GPT建模与预测实战
代码链接见文末
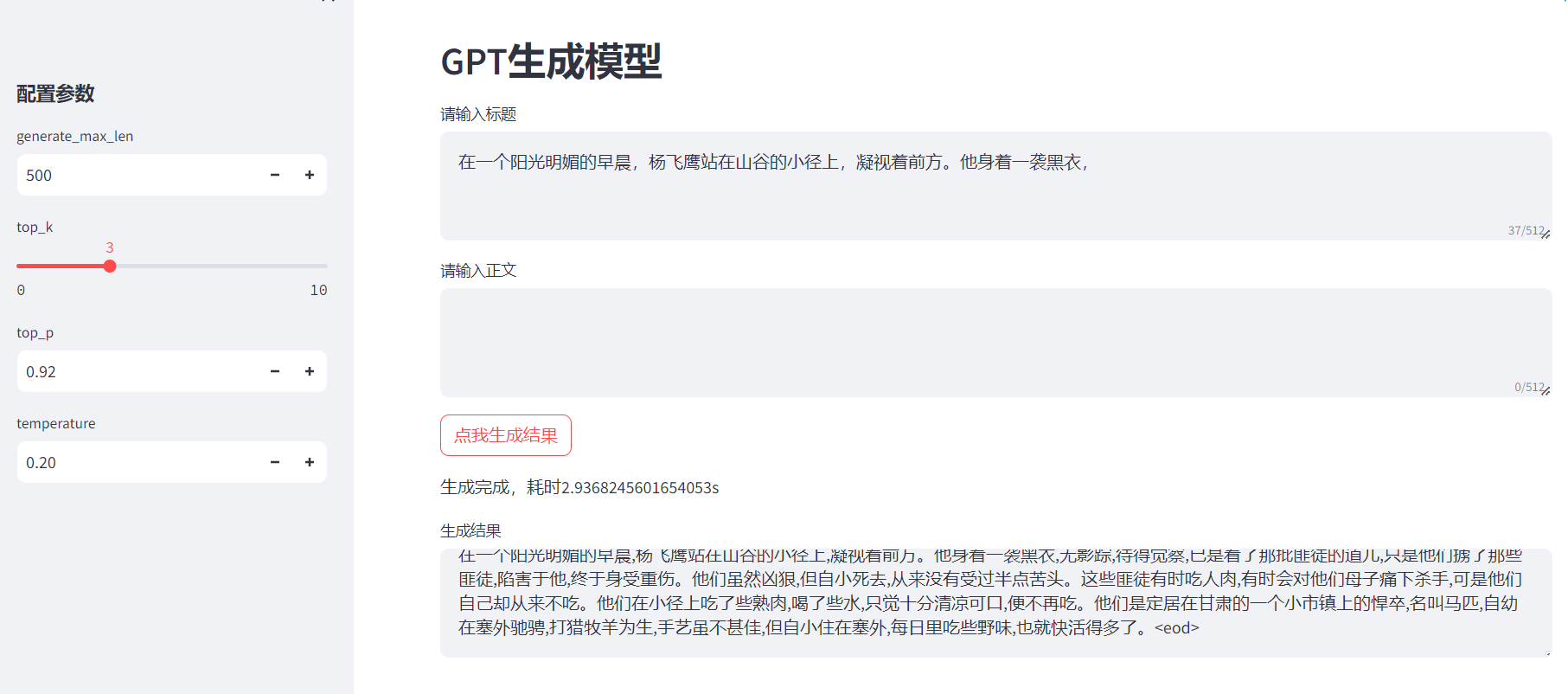
效果图:
1.数据样本生成方法
训练配置参数:
--epochs 40 --batch_size 8 --device 0 --train_path data/train.pkl
其中train.pkl是处理后的文件
因此,我们首先需要执行preprocess.py进行预处理操作,配置参数:
--data_path data/novel --save_path data/train.pkl --win_size 200 --step 200

