GFS部署实验
目录
1、部署环境
编辑
2、更改节点名称
3、准备环境
4、磁盘分区,并挂载
5. 做主机映射--/etc/hosts/
6. 复制脚本文件
7. 执行脚本完成分区
8. 安装客户端软件
1. 安装解压源包
2. 创建gfs
3. 安装 gfs
4. 开启服务
9、 添加节点到存储信任池中
10、创建卷
1. 规划创建卷
2.创建分布式卷
3.创建条带卷
4. 创建复制卷
5.创建分布式条带卷
6.创建分布式复制卷
7.查看卷列表
11、部署客户端--7-1
1.复制文件并解压
2. 建立元数据
3.安装
4.创建挂载目录
5. 给客户端做主机名映射
6.挂载Gluster文件系统
12、测试Gluster文件系统
1.在5个卷中写入文件
13、查看文件分布
1. 查看分布式文件分布
2.查看条带卷文件分布
3.查看复制卷分布
4.查看分布式条带卷分布
5.查看分布式复制卷分布
14.破坏性测试
1.挂起node2
15.客户端查看破坏结果
1.查看分布式数据
2.查看条带卷数据
3.查看复制卷数据
4.查看分布式条带卷数据
5.查看分布式复制卷数据
16、总结
1.查看GlusterFS卷
2.查看所有卷的信息
3.查看所有卷的状态
4.停止一个卷
5.删除一个卷,注意:删除卷时,需要先停止卷,且信任池中不能有主机处于宕机状态,否则删除不成功
6.设置卷的访问控制
1、部署环境
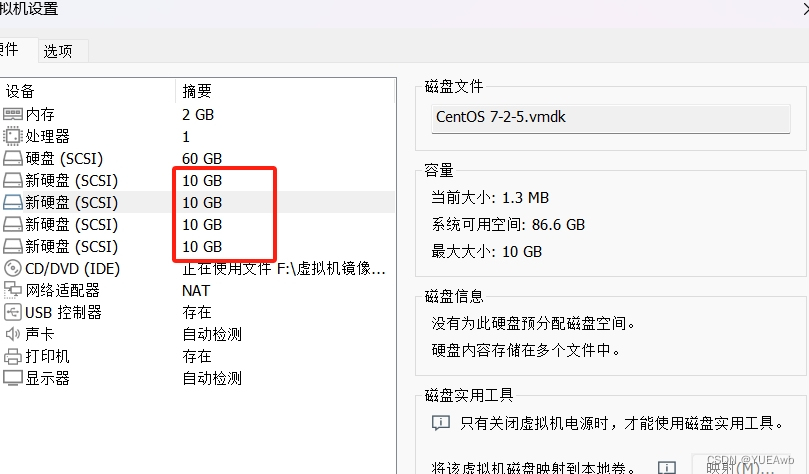
Node1节点:node1/192.168.91.102 磁盘: /dev/sdb1 挂载点: /data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1Node2节点:node2/192.168.91.103 磁盘: /dev/sdb1 挂载点: /data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1Node3节点:node3/192.168.91.104 磁盘: /dev/sdb1 挂载点: /data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1Node4节点:node4/192.168.91.105 磁盘: /dev/sdb1 挂载点: /data/sdb1/dev/sdc1 /data/sdc1/dev/sdd1 /data/sdd1/dev/sde1 /data/sde1=====客户端节点:192.168.91.100=====给四个服务器,每台添加4块硬盘
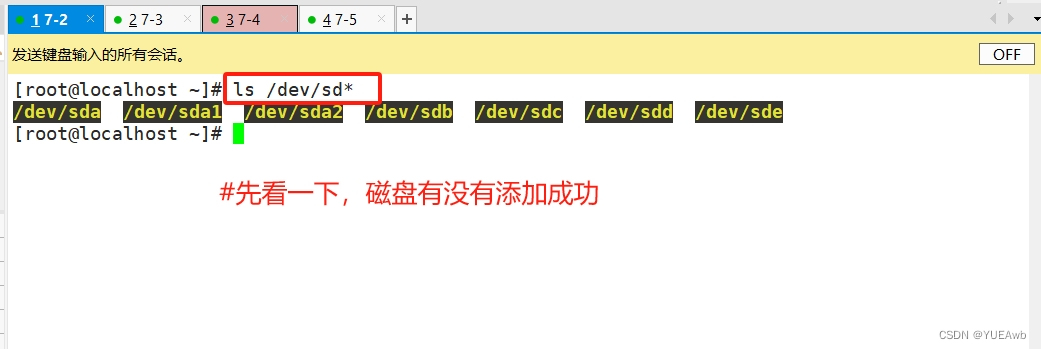
[root@localhost ~]# ls /dev/sd*
2、更改节点名称
node1(192.168.91.102)
[root@localhost ~] # hostnamectl set-hostname node1
[root@localhost ~] # bashnode2(192.168.91.103)
[root@localhost ~] # hostnamectl set-hostname node2
[root@localhost ~] # bashnode3(192.168.91.104)
[root@localhost ~] # hostnamectl set-hostname node3
[root@localhost ~] # bashnode4(192.168.91.105)
[root@localhost ~] # hostnamectl set-hostname node4
[root@localhost ~] # bash3、准备环境
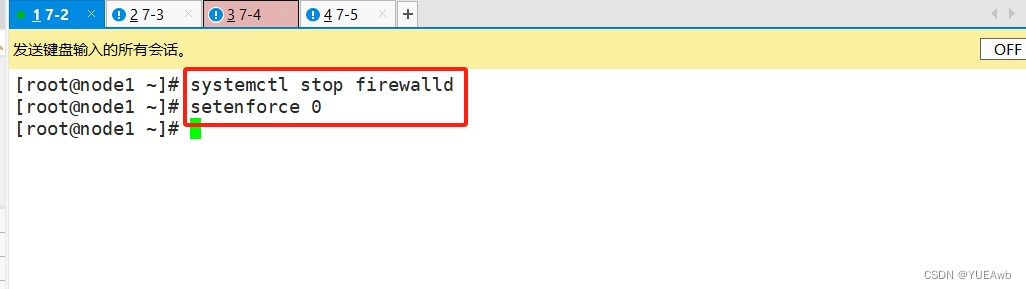
关闭防火墙和selinux
[root@node1 ~]# systemctl stop firewalld
[root@node1 ~]# setenforce 0
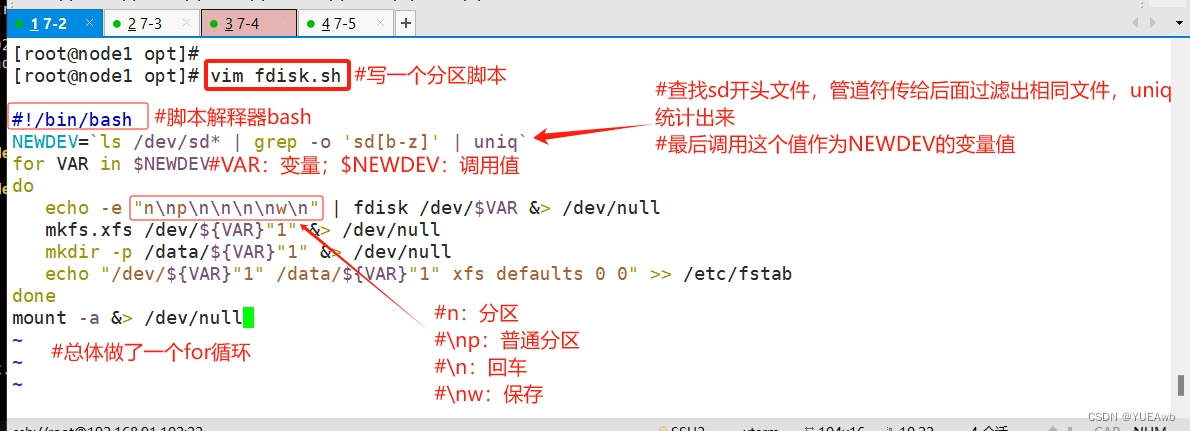
4、磁盘分区,并挂载
vim /opt/fdisk.sh
#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
for VAR in $NEWDEV
doecho -e "n\np\n\n\n\nw\n" | fdisk /dev/$VAR &> /dev/nullmkfs.xfs /dev/${VAR}"1" &> /dev/nullmkdir -p /data/${VAR}"1" &> /dev/nullecho "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
done
mount -a &> /dev/null
chmod +x /opt/fdisk.sh
5. 做主机映射--/etc/hosts/
echo "192.168.91.102 node1" >> /etc/hosts
echo "192.168.91.103 node2" >> /etc/hosts
echo "192.168.91.104 node3" >> /etc/hosts
echo "192.168.91.105 node4" >> /etc/hosts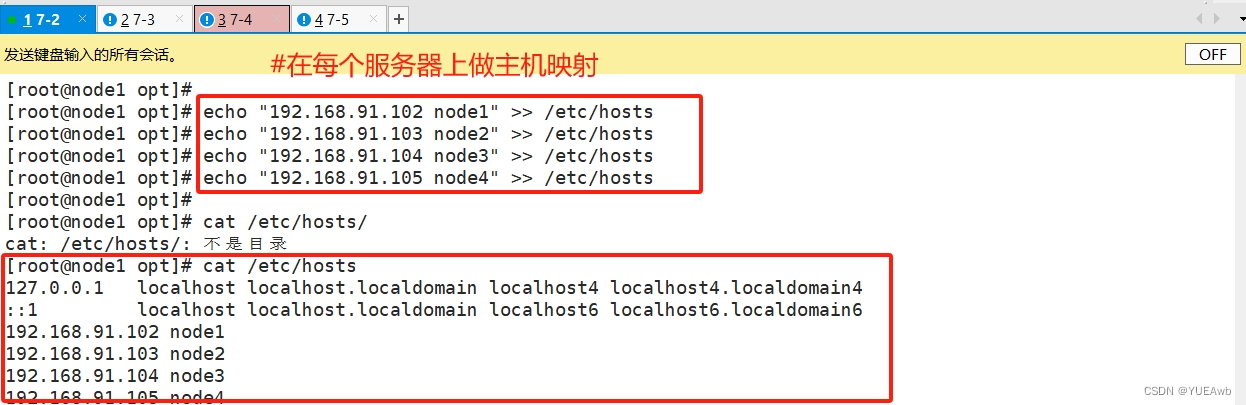
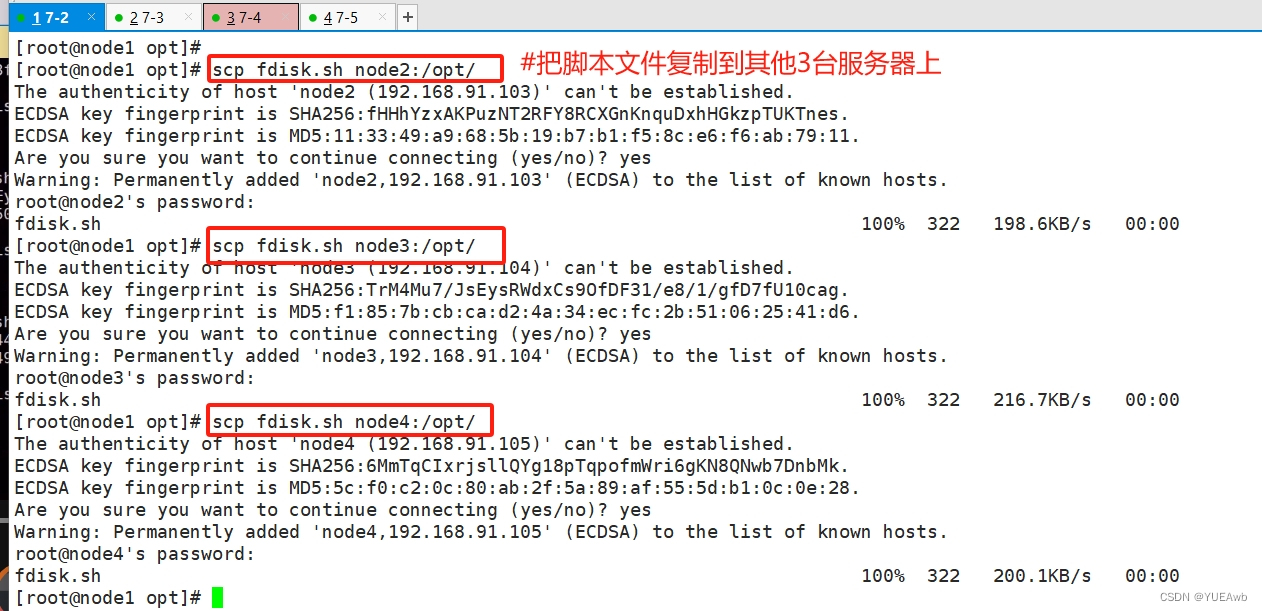
6. 复制脚本文件
[root@node1 opt]# scp fdisk.sh node2:/opt/
[root@node1 opt]# scp fdisk.sh node3:/opt/
[root@node1 opt]# scp fdisk.sh node4:/opt/
7. 执行脚本完成分区

