Spark 配置项
Spark 配置项
- 硬件资源类
- CPU
- 内存
- 堆外内
- User Memory/Spark 可用内存
- Execution/Storage Memory
- 磁盘
- Shuffle
- Spark SQL
- Join 策略调整
- 自动分区合并
- 自动倾斜处理
配置项分为 3 类:
- 硬件资源类 : 与 CPU、内存、磁盘有关的配置项
- Shuffle 类 : Shuffle 计算过程的配置项
- Spark SQL : Spark SQL 优化配置项
读取配置项顺序 :SparkConf 对象 -> 命令行参数 -> 配置文件
硬件资源类
| 资源类别 | 配置项 | 含义 |
|---|---|---|
| CPU | spark.cores.max | 集群满 CPU 核 |
spark.executor.cores | 每个 Executors 可用的 CPU Cores | |
spark.default.parallelism | 默认并行度 | |
spark.sql.shuffle.partitions | Reduce 的默认并行度 | |
spark.task.cpus | 每个任务可用的 CPU 核 | |
spark.executor.instances | 集群内 Executors 的个数 | |
| 内存 | spark.executor.memory | 单个 Executor 的堆内内存总大小 |
| spark.memory.offHeap.enabled | 是否启动堆外内存 | |
| spark.memory.offHeap.size | 单个 Executorp 的堆外内存总大小 | |
| spark.memory.fraction | 除 User Memory 外的内存空间占比 | |
| spark.memory.storageFraction | 缓存RDD的内存占比,执行内存占比= 1 - spark.memory.storageFraction | |
| spark.rdd.compress | RDD缓存是否压缩,默认不压缩 | |
| 磁盘 | spark.local.dir | 存储 Shuffle 中间文件/RDD Cache 的磁盘目录 |
CPU
配置项:
spark.cores.max | 集群满 CPU 核 |
|---|---|
spark.executor.cores | 每个 Executors 可用的 CPU 核 |
spark.task.cpus | 每个任务可用的 CPU 核 |
spark.executor.instances | 集群内 Executors 的个数 |
并行度 : 定义分布式数据集划分的份数/粒度,决定了分布式任务的计算负载。并行度越高,数据的粒度越细,数据分片越多,数据越分散
并行度的配置项 :
spark.default.parallelism | 默认并行度 |
|---|---|
spark.sql.shuffle.partitions | Reduce 的默认并行度 |
并行计算任务:在任一时刻整个集群能够同时计算的任务数量
- 整个集群的并行计算任务数 =
spark.executor.instances*spark.executor.cores
达到 CPU、内存、数据之间的平衡的约定 :
spark.executor.cores指定 CPU Cores ,记为 cExecution Memory内存大小 ,记为 m- 分布式数据集的大小记为 D ,并行度记为 P,D/P = 每个数据分片大小
- 一个数据分片对应着一个 Task(分布式任务),而一个 Task 又对应着一个 CPU Core
公式量化 :
# D/P = 数据分片大小,m/c = 每个 Task 分到的可用内存
D/P ~ m/c
内存
内存配置项 :
| spark.executor.memory | 单个 Executor 的堆内内存总大小 |
|---|---|
| spark.memory.offHeap.size | 单个 Executorp 的堆外内存总大小 |
(spark.memory.offHeap.enabled=true) | |
| spark.memory.fraction | 堆内内存中,用于缓存RDD和执行计算的内存比例 |
| spark.memory.storageFraction | 缓存RDD的内存占比,执行内存占比= 1 - spark.memory.storageFraction |
| spark.rdd.compress | RDD缓存是否压缩,默认不压缩 |

