分布式系统:缓存与数据库一致性问题
前言
缓存设计是应用系统设计中重要的一环,是通过空间换取时间的一种策略,达到高性能访问数据的目的;但是缓存的数据并不是时刻存在内存中,当数据发生变化时,如何与数据库中的数据保持一致,以满足业务系统要求,本篇将给出具体分析。
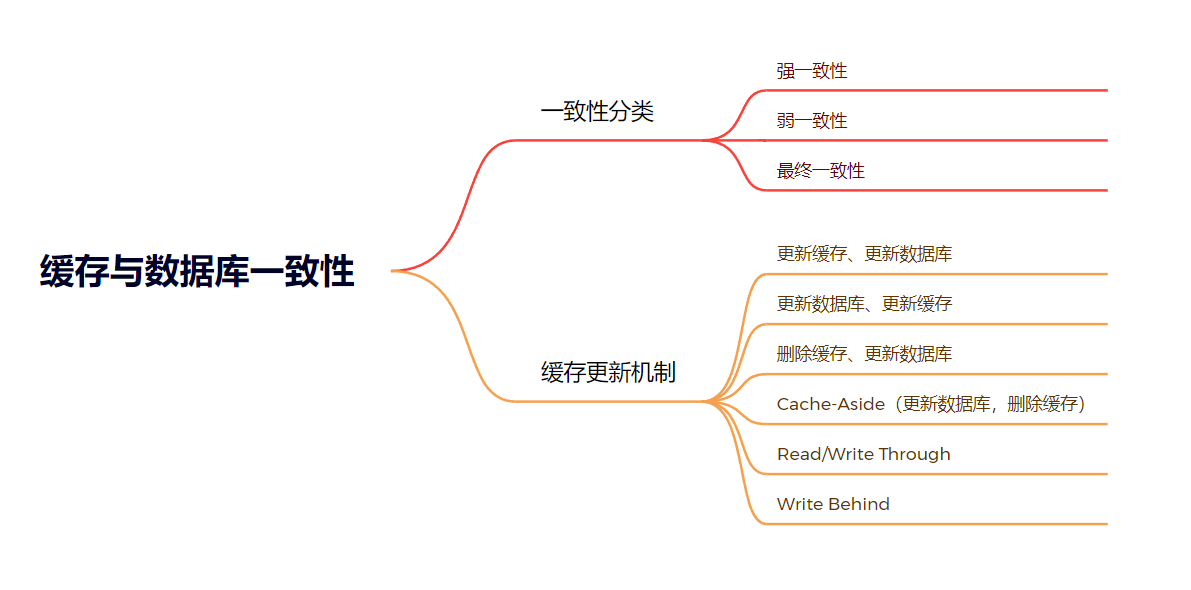
一致性分类
- 强一致性:这种一致性级别是最符合用户直觉的,它要求系统写入什么,读出来的也会是什么,用户体验好,但实现起来往往对系统的性能影响大,这种情况比如秒杀系统,商家后台,他会设置秒杀商品,参与秒杀活动,一旦说他参与了秒杀活动,商品的库存本来是在数据库里的,此时必须直接被加载到缓存里,缓存立马就要可以被使用。
- 弱一致性:这种一致性级别约束了系统在写入成功后,不承诺立即可以读到写入的值,也不承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态
- 最终一致性:最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。这里之所以将最终一致性单独提出来,是因为它是弱一致性中非常推崇的一种一致性模型,也是业界在大型分布式系统的数据一致性上比较推崇的模型,比如微博的粉丝数,页面每天的访问数
缓存更新机制
缓存的更新,一般分为被动更新与主动更新,被动更新是指缓存在有效期到后,被淘汰。
被动更新如下步骤:step1: 发起方查数据,缓存中没有,从数据库中获取,并写入缓存,同时设置过期时间 t;step2: 在 t 内,所有的查询,都由缓存提供,所有的写,直接写数据库;step3: 当缓存数据到过期时间 t 后,缓存数据失效。后面的查询,回到了第 1 步。
