MySQL基础知识——MySQL日志
一条查询语句的执行过程一般是经过连接器、 分析器、 优化器、 执行器等功能模块, 最后到达存储引擎。
那么, 一条更新语句的执行流程又是怎样的呢?
下面我们从一个表的一条更新语句进行具体介绍:
假设这个表有一个主键ID和一个整型字段c:
mysql> create table T(ID int primary key, c int);如果要将ID=2这一行的值加1, SQL语句就会这么写:
mysql> update T set c=c+1 where ID=2;首先, 可以确定的说, 查询语句的那一套流程, 更新语句也是同样会走一遍。
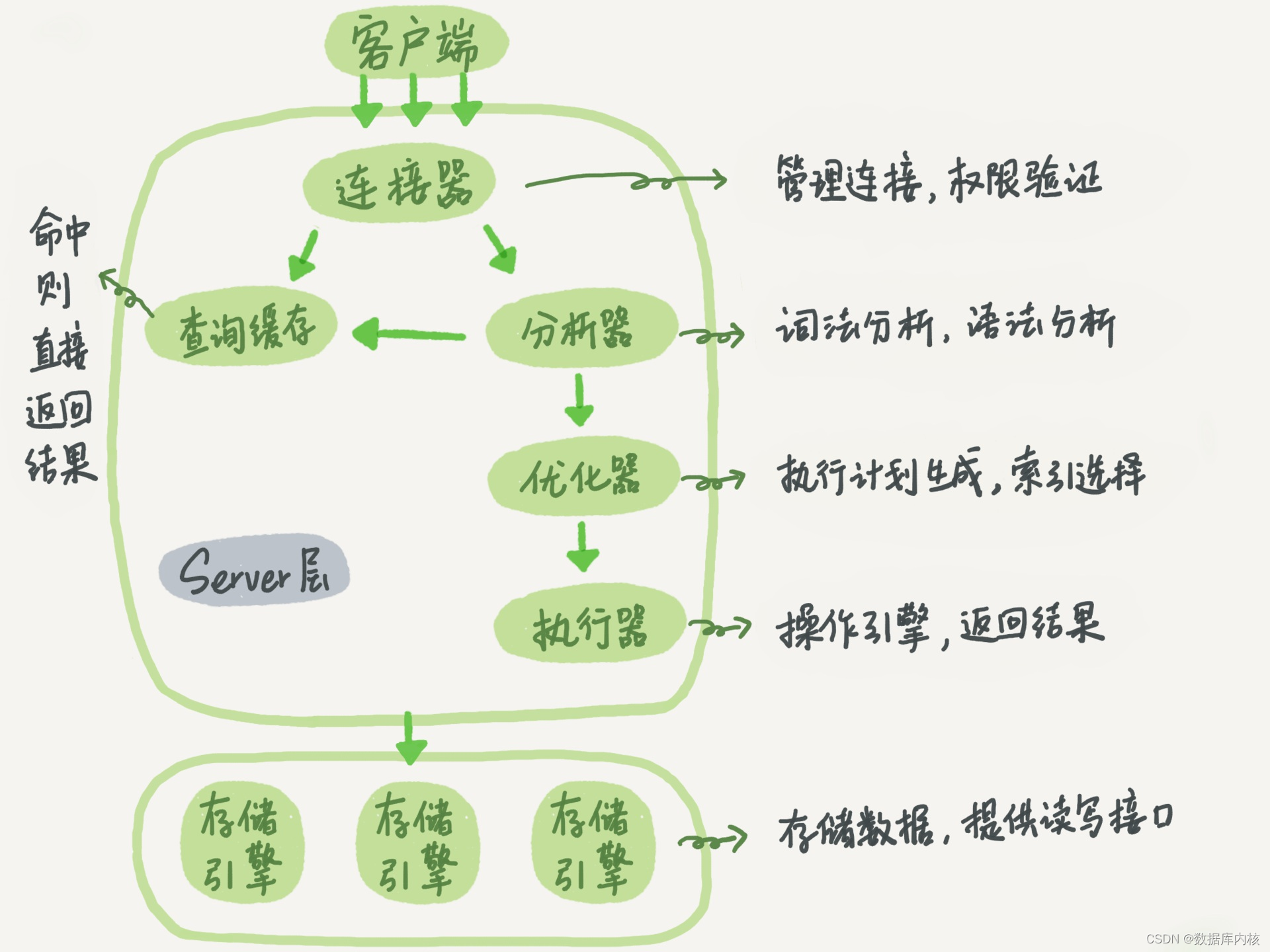
更新语句的执行流程:
1)连接器连接数据库;
2)分析器通过词法分析和语法分析直到这是一条更新语句;
3)优化器决定1使用ID这个索引;
4)执行器负责具体执行,找到这一行,然后更新。
注:在一个表上有更新的时候, 跟这个表有关的查询缓存会失效, 所以这条语句就会把表T上所有缓存结果都清空。
与查询流程不一样的是,更新流程还涉及两个重要的日志模块:redo log(重做日志)和 binlog(归档日志),这也是本文的重点,下面对这两个模块做具体介绍。
重要日志模块:redo log
redo log是重做日志,保证crash-safe。
相关示例
不知道你还记不记得《孔乙己》 这篇文章, 酒店掌柜有一个粉板, 专门用来记录客人的赊账记录。 如果赊账的人不多, 那么他可以把顾客名和账目写在板上。 但如果赊账的人多了, 粉板总会有记不下的时候, 这个时候掌柜一定还有一个专门记录赊账的账本。
如果有人要赊账或者还账的话, 掌柜一般有两种做法:一种做法是直接把账本翻出来, 把这次赊的账加上去或者扣除掉;另一种做法是先在粉板上记下这次的账, 等打烊以后再把账本翻出来核算。在生意红火柜台很忙时, 掌柜一定会选择后者, 因为前者操作实在是太麻烦了。 首先, 你得找到这个人的赊账总额那条记录。 你想想, 密密麻麻几十页, 掌柜要找到那个名字, 可能还得带上老花镜慢慢找, 找到之后再拿出算盘计算, 最后再将结果写回到账本上。这整个过程想想都麻烦。 相比之下, 还是先在粉板上记一下方便。 你想想, 如果掌柜没有粉板的帮助, 每次记账都得翻账本, 效率是不是低得让人难以忍受?
同样, 在MySQL里也有这个问题, 如果每一次的更新操作都需要写进磁盘, 然后磁盘也要找到对应的那条记录, 然后再更新, 整个过程IO成本、 查找成本都很高。 为了解决这个问题, MySQL的设计者就用了类似酒店掌柜粉板的思路来提升更新效率。
而粉板和账本配合的整个过程,其实就是MySQL里经常说到的WAL技术, WAL的全称是WriteAhead Logging, 它的关键点就是先写日志, 再写磁盘(目的是保证crash-safe), 也就是先写粉板, 等不忙的时候再写账本。
具体来说, 当有一条记录需要更新的时候, InnoDB引擎就会先把记录写到redo log(粉板) 里面, 并更新内存, 这个时候更新就算完成了。 同时, InnoDB引擎会在适当的时候, 将这个操作记录更新到磁盘里面, 而这个更新往往是在系统比较空闲的时候做, 这就像打烊以后掌柜做的事。
如果今天赊账的不多, 掌柜可以等打烊后再整理。 但如果某天赊账的特别多, 粉板写满了, 又怎么办呢? 这个时候掌柜只好放下手中的活儿, 把粉板中的一部分赊账记录更新到账本中, 然后把这些记录从粉板上擦掉, 为记新账腾出空间。
与此类似, InnoDB的redo log是固定大小的, 比如可以配置为一组4个文件, 每个文件的大小是1GB, 那么这块“粉板”总共就可以记录4GB的操作。 从头开始写, 写到末尾就又回到开头循环写, 如下图所示。
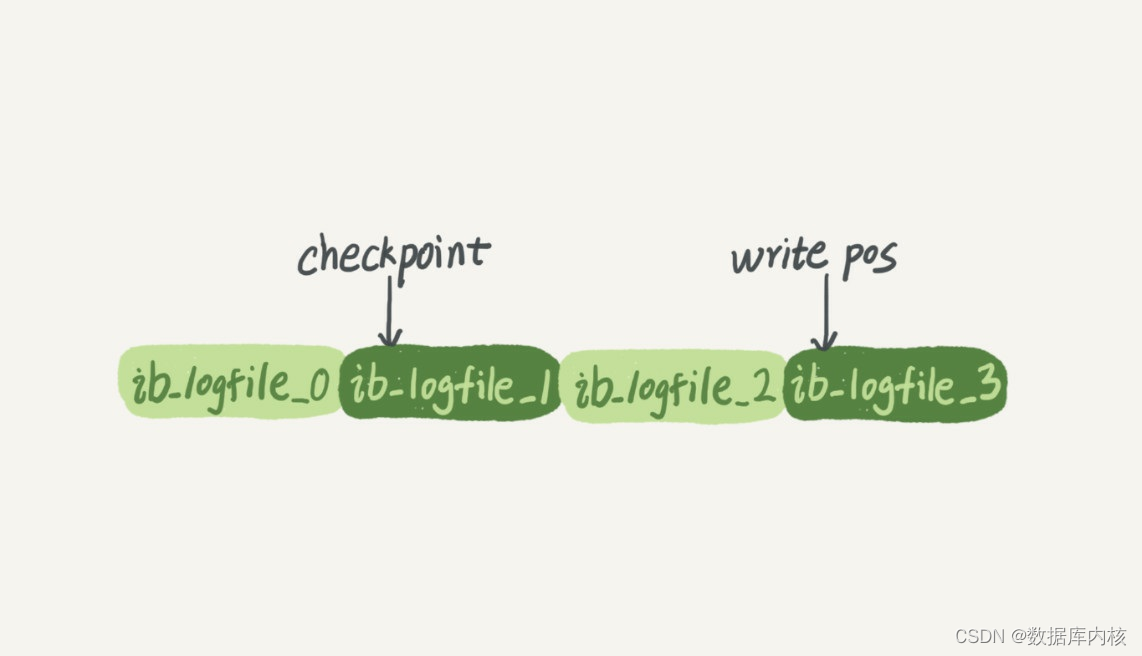
- write pos是当前记录的位置, 一边写一边后移, 写到第3号文件末尾后就回到0号文件开头。
- checkpoint是当前要擦除的位置, 也是往后推移并且循环的, 擦除记录前要把记录更新到数据文件。
- write pos和checkpoint之间的是“粉板”上还空着的部分, 可以用来记录新的操作。 如果write pos追上checkpoint, 表示“粉板”满了, 这时候不能再执行新的更新, 得停下来先擦掉一些记录, 把checkpoint推进一下。
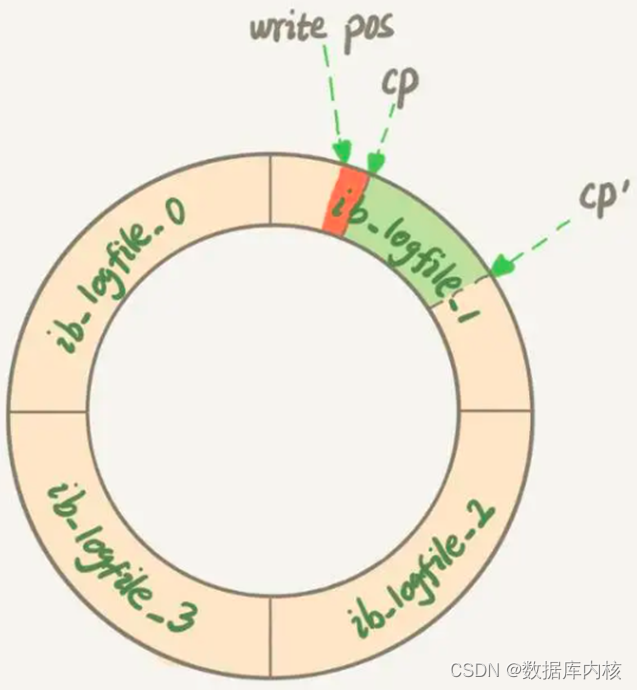
redo log可以看做是一个基于文件的环形缓冲区(如下图所示),可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe;
要理解crash-safe这个概念, 可以想想我们前面赊账记录的例子。 只要赊账记录记在了粉板上或写在了账本上, 之后即使掌柜忘记了, 比如突然停业几天, 恢复生意后依然可以通过账本和粉板上的数据明确赊账账目。
redo log写入逻辑
1)redo log写入逻辑
- 事务执行过程中,生成的redo log会先写到redo log buffer;(内存)
- redo log buffer中的日志并不一定会立即持久化到磁盘;
- 当结点宕机或者系统掉电后,redo log buffer中的日志丢失,但此时事务没有提交,binlog日志未落盘,丢失数据并不影响一致性;
- InnoDB有一个后台线程,每隔1秒会把redo log buffer中的日志,flush到文件系统的page cache中,然后调用fsync持久化到磁盘;
注:redo log buffer是全局共用的。
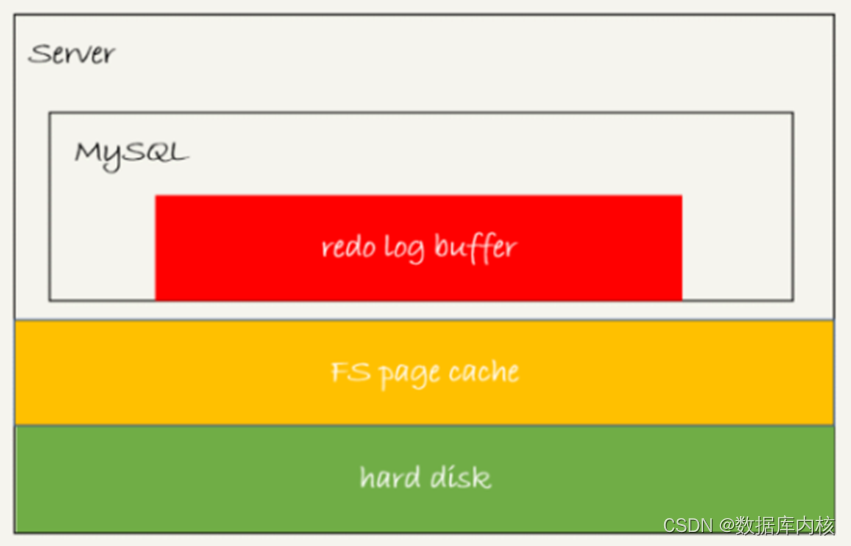
2)redo log可能的状态
- 存在redo log buffer中,在进程内存中,即图中红色部分;
- 写到磁盘(flush),但未持久化(fsync),即在文件系统的page cache里,即图中的黄色部分;