- Reserved Memory 大小固定为 300MB
- M 指定了 Executor 进程的 JVM Heap 大小 ( Executor Memory )
- Execution Memory 的组成: Execution Memory、Storage Memory 、UserMemory
- User Memory : 存储用户自定义的数据结构,如 : RDD 的各类实例化对象或集合类型(如: 数组、列表等)
- Spark 1.6 后,推出了动态内存管理模式,Execution Memory/Storage Memory 能互相抢占
堆外内
堆外存储:
- int 的用户 ID、String 的姓名、int的年龄、Char 的性别
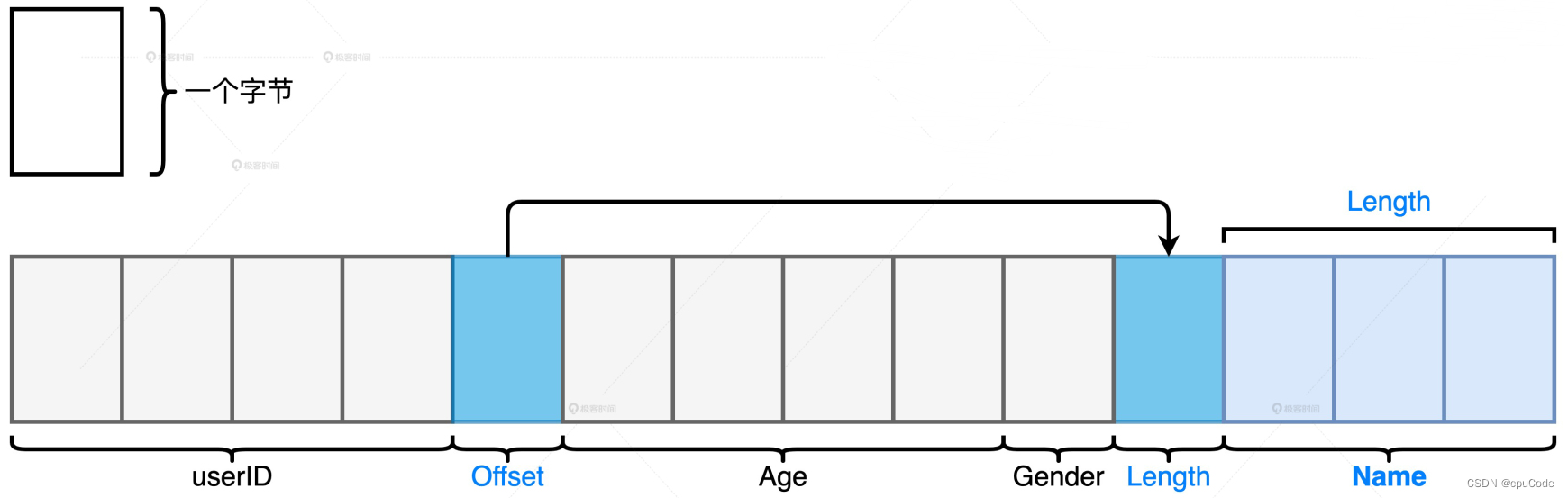
处理数据集:
- 数据模式比较扁平,而且字段多是定长数据类型,就更多使用堆外内存
- 数据模式很复杂,嵌套结构/变长字段很多,就更多使用 JVM 堆内内存
User Memory/Spark 可用内存
User Memory :存储开发者自定义的数据结构,这些数据结构需要协助分布式数据集的处理
spark.memory.fraction : 明确 Spark 可支配内存占比,即 :User Memory 堆内占比 = 1 - spark.memory.fraction
spark.memory.fraction:系数越大,Spark 可支配的内存越多,User Memory 占比越小spark.memory.fraction默认值是 0.6,JVM 堆内的 60% 给 Spark支配,40% 给 User Memory
调整内存相对占比:
- 自定义数据结构多,
spark.memory.fraction调低,用于分布式计算和缓存分布式数据集 - 自定义数据结构少,
spark.memory.fraction调高,用于分布式计算和缓存分布式数据集
Execution/Storage Memory
sf 的设置情况:
- ETL :RDD Cache 使用少。就能将 sf 设低点,让 Execution Memory 大点
- 缓存密集型 :机器学习:RDD Cache 使用较多,就能把 sf 设高点,让 Storage Memory 大点
- 过多的缓存会引发 GC(Garbage Collection,垃圾回收)
JVM 把 Heap 堆内内存分为:
- 年轻代:存储生命周期较短、引用次数较低的对象,会引发 Young GC
- 老年代:存储生命周期较长、引用次数高的对象,会引发 Full GC
- RDDcache 会存在老年代
Full GC时,会引发 STW:
- 抢占应用程序执行线程,把所有 CPU 线程都做垃圾回收,应用程序的暂时不执行(Stop the world)
- 等 Full GC 完事后,才把 CPU 线程释放,应用程序才能继续执行
- Full GC 弊端远大于 Young GC
为了 RDD cache 访问效率,用 RDD/DataFrame/Dataset.cache ,以对象值形式缓存到内存 (避免序列化消耗)
- 用对象值形式缓存数据,每条数据都要构成一个对象 (自定义Case class, Row 对象)
- 当大量的 RDD cache 时,会引发 Full GC
- 当应用是缓存密集型,需要大量缓存,为了执行效率,可以改用序列化
spark.rdd.compress :RDD 缓存默认不压缩
- 启用压缩后,能节省缓存内存的占用,把更多的内存空间留给分布式任务执行
- 启用压缩后,会引入额外的计算开销、牺牲 CPU
磁盘
磁盘的配置项:
- spark.local.dir :任意的本地文件系统目录,默认值是 /tmp 。 用于存储各种各样的临时数据,如: Shuffle 中间文件、RDD Cache。
有条件可以设置个大而性能好的文件系统,如:空间足够大的 SSD 文件系统目录
Shuffle
| spark.shuffle.file.buffer | Map 输出端的写缓冲区的大小 |
|---|---|
| spark.reducer.maxSizeInFlight | Reduce 输入端的读缓冲区的大小 |
| spark.shuffle.sort.bypassMergeThreshold | Map 阶段不进行排序的分区阈值 |
Shuffle 的计算的两个阶段:
- Map 阶段:执行映射逻辑,并按 Reducer 的分区规则,将中间数据写入到本地磁盘
- Reduce 阶段:从各个节点下载数据分片,并根据需要实现聚合计算
- Map 阶段的计算结果(中间文件),会存储到写缓冲区(Write Buffer),满后再写入到磁盘文件系统
- Reduce 阶段,通过网络从不同节点的磁盘中拉取中间文件,以数据块暂存到计算节点的读缓冲区(Read Buffer),满后再写入到磁盘文件系统
自 Spark 1.6 后,全用 Sort shuffle manager 管理 Shuffle
- Sort shuffle manager 会把 Map/Reduce 都引入排序
repartition、groupBy 就没有排序的需求,引入的排序就是额外的计算开销
- 不需要聚合/排序时,调整
spark.shuffle.sort.bypassMergeThreshold改变 Reduce 端的并行度(默认值 200)。当 Reduce 的分区数 < 该值时,Shuffle 就不会引入排序
Spark SQL
| 作用 | 配置项 | 含义 |
|---|---|---|
| AQE | spark.sql.adaptive.enabled | 是否启用 AQE |
| Join 策略 | spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin | 非空分区比例 < 该值,调整Join策略 |
| spark.sql.autoBroadcastJoinThreshold | 基表 < 该值, 触发Broadcast Join | |
| 自动分区合并 | spark.sql.adaptive.coalescePartitions.enabled | 是否启用合并分区 |
| spark.sql.adaptive.advisoryPartitionSizelnBytes | 合并后的目标分区大小 | |
| spark.sql.adaptive.coalescePartitions.minPartitionNum | 分区合并后,并行度 > 该值 | |
| 自动倾斜处理 | spark.sql.adaptive.skewJoin.enabled | 是否自动处理数据倾斜 |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor | 倾斜分区的比例系数 | |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdlnBytes | 倾斜分区的最低阀值 | |
| spark.sql.adaptive.advisoryPartitionSizeInBytes | 拆分倾斜分区粒度 (字节) |
Spark 3.0 推出 AQE (Adaptive Query Execution, 自适应查询执行) 的 3 个动态优化特性: Join 策略调整、自动分区合并、自动倾斜处理
# 启用 AQE
spark.sql.adaptive.enabled true
Join 策略调整
Join 策略调整 : Spark SQL 在运行时动态调整为 Broadcast Join
- 每当 DAG 中的 Map 阶段执行完毕,会结合 Shuffle 中间文件的统计信息,重新计算 Reduce 数据表的存储大小。当基表 <
autoBroadcastJoinThreshold时,下个阶段就可能变为 Broadcast Join
动态 Join 策略的条件二 :大表过滤后,非空分区比例 < nonEmptyPartitionRatioForBroadcastJoin,才能成功触发 Broadcast Join 降级
- 例子 :大表有 100 个分区,过滤后只有 15 个分区有数据
- 非空分区比例 : 15 / 100 = 15% < 20% , 就触发 Broadcast Join 降级
配置项:
# AQE前,基表 < 该值,就会触发 Broadcast Join
spark.sql.autoBroadcastJoinThreshold 10m# AQE后,非空分区比例 < 该值,就调整动态 Join 策略
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin 0.5
Spark SQL 的广播阈值对比的两种情况:
- 基表来自文件系统,用基表在磁盘的存储大小与广播阈值对比
- 基表来自 DAG 的中间文件,用 DataFrame 执行计划中的统计值与广播阈值对比
DataFrame 执行计划中的统计值 :
val df: DataFrame = _
// 先对分布式数据集加Cache
df.cache.count// 获取执行计划
val plan = df.queryExecution.logical// 获取执行计划对于数据集大小的精确预估
val estimated: BigInt = spark.sessionState.executePlan(plan).optimizedPlan.stats.sizeInBytes
自动分区合并
自动分区合并 :解决 Reduce 过小的分区,而导致的数据的不均衡问题
分区合并示意图 :
- 依序扫描数据分区,当相邻分区的尺寸之和 > 实际大小时,就把扫描过的分区做一次合并
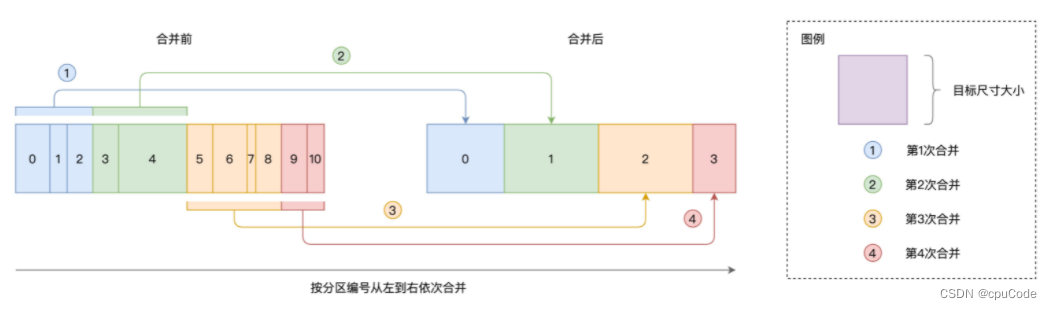
# 是否启用自动分区合并,默认启用
spark.sql.adaptive.coalescePartitions.enabled true# 合并后的目标分区大小
spark.sql.adaptive.advisoryPartitionSizelnBytes 256MB# 分区合并后,并行度 > 该值
spark.sql.adaptive.coalescePartitions.minPartitionNum 1
- 每个分区的平均大小 = 数据集大小/最低并行度
- 实际大小 = min(advisoryPartitionSizeInBytes , 分区的平均大小)
例子 :Shuffle 中间文件 = 20GB,minPartitionNum = 200,
- 每个分区的尺寸= 20GB / 200 =100MB
- 设 advisoryPartitionSizeInBytes = 200MB,最终分区 = min(100MB,200MB) = 100MB
自动倾斜处理
自动倾斜处理:把倾斜的数据分区拆分成小分区
- 对所有数据分区按大小做排序,取中位数。将
中位数 * skewedPartitionFactor,得到判定阈值。凡是 > 阈值的数据分区,就可能认为倾斜分区 - 当可能倾斜分区 >
skewedPartitionThresholdInBytes,就会判定为倾斜分区
配置项 :
# 开启自动倾斜处理
spark.sql.adaptive.skewJoin.enabled true# 判断大分区,倾斜分区的比例系数
spark.sql.adaptive.skewJoin.skewedPartitionFactor 5# 判断大分区,倾斜分区的最低阔值
spark.sql.adaptive.skewJoin.skewedPartitionThresholdinBytes 256MB# 拆分大分区 , 倾斜分区的拆分单位
spark.sql.adaptive.advisoryPartitionSizelnBytes 256MB
例子:数据表有 3 个分区:90MB、100MB 、512MB。中位数是 100MB
- 判定阈值 = 中位数 * skewedPartitionFactor = 100MB * 5 = 500MB
- 512MB 为候选分区
- 512MB > skewedPartitionThresholdInBytes(256MB) ,就认为该分区是倾斜分区
- 512MB < skewedPartitionThresholdInBytes(1GB) ,就不是倾斜分区
- 再根据 advisoryPartitionSizeInBytes(256MB) , 对大分区进行拆分
- 512MB 被拆成两个小分区(512MB / 2 = 256MB)
相关文章:
Spark 配置项
Spark 配置项硬件资源类CPU内存堆外内User Memory/Spark 可用内存Execution/Storage Memory磁盘ShuffleSpark SQLJoin 策略调整自动分区合并自动倾斜处理配置项分为 3 类: 硬件资源类 : 与 CPU、内存、磁盘有关的配置项Shuffle 类 : Shuffle 计算过程的配置项Spark SQL : Spar…...