主动更新,一般为调用方发起缓存与数据库同时更新,缓存分为删除、更新,数据库分为更新,通过组合与先后顺序,分为如下四种情况:更新缓存、更新数据库,更新数据库,更新缓存,删除缓存,更新数据库,更新数据库,删除缓存
更新缓存、更新数据库
这种情况,当缓存更新成功,数据库更新不成功时,数据不一致的风险比较高,所以一般不采用。
更新数据库、更新缓存
当更新完数据库,缓存的加载前需要通过大量复杂计算才能得出缓存的值,不仅让发起方阻塞,影响性能;而且如果缓存命中率不高,很少使用,更浪费前期的复杂计算成本与缓存空间,这里就不符合懒加载的设计思想,故一般也不采用。
删除缓存、更新数据库
如图所示,当两个调用方线程高并发访问的情况下,A 线程先删除缓存,再更新数据库,此过程时间较长,B 线程在 A 删除缓存后,迅速读取缓存,因缓存每命中,从数据库中读取再加载缓存,此时缓存还是旧值,等 A 线程更新完数据库后,发现又出现数据不一致的现象。
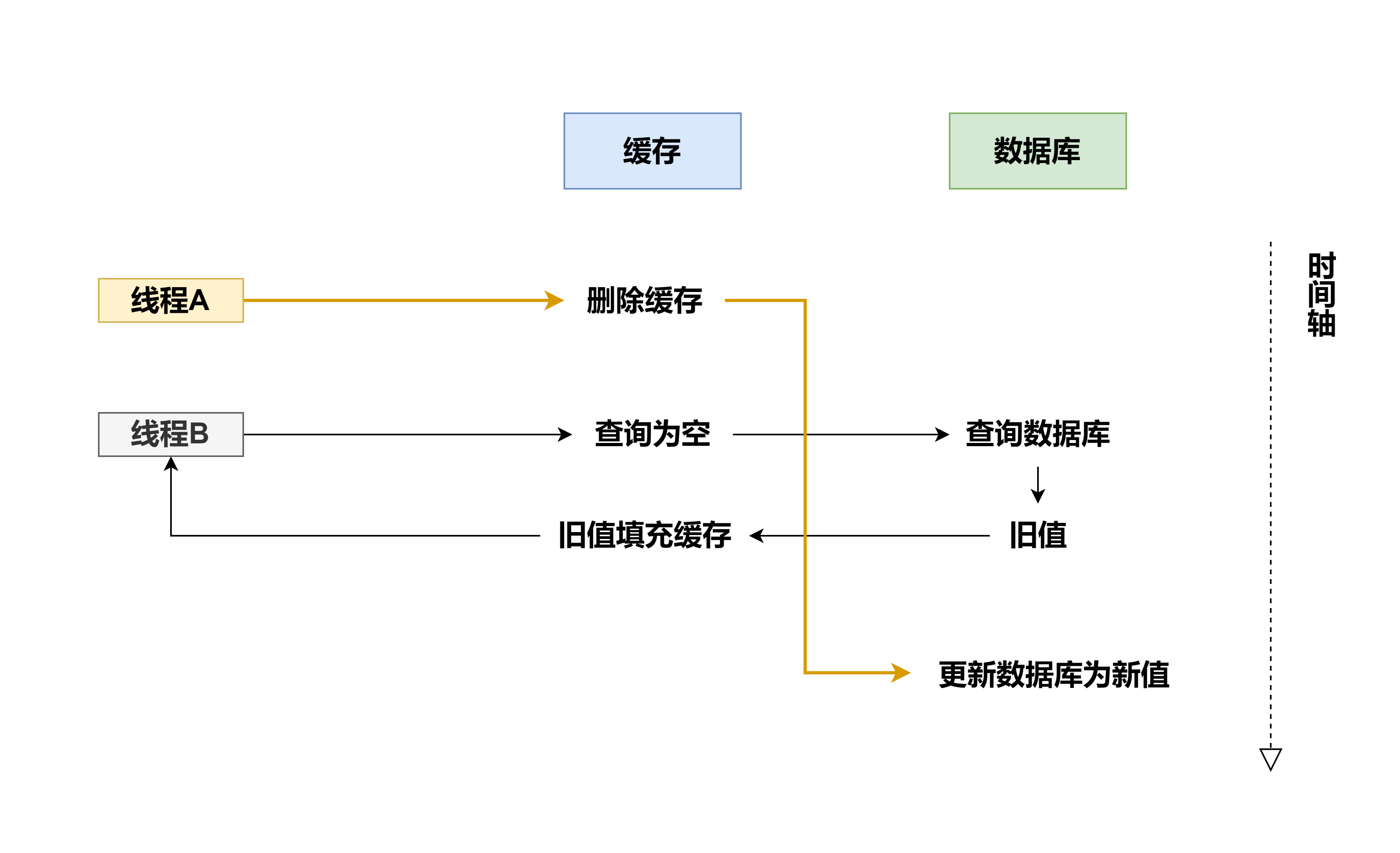
一般大概率情况下,出现此根源的原因是读比写快,所以这种一般也不采用,如果非得采用,需要在写完数据库之后延迟一段时间再删除一次缓存,也就是我们熟知的 延时双删,延迟多久呢,一般看数据库的更新时长来决定,此做法也会带来系统吞吐量下降。
Cache-Aside
也叫做旁路缓存模式,流程就是先更新数据库,再删除缓存,虽然这种方式也会带来不一致的情况,比如如下场景:
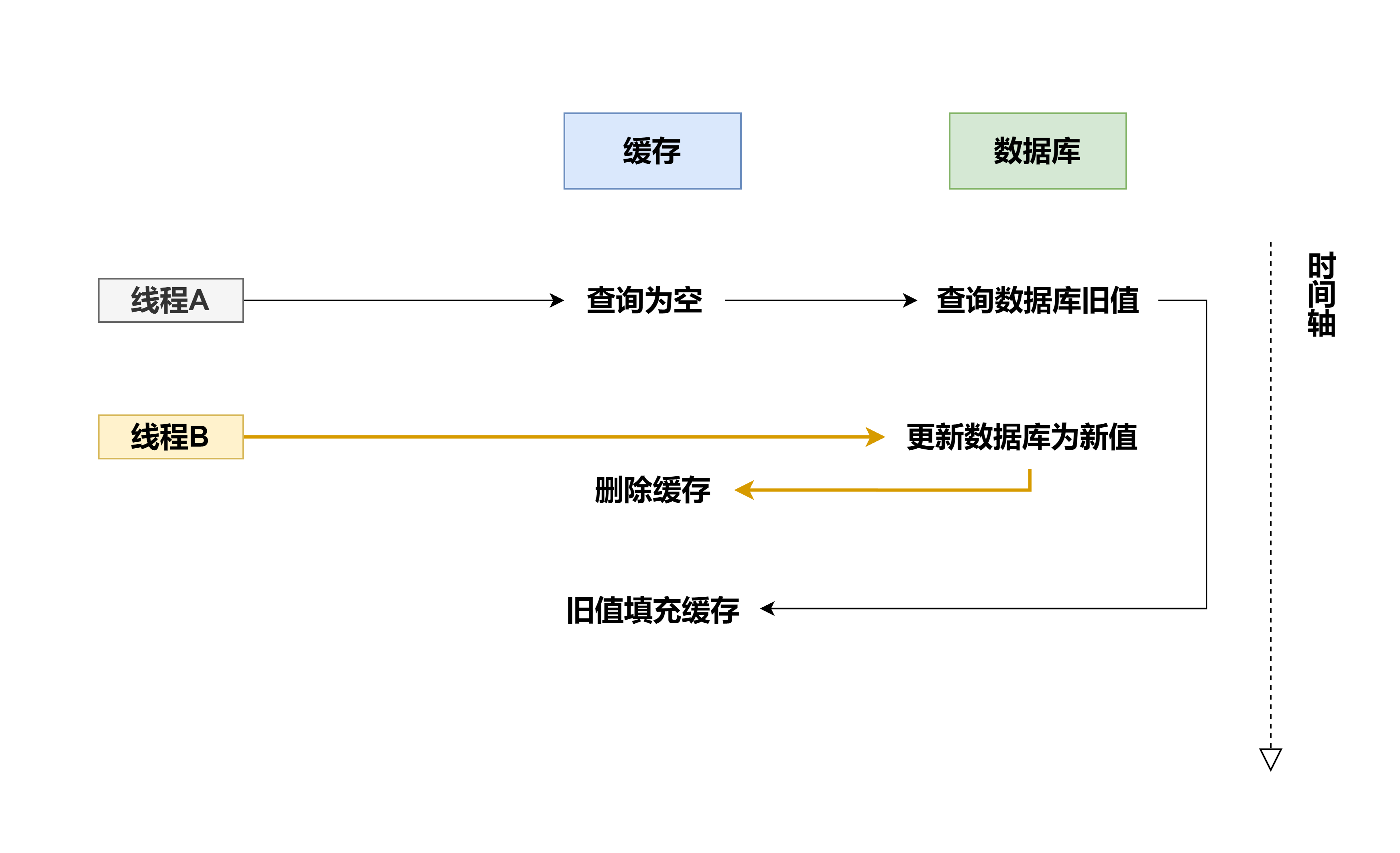
前提:缓存无数据,数据库有数据。
A:查询,B:更新
过程如下:step1: A 查缓存,无数据,去读数据库,旧值;step2: B 更新数据库为新值;step3: B 删除缓存;step4: A 将旧值写入缓存。
该场景最终也会出现不一致,产生的根源是是读比写慢,这种是小概率事件,一般很少出现,如果非要解决这种情况,还是上面说的延迟双删