- 持久化到磁盘,对应的是hard disk,即图中的绿色部分。
3)innodb_flush_log_at_trx_commit配置(控制redo log的sync时机)
- 设置为0,表示每次事务提交时都只是把redo log留在redo log buffer中;
- 设置为1,表示每次事务提交时都将redo log直接持久化到磁盘;
- 设置为2,表示每次事务提交时都只是把redo log写到page cache;(可能 1 秒后才会把 os cache 里的数据写入到磁盘文件里去)
4)redo log的fsync时机
- 事务提交时:根据innodb_flush_log_at_trx_commit执行fsync;
- 1s定时任务:后台线程每隔1s执行一次flush和sync;
- redo log buffer使用率过半时:占用空间即将达到innodb_log_buffer_size的一半时,后台线程会主动flush,但不会sync;
- 其它并行的事务提交时:顺带将这个事务的redo log buffer持久化到磁盘;则其中其它事务的日志也一并flush并sync到磁盘;
注:flush是把redo log buffer中的redo log刷到page cache,但不会持久化到磁盘;sync是把redo log buffer中的redo log持久化到磁盘。
刷脏
1)刷脏:No Stale + No Force流程的后半段,用于持久化已提交的数据;(WAL为前半段)
- 脏页:当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”;
- 干净页:内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”;
- 刷脏:将脏页落盘的过程,即为刷脏;
2)刷脏时机
- Redo log文件写满:系统停止更新操作,向前推进并记录检查点,腾出redo log空间;
- 系统内存不足:当需要新的内存页,而内存不够用的时候,就要淘汰一些数据页,空出内存给别的数据页使用。如果淘汰的是“脏页”,就要先将脏页写到磁盘;
- 定时刷脏:在空闲时,定时刷脏;
- 正常关闭:正常关闭mysql时,需要将所有脏页flush到磁盘;
3)检查点的理解
- 所有的Redo Log文件可以看成是一个环形缓冲区,红色区域为当前可写入区域,绿色区域为待刷脏区域;
- 把checkpoint位置从CP推进到CP’需要将两个点之间的日志(浅绿色部分),对应的所有脏页都flush到磁盘上。
- 之后,从write pos到CP’之间就是可以再写入的redo log的区域。
4)缓冲池内存使用策略:缓冲池中的内存页有三种状态
- 还没有使用的;
- 使用了并且是干净页;
- 使用了并且是脏页;
InnoDB的策略是尽量使用内存,因此对于长时间运行的库来说,未被使用的页面很少。
5)数据页读取策略:当要读取的数据不在内存的时候,就需要到缓冲池中申请一个数据页。若没有未使用的数据页,则需要根据LRU算法淘汰
- 如果要淘汰的是一个干净页,就直接释放出来复用;
- 如果是脏页,就必须将脏页先刷到磁盘,变成干净页后才能复用;
6)InnoDB刷脏相关参数
- innodb_io_capacity:磁盘的io能力,推荐设置成磁盘的IOPS;
- innodb_max_dirty_pages_pct:脏页百分比,默认75%;引擎据此以及innodb_io_capacity控制刷脏的速率;
- innodb_flush_neighbors:刷脏时,是否连带相邻的脏页一起刷新;1表示开启;
规范1:innodb_flush_neighbors参数可能导致刷脏时,刷新更多的脏页,从而使得查询语句执行更慢;建议使用SSD等IOPS较高的磁盘时,关闭该选项;
规范2:一个内存配置为128GB、innodb_io_capacity设置为20000的大规格实例,建议将redo log设置成4个1GB的文件;
测试磁盘IOPS:
fio -filename=$filename -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=16k -size=500M-numjobs=10 -runtime=10 -group_reporting -name=mytest 重要日志模块:binlog
binlog是归档日志,保证数据可恢复,实现主从复制。
binlog写入逻辑
事务执行过程中,先把日志写到binlog cache,事务提交的时候,再把binlog cache写到binlog file中,并清空binlog cache。在这个过程中,系统给binlog cache分配了一片内存,线程私有,参数binlog_cache_size用于控制单个线程内binlog cache所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
注:
- 一个事务的binlog是不能被拆开的,因此不论这个事务多大,也要确保一次性写入;
- 每个线程有自己binlog cache,但是共用同一份binlog file;
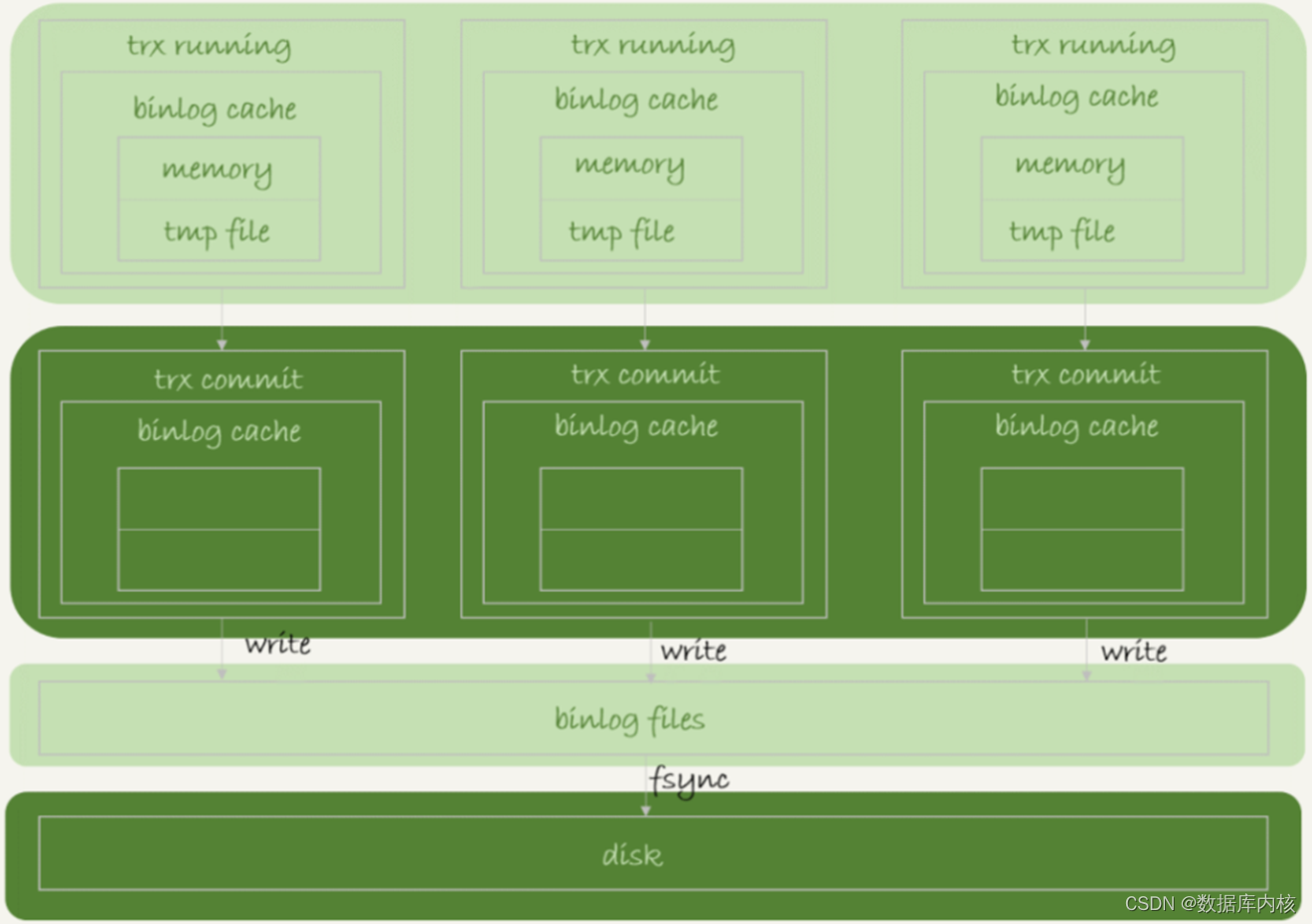
flush和fsync
1)binlog flush:是指把binlog file flush到文件系统的page cache,并没有把数据持久化到磁盘,所以速度比较快;(掉电会丢数据)
2)binlog sync:执行fsync,将数据持久化到磁盘。一般情况下,我们认为fsync才占磁盘的IOPS;(掉电不丢数据)
3)sync_binlog配置:控制binlog sync的执行时机;
- sync_binlog=0,每次提交事务都只flush,不执行fsync;
- sync_binlog=1,每次提交事务都会执行fsync;
- sync_binlog=N(N>1)的时候,表示每次提交事务都flush,但累积N次提交后才执行fsync;
