机器学习—数据集(二)
1可用数据集
公司内部 eg:百度
数据接口 花钱
数据集
学习阶段可用的数据集:
- sklearn:数据量小,方便学习
- kaggle:80万科学数据,真实数据,数据量大
- UCI:收录了360个数据集,覆盖科学、生活、经济等领域,数据量几十万
Kaggle网址:http://www.kaggle.com/datasets
UCI网址:http://archive.ics.uci.edu/ml/
scikit-learn网址:http://scikit-learn.org/stable/datasets/index.html
2scikit-learn工具介绍

- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API
- 目前稳定版本0.19.1
2.1安装
pip3 install Scikit-learn==0.19.1
安装好之后可以通过以下命令查看是否安装成功
import sklearn
注:安装scikit-learn需要Numpy,Scipy等库
2.2sklearn数据集
scikit-learn数据集API介绍:
- sklearn.datasets
- 加载获取流行数据集
- datasets.load_*()
- 获取小规模数据集,数据包含在datasets里 - datasets.fetch_*(data_home=None)
- 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是~/scikit_learn_data/
sklearn小数据集:
- sklearn.datasets.load_iris()
-加载并返回鸢尾花数据集
| 名称 | 数量 |
|---|---|
| 类别 | 3 |
| 特征 | 4 |
| 样本数量 | 150 |
| 每个类别数量 | 50 |
- sklearn.datasets.load_boston()
-加载并返回波士顿房价数据集
| 名称 | 数量 |
|---|---|
| 目标类别 | 5-50 |
| 特征 | 13 |
| 样本数量 | 506 |
sklearn大数据集:
- sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
- subset: "train’或者’test’,"all’,可选,选择要加载的数据集。
- 训练集的“训练”,测试集的“测试”,两者的“全部”
sklearn数据集的使用:
- 以鸢尾花数据集为例:

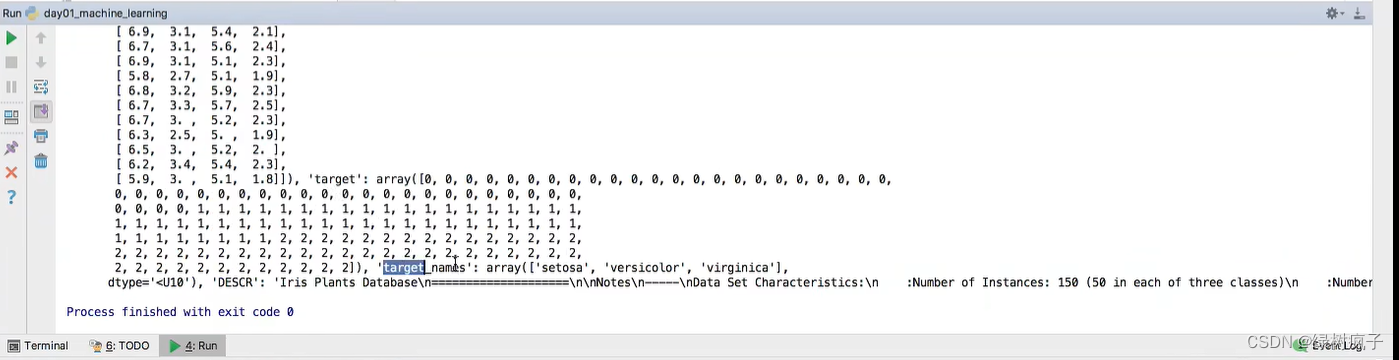
sklearn数据集返回值介绍: - load和fetch返回的数据类型datasets.base.Bunch(字典格式)
- data:特征数据数组,是[n_samples * n_features]的二维numpy.ndarray数组
- target:标签数组,是n_samples的一维numpy.ndarray数组
- DESCR:数据描述
- feature_names:特征名,新闻数据,手写数字、回归数据集没有
- otarget_names:标签名
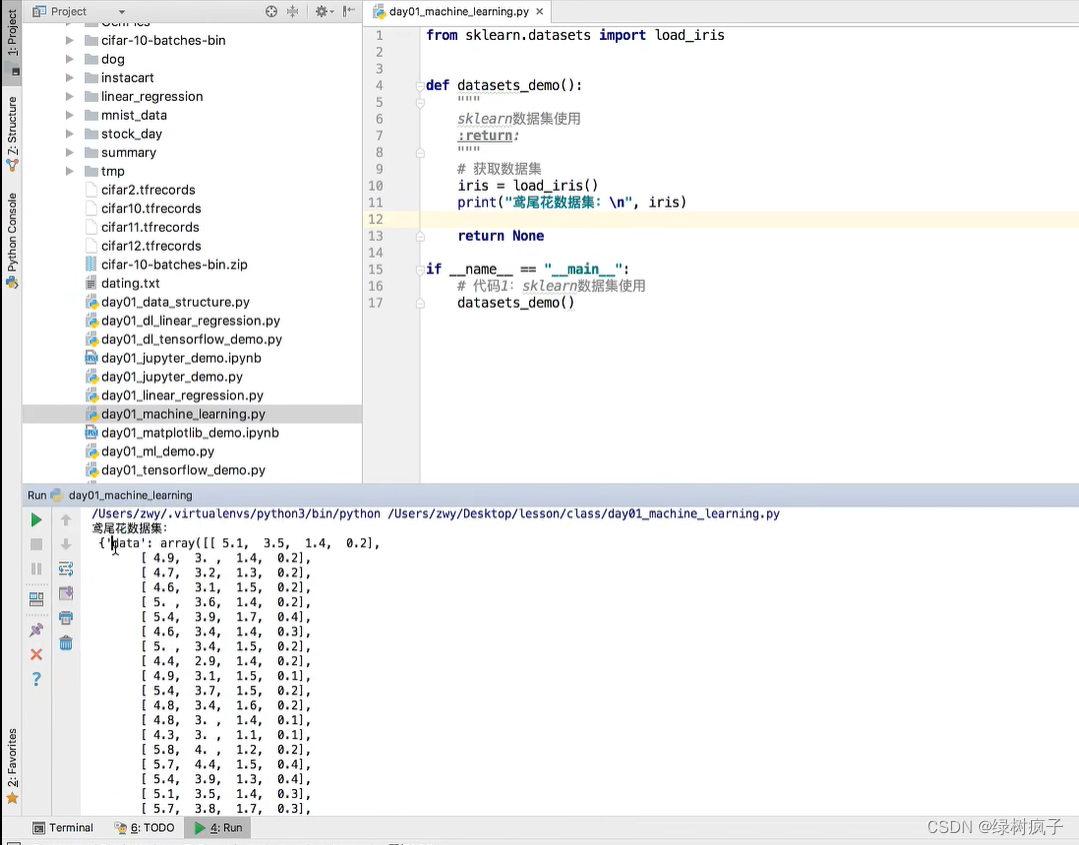
from sklearn.datasets import load_iris
#获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
#返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n", iris ["data""])
print("鸢尾花的目标值:\n",iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字: \n",iris.target_names)
print("鸢尾花的描述:\in", iris.DESCR)
2.3数据集的划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
训练集:70% 80% 75%
测试集:30% 20% 30%
数据集划分api:
- sklearn.model_selection.train_test_split(arrays, "options)
- ×数据集的特征值
- y数据集的标签值
- test_size测试集的大小,一般为float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return 训练集特征值,测试集特征值,训练集目标值,测试集目标值
x_train,x_test, y_train,y_test
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split#数据集划分
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=22)
print("训练集的特征值:\n", x_train,x_train.shape)
相关文章:
机器学习—数据集(二)
1可用数据集 公司内部 eg:百度 数据接口 花钱 数据集 学习阶段可用的数据集: sklearn:数据量小,方便学习kaggle:80万科学数据,真实数据,数据量大UCI:收录了360个数据集,覆盖科学、生活、经济等…...

华为S5735S核心交换配置实例
以下脚本实现创建vlan2,3,IP划分,DHCP启用,接口划分,ssh,telnet,http,远程登录启用 默认用户创建admin/admin123提示首次登录需要更改用户密码S5735产品手册更多功能配置,移步官网参考手册配置 system-viewsysname t…...

Mysql主从复制安装配置
mysql主从复制安装配置 1、基础设置准备 #操作系统: centos6.5 #mysql版本: 5.7 #两台虚拟机: node1:192.168.85.111(主) node2:192.168.85.112(从)2、安装mysql数据库 #详细安装和卸载的步骤…...

【刷题】图论——最小生成树:Prim、Kruskal【模板】
假设有n个点m条边。 Prim适用于邻接矩阵存的稠密图,时间复杂度是 O ( n 2 ) O(n^2) O(n2),可用堆优化成 O ( n l o g n ) O(nlogn) O(nlogn)。 Kruskal适用于稀疏图,n个点m条边,时间复杂度是 m l o g ( m ) mlog(m) mlog(m)。 Pr…...

使用uniapp实现小程序获取wifi并连接
Wi-Fi功能模块 App平台由 uni ext api 实现,需下载插件:uni-WiFi 链接:https://ext.dcloud.net.cn/plugin?id10337 uni ext api 需 HBuilderX 3.6.8 iOS平台获取Wi-Fi信息需要开启“Access WiFi information”能力登录苹果开发者网站&…...
回忆杀之手搓当年搓过的Transformer
整体代码 import mathimport paddle import paddle.nn as nn import paddle.nn.functional as Fclass MaskMultiHeadAttention(nn.Layer):def __init__(self, hidden_size, num_heads):super(MaskMultiHeadAttention, self).__init__()assert hidden_size % num_heads 0, &qu…...

