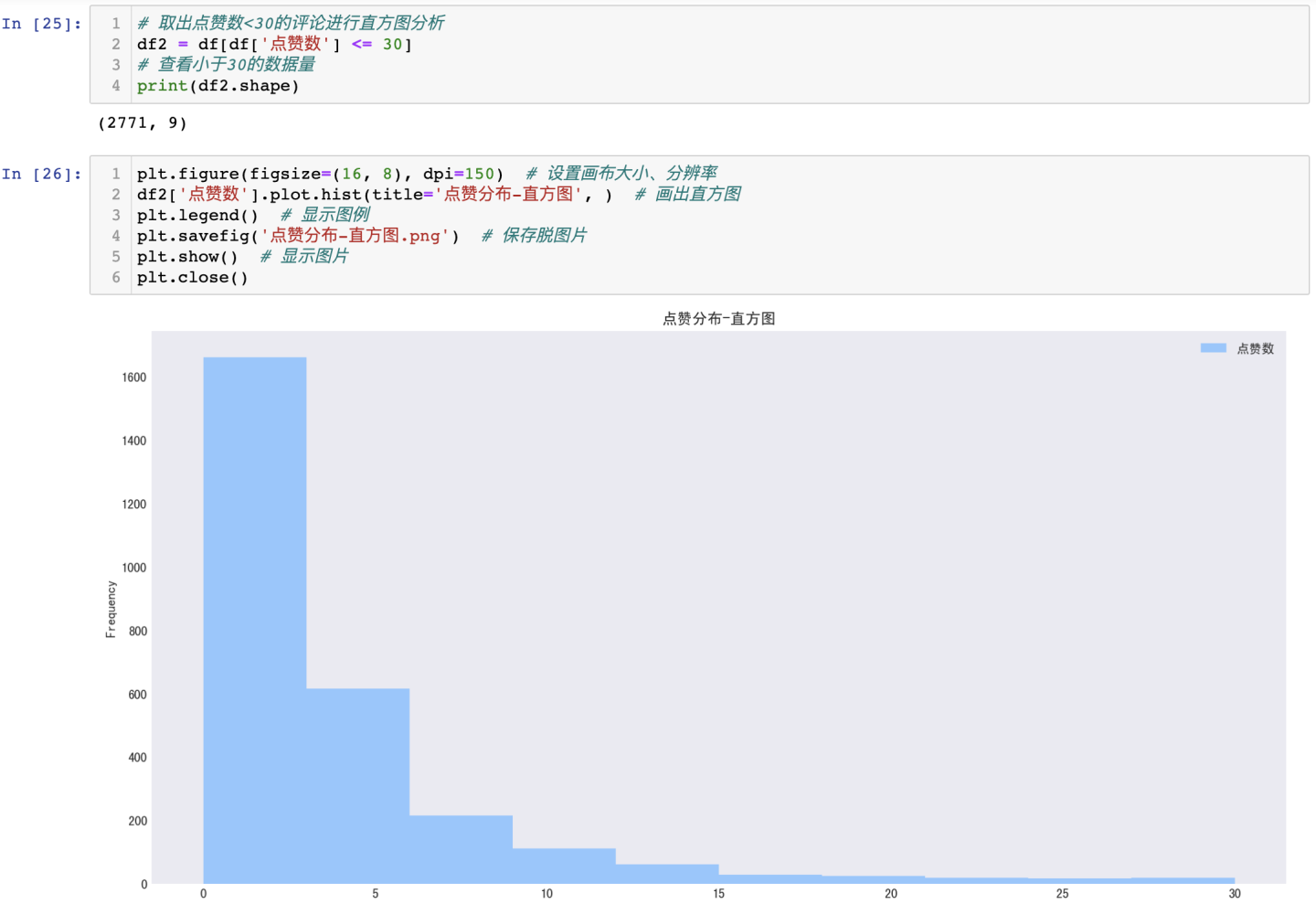
可得结论:从直方图的分布来看,点赞数在0-3个的评论占据大多数,很少点赞数达到了上千上万的情况。证明网友对狂飙这部作品的态度分布比较均匀,没有出现态度非常聚集的评论内容。
3.3.4 评论内容-情感分布饼图
针对中文评论数据,采用snownlp开发情感判定函数:
情感分布饼图,如下:
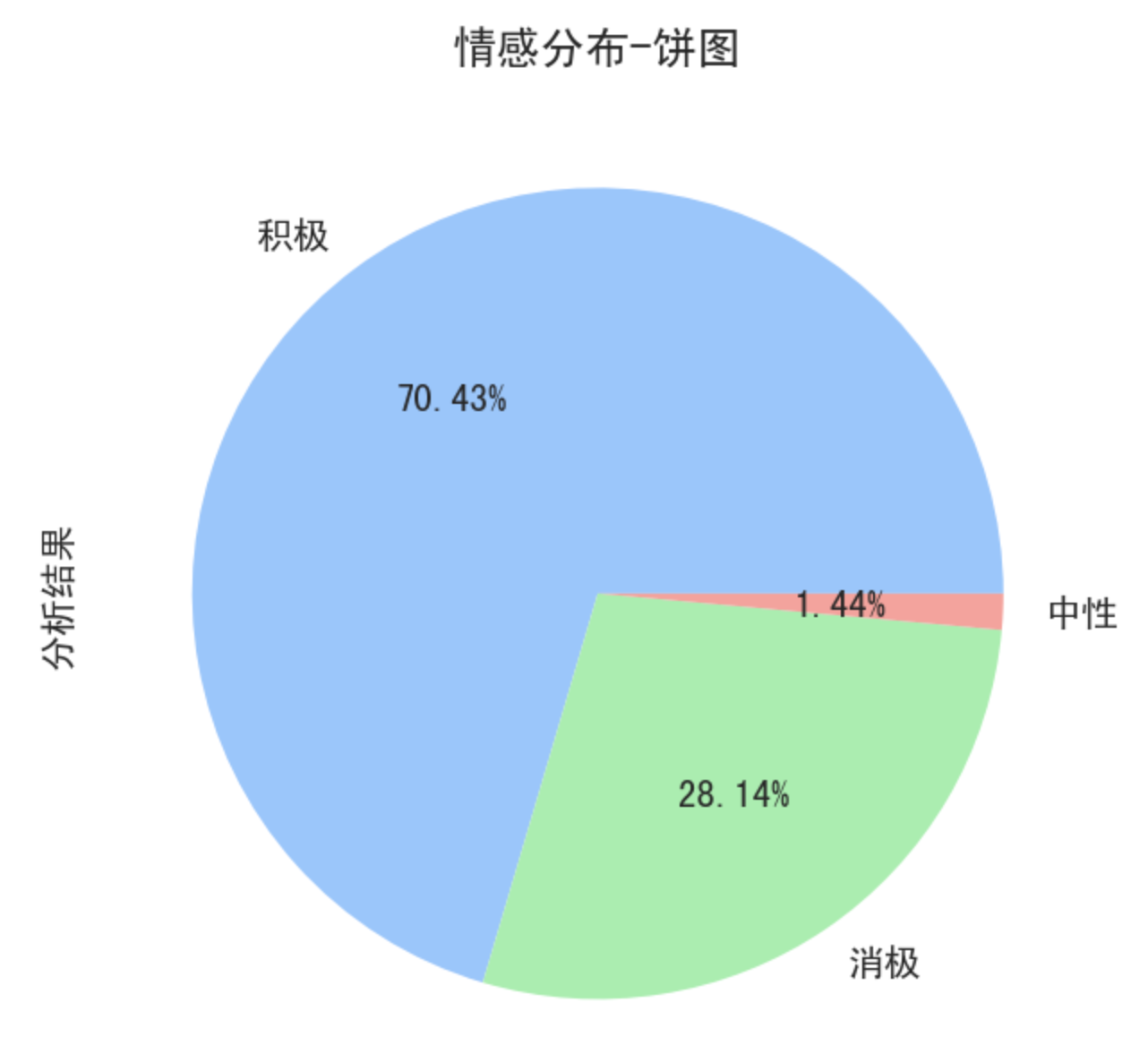
可得结论:关于狂飙这部电视剧,网友的评论情感以正面居多,占据了70.43%,说明这部电视剧获得了网友们很高的评价。
3.3.5 评论内容-词云图
除了哈工大停用词之外,还新增了自定义停用词:

jieba分词之后,对分词后数据进行绘制词云图:
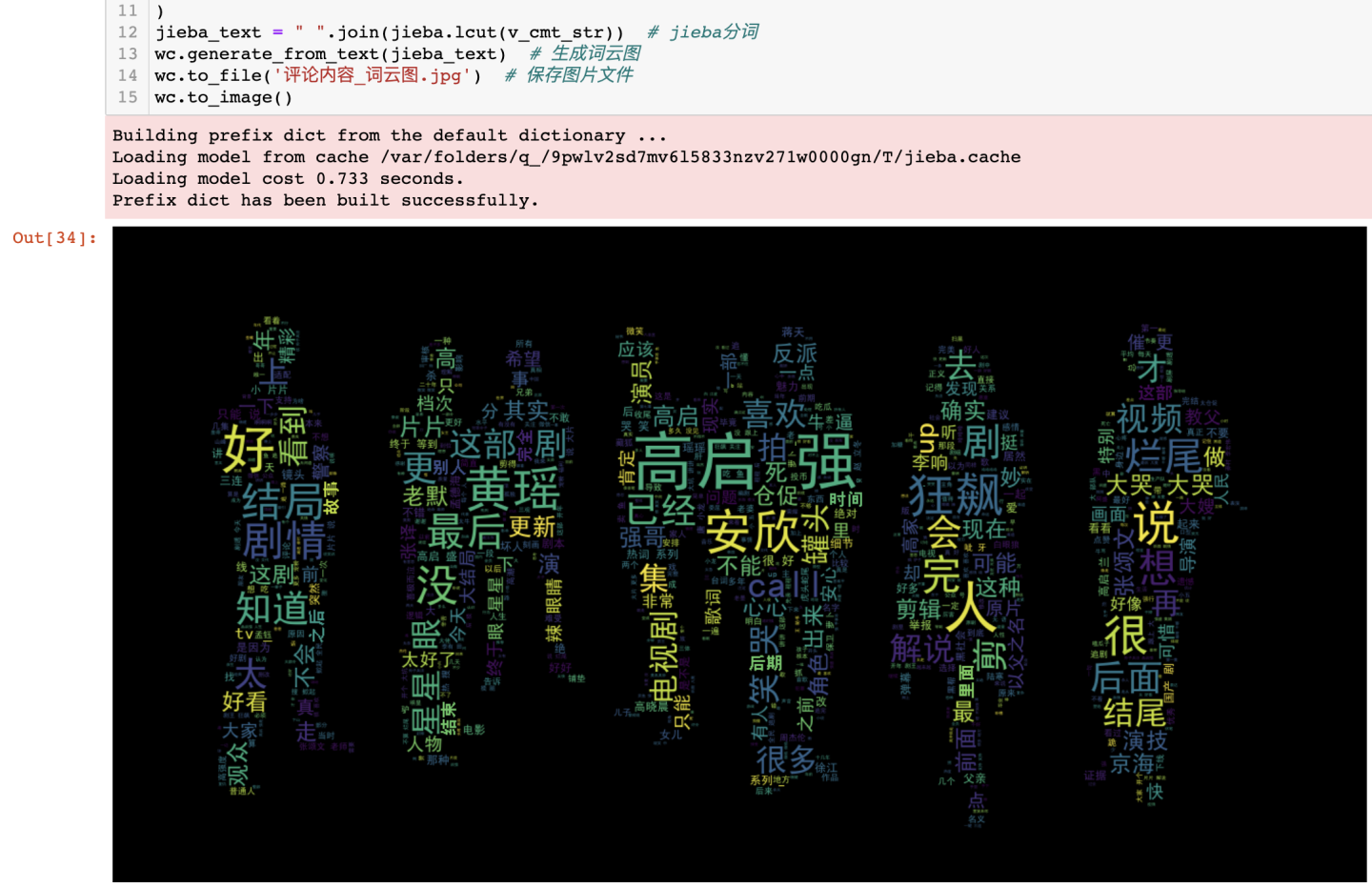
可得结论:在词云图中,狂飙、高启强、黄瑶、安欣、结局等词汇较大,出现频率较高,反应出众多网友对狂飙这部电视剧的剧情讨论热度很高。
附原始背景图,可对比看:(需要先人物抠图)