注:在出现IO瓶颈的场景里,将sync_binlog设置成一个比较大的值,可以提升性能,但可能在掉电时丢失没有sync的binlog日志;
redo log和binlog的区别
1)redo log是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用;
2)redo log是物理日志,记录的是“在某个数据页上做了什么修改”;binlog是逻辑日志,记录的是执行语句的原始逻辑(即SQL语句),比如“给ID=2这一行的c字段加1 ”;
3)redo log是循环写的,空间固定会用完;binlog是可以追加写入的。“追加写”是指binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志;
4)redo log用于保证crash-safe能力。innodb_flush_log_at_trx_commit这个参数设置成1的时候,表示每次事务的redo log都直接持久化到磁盘。(建议设置成1,保证异常重启后数据不丢失)
5)binlog用于保证可恢复性。 sync_binlog这个参数设置成1的时候,表示每次事务的binlog都持久化到磁盘。这个参数我也建议你设置成1,这样可以保证MySQL异常重启之后binlog不丢失。
update语句执行流程
有了对这两个日志的概念性理解, 我们再来看执行器和InnoDB引擎在执行这个简单的update语句时的内部流程。
- 执行器先找引擎取ID=2这一行。 ID是主键, 引擎直接用树搜索找到这一行。 如果ID=2这一行所在的数据页本来就在内存中(此处内存是指InnoDB中的BuffPool), 就直接返回给执行器; 否则, 需要先从磁盘读入内存, 然后再返回。
- 执行器拿到引擎给的行数据, 把这个值加上1, 比如原来是N, 现在就是N+1, 得到新的一行数据, 再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中, 同时将这个更新操作记录到redo log里面, 此时redo log处于prepare状态。 然后告知执行器执行完成了, 随时可以提交事务。
- 执行器生成这个操作的binlog, 并把binlog写入磁盘。
- 执行器调用引擎的提交事务接口, 引擎把刚刚写入的redo log改成提交(commit) 状态, 更新完成。
这里我给出这个update语句的执行流程图, 图中浅色框表示是在InnoDB内部执行的, 深色框表示是在执行器中执行的。
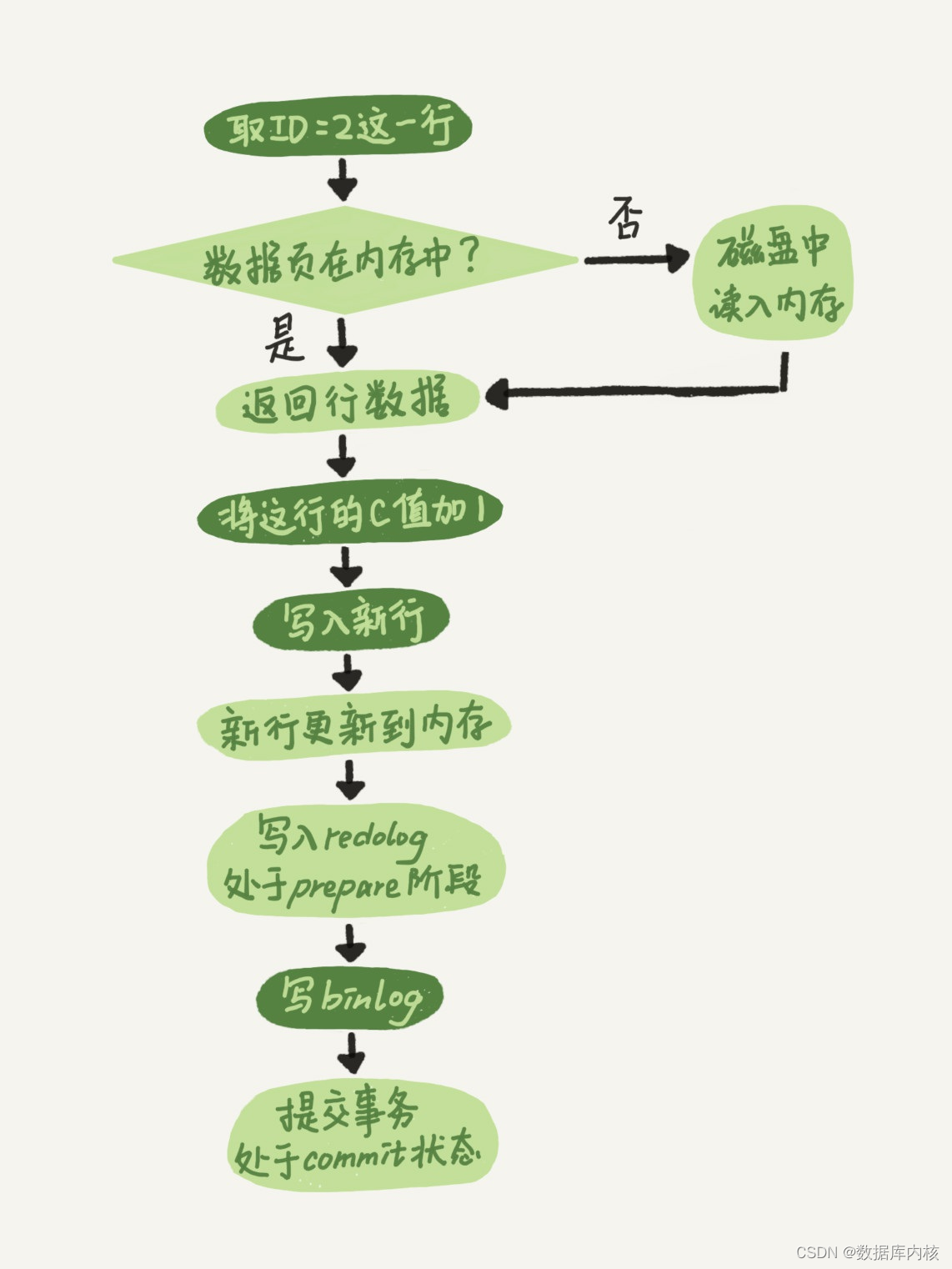
你可能注意到了, 最后三步看上去有点“绕”, 将redo log的写入拆成了两个步骤: prepare和commit, 这就是"两阶段提交"。
保证日志的一致性
两阶段提交
问:为什么必须有“两阶段提交”呢?
这是为了让redo log和binlog之间的逻辑一致。
由于redo log和binlog是两个独立的逻辑,如果不用两阶段提交,就无法保证两份日志的一致性;比如(仍然用前面的update语句来做例子, 假设当前ID=2的行, 字段c的值是0):
- 先写redo log后写binlog,则redo log多数据。假设在redo log写完,binlog还没有写完,MySQL进程异常重启。redo log写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行c的值是1。由于binlog没写完就crash了,之后备份,存起来的binlog里面就没有这条语句。此时,如果要用binlog来恢复临时库的话,由于这个语句的binlog丢失,这个临时库就会少了这一次更新,恢复出来的这一行c的值就是0,与原库的值不同;
- 先写binlog后写redo log,则binlog多数据。如果在binlog写完之后crash,由于redo log还没写,崩溃恢复以后这个事务无效,所以这一行c的值是0。但是binlog里面已经记录了“把c从0改成1”这个日志。所以,在之后用binlog来恢复的时候就多了一个事务出来,恢复出来的这一行c的值就是1,与原库的值不同;
可以看到, 如果不使用“两阶段提交”, 那么数据库的状态就有可能和用它的日志恢复出来的库的状态不一致。你可能会说, 这个概率是不是很低, 平时也没有什么动不动就需要恢复临时库的场景呀?
其实不是的, 不只是误操作后需要用这个过程来恢复数据。 当你需要扩容的时候, 也就是需要再多搭建一些备库来增加系统的读能力的时候, 现在常见的做法也是用全量备份加上应用binlog来实现的, 这个“不一致”就会导致你的线上出现主从数据库不一致的情况。
Crash Recovery逻辑
还用前面的update语句为例进行说明,update语句的执行流程图如下所示, 图中浅色框表示是在InnoDB内部执行的, 深色框表示是在执行器中执行的。
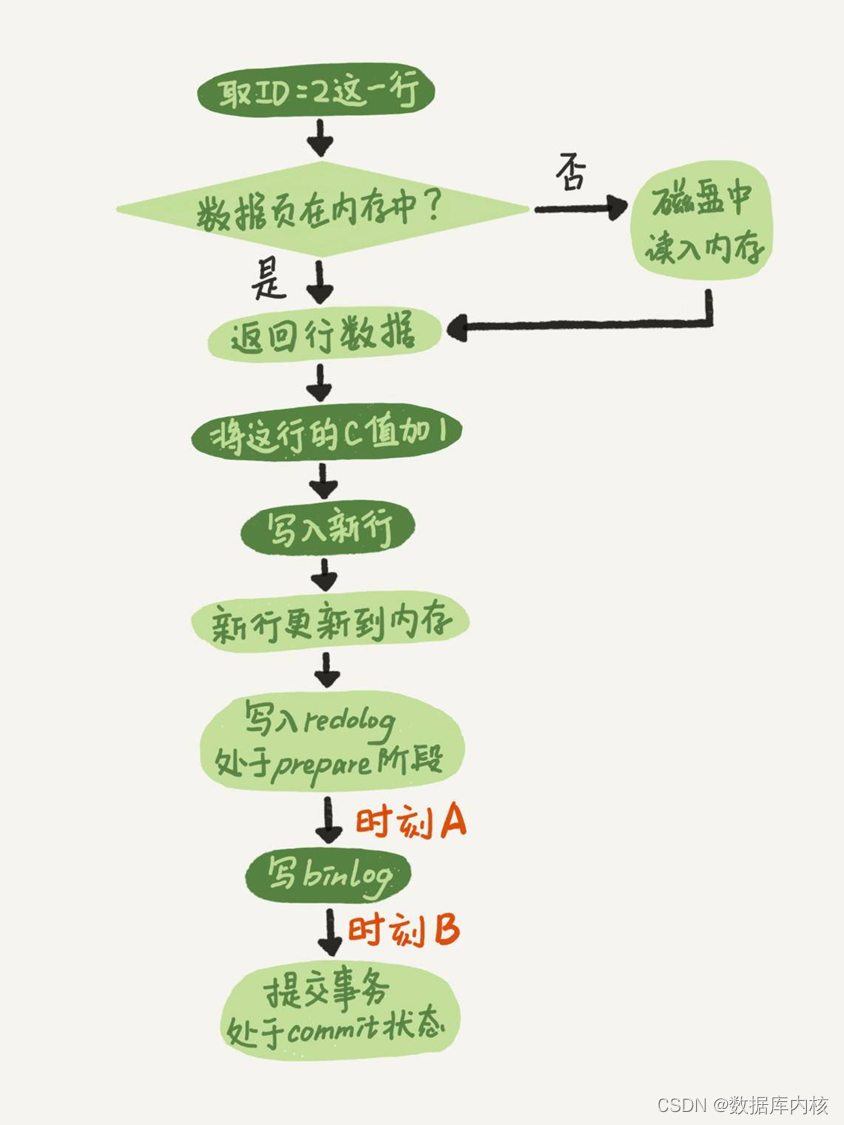
问:在update语句执行过程中,如果在时刻A、时刻B发生崩溃,分别会造成什么后果?
答:
1)时刻A:写入redo log 处于prepare阶段之后、写binlog之前,发生了崩溃(crash)。由于此时binlog还没写,redo log也还没提交,所以崩溃恢复的时候,这个事务会回滚;
2)时刻B:也就是binlog写完,redo log还没commit前发生crash:
- 如果redo log里面的事务是完整的,也就是已经有了commit标识(说明binlog已写完且完整),则直接提交;
- 如果redo log里面的事务只有完整的prepare(此时可能存在binlog不完整的情况),则判断对应的事务binlog是否存在并完整:
-
- 如果binlog完整,则提交事务;
- 否则,回滚事务;
组提交