【AR】使用深度API实现虚实遮挡
遮挡效果 本段描述摘自 https://developers.google.cn/ar/develop/depth 遮挡是深度API的应用之一。 遮挡(即准确渲染虚拟物体在现实物体后面)对于沉浸式 AR 体验至关重要。 参考下图,假设场景中有一个Andy,用户可能需要放置在包含…...

python-pytorch实现skip-gram 0.5.001
python-pytorch实现skip-gram 0.5.000 数据加载、切词准备训练数据准备模型和参数训练保存模型加载模型简单预测获取词向量画一个词向量的分布图使用词向量计算相似度参考数据加载、切词 按照链接https://blog.csdn.net/m0_60688978/article/details/137538274操作后,可以获得…...

C语言:约瑟夫环问题详解
前言 哈喽,宝子们!本期为大家带来一道C语言循环链表的经典算法题(约瑟夫环)。 目录 1.什么是约瑟夫环2.解决方案思路3.创建链表头结点4.创建循环链表5.删除链表6.完整代码实现 1.什么是约瑟夫环 据说著名历史学家Josephus有过以下…...
【刷题篇】回溯算法(二)
文章目录 1、求根节点到叶节点数字之和2、二叉树剪枝3、验证二叉搜索树4、二叉搜索树中第K小的元素5、二叉树的所有路径 1、求根节点到叶节点数字之和 给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。 每条从根节点到叶节点的路径都代表…...
Windows系统本地部署Jupyter Notebook并实现公网访问编辑笔记
文章目录 1.前言2.Jupyter Notebook的安装2.1 Jupyter Notebook下载安装2.2 Jupyter Notebook的配置2.3 Cpolar下载安装 3.Cpolar端口设置3.1 Cpolar云端设置3.2.Cpolar本地设置 4.公网访问测试5.结语 1.前言 在数据分析工作中,使用最多的无疑就是各种函数、图表、…...
Ansible 实战Shell 插件和模块工具)
自动化运维(二十七)Ansible 实战Shell 插件和模块工具
Ansible 支持多种类型的插件,这些插件可以帮助你扩展和定制 Ansible 的功能。每种插件类型都有其特定的用途和应用场景。今天我们一起学习Shell 插件和模块工具。 一、 Shell 插件 Ansible shell 插件决定了 Ansible 如何在远程系统上执行命令。这些插件非常关键&a…...

Jenkins使用-绑定域控与用户授权
一、Jenkins安装完成后,企业中使用,首先需要绑定域控以方便管理。 操作方法: 1、备份配置文件,防止域控绑定错误或授权策略选择不对,造成没办法登录,或登录后没有权限操作。 [roottest jenkins]# mkdir ba…...
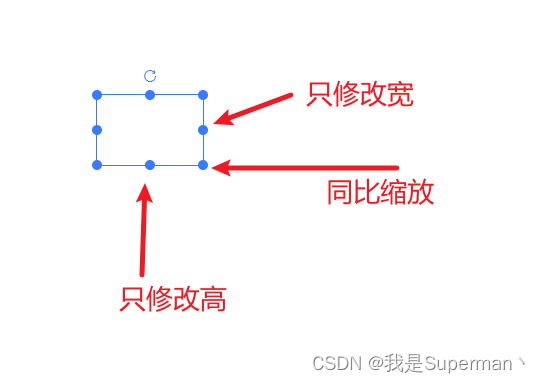
【前端】es-drager 图片同比缩放 缩放比 只修改宽 只修改高
【前端】es-drager 图片同比缩放 缩放比 ES Drager 拖拽组件 (vangleer.github.io) 核心代码 //初始宽 let width ref(108)//初始高 let height ref(72)//以下两个变量 用来区分是单独的修改宽 还是高 或者是同比 //缩放开始时的宽 let oldWidth 0 //缩放开始时的高 let o…...

蓝桥杯第十四届蓝桥杯大赛软件赛省赛C/C++ 大学 A 组题解
1.幸运数 题目链接:0幸运数 - 蓝桥云课 (lanqiao.cn) #include<bits/stdc.h> using namespace std; bool deng(string& num){int n num.size();int qian 0,hou 0;for(int i0;i<n/2;i) qian (num[i]-0);for(int in/2;i<n;i) hou (num[i]-0);r…...
eclipse .project
.project <?xml version"1.0" encoding"UTF-8"?> <projectDescription> <name>scrm-web</name> <comment></comment> <projects> </projects> <buildSpec> <buil…...

react的闭包陷阱
React 的闭包陷阱是指在使用 React Hooks 时,由于闭包特性导致在某些函数或异步操作中无法正确访问到更新后状态或 prop 的值,而仍旧使用了旧值。下面通过几个代码示例来具体说明闭包陷阱的几种常见情形: 示例 1: useState 闭包陷阱 import…...