四、演示视频
代码演示视频:
https://www.bilibili.com/video/BV1D8411T7dm
五、附完整源码
完整源码,微信公众号"老男孩的平凡之路"后台回复"狂飙"即可获取。
点击直达:【爬虫+数据清洗+可视化分析】舆情分析哔哩哔哩"狂飙"的评论
相关文章:
【爬虫+数据清洗+可视化分析】Python文本分析《狂飙》电视剧的哔哩哔哩评论
一、背景介绍 把《狂飙》换成其他影视剧,套用代码即可得分析结论! 2023《狂飙》热播剧引发全民追剧,不仅全员演技在线,且符合主旋律,创下多个收视记录! 基于此热门事件,我用python抓取了B站上千…...

使用vite从头搭建一个vue3项目(二)创建目录文件夹以及添加vue-router
目录 一、创建 vue3 项目 vite-vue3-project-js二、创建项目目录三、创建Home、About组件以及 vue-router 配置路由四、修改完成后页面 一、创建 vue3 项目 vite-vue3-project-js 使用 vite 创建一个极简 vue3 项目请参考此文章:使用Vite创建一个vue3项目 下面是我…...
)
循环控制语句的实际应用(3)
3194:【例32.3】 数位积 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 5116 通过数: 1971 【题目描述】 給出一个非负整数n,请求出n中各个数位上的数字之积。 【输入】 一开始有一个整数 T(1≤T≤100),表示共有几组测试数据。接下来有T个…...

突破像素限制,尽显照片细腻之美——Topaz Gigapixel AI for Mac/Win
在这个数字化的时代,我们都热爱用照片记录生活中的美好瞬间。然而,有时候我们会发现,由于各种原因,照片的像素可能无法满足我们的需求。这时候,Topaz Gigapixel AI for Mac/Win 这款强大的照片放大工具应运而生。 Top…...

CSS特效---HTML+CSS实现3D旋转卡片
1、演示 2、一切尽在代码中 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><title>Document</title&…...

Rust跨平台编译
❝ 如果你感觉自己被困住了,焦虑并充满消极情绪,生命出现了停滞,那么治疗方法很简单:「做点什么」。 ❞ 大家好,我是「柒八九」。一个「专注于前端开发技术/Rust及AI应用知识分享」的Coder 前言 之前我们不是写了一篇R…...