8. 安装客户端软件
一定要先解压源包,才能成功创建gfs
1. 安装解压源包

2. 创建gfs
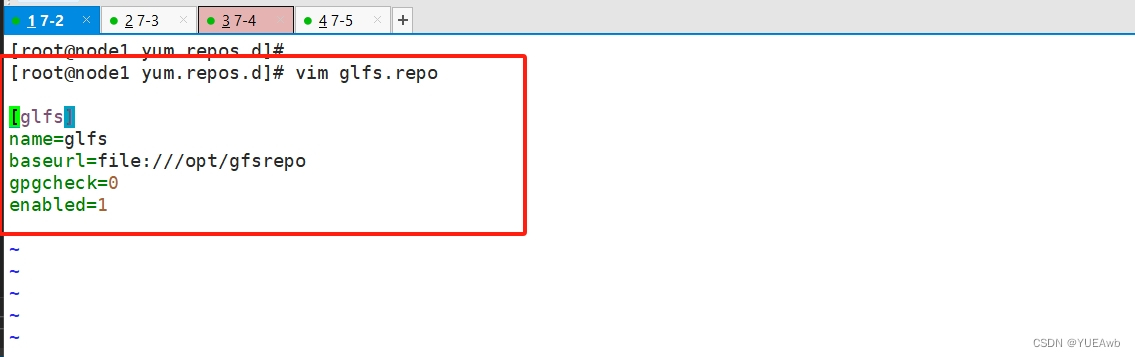
四台node服务器都要创建
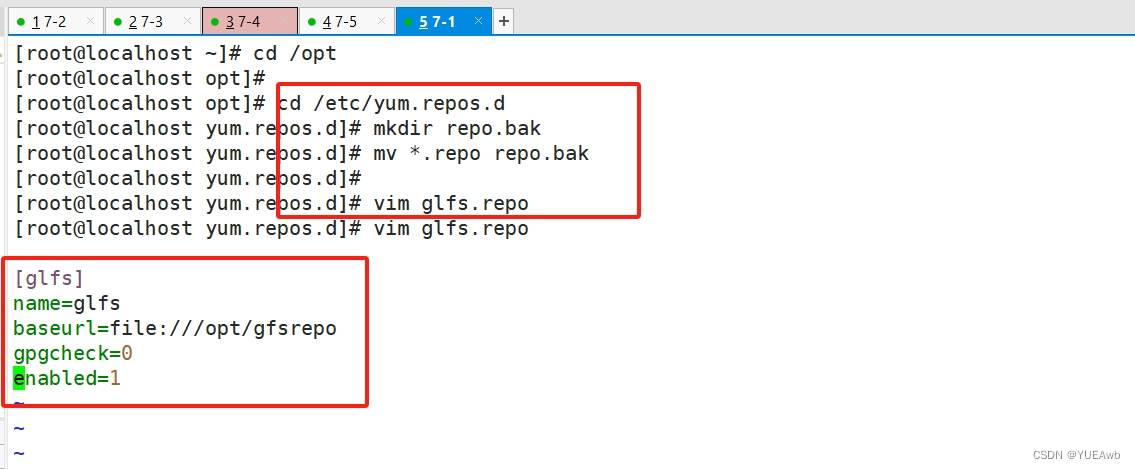
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bakvim glfs.repo[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1

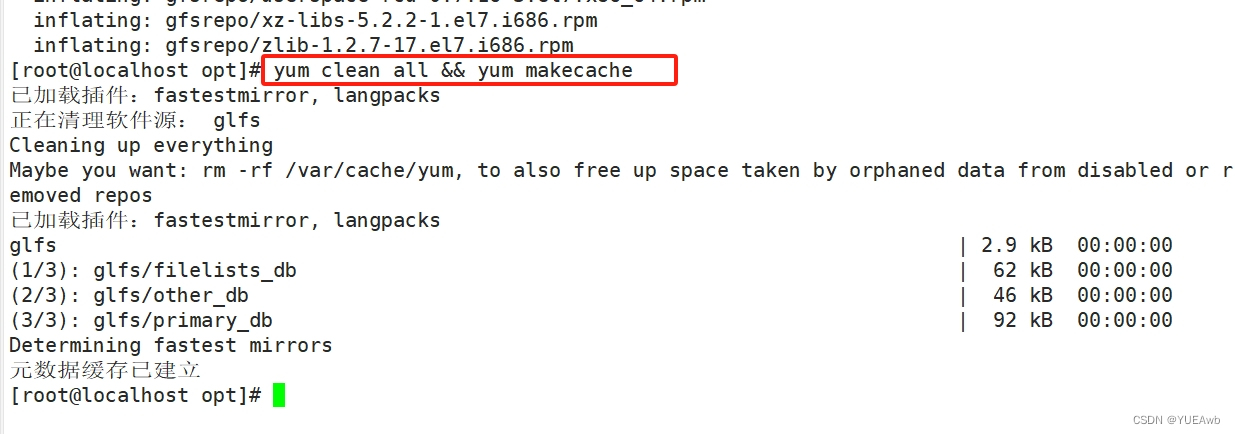
yum clean all && yum makecache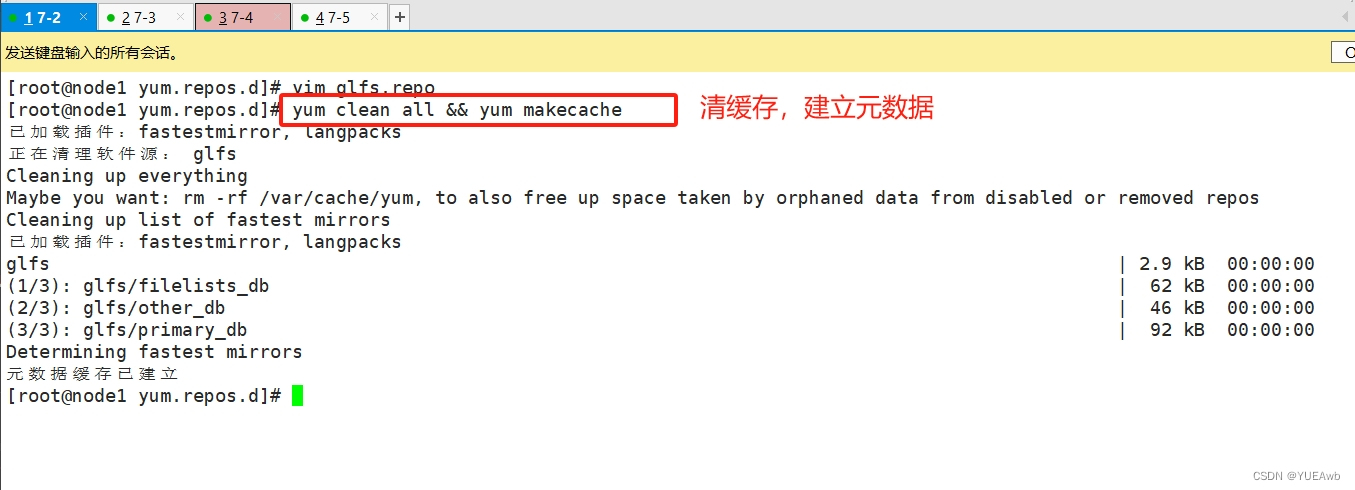
3. 安装 gfs
yum remove glusterfs-api.x86_64 glusterfs-cli.x86_64 glusterfs.x86_64 glusterfs-libs.x86_64 glusterfs-client-xlators.x86_64 glusterfs-fuse.x86_64 -y

yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma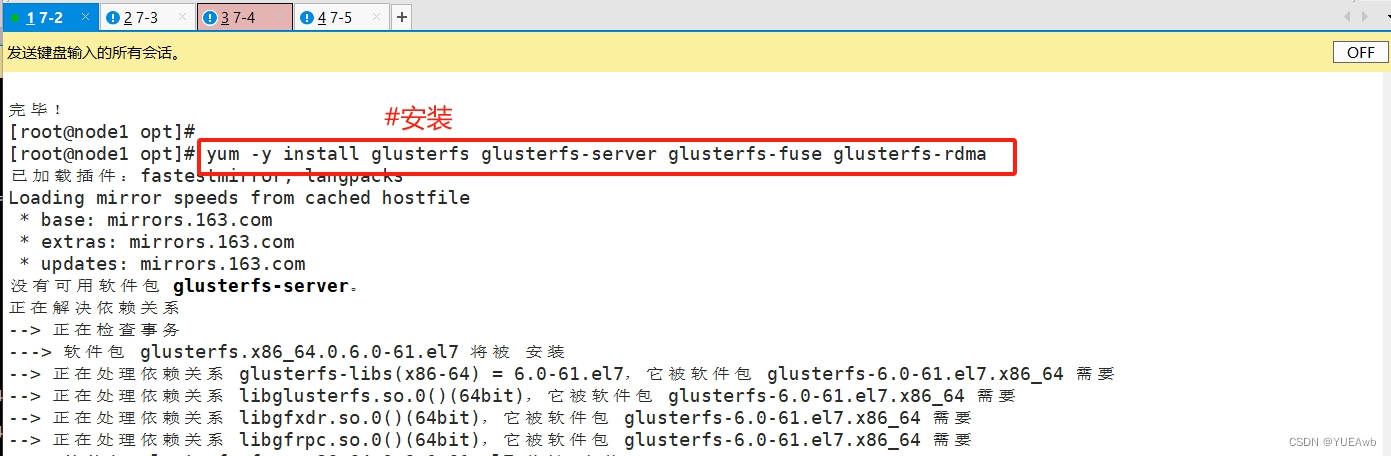
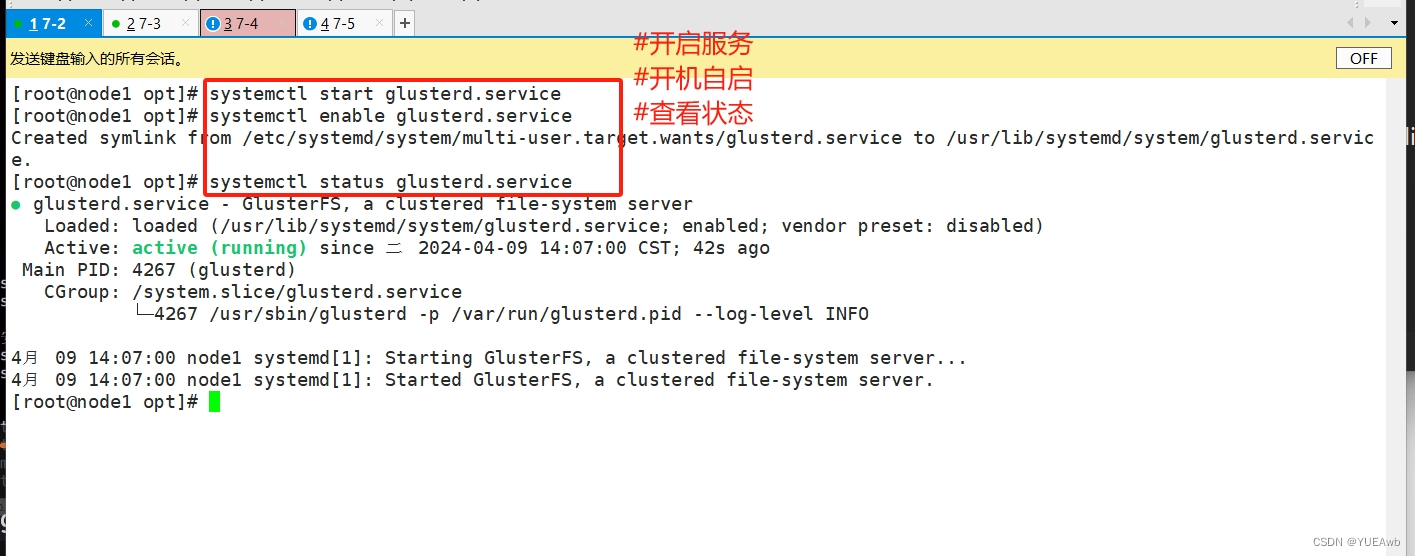
4. 开启服务
systemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service
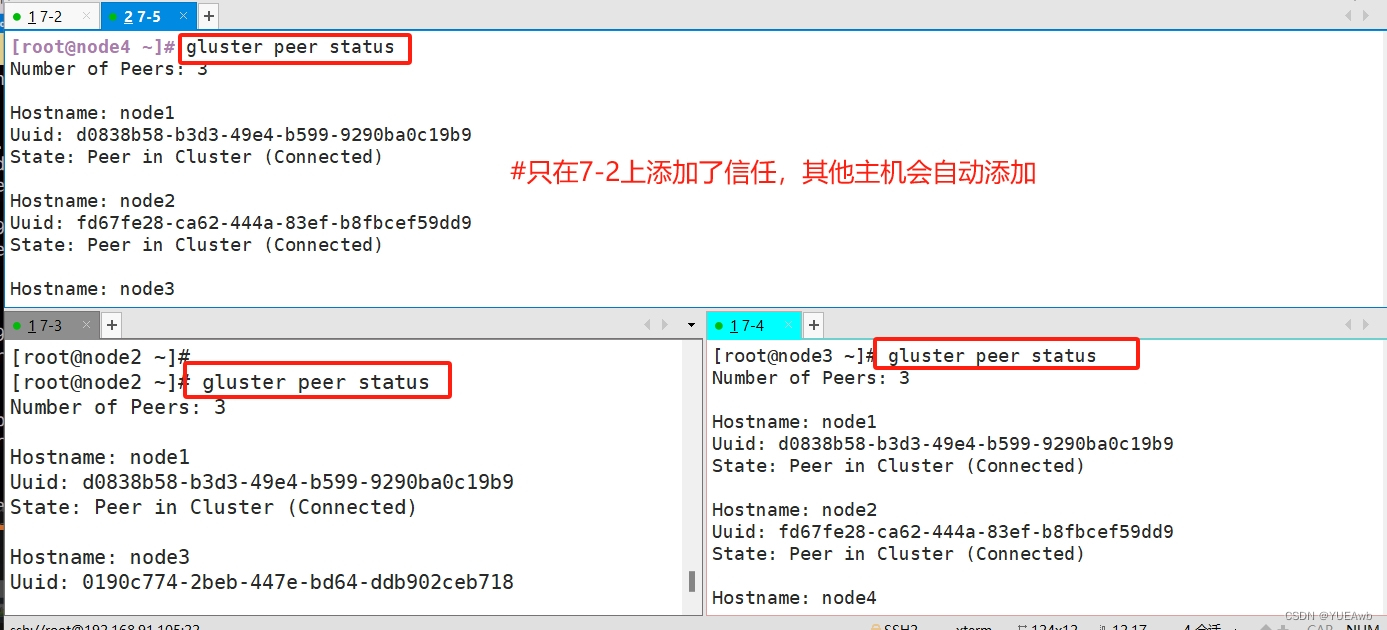
9、 添加节点到存储信任池中
#只要在一台Node节点上添加其它节点即可
gluster peer probe node2
gluster peer probe node3
gluster peer probe node4gluster peer status
在7-2一台主机上添加信任,其他主机会自动添加
10、创建卷
1. 规划创建卷
============================根据以下规划创建卷=============================
卷名称 卷类型 Brick
fenbushi 分布式卷 node1(/data/sdb1)、node2(/data/sdb1)
tiaodai 条带卷 node1(/data/sdc1)、node2(/data/sdc1)
fuzhi 复制卷 node3(/data/sdb1)、node4(/data/sdb1)
fbs-td 分布式条带卷 node1(/data/sdd1)、node2(/data/sdd1)、node3(/data/sdd1)、node4(/data/sdd1)
fbs-fz 分布式复制卷 node1(/data/sde1)、node2(/data/sde1)、node3(/data/sde1)、node4(/data/sde1)2.创建分布式卷
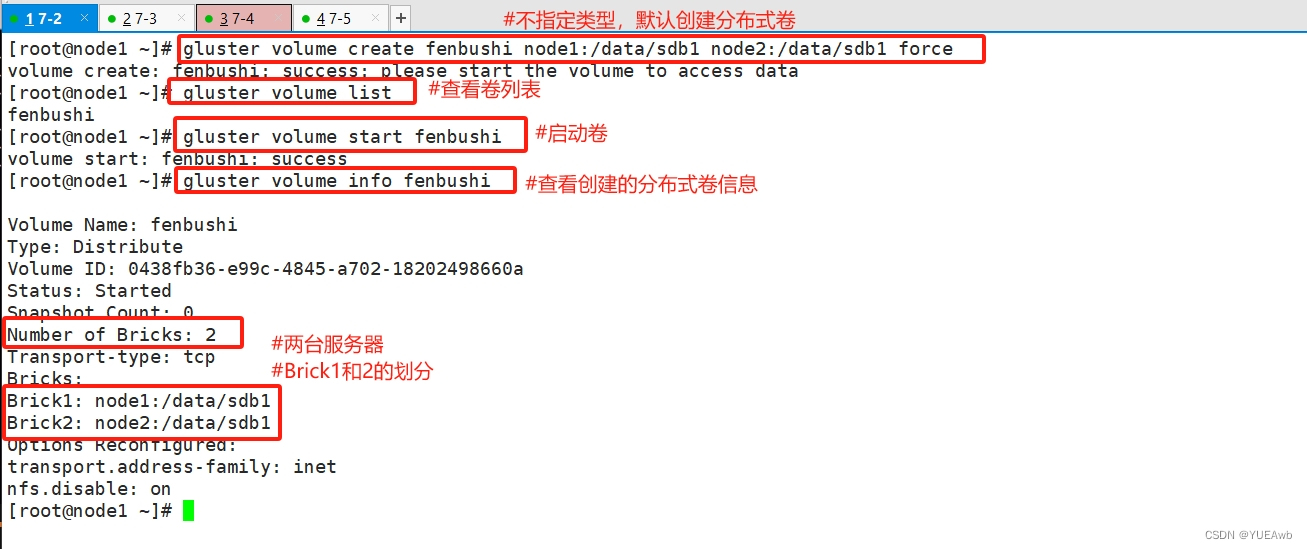
#创建分布式卷,没有指定类型,默认创建的是分布式卷[root@node1 ~]# gluster volume create fenbushi node1:/data/sdb1 node2:/data/sdb1 force
volume create: fenbushi: success: please start the volume to access data
[root@node1 ~]# gluster volume list
fenbushi
[root@node1 ~]# gluster volume start fenbushi
volume start: fenbushi: success
[root@node1 ~]# gluster volume info fenbushi Volume Name: fenbushi
Type: Distribute
Volume ID: 0438fb36-e99c-4845-a702-18202498660a
Status: Started
Snapshot Count: 0
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdb1
Brick2: node2:/data/sdb1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 ~]#
3.创建条带卷
[root@node1 ~]# gluster volume create tiaodai stripe 2 node1:/data/sdc1 node2:/data/sdc1 force
volume create: tiaodai: success: please start the volume to access data
[root@node1 ~]# gluster volume start tiaodai
volume start: tiaodai: success
[root@node1 ~]# gluster volume info tiaodai Volume Name: tiaodai
Type: Stripe
Volume ID: f64b6b6a-dadd-427f-8806-6e7dff448b66
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdc1
Brick2: node2:/data/sdc1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 ~]#