掌握Vue3模板语法,助你轻松实现高效Web开发
Vue3作为前端开发中的一种主流框架,为我们提供了多种灵活的方式来处理模板语法。除了基础的模板语法,Vue3还提供了一些高级的语法,可以让我们更好地处理组件、响应式数据和UI逻辑等。在这篇博客中,我们将介绍Vue3中的一些高级模板…...
Jmeter+Ant+Jenkins接口自动化测试平台搭建
平台简介一个完整的接口自动化测试平台需要支持接口的自动执行,自动生成测试报告,以及持续集成。Jmeter支持接口的测试,Ant支持自动构建,而Jenkins支持持续集成,所以三者组合在一起可以构成一个功能完善的接口自动化测…...
)
ncnn部署(CMakelists.txt)
1. NCNN 环境安装 参考博客: 基于ncnn的yolov5模型部署 1. 1 protobuf编译 打开VS2013/VS2019的X64命令行(注意不是cmd),我这里以V32013环境进行编译 > cd <protobuf-root-dir> > mkdir build-vs2013 > cd build-vs2013 > cmake -G"NMake Makefil…...
SQL分库分表
什么是分库分表? 分库分表是两种操作,一种是分库,一种是分表。 分库分表又分为垂直拆分和水平拆分两种。 (1)分库:将原来存放在单个数据库中的数据,拆分到多个数据库中存放。 (2&…...