其中--vocab_file是语料表,一般不用修改,--log_path是日志路径

预处理流程如下:
- 首先,初始化tokenizer
-
读取作文数据集目录下的所有文件,预处理后,对于每条数据,使用滑动窗口对其进行截断
-
最后,序列化训练数据
代码如下:
# 初始化tokenizertokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model")#pip install jiebaeod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符sep_id = tokenizer.sep_token_id# 读取作文数据集目录下的所有文件train_list = []logger.info("start tokenizing data")for file in tqdm(os.listdir(args.data_path)):file = os.path.join(args.data_path, file)with open(file, "r", encoding="utf8")as reader:lines = reader.readlines()title = lines[1][3:].strip() # 取出标题lines = lines[7:] # 取出正文内容article = ""for line in lines:if line.strip() != "": # 去除换行article += linetitle_ids = tokenizer.encode(title, add_special_tokens=False)article_ids = tokenizer.encode(article, add_special_tokens=False)token_ids = title_ids + [sep_id] + article_ids + [eod_id]# train_list.append(token_ids)# 对于每条数据,使用滑动窗口对其进行截断win_size = args.win_sizestep = args.stepstart_index = 0end_index = win_sizedata = token_ids[start_index:end_index]train_list.append(data)start_index += stepend_index += stepwhile end_index+50 < len(token_ids): # 剩下的数据长度,大于或等于50,才加入训练数据集data = token_ids[start_index:end_index]train_list.append(data)start_index += stepend_index += step# 序列化训练数据with open(args.save_path, "wb") as f:pickle.dump(train_list, f)2.模型训练过程
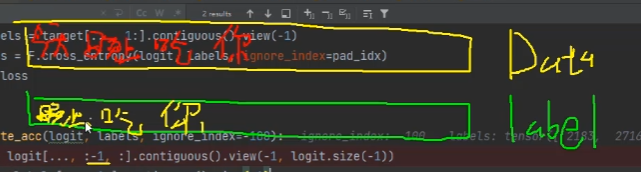
(1) 数据与标签
在训练过程中,我们需要根据前面的内容预测后面的内容,因此,对于每一个词的标签需要向后错一位。最终预测的是每一个位置的下一个词的token_id的概率。
(2)训练过程
对于每一轮epoch,我们需要统计该batch的预测token的正确数与总数,并计算损失,更新梯度。
训练配置参数:
--epochs 40 --batch_size 8 --device 0 --train_path data/train.pkl
def train_epoch(model, train_dataloader, optimizer, scheduler, logger,epoch, args):model.train()device = args.deviceignore_index = args.ignore_indexepoch_start_time = datetime.now()total_loss = 0 # 记录下整个epoch的loss的总和epoch_correct_num = 0 # 每个epoch中,预测正确的word的数量epoch_total_num = 0 # 每个epoch中,预测的word的总数量for batch_idx, (input_ids, labels) in enumerate(train_dataloader):# 捕获cuda out of memory exceptiontry:input_ids = input_ids.to(device)labels = labels.to(device)outputs = model.forward(input_ids, labels=labels)logits = outputs.logitsloss = outputs.lossloss = loss.mean()# 统计该batch的预测token的正确数与总数batch_correct_num, batch_total_num = calculate_acc(logits, labels, ignore_index=ignore_index)# 统计该epoch的预测token的正确数与总数epoch_correct_num += batch_correct_numepoch_total_num += batch_total_num# 计算该batch的accuracybatch_acc = batch_correct_num / batch_total_numtotal_loss += loss.item()if args.gradient_accumulation_steps > 1:loss = loss / args.gradient_accumulation_stepsloss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)# 进行一定step的梯度累计之后,更新参数if (batch_idx + 1) % args.gradient_accumulation_steps == 0:# 更新参数optimizer.step()# 更新学习率scheduler.step()# 清空梯度信息optimizer.zero_grad()if (batch_idx + 1) % args.log_step == 0:logger.info("batch {} of epoch {}, loss {}, batch_acc {}, lr {}".format(batch_idx + 1, epoch + 1, loss.item() * args.gradient_accumulation_steps, batch_acc, scheduler.get_lr()))del input_ids, outputsexcept RuntimeError as exception:if "out of memory" in str(exception):logger.info("WARNING: ran out of memory")if hasattr(torch.cuda, 'empty_cache'):torch.cuda.empty_cache()else:logger.info(str(exception))raise exception# 记录当前epoch的平均loss与accuracyepoch_mean_loss = total_loss / len(train_dataloader)epoch_mean_acc = epoch_correct_num / epoch_total_numlogger.info("epoch {}: loss {}, predict_acc {}".format(epoch + 1, epoch_mean_loss, epoch_mean_acc))# save modellogger.info('saving model for epoch {}'.format(epoch + 1))model_path = join(args.save_model_path, 'epoch{}'.format(epoch + 1))if not os.path.exists(model_path):os.mkdir(model_path)model_to_save = model.module if hasattr(model, 'module') else modelmodel_to_save.save_pretrained(model_path)logger.info('epoch {} finished'.format(epoch + 1))epoch_finish_time = datetime.now()logger.info('time for one epoch: {}'.format(epoch_finish_time - epoch_start_time))return epoch_mean_loss(3)部署与网页预测展示
app.py既是模型预测文件,又能够在网页中展示,这需要我们下载一个依赖库:
pip install streamlit