php其他反序列化知识学习
简单总结一下最近学习的,php其他的一些反序列化知识 phar soap session 其他 __wakeup绕过gc绕过异常非公有属性,类名大小写不敏感正则匹配,十六进制绕过关键字检测原生类的利用 phar 基础知识 在 之前学习的反序列化利用中࿰…...
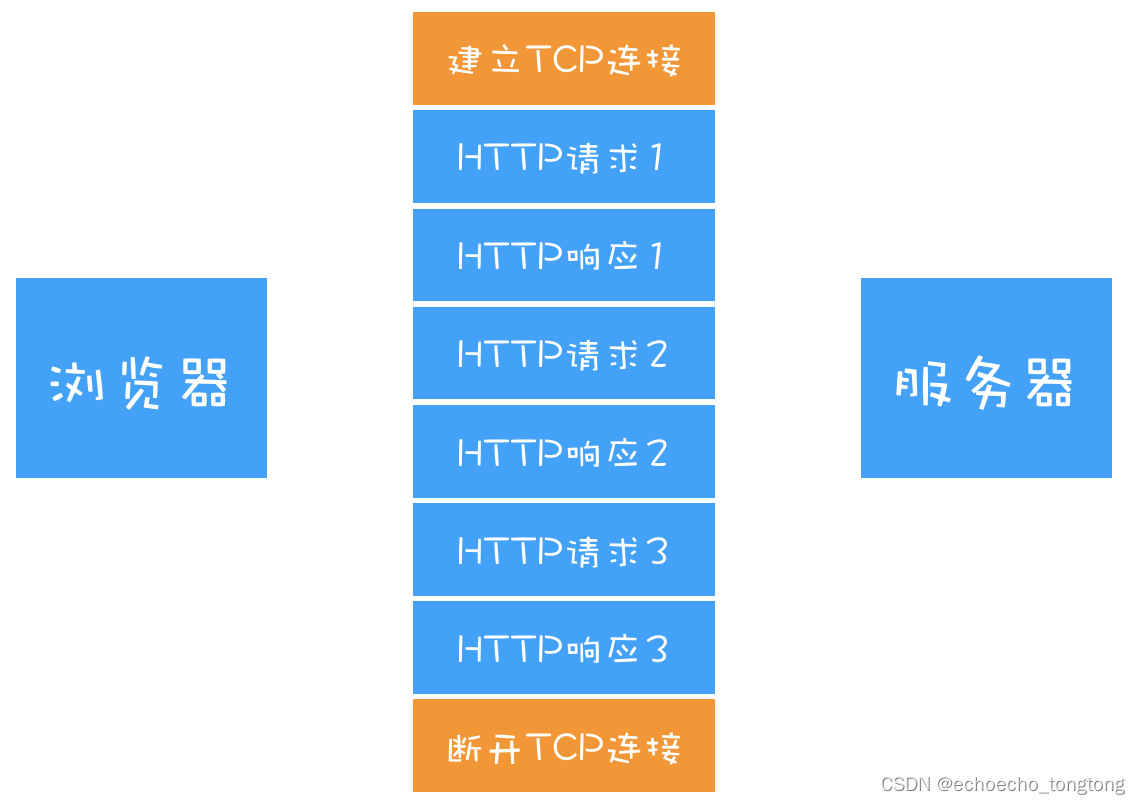
浏览器工作原理与实践--HTTP/1:HTTP性能优化
谈及浏览器中的网络,就避不开HTTP。我们知道HTTP是浏览器中最重要且使用最多的协议,是浏览器和服务器之间的通信语言,也是互联网的基石。而随着浏览器的发展,HTTP为了能适应新的形式也在持续进化,我认为学习HTTP的最佳…...

idea 使用springboot helper 创建springboot项目
Spring Boot Helper 是一个在 IntelliJ IDEA 中用于快速创建 Spring Boot 项目的插件。通过这个插件,开发者可以简化 Spring Boot 项目的创建过程,并快速生成所需的依赖和配置文件。以下是使用 Spring Boot Helper 插件创建 Spring Boot 项目的详细步骤&…...
关于 Amazon DynamoDB 的学习和使用
文章主要针对于博主自己的技术栈,从Unity的角度出发,对于 DynamoDB 的使用。 绿色通道: WS SDK for .NET Version 3 API Reference - AmazonDynamoDBClient Amazon DynamoDB Amazon DynamoDB is a fast, highly scalable, highly available,…...
【fastapi】搭建第一个fastapi后端项目
本篇文章介绍一下fastapi后端项目的搭建。其实没有什么好说的,按照官方教程来即可:https://fastapi.tiangolo.com/zh/ 安装依赖 这也是我觉得python项目的槽点之一。所有依赖都安装在本地,一旦在别人电脑上编写项目就又要安装一遍。很扯淡。…...
)
Qt/QML编程之路:图片进度条的实现(50)
要实现进度条,而进度条是通过一个图片来展示的,比如逐渐增大的音量,或者逐步增大的车速,通过图片显示的效果肯定更好一些。最直接的想法是通过一个透明的rectagle,把不想让看到的遮住,实际上这种方法不可行。 import QtQuick 2.5 import QtQuick.Window 2.2 import QtGra…...