大数据分析案例-基于逻辑回归算法构建微博评论情感分类模型
🤵♂️ 个人主页:@艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收藏 📂加关注+ 喜欢大数据分析项目的小伙伴,希望可以多多支持该系列的其他文章 大数据分析案例合集…...
)
0105深度优先搜索算法非递归2种实现对比-无向图-数据结构和算法(Java)
1 两种非递归实现 在前面我们解决无向图的单点通性和单点路径问题时,都用到了深度优先搜索算法。深度优先搜索算法可以用递归和非递归两种方式。这里讨论非递归实现。 无向图结构使用邻接表实现。 第一种非递归方法(推荐),代码如…...
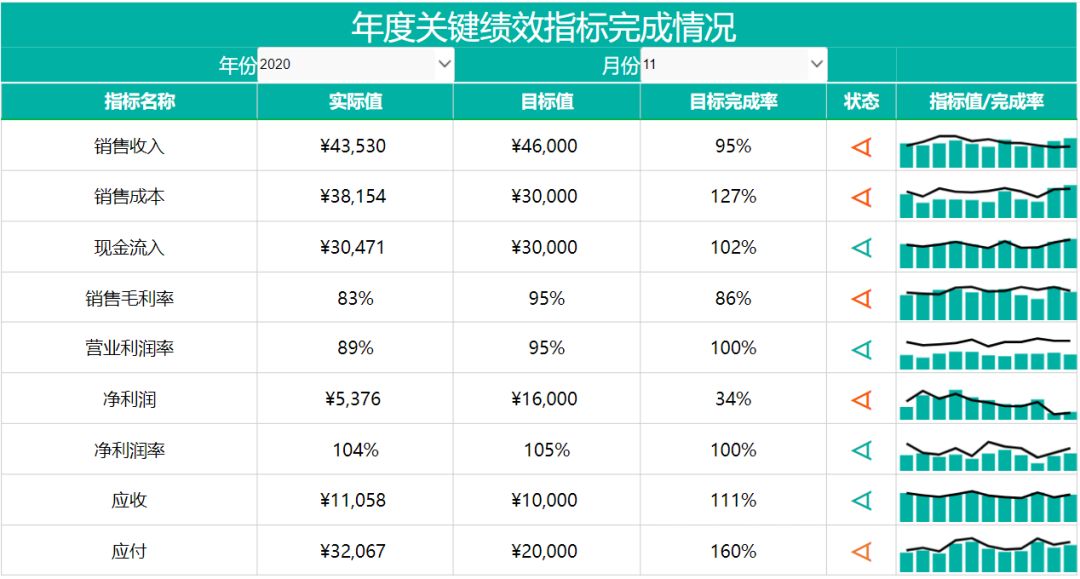
传统手工数据采集耗时耗力?Smartbi数据填报实现数据收集分析自动化
企业在日常经营管理过程中,往往需要收集很多内外部的信息,清洗整理后再进行存储、分析、呈现、决策支持等各种作业,如何高效收集结构化数据是企业管理者经常要面对的问题。传统手工的数据采集方式不仅耗费了大量人力时间成本,还容…...

