java es相关操作
一.es 后期修改分片数量
在Elasticsearch中一旦索引创建后,分片的数量就不能直接更改。如果需要更改分片的数量,你需要按照以下步骤操作:
-
创建一个新的索引,并指定所需的分片数量。
-
将旧索引的数据复制到新索引中。
-
关闭旧索引,并将新索引设置为激活状态。
-
<dependencies><!-- 添加Elasticsearch客户端依赖 --><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.10.2</version> <!-- 请根据需要替换为合适的版本号 --></dependency><!-- 其他依赖... --> </dependencies> -
import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.client.indices.CreateIndexRequest; import org.elasticsearch.client.indices.CreateIndexResponse; import org.elasticsearch.client.indices.GetIndexRequest; import org.elasticsearch.client.indices.UpdateAliasesRequest; import org.elasticsearch.client.indices.UpdateIndexSettingsRequest; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.xcontent.XContentType;public class ChangeShardsExample {public static void main(String[] args) throws IOException {// 初始化Elasticsearch客户端try (RestHighLevelClient client = new RestHighLevelClient(...)) {// 创建新索引String newIndex = "new_index";CreateIndexRequest createIndexRequest = new CreateIndexRequest(newIndex);createIndexRequest.settings(Settings.builder().put("index.number_of_shards", 5) // 设置新的分片数量.put("index.number_of_replicas", 1));CreateIndexResponse createIndexResponse = client.indices().create(createIndexRequest, RequestOptions.DEFAULT);if (createIndexResponse.isAcknowledged()) {System.out.println("新索引创建成功");// 复制旧索引数据到新索引// ...// 关闭旧索引String oldIndex = "old_index";client.indices().close(new CloseIndexRequest(oldIndex), RequestOptions.DEFAULT);// 更新别名,使新索引可用AliasActions aliasAction = new AliasActions(AliasActions.Type.ADD).index(newIndex).alias(oldIndex);UpdateAliasesRequest aliasRequest = new UpdateAliasesRequest().actions(aliasAction);client.indices().updateAliases(aliasRequest, RequestOptions.DEFAULT);System.out.println("旧索引已关闭,新索引设置为可用");}}} }es的分片数量的计算规则是最好保证每个分片的的数据在20G左右,根据实际情况测试
二。 es 查询 and or 等
es是使用DSL语句进行查询的,java提供了相关api,生成最终的DSL语句,下面代码中的boolQueryBuilder对象中就有最终的DSL语句。
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.search.SearchHit;// 假设你已经有了一个RestHighLevelClient实例client
RestHighLevelClient client;// 创建一个BoolQueryBuilder来构建AND和OR查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();// 添加AND查询条件
boolQueryBuilder.must(QueryBuilders.matchQuery("field1", "value1"));
boolQueryBuilder.must(QueryBuilders.matchQuery("field2", "value2"));// 添加OR查询条件
boolQueryBuilder.should(QueryBuilders.matchQuery("field3", "value3"));
boolQueryBuilder.should(QueryBuilders.matchQuery("field4", "value4"));// 设置查询的索引
String index = "your_index";// 创建一个搜索请求
SearchRequest searchRequest = new SearchRequest(index);// 创建搜索源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(boolQueryBuilder);// 设置搜索源
searchRequest.source(searchSourceBuilder);try {// 执行搜索SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);// 处理搜索结果for (SearchHit hit : searchResponse.getHits().getHits()) {System.out.println(hit.getSourceAsString());}
} catch (IOException e) {e.printStackTrace();
}三. es 根据字段排序
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.search.sort.SortOrder;