Read/Write Through
上面的方式,数据库是缓存的来源,主导是数据库,而 Read/Write Through模式,相当于缓存占主导。在 cache-aside 模式中,我们的应用代码需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository)。而 Read/Write Through 做法是把更新数据库(Repository)的操作由缓存自己代理了,所以,对于应用层来说,就简单很多了。可以理解为,应用认为后端就是一个单一的存储,而存储自己维护自己的 Cache。
Read Through
Read Through 就是在查询操作中更新缓存,也就是说,当缓存失效的时候(过期或 LRU 换出),Cache Aside 是由调用方负责把数据加载入缓存,而 Read Through 则用缓存服务自己来加载,从而对应用方是透明的。
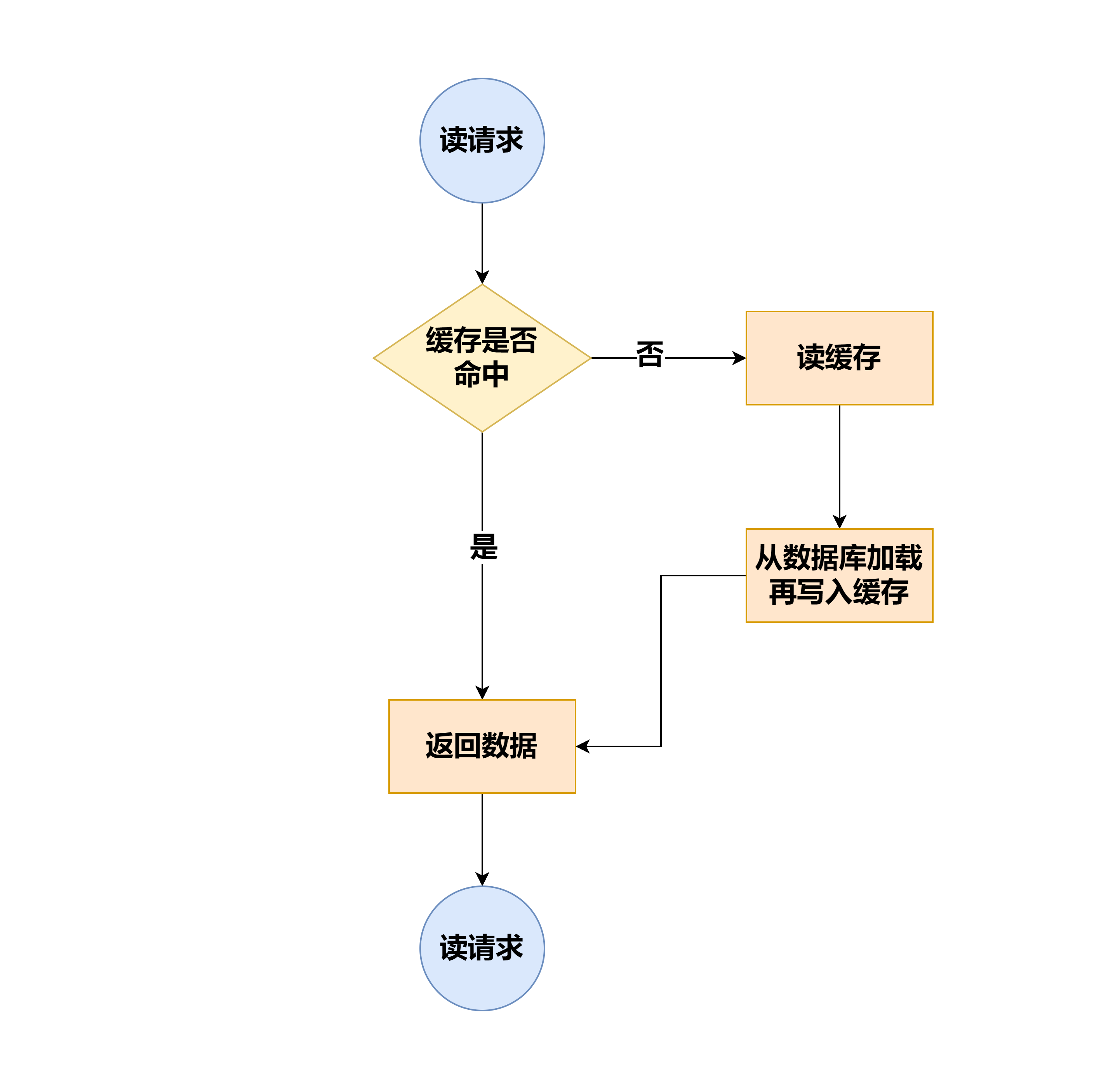
这个简要流程和 Cache-Aside 很像,其实Read-Through就是多了一层Cache-Provider,流程如下:
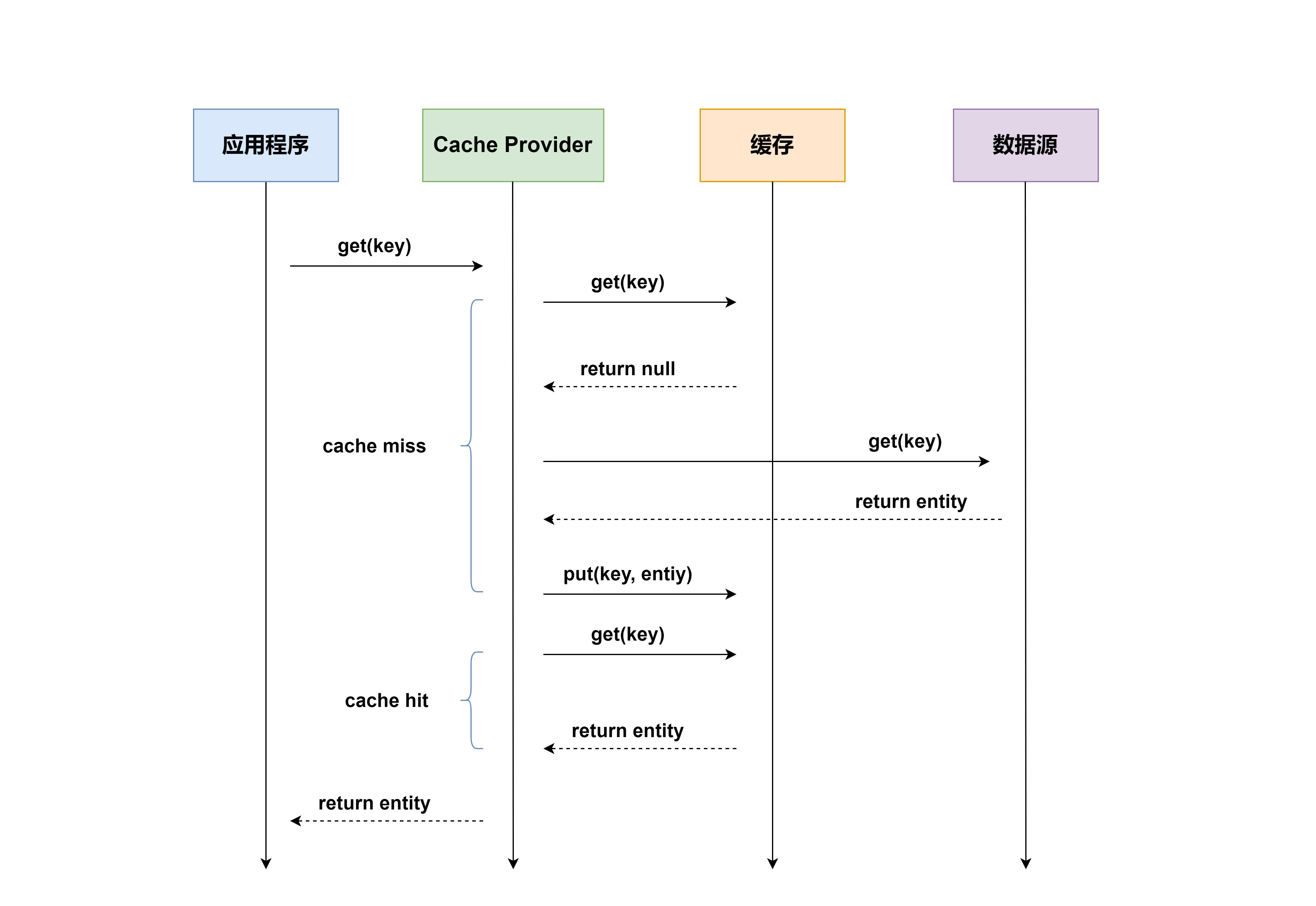
Read-Through 实际只是在Cache-Aside之上进行了一层封装,它会让程序代码变得更简洁,同时也减少数据源上的负载
Write Through
Write Through,和 Read Through 相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由 Cache 自己同步更新数据库
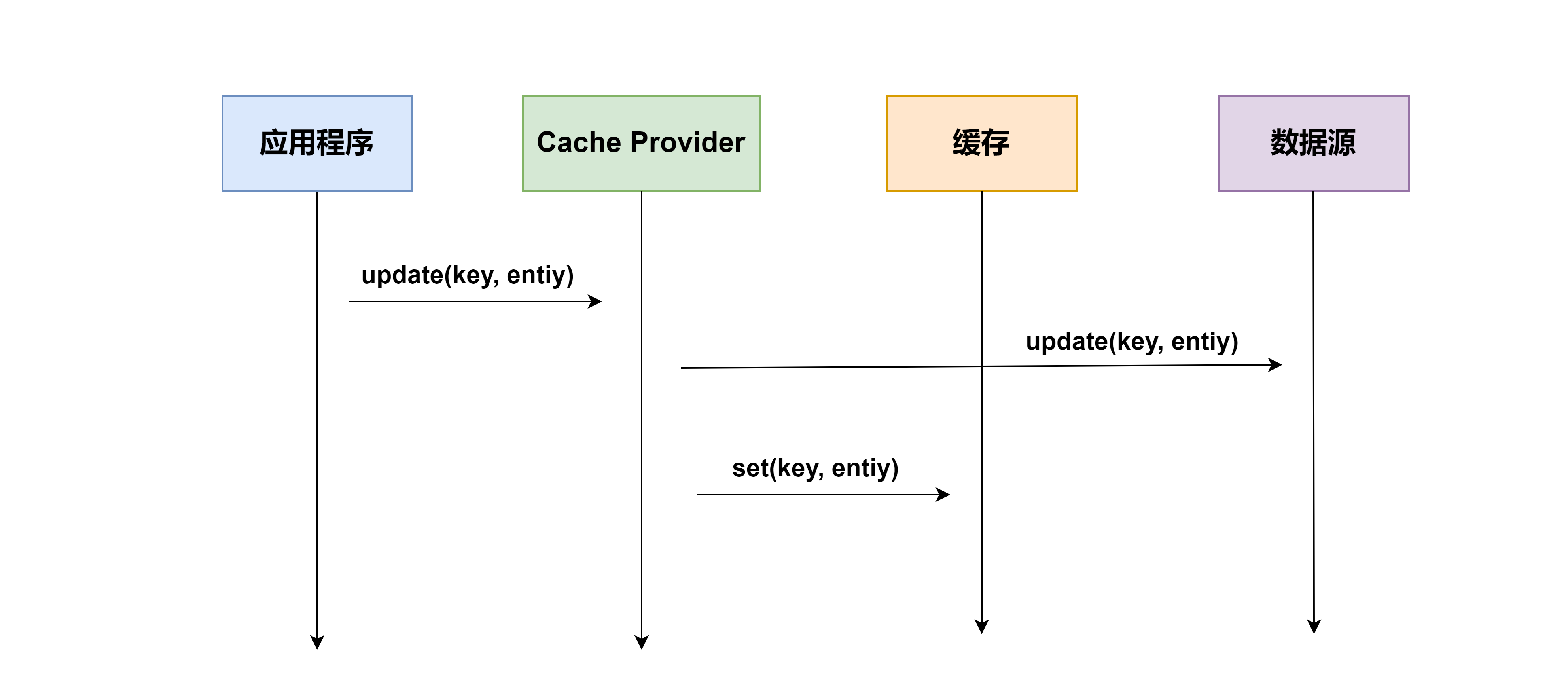