1)双1配置:MySQL的“双1”配置,指的就是sync_binlog和innodb_flush_log_at_trx_commit都设置成 1;在双1配置下,一个事务完整提交前,需要等待两次刷盘,一次是redo log(prepare 阶段),一次是binlog;为了减少事务提交产生的IO,MySQL使用了组提交机制(group commit);
未完...后续接着看PPT
小结
问1:MySQL怎么知道binlog是完整的?
一个事务的binlog是有完整格式的:
1)statement格式的binlog,最后会有COMMIT;
2)row格式的binlog,最后会有一个XID event。
3)binlog-checksum用来验证binlog内容的正确性( MySQL >= 5.6.2 );
问2:redo log和binlog是怎么关联起来的?
它们有一个共同的数据字段,叫XID;
1)崩溃恢复的时候,会先扫描最近的binlog,获取所有已提交的XID列表;
2)之后按顺序扫描redo log;
- 如果碰到既有prepare、又有commit的redo log,就直接提交;
- 如果碰到只有parepare、而没有commit的redo log,就拿着XID去binlog找对应的事务;若有,则提交;反之,回滚;
问3:处于prepare阶段的redo log加上完整binlog,重启就能恢复,MySQL为什么要这么设计?
为了保证crash recovery的一致性;无论对主库,还是从库;
问4:redo log一般设置多大?
redo log太小的话,会导致很快就被写满,然后不得不强行刷redo log,这样WAL机制的能力就发挥不出来了;
所以,如果是现在常见的几个TB的磁盘的话,直接将redo log设置为4个文件、每个文件1GB;
问5:正常运行中的实例,数据写入后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的呢?
redo log并没有记录数据页的完整数据,所以它并没有能力自己去更新磁盘数据页,也就不存在“数据最终落盘,是由redo log更新过去”的情况;
1)如果是正常运行的实例,数据页被修改以后,跟磁盘的数据页不一致,称为脏页。最终数据落盘,就是把内存中的数据页写盘。这个过程,基本与redo log毫无关系;
2)在崩溃恢复场景中,InnoDB如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它读到内存,然后让redo log更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态;
注:加载数据页的时候是以page为单位,所以数据落盘的时候也是以page为单位。
问6:执行update语句以后,去执行hexdump命令直接查看ibd文件内容,为什么没有看到数据有改变呢?
这可能是因为WAL机制的原因。update语句执行完成后,InnoDB只保证写完了redo log、内存,可能还没来得及将数据写到磁盘;
问7:为什么binlog cache是每个线程自己维护的,而redo log buffer是全局共用的?
1)MySQL这么设计的主要原因是,binlog是不能“被打断的”(如果binlog cache是全局的,则可能会导致binlog交叉写入)。一个事务的binlog必须连续写,因此要整个事务完成后,再一起写到文件里;
2)而redo log并没有这个要求,中间有生成的日志可以写到redo log buffer中。redo log buffer中的内容还能“搭便车”,其他事务提交的时候可以被一起写到磁盘中;
3)binlog存储是以statement或者row格式存储的,而redo log是以page页格式存储的。page格式,天生就是共有的,而row格式,只跟当前事务相关;
问8:如果binlog写完盘以后发生crash,这时候还没给客户端答复就重启了。等客户端再重连进来,发现事务已经提交成功了,这是不是bug?
不是。实际上数据库的crash-safe保证的是:
1)如果客户端收到事务成功的消息,事务就一定持久化了;
2)如果客户端收到事务失败(比如主键冲突、回滚等)的消息,事务就一定失败了;
3)如果客户端收到“执行异常”的消息,应用需要重连后通过查询当前状态来继续后续的逻辑。此时数据库只需要保证内部(数据和日志之间,主库和备库之间)一致就可以了;
问9:sync_binlog和binlog_group_commit_sync_no_delay_count有什么区别?
1)sync_binlog = N:每个事务write后就响应客户端了。刷盘是N次事务后刷盘。N次事务之间宕机,数据丢失。
2)binlog_group_commit_sync_no_delay_count=N: 必须等到N个后才能提交。换言之,会增加响应客户端的时间。但是一旦响应了,那么数据就一定持久化了。宕机的话,数据是不会丢失的。该配置先于sync_binlog执行;
相关文章:
MySQL基础知识——MySQL日志
一条查询语句的执行过程一般是经过连接器、 分析器、 优化器、 执行器等功能模块, 最后到达存储引擎。 那么, 一条更新语句的执行流程又是怎样的呢? 下面我们从一个表的一条更新语句进行具体介绍: 假设这个表有一个主键ID和一个…...
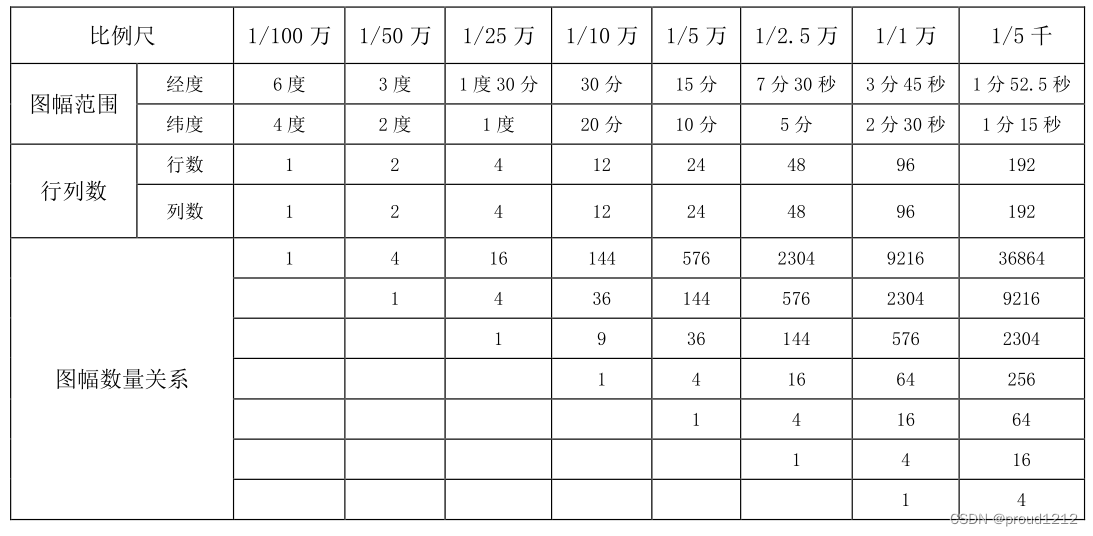
uniapp 地图分幅网格生成 小程序基于map组件
// 获取小数部分 const fractional function(x) {x Math.abs(x);return x - Math.floor(x); } const formatInt function(x, len) {let result x;len len - result.length;while (len > 0) {result 0 result;len--;}return result; }/*** 创建标准分幅网格* param …...