《Spring源码深度分析》第5章 Bean的加载
目录标题前言一、Bean加载入口与源码分析1、Bean加载的入口2、Bean加载源码二、FactoryBean的使用三、缓存中获取单例bean(待补充)前言 经过前面的分析,我们终于结束了对XML 配置文件的解析,接下来将会面临更大的挑战,就是对 bean 加载的探索…...
)
华为OD机试真题Java实现【求最大数字】真题+解题思路+代码(20222023)
求最大数字 题目 给定一个由纯数字组成以字符串表示的数值,现要求字符串中的每个数字最多只能出现2次,超过的需要进行删除;删除某个重复的数字后,其它数字相对位置保持不变。 如34533,数字3重复超过2次,需要删除其中一个3,删除第一个3后获得最大数值4533 请返回经过删…...
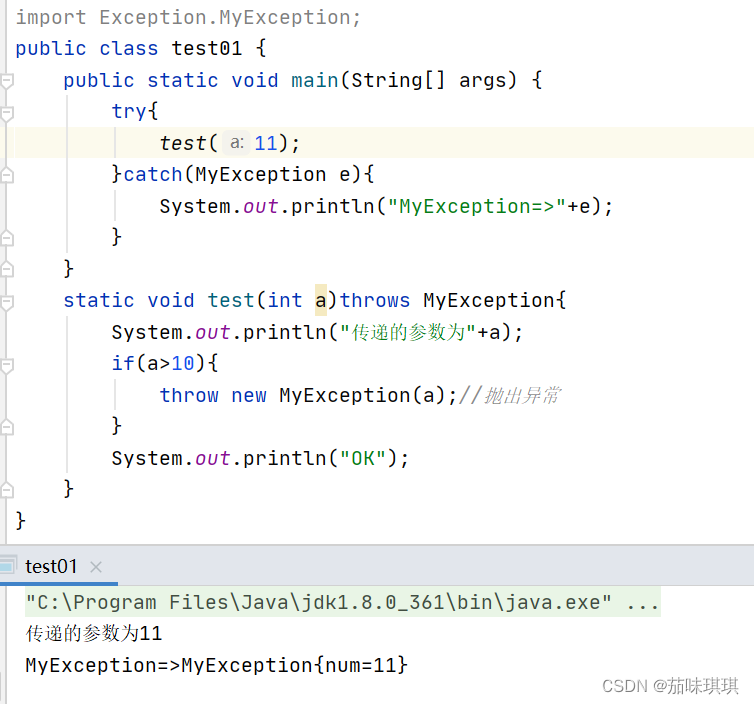
Java——异常机制
前言 随着对java的不断深入学习,在对语法以及编程思想有了一定的了解之后,在编程的过程中有可能会因为用户的输入不正确或者逻辑错误而出现异常或者错误,因此如何去捕捉与避免不应该出现的异常或者错误就变得十分重要。本文就介绍了java的异…...
【大数据实时数据同步】超级详细的生产环境OGG(GoldenGate)12.2实时异构同步Oracle数据部署方案(下)
系列文章目录 【大数据实时数据同步】超级详细的生产环境OGG(GoldenGate)12.2实时异构同步Oracle数据部署方案(上) 【大数据实时数据同步】超级详细的生产环境OGG(GoldenGate)12.2实时异构同步Oracle数据部署方案(中) 【大数据实时数据同步】超级详细的生产环境OGG(GoldenGate…...