import org.elasticsearch.search.sort.FieldSortBuilder;import java.io.IOException;public class ElasticsearchSortExample {public static void main(String[] args) throws IOException {// 初始化Elasticsearch客户端(这里需要根据实际情况进行配置)RestHighLevelClient client = new RestHighLevelClient(...);// 创建搜索请求并设置索引名SearchRequest searchRequest = new SearchRequest("your_index");// 构建搜索源构建器SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 设置查询条件(这里以匹配所有为例)searchSourceBuilder.query(QueryBuilders.matchAllQuery());// 添加排序searchSourceBuilder.sort(new FieldSortBuilder("your_sort_field").order(SortOrder.ASC)); // 根据字段升序排序// 将搜索源构建器设置到搜索请求中searchRequest.source(searchSourceBuilder);// 执行搜索SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);// 处理搜索结果(这里仅打印命中数量)System.out.println("Total hits: " + searchResponse.getHits().getTotalHits().value);// 关闭客户端client.close();}
}四.es评分修改(评分是搜索的结果排序依据是es中一个重要的点)
在Elasticsearch中,评分是一个复杂的过程,它涉及到文档与查询的匹配程度。评分是基于文档与查询中的某个字段相关性来计算的。在Elasticsearch中,有多种方法来影响评分过程,例如:
-
使用不同的相关性模型,如TF-IDF,BM25等。
-
使用函数查询,调整字段的权重。
-
使用索引时的设置,如分析器,提高某些字段的重要性。
评分的计算过程如下:
-
计算查询与文档的匹配程度。
-
计算每个字段的评分。
-
将字段的评分累加到文档级别的评分中。
-
对所有文档进行排序,评分高的排在前面。
以下是一个简单的Java代码示例
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.metrics.AvgAggregationBuilder;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.metrics.AvgAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.ValueCountAggregationBuilder;
import org.elasticsearch.search.aggregations.pipeline.PipelineAggregatorBuilders;
import org.elasticsearch.search.aggregations.pipeline.BucketSelectorPipelineAggregationBuilder;// 假设你已经有了一个RestHighLevelClient实例clientSearchRequest searchRequest = new SearchRequest("index_name"); // 替换为你的索引名
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());// 添加一个计分函数,比如使用一个辅导聚合
searchSourceBuilder.functionScore().scoreMode("sum") // 可以是 "sum", "multiply", "min", "max", "avg".setMinScore(1); // 设置最小分数,如果所有函数分数加起来低于这个值,则文档将被丢弃// 你可以添加多个计分函数,比如使用一个平均聚合
AvgAggregationBuilder avgAggregation = AggregationBuilders.avg("avg_price").field("price");
searchSourceBuilder.functionScore().add(new FunctionScoreQueryBuilder.FilterFunctionBuilder(new QueryBuilders.matchAllQuery()).scoreMode("multiply").setFilter(QueryBuilders.matchQuery("type", "electronics")).setWeight(1.5))).add(new FunctionScoreQueryBuilder.FilterFunctionBuilder().scoreFunction(new FunctionScoreQueryBuilder.WeightBuilder().setWeight(2.0)).setFilter(QueryBuilders.matchQuery("type", "books"))));searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = client.search(searchRequest);// 处理搜索响应// 注意:确保在完成操作后关闭client以释放资源5.es使用自定义的评分
script_score 是es中用于自定义脚本计算评分,Java也提供了相关api,script_score可以接受参数用于计算,比方说20岁左右的人优先查询
//client 创建代码省略// 初始化你的Elasticsearch客户端
String indexName = "your_index"; // 你的索引名SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
ScriptScoreQueryBuilder scriptScoreQueryBuilder = QueryBuilders.scriptScoreQuery(QueryBuilders.matchAllQuery());
//Script 可以支持从外部传参,参数是一个map,如果需要从客户端传入参数可以这样使用
Script script = new Script("doc['age'].value - 20"); // 假设age是你存储年龄的字段
scriptScoreQueryBuilder.script(script);searchSourceBuilder.query(scriptScoreQueryBuilder);
searchSourceBuilder.sort("_score"); // 根据得分排序SearchRequest searchRequest = new SearchRequest(indexName);
searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
相关文章:

java es相关操作
一.es 后期修改分片数量 在Elasticsearch中一旦索引创建后,分片的数量就不能直接更改。如果需要更改分片的数量,你需要按照以下步骤操作: 创建一个新的索引,并指定所需的分片数量。 将旧索引的数据复制到新索引中。 关闭旧索引…...

腾讯EdgeOne产品测评体验——开启安全防护,保障数据无忧
当今时代数字化经济蓬勃发展人们的生活逐渐便利,类似线上购物、线上娱乐、线上会议等数字化的服务如雨后春笋般在全国遍地生长,在人们享受这些服务的同时也面临着各式各样的挑战,如网络数据会不稳定、个人隐私容易暴露、资产信息会被攻击等。…...

机器视觉图形处理软件介绍
机器视觉图形处理软件介绍 一.VisionPro 康耐视公司推出的 系统,具有快速而强大的应用系统开发能力。可快速建立原型和易于集成 。具有高可靠性、硬件灵活性。VisionPro 提供了易于应用的原型、发展和应用。VisionProQuickStart 原型环境加速了强大机器视觉系统的…...

C# WinForm简介
Winform是什么? .Net开发平台中对Windows Form的简称,基于.Net Framework平台 的客户端开发技术,一般使用C#编程。Windows 风格的控件,以及事件,直接使用,开发快速。Windows Form:Windows窗体Windows应用程…...

概念:CPU、内存、磁盘、Android内存分配
cpu CPU的全称是Central Processing Unit,中文名称为中央处理单元。它是计算机硬件的核心部件,负责解释计算机程序指令并处理计算机软件中的数据。简言之,CPU执行计算机程序中的操作指令,包括基本算术、逻辑、控制和输入/输出&am…...

Vue 图片加载失败显示默认图片
方法一:通过onerror属性加载默认图片 <img :src"img" :onerror"defaultImg" /><script> export default {data() {return {img: , // 访问图片的ip地址defaultImg: this.src ${require(/assets/images/right/default-person.png)…...

【Sentinel的限流使用】⭐️SpringBoot整合Sentinel实现Api的限流
目录 前言 一、Sentinel下载 二、SpringBoot 整合 Sentinel 三、流控规则 章末 前言 小伙伴们大家好,上次使用OpenFeign时用到了 Hystrix实现熔断和限流的功能,但是发现该工具已经停止维护了,于是想到了Spring Cloud Alibaba开发的Sentin…...
【示例】MySQL-SQL语句优化
前言 本文主要讲述不同SQL语句的优化策略。 SQL | DML语句 insert语句 插入数据的时候,改为批量插入 插入数据的时候,按照主键顺序插入 大批量插入数据的时候(百万),用load指令,从本地文件载入&#x…...

QT 线程的使用
1.头文件: #include<QThread> 2.在.h文件中定义全局: QThread* threadTraj; void threadTrajProcess();//回调函数 3.在.cpp文件中: threadTraj new QThread();//初始化 //连接槽函数 QObject::connect(threadTraj, &QThre…...
Python基于flask的豆瓣电影分析可视化系统
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...
【迅为iTOP-4412-linux 系统制作(4)】ADB 或者 TF 卡烧写测试
准备工作 编译生成的内核镜像uImage 和设备树 dtb 文件“exynos4412-itop-elite.dtb”已经可以使用了。 把编译生成的uimage和dtb文件。拷贝fastboot工具。官方的u-boot-iTOP-4412.bin 也拷贝到 platform-tools 文件夹目录内。system.img 也拷贝到 platform-tools 文件夹目录…...

阿里云对象存储OSS批量上传,单个上传,批量删除,单个删除!
请自行替换秘钥: #阿里云 OSS src/main/resources/application.properties #不同的服务器,地址不同 aliyun.oss.file.endpointhttps://oss-cn-hangzhou.aliyuncs.com aliyun.oss.file.accessKeyIdLTAI5t9wUqCoD42qPGRy8S aliyun.oss.file.accessKeySecre…...
Python的国际化和本地化【第162篇—国际化和本地化】
👽发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击进入巨牛的人工智能学习网站】。 随着全球化的发展,多语言支持在软件开发中变得越来越重要。Python作为一种流行的…...