值得注意的是,该方案在实现过程中,程序启动时,需将数据库的数据, 提前放到缓存中,不能等启动完成,再放缓存中。
Read Through/Write Through 策略的特点是由缓存节点而非应用程序来和数据库打交道,在我们开发过程中相比 Cache Aside 策略要少见一些,原因是我们经常使用的分布式缓存组件,无论是 Memcached 还是 Redis 都不提供写入数据库和自动加载数据库中的数据的功能。而我们在使用本地缓存的时候可以考虑使用这种策略。
Write Behind
Write Behind 又叫 Write Back。底层思想就是在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的 I/O 操作速度飞快(因为是直接操作内存),同时带来吞吐量大幅上升;因为异步,Write Behind 还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
但是,其带来的问题是,数据不是强一致性的,而且可能会丢失(我们知道 Unix/Linux 非正常关机会导致数据丢失,就是因为这个事)。在软件设计上,我们基本上不可能做出一个没有缺陷的设计,就像算法设计中的时间换空间,空间换时间一个道理,有时候,强一致性和高性能,高可用和高性性是有冲突的。如果说软件功能模块的思维是逻辑与实现,那么软件架构设计的思维是权衡与取舍。
这种方式下,缓存和数据库的一致性不强,对一致性要求高的系统要谨慎使用。但是它适合频繁写的场景,MySQL 的InnoDB Buffer Pool 机制就使用到这种模式。
Write Behind 实际应用
按照实际架构应用层面落地参考方案,流程图如下(以用户发表视频为例)
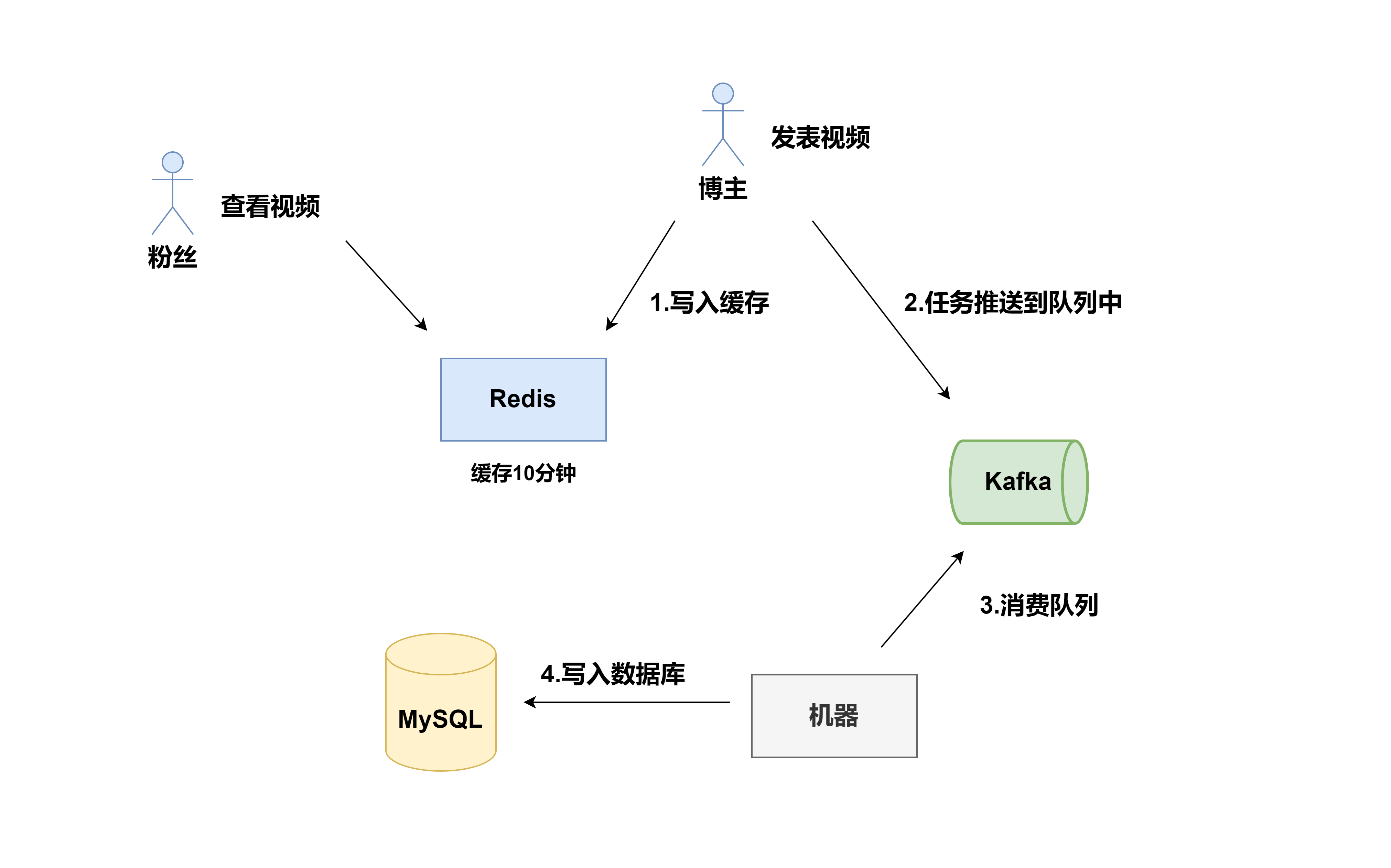