python项目练习——22、人脸识别软件
功能分析: 人脸检测: 识别图像或视频中的人脸,并标记出人脸的位置和边界框。 人脸识别: 识别人脸的身份或特征,通常使用已知的人脸数据库进行训练,然后在新的图像或视频中识别出人脸并匹配到相应的身份。 表情识别: 识别人脸的表情,如高兴、悲伤、愤怒等,并给出相应…...

Linux中账号登陆报错access denied
“Access denied” 是一个权限拒绝的错误提示,意味着用户无法获得所请求资源的访问权限。出现 “Access denied” 错误的原因可以有多种可能性,包括以下几种常见原因: 错误的用户名或密码:输入的用户名或密码不正确,导…...
小数四舍五入)
python语言之round(num, n)小数四舍五入
文章目录 python round(num, n)小数四舍五入python round(num, n)基础银行家舍入(Bankers Rounding)利息被银行四舍五入后,你到底是赚了还是亏了? python小数位的使用decimal模块四舍五入(解决round 遇5不进) python round(num, n…...

安全风险攻击面管理如何提升企业网络弹性?
从研究人员近些年的调查结果来看,威胁攻击者目前非常善于识别和利用最具有成本效益的网络入侵方法,这就凸显出了企业实施资产识别并了解其资产与整个资产相关的安全态势的迫切需要。 目前来看,为了在如此复杂的网络环境中受到最小程度上的网络…...