神经网络解决回归问题(更新ing)
神经网络应用于回归问题 优势是什么???生成数据集:通用神经网络拟合函数调整不同参数对比结果初始代码结果调整神经网络结构调整激活函数调整迭代次数增加早停法变量归一化处理正则化系数调整学习率调整 总结ingfnn.py进行计算&am…...

【小红书校招场景题】12306抢票系统
1 坐过高铁吧,有抢过票吗。你说说抢票系统对于后端开发人员而言会有哪些情况? 对于后端开发人员来说,开发和维护一个高铁抢票系统(如中国的12306)会面临一系列的挑战和情况。这些挑战主要涉及系统的性能、稳定性、数据…...
)
Spring(三)
1. Spring单例Bean是不是线程安全的? Spring单例Bean默认并不是线程安全的。由于多个线程可能访问同一份Bean实例,当Bean的内部包含了可变状态(mutable state)即有可修改的成员变量时,就可能出现线程安全问题。Spring容器不会自动…...

ATE PCB组装:半导体测试中的精密工艺与挑战解析
1. ATE PCB组装:半导体测试的基石与挑战 在半导体行业,一颗芯片从设计到最终封装出厂,其性能与可靠性的验证是决定产品成败的最后一环。随着芯片工艺节点不断微缩,集成度呈指数级增长,对测试环节的要求也达到了前所未有…...

企业如何通过Taotoken实现API密钥的统一管理与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业如何通过Taotoken实现API密钥的统一管理与审计 在将大模型能力集成到企业业务流程的过程中,一个常见的挑战是如何安…...

Curxy:轻量级P2P内网穿透工具的原理与实战部署指南
1. 项目概述与核心价值最近在折腾一些跨平台的文件同步和远程访问需求时,发现了一个挺有意思的项目:ryoppippi/curxy。乍一看这个名字,你可能和我最初一样有点摸不着头脑,它既不像一个常见的工具名,也不像某个知名软件…...

可配置处理器技术:嵌入式SOC设计的灵活加速方案
1. 可配置处理器技术概述在嵌入式系统芯片(SOC)设计领域,算法实现方式的选择一直是个关键决策点。传统上,开发者面临两种主要选择:要么将算法编译成通用处理器(如RISC或DSP)可执行的软件,要么将其直接实现为专用硬件电路(ASIC)。前…...
)
SITS 2026发布12项技术白皮书+7套开源工具链:附CSDN认证工程师亲测部署清单(含GitHub直达链接)
更多请点击: https://intelliparadigm.com 第一章:CSDN主办SITS 2026:2026奇点智能技术大会亮点全解析 SITS 2026(Singularity Intelligence Technology Summit)由CSDN联合中国人工智能学会、中科院自动化所共同主办&…...

企业/学校如何自建在线“慕课“教学平台?Moodle 开源 LMS 初识与部署全攻略
[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ] 0x00 前言简述 背景说明 出于内部学习平台搭建需要,领导吩咐我去探究部署一些开源学习平台,要求支持Office协同文档、学习课程发布、学习记录反馈和支持 OAuth2 客户端以对…...

第十四节:Project Glasswing 落地——构建本地 Agent 的双向审查防火墙
引言 承接上一章对大模型 Prompt 注入与越狱攻击的防御,本章将深入探讨 Project Glasswing 的安全治理理念,重点解决本地 Agent 在输入与输出两个环节的安全审查,构建企业级的双向审查防火墙。 核心理论 Project Glasswing 旨在打造一个“看门狗”机制,利用 AI 模型和规…...

【SITS大会技术社区交流活动深度复盘】:20年一线专家亲述3大未公开的破圈协作模型与落地工具包
更多请点击: https://intelliparadigm.com 第一章:【SITS大会技术社区交流活动深度复盘】:20年一线专家亲述3大未公开的破圈协作模型与落地工具包 模型一:异构角色动态配对机制 传统技术沙龙常陷入“讲师单向输出、听众被动接收…...

GitHubCopilot与Gemini3.1Pro协同开发实战
在 2026 年,AI 编程工具的差异已经从“谁能写代码”转向“谁能把代码写对、写稳、写得可维护”。很多团队开始采用“双引擎协作”:GitHub Copilot 负责快速生成与代码补全,而 Gemini 3.1 Pro 负责更强的推理、架构级建议、测试策略与长上下文…...

3步掌握Hitboxer:解决游戏按键冲突的终极指南
3步掌握Hitboxer:解决游戏按键冲突的终极指南 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键导致角色原地不动而错失良机?或…...