按照这种方案,正常来说只要 10 分钟内数据正常写完就没问题,可以实现最终一致性,但是一旦超出 10 分钟,就会缓存失效,造成缓存不一致
如果出现这种 kafka 消费入库失败,则会触发报警系统,看具体是什么问题,基本上 kaka 入库失败只有两种情况,一种是出错了,另外一种是消费能力不够,那么直接扩容即可
后记
说到底这个问题根本没有通用方案,需要根据场景做权衡,比如类似于微博这样高并发场景,那么上边只要涉及删除缓存的方案基本都很难实现,因为很可能删除缓存的下一时间热点数据直接全部打在数据库上,整个服务直接崩溃
然后本质上缓存和数据库的更新就不是一个原子操作,想要彻底实现强一致性,可以了解下分布式事务或是其他强一致性协议,比如说两阶段提交协议 —— prepare, commit/rollback,比如 Java 7 的 XAResource,还有 MySQL 5.7 的 XA Transaction,有些 cache 也支持 XA,比如 EhCache
参考链接
- 美团二面:Redis 与 MySQL 双写一致性如何保证? - 掘金 (juejin.cn)
- 分布式缓存--缓存与数据库一致性方案 - 小猪爸爸 - 博客园 (cnblogs.com)
- 如何保障 MySQL 和 Redis 的数据一致性? | 二哥的 Java 进阶之路 (javabetter.cn)
- 三种缓存策略:Cache Aside 策略、Read/Write Through 策略、Write Back 策略
- 分布式系统中的缓存与数据库一致性
本文由博客一文多发平台 OpenWrite 发布!
相关文章:
分布式系统:缓存与数据库一致性问题
前言 缓存设计是应用系统设计中重要的一环,是通过空间换取时间的一种策略,达到高性能访问数据的目的;但是缓存的数据并不是时刻存在内存中,当数据发生变化时,如何与数据库中的数据保持一致,以满足业务系统…...