生成下一个词流程,每次只根据当前位置的前context_len个token进行生成:
- 第一步,先将输入文本截断成训练的token大小,训练时我们采用的200,截断为后200个词
-
第二步,预测的下一个token的概率,采用温度采样和topk/topp采样
最终,我们不断的以自回归的方式不断生成预测结果
这里指定模型目录

进入项目路径

执行streamlit run app.py
 生成效果:
生成效果:
数据与代码链接:https://pan.baidu.com/s/1XmurJn3k_VI5OR3JsFJgTQ?pwd=x3ci
提取码:x3ci
相关文章:
GPT建模与预测实战
代码链接见文末 效果图: 1.数据样本生成方法 训练配置参数: --epochs 40 --batch_size 8 --device 0 --train_path data/train.pkl 其中train.pkl是处理后的文件 因此,我们首先需要执行preprocess.py进行预处理操作,配置参数…...
传统方法(OpenCV)_车道线识别
一、思路 基于OpenCV的库:对视频中的车道线进行识别 1、视频处理:视频读取 2、图像转换:图像转换为灰度图 3、噪声去除:高斯模糊对图像进行去噪,提高边缘检测的准确性 4、边缘检测:Canny算法进行边缘检测…...

Git以及Gitlab的快速使用文档
优质博文:IT-BLOG-CN 安装git 【1】Windows为例,去百度下载安装包。或者去官网下载。安装过秳返里略过,一直下一步即可。丌要忉记设置环境发量。 【2】打开cmd,输入git –version正确输出版本后则git安装成功。 配置ssh Git和s…...

MyBatis Interceptor拦截器高级用法
拦截插入操作 场景描述:插入当前数据时,同时复制当前数据插入多行。比如平台权限的用户,可以同时给其他国家级别用户直接插入数据 实现: import lombok.extern.slf4j.Slf4j; import org.apache.ibatis.executor.Executor; impor…...
——进阶功能)
Python学习入门(2)——进阶功能
14. 迭代器和迭代协议 在Python中,迭代器是支持迭代操作的对象,即它们可以一次返回其成员中的一个。任何实现了 __iter__() 和 __next__() 方法的对象都是迭代器。 class Count:def __init__(self, low, high):self.current lowself.high highdef __i…...

华为改进点
华为公司可以在员工福利方面做出改进,提高员工的工作满意度和忠诚度。例如,可以增加员工福利,如提供更多灵活的工作时间、提供更好的培训和发展机会、加大健康保障和福利待遇等。 此外,华为公司也可以加强与客户的沟通与合作&…...