OOCT WPF_D3D项目报错无法加载依赖项
运行示例项目报错缺少dll,发现运用了这个大老李,通过添加PATH路径也无法解决,看到debug文件夹下面没有其他的依赖项。 通过depneds工具可以看到 OCCTProxy_D3D.dll 缺少依赖项,图中的缺项都是OCCT生成的模块dll所以讲这些dll从..…...

模板方法模式:定义算法骨架的设计策略
在软件开发中,模板方法模式是一种行为型设计模式,它在父类中定义一个操作的算法框架,允许子类在不改变算法结构的情况下重定义算法的某些步骤。这种模式是基于继承的基本原则,通过抽象类达到代码复用的目的。本文将详细介绍模板方…...
解析(2024-04-12))
es6对于变量的解构赋值(数组解构,对象解构,字符串解构,函数解构等)解析(2024-04-12)
1、数组的解构赋值 [ ] 1.1 数组解构的基本用法 ES6 允许按照一定模式,从数组和对象中提取值,对变量进行赋值,这被称为解构(Destructuring)。本质上叫模型匹配,等号两边的模型相同就可以对应上。 //以前…...
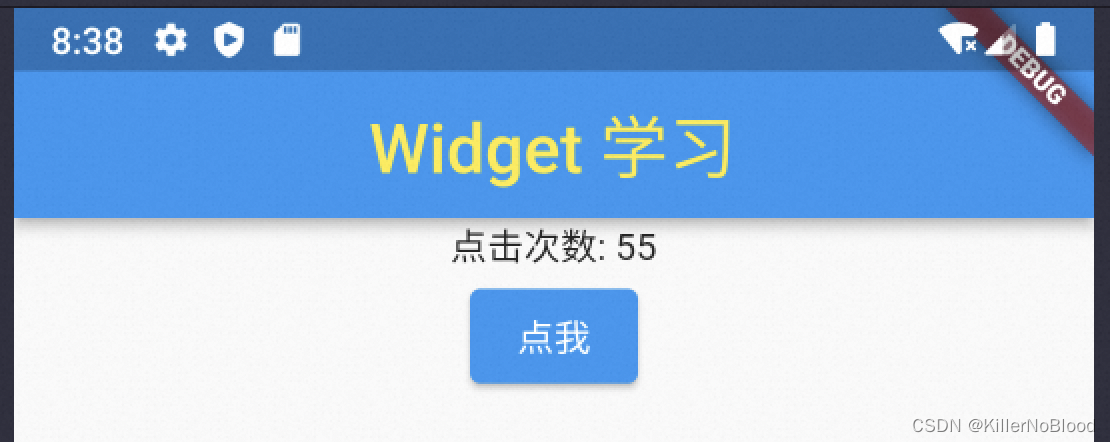
Flutter学习13 - Widget
1、Flutter中常用 Widget 2、StatelessWidget 和 StateFulWidget Flutter 中的 widget 有很多,但主要分两种: StatelessWidget无状态的 widget如果一个 widget 是最终的或不可变的,那么它就是无状态的StatefulWidget有状态的 widget如果一个…...

Django开发一个学生选课系统
在这个选课系统中,分为管理员和学生两种角色。 学生登录系统以后,只能看到选课信息。管理员登录以后,可以看到选课信息和其他的管理系统。 选课界面如下: 学生管理界面如下: 数据分析界面如下: 数据…...