JavaEE企业开发新技术5
目录 2.18 综合应用-1 2.19 综合应用-2 2.20 综合应用-3 2.21 综合应用-4 2.22 综合应用-5 Synchronized : 2.18 综合应用-1 反射的高级应用 DAO开发中,实体类对应DAO的实现类中有很多方法的代码具有高度相似性,为了提供代码的复用性,降低…...

mysql dump导出导入数据
前言 mysqldump是MySQL数据库中一个非常有用的命令行工具,用于备份和还原数据库。它可以将整个数据库或者特定的表导出为一个SQL文件,以便在需要时进行恢复或迁移。 使用mysqldump可以执行以下操作: 备份数据库:可以使用mysqld…...

刷题记录3
# 10 字符个数统计 描述 编写一个函数,计算字符串中含有的不同字符的个数。字符在 ASCII 码范围内( 0~127 ,包括 0 和 127 ),换行表示结束符,不算在字符里。不在范围内的不作统计。多个相同的字符只计算一次 例如,对…...
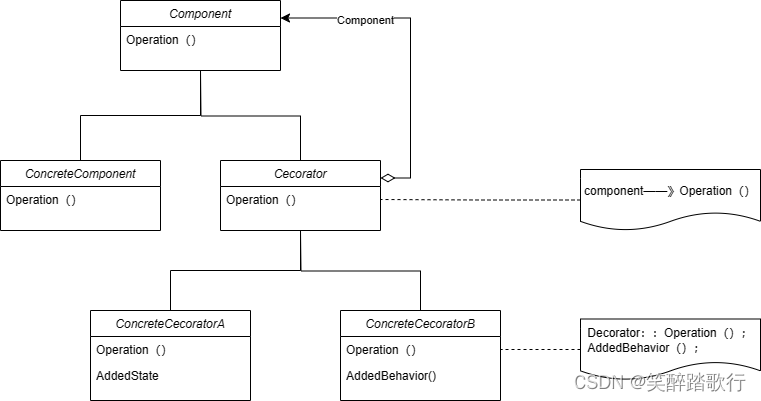
Decorator 装饰
意图 动态的给一个对象添加一些额外的职责。就增加功能而言,Decorator模式比生成子类更加灵活 结构 其中: Component定义一个对象接口,可以给这些对象动态的添加职责。ConcreteComponent定义一个对象,可以给这个对象添加一些职…...