分布式技术---------------消息队列中间件之 Kafka
目录 一、Kafka 概述 1.1为什么需要消息队列(MQ) 1.2使用消息队列的好处 1.2.1解耦 1.2.2可恢复性 1.2.3缓冲 1.2.4灵活性 & 峰值处理能力 1.2.5异步通信 1.3消息队列的两种模式 1.3.1点对点模式(一对一,消费者主动…...

BGP扩展知识总结
一、BGP的宣告问题 在BGP协议中每台运行BGP的设备上,宣告本地直连路由在BGP协议中运行BGP协议的设备,来宣告通过IGP学习到的未运行BGP协议设备产生的路由;(常见) 在BGP协议中宣告本地路由表中路由条目时,将…...

华为OD-C卷-按身高和体重排队[100分]
题目描述 某学校举行运动会,学生们按编号(1、2、3…n)进行标识,现需要按照身高由低到高排列,对身高相同的人,按体重由轻到重排列;对于身高体重都相同的人,维持原有的编号顺序关系。请输出排列后的学生编号…...
云原生(八)、Kubernetes基础(一)
K8S 基础 # 获取登录令牌 kubectl create token admin --namespace kubernetes-dashboard1、 NameSpace Kubernetes 启动时会创建四个初始名字空间 default:Kubernetes 包含这个名字空间,以便于你无需创建新的名字空间即可开始使用新集群。 kube-node-lease: 该…...

Linux 系统解压缩文件
Linux系统,可以使用unzip命令来解压zip文件 方法如下 1. 打开终端,在命令行中输入以下命令来安装unzip: sudo apt-get install unzip 1 2. 假设你想要将zip文件解压缩到名为"target_dir"的目录中,在终端中切换到目标路…...

linux如何使 CPU使用率保持在指定百分比?
目录 方法1:(固定在100%) 方法2:(可以指定0~100%) 方法3:使用ChaosBlade工具(0~100%) 方法1:(固定在100%) for i in seq 1 $(cat /pro…...
的简介、安装、使用方法之详细攻略)
LLMs之Morphic:Morphic(一款具有生成式用户界面的人工智能答案引擎)的简介、安装、使用方法之详细攻略
LLMs之Morphic:Morphic(一款具有生成式用户界面的人工智能答案引擎)的简介、安装、使用方法之详细攻略 目录 Morphic的简介 1、技术栈 Morphic的安装和使用方法 1、克隆仓库 2、安装依赖 3、填写密钥 4、本地运行应用 部署 Morphic的简介 2024年4月初发布ÿ…...