Vue3项目搭建及文件结构
一. Vue3项目搭建 # 安装Vue CLI npm install -g vue/cli# 通过Vue CLI创建项目: vue create my-vue3-project# 当问到你想要使用哪个版本的Vue时,选择Vue3 # 完成配置后,CLI会自动安装依赖并创建项目 # 最后,启动你的Vue3项目cd…...

【机器学习】Logistic与Softmax回归详解
在深入探讨机器学习的核心概念之前,我们首先需要理解机器学习在当今世界的作用。机器学习,作为人工智能的一个重要分支,已经渗透到我们生活的方方面面,从智能推荐系统到自动驾驶汽车,再到医学影像的分析。它能够从大量…...
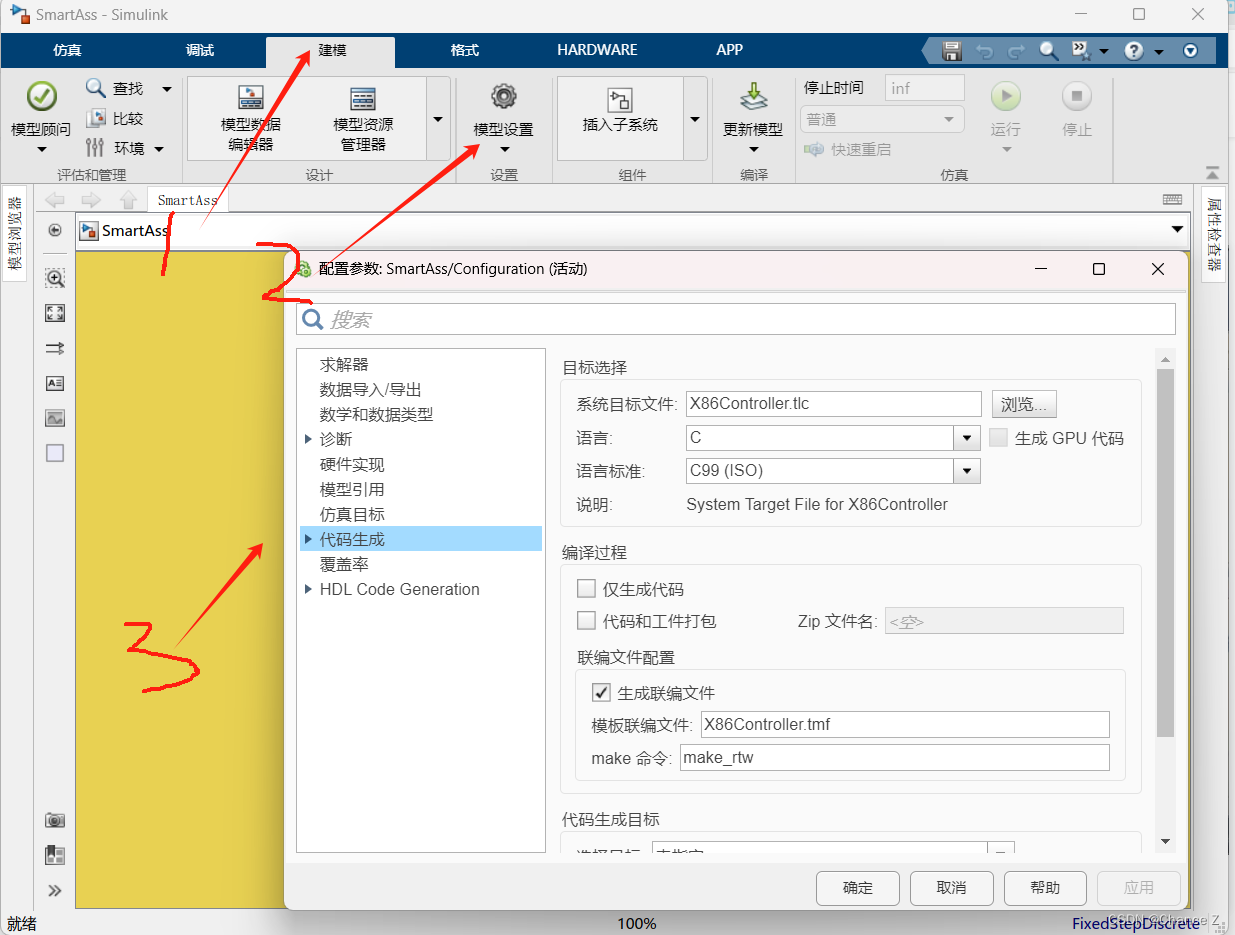
MATLAB Simulink仿真搭建及代码生成技术—01自定义新建模型模板
MATLAB Simulink仿真搭建及代码生成技术 目录 01-自定义新建模型模板点击运行:显示效果:查看模型设置: 01-自定义新建模型模板 新建模型代码如下: function new_model(modelname) %建立一个名为SmartAss的新的模型并打开 open_…...