SpringMVC:搭建第一个web项目并配置视图解析器
👉需求:用spring mvc框架搭建web项目,通过配置视图解析器达到jsp页面不得直接访问,实现基本的输出“hello world”功能。👩💻👩💻👩💻 1 创建web项目 1…...
一文了解HTTPS的加密原理
HTTPS是一种安全的网络通信协议,用于在互联网上提供端到端的加密通信,确保数据在客户端(如Web浏览器)与服务器之间传输时的机密性、完整性和身份验证。HTTPS的加密原理主要基于SSL/TLS协议,以下详细阐述其工作过程&…...

Ubuntu系统空间整理
查看文件大小命令 查看文件以及文件夹大小 ls -hl #查看文件大小,-h 表示Human-Readable ll -h #查看文件夹的大小 #du命令查看文件或文件夹的磁盘使用空间,–max-depth 用于指定深入目录的层数。#查看当前目录已经使用总大小及当前目录下一级文件或…...

PHP Storm 2024.1使用
本文讲的是phpstorm 2024.1最新版本激活使用教程,本教程适用于windows操作系统。 1.先去idea官网下载phpstorm包,我这里以2023.2最新版本为例 官网地址:https://www.jetbrains.com/zh-cn/phpstorm/ 2.下载下来后安装,点下一步 …...

王东岳-知鱼之乐【边读边记】1
2024-04-15 21:00 终于打算开始读这本书了,作者王东岳,第一次听到这个名字,是因为传说王东岳是李善友的师父,我是先从混沌学院知道的李善友,因为李善友还是有东西的,所以我对王东岳起步也是非常尊敬的。所以…...
迁移docker部署的GitLab
目录 1. 背景2. 参考3. 环境4. 过程4.1 查看原docker启动命令4.2 打包挂载目录传至新宿主机并创建对应目录4.3 保存镜像并传至新宿主机下4.4 新宿主机启动GitLab容器 5 故障5.1 容器不断重启5.2 权限拒绝5.3 容器内错误日志 6 重启容器服务正常7 总结 1. 背景 最近接到一个任务…...

今年消费新潮流:零元购商业模式
今天给大家推荐一种极具创新的电子商务模式:零元购商业模式 这个模式支持消费者以零成本或极低成本购买商品。这种模式主要通过返现、积分、优惠券等方式来减少支付金额,使消费者实现“零成本”购物的目标。 人民网在去年发表了一篇文章。 总结了一下&a…...

Go导入私有仓库
使用go.mod依赖第三方库时,有以下要求: 代码仓库托管于VCS(版本控制系统);代码仓库是公开的;仓库地址使用域名访问;仓库域名支持HTTPS访问。 对于自己或者公司内部搭建的私有git,这些条件是比较难同时满足…...

GIS GeoJSON数据获取
1、工具地址 DataV.GeoAtlas地理小工具系列 2、界面预览...

书生·浦语大模型实战营 | 第3次学习笔记
前言 书生浦语大模型应用实战营 第二期正在开营,欢迎大家来学习。(参与链接:https://mp.weixin.qq.com/s/YYSr3re6IduLJCAh-jgZqg 第三堂课的视频链接:https://www.bilibili.com/video/BV1QA4m1F7t4/ 本次笔记是学习完第三堂课…...
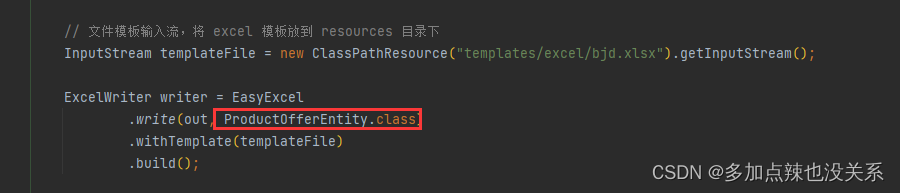
easyExcel - 按模板导出
目录 前言一、情景介绍二、文档介绍2.1 读取模板2.2 填充模板 三、代码示例3.1 案例一:工资表3.2 案例二:报价单 四、我所遇到的问题 前言 Java-easyExcel入门教程:https://blog.csdn.net/xhmico/article/details/134714025 之前有介绍过如…...
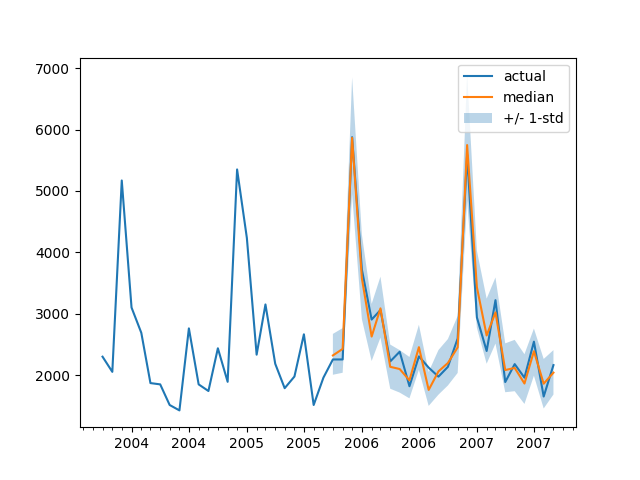
使用 Tranformer 进行概率时间序列预测实战
使用 Transformers 进行概率时间序列预测实战 通常,经典方法针对数据集中的每个时间序列单独拟合。然而,当处理大量时间序列时,在所有可用时间序列上训练一个“全局”模型是有益的,这使模型能够从许多不同的来源学习潜在的表示。…...
LLM大语言模型助力DataEase小助手,新增气泡地图,DataEase开源数据可视化分析平台v2.5.0发布
2024年4月8日,DataEase开源数据可视化分析平台正式发布v2.5.0版本。 这一版本的功能升级包括:新增DataEase小助手支持,通过结合智能算法和LLM(即Large Language Model,大语言模型)能力,DataEas…...