4. 创建复制卷
[root@node1 ~]# gluster volume create fuzhi replica 2 node3:/data/sdb1 node4:/data/sdb1 force
volume create: fuzhi: success: please start the volume to access data
[root@node1 ~]# gluster volume start fuzhi
volume start: fuzhi: success
[root@node1 ~]# gluster volume info fuzhi Volume Name: fuzhi
Type: Replicate
Volume ID: 3cdffb32-a007-41c6-8e19-dbc17878ea12
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: node3:/data/sdb1
Brick2: node4:/data/sdb1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 ~]#

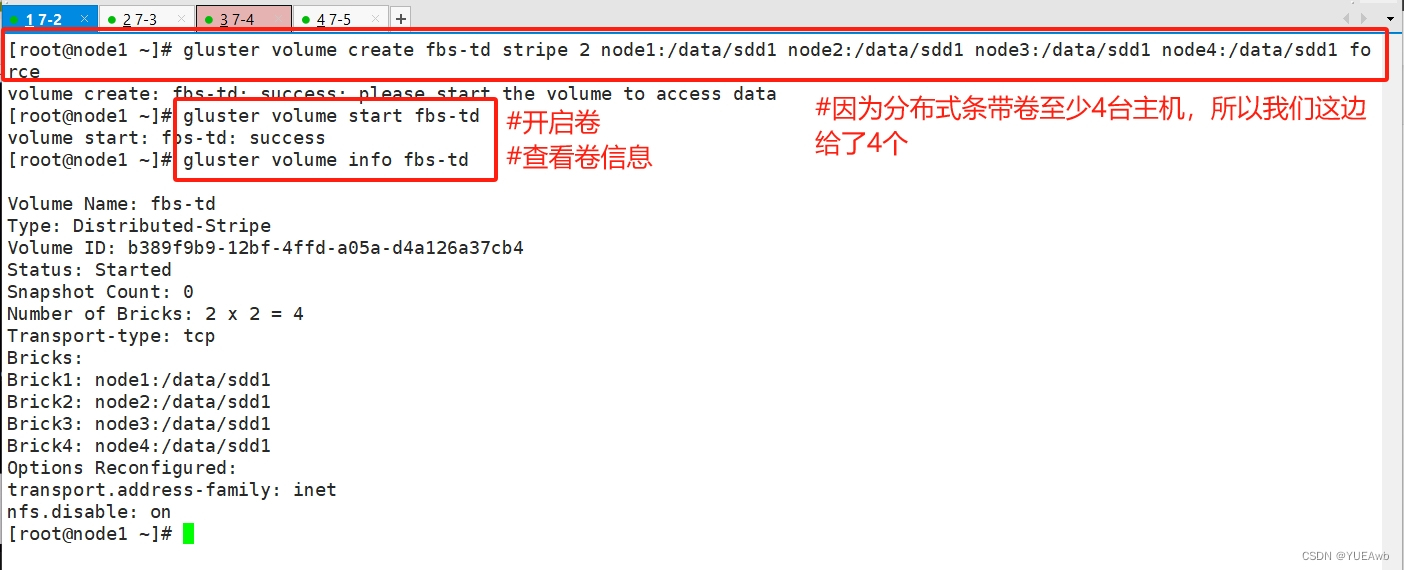
5.创建分布式条带卷
[root@node1 ~]# gluster volume create fbs-td stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force
volume create: fbs-td: success: please start the volume to access data
[root@node1 ~]# gluster volume start fbs-td
volume start: fbs-td: success
[root@node1 ~]# gluster volume info fbs-td Volume Name: fbs-td
Type: Distributed-Stripe
Volume ID: b389f9b9-12bf-4ffd-a05a-d4a126a37cb4
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdd1
Brick2: node2:/data/sdd1
Brick3: node3:/data/sdd1
Brick4: node4:/data/sdd1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 ~]#
6.创建分布式复制卷
[root@node1 ~]# gluster volume create fbs-fz replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force
volume create: fbs-fz: success: please start the volume to access data
[root@node1 ~]# gluster volume start fbs-fz
volume start: fbs-fz: success
[root@node1 ~]# gluster volume info fbs-fzVolume Name: fbs-fz
Type: Distributed-Replicate
Volume ID: f6913316-f886-4f4b-8e53-94feaf448587
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: node1:/data/sde1
Brick2: node2:/data/sde1
Brick3: node3:/data/sde1
Brick4: node4:/data/sde1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 ~]#