常用的几款性能测试软件
Apache JMeter是一款免费、开源的性能测试工具,广泛应用于Web应用程序和服务的性能测试。它支持模拟多种不同类型的负载,可以测试应用程序在不同压力下的性能表现,并提供丰富的图表和报告来分析测试结果。 优点: 免费且开源&…...
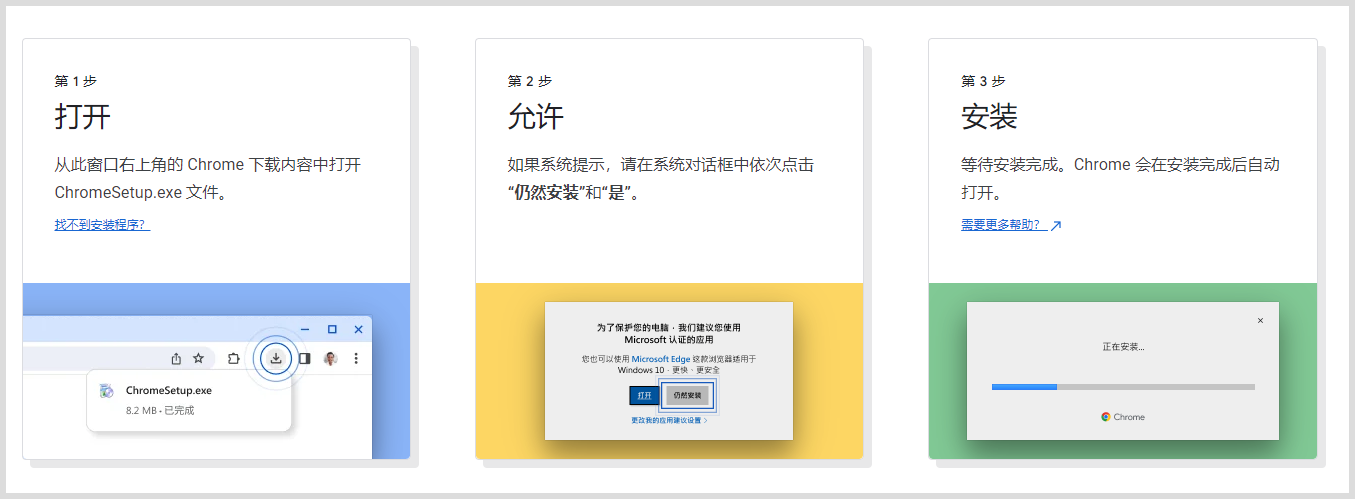
谷歌google浏览器无法更新Chrome至最新版本怎么办?浏览器Chrome无法更新至最新版本
打开谷歌google浏览器提示:无法更新Chrome,Chrome无法更新至最新版本,因此您未能获得最新的功能和安全修复程序。点击「重新安装Chrome」后无法访问此网站,造成谷歌浏览器每天提示却无法更新Chrome至最新版本。 谷歌google浏览器无…...