3步专业级FanControl配置指南:从基础部署到高级调优
3步专业级FanControl配置指南:从基础部署到高级调优 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/F…...

强力掌控电脑散热:FanControl让你告别风扇噪音与高温烦恼
强力掌控电脑散热:FanControl让你告别风扇噪音与高温烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...

SDR++终极指南:如何快速掌握跨平台软件定义无线电
SDR终极指南:如何快速掌握跨平台软件定义无线电 【免费下载链接】SDRPlusPlus Cross-Platform SDR Software 项目地址: https://gitcode.com/GitHub_Trending/sd/SDRPlusPlus SDR软件定义无线电是一款开源的跨平台SDR软件,以其轻量级架构和直观界…...

CANN asc-devkit Maxs API参考
Maxs 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann/…...

工业网关、电机控制、人机界面:ATSAME70Q21B-AN的应用版图
ATSAME70Q21B-AN:300MHz Cortex-M7工业MCU的嵌入式应用解析在工业控制、人机界面和物联网网关等领域,微控制器需要在处理性能、外设集成度和环境适应性之间取得平衡。ATSAME70Q21B-AN是Microchip推出的基于ARM Cortex-M7内核的高性能32位微控制器&#x…...

3天搞定中文API大全:从菜鸟到高手的完整指南
3天搞定中文API大全:从菜鸟到高手的完整指南 嘿,开发者!你是不是经常为找一个好用的API而烦恼?项目做到一半,突然发现某个API文档全是英文,看得头大?别担心,今天我要给你介绍一个超级…...

MRIcroGL如何让医学影像三维可视化变得简单高效?
MRIcroGL如何让医学影像三维可视化变得简单高效? 【免费下载链接】MRIcroGL v1.2 GLSL volume rendering. Able to view NIfTI, DICOM, MGH, MHD, NRRD, AFNI format images. 项目地址: https://gitcode.com/gh_mirrors/mr/MRIcroGL MRIcroGL是一款专业的开源…...

5分钟快速上手:Windows触控板优化终极指南
5分钟快速上手:Windows触控板优化终极指南 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/th/ThreeFingersDragOnWindows …...
)
保姆级教程:用Vector CANoe搞定LIN诊断刷写自动化测试(附CAPL脚本思路)
从零构建LIN诊断刷写自动化测试:Vector CANoe实战指南 当汽车电子系统开始全面拥抱OTA升级浪潮时,LIN总线上的控制器也必须具备可靠的远程刷写能力。作为测试工程师,我们面临的挑战是如何在资源有限的LIN网络上,构建一个既能模拟…...

告别手动计算!用Python+GDAL复现CASA模型NPP估算,效率提升不止一点点
告别手动计算!用PythonGDAL复现CASA模型NPP估算,效率提升不止一点点 遥感生态研究中,净初级生产力(NPP)的估算一直是评估植被生长状况和碳循环的重要指标。传统基于IDLENVI的CASA模型实现方案,虽然成熟稳定…...