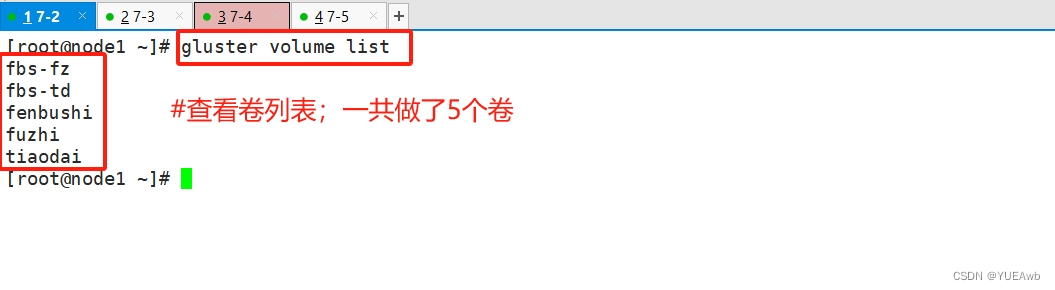
7.查看卷列表
gluster volume list
11、部署客户端--7-1
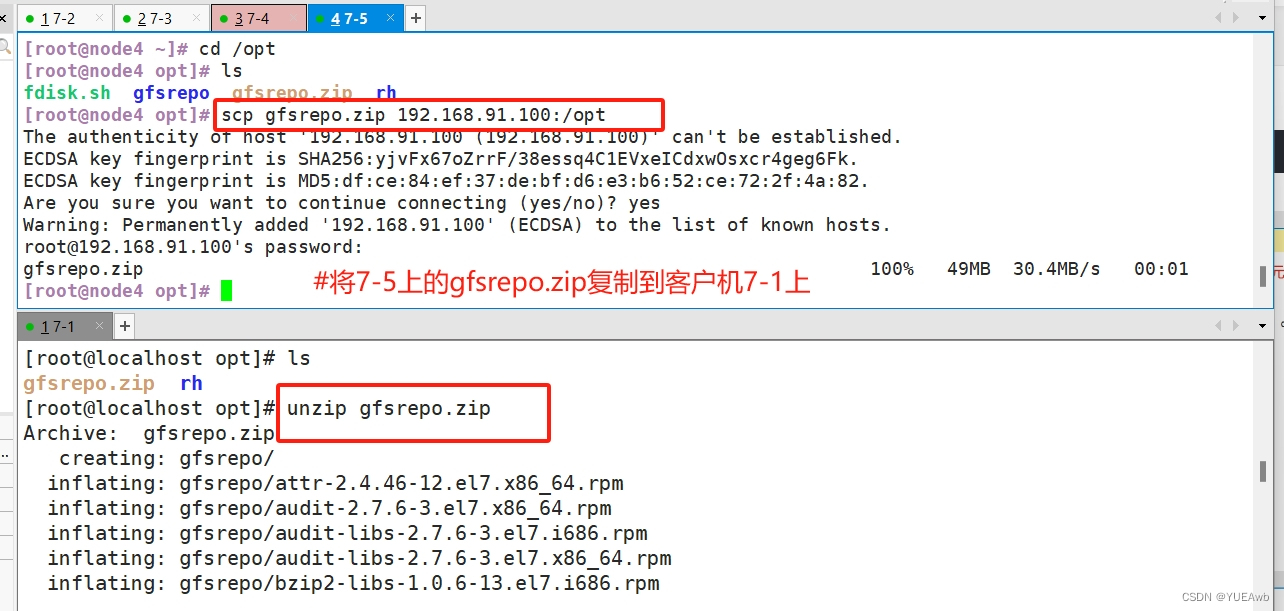
1.复制文件并解压
2. 建立元数据
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bakvim glfs.repo[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1
[root@localhost opt]# yum clean all && yum makecache
3.安装
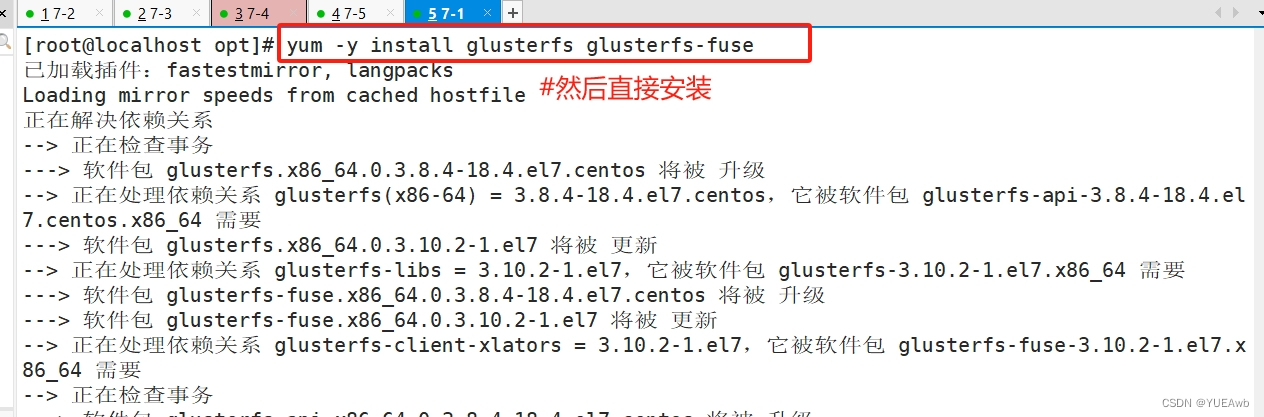
yum -y install glusterfs glusterfs-fuse
4.创建挂载目录
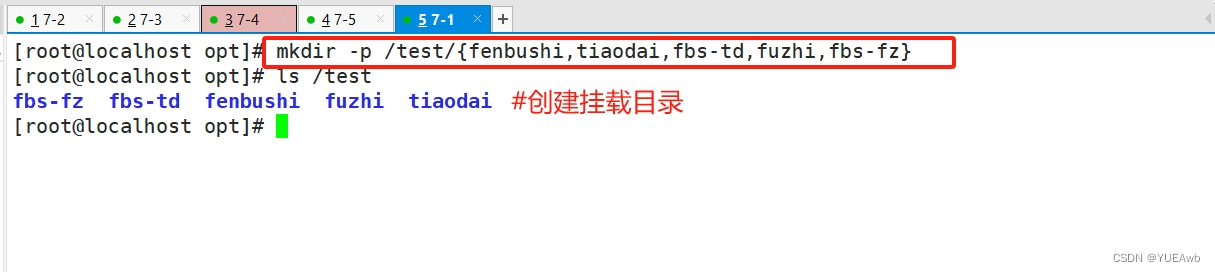
mkdir -p /test/{fenbushi,tiaodai,fbs-td,fuzhi,fbs-fz}
5. 给客户端做主机名映射
192.168.91.102 node1
192.168.91.103 node2
192.168.91.104 node3
192.168.91.105 node4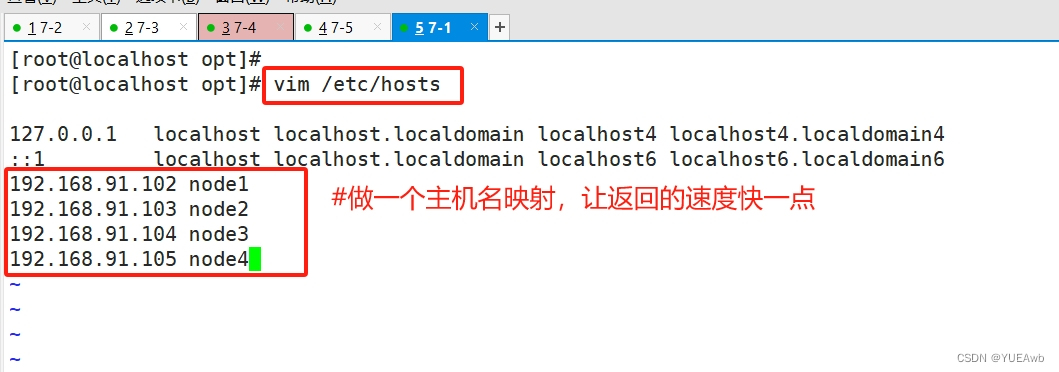
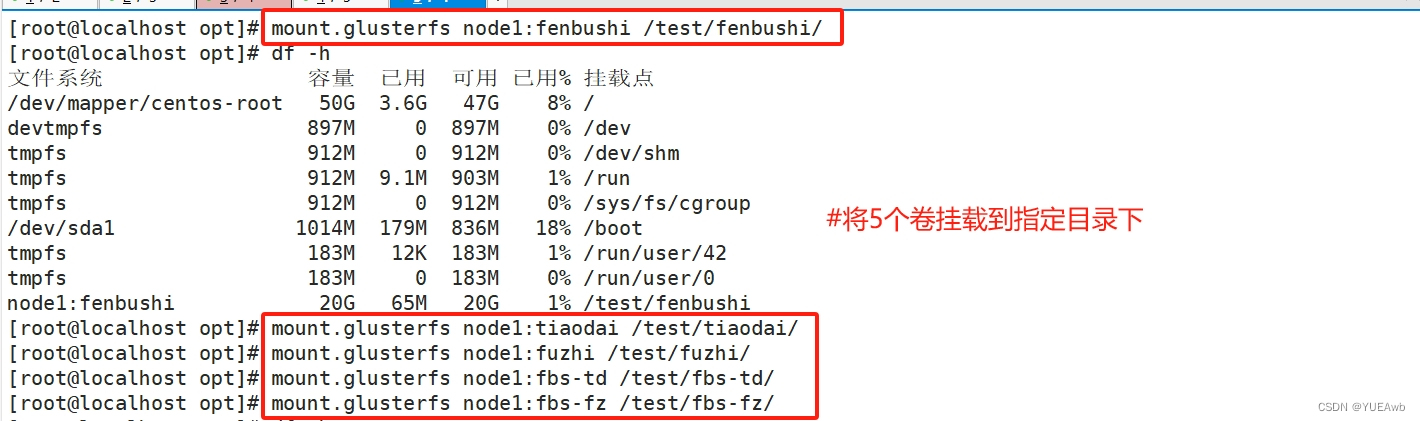
6.挂载Gluster文件系统
#临时挂载
[root@localhost opt]# mount.glusterfs node1:fenbushi /test/fenbushi/
[root@localhost opt]# mount.glusterfs node1:tiaodai /test/tiaodai/
[root@localhost opt]# mount.glusterfs node1:fuzhi /test/fuzhi/
[root@localhost opt]# mount.glusterfs node1:fbs-td /test/fbs-td/
[root@localhost opt]# mount.glusterfs node1:fbs-fz /test/fbs-fz/
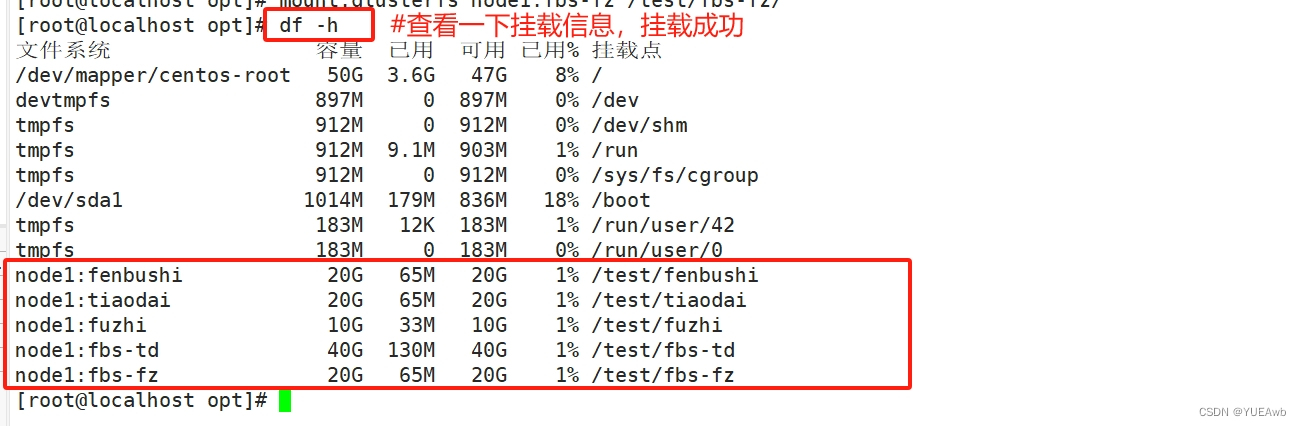
df -h###查看挂载效果
12、测试Gluster文件系统
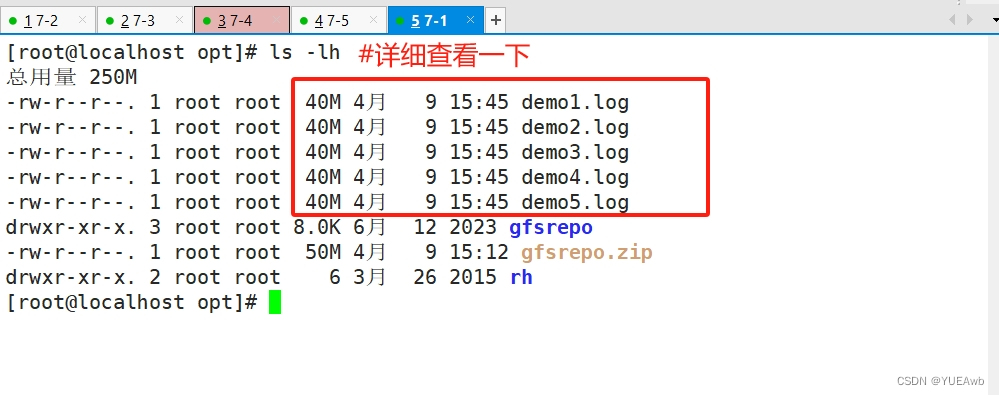
1.在5个卷中写入文件
cd /opt
dd if=/dev/zero of=/opt/demo1.log bs=1M count=40
dd if=/dev/zero of=/opt/demo2.log bs=1M count=40
dd if=/dev/zero of=/opt/demo3.log bs=1M count=40
dd if=/dev/zero of=/opt/demo4.log bs=1M count=40
dd if=/dev/zero of=/opt/demo5.log bs=1M count=40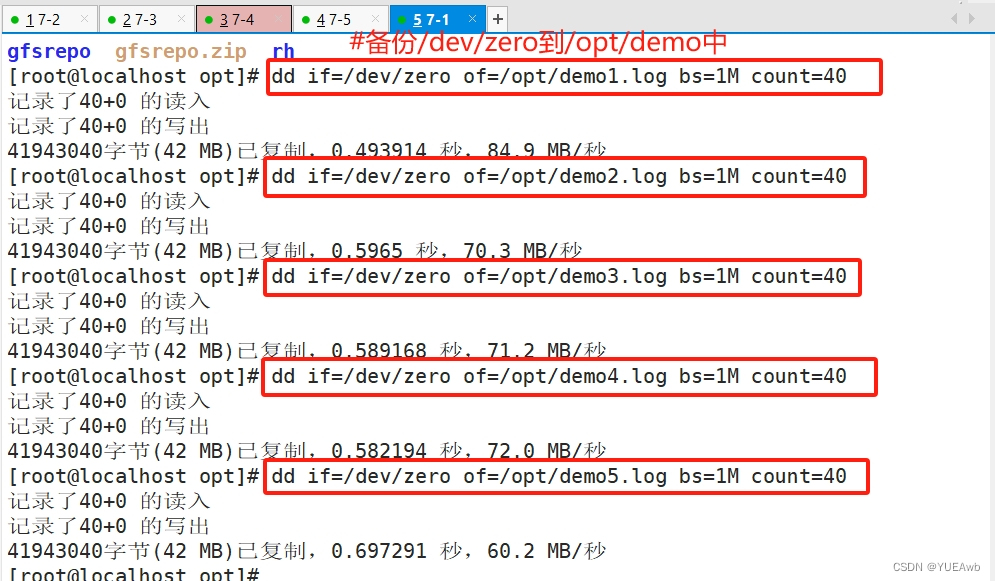
[root@localhost opt]# cp /opt/demo* /test/fenbushi/
[root@localhost opt]# cp /opt/demo* /test/tiaodai/
[root@localhost opt]# cp /opt/demo* /test/fuzhi/
[root@localhost opt]# cp /opt/demo* /test/fbs-td/
[root@localhost opt]# cp /opt/demo* /test/fbs-fz/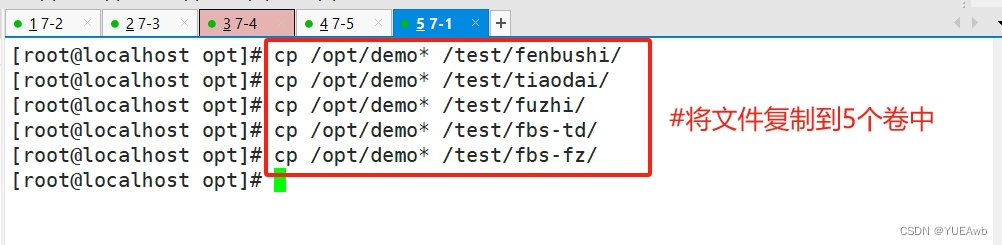
13、查看文件分布
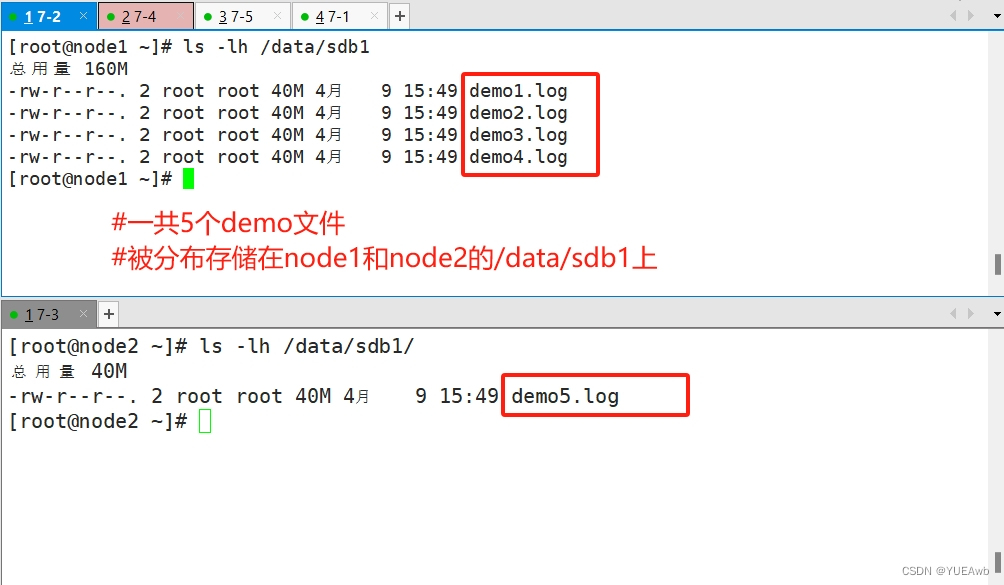
1. 查看分布式文件分布
没有数据分片
1. 因为我们之前做分布式卷的时候,指定就是node1和node2的sdb1磁盘
2. 所以我们查看文件分布的时候,要对应之前创建卷的时候的分布
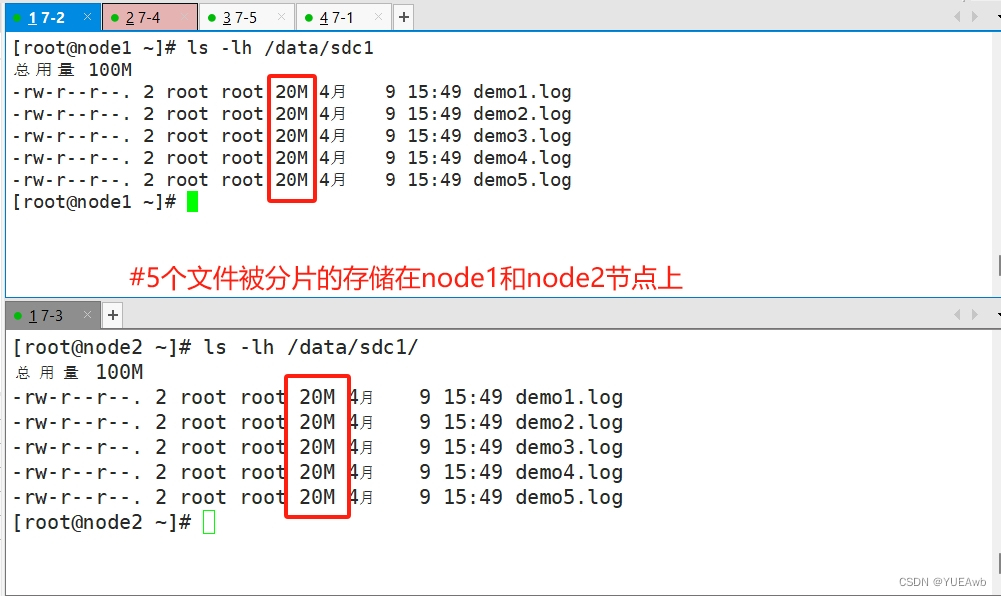
2.查看条带卷文件分布
数据被分片
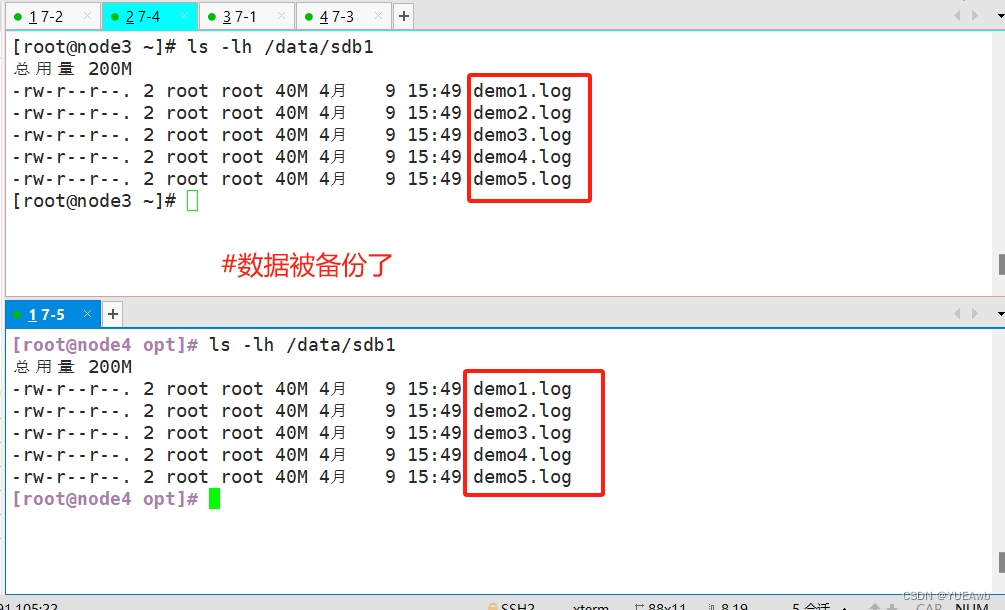
3.查看复制卷分布
数据备份了
4.查看分布式条带卷分布
数据被分布式存储;数据被分片