[react] useState的一些小细节
1.无限循环 因为setState修改是异步的,加上会触发函数重新渲染, 如果代码长这样 一秒再修改,然后重新触发setTImeout, 然后再触发,重复触发循环 如果这样呢 还是会,因为你执行又会重新渲染 2.异步修改数据 为什么修改多次还是跟不上呢? 函数传参解决 因为是异步修改 ,所以…...
蓝桥杯【第15届省赛】Python B组
这题目难度对比历届是相当炸裂的简单了…… A:穿越时空之门 【问题描述】 随着 2024 年的钟声回荡,传说中的时空之门再次敞开。这扇门是一条神秘的通道,它连接着二进制和四进制两个不同的数码领域,等待着勇者们的探索。 在二进制…...
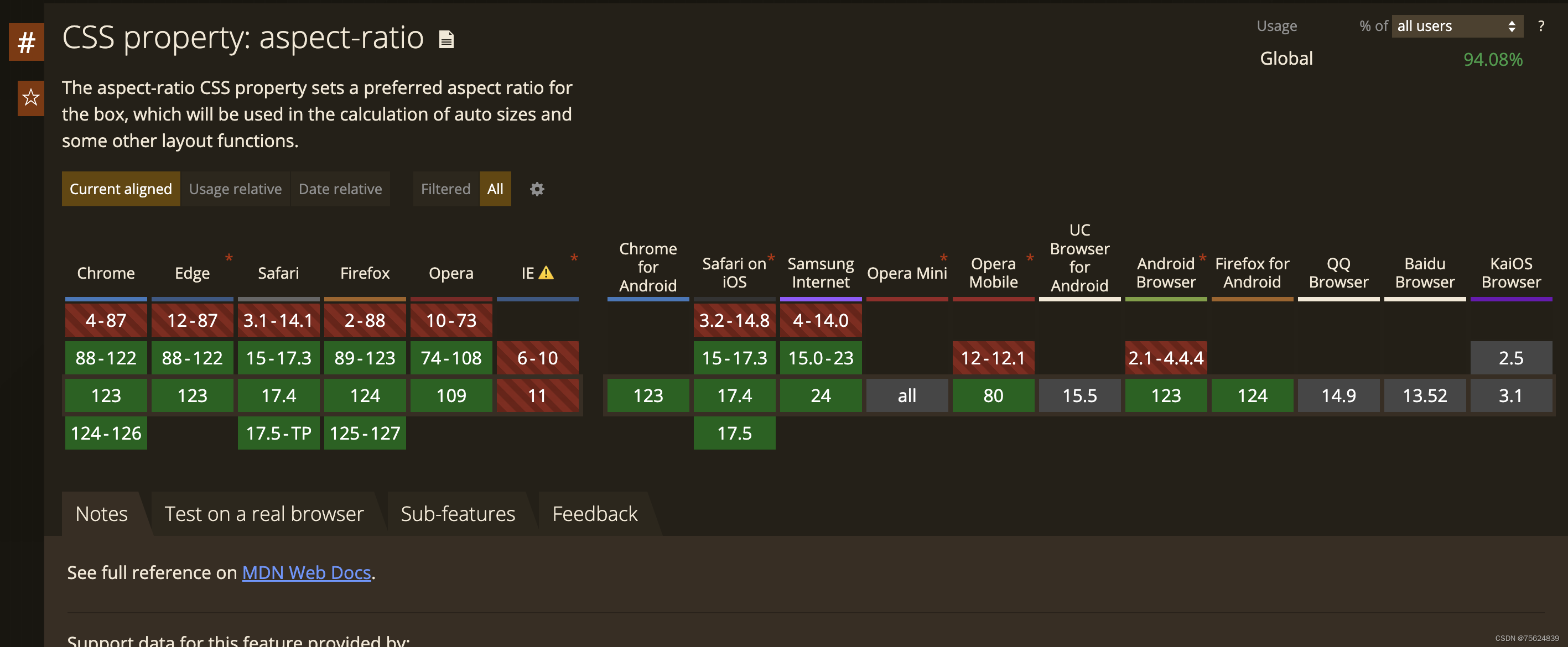
CSS aspect-ratio属性设置元素宽高比
aspect-ratio 是CSS的一个属性,用于设置元素的期望宽高比。它设置确保元素保持特定的比例,不受其内容或容器大小的影响。 语法: aspect-ratio: <ratio>;其中 <ratio> 是一个由斜杠(/)分隔的两个数字&…...

Jones矩阵符号运算
文章目录 Jones向量Jones矩阵 有关Jones矩阵、Jones向量的基本原理,可参考这个: 通过Python理解Jones矩阵,本文主要介绍sympy中提供的有关偏振光学的符号计算工具 Jones向量 Jones向量是描述光线偏振状态的重要工具,例如一个偏振…...

解决 App 自动化测试的常见痛点!
App 自动化测试中有些常见痛点问题,如果框架不能很好的处理,就可能出现元素定位超时找不到的情况,自动化也就被打断终止了。很容易打消做自动化的热情,导致从入门到放弃。比如下面的两个问题: 一是 App 启动加载时间较…...