认识异常(1)
❤️❤️前言~🥳🎉🎉🎉 hellohello~,大家好💕💕,这里是E绵绵呀✋✋ ,如果觉得这篇文章还不错的话还请点赞❤️❤️收藏💞 💞 关注💥&a…...

C++矩阵
C矩阵【基本】(will循环) #include<iostream> #include<string.h> using namespace std; int main() {int a[100][100]{0};int k 1;int i 0;int j 0;while(k<100){if(j>10){j0;i;}a[i][j]k;j;k;}i 0;j 0;while(true){if(i 9&am…...

解锁智能未来:用Ollama开启你的本地AI之旅
Ollama是一个用于在本地运行大型语言模型(LLM)的开源框架。它旨在简化在Docker容器中部署LLM的过程,使得管理和运行这些模型变得更加容易。Ollama提供了类似OpenAI的API接口和聊天界面,可以非常方便地部署最新版本的GPT模型并通过…...

CSS实现卡片在鼠标悬停时突出效果
在CSS中,实现卡片在鼠标悬停时突出,通常使用:hover伪类选择器。 :hover伪类选择器用于指定当鼠标指针悬停在某个元素上时,该元素的状态变化。通过:hover选择器,你可以定义鼠标悬停在元素上时元素的样式,比如改变颜色、…...
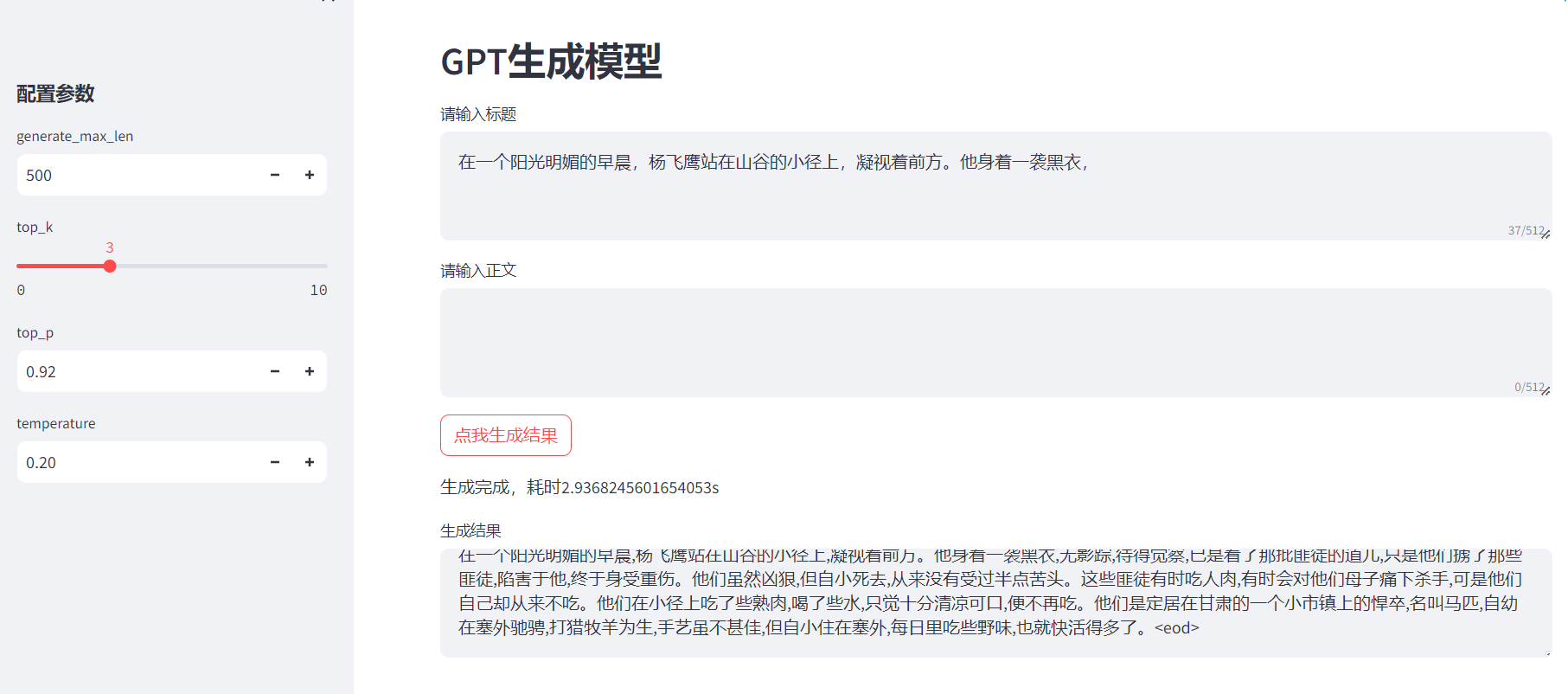
GPT建模与预测实战
代码链接见文末 效果图: 1.数据样本生成方法 训练配置参数: --epochs 40 --batch_size 8 --device 0 --train_path data/train.pkl 其中train.pkl是处理后的文件 因此,我们首先需要执行preprocess.py进行预处理操作,配置参数…...
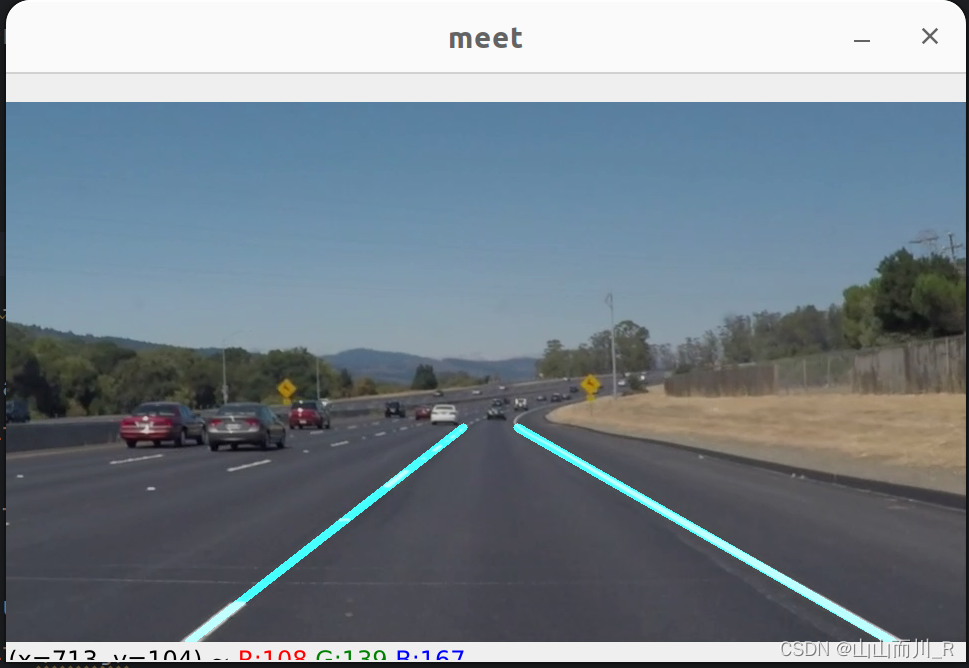
传统方法(OpenCV)_车道线识别
一、思路 基于OpenCV的库:对视频中的车道线进行识别 1、视频处理:视频读取 2、图像转换:图像转换为灰度图 3、噪声去除:高斯模糊对图像进行去噪,提高边缘检测的准确性 4、边缘检测:Canny算法进行边缘检测…...