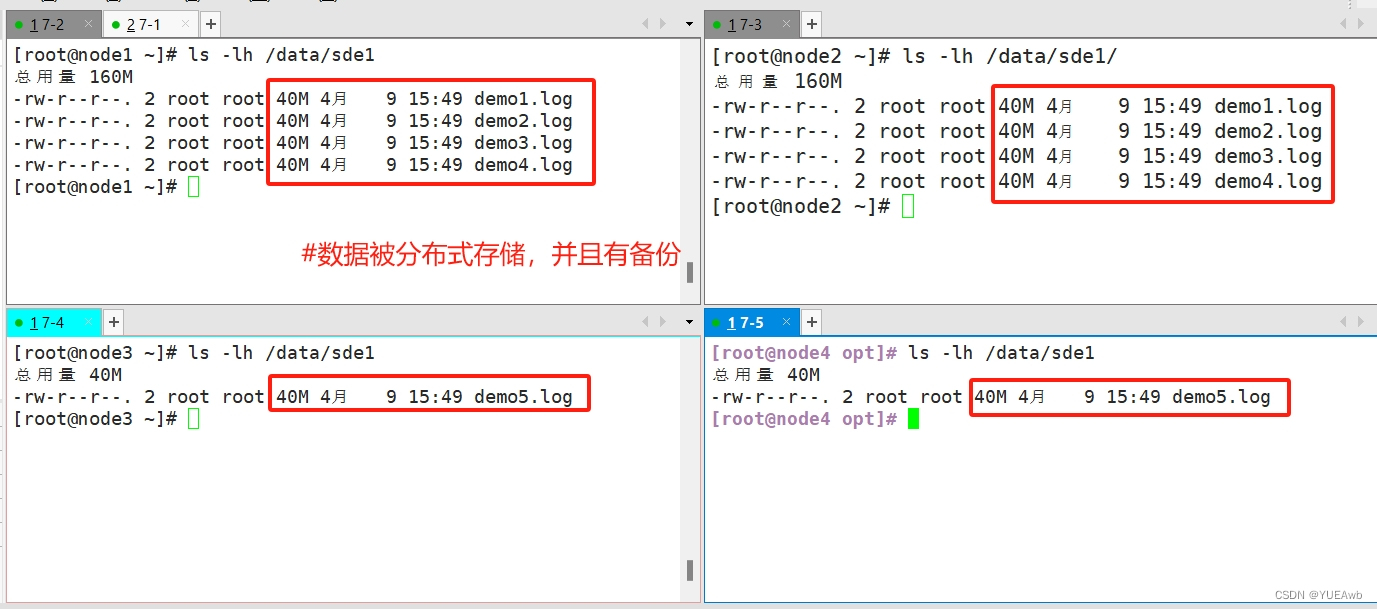
5.查看分布式复制卷分布
14.破坏性测试
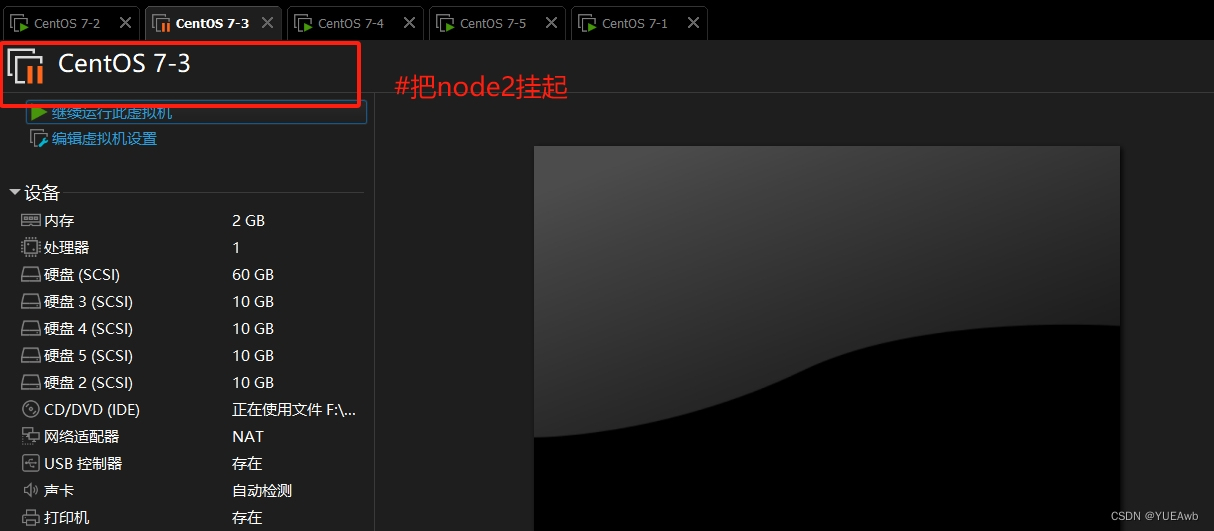
1.挂起node2
15.客户端查看破坏结果
1.查看分布式数据