播放Samba协议下的音视频文件
Samba(也被称为SMB/CIFS)是一个用于在局域网内共享文件和打印服务的协议,广泛应用于Windows和Linux系统之间的文件共享。 一、展示Samba服务器下的文件 使用如jcifs这样的Java库来在安卓应用中集成SMB/CIFS客户端功能。这个库提供了与SMB/CI…...

Excel全套213集教程
Excel全套213集教程 包含技术入门93集 图表17集 数据透视35集 公式函数68 基础入门 93节 https://www.alipan.com/s/cMxuPstkS1x 提取码: 77dd 点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视…...

【七 (1)指标体系建设-构建高效的故障管理指标体系】
目录 文章导航一、故障概述1、故障:2、故障管理: 二、指标体系概述1、指标2、指标体系 三、指标体系构建难点1、管理视角2、业务视角3、技术视角 四、指标体系构建原则1、与战略目标对齐2、综合和平衡3、数据可获得性4、可操作性5、具体和可衡量6、参与和…...

Go gin框架(详细版)
目录 0. 为什么会有Go 1. 环境搭建 2. 单-请求&&返回-样例 3. RESTful API 3.1 首先什么是RESTful API 3.2 Gin框架支持RESTful API的开发 4. 返回前端代码 go.main index.html 5. 添加静态文件 main.go 改动的地方 index.html 改动的地方 style.css 改动…...
Git分布式版本控制系统——Git常用命令(二)
五、Git常用命令————分支操作 同一个仓库可以有多个分支,各个分支相互独立,互不干扰 分支的相关命令,具体如下: git branch 查看分支 git branch [name] 创建分支&#x…...
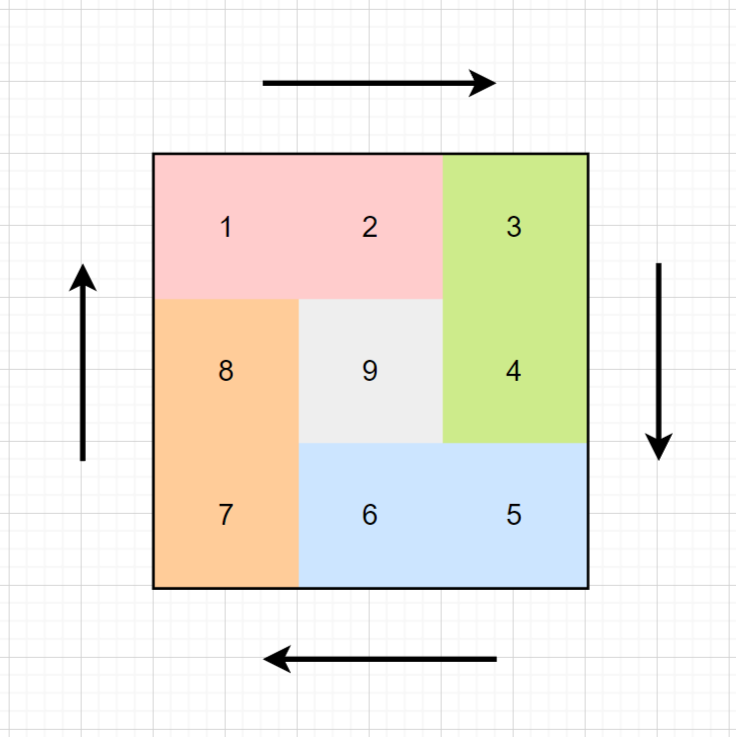
LeetCode 59.螺旋矩阵II
LeetCode 59.螺旋矩阵II 1、题目 力扣题目链接:59. 螺旋矩阵 II - 力扣(LeetCode) 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。 示例 1࿱…...