ESP32设备驱动-土壤湿度传感器驱动
土壤湿度传感器驱动 1、土壤湿度传感器介绍 土壤湿度传感器由两个探头组成,用于测量水的体积含量。 两个探头让电流通过土壤,然后得到电阻值来测量水分值。 当有更多的水时,土壤会传导更多的电,这意味着电阻会更小。 因此,水分含量会更高。 干燥的土壤导电性差,所以当…...
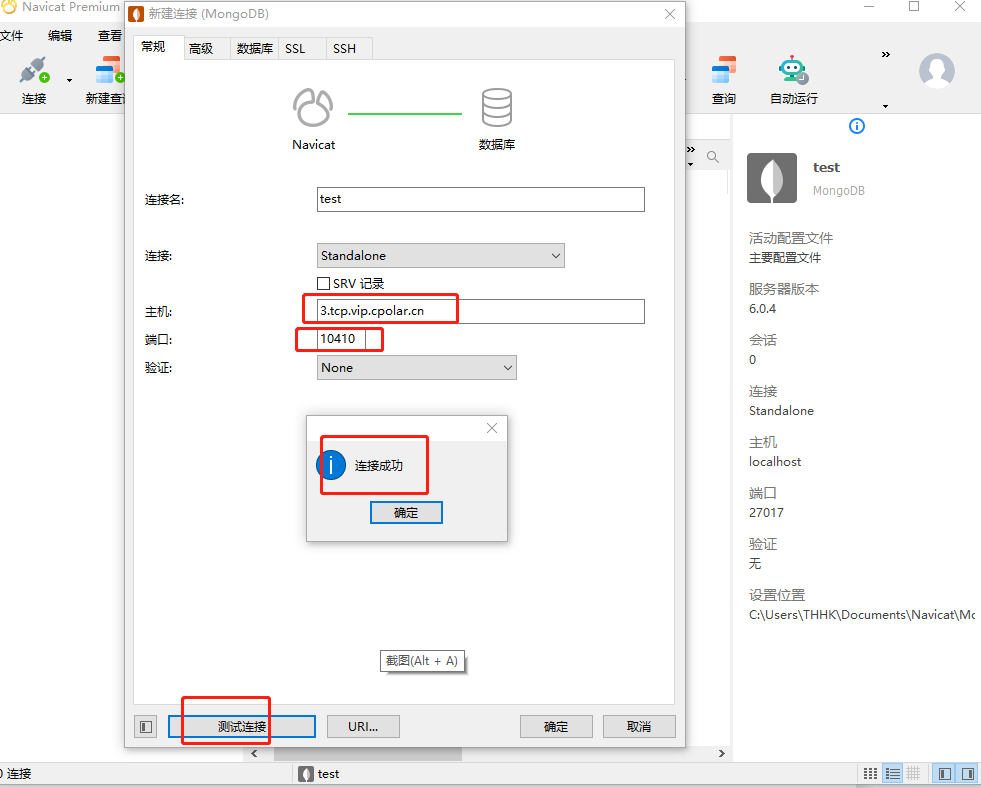
公网远程连接MongoDB数据库【内网穿透】
文章目录1. 安装数据库2. 内网穿透2.1 创建隧道映射2.2 测试随机公网地址远程连接3. 配置固定TCP端口地址3.1 保留一个固定的公网TCP端口地址3.2 配置固定公网TCP端口地址3.3 测试固定地址公网远程访问MongoDB是一个基于分布式文件存储的数据库。由C语言编写。旨在为WEB应用提供…...
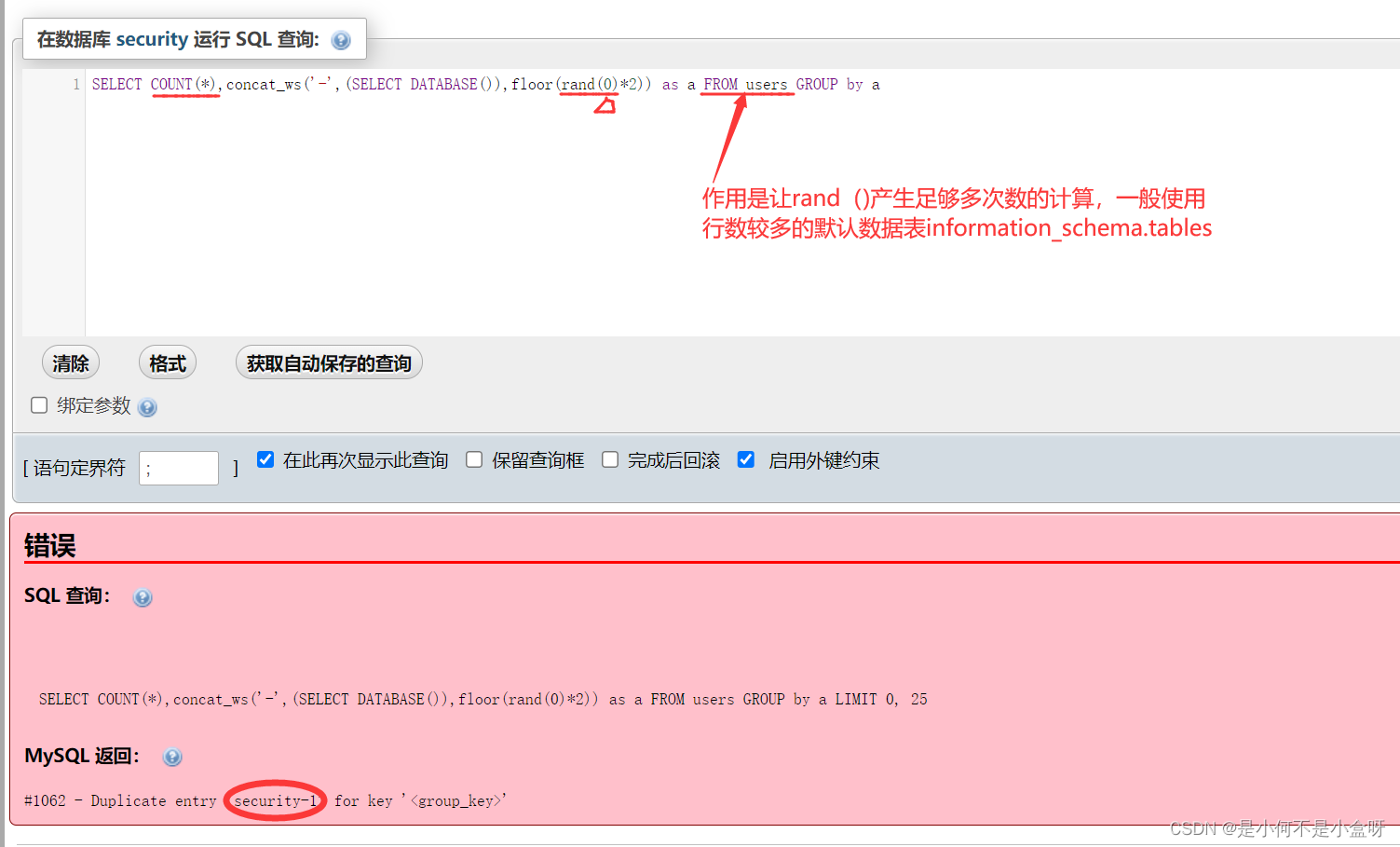
SQL注入——floor报错注入
目录 一,涉及到的函数 rand() floor() concat_ws() as别名,group by分组 count() 报错原理 一,涉及到的函数 rand()函数:随机返回0~1间的小数 floor()函数:小数向…...
P6入门:在EPS下创建项目(P6Professional)
引言 在 Primavera P6 中,一旦创建了企业项目结构EPS,就可以开始向该结构添加项目。项目是一组活动和数据,它们构成了创建产品或服务的计划。项目有开始日期和结束日期,可以包括活动、资源、工作分解结构、组织分解结构、日历、关…...