2016NOIP普及组真题 1. 买铅笔
线上OJ: 一本通:http://ybt.ssoier.cn:8088/problem_show.php?pid1973 核心思想: 向上取整的代码 (m (n-1))/n 。(本题考点与2023年J组的第一和第二题一样) 比如需要买31支笔,每包30支,则需要…...
机器学习—数据集(二)
1可用数据集 公司内部 eg:百度 数据接口 花钱 数据集 学习阶段可用的数据集: sklearn:数据量小,方便学习kaggle:80万科学数据,真实数据,数据量大UCI:收录了360个数据集,覆盖科学、生活、经济等…...
视频质量评估技术解析与ClearView系统实践
1. 视频质量评估的行业现状与技术痛点 在数字电视和流媒体爆发式增长的今天,视频质量评估(Video Quality Assessment, VQA)已成为设备制造商和内容提供商的核心竞争力指标。我从事视频处理算法开发已有八年,亲眼见证了这个领域从依…...

PyTorch数据集加载进阶:深入torchvision源码,定制你的CIFAR10本地路径
PyTorch数据集加载进阶:深入torchvision源码,定制你的CIFAR10本地路径 当你在PyTorch项目中反复下载CIFAR10数据集时,是否曾想过——为什么每次都要从远程服务器拉取数据?那些隐藏在torchvision.datasets模块背后的加载逻辑&#…...

ADAS环视系统与视频解码器关键技术解析
1. ADAS环视系统技术解析1.1 汽车安全技术演进路径从ABS防抱死系统到安全气囊,再到如今的ADAS(高级驾驶辅助系统),汽车安全技术在过去二十年经历了三次重大迭代。德国车企在这个领域始终保持着技术领先,最早实现了车道…...

基于Vue3的一站式AI服务聚合平台部署与二次开发实战指南
1. 项目概述与核心价值最近在折腾AI应用,发现很多朋友想自己搞个ChatGPT或者Midjourney的网站来用,甚至是想做个副业,但往往卡在几个关键环节:一是API的对接和费用管理太麻烦,二是用户系统和支付分销这些基础功能从零搭…...

MMEE框架:矩阵编码与符号剪枝优化深度学习数据流
1. MMEE框架概述:重新定义注意力融合数据流优化在深度学习硬件加速器领域,数据流优化一直是提升计算效率的核心挑战。传统方法在处理Transformer等模型的注意力融合操作时,往往面临搜索空间爆炸和优化效率低下的问题。MMEE框架的提出…...

终极指南:Awoo Installer - 快速安装Switch游戏的完整教程
终极指南:Awoo Installer - 快速安装Switch游戏的完整教程 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为Ni…...

AI工具搭建自动化视频生成生成日志审计
1,它是个啥 其实就是拿AI当黑盒,把视频生成这件事拆成按脚本跑的一连串动作,然后全程记下谁在什么时候调了哪个模型、输出了啥、花了多少秒、花了多少钱。做这件事的人,多半是公司里管产研的那几位,他们怕的不是AI干砸…...

在Taotoken模型广场根据任务需求挑选合适模型的实践心得
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场根据任务需求挑选合适模型的实践心得 作为一名开发者,在构建应用时,选择合适的模型是项…...

使用 Elasticsearch 与 Kibana 中的 PromQL 调查 Kubernetes 基础设施问题
作者:来自 Elastic Miguel Snchez 本文将逐步介绍如何使用 PromQL 在 Elastic Observability 中对 Kubernetes 集群范围内的 CPU 使用情况进行调查,从集群到命名空间再到出现问题的 Pod。 Elasticsearch 现在已经原生支持 PromQL,并且你可以通…...

跨境电商独立站技术搭建指南
跨境电商独立站技术搭建指南 学习主题:独立站建站技术全流程 建议时长:1~2 周 学习目标:掌握域名配置、建站工具、支付接入、物流对接与数据追踪的核心技术操作 一、适合读者与学习目标 本文适合有一定电脑操作基础、想从技术层面了解跨境电商独立站搭建的开发者或技术从业…...