03-JAVA设计模式-适配器模式
适配器模式 设么是适配器模式 它属于结构型模式,主要用于将一个类的接口转换成客户端所期望的另一种接口,从而使得原本由于接口不兼容而无法协同工作的类能够一起工作。 适配器模式主要解决的是不兼容接口的问题。在软件开发中,经常会有这…...

告别时钟线!用三根线搞定高速传输:MIPI C-PHY硬件连接与编码原理详解
告别时钟线!用三根线搞定高速传输:MIPI C-PHY硬件连接与编码原理详解 在高速数据传输领域,传统并行总线的时钟同步机制已成为提升速率的瓶颈。MIPI联盟推出的C-PHY标准,以革命性的"三线无时钟"架构打破了这一僵局。本文…...

近屿AI学:白天做运维,晚上学AI,两天入职
何屿(化名)白天还在做传统运维,晚上已经开始补AI课程。听起来有点折腾,但他比谁都清楚,稳定并不等于安全。AI兴起后,岗位要求正在变,旧经验能撑多久,他心里没底。与其等到被动调整&a…...

从Hub到交换机:一个被遗忘的环路案例,带你重新审视STP的实际价值与配置陷阱
从Hub到交换机:一个被遗忘的环路案例,带你重新审视STP的实际价值与配置陷阱 在某个制造业工厂的机房角落,一台老式集线器(HUB)仍然顽强地工作着——它连接着几台关键设备,因为某些历史原因尚未被替换。当网…...

从RRM到RIC:手把手拆解5G O-RAN智能控制器如何“接管”你的基站
从RRM到RIC:5G O-RAN智能控制器的技术演进与实战解析 在5G网络架构的演进浪潮中,O-RAN联盟提出的开放无线接入网理念正在重塑传统基站的控制方式。本文将带您深入探索无线资源管理(RRM)如何进化为近实时智能控制器(Nea…...

通过MCP协议集成ChatGPT桌面应用,实现AI助手无缝协作
1. 项目概述与核心价值最近在折腾AI工作流,发现一个痛点:我经常在Claude Desktop或者Cursor这类支持MCP协议的AI助手里面写代码、分析问题,但有时候需要调用ChatGPT的能力,比如让它帮我润色一段英文,或者用它的代码解释…...

从人工到有机:数字健康AI的范式转变与工程实践
1. 从“人工”到“有机”:一次关于智能本质的范式转变在数字健康领域,我们每天都在与“人工智能”打交道。从辅助医生阅片的影像分析系统,到预测患者风险的算法模型,AI似乎已经成为推动医疗革新的核心引擎。然而,当我们…...

百度网盘群晖套件终极指南:3步实现NAS云存储完美整合
百度网盘群晖套件终极指南:3步实现NAS云存储完美整合 【免费下载链接】synology-baiduNetdisk-package 项目地址: https://gitcode.com/gh_mirrors/sy/synology-baiduNetdisk-package 想在群晖NAS上直接管理百度网盘文件?这个开源套件让你轻松实…...

Awesome BigData实时数据集成平台:CDC连接器与数据同步工具终极指南
Awesome BigData实时数据集成平台:CDC连接器与数据同步工具终极指南 【免费下载链接】awesome-bigdata A curated list of awesome big data frameworks, ressources and other awesomeness. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-bigdata G…...

反PUA30天 Day15:“你格局小“——当这句话出现时,通常意味着对方已经没有别的论据了 |乐想屋
“本文来自「乐想屋」公众号,系列更新[职场反PUA30天觉醒计][职场生存暗规则],每天一篇清醒认知,拒绝内耗,少踩坑,快速成长。”绩效沟通那天,leader跟我说了一句话:「你不要老盯着自己那一亩三分…...

杰理之部分芯片跑2.3G出现连接不上【篇】
部分芯片跑2.3G出现连接不上...