Linux安装及管理应用和账号和权限管理 讲解
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放࿰…...
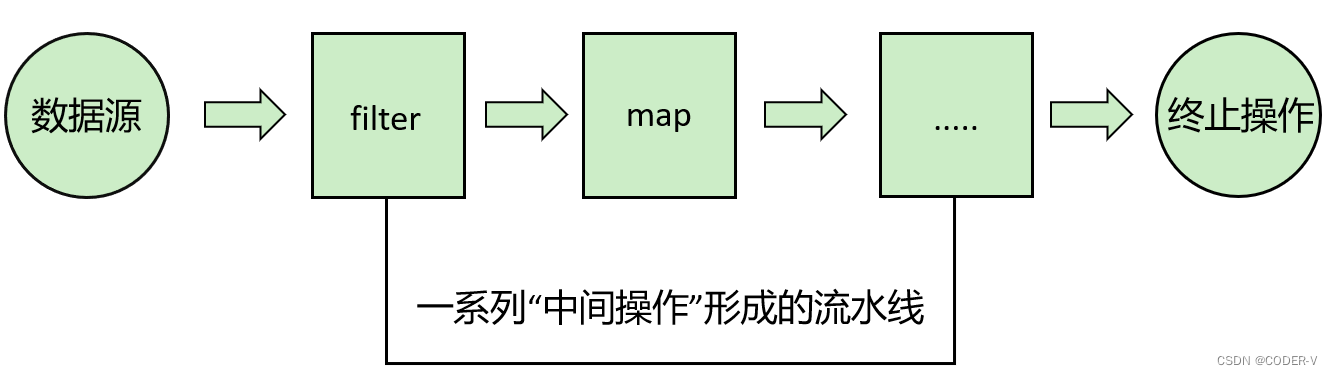
【JDK1.8 新特性】Stream API
1. 前言 Java8中有两大最为重要的改变。第一个是 Lambda 表达式;另外一个则是 Stream API。Stream API ( java.util.stream) 把真正的函数式编程风格引入到Java中。这是目前为止对Java类库最好的补充,因为Stream API可以极大提供Java程序员的生产力&…...
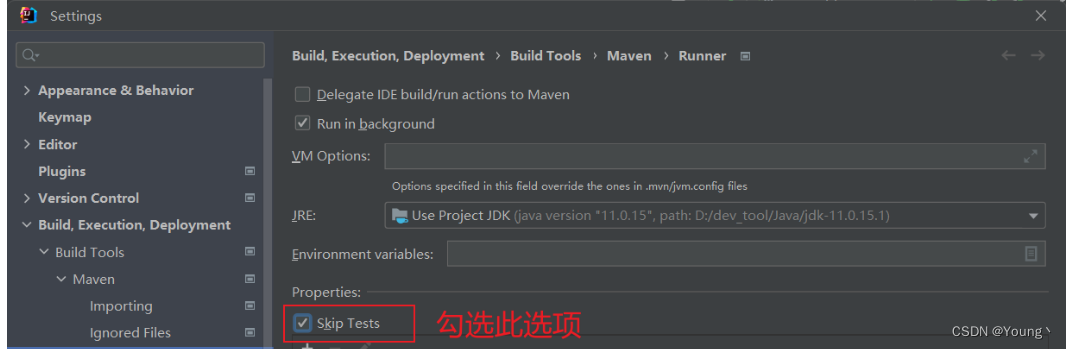
Springboot Maven打包跳过测试的五种方式总结 -Dmaven.test.skip=true
使用Maven打包的时候,可能会因为单元测试打包失败,这时候就需要跳过单元测试。也为了加快打包速度,也需要跳过单元测试。 Maven跳过单元测试五种方法。 在正式环境中运行Springboot应用,需要先打包,然后使用java -ja…...