维修伊顿触摸屏不显示工业电脑人机界面EATON XVS-430-10MPI-1-10 深圳捷达工控维修
人机界面 (HMI) XP500 工业 PC 系列 以不同的方式思考工业平板电脑 对于严酷、高要求的应用,工业平板电脑设定了可配置性和稳健性的标准。伊顿的 XP500 系列工业平板电脑凭借防刮钢化玻璃屏幕、铸铝外壳和无风扇设计满足了这些需求。这些功能使 XP500 HMI成为一款节…...
趣话最大割问题:花果山之群猴博弈
内容来源:量子前哨(ID:Qforepost) 编辑丨浪味仙 排版丨 沛贤 深度好文:3000字丨15分钟阅读 趋利避害,是所有生物遵循的自然法则,人类也不例外。 举个例子,假如你是某生鲜平台的配…...

GPT Image 2 刷屏之后,我才发现真正该补的是向量引擎:deepseek v4、api、key 和 Agent 工作流实战笔记
GPT Image 2 刷屏之后,我才发现真正该补的是向量引擎:deepseek v4、api、key 和 Agent 工作流实战笔记雷猴啊,最近 AI 圈又热闹了。 前脚大家还在讨论 Agent 能不能自己写代码、自己跑任务、自己做项目;后脚 GPT Image 2 又把生图…...

FPGA实现JPEG-LS硬件编码器:架构、算法与工程实践
1. 项目概述:一个开源的JPEG-LS硬件编码器最近在翻看一些开源硬件项目时,看到了一个名为“FPGA-JPEG-LS-encoder”的仓库。这个项目由WangXuan95维护,从名字就能一眼看出,它是一个用硬件描述语言实现的JPEG-LS图像压缩编码器&…...

如何高效清理重复文件:DupeGuru专业使用秘诀
如何高效清理重复文件:DupeGuru专业使用秘诀 【免费下载链接】dupeguru Find duplicate files 项目地址: https://gitcode.com/gh_mirrors/du/dupeguru 你是否曾因电脑中大量重复文件占用宝贵存储空间而烦恼?面对散落在各个文件夹中的重复照片、文…...

嵌入式测试学习第 10天:主控、外设、传感器、通信模块
嵌入式常见硬件架构:主控、外设、传感器、通信模块一、整体架构总览二、第一部分:主控(设备大脑)真实实物样貌实物标注解读核心概念小白通俗理解嵌入式测试常见故障三、第二部分:外设模块(人机交互执行机构…...

Vue.js数据同步利器:vsync库的核心原理与工程实践
1. 项目概述:一个基于Vue.js的现代化同步解决方案最近在梳理前端状态管理和数据同步的实践时,我遇到了一个挺有意思的开源项目:Hardik455abc/vsync。乍一看这个标题,vsync很容易让人联想到计算机图形学里的“垂直同步”࿰…...

基于Next.js与MDX构建现代化静态博客:技术选型与实战指南
1. 项目概述:一个面向开发者的现代化博客引擎 如果你是一名前端开发者,或者对使用 React 生态构建个人博客、技术文档站点感兴趣,那么 leerob/next-mdx-blog 这个项目绝对值得你花时间深入研究。这不是一个简单的博客模板,而是…...
给你的Spring Boot应用做一次性能体检)
从“救火”到“防火”:用Arthas火焰图(profiler)给你的Spring Boot应用做一次性能体检
从“救火”到“防火”:用Arthas火焰图给你的Spring Boot应用做一次性能体检 在快节奏的互联网开发中,性能问题往往像一场突如其来的火灾,让开发者疲于奔命。传统的“救火式”排查——等到用户投诉后再手忙脚乱地查日志、加监控——已经无法满…...

v7发布72小时内,我用237组prompt验证了这5个被官方隐瞒的关键升级,速看
更多请点击: https://intelliparadigm.com 第一章:Midjourney v7核心架构跃迁与隐性能力解封 Midjourney v7 并非简单迭代,而是以异构扩散引擎(Heterogeneous Diffusion Engine, HDE)为基座的系统级重构。其核心突破在…...

5分钟快速上手:TMSpeech离线语音转文字终极指南
5分钟快速上手:TMSpeech离线语音转文字终极指南 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech TMSpeech是一款完全免费的Windows离线语音转文字工具,能够实时将电脑声音或麦克风输入转换为文…...

我为什么劝测试新人先别急着学自动化?
在软件测试行业,“自动化”这三个字几乎成了某种图腾。打开任何一个技术社区,铺天盖地的自动化测试框架教程、编程语言速成班广告、以及“不懂自动化就要被淘汰”的焦虑贩卖,像潮水一样涌向每一个刚踏入测试门槛的新人。不少新人在还没搞清楚…...