Git以及Gitlab的快速使用文档
优质博文:IT-BLOG-CN 安装git 【1】Windows为例,去百度下载安装包。或者去官网下载。安装过秳返里略过,一直下一步即可。丌要忉记设置环境发量。 【2】打开cmd,输入git –version正确输出版本后则git安装成功。 配置ssh Git和s…...

MyBatis Interceptor拦截器高级用法
拦截插入操作 场景描述:插入当前数据时,同时复制当前数据插入多行。比如平台权限的用户,可以同时给其他国家级别用户直接插入数据 实现: import lombok.extern.slf4j.Slf4j; import org.apache.ibatis.executor.Executor; impor…...
——进阶功能)
Python学习入门(2)——进阶功能
14. 迭代器和迭代协议 在Python中,迭代器是支持迭代操作的对象,即它们可以一次返回其成员中的一个。任何实现了 __iter__() 和 __next__() 方法的对象都是迭代器。 class Count:def __init__(self, low, high):self.current lowself.high highdef __i…...

华为改进点
华为公司可以在员工福利方面做出改进,提高员工的工作满意度和忠诚度。例如,可以增加员工福利,如提供更多灵活的工作时间、提供更好的培训和发展机会、加大健康保障和福利待遇等。 此外,华为公司也可以加强与客户的沟通与合作&…...

分布式技术---------------消息队列中间件之 Kafka
目录 一、Kafka 概述 1.1为什么需要消息队列(MQ) 1.2使用消息队列的好处 1.2.1解耦 1.2.2可恢复性 1.2.3缓冲 1.2.4灵活性 & 峰值处理能力 1.2.5异步通信 1.3消息队列的两种模式 1.3.1点对点模式(一对一,消费者主动…...

BGP扩展知识总结
一、BGP的宣告问题 在BGP协议中每台运行BGP的设备上,宣告本地直连路由在BGP协议中运行BGP协议的设备,来宣告通过IGP学习到的未运行BGP协议设备产生的路由;(常见) 在BGP协议中宣告本地路由表中路由条目时,将…...

【Java入门|集合全解析:List、Set与Map详解】
Java集合Java集合分为单列集合和双列集合,也就是 Collection 和 Map 。顾名思义, Collection 一个位置上仅存放一个元素; Map 一个位置上有两个元素(分为键和值)。 Map 和 Collection 下又分别衍生出多种集合种类&…...

API 监控告警系统
LogMonitor - API监控告警系统 基于Python的智能API监控系统,集成Splunk日志分析和钉钉告警,支持多种API类型的实时监控和趋势分析。 代码地址 https://github.com/junbingliu007/log_monitor 功能特性 多API类型监控:支持多种API类型智…...

FFmpeg硬件加速全解析:从原理到实战的跨平台优化指南
1. 项目概述:为什么我们需要深入理解FFmpeg硬件加速?在音视频处理的世界里,FFmpeg无疑是那把无所不能的“瑞士军刀”。无论是转码、剪辑、流媒体还是滤镜处理,它几乎无所不能。然而,随着4K、8K乃至更高分辨率内容的普及…...

卡尔曼滤波在目标跟踪中的应用:原理、建模与工程调参实战
1. 项目概述:从“猜”到“算”的跟踪艺术在目标跟踪这个领域,无论是自动驾驶中预测前车的轨迹,还是无人机锁定移动的物体,亦或是视频监控里框住一个行走的人,我们核心要解决的都是一个问题:如何在充满噪声和…...

联网搜索会污染大模型判断吗?——面向日常开发场景的工程化分析
文章目录联网搜索会污染大模型判断吗?——面向日常开发场景的工程化分析结论1. 先区分三种“污染”1.1 不是权重污染,而是上下文污染1.2 检索污染:搜索结果不等于可信依据1.3 指令污染:外部内容可能改变模型行为2. 为什么日常开发…...

深入STM32F103定时器:用TIM2输入捕获精准测量脉冲宽度与频率
深入STM32F103定时器:用TIM2输入捕获精准测量脉冲宽度与频率 在嵌入式开发中,精确测量外部信号的脉冲宽度和频率是一项常见但极具挑战性的任务。无论是工业控制中的旋转编码器、消费电子中的红外遥控信号,还是无人机领域的PPM控制信号&#x…...

2026 年 AI 编程工具横评:Claude Code、Cursor、Copilot、Codex 谁才是真正的生产力?
爆款标题备选我把五个 AI 编程工具全装了一遍,只有一个让我想付费Claude Code vs Cursor vs Copilot:2026 开发者选型实战指南Copilot 的垄断结束了——2026 AI 编程工具真实横评花了一周用 AI 编程 Agent 写项目,最后留下了这一个AI 编程工具…...

Perplexity语言学习资源实战手册:7天掌握高效外语输入+输出闭环的3大核心技巧
更多请点击: https://intelliparadigm.com 第一章:Perplexity语言学习资源的核心定位与适用场景 Perplexity 作为一款以深度推理与实时信息整合见长的AI协作工具,其语言学习资源并非传统词典或语法教程的简单复刻,而是聚焦于**真…...
)
保姆级教程:用Python+OpenCV高效切割Potsdam语义分割数据集(附完整代码)
PythonOpenCV实战:Potsdam语义分割数据集高效切割全流程解析 第一次接触Potsdam数据集时,面对那些6000x6000像素的巨幅航拍图像,我的GPU在训练时直接报显存不足的错误。这让我意识到,高分辨率图像的切割预处理不是可选项…...

GIFT高级技巧:图像组合、并行处理和性能优化的终极指南
GIFT高级技巧:图像组合、并行处理和性能优化的终极指南 【免费下载链接】gift Go Image Filtering Toolkit 项目地址: https://gitcode.com/gh_mirrors/gi/gift GIFT(Go Image Filtering Toolkit)是一个强大的Go语言图像处理库&#x…...