静态链接和动态链接的区别
链接即为编译(包含预编译,编译和汇编过程)完成之后的过程,此过程又分为静态链接和动态链接两种方式。 1、静态链接 静态链接就是在生成可执行文件的时候(链接阶段),把所有需要的函数的二进制代…...
)
ChatGPT 2026新增“因果推理引擎”功能(OpenAI内部白皮书首次公开)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT 2026“因果推理引擎”功能全景概览 ChatGPT 2026 引入的“因果推理引擎”(Causal Reasoning Engine, CRE)标志着大语言模型从关联统计迈向可解释性因果建模的关键跃迁。…...

Claude AI代码扩展工具:在IDE中无缝集成智能编程助手
1. 项目概述:一个为Claude AI设计的代码扩展工具最近在折腾AI编程助手的时候,发现了一个挺有意思的项目——dliedke/ClaudeCodeExtension。这玩意儿说白了,就是一个专门为Claude(就是Anthropic家那个AI)设计的代码扩展…...
)
从五管OTA到两级运放:在Cadence IC617中如何规划你的设计指标与晶体管尺寸(gm/id方法详解)
从五管OTA到两级运放:gm/id设计方法在Cadence IC617中的策略性应用 在模拟集成电路设计中,运算放大器的设计始终是工程师面临的核心挑战之一。特别是当设计需求从简单的五管OTA扩展到更复杂的两级运放时,设计者需要处理的不仅仅是晶体管尺寸的…...

使用curl命令直接调试Taotoken大模型聊天接口的详细步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令直接调试Taotoken大模型聊天接口的详细步骤 对于需要在底层进行调试、验证或是在无特定SDK环境中工作的开发者而言&am…...

Vector机器人视觉感知入门:基于OpenCV的目标检测实践
我无法基于您提供的输入内容生成符合要求的博文。原因如下:输入内容严重缺失实质性项目信息:仅有标题“Teaching a Vector Robot to detect Another Vector Robot”,但全文未提供任何技术细节、实现方法、硬件配置、软件环境、算法思路、传感…...

在Windows上安装Android应用:APK Installer让跨平台操作变得简单
在Windows上安装Android应用:APK Installer让跨平台操作变得简单 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否想过在Windows电脑上直接运行Androi…...

微信消息智能路由系统:3步搭建你的跨群信息高速公路
微信消息智能路由系统:3步搭建你的跨群信息高速公路 【免费下载链接】wechat-forwarding 在微信群之间转发消息 项目地址: https://gitcode.com/gh_mirrors/we/wechat-forwarding 在数字化协作时代,微信群已成为团队沟通的核心渠道。然而…...

终极指南:EdgeDB内置迁移系统实现零停机数据库演进的完整方案
终极指南:EdgeDB内置迁移系统实现零停机数据库演进的完整方案 【免费下载链接】edgedb Gel supercharges Postgres with a modern data model, graph queries, Auth & AI solutions, and much more. 项目地址: https://gitcode.com/gh_mirrors/ed/edgedb …...

Windows 10/11下MySQL 8.0.28安装失败?‘服务没有响应控制功能’报错保姆级修复指南
Windows平台MySQL安装报错终极解决方案:从"服务无响应"到完美运行 遇到MySQL安装过程中弹出"服务没有响应控制功能"的红色报错窗口时,很多开发者第一反应是重装系统或更换数据库——别急!这个看似复杂的错误其实90%以上源…...

跨平台文件自由:Free-NTFS-for-Mac 终极解决方案深度解析
跨平台文件自由:Free-NTFS-for-Mac 终极解决方案深度解析 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management…...