2.查看条带卷数据

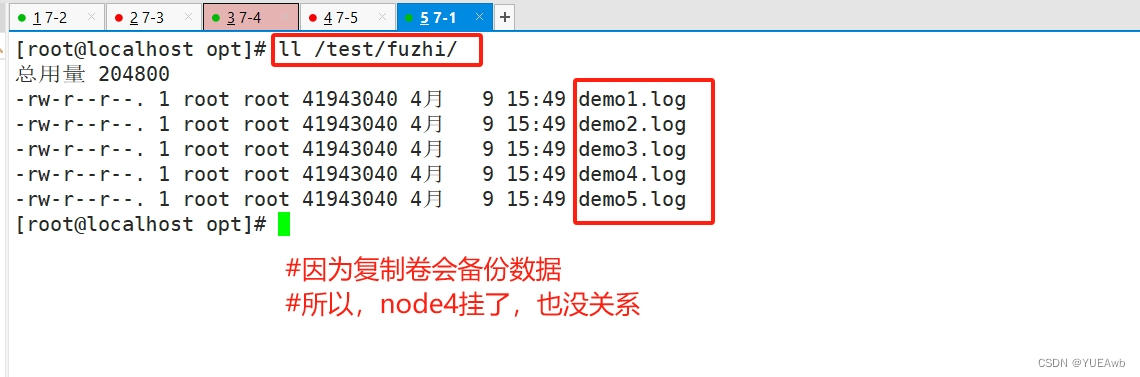
3.查看复制卷数据
因为我们把复制卷坐在了node3和node4上
所以,我们把node4挂起
4.查看分布式条带卷数据

5.查看分布式复制卷数据
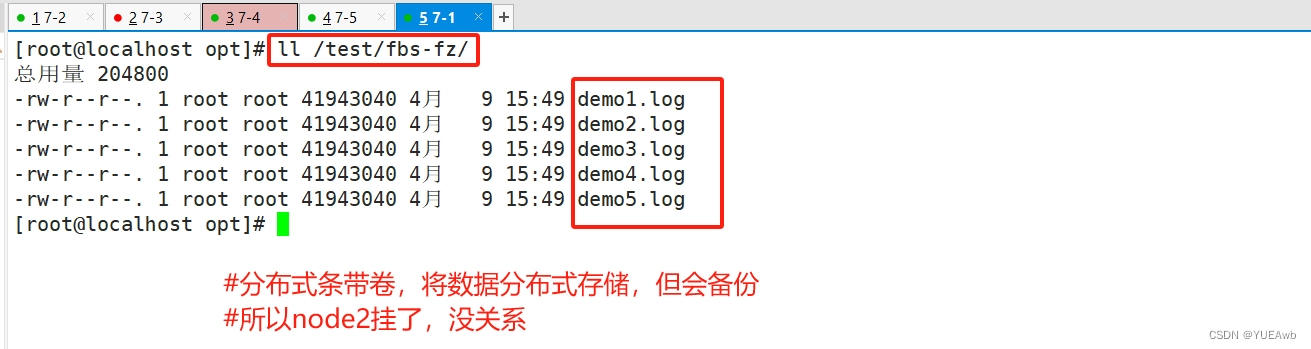
16、总结
##### 上述实验测试,凡是带复制数据,相比而言,数据比较安全 #####
#扩展其他的维护命令:
1.查看GlusterFS卷
gluster volume list
2.查看所有卷的信息
gluster volume info
3.查看所有卷的状态
gluster volume status
4.停止一个卷
gluster volume stop dis-stripe
5.删除一个卷,注意:删除卷时,需要先停止卷,且信任池中不能有主机处于宕机状态,否则删除不成功
gluster volume delete dis-stripe
6.设置卷的访问控制
#仅拒绝
gluster volume set dis-rep auth.deny 192.168.80.100
#仅允许
gluster volume set dis-rep auth.allow 192.168.80.* #设置192.168.80.0网段的所有IP地址都能访问dis-rep卷(分布式复制卷)
相关文章:
GFS部署实验
目录 1、部署环境 编辑 2、更改节点名称 3、准备环境 4、磁盘分区,并挂载 5. 做主机映射--/etc/hosts/ 6. 复制脚本文件 7. 执行脚本完成分区 8. 安装客户端软件 1. 安装解压源包 2. 创建gfs 3. 安装 gfs 4. 开启服务 9、 添加节点到存储信任池中 1…...
最前沿・量子退火建模方法(1) : subQUBO讲解和python实现
前言 量子退火机在小规模问题上的效果得到了有效验证,但是由于物理量子比特的大规模制备以及噪声的影响,还没有办法再大规模的场景下应用。 这时候就需要我们思考,如何通过软件的方法怎么样把大的问题分解成小的问题,以便通过现在…...
如何在Linux部署MeterSphere并实现公网访问进行远程测试工作
文章目录 前言1. 安装MeterSphere2. 本地访问MeterSphere3. 安装 cpolar内网穿透软件4. 配置MeterSphere公网访问地址5. 公网远程访问MeterSphere6. 固定MeterSphere公网地址 前言 MeterSphere 是一站式开源持续测试平台, 涵盖测试跟踪、接口测试、UI 测试和性能测试等功能&am…...
postgis导入shp数据时“dbf file (.dbf) can not be opened.“
作者进行矢量数据导入数据库中出现上述报错 导致报错原因 导入的shp文件路径太深导入的shp文件名称或路径中有中文将需要导入数据的shp 文件、dbf 文件、prj 等文件放在到同一个文件夹内,且名字要一致;导入失败: 导入成功:...
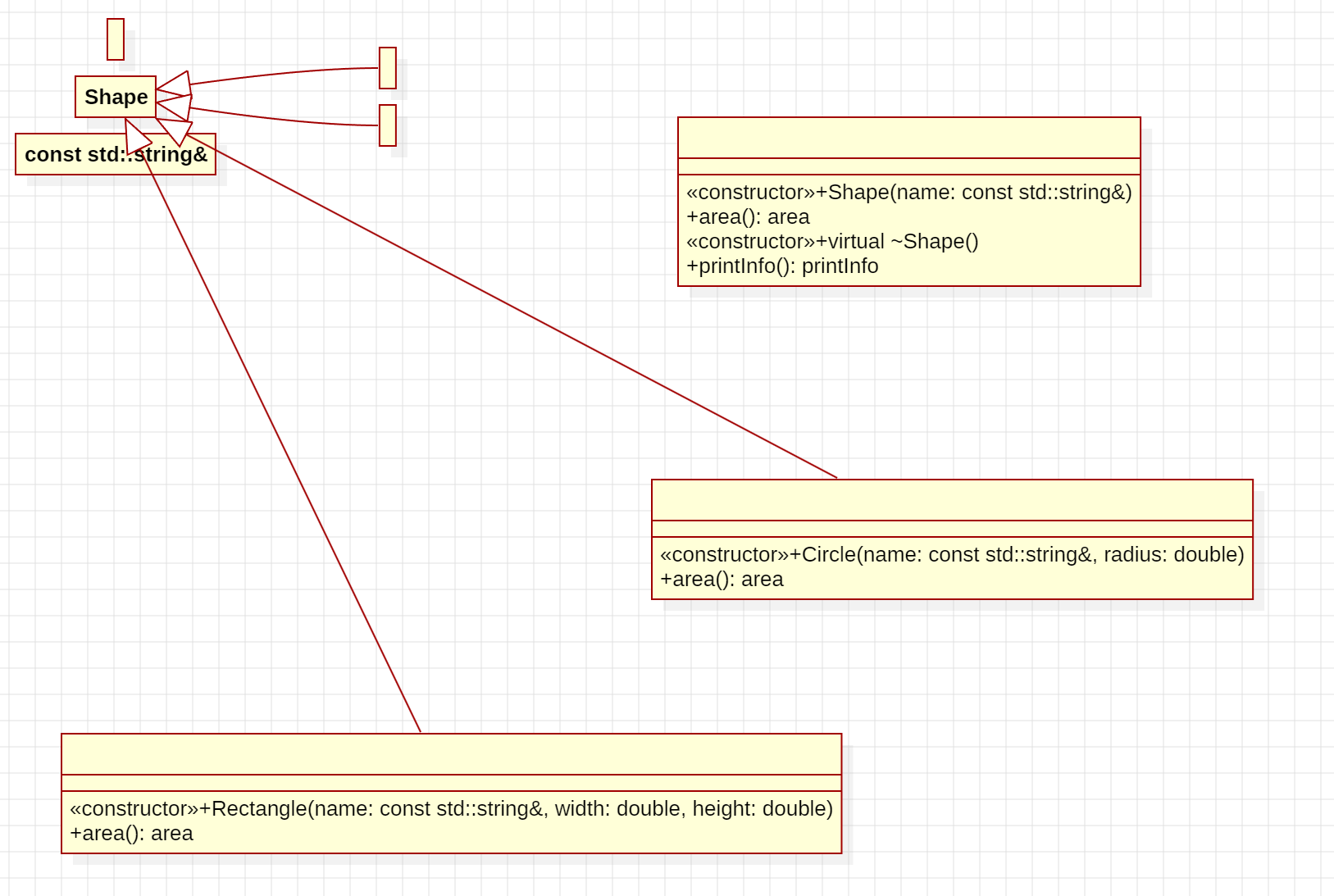
StarUML笔记之从C++代码生成UML图
StarUML笔记之从C代码生成UML图 —— 2024-04-14 文章目录 StarUML笔记之从C代码生成UML图1.安装C插件2.准备好一个C代码文件放某个路径下3.点击Reverse Code选择项目文件夹4.拖动(Class)到中间画面可以形成UML5.另外一种方式:双击Type Hierarchy,然后…...
和strlen)
sizeof()和strlen
一、什么是sizeof() sizeof()是一个在C和C中广泛使用的操作符,用于计算数据类型或变量所占内存的字节数。它返回一个size_t类型的值,表示其操作数所占的字节数。 在使用时,sizeof()可以接收一个数据类型作为参数,也可以接收一个…...

Python学习笔记13 - 元组
什么是元组 元组的创建方式 为什么要将元组设计为不可变序列? 元组的遍历...
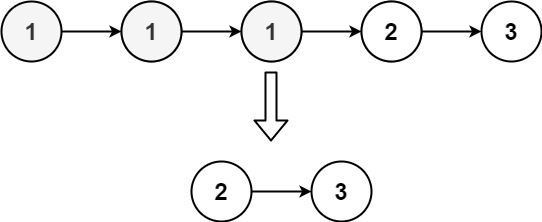
[leetcode]remove-duplicates-from-sorted-list-ii
. - 力扣(LeetCode) 给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。 示例 1: 输入:head [1,2,3,3,4,4,5] 输出:[1,2,5]示例 2&…...

共享内存和Pytorch中的Dataloader结合
dataloader中通常使用num_workers来指定多线程来进行数据的读取。可以使用共享内存进行加速。 代码地址:https://github.com/POSTECH-CVLab/point-transformer/blob/master/util/s3dis.py 文章目录 1. 共享内存和dataloader结合1.1 在init中把所有的data存储到共享内…...
分享 WebStorm 2024 激活的方案,支持JetBrains全家桶
大家好,欢迎来到金榜探云手! WebStorm公司简介 JetBrains 是一家专注于开发工具的软件公司,总部位于捷克。他们以提供强大的集成开发环境(IDE)而闻名,如 IntelliJ IDEA、PyCharm、和 WebStorm等。这些工具…...
Android OOM问题定位、内存优化
一、OOM out of memory:简称OOM,内存溢出,申请的内存大于剩余的内存而抛出的异常。 对于Android平台,广义的OOM主要是以下几种类型 JavaNativeThread 线程数的上限默认为32768,部分华为设备的限制是500通常1000左右…...
)
棋盘(c++题解)
题目描述 有一个m m的棋盘,棋盘上每一个格子可能是红色、黄色或没有任何颜色的。你现在要从棋盘的最左上角走到棋盘的最右下角。 任何一个时刻,你所站在的位置必须是有颜色的(不能是无色的) ,你只能向上、下、 左、右…...
滑动窗口例题
一、209:长度最小的子数组 209:长度最小的子数组 思路:1、暴力解法:两层for循环遍历,当sum > target时计算子数组长度并与result比较,取最小的更新result。提交但是超出了时间限制。 class Solution {public int minSubArray…...

智过网:注册安全工程师注册有效期与周期解析
在职业领域,各种专业资格认证不仅是对从业者专业能力的认可,也是保障行业安全、规范发展的重要手段。其中,注册安全工程师证书在安全生产领域具有举足轻重的地位。那么,注册安全工程师的注册有效期是多久呢?又是几年一…...

腐蚀Rust 服务端搭建架设个人社区服务器Windows教程
腐蚀Rust 服务端搭建架设个人社区服务器Windows教程 大家好我是艾西,一个做服务器租用的网络架构师也是游戏热爱者。最近在steam发现rust腐蚀自建的服务器以及玩家还是非常多的,那么作为服务器供应商对这商机肯定是不会放过的哈哈哈! 艾西这…...

蓝桥杯备赛:考前注意事项
考前注意事项 1、DevCpp添加c11支持 点击 工具 - 编译选项 中添加: -stdc112、万能头文件 #include <bits/stdc.h>万能头文件的缺陷:y1 变量 在<cmath>中用过了y1变量。 #include <bits/stdc.h> using namespace std;// 错误示例 …...

111111111111
111111111111...
uniapp 卡片勾选
前言 公司的app项目使用的uniapp,项目里有一个可勾选的卡片功能,效果图如下: 找了一圈没找到什么太好的组件,于是就自己简单写了一个,记录一下。避免以后还会用到 代码 <template><view class"card-…...

乐趣Python——文件与数据:挥别乱糟糟的桌面
各位朋友们,今天我们要开启一场非凡的冒险——进入文件操作的世界!你知道吗,在你的电脑里,有一个叫做“文件系统”的迷宫,里面藏着各种各样的文件和文件夹,它们就像是迷宫中的宝藏。但有时候,这…...

docker nginx-lua发送post json 请求
环境准备 dockerfile from fabiocicerchia/nginx-lua:1.25.3-ubuntu22.04 run apt-get -qq update && apt-get -qq install luarocks run luarocks install lua-cjson run luarocks install lua-iconv run luarocks install lua-resty-http后台代理服务准备ÿ…...

GKD订阅管理实战手册:一站式解决Android自动化规则配置难题
GKD订阅管理实战手册:一站式解决Android自动化规则配置难题 【免费下载链接】GKD_THS_List GKD第三方订阅收录名单 项目地址: https://gitcode.com/gh_mirrors/gk/GKD_THS_List GKD订阅管理是Android自动化工具GKD的第三方订阅收录平台,为GKD用户…...

AI智能体安全防护:ClawGuard主动防御系统架构与实战部署
1. 项目概述:为AI智能体构建一道主动防御的“防火墙”在AI智能体(AI Agent)技术快速普及的今天,我们正面临一个全新的安全挑战。想象一下,你精心调教的AI助手,能够自主浏览网页、调用API、执行命令…...

一次讲清本地大模型语音识别三件套:Vulkan 为什么是加速主线,而说话人识别为何成为唯一短板
把 whisper.cpp、sherpa-onnx、llama.cpp 三套引擎整合到一起,再用 Electron 包成桌面应用,这个技术思路本身并不复杂。真正考验工程功力的,是面向完全不懂技术的最终端用户,怎样让这些引擎尽可能“一键加速”,同时还不…...

数据获取指南
教程:数据获取指南 作者:太虚野老 目录 说明: 3 数据获取指南 4 计划:创建和填充示例表 4 基础数据检索 4 过滤和排序结果 6 处理多表(JOIN)和函数 7 SELECT 语句修饰符 8 说明: 1.MariaDB版本:10.11.14 2.开发工具:dbeaver(版本25.3.0) 3.操作系统:debian12…...

RE3SIM系统:3D真实感仿真数据生成技术解析
1. RE3SIM系统概述:3D真实感仿真数据生成新范式在机器人操作领域,获取高质量训练数据一直是制约算法发展的瓶颈。传统基于真实环境的示教数据采集不仅需要昂贵硬件支持,还依赖专业操作人员,单次任务采集成本可达数千元。RE3SIM系统…...

基于MCP协议与Google Apps Script的Google Workspace自动化集成实践
1. 项目概述:当Google Workspace遇上MCP如果你是一名开发者,或者负责企业内部的自动化流程,那么对Google Workspace(谷歌工作区)一定不陌生。从Gmail、Google Drive到Sheets、Docs和Calendar,它几乎构成了现…...

蓝桥杯EDA国赛备赛
一.电路设计部分(1)13届国赛要求:数码管驱动电路设计区域内,使用给定的元器件(锁存器-U6、电容等)和网络标识补充完成数码管驱动电路,实现单片机对数码管的显示控制。参考答案:1. 10…...

OpenClaw Memory启动器:快速构建AI记忆系统的开源脚手架
1. 项目概述:一个为AI记忆系统设计的开源启动器最近在折腾AI应用开发,特别是那些需要长期记忆和上下文管理的项目时,发现了一个挺有意思的GitHub仓库:christiancaviedes/openclaw-memory-starter。这本质上是一个为“OpenClaw Mem…...

Perplexity无法解析Springer LaTeX公式?2024.06最新MathJax兼容补丁+3类数学文献精准摘要生成术
更多请点击: https://intelliparadigm.com 第一章:Perplexity解析Springer文献的底层机制与失效归因 Perplexity 作为衡量语言模型预测能力的关键指标,在学术文献解析场景中常被误用为“质量代理”,尤其在处理 Springer 出版集团…...

基于MCP协议的elabftw AI助手:安全模型、配置与自动化实践
1. 项目概述:为电子实验笔记本插上AI的翅膀如果你是一名科研人员、实验室管理者,或者像我一样,经常需要和电子实验笔记本(ELN)打交道,那你一定对重复性的数据查询、整理和录入工作感到头疼。每天在